数据库对象介绍与实践:视图、函数、存储过程、触发器和物化视图
文章目录
- 一、视图(View)
- 1、概念
- 2、基本操作
- 1)创建视图
- 2)修改视图
- 3)删除视图
- 4)使用视图
- 3、使用场景
- 4、实践
- 二、函数(Function)
- 1、概念
- 2、基本操作
- 1)创建函数
- 2)使用函数
- 3、使用场景
- 4、实践
- 三、存储过程(Stored Procedure)
- 1、概念
- 2、基本操作
- 1)创建存储过程
- 2)使用存储过程
- 3、使用场景
- 4、实践
- 四、触发器(Trigger)
- 1、概念
- 2、基本操作
- 1) 创建触发器
- 2) 使用触发器
- 3、使用场景
- 4、实践
- 五、物化视图(Materialized View)
- 1、概念
- 2、使用场景
- 3、实践
- 六、总结
一、视图(View)
1、概念
视图是数据库中的一个虚拟表,它是基于一个或多个表的查询结果构建的。视图可以被视为存储在数据库中的预定义查询。通过创建视图,您可以简化复杂的查询,隐藏底层表的细节,并提供更简洁和易于理解的数据访问方式。视图可以像表一样使用,可以查询、插入、更新和删除视图中的数据,但实际上它们并不存储任何数据。
2、基本操作
1)创建视图
语法如下:
CREATE[OR REPLACE][ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}][DEFINER = user][SQL SECURITY { DEFINER | INVOKER }]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]
参数说明:
- CREATE: 这是创建视图的关键字。
- OR REPLACE: 这是一个可选的选项,表示如果已经存在同名的视图,则替换它。
- ALGORITHM: 这也是一个可选的选项,用于指定用于视图的算法。它可以取UNDEFINED、MERGE或TEMPTABLE这三种值。UNDEFINED表示由数据库选择算法,这是默认值。MERGE表示将使用与普通查询相同的算法。TEMPTABLE表示将创建一个临时表,并将查询结果存储在该临时表中。
- DEFINER: 这是可选的选项,用于指定定义视图的用户。通常,这个值应该是创建视图的用户的用户名。
- SQL SECURITY: 这也是可选的选项,用于指定视图的安全性选项。它可以是DEFINER或INVOKER,表示视图的定义者和调用者的安全级别。
- VIEW: 这是创建视图的关键词。view_name: 这是要创建的视图的名称。column_list: 可选的参数,用于指定视图的列名。如果省略,则视图的列名将与查询语句的输出列名相同。
- AS select_statement: 这是指定视图内容的语句。视图的内容是通过一个或多个SELECT语句定义的。
- WITH [CASCADED | LOCAL] CHECK OPTION: 可选的选项,用于指定对视图进行插入、更新和删除操作的约束。如果选择CASCADED,则将对视图的所有后续查询都强制执行该约束。如果选择LOCAL,则只对直接查询该视图的用户强制执行该约束。如果省略,则默认为CASCADED。
2)修改视图
语法如下:
ALTER[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}][DEFINER = user][SQL SECURITY { DEFINER | INVOKER }]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]
参数和创建视图差不多,只不过创建是关键字CREATE,修改是ALTER
3)删除视图
语法如下:
DROP VIEW [IF EXISTS]view_name [, view_name] ...[RESTRICT | CASCADE]
参数说明:
- DROP VIEW: 这是删除视图的关键字。
- IF EXISTS: 这是一个可选的参数,用于指定在尝试删除视图之前是否检查视图是否存在。如果存在,则执行删除操作,否则忽略该操作。
- view_name: 这是要删除的视图的名称。您可以指定一个或多个视图名称,用逗号分隔。
- RESTRICT: 这是一个可选的参数,用于指定如果存在依赖于该视图的任何对象(例如其他视图或存储过程),则不允许删除该视图。如果未指定该参数,并且存在依赖于该视图的对象,则删除操作将被禁止。
- CASCADE: 这是一个可选的参数,用于指定删除视图以及所有依赖于该视图的对象。如果未指定该参数,并且存在依赖于该视图的对象,则删除操作将被禁止。
例子:DROP VIEW IF EXISTS view1, view2 CASCADE;
这个示例将尝试删除名为view1和view2的两个视图。如果这两个视图存在,则它们将被删除,并且所有依赖于它们的对象也将被删除(因为指定了CASCADE参数)。如果这两个视图不存在,则该命令将被忽略(因为指定了IF EXISTS参数)。
4)使用视图
使用视图时,可以像使用表一样进行查询操作,例如:SELECT * FROM my_view;
3、使用场景
-
简化复杂查询:视图可以封装复杂的查询逻辑,简化应用程序中的查询操作,提高查询的可读性和复用性。
-
数据安全性和权限控制:通过视图可以隐藏底层表的结构和数据,只向用户暴露必要的信息,从而提高数据安全性和权限控制。
-
简化应用程序逻辑:视图可以在数据库层面实现一些通用的逻辑,简化应用程序中的代码,提高代码复用性。
-
数据报表和分析:视图可以用于创建数据报表和分析视图,方便用户进行数据分析和报表生成。
-
数据结构的抽象:视图可以将多个表的数据结构抽象为一个虚拟的表,简化数据访问和操作。
总的来说,MySQL视图适合于需要简化复杂查询、提高数据安全性、简化应用程序逻辑和进行数据报表分析的场景。
4、实践
这里我们将下面这个复杂查询写到视图里面

首先创建视图
CREATE VIEW vw_forlan_student AS SELECTA.`name`,A.age,B.class_name
FROMforlan_student A INNER JOIN forlan_class B ON A.class_id = B.id;
然后,直接查询即可,可以看到效果,和前面的复杂查询得到了一模一样的内容
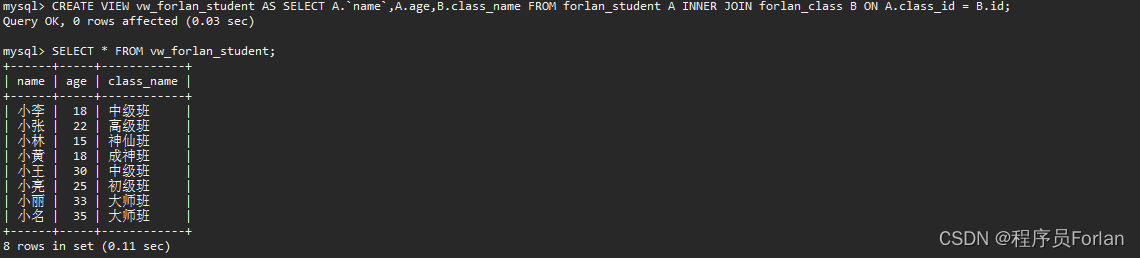
那么,我们直接查和通过视图查,有啥区别,我们先来看看执行计划,发现没啥不同?
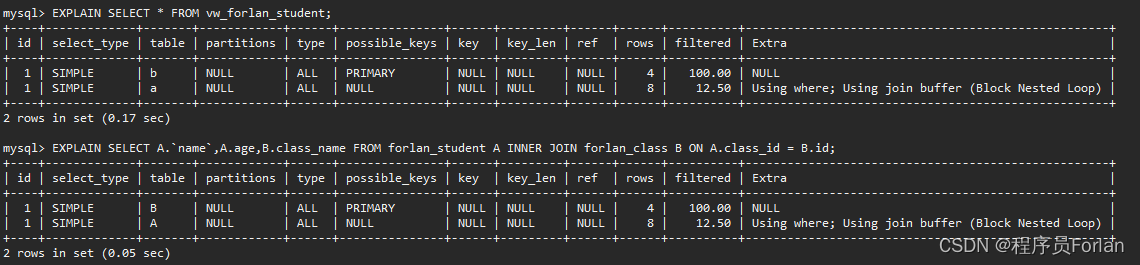
但总的来说,官方是给出了以下区别:
- 可读性:将复杂SQL定义在视图中可以提高查询语句的可读性。通过将复杂的逻辑封装在视图中,可以使查询语句更简洁、易于理解和维护。
- 重用性:定义视图后,可以在多个查询中重复使用该视图,而不需要重复编写复杂的SQL语句。这样可以提高代码的重用性和减少代码冗余。
- 安全性:通过将复杂SQL定义在视图中,可以限制用户对底层数据的直接访问。只有授予对视图的访问权限的用户才能查询视图中的数据,而无法直接访问底层表。
- 性能:在某些情况下,将复杂SQL定义在视图中可能会提高查询性能。视图可以使用索引和其他优化技术来加速查询,而直接查询复杂SQL可能需要更多的计算资源和时间。
需要注意的是,将复杂SQL定义在视图中也可能带来一些额外的开销,例如视图的创建和维护成本。因此,在选择使用哪种方式时,需要综合考虑查询的复杂性、可读性、重用性和性能等因素。
二、函数(Function)
1、概念
函数是一段可重复使用的代码,用于执行特定的操作或计算,并返回结果。函数可以接受参数,并根据这些参数执行一系列的操作,最后返回一个结果。
MySQL提供了许多内置函数,用于执行各种操作,例如数学计算、字符串处理、日期和时间操作等。除了内置函数,MySQL还支持自定义函数,以满足特定的需求。
以下是一些常见的MySQL内置函数的示例:
数学函数:例如SUM、AVG、MAX、MIN等用于执行数值计算的函数。
字符串函数:例如CONCAT、SUBSTRING、LENGTH等用于处理字符串的函数。
日期和时间函数:例如NOW、DATE_FORMAT、DATE_ADD等用于处理日期和时间的函数。
2、基本操作
1)创建函数
CREATE FUNCTION function_name ([parameter1 data_type [, parameter2 data_type, ...]])RETURNS return_data_type[DETERMINISTIC][COMMENT 'string']BEGIN-- 函数体,包含具体的操作和逻辑-- 使用RETURN语句返回结果END;
参数说明:
- CREATE FUNCTION:指示创建一个函数。
- function_name:自定义函数的名称。
- parameter1, parameter2, …:函数的参数列表,每个参数由参数名称和数据类型组成。
- return_data_type:函数的返回值数据类型。可以选择函数返回一个字符串(STRING)、整数(INTEGER)、实数(REAL)或十进制数(DECIMAL)。
- DETERMINISTIC:可选项,指示函数是否是确定性的(即,对于给定的输入,是否总是返回相同的结果)。
- COMMENT ‘string’:可选项,用于为函数添加注释。
- BEGIN和END:用于定义函数体的开始和结束。
拓展- 加载函数
CREATE [AGGREGATE] FUNCTION function_nameRETURNS {STRING|INTEGER|REAL|DECIMAL}SONAME shared_library_name
参数说明:
- CREATE FUNCTION是用于定义一个新函数的语句。当你在这里使用AGGREGATE FUNCTION时,你正在创建一个聚合函数,它会对一组值执行特定的操作。
- SONAME shared_library_name: 这是指定函数所在的共享库的部分。shared_library_name是你要引用的共享库的名称。共享库是一种存储预先编译的函数代码的方式,这样在调用函数时可以更快地执行。
2)使用函数
函数可以在SQL查询中使用,也可以在存储过程和触发器中使用。一般在SELECT语句中使用函数来计算和转换数据,或者在WHERE子句中使用函数来过滤数据。
例如:SELECT function_name(arguments) FROM table_name;
3、使用场景
-
数据处理和计算:函数可以用于执行特定的数据处理、计算和转换,例如日期处理、字符串操作、数学运算等。
-
查询优化:通过函数可以封装复杂的查询逻辑,提高查询的可读性和复用性,同时也有助于优化查询性能。
-
业务规则和验证:函数可以用于实现特定的业务规则和验证逻辑,例如数据有效性检查、权限控制等。
-
简化应用程序逻辑:函数可以在数据库层面实现一些通用的逻辑,简化应用程序中的代码,提高代码复用性。
-
自定义聚合函数:通过自定义聚合函数,可以实现特定的数据聚合逻辑,满足特定的业务需求。
总的来说,MySQL函数适合于需要在数据库层面执行特定的数据处理、计算和验证逻辑,以及优化查询性能、简化应用程序逻辑的场景。
4、实践
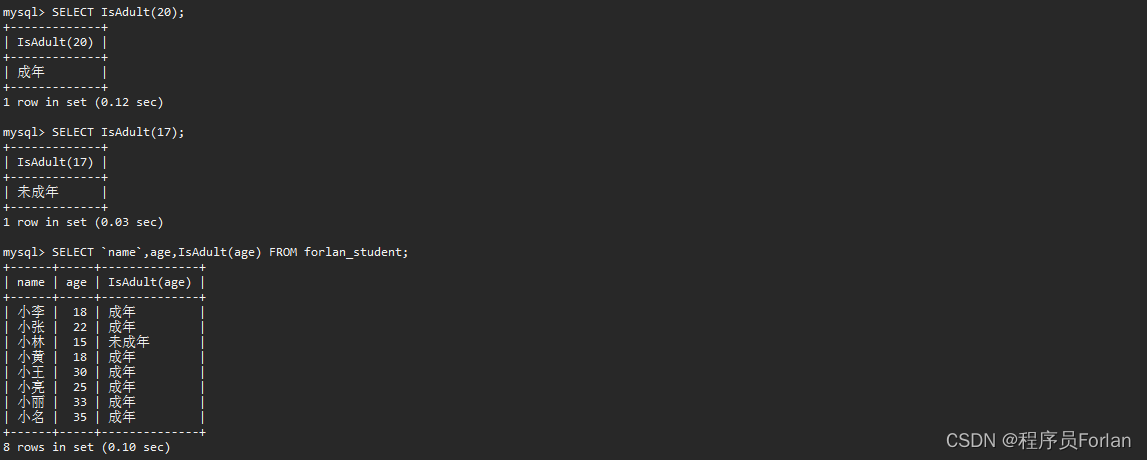
创建一个函数,判断年龄是否成年,代码如下:
CREATE FUNCTION IsAdult(age INT)
RETURNS VARCHAR(10)
BEGINDECLARE result VARCHAR(10);IF age >= 18 THENSET result = '成年';ELSESET result = '未成年';END IF;RETURN result;
END;
测试效果如下:
三、存储过程(Stored Procedure)
1、概念
存储过程是一组预定义的SQL语句集合,可以在数据库中进行重复使用。存储过程类似于函数,但不返回结果。它可以接受参数,并且可以包含条件逻辑、循环、异常处理等。
存储过程由以下组成:
- 存储过程名称:用于唯一标识存储过程的名称。
- 参数列表:可选项,用于传递给存储过程的输入参数。
- 存储过程体:包含一系列SQL语句和控制结构,用于实现特定的功能。
- 存储过程结束标记:表示存储过程的结束。
2、基本操作
1)创建存储过程
CREATE PROCEDURE procedure_name[ (IN parameter1 datatype1 [, OUT|INOUT parameter2 datatype2 [, ...]] ) ]
BEGIN-- 存储过程的逻辑代码
END;
参数说明:
- CREATE PROCEDURE:指示创建一个存储过程。
- procedure_name:存储过程的名称。
- parameter1, parameter2, …:存储过程的参数列表,每个参数由参数名称和数据类型组成。
- IN参数:用于将值传递给存储过程。在存储过程内部,IN参数的值是只读的,不能在存储过程中修改。
- OUT参数:用于从存储过程中返回值。在存储过程内部,OUT参数的值可以被修改,并在存储过程执行完毕后返回给调用者。
- INOUT参数:既可以传递值给存储过程,也可以从存储过程中返回值。在存储过程内部,INOUT参数的值可以被修改,并在存储过程执行完毕后返回给调用者。
- BEGIN和END:用于定义存储过程体的开始和结束。
2)使用存储过程
使用CALL语句来调用存储过程。在调用存储过程时,您可以传递参数值,根据需要指定参数的模式(IN、OUT或INOUT)。
3、使用场景
-
数据处理和业务逻辑:存储过程可以封装复杂的数据处理逻辑,例如数据清洗、转换、计算等,以及实现特定的业务规则和流程。
-
数据安全性和权限控制:通过存储过程,可以对数据库操作进行封装和控制,限制用户对数据的访问和操作,提高数据安全性。
-
提高性能:存储过程可以减少网络通信开销,提高数据库操作的性能,尤其是在需要频繁执行相同逻辑的情况下。
-
代码复用和维护:存储过程可以被多个应用程序共享和调用,提高代码的复用性,同时也方便对逻辑进行统一管理和维护。
-
批量操作和事务管理:存储过程可以实现批量数据操作,同时也可以管理事务,确保一系列操作的原子性和一致性。
总的来说,存储过程适合于需要在数据库层面实现复杂逻辑、提高性能、增强安全性和方便维护的场景。
4、实践
使用存储过程插入新班级新学生数据
1)创建一个存储过程,用于插入班级信息并返回班级ID
CREATE PROCEDURE insert_class(IN class_name VARCHAR(255), OUT class_id INT)
BEGININSERT INTO forlan_class (class_name) VALUES (class_name);SET class_id = LAST_INSERT_ID();
END;
2)创建另一个存储过程,用于插入学生信息并使用上一步中返回的班级ID:
CREATE PROCEDURE insert_student(IN name VARCHAR(255), IN age INT, IN class_id INT)
BEGININSERT INTO forlan_student (name, age, class_id) VALUES (name, age, class_id);
END;
3)调用存储过程
CALL insert_class('存储过程学习班', @class_id);
CALL insert_student('forlan', 20, @class_id);
4)通过查看视图验证,可以查到我们刚刚插入的,如下:

四、触发器(Trigger)
1、概念
触发器是一种数据库对象,它在指定的表上自动执行特定的操作。当满足特定的事件(如插入、更新或删除数据)时,触发器会触发并执行预定义的操作。这些操作可以是SQL语句、存储过程或其他自定义逻辑。触发器通常用于实现数据完整性约束、审计跟踪和自动化业务逻辑等功能
2、基本操作
1) 创建触发器
CREATE[DEFINER = user]TRIGGER trigger_name{ BEFORE | AFTER } { INSERT | UPDATE | DELETE }ON tbl_name FOR EACH ROW[{ FOLLOWS | PRECEDES } other_trigger_name]trigger_body
参数说明:
- DEFINER = user: 这部分指定了触发器的定义者
- TRIGGER trigger_name:指定触发器的名称,用于标识触发器对象。
- BEFORE或AFTER:指定触发器在事件之前或之后执行。BEFORE表示在事件执行之前触发,AFTER表示在事件执行之后触发。
- INSERT、UPDATE或DELETE:指定触发器要响应的事件类型。INSERT表示在插入数据之前或之后触发,UPDATE表示在更新数据之前或之后触发,DELETE表示在删除数据之前或之后触发。
- ON table_name:指定触发器所属的表名,即触发器要监视的表。
- trigger_order:指定触发器的执行顺序。
- FOR EACH ROW:表示触发器将为每一行数据执行操作。这意味着触发器的操作逻辑将在每次插入、更新或删除数据时执行。
- { FOLLOWS | PRECEDES } other_trigger_name 表示该触发器与其他触发器之间的执行顺序关系
2) 使用触发器
一旦创建触发器,它将自动与指定的表关联。当触发器所监视的事件发生时,触发器的操作逻辑将被执行。
3、使用场景
-
数据完整性和约束:触发器可以用于实现数据完整性和约束,例如在插入、更新、删除数据时进行验证和限制。
-
数据审计和日志记录:触发器可以用于记录数据变更的日志,包括谁在什么时间做了什么操作。
-
数据复制和同步:触发器可以用于在数据变更时触发数据复制和同步操作,确保数据的一致性。
-
自动化任务和业务逻辑:触发器可以用于执行特定的业务逻辑和自动化任务,例如在特定条件下触发某些操作。
-
数据转换和处理:触发器可以用于在数据变更时进行特定的数据转换和处理,例如数据格式转换、计算字段值等。
总的来说,MySQL触发器适合于需要在特定的数据变更时执行特定的逻辑、记录数据变更日志、实现数据复制和同步、以及执行特定的自动化任务和业务逻辑的场景。
4、实践
我们写一个触发器,来实现当班级信息发生变化时,触发更新学生信息
1)创建触发器
CREATE TRIGGER update_forlan_student
AFTER UPDATE ON forlan_class
FOR EACH ROW
BEGIN-- 更新学生表中对应班级的信息UPDATE forlan_studentSET class_name = NEW.class_nameWHERE class_id = NEW.id;
END;
注:NEW关键字表示触发器所监视的事件中的新数据
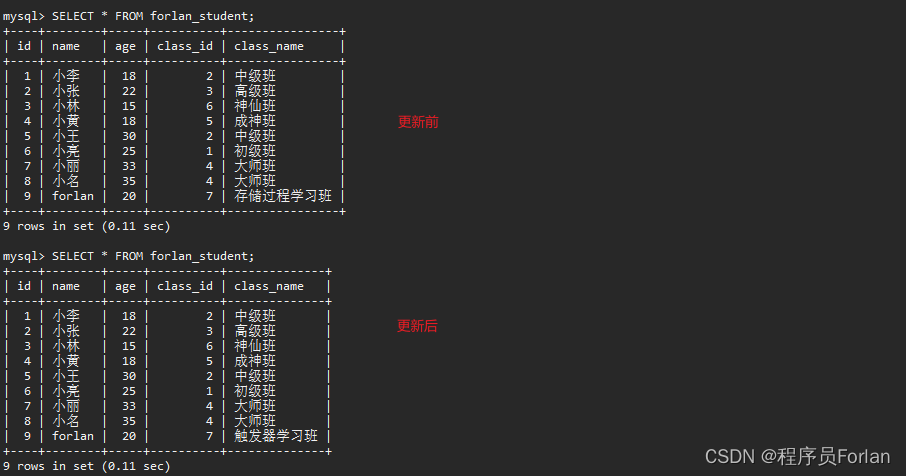
2)修改班级信息
UPDATE `forlan_class` SET `class_name` = '触发器学习班' WHERE `id` = 7
3)查看触发器监情况,效果如下:
五、物化视图(Materialized View)
1、概念
在MySQL中,物化视图(Materialized View)是一种预先计算和存储的查询结果集。与普通视图不同,物化视图在创建时会将查询结果保存在磁盘上,而不是在每次查询时动态计算。这样可以显著提高查询性能,并减少对原始表的查询次数。
总的来说,通常用于存储预先计算的结果,以提高查询性能。然而,MySQL本身并不直接支持物化视图,但可以通过函数、存储过程、触发器、视图来实现类型的功能
2、使用场景
- 复杂查询优化:当数据库中存在复杂的查询,需要多个表的联接和聚合操作时,可以使用物化视图来预先计算并存储查询结果,以提高查询性能。
- 数据汇总和报表生成:物化视图可以用于汇总和聚合大量数据,以生成报表和分析结果。通过预先计算和存储汇总数据,可以加快报表生成的速度。
- 数据仓库和决策支持系统:在数据仓库和决策支持系统中,物化视图可以用于存储预先计算的指标和维度数据,以支持复杂的分析和决策过程。
- 实时数据更新:物化视图可以定期或实时地更新,以保持与源数据的同步。这对于需要实时或近实时数据的应用程序非常有用。
需要注意的是,物化视图的创建和维护可能会增加数据库的存储空间和更新成本。因此,在选择使用物化视图时,需要权衡查询性能的提升和资源消耗之间的平衡。
3、实践
学生表如下:
CREATE TABLE `forlan_student` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`name` varchar(200) DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年龄',`class_id` bigint(20) DEFAULT NULL COMMENT '所属班级',`class_name` varchar(255) DEFAULT NULL COMMENT '所属班级名称',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='学生信息表';
假设我们需要在页面查看是否成年,这时候会有多种实现方案,我们来分析下:
- 方案一:代码里面写if…else…判断,但这样每次查询都要计算一遍
- 方案二:在学生表新增一个字段,但这不符合数据库第三范式了,因为是否成年”可以由“年龄”推出,具体数据库范式可以去看数据库基础概念与范式反范式总结
- 方案三:新增一张表,但是需要改代码,增删改,都要重新计算去维护多一张表信息,挺麻烦的,这里就可以通过物化视图来弄,自动触发维护即可
1)创建学生年龄表
CREATE TABLE `materialized_student_adult_status` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`student_id` bigint(20) DEFAULT NULL COMMENT '学生id',`is_adult` varchar(255) DEFAULT NULL COMMENT '是否成年',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='学生年龄表';
2)创建一个存储过程,用于更新物化视图的数据:
CREATE PROCEDURE update_student_adult_status()
BEGINDELETE FROM materialized_student_adult_status;INSERT INTO materialized_student_adult_status (student_id, is_adult)SELECT id, isAdult(age) FROM forlan_student;
END;
注:isAdult是我们前面自定义的函数
3)创建一个触发器,当学生表中的年龄字段发生变化时,自动触发更新物化视图的存储过程:
CREATE TRIGGER student_age_update_trigger
AFTER UPDATE ON forlan_student
FOR EACH ROW
BEGINIF NEW.age <> OLD.age THENCALL update_student_adult_status();END IF;
END;
4)创建一个普通视图,用于展示我们需要的信息
CREATE VIEW vw_student_adult_status AS
SELECT A.*,B.is_adult
FROM forlan_student A JOIN materialized_student_adult_status B ON A.id = B.student_id;
5)查看效果,是否返回了学生表的信息,还返回了对应的是否成年字段,而且我们修改了年龄后,自动维护了is_adult字段
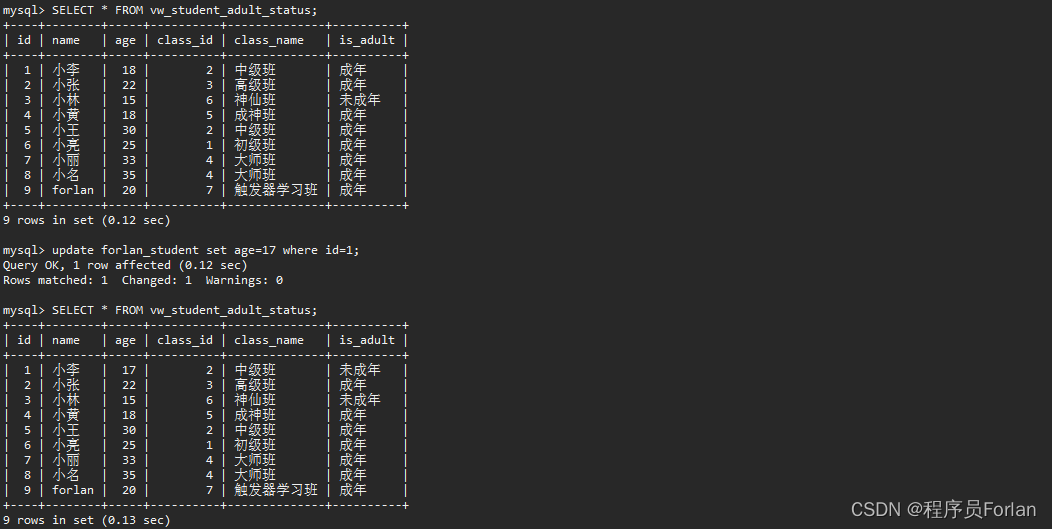
六、总结
从上面的理论与实现相结合,我们大概知道了视图、函数、存储过程、触发器和物化视图是干嘛的,总结如下:
- 视图:一般用于预定义一些复杂查询操作,隐藏底表实现细节,本身不存储实际数据;
- 函数:把重复代码抽取为一个公共方法,方便SQL语句、视图、存储过程、触发器等调用;
- 存储过程:一般用于实现复杂业务逻辑和数据处理,需要显示使用CALL语句调用;
- 触发器:类似于监听器,监听表的某些行为,触发相应的动作;
- 物化视图:类似于视图,只不过它本身存储数据,会把计算结果落库,而不是每次查询动态计算;
相关文章:
数据库对象介绍与实践:视图、函数、存储过程、触发器和物化视图
文章目录 一、视图(View)1、概念2、基本操作1)创建视图2)修改视图3)删除视图4)使用视图 3、使用场景4、实践 二、函数(Function)1、概念2、基本操作1)创建函数2ÿ…...

arm平台编译so文件回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、几个点二、回顾过程 1.上来就执行Makefile2.编译第三方开源库.a文件 2.1 build.sh脚本2.2 Makefile3.最终编译三、其它知识点总结 前言 提示:这…...
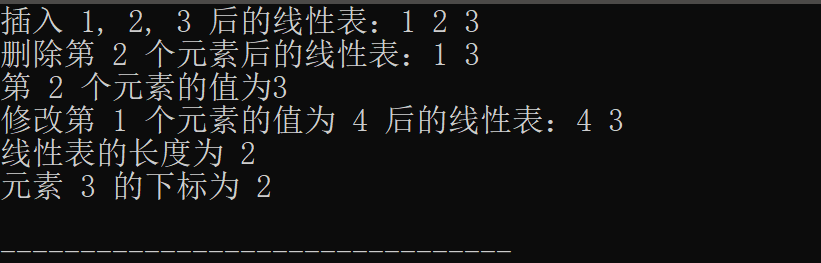
【数据结构】顺序表的定义和运算
目录 1.初始化 2.插入 3.删除 4.查找 5.修改 6.长度 7.遍历 8.完整代码 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 &…...
idea使用maven的package打包时提示“找不到符号”或“找不到包”
介绍:由于我们的项目是多模块开发项目,在打包时有些模块内容更新导致其他模块在引用该模块时不能正确引入。 情况一:找不到符号 情况一:找不到包 错误代码部分展示: Failure to find com.xxx.xxxx:xxx:pom:0.5 in …...

MetricBeat监控MySQL
目录 一、安装部署 二、开启mysql监控模块 三、编辑mysql配置文件 四、启动Metricbeat 五、查看监控图表 一、安装部署 metriceat的安装部署参考章节: Metricbeat安装使用,这里不再赘述。 二、开启mysql监控模块 进入metricbeat安装目录 ./metricb…...
Child Mind Institute - Detect Sleep States(2023年第一次Kaggle拿到了银牌总结)
感谢 感谢艾兄(大佬带队)、rich师弟(师弟通过这次比赛机械转码成功、耐心学习)、张同学(也很有耐心的在学习),感谢开源方案(开源就是银牌),在此基础上一个月…...

Esxi7Esxi8设置VMFSL虚拟闪存的大小
Esxi7Esxi8设置VMFSL虚拟闪存的大小 ESXi7,8 默认安装会分配一个 VMFSL(VMFS-L)(Local VMFS)很大空间(120G), 感觉很浪费, 实际给 8G 就可以了, 最少 6G , 经实验,给2G没法安装 . Esxi7是虚拟闪存的 修改的方法是: 在安装时修改 设置 autoPartitionOSDataSize8192 在cdromBoo…...
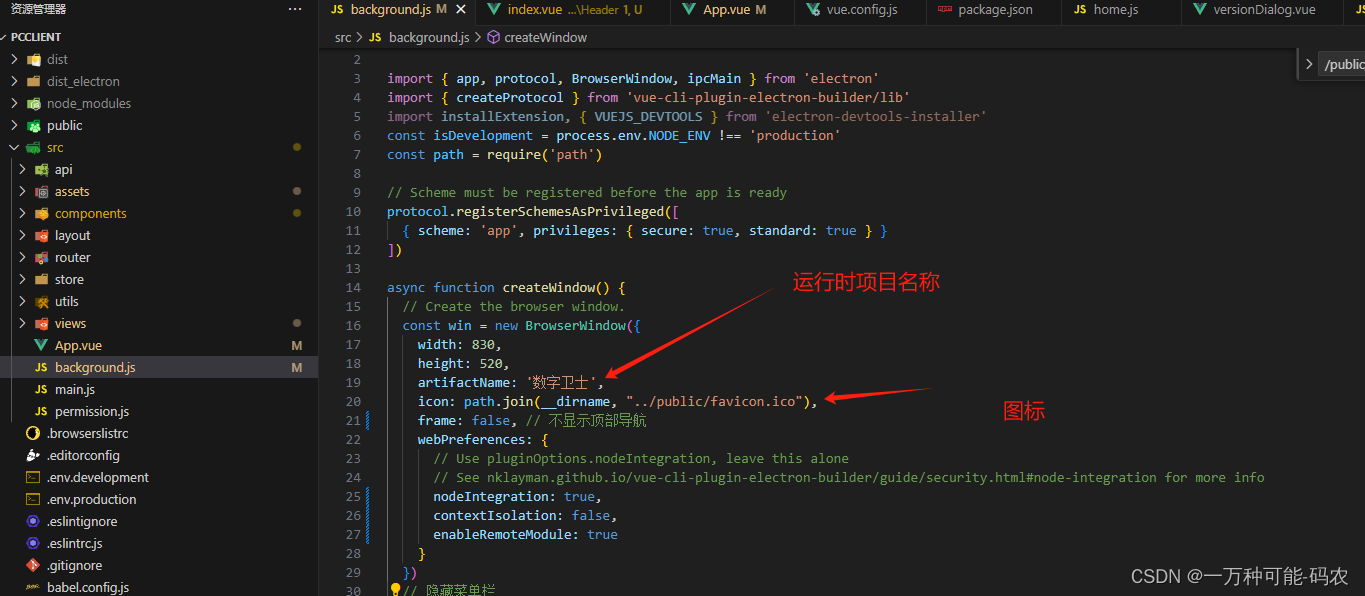
vue2+electron桌面端一体机应用
vue2+electron项目 前言:公司有一个项目需要用Vue转成exe,首先我使用vue-cli脚手架搭建vue2项目,然后安装electron 安装electron 这一步骤可以省略,安装electron-builder时会自动安装electron npm i electron 安装electron-builder vue add electron-builder 项目中多出…...

目标检测——OverFeat算法解读
论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun 链接:https://arxiv.org/abs/1312.6229 文章…...

vue获取主机id和IP地址
获取主机id和IP地址 在vue.config.js const os require(“os”); function getNetworkIp() { let needHost “”; // 打开的host try { // 获得网络接口列表 let network os.networkInterfaces(); for (let dev in network) { let iface network[dev]; for (let i 0; i …...
在pytorch中自定义dataset读取数据
这篇是我对哔哩哔哩up主 霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享 有关我们数据读取预训练 以及如何将它打包成一个一个batch输入我们的网络的 首先我们来看一下之前我们在讲resnet网络时所使用的源码 我们去使用了官方实现的image folder去读取我们的图像数据 然…...

ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
1.关于稀疏卷积的解释:https://zhuanlan.zhihu.com/p/382365889 2. 答案: 在深度学习领域,尤其是计算机视觉任务中,遮蔽图像建模(Masked Image Modeling, MIM)是一种自监督学习策略,其基本思想…...

Java后端的登录、注册接口是怎么实现的
目录 Java后端的登录、注册接口是怎么实现的 Java后端的登录接口是怎么实现的 Java后端的注册接口怎么实现? 如何防止SQL注入攻击? Java后端的登录、注册接口是怎么实现的 Java后端的登录接口是怎么实现的 Java后端的登录接口的实现方式有很多种&a…...

TCP Keepalive 和 HTTP Keep-Aliv
HTTP的Keep-Alive 在http1.0的版本中,它是基于请求-应答模型和TCP协议的,也就是在建立TCP连接后,客户端发送一次请求并且接收到响应后,就会立马断开TCP连接,称为HTTP短连接,这种方式比较耗费时间以及浪费资…...

操作系统 复习笔记
操作系统的目标和作用 操作系统的目标 1.方便性 2.有效性 3.可扩展性 4.开放性 操作系统的作用 1.OS作为用户与计算机硬件系统之间的接口 2.OS作为计算机系统资源的管理者 3.OS实现了对计算机系统资源的抽象 推动操作系统发展的主要动力 1.不断提高计算机系统资源的…...

Java中实现单例模式的方式
1. 使用静态内部类实现单例模式 在Java中,使用静态内部类实现单例模式是一种常见而又有效的方式。这种方式被称为“静态内部类单例模式”或者“Holder模式”。这种实现方式有以下优点: 懒加载(Lazy Initialization):静…...
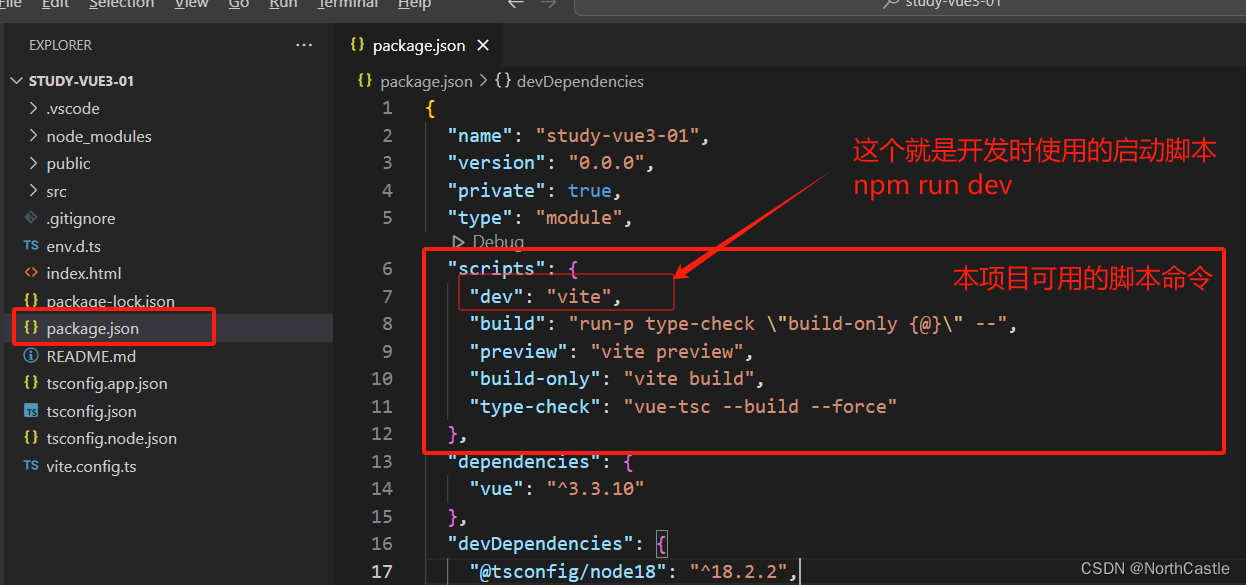
Vue3-01-创建项目
环境准备 1.需要用到 16.0 以及更高版本的 node.js 2.使用vscode编辑器进行项目开发可以在命令行中查看node的版本号: node -v创建项目 1.准备一个目录 例如,我创建项目的时候是在该目录下进行的;D:\projectsTest\vue3project2.执行创建命令(*&#x…...
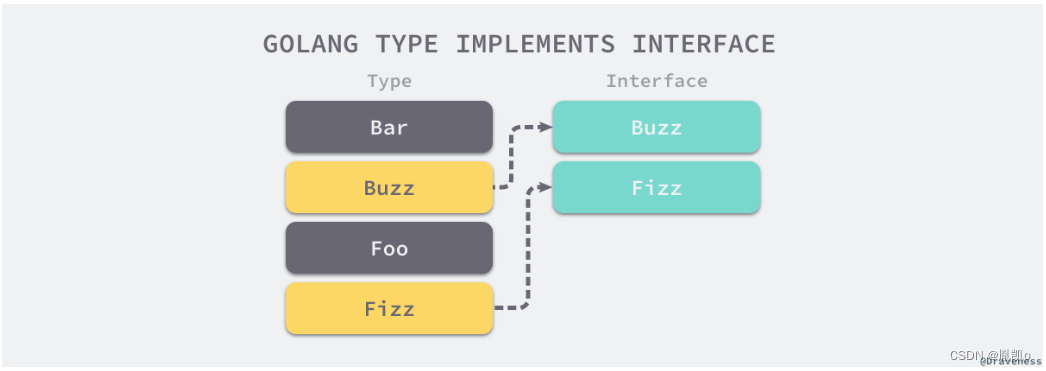
Go 语言中的反射机制
欢迎大家到我的博客浏览,更好的阅读体验请点击 反射 | YinKais Blog 反射在大多数的应用和服务中并不常见,但是很多框架都依赖 Go 语言的反射机制简化代码。<!--more-->因为 Go 语言的语法元素很少、设计简单,所以它没有特别强的表达能…...

[leetcode 前缀和]
525. 连续数组 M :::details 给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。 示例 1: 输入: nums [0,1] 输出: 2 说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。示例 2: 输入: nums [0,1,0] 输出: …...
Python与ArcGIS系列(十五)根据距离抓取字段
目录 0 简述1 实例需求2 arcpy开发脚本0 简述 在处理gis数据的时候,会遇到这种需求:将一个图层与另一个图层中相近的要素进行字段赋值。本篇将介绍如何利用arcpy及arcgis的工具箱实现这个功能。 1 实例需求 为了介绍这个功能的实现,我们需要有一个特定的功能需求。在这里选…...

基于CircuitPython与Adafruit CLUE的创意灵感生成器开发指南
1. 项目概述:用硬件激发创意的火花你有没有过这样的时刻——面对空白的画布、闪烁的光标,或者一堆零散的电子元件,脑子里却一片空白,急需一个点子来点燃创作的引擎?这种“创意阻塞”几乎是每个创作者都会遇到的难题。传…...

小红书二面:Function Calling 的可靠性怎么保证?
1. 题目分析 Function Calling 大概是 LLM 应用开发中最拧巴的一个环节——你让一个概率模型去做一件需要百分之百精确的事。模型生成的自然语言可以有措辞差异、可以有风格变化,用户多半不会在意,但一个工具调用的参数少了一个字段、日期格式从 YYYY-M…...

终极指南:fmt库如何用SFINAE和Concepts构建现代C++类型特征系统
终极指南:fmt库如何用SFINAE和Concepts构建现代C类型特征系统 【免费下载链接】fmt A modern formatting library 项目地址: https://gitcode.com/GitHub_Trending/fm/fmt fmt库作为现代C格式化库的典范,巧妙融合了SFINAE(Substitutio…...

架构设计经验分享:从方法论到落地的完整实践
写在前面 “架构"是技术圈里被滥用最严重的词之一。很多人一说架构就开始画框图、讲中间件、列技术栈,但问一句"你这个架构解决了什么问题”,答不上来。 我做架构这些年,最深的体会是:架构不是技术选型的堆砌࿰…...

nRF52840开发板移植CircuitPython实战:从编译到蓝牙应用
1. 项目概述与核心价值 如果你手头有一块基于 Nordic nRF52840 芯片的开发板,比如官方的 nRF52840-DK 或者 Particle 的 Argon/Xenon,并且厌倦了在 C 语言和复杂的 SDK 中挣扎,想用 Python 的简洁语法快速实现一个蓝牙传感器节点或者物联网设…...

Linux SSH身份验证全解析:从密码到证书的六种方法与实践指南
1. SSH身份验证:守护远程访问的第一道门在Linux世界里,SSH(Secure Shell)就是那把打开远程服务器大门的钥匙。无论是管理云服务器、部署应用,还是进行日常运维,我们几乎每天都在和它打交道。但很多人可能没…...

项目烂尾的魔咒:为什么你的物联网系统总是“上线即落后”?
在物联网行业有一个令人沮丧的“3-6-12”现象:3个月调研,6个月开发,12个月后项目烂尾或重构。 为什么投入巨资打造的智慧园区或工业互联系统,往往在验收通过的那一刻,就已经开始走向僵化?问题往往不出在硬…...

终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头
终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 想要将手机摄像头变成OBS直播的高清视频源吗?DroidCam …...
—— 调度策略与栈管理的实战权衡)
基于ETAS RTA-OS的Autosar OS详解(二)—— 调度策略与栈管理的实战权衡
1. 调度策略的实战选择与性能影响 在嵌入式系统开发中,任务调度策略的选择直接影响系统实时性和稳定性。ETAS RTA-OS作为Autosar标准操作系统,提供了三种经典调度策略,每种策略都有其独特的适用场景和性能特征。 1.1 打断式调度的优势与陷阱…...

从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板
从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板 当你第一次点亮TMS320F28335开发板上的LED时,那种成就感无与伦比。但很快你会发现,随着项目复杂度提升,代码开始变得混乱不堪——头文件散落各处、函数命名随意、每次…...