Hadoop学习笔记(HDP)-Part.15 安装HIVE
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十五、安装HIVE
1.配置MetaStore
利用ambari创建的MySQL作为MetaStore,创建用户hive及数据库hive
mysql -uroot -p
CREATE DATABASE hive;
CREATE USER 'hive'@'%' IDENTIFIED BY 'lnyd@LNsy115';
GRANT ALL ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
2.安装
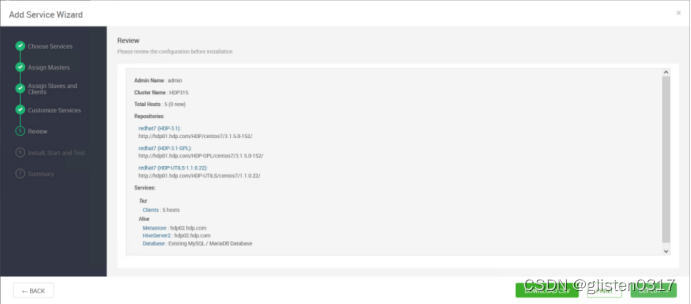
在服务中添加Hive
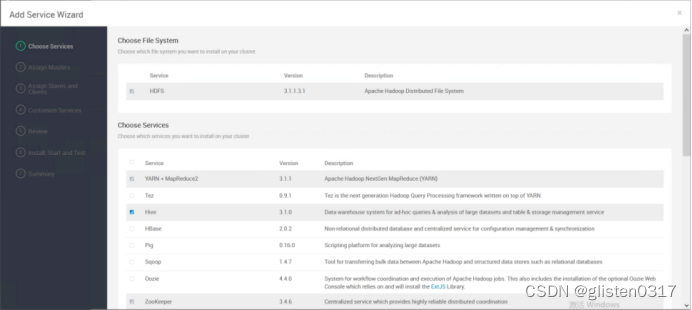
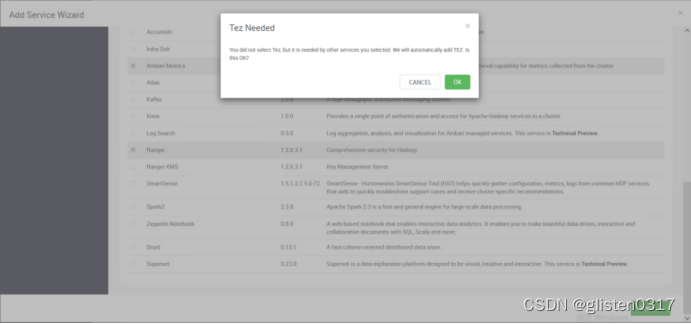
安装hive时需要同步安装Tez
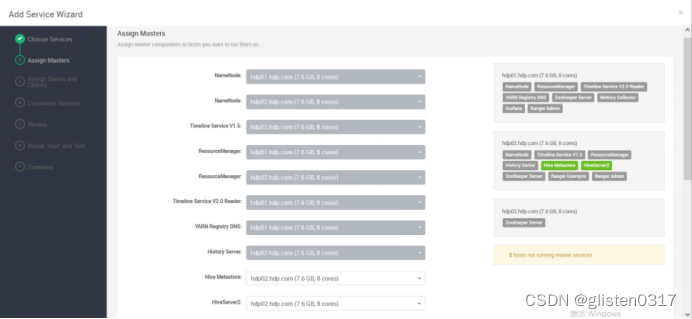
DATABASE
Hive Database:Existing MySQL / MariaDB
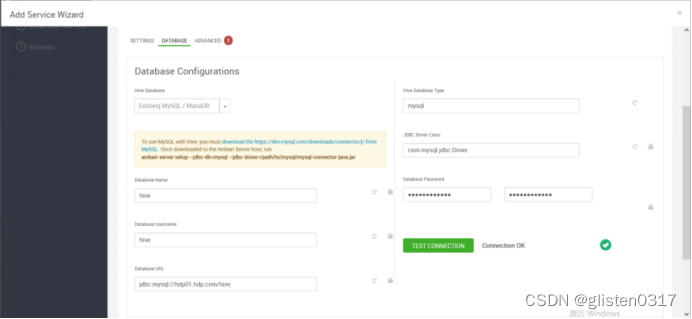
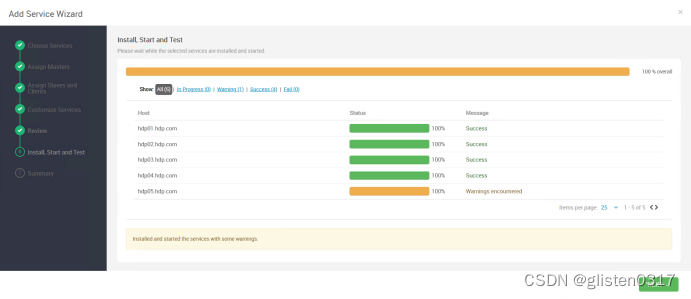

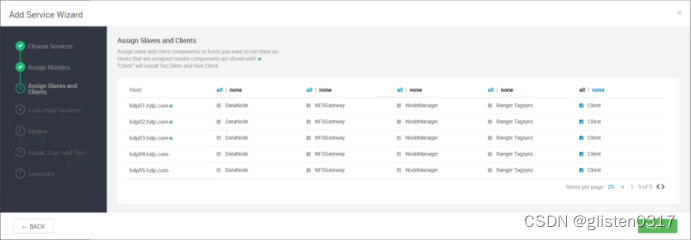
安装完成后,需要按照提示将hdfs、yarn等服务进行重启。
Ambari安装后,Hive使用了Tez作为计算引擎,也可以修改为MR或Spark,在配置文件中调整,/usr/hdp/3.1.5.0-152/hive/conf/hive-site.xml
<property><name>hive.execution.engine</name><value>tez</value></property>
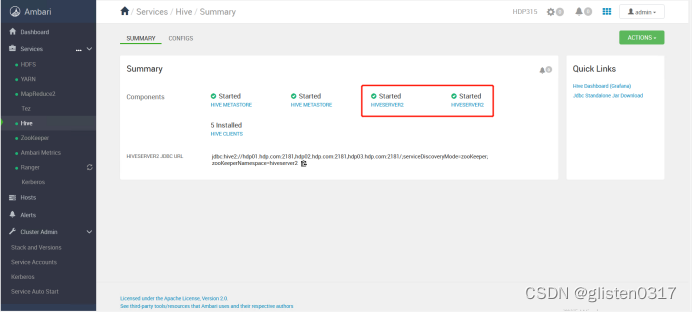
3.高可用
(1)MetaSore HA
ACTIONS->Add Hive Metastore
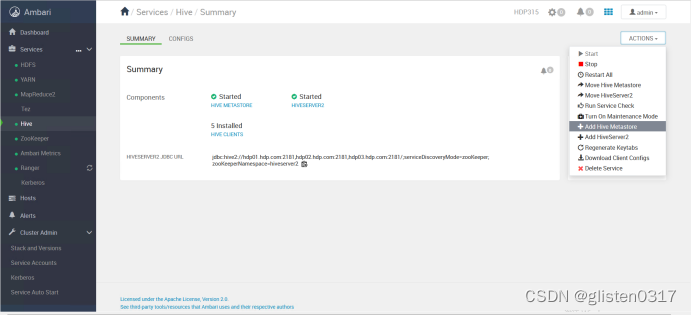
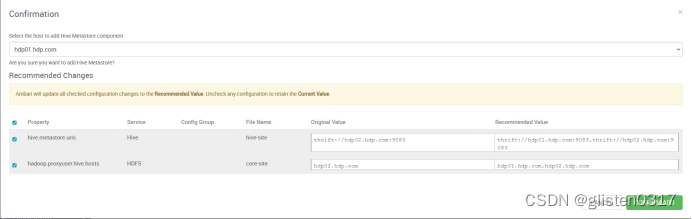
重启相关服务后完成HA启用。
(2)HiveServer2 HA
ACTIONS->Add HiveServer2
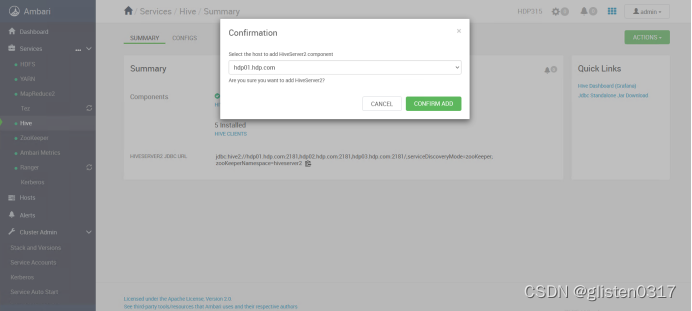
重启HIVE和Tez服务后完成HA启用。
4.Ranger授权
在Ranger上新建策略完成对租户的授权
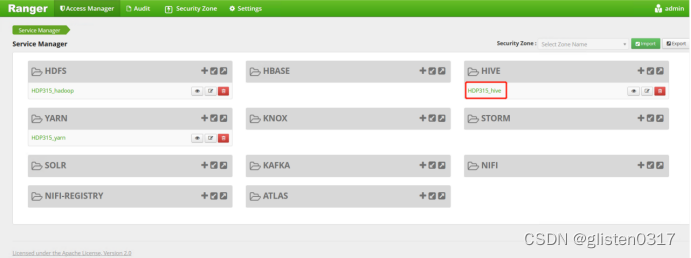

权限策略可以精细到列
5.常用指令
(1)CLI连接
类似于mysql的命令行工具,但是只能操作本地的Hive服务,无法通过JDBC连接远程服务,且sql执行结果没有格式化,看起来不是很直观。
先用keytab登录,使用hive客户端进入
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
hive

可以设置一些基本参数,让hive使用起来更便捷:
让提示符显示当前库
set hive.cli.print.current.db=true;
显示查询结果时显示字段名称
set hive.cli.print.header=true;
设置只对当前会话有效,重启hive会话后就失效。
创建测试数据库test_hive_db
create database test_hive_db;

查看数据库的信息
desc database test_hive_db;
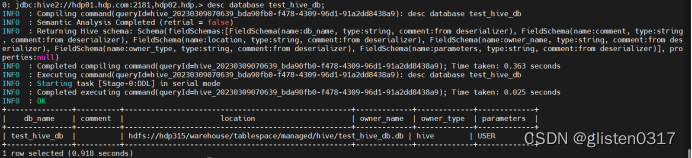
从输出结果看,测试数据库test_hive_db存储在hdfs上,位置为hdfs://hdp315/warehouse/tablespace/managed/hive/test_hive_db.db
(2)Beeline连接
HiveServer2支持一个新的命令行Shell,称为:Beeline,后续将会使用Beeline替代Hive CLI。Beeline基于SQLLine CLI的JDBC客户端。Hive CLI和Beeline都属于命令行操作模式,主要区别是Hive CLI只能操作本地的Hive服务,而Beeline可以通过JDBC连接远程服务。
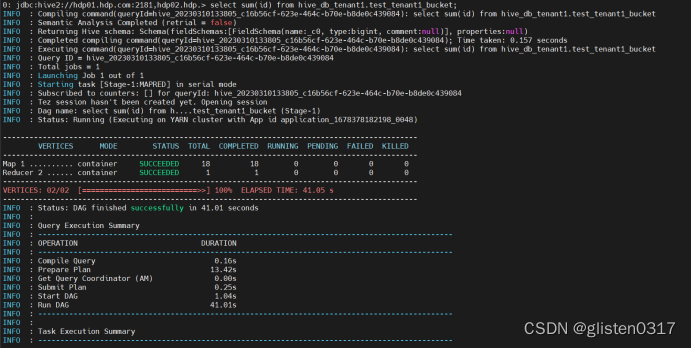
开启了kerberos认证的hadoop集群,hive默认使用kerberos认证。先以hive/hdp01.hdp.com@HDP315.COM身份登录,创建数据库hive_db_tenant1和tenant2、表hive_table_tenant1和hive_table_tenant2,在ranger上分别将两个租户赋权到对应的数据库上,然后以tenant1身份连接,分别尝试连接两个数据库,看是否有权限访问
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
create database hive_db_tenant1;
create database hive_db_tenant2;
create table hive_db_tenant1.hive_table_tenant1 (id int,name string,address string,phone string);
create table hive_db_tenant2.hive_table_tenant2 (id int,name string,address string,phone string);
kdestroy
kinit -kt /root/keytab/tenant1.keytab tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
describe hive_db_tenant1.hive_table_tenant1;
describe hive_db_tenant2.hive_table_tenant2;
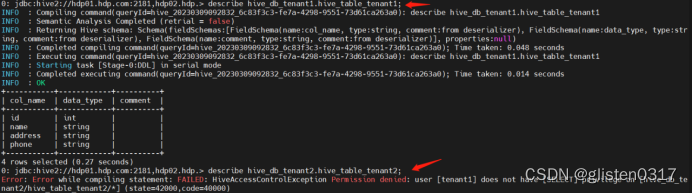
从结果看,无法访问hive_table_tenant2的表。
(3)导入数据等测试
生成6GB大小的文件
#!/bin/bash
cat /dev/null > /root/bigFile.txt
for((i=1;i<=100000000;i++));
doecho "$i,testname$i,testaddress$i,testphonenumber$i" >> /root/bigFile.txt;
done
本次测试使用tenant1
kinit -kt /root/keytab/tenant1.keytab tenant1
hdfs dfs -put /root/bigFile.txt /testhdfs/tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
set tez.queue.name=tenant1;
① 导入测试
测试一次性导入和切分导入的性能
新建表,用于一次性导入
CREATE TABLE `test_tenant1_one`(
`id` int,
`name` string,
`address` string,
`phone` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_one.db';
执行导入
LOAD DATA INPATH 'hdfs://hdp315/testhdfs/tenant1/bigFile.txt' INTO TABLE hive_db_tenant1.test_tenant1_one;

新建表,用于分桶导入,分桶的实质就是对分桶的字段做了hash,然后存放到对应文件中,所以说如果原有数据没有按key hash,需要在插入分桶的时候hash,也就是说向分桶表中插入数据的时候必然要执行一次MAPREDUCE,这也就是分桶表的数据基本只能通过从结果集查询插入的方式进行导入
CREATE TABLE `test_tenant1_bucket`(
`id` int,
`name` string,
`address` string,
`phone` string
)
CLUSTERED BY(id) INTO 16 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_bucket.db';
执行导入
INSERT OVERWRITE TABLE test_tenant1_bucket SELECT * FROM test_tenant1_one;
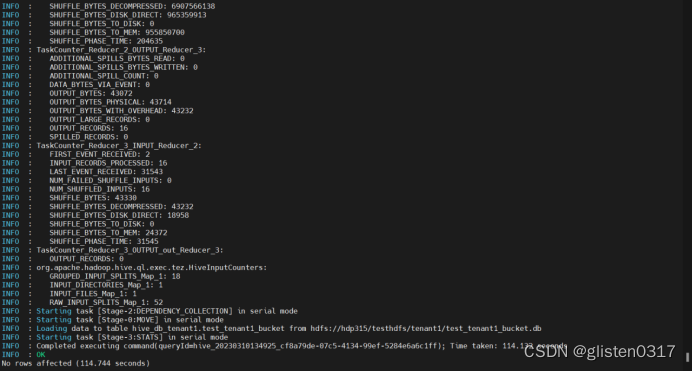
此时,分桶后的文件会分成16个分片
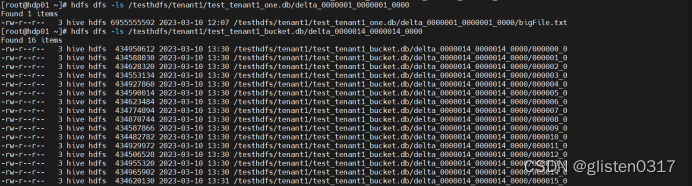
② 查询测试
对测试的数据库进行查询操作
SELECT SUM(id) FROM hive_db_tenant1.test_tenant1_bucket;
6.常见报错
(1)提示没有权限调用default队列
Select查询不报错,但count、insert、load等操作需要调用tez引擎时会报错
报错信息:
ERROR : Job Submission failed with exception 'java.io.IOException(org.apache.hadoop.yarn.exceptions.YarnException: org.apache.hadoop.security.AccessControlException: User hive does not have permission to submit application_1678378182198_0002 to queue default
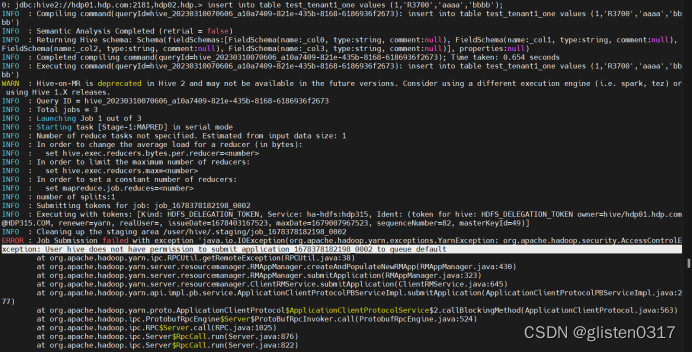
默认调用的是default队列,需要手工指定使用的队列
mr指定队列:
set mapreduce.job.queuename=tenant1;
tez指定队列:
set tez.queue.name=tenant1;
相关文章:
Hadoop学习笔记(HDP)-Part.15 安装HIVE
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

【力扣100】4.移动零
题目链接 我的题解: class Solution:def moveZeroes(self, nums: List[int]) -> None:"""Do not return anything, modify nums in-place instead."""# 思路是先计算共有几个0,然后remove几次,再末位加几个…...

Filebeat使用指南
Filebeat介绍主要优势主要功能配置日志的解析Kibana中设置日志解析安装步骤安装Filebeat安装监控通过prometheus监控 Filebeat和Logstash的主要区别 Filebeat介绍 Filebeat是使用Golang实现的轻量型日志采集器,也是Elasticsearch stack的一员。它可以作为一个agent…...
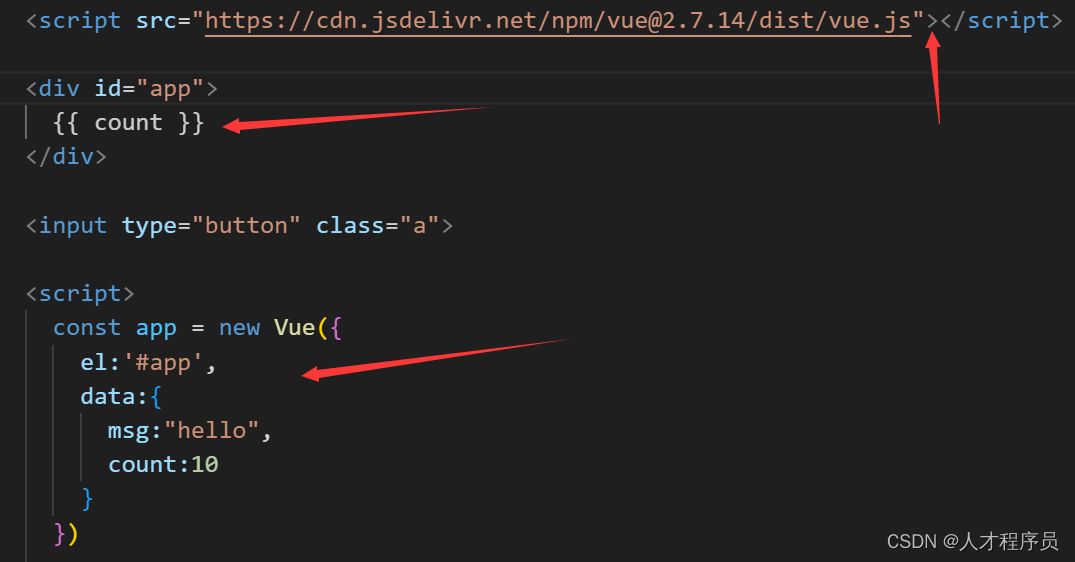
【Vue2】Vue的介绍与Vue的第一个实例
文章目录 前言一、为什么要学习Vue二、什么是Vue1.什么是构建用户界面2.什么是渐进式Vue的两种开发方式: 3.什么是框架 三、创建Vue实例四、插值表达式 {{}}1.作用:利用表达式进行插值,渲染到页面中2.语法3.错误用法 五、响应式特性1.什么是响…...

十五届蓝桥杯分享会(一)
注:省赛4月,决赛6月 一、蓝桥杯整体介绍 1.十四届蓝桥杯软件电子赛参赛人数:C 8w,java/python 2w,web 4k,单片机 1.8w,嵌入式/EDA5k,物联网 300 1.1设计类参赛人数:平…...

原生video设置控制面板controls显示哪些控件
之前我们学习了如何使用原生video播放视频 今天来一个进阶版的——设置控制面板controls显示哪些控件 先看一下当我们使用原生video时,controls属性为true时,相关代码如下: 正常的控制面板默认显示的控件有:播放、时间线、音量调…...
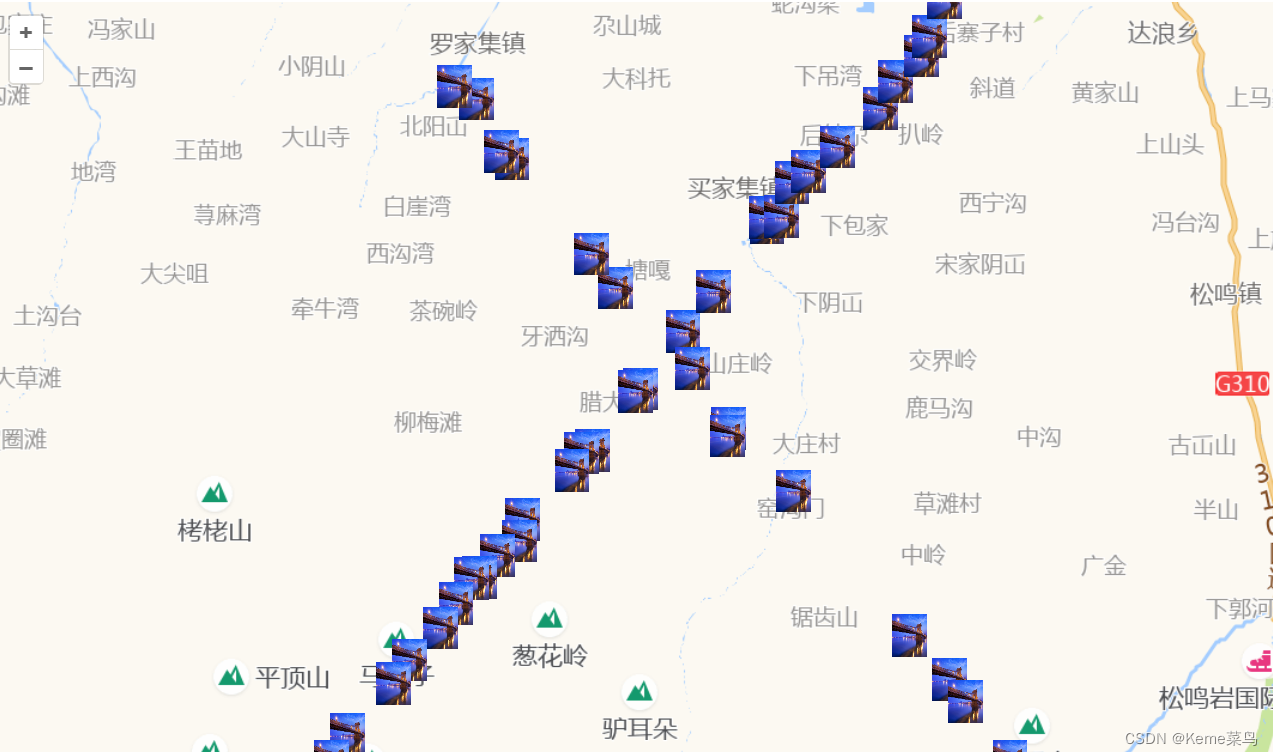
openlayers地图使用---跟随地图比例尺动态标绘大小的一种方式2
openlayers地图使用—跟随地图比例尺动态标绘大小的一种方式2 预期:随着地图比例尺放大缩小,地图上的标绘随着变化尺寸 思路:通过不断添加地图图层实现标绘的动态缩放 优点:标绘放大缩小非常流畅 缺点:标绘超过1000…...

C语言期末考试复习PTA数据类型及表达式-分支结构程序-循环结构-数组经典选择题
目录 第一章:C语言数据类型和表达式 第一题: 第二题: 第三题: 第四题: 第五题: 第六题: 第七题: 第八题: 第九题: 第二章:分支结构程序…...
RHEL8_Linux访问NFS存储及自动挂载
本章主要介绍NFS客户端的使用 创建FNS服务器并通过NFS共享一个目录在客户端上访问NFS共享的目录自动挂载的配置和使用 1.访问NFS存储 前面介绍了本地存储,本章就来介绍如何使用网络上的存储设备。NFS即网络文件系统,所实现的是 Linux 和 Linux 之间的共…...

python 使用 AppiumService 类启动appium server
一、前置说明 在Appium的1.6.0版本中引入了AppiumService类,可以很方便的通过该类来管理Appium服务器的启动和停止。 二、操作步骤 import osfrom appium.webdriver.appium_service import AppiumService as OriginalServerfrom libs import pathclass AppiumSer…...
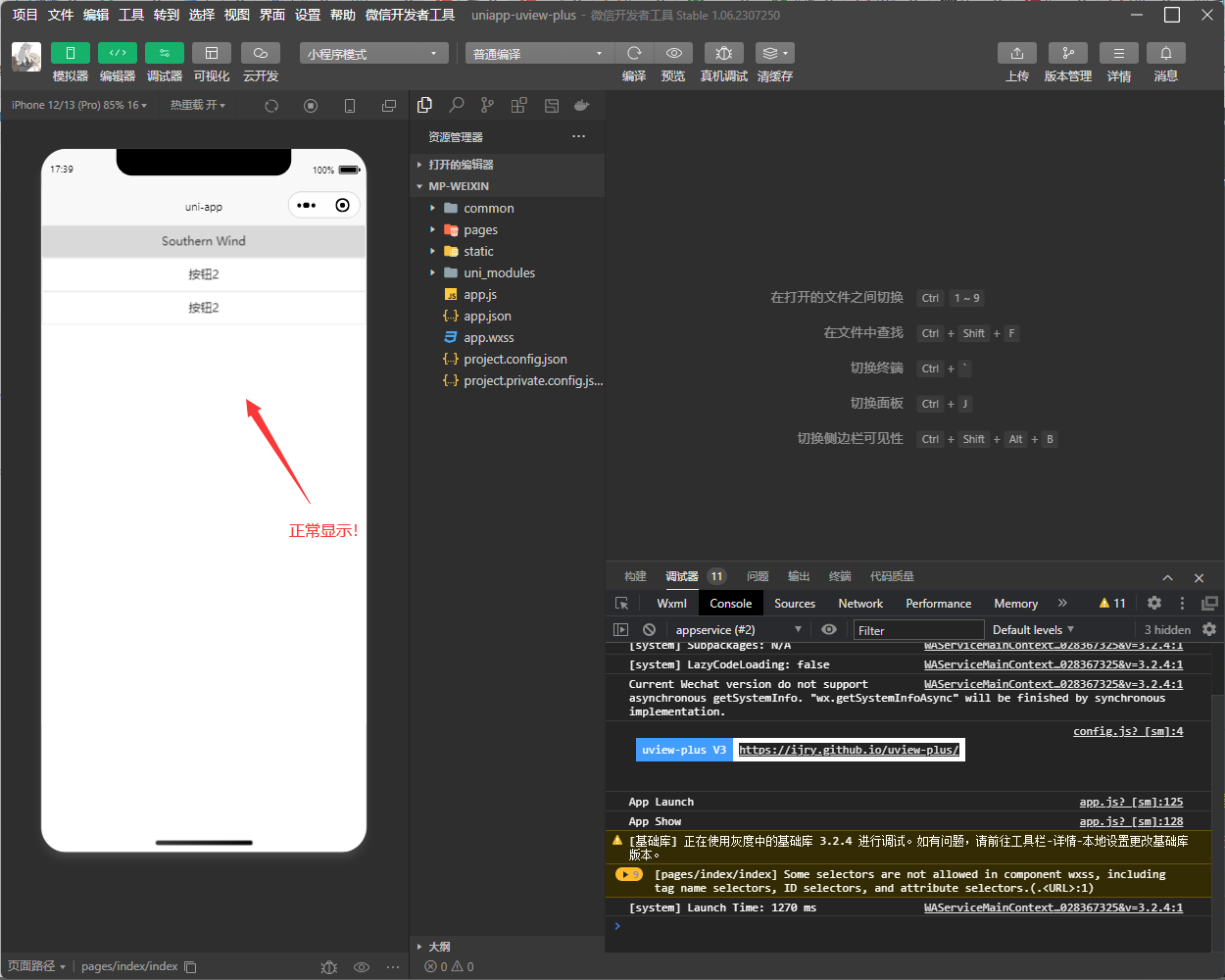
HbuilderX使用Uniapp+Vue3安装uview-plus
如果你是vue2版本想使用uniapp去配置uviewui库可以参考之前的文章 小程序的第三方ui库推荐较多的还是uview的,看起来比较美观,功能也比较完善,下面将提一下Vue3安装uview-plus库的教程 创建项目 安装 首先进入官网 uView-Plus 直接下载并导…...
的`Selector`类来实现非阻塞的Socket监听)
【Android】Java NIO(New I/O)的`Selector`类来实现非阻塞的Socket监听
如果你不想使用循环来监听客户端的连接和数据,你可以使用Java NIO(New I/O)的Selector类来实现非阻塞的Socket监听。Selector类提供了一种选择一组已经就绪的通道的机制,这样你就不需要使用循环来等待连接和数据。 以下是使用Sel…...
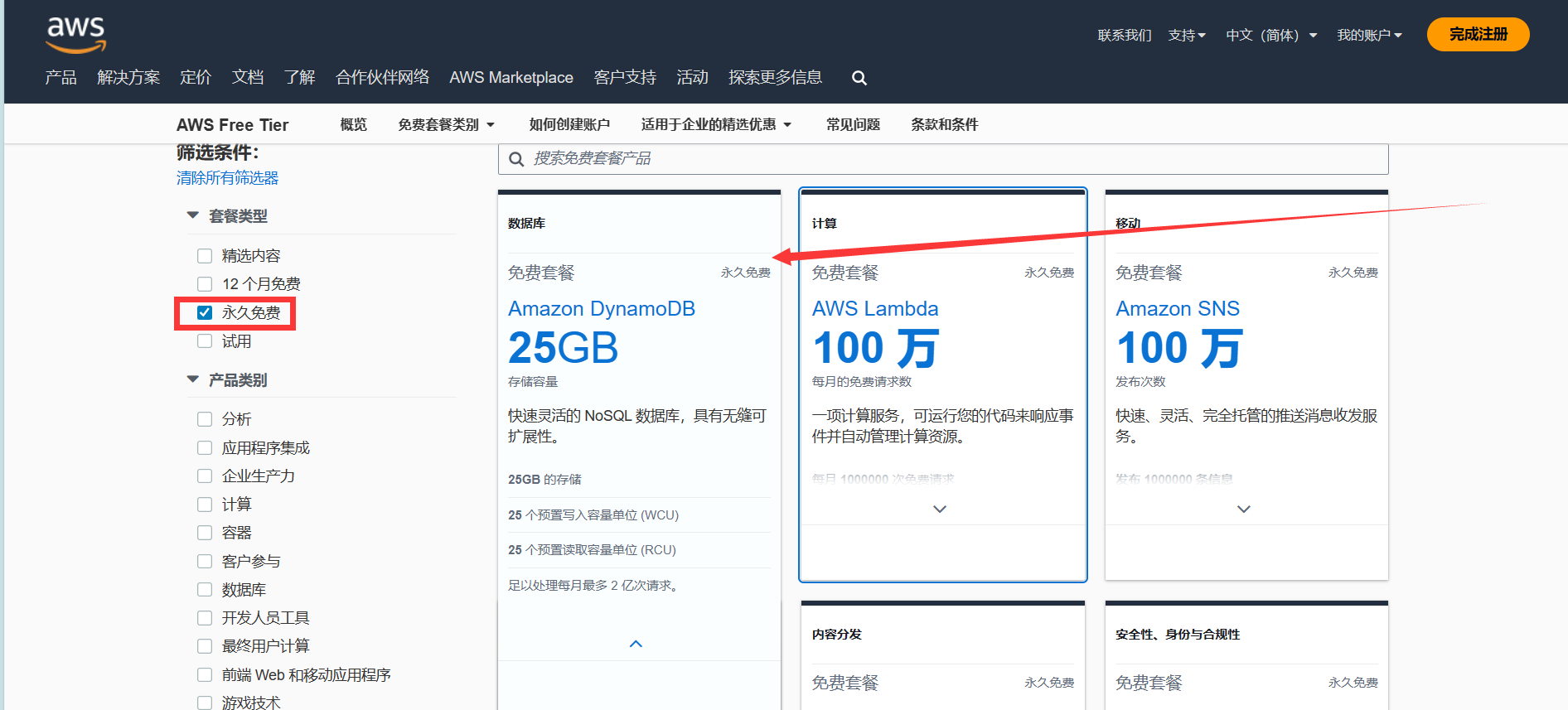
『亚马逊云科技产品测评』在当前飞速发展的AI人工智能时代云服务技术哪家强?
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 文章目录 引言一、亚马逊&阿里云发展历史介绍1.1 亚马逊发展历史1.2…...

经典神经网络——ResNet模型论文详解及代码复现
论文地址:Deep Residual Learning for Image Recognition (thecvf.com) PyTorch官方代码实现:vision/torchvision/models/resnet.py at main pytorch/vision (github.com) B站讲解: 【精读AI论文】ResNet深度残差网络_哔哩哔哩_bilibili …...
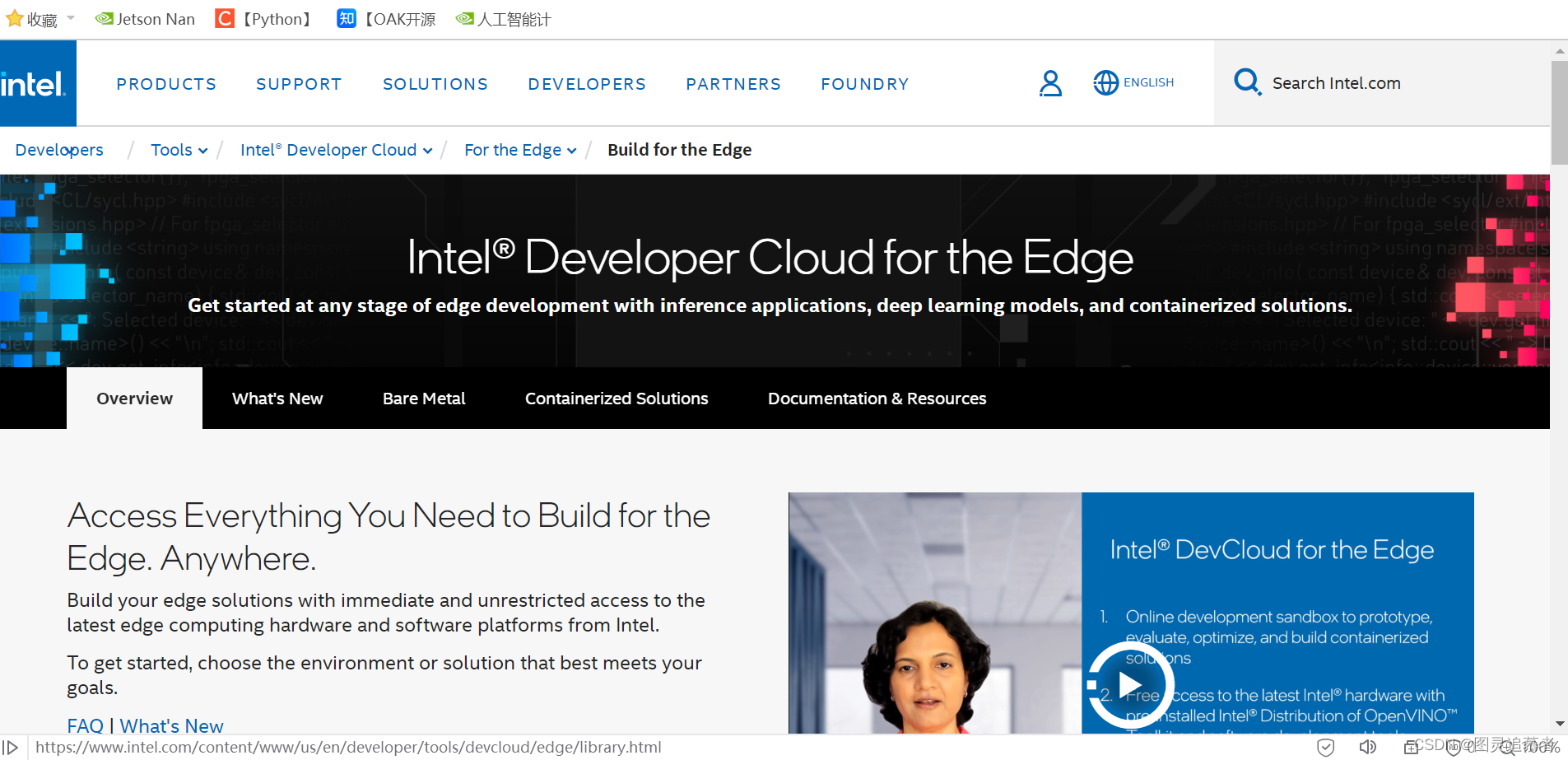
OpenCV-Python:DevCloud CodeLab介绍及学习
1.Opencv-Python演示环境 windows10 X64 企业版系统python 3.6.5 X64OpenCV-Python 3.4.2.16本地PyCharm IDE线上注册intel账号,使用DevCloud CodeLab 平台 2.DevCloud CodeLab是什么? DevCloud是一个基于云端的开发平台,提供了强大的计算…...

如何在Linux环境搭建本地SVN服务器并结合cpolar实现公网访问
目录 前言 1. Ubuntu安装SVN服务 2. 修改配置文件 2.1 修改svnserve.conf文件 2.2 修改passwd文件 2.3 修改authz文件 3. 启动svn服务 4. 内网穿透 4.1 安装cpolar内网穿透 4.2 创建隧道映射本地端口 5. 测试公网访问 6. 配置固定公网TCP端口地址 6.1 保留一个固定…...
C语言入门课程之课后习题之折半查找法
目录 1解题思路: 2代码所示: 3运行代码: 4习题不难,多刷题,练思路,最重要的不是学会了一道题,而是掌握其编程思想; 1解题思路: 折半查找法(half-interval…...

【CSP】202209-1_如此编码Python实现
文章目录 [toc]试题编号试题名称时间限制内存限制题目背景题目描述输入格式输出格式样例1输入样例1输出样例2输入样例2输出样例3输入样例3输出样例3解释子任务提示Python实现 试题编号 202209-1 试题名称 如此编码 时间限制 1.0s 内存限制 512.0MB 题目背景 某次测验后&#x…...

std::function
通过使用std::function,可以将不同类型的可调用对象封装成统一的格式,从而使用相同的接口进行调用;在设计回掉函数、事件处理 、函数对象等场景中十分有用。 ① 封装函数指针 ② 封装lambda ③ 封装成员函数等 1. 包含头文件 #include<fun…...

SQL Server——权限管理
一。SQL Server的安全机制 SQL Server 的安全性是建立在认证和访问许可两种安全机制之上的。其中.认证用来确定登录Sal Server 的用户的登录账户和密码是否正确.以此来验证其是否具有连接SQL Server 的权限;访问许可用来授予用户或组能够在数据库中执行哪…...

Linux 下用火焰图进行性能分析
软件的性能分析,往往需要查看 CPU 耗时,了解瓶颈在哪里。火焰图 (flame graph) 是性能分析的利器。 1. 火焰图简介 很多人感冒发烧的时候,往往会模仿神农氏尝百草的路子:先尝尝抗病毒的药,再试试抗细菌的药ÿ…...

Ardb源码深度解析:从网络层到存储引擎的完整架构设计
Ardb源码深度解析:从网络层到存储引擎的完整架构设计 【免费下载链接】ardb A redis protocol compatible nosql, it support multiple storage engines as backend like Googles LevelDB, Facebooks RocksDB, OpenLDAPs LMDB, PerconaFT, WiredTiger, ForestDB. …...
)
Unity SLG大地图实战:用TileManager和AOI搞定网格管理与视野同步(附Demo代码)
Unity SLG大地图开发实战:网格管理与AOI视野同步的工程化解决方案 在SLG游戏开发中,大地图系统是核心体验的基石。面对动辄数万网格的动态管理需求,以及需要与后端高效协作的视野同步问题,传统开发方式往往陷入性能瓶颈和逻辑混乱…...

画图工具2.0
在上篇文章中,我们已经对简易画图工具有了一个初步了解,下面我们要对一些具体细节进行完善并加上一些新的功能,我们直接来看升级点:1.界面类加上颜色按钮Color[] colors {Color.BLACK, Color.RED, Color.GREEN, Color.BLUE, Colo…...

常见 PE 启动盘
文章目录常见 PE 启动盘一、强烈推荐 纯净无捆绑类二、功能强大 可选推广类三、老牌经典 捆绑较多类四、官方原版常见 PE 启动盘 这里整理了一份常见的PE启动盘大全,按纯净度和口碑分类,并附上官网或可靠的下载渠道。 一、强烈推荐 纯净无捆绑类 这…...

ElevenLabs奥里亚文语音合规性警告:印度《2023语言技术法案》生效后,这4类商用场景必须重做语音备案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs奥里亚文语音合规性警告的背景与紧迫性 ElevenLabs 作为领先的文本转语音(TTS)服务提供商,近期在其 API 文档与开发者控制台中新增了针对奥里亚文…...
)
ElevenLabs成年男性语音定制全流程(含Stability Score阈值表+Voice Embedding相似度热力图)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs成年男性语音定制的核心价值与适用边界 ElevenLabs 的成年男性语音定制能力,本质上是通过深度神经声码器与说话人嵌入(speaker embedding)联合建模实现的高…...

SLO-Warden:基于错误预算的智能SLO守护平台设计与实践
1. 项目概述:一个面向SLO的智能守护者在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是“锦上添花”,而是“生死攸关”的底线。作为一线的运维工程师或SRE,我们每天都在和各种监控指标、告警风暴作斗争。传统的监控…...
)
保姆级教程:用PyTorch在MuJoCo的Ant-v2环境跑通PPO算法(附完整代码)
从零实现PPO算法:MuJoCo Ant-v2环境实战指南 在强化学习领域,让一个虚拟蚂蚁学会行走是经典的基准测试任务。本文将带你用PyTorch框架,在MuJoCo的Ant-v2环境中完整实现PPO算法。不同于理论讲解,我们聚焦于可运行的代码实现和实际…...

从实验室到机房:把eNSP里练熟的Telnet AAA配置,无缝迁移到真实华为交换机上
从模拟到实战:华为交换机Telnet AAA配置的迁移指南 当你在eNSP模拟器中反复练习Telnet AAA配置,看着那些绿色指示灯亮起时,是否曾想过:"这些命令在真实设备上真的完全一样吗?"作为一位从实验室走向机房的网络…...