学习pytorch18 pytorch完整的模型训练流程
pytorch完整的模型训练流程
- 1. 流程
- 1. 整理训练数据 使用CIFAR10数据集
- 2. 搭建网络结构
- 3. 构建损失函数
- 4. 使用优化器
- 5. 训练模型
- 6. 测试数据 计算模型预测正确率
- 7. 保存模型
- 2. 代码
- 1. model.py
- 2. train.py
- 3. 结果
- tensorboard结果
- 以下图片 颜色较浅的线是真实计算的值,颜色较深的线是做了平滑处理的值
- 训练loss
- 测试loss
- 测试集正确率
- 4. 需要注意的细节
1. 流程
1. 整理训练数据 使用CIFAR10数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
2. 搭建网络结构

model.py
3. 构建损失函数
loss_fn = nn.CrossEntropyLoss()
4. 使用优化器
learing_rate = 1e-2 # 0.01
optimizer = torch.optim.SGD(net.parameters(), lr=learing_rate)
5. 训练模型
output = net(imgs) # 数据输入模型
loss = loss_fn(output, targets) # 损失函数计算损失 看计算的输出和真实的标签误差是多少
# 优化器开始优化模型 1.梯度清零 2.反向传播 3.参数优化
optimizer.zero_grad() # 利用优化器把梯度清零 全部设置为0
loss.backward() # 设置计算的损失值的钩子,调用损失的反向传播,计算每个参数结点的参数
optimizer.step() # 调用优化器的step()方法 对其中的参数进行优化
6. 测试数据 计算模型预测正确率
output = net(imags)
# 计算测试集的正确率
preds = (output.argmax(1)==targets).sum()
accuracy += preds
rate = accuracy/len(test_data)
调用模型输出tensor 数据类型的 argmax方法, argmax或获取一行或者一列数值中最大数值的下标位置,argmax(0) 是从列的维度取一列数值的最大值的下标,argmax(1) 是从行的维度取一行数值的最大值的下标
output.argmax(1)==targets 会输出如下图最后一行 [false, ture], 对应位置相同则为true,对应位置不同则为false;
调用sum()方法,计算求和,false值为0,true值为1.
最后计算得出测试集整体正确率: rate = accuracy/len(test_data)

7. 保存模型
torch.save(net, './net_epoch{}.pth'.format(i))
2. 代码
1. model.py
import torch
from torch import nn# 2. 搭建模型网络结构--神经网络
class Cifar10Net(nn.Module):def __init__(self):super(Cifar10Net, self).__init__()self.net = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.net(x)return xif __name__ == '__main__':net = Cifar10Net()input = torch.ones((64, 3, 32, 32))output = net(input)print(output.shape)
2. train.py
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriterfrom p24_model import *# 1. 准备数据集
# 训练数据
from torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
# 测试数据
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)# 查看数据大小--size
print("训练数据集大小:", len(train_data))
print("测试数据集大小:", len(test_data))
# 利用DataLoader来加载数据集
train_loader = DataLoader(dataset=train_data, batch_size=64)
test_loader = DataLoader(dataset=test_data, batch_size=64)# 2. 导入模型结构 创建模型
net = Cifar10Net()# 3. 创建损失函数 分类问题--交叉熵
loss_fn = nn.CrossEntropyLoss()# 4. 创建优化器
# learing_rate = 0.01
# 1e-2 = 1 * 10^(-2) = 0.01
learing_rate = 1e-2
print(learing_rate)
optimizer = torch.optim.SGD(net.parameters(), lr=learing_rate)# 设置训练网络的一些参数
epoch = 10 # 记录训练的轮数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数# 利用tensorboard显示训练loss趋势
writer = SummaryWriter('./train_logs')for i in range(epoch):# 训练步骤开始net.train() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用for data in train_loader:imgs, targets = data # 获取数据output = net(imgs) # 数据输入模型loss = loss_fn(output, targets) # 损失函数计算损失 看计算的输出和真实的标签误差是多少# 优化器开始优化模型 1.梯度清零 2.反向传播 3.参数优化optimizer.zero_grad() # 利用优化器把梯度清零 全部设置为0loss.backward() # 设置计算的损失值,调用损失的反向传播,计算每个参数结点的参数optimizer.step() # 调用优化器的step()方法 对其中的参数进行优化# 优化一次 认为训练了一次total_train_step += 1if total_train_step % 100 == 0:print('训练次数: {} loss: {}'.format(total_train_step, loss))# 直接打印loss是tensor数据类型,打印loss.item()是打印的int或float真实数值, 真实数值方便做数据可视化【损失可视化】# print('训练次数: {} loss: {}'.format(total_train_step, loss.item()))writer.add_scalar('train-loss', loss.item(), global_step=total_train_step)# 利用现有模型做模型测试# 测试步骤开始total_test_loss = 0accuracy = 0net.eval() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用with torch.no_grad():for data in test_loader:imags, targets = dataoutput = net(imags)loss = loss_fn(output, targets)total_test_loss += loss.item()# 计算测试集的正确率preds = (output.argmax(1)==targets).sum()accuracy += preds# writer.add_scalar('test-loss', total_test_loss, global_step=i+1)writer.add_scalar('test-loss', total_test_loss, global_step=total_test_step)writer.add_scalar('test-accracy', accuracy/len(test_data), total_test_step)total_test_step += 1print("---------test loss: {}--------------".format(total_test_loss))print("---------test accuracy: {}--------------".format(accuracy))# 保存每一个epoch训练得到的模型torch.save(net, './net_epoch{}.pth'.format(i))writer.close()
3. 结果
训练数据集大小: 50000
测试数据集大小: 10000
0.01
训练次数: 100 loss: 2.2905373573303223
训练次数: 200 loss: 2.2878968715667725
训练次数: 300 loss: 2.258394718170166
训练次数: 400 loss: 2.1968581676483154
训练次数: 500 loss: 2.0476632118225098
训练次数: 600 loss: 2.002145767211914
训练次数: 700 loss: 2.016021728515625
---------test loss: 316.382279753685--------------
训练次数: 800 loss: 1.8957302570343018
训练次数: 900 loss: 1.8659226894378662
训练次数: 1000 loss: 1.9004186391830444
训练次数: 1100 loss: 1.9708642959594727
......
tensorboard结果
安装tensorboard运行环境
pip install tensorboard
pip install opencv-python
pip install six
tensorboard --logdir=train_logs
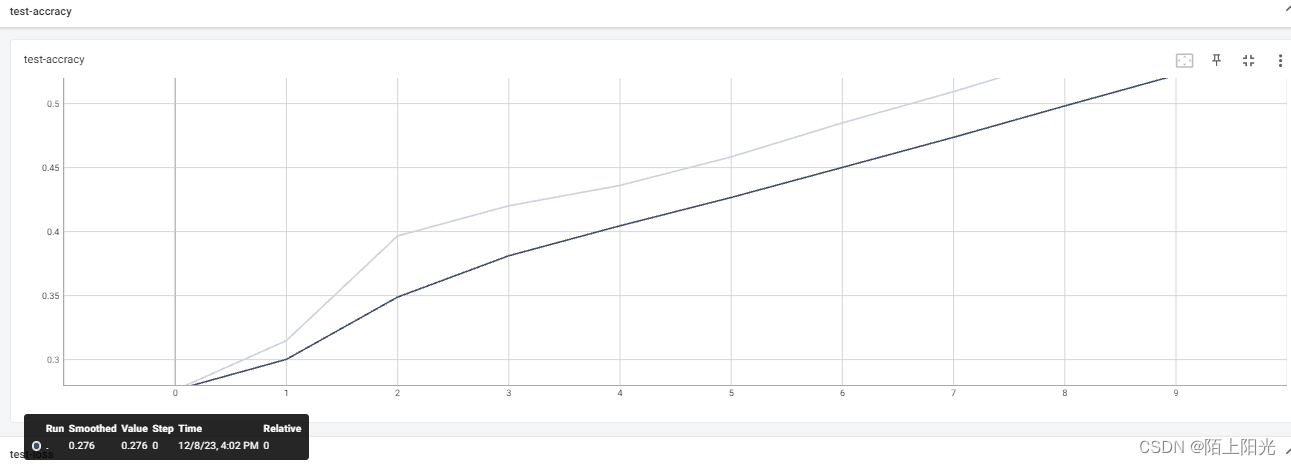
以下图片 颜色较浅的线是真实计算的值,颜色较深的线是做了平滑处理的值
训练loss

测试loss

测试集正确率
4. 需要注意的细节
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
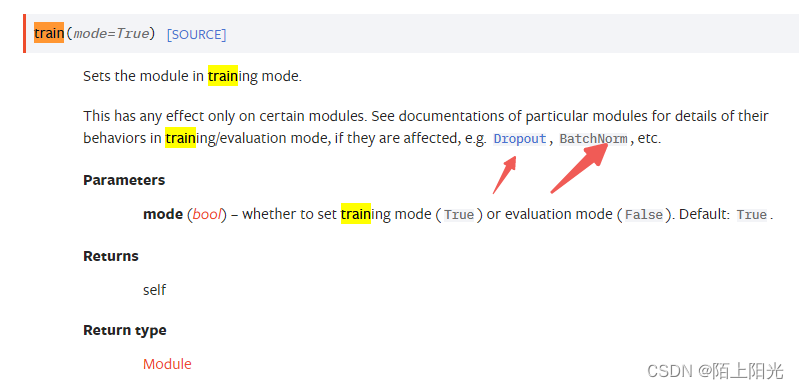
所有网络层继承于torch.nn.Module, net.train() net.eval() 在模型训练或测试之初 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用,当模型有这两个网络层的时候,两个代码需要加上。

相关文章:
学习pytorch18 pytorch完整的模型训练流程
pytorch完整的模型训练流程 1. 流程1. 整理训练数据 使用CIFAR10数据集2. 搭建网络结构3. 构建损失函数4. 使用优化器5. 训练模型6. 测试数据 计算模型预测正确率7. 保存模型 2. 代码1. model.py2. train.py 3. 结果tensorboard结果以下图片 颜色较浅的线是真实计算的值&#x…...

电子学会C/C++编程等级考试2021年09月(五级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:抓牛 农夫知道一头牛的位置,想要抓住它。农夫和牛都位于数轴上,农夫起始位于点N(0<=N<=100000),牛位于点K(0<=K<=100000)。农夫有两种移动方式: 1、从X移动到X-1或X+1,每次移动花费一分钟 2、从X移动到2*X,每…...
Halcon联合winform显示以及处理
在窗口中添加窗体和按钮,并在解决方案资源管理器中调加了导入Halcon导出的.cs文件,运行出现下图的问题: 问题1:CS0017 程序定义了多个入口点。使用/main(指定包含入口点的类型)进行编译。 解决方案1.: 右…...
【设计模式-4.3】行为型——责任链模式
说明:本文介绍设计模式中行为型设计模式中的,责任链模式; 审批流程 责任链模式属于行为型设计模式,关注于对象的行为。责任链模式非常典型的案例,就是审批流程的实现。如一个报销单的审批流程,根据报销单…...
单片机语言--C51语言的数据类型以及存储类型以及一些基本运算
C51语言 本文主要涉及C51语言的一些基本知识,比如C51语言的数据类型以及存储类型以及一些基本运算。 文章目录 C51语言一、 C51与标准C的比较二、 C51语言中的数据类型与存储类型2.1、C51的扩展数据类型2.2、数据存储类型 三、 C51的基本运算3.1 算术运算符3.2 逻辑…...
《每天一个Linux命令》 -- (5)通过sshkey密钥登录服务器
欢迎阅读《每天一个Linux命令》系列!在本篇文章中,将介绍通过密钥生成,使用公钥连接管理服务器。 概念 SSH 密钥是用于安全地访问远程服务器的一种方法。SSH 密钥由一对密钥组成:公钥和私钥。公钥存储在远程服务器上,…...
)
kubernetes的服务发现(二)
如前面的文章我们说了,kubernetes的服务发现是服务端发现模式。它有一个服务注册中心,使用DNS作为服务的注册表。每个集群都会运行一个DNS服务,默认是CoreDNS服务。每个服务都会在这个DNS中注册。注册的大致过程: 1、向kube-apise…...

【矩阵论】Chapter 4—特征值和特征向量知识点总结复习
文章目录 1 特征值和特征向量2 对角化3 Schur定理和正规矩阵4 Python求解 1 特征值和特征向量 定义 设 σ \sigma σ为数域 F F F上线性空间 V V V上的一个线性变换,一个非零向量 v ∈ V v\in V v∈V,如果存在一个 λ ∈ F \lambda \in F λ∈F使得 σ (…...

Linux 进程地址空间
知识回顾 在 C 语言的学习过程中,我们知道内存是可以被划分为栈区,堆区,全局数据区,字符常量区,代码区的。他的空间排布可能是下面的样子: 其中,全局数据区,可以划分为已初始化全局…...

websocket vue操作
let websocket: WebSocket; /** websocket测试 */ function connectWebsocket() {if (typeof WebSocket "undefined") {console.log("您的浏览器不支持WebSocket");return;}// let ip window.location.hostname ":8080";let ip "10.192…...
腾讯云CentOS8 jenkins war安装jenkins步骤文档
腾讯云CentOS8 jenkins war安装jenkins步骤文档 一、安装jdk 1.1 上传jdk-11.0.20_linux-x64_bin.tar.gz 1.2 解压jdk安装包文件 tar -zxvf jdk*.tar.gz 1.3 在/usr/local 目录下创建java目录 cd /usr/local mkdir java 1.4 切到java目录,把jdk解压文件改名为jd…...

Linux: glibc: net/if.h vs linux/if.h
最近看到一段代码改动,用net/if.h替换了linux/if.h。仔细看了看这两个的区别: https://stackoverflow.com/questions/20082433/what-is-the-difference-between-linux-if-h-and-net-if-h 从网上搜了一下看到如下的一个编译错误,如果同时使用这两个if.h文件,需要将net/if.h…...
使用Android Studio导入Android源码:基于全志H713 AOSP,方便解决编译、编码问题
文章目录 一、 篇头二、 操作步骤2.1 编译AOSP AS工程文件2.2 将AOSP导入Android Studio2.3 切到Project试图2.4 等待index结束2.5 下载缺失的JDK 1.82.6 导入完成 三、 导入AS的好处3.1 本文案例演示源码编译错误AS对比同文件其余地方的调用AS错误提示依赖AS做错误修正 一、 篇…...

python random详解
文章目录 random简单示例1. 生成随机浮点数:2. 生成指定范围内的随机整数:3. 从序列中随机选择元素:4. 打乱序列顺序: 常用的方法及其解释和例子:1. random():该方法返回一个0到1之间的随机浮点数。例如&am…...
java-两个列表进行比较,判断那些是需要新增的、删除的、和更新的
文章目录 前言两个列表进行比较,判断那些是需要新增的、删除的、和更新的 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实…...
【WPF.NET开发】WPF中的对话框
目录 1、消息框 2、通用对话框 3、自定义对话框 实现对话框 4、打开对话框的 UI 元素 4.1 菜单项 4.2 按钮 5、返回结果 5.1 模式对话框 5.2 处理响应 5.3 非模式对话框 Windows Presentation Foundation (WPF) 为你提供了自行设计对话框的方法。 对话框是窗口&…...

NLP项目实战01之电影评论分类
介绍: 欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。 展示: 训练展示如下…...

一款可无限扩展的软件定时器开源框架项目代码
摘自链接 时间片轮询架构如何稳定高效实现,取代传统的标志位判断方式,更优雅更方便地管理程序的时间触发操作。 可以在STM32单片机上运行。...

GRE与顺丰圆通快递盒子
1. DNS污染 随想: 在输入一串网址后,会发生如下变化如果你在系统中配置了 Hosts 文件,那么电脑会先查询 Hosts 文件如果 Hosts 里面没有这个别名,就通过域名服务器查询域名服务器回应了,那么你的电脑就可以根据域名服…...
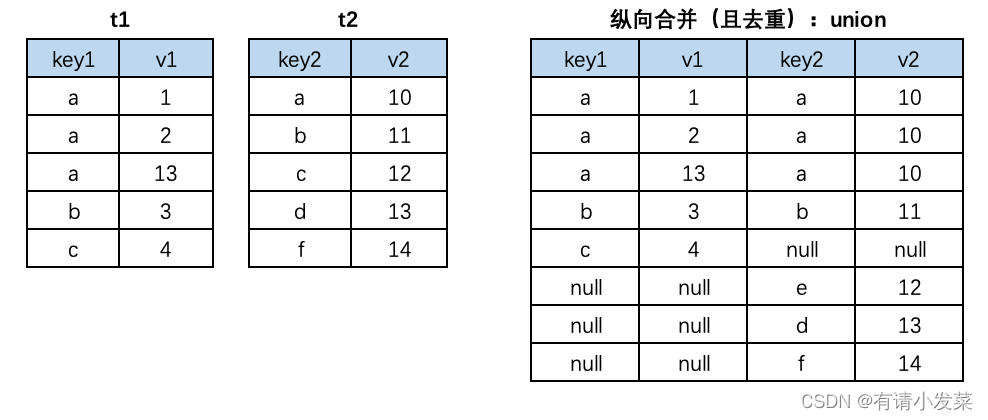
12.Mysql 多表数据横向合并和纵向合并
Mysql 函数参考和扩展:Mysql 常用函数和基础查询、 Mysql 官网 Mysql 语法执行顺序如下,一定要清楚!!!运算符相关,可前往 Mysql 基础语法和执行顺序扩展。 (8) select (9) distinct (11)<columns_name…...

高性能缓冲管理中的数组翻译技术解析
1. 高性能缓冲管理中的数组翻译技术解析在现代数据库系统中,缓冲管理器是连接内存与持久化存储的关键组件,其核心任务是将逻辑页ID映射到物理内存帧。传统方案如哈希表或指针交换存在三个根本性缺陷:内存开销随数据集线性增长、并行访问时的锁…...

0.2mm间距测试探针技术解析与应用指南
1. 0.2mm间距测试探针的技术突破与应用价值在半导体测试领域,随着芯片封装尺寸的持续缩小和信号频率的不断提升,传统测试探针已难以满足高密度互连与高频测试的双重需求。Aries Electronics最新推出的0.2mm间距测试探针,采用镀金铍铜材料和特…...

基于Claude API的视频转录技能开发:从语音识别到AI集成实战
1. 项目概述:一个为Claude设计的视频转录技能最近在折腾AI应用开发,特别是围绕Claude API构建一些实用工具。我发现一个挺有意思的项目,叫Johncli7941/claude-skill-video-transcribe。从名字就能看出来,这是一个为Claude设计的“…...

LZ4与ZSTD压缩算法在LLM内存优化中的硬件实现对比
1. 项目概述:压缩算法在LLM内存优化中的关键作用 在大型语言模型(LLM)推理过程中,内存带宽和容量一直是制约性能的关键瓶颈。特别是随着模型规模的不断扩大,KV缓存(Key-Value Cache)所占用的内存…...

仅限首批200名DevOps工程师解密:DeepSeek内部CI/CD可观测性看板DSL语法与12个预置PromQL故障模式模板
更多请点击: https://intelliparadigm.com 第一章:DeepSeek CI/CD流水线的可观测性演进与战略定位 可观测性已从传统监控的“事后响应”范式,跃迁为DeepSeek CI/CD流水线的核心设计原则与战略支点。它不再仅关注指标(Metrics&…...

RK3568 Debian系统Docker安装与ARM64容器化部署实战指南
1. 项目概述与核心价值最近在折腾一块基于瑞芯微RK3568的开发板,想在上面跑一些服务,自然而然地就想到了Docker。毕竟,Docker带来的环境隔离和便捷部署,对于嵌入式开发和边缘计算场景来说,简直是“神器”。但当我真正动…...

【职场】职场上,从不发脾气的人,最值得警惕
职场上,从不发脾气的人,最值得警惕“真正危险的人,从来不是那个拍桌子的人。而是那个,永远在微笑的人。”一、你身边有没有这种人 开会的时候,无论发生什么,他都面带微笑。 被否定了,点头&#…...

如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持 对于使用 Hermes Agent 构建复杂应用的开发者而言,其强大的自…...

Steam Deck Windows控制器驱动深度配置指南
Steam Deck Windows控制器驱动深度配置指南 【免费下载链接】steam-deck-windows-usermode-driver A windows usermode controller driver for the steam deck internal controller. 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck-windows-usermode-driver 想…...

星链引擎:AI 驱动的全域营销决策自动化系统技术实现
一、引言在当前数字化营销时代,企业面临着前所未有的数据爆炸和决策复杂度。一个典型的全域营销场景中,企业每天需要处理来自多个平台的数百万条用户行为数据,同时还要根据市场变化、竞品动态和用户反馈,实时调整内容策略、发布策…...