高并发场景下的httpClient使用优化技巧
1. 背景
我们有个业务,会调用其他部门提供的一个基于http的服务,日调用量在千万级别。使用了httpclient来完成业务。之前因为qps上不去,就看了一下业务代码,并做了一些优化,记录在这里。
先对比前后:优化之前,平均执行时间是250ms;优化之后,平均执行时间是80ms,降低了三分之二的消耗,容器不再动不动就报警线程耗尽了。
2. 分析
项目的原实现比较粗略,就是每次请求时初始化一个httpclient,生成一个httpPost对象,执行,然后从返回结果取出entity,保存成一个字符串,最后显式关闭response和client。我们一点点分析和优化:
2.1 httpclient反复创建开销
httpclient是一个线程安全的类,没有必要由每个线程在每次使用时创建,全局保留一个即可。
2.2 反复创建tcp连接的开销
tcp的三次握手与四次挥手两大裹脚布过程,对于高频次的请求来说,消耗实在太大。试想如果每次请求我们需要花费5ms用于协商过程,那么对于qps为100的单系统,1秒钟我们就要花500ms用于握手和挥手。又不是高级领导,我们程序员就不要搞这么大做派了,改成keep alive方式以实现连接复用!
2.3 重复缓存entity的开销
原本的逻辑里,使用了如下代码:
HttpEntity entity = httpResponse.getEntity();
String response = EntityUtils.toString(entity);
这里我们相当于额外复制了一份content到一个字符串里,而原本的httpResponse仍然保留了一份content,需要被consume掉,在高并发且content非常大的情况下,会消耗大量内存。并且,我们需要显式的关闭连接
3. 实现
按上面的分析,我们主要要做三件事:一是单例的client,二是缓存的保活连接,三是更好的处理返回结果。一就不说了,来说说二。
提到连接缓存,很容易联想到数据库连接池。httpclient4提供了一个PoolingHttpClientConnectionManager 作为连接池。接下来我们通过以下步骤来优化:
3.1 定义一个keep alive strategy
关于keep-alive,本文不展开说明,只提一点,是否使用keep-alive要根据业务情况来定,它并不是灵丹妙药。还有一点,keep-alive和time_wait/close_wait之间也有不少故事。
在本业务场景里,我们相当于有少数固定客户端,长时间极高频次的访问服务器,启用keep-alive非常合适
再多提一嘴,http的keep-alive 和tcp的KEEPALIVE不是一个东西。回到正文,定义一个strategy如下:
ConnectionKeepAliveStrategy myStrategy = new ConnectionKeepAliveStrategy() {@Overridepublic long getKeepAliveDuration(HttpResponse response, HttpContext context) {HeaderElementIterator it = new BasicHeaderElementIterator(response.headerIterator(HTTP.CONN_KEEP_ALIVE));while (it.hasNext()) {HeaderElement he = it.nextElement();String param = he.getName();String value = he.getValue();if (value != null && param.equalsIgnoreCase("timeout")) {return Long.parseLong(value) * 1000;}}return 60 * 1000;//如果没有约定,则默认定义时长为60s}
};
3.2 配置一个PoolingHttpClientConnectionManager
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager();
connectionManager.setMaxTotal(500);
connectionManager.setDefaultMaxPerRoute(50);//例如默认每路由最高50并发,具体依据业务来定
也可以针对每个路由设置并发数。
3.3 生成httpclient
httpClient = HttpClients.custom().setConnectionManager(connectionManager).setKeepAliveStrategy(kaStrategy).setDefaultRequestConfig(RequestConfig.custom().setStaleConnectionCheckEnabled(true).build()).build();
注意:使用setStaleConnectionCheckEnabled方法来逐出已被关闭的链接不被推荐。更好的方式是手动启用一个线程,定时运行closeExpiredConnections 和closeIdleConnections方法,如下所示。3.4 使用httpclient执行method时降低开销。
这里要注意的是,不要关闭connection。
一种可行的获取内容的方式类似于,把entity里的东西复制一份:
res = EntityUtils.toString(response.getEntity(),"UTF-8");
EntityUtils.consume(response1.getEntity());
但是,更推荐的方式是定义一个ResponseHandler,方便你我他,不再自己catch异常和关闭流。在此我们可以看一下相关的源码:
public <T> T execute(final HttpHost target, final HttpRequest request,final ResponseHandler<? extends T> responseHandler, final HttpContext context)throws IOException, ClientProtocolException {Args.notNull(responseHandler, "Response handler");final HttpResponse response = execute(target, request, context);final T result;try {result = responseHandler.handleResponse(response);} catch (final Exception t) {final HttpEntity entity = response.getEntity();try {EntityUtils.consume(entity);} catch (final Exception t2) {// Log this exception. The original exception is more// important and will be thrown to the caller.this.log.warn("Error consuming content after an exception.", t2);}if (t instanceof RuntimeException) {throw (RuntimeException) t;}if (t instanceof IOException) {throw (IOException) t;}throw new UndeclaredThrowableException(t);}// Handling the response was successful. Ensure that the content has// been fully consumed.final HttpEntity entity = response.getEntity();EntityUtils.consume(entity);//看这里看这里return result;}
可以看到,如果我们使用resultHandler执行execute方法,会最终自动调用consume方法,而这个consume方法如下所示:
public static void consume(final HttpEntity entity) throws IOException {if (entity == null) {return;}if (entity.isStreaming()) {final InputStream instream = entity.getContent();if (instream != null) {instream.close();}}}
可以看到最终它关闭了输入流。
4. 其他
通过以上步骤,基本就完成了一个支持高并发的httpclient的写法,下面是一些额外的配置和提醒:
4.1 httpclient的一些超时配置
CONNECTION_TIMEOUT是连接超时时间,SO_TIMEOUT是socket超时时间,这两者是不同的。连接超时时间是发起请求前的等待时间;socket超时时间是等待数据的超时时间。
HttpParams params = new BasicHttpParams();
//设置连接超时时间
Integer CONNECTION_TIMEOUT = 2 * 1000; //设置请求超时2秒钟 根据业务调整
Integer SO_TIMEOUT = 2 * 1000; //设置等待数据超时时间2秒钟 根据业务调整//定义了当从ClientConnectionManager中检索ManagedClientConnection实例时使用的毫秒级的超时时间
//这个参数期望得到一个java.lang.Long类型的值。如果这个参数没有被设置,默认等于CONNECTION_TIMEOUT,因此一定要设置。
Long CONN_MANAGER_TIMEOUT = 500L; //在httpclient4.2.3中我记得它被改成了一个对象导致直接用long会报错,后来又改回来了params.setIntParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, CONNECTION_TIMEOUT);
params.setIntParameter(CoreConnectionPNames.SO_TIMEOUT, SO_TIMEOUT);
params.setLongParameter(ClientPNames.CONN_MANAGER_TIMEOUT, CONN_MANAGER_TIMEOUT);
//在提交请求之前 测试连接是否可用
params.setBooleanParameter(CoreConnectionPNames.STALE_CONNECTION_CHECK, true);//另外设置http client的重试次数,默认是3次;当前是禁用掉(如果项目量不到,这个默认即可)
httpClient.setHttpRequestRetryHandler(new DefaultHttpRequestRetryHandler(0, false));4.2 如果配置了nginx的话,nginx也要设置面向两端的keep-alive
现在的业务里,没有nginx的情况反而比较稀少。nginx默认和client端打开长连接而和server端使用短链接。注意client端的keepalive_timeout和keepalive_requests参数,以及upstream端的keepalive参数设置,这三个参数的意义在此也不再赘述。
以上就是我的全部设置。通过这些设置,成功地将原本每次请求250ms的耗时降低到了80左右,效果显著。
JAR包如下:
<!-- httpclient -->
<dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.6</version>
</dependency>
代码如下:
//Basic认证
private static final CredentialsProvider credsProvider = new BasicCredentialsProvider();
//httpClient
private static final CloseableHttpClient httpclient;
//httpGet方法
private static final HttpGet httpget;
//
private static final RequestConfig reqestConfig;
//响应处理器
private static final ResponseHandler<String> responseHandler;
//jackson解析工具
private static final ObjectMapper mapper = new ObjectMapper();
static {System.setProperty("http.maxConnections","50");System.setProperty("http.keepAlive", "true");//设置basic校验credsProvider.setCredentials(new AuthScope(AuthScope.ANY_HOST, AuthScope.ANY_PORT, AuthScope.ANY_REALM),new UsernamePasswordCredentials("", ""));//创建http客户端httpclient = HttpClients.custom().useSystemProperties().setRetryHandler(new DefaultHttpRequestRetryHandler(3,true)).setDefaultCredentialsProvider(credsProvider).build();//初始化httpGethttpget = new HttpGet();//初始化HTTP请求配置reqestConfig = RequestConfig.custom().setContentCompressionEnabled(true).setSocketTimeout(100).setAuthenticationEnabled(true).setConnectionRequestTimeout(100).setConnectTimeout(100).build();httpget.setConfig(reqestConfig);//初始化response解析器responseHandler = new BasicResponseHandler();
}
/** 功能:返回响应*/
public static String getResponse(String url) throws IOException {HttpGet get = new HttpGet(url);String response = httpclient.execute(get,responseHandler);return response;
}/** 功能:发送http请求,并用net.sf.json工具解析*/
public static JSONObject getUrl(String url) throws Exception{try {httpget.setURI(URI.create(url));String response = httpclient.execute(httpget,responseHandler);JSONObject json = JSONObject.fromObject(response);return json;} catch (IOException e) {e.printStackTrace();}return null;
}
/** 功能:发送http请求,并用jackson工具解析*/
public static JsonNode getUrl2(String url){try {httpget.setURI(URI.create(url));String response = httpclient.execute(httpget,responseHandler);JsonNode node = mapper.readTree(response);return node;} catch (IOException e) {e.printStackTrace();}return null;
}
/** 功能:发送http请求,并用fastjson工具解析*/
public static com.alibaba.fastjson.JSONObject getUrl3(String url){try {httpget.setURI(URI.create(url));String response = httpclient.execute(httpget,responseHandler);com.alibaba.fastjson.JSONObject jsonObject = com.alibaba.fastjson.JSONObject.parseObject(response);return jsonObject;} catch (IOException e) {e.printStackTrace();}return null;
}
相关文章:

高并发场景下的httpClient使用优化技巧
1. 背景 我们有个业务,会调用其他部门提供的一个基于http的服务,日调用量在千万级别。使用了httpclient来完成业务。之前因为qps上不去,就看了一下业务代码,并做了一些优化,记录在这里。 先对比前后:优化…...

用php上传图片到阿里云oss
如果你想自动创建目录并将文件上传到新的目录下,你可以使用阿里云 OSS 的 createObject 方法来实现。下面是更新后的示例代码: php <?php require_once __DIR__ . /vendor/autoload.php; // 引入 SDKuse OSS\OssClient; use OSS\Core\OssException;…...

服务器适合哪些使用场景_Maizyun
服务器适合哪些使用场景 在当今的数字化时代,服务器作为互联网基础设施的核心组件,被广泛应用于各种场景。本文将探讨服务器适合哪些使用场景。 一、Web服务器 Web服务器是服务器中最常见的一种,用于托管和运行网站。它负责处理来自客户端…...

发布“最强”AI大模型,股价大涨,吊打GPT4的谷歌股票值得投资吗?
来源:猛兽财经 作者:猛兽财经 谷歌在AI领域的最新进展,引发投资者关注 在谷歌-C(GOOGL)谷歌-A(GOOG)昨日发布了最新的AI大模型Gemini后,其股价就出现了大幅上涨,更是引发了投资者的密切关注&a…...
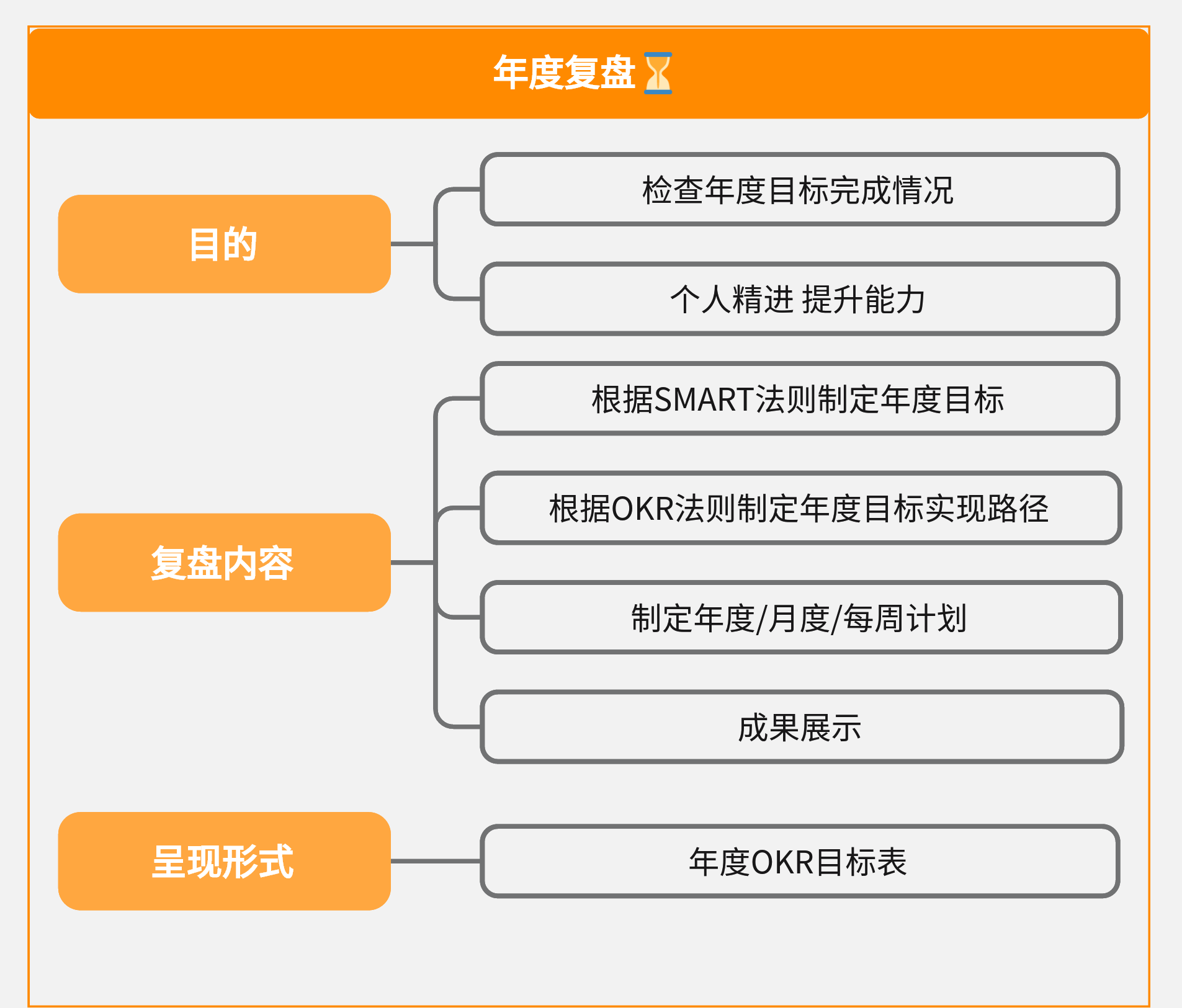
年度工作总结怎么写?掌握这些年终总结万能公式,让你的报告出彩无比!
光阴似箭,日月如梭,时间总是不疾不徐地向前奔去,转眼就来到了2023年的最后一个月,12月一到,上班族和打工人又要开始忙活工作总结的事情~ 工作总结,不仅是一年工作的回顾,更是未来规划的起点。你…...

常用Nmap脚本
端口扫描类脚本 Nmap是一款非常流行的端口扫描工具,它可以帮助渗透测试工程师识别目标网络上开放的端口,并提供有关这些端口的详细信息。Nmap还提供了一系列基于脚本的功能,这些脚本可以扩展Nmap的功能,使其能够更深入地探测目标网…...

在pom.xml中添加maven依赖,但是类里面import导入的时候报错
问题: Error:(27, 8) java: 类TestKuDo是公共的, 应在名为 TestKuDo.java 的文件中声明 Error:(7, 23) java: 程序包org.apache.kudu不存在 Error:(8, 23) java: 程序包org.apache.kudu不存在 Error:(9, 23) java: 程序包org.apache.kudu不存在 Error:(10, 30) jav…...

【NEON】学习资料汇总
一、资料链接 Guide : http://www.heenes.de/ro/material/arm/DEN0018A_neon_programmers_guide_en.pdf csdn博文1,基础案例: https://blog.csdn.net/kakasxin/article/details/103912832? csdn博文2,内部函数: ht…...

java中ReentrantLock的实现原理是什么?
ReentrantLock 的实现原理主要涉及到两个关键概念:同步器(Sync)和 AQS(AbstractQueuedSynchronizer,抽象队列同步器)。 ReentrantLock 使用 AQS 来实现可重入锁的机制。AQS 是 Java 并发包中的一个抽象基类…...

C语言精选——选择题Day40
第一题 1. int a[10] {2,3,5}, 请问a[3]及a[3]之后的数值是() A:不确定的数据 B:5 C:0 D:0xf f f f f f f f 答案及解析 C 数组的不完全初始化,会自动把没初始化的部分初始化为0; 第…...
)
大屏适配方案一scale()
背景 在做大屏可视化项目的时候,一般设计稿会设计成1920 * 1080,但是页面写死1920 * 1080在2k、4k等分辨率的屏幕下是不适配的。 方案一:css3的缩放属性transform以及scale() 在做项目之前我们需要搞清楚客户的数据可视化平台需要在什么屏幕…...

WordPress免费插件大全清单【2023最新】
WordPress已经成为全球范围内最受欢迎的网站建设平台之一。要让您的WordPress网站更具功能性、效率性,并提供卓越的用户体验,插件的选择与使用变得至关重要。 WordPress插件的作用 我们先理解一下插件在WordPress生态系统中的作用。插件是一种能够为Wo…...

支付宝小程序接口传参会默认排序
一:问题 描述:最近项目中的接口都加了签名,在同步到支付宝小程序上时,发现有些接口报错,经过排查,导致报错的原因是因为传参顺序被支付宝小程序默认排序了,比如: 设置的原始参数&a…...

Numpy数组的运算(第7讲)
Numpy数组的运算(第7讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ…...
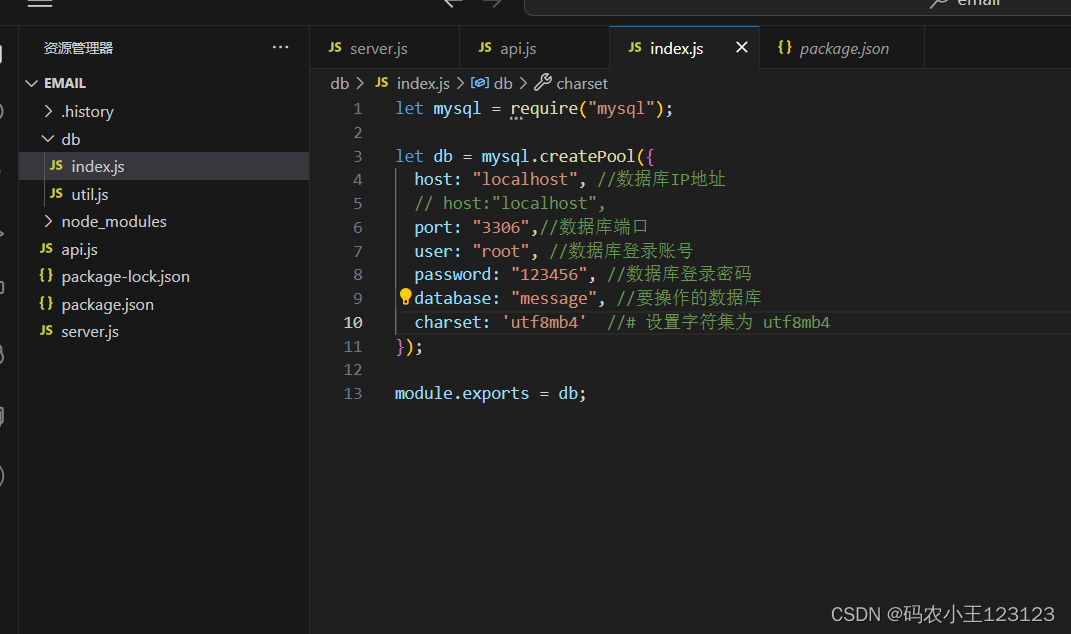
node后端接口无法插入数据为emoji的表情的问题
原因 emoji的表情一般是这样的\xF0\x9F\x98\x80或者是\xF0\x9F\x98 ,事实上 一般数据库的utf8的编码类型都是能保存\xF0\x9F\x98 但是不能保存\xF0\x9F\x98\x80这种样的emoji,要将数据库编码格式为utf8mb4 也就是utf8的超集 另外,除了 数据库…...

Conda常用命令总结
使用conda或anaconda的小伙伴们都知道,图形界面时不靠谱的,而在命令行下,所有的操作就会稳定很多,且极少出现问题。因此,熟记conda的命令行就变得十分有用。但对于我这样近50岁依旧奋斗在代码第一线的大龄程序员而已&a…...
)
Oracle数据库如何实现自增-序列Sequence介绍(适合小白)
Oracle数据库中的Sequence是一种特殊的数据库对象,可以生成一组等间隔的数值,常用于为表中的行自动生成序列号。也常用于主键自增的情况。 下面我将以小白的视角带大家介绍下Oracle数据库序列Sequence: 一、创建简单序列 创建简单序列语法…...

ke14--10章-2JDBC例子
驱动forName,创建连接对象getConnection要三个参数,执行String sql "INSERT INTO等",创建执行SQL语句的PreparedStatement对象进行setString,然后执行preStmt.executeUpdate(); 为什么要preStmt conn.prepareStatement(sql);conn DriverManager.getConnection(url…...
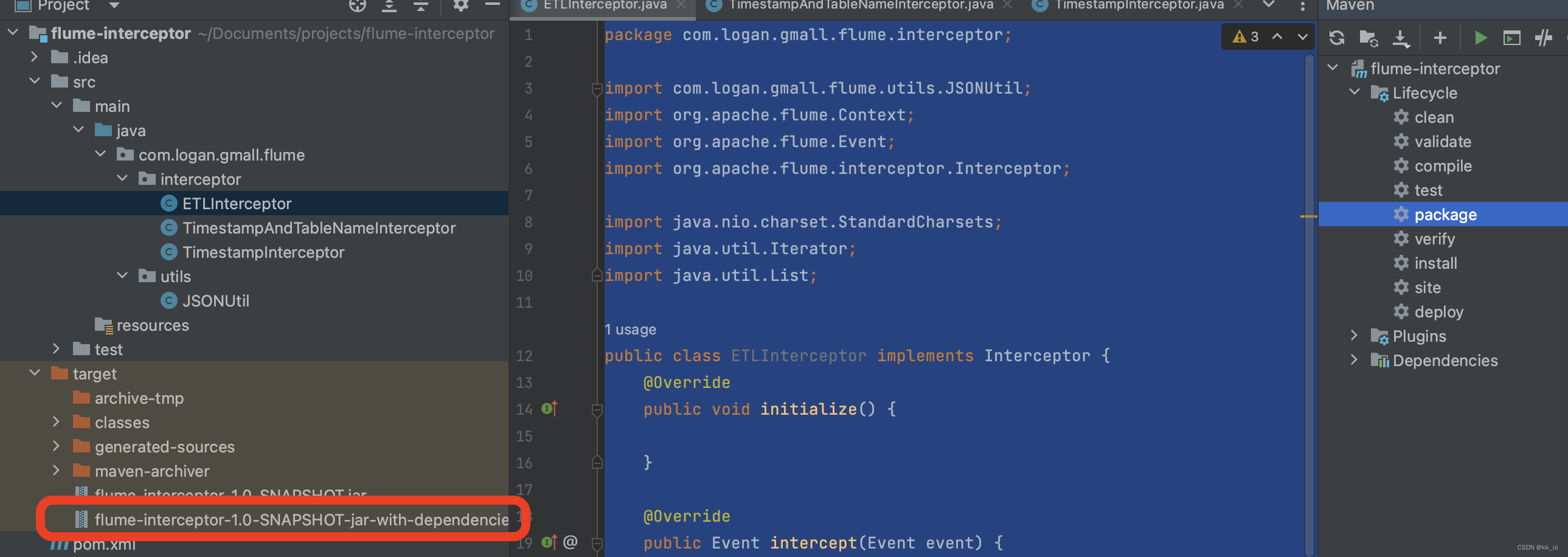
04数据平台Flume
Flume 功能 Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。 Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。 Flume 架构 Flume组成架构如下图所示: A…...
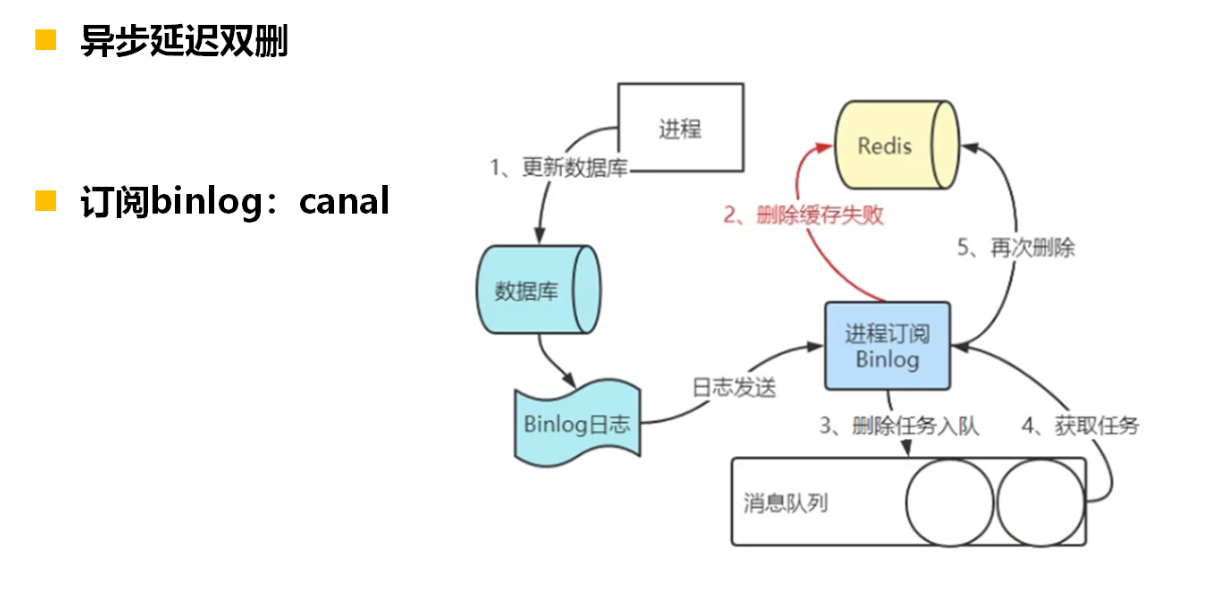
Redis--13--缓存一致性问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 缓存一致性问题1、先更新缓存,再更新DB方案二:先更新DB,再更新缓存方案三:先删缓存,再写数据库推荐1&…...

开源ChatGPT API代理部署指南:低成本调用AI模型实战
1. 项目概述:一个开源ChatGPT API代理的诞生最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何稳定、低成本地调用类似ChatGPT这样的强大语言模型。官方API虽然稳定,但价格和网络限制让很多个人开发者和初创团队望而却步…...

基于eNSP的园区网络高可用与安全隔离综合实验
1. 实验背景与核心价值 园区网络作为企业数字化转型的基础设施,其稳定性和安全性直接关系到日常运营效率。记得去年参与某金融机构网络改造项目时,他们的核心业务系统因为单点故障导致全网瘫痪4小时,直接损失超过百万。这个案例让我深刻认识到…...

Cursor Free VIP:如何轻松突破AI编程助手限制的完整指南
Cursor Free VIP:如何轻松突破AI编程助手限制的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

独立开发者利用Taotoken Token Plan套餐实现个人项目的长期成本规划
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用Taotoken Token Plan套餐实现个人项目的长期成本规划 对于独立开发者或小型工作室而言,运营多个集成大语…...

如何快速优化EVE Online舰船配置:免费专业工具指南
如何快速优化EVE Online舰船配置:免费专业工具指南 【免费下载链接】Pyfa Python fitting assistant, cross-platform fitting tool for EVE Online 项目地址: https://gitcode.com/gh_mirrors/py/Pyfa Pyfa(Python Fitting Assistant)…...
)
Mac磁盘工具里找不到APFS格式?别急,可能是你的U盘分区表选错了(GUID分区图详解)
Mac磁盘工具里找不到APFS格式?可能是分区表惹的祸 当你准备将外置存储设备格式化为APFS时,却发现磁盘工具里压根没有这个选项——这种场景对Mac用户来说并不陌生。上周帮同事迁移数据时就遇到了这个典型问题:一块全新的SSD移动硬盘插入MacBoo…...

AutoHotkey V2扩展库:从脚本小子到全能开发者的进化之路
AutoHotkey V2扩展库:从脚本小子到全能开发者的进化之路 【免费下载链接】ahk2_lib 项目地址: https://gitcode.com/gh_mirrors/ah/ahk2_lib 你是否曾因AutoHotkey的功能局限而感到束手束脚?🤔 当简单的热键脚本无法满足复杂的业务需…...
到应用就绪)
深入解析Spring Boot启动流程:从SpringApplication.run()到应用就绪
1. 项目概述:为什么我们需要深入理解SpringApplication.run()如果你是一个Java开发者,尤其是使用Spring Boot框架的,那么SpringApplication.run(YourApplication.class, args)这行代码对你来说一定不陌生。它几乎是每个Spring Boot应用的启动…...

3步解锁BitLocker加密盘:Linux/macOS跨平台数据恢复实战指南
3步解锁BitLocker加密盘:Linux/macOS跨平台数据恢复实战指南 【免费下载链接】dislocker FUSE driver to read/write Windows BitLocker-ed volumes under Linux / Mac OSX 项目地址: https://gitcode.com/gh_mirrors/di/dislocker 核心关键词:Bi…...

开源项目质量门禁实践:从代码规范到安全扫描的自动化检查
1. 项目概述:一个开源项目的“守门人”最近在整理自己的开源项目时,我一直在思考一个问题:如何确保项目仓库的“健康度”?这里的健康度,不仅仅是指代码没有Bug,更是指整个项目的协作流程、代码质量、依赖安…...