Linux 进程地址空间
知识回顾
在 C 语言的学习过程中,我们知道内存是可以被划分为栈区,堆区,全局数据区,字符常量区,代码区的。他的空间排布可能是下面的样子:

其中,全局数据区,可以划分为已初始化全局数据区和未初始化全局数据区!
- 栈区向下增长。(表现形式之一:同一个栈桢中先定义的变量地址更高,后定义的变量地址更低)
- 堆区向上增长。(随着堆区的使用,变量的地址是向上增长的!)
堆栈之间的区域叫做共享区,这个会在动静态库的时候详解!
内核空间:这是操作系统的代码和数据!
我们可以写一个简单的代码来验证一下:
#include<stdio.h>
#include<stdlib.h>int g_val = 10;int main()
{int a = 1;int b = 2;char* str = "hello linux";int* heap1 = (int*)malloc(sizeof(int));printf("栈区先定义的变量: &a: %p\n", &a);printf("栈区后定义的变量: &b: %p\n", &b);printf("堆区定义的变量: &heap1: %p\n", &heap1);printf("全局数据: &g_val_init: %p\n", &g_val);printf("字符常量区: &str: %p\n", str);return 0;
}

这里说明一下:static 修饰的局部变量,只能初始化一次,作用域在局部,但是生命周期和全局变量一样,那是因为在编译的时候就将这个局部变量定义在了全局数据区,你可以通过打印静态变量的地址看出来!
进程地址空间引入
我们学习了进程地址空间之后,就能解决在进程创建的那一节中提出的一个问题:用 id 变量接收 fork 函数的返回值,为什么一个变量能读出来两个不同的值?
我们来看一段代码:定义一个全局变量 g_val = 100,使用 fork 创建子进程,子进程每隔一秒打印 pid ppid g_val g_val,5 秒之后将 g_val 修改为 200;父进程每隔一秒打印 pid g_val &g_val。看看能观察到什么现象:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>int g_val = 100;int main()
{pid_t id = fork();if(id == 0){//这是子进程int cnt = 5;while(1){printf("I am child process, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);sleep(1);if(cnt) cnt--;else{g_val = 200;printf("child process change g_val: 100->200\n");cnt--;}}}else if(id > 0){while(1){printf("I am parent, pid: %d, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);sleep(1);}}else{perror("fork():");}return 0;
}
5 秒中之后子进程修改全局变量 g_val ,子进程修改父子进程的共享数据发生写时拷贝,为子进程的 g_val 重新开辟空间!打印的时候子进程的 g_val 等于 200,父进程的 g_val 等于 100。这没问题!但是我们发现,发生写时拷贝之后,父子进程打印出来的 &g_val 是一样的!

怎么可能同一个变量,同一个地址,同时读取,读到了不同的内容呢?
因此我们得到一个结论:这里打印出来的地址绝对不是物理地址,我们把这个打印出来的地址称为虚拟地址或者线性地址。
我们在写 C/C++ 程序中使用的指针,地址其实都不是物理地址!
什么是进程地址空间
我们先不说什么是进程地址空间,我们先来看子进程创建时父子进程是如何做到共享代码和数据的!
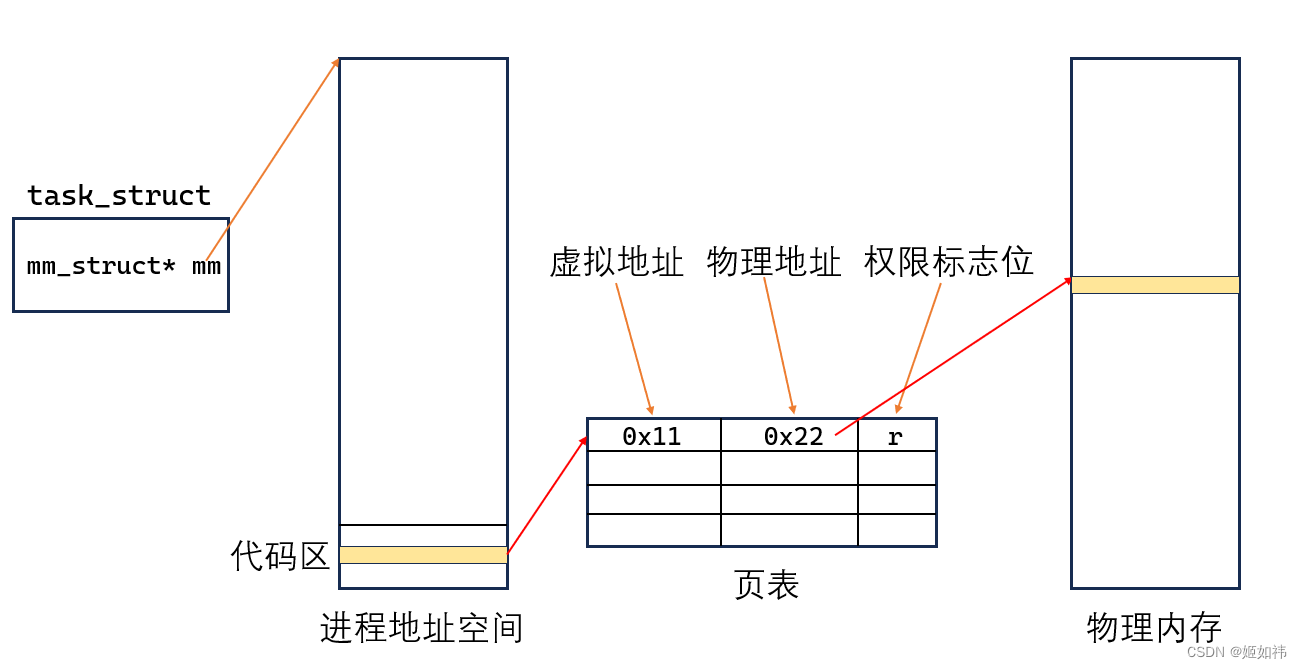
- 首先,父进程有自己的
task_struct在这个结构体中,有一个字段叫做mm_struct*,能通过这个字段找到父进程的虚拟地址(线性地址)。我们定义了一个全局变量g_val就会给这个变量分配一个虚拟地址!在Linux操作系统中有一个叫做页表的东西,你可以把他理解为一个map他存储的是虚拟地址到物理地址的映射关系!也就是说,通过页表,我们能够通过虚拟地址访问物理地址(物理内存)! fork()创建子进程,会为子进程创建task_struct,拷贝父进程的虚拟内存,拷贝虚拟内存的页表!- 拷贝父进程的虚拟内存: 那么,这个全局变量的虚拟地址在父子进程中都是一样的!
- 拷贝父进程的页表:那么,通过相同的虚拟地址,相同的页表,就能做到访问相同的物理内存!
上面的论述证明了父子进程数据是共享的!代码共享的原理是一样的!
我们可以画出示意图:

这个示意图可以帮助大家理解虚拟地址和物理地址,其中页表这么画是不对的,我们后面会详解页表的真实结构!不过页表以这种结构来理解是没有大问题的!
子进程是如何做到 g_val 的写时拷贝的?
父子进程代码和数据是共享的,当我们在子进程中对 g_val 做出修改的时候,操作系统就会为子进程重新开辟 g_val 类型大小的空降,然后将 g_val 拷贝到这块新的空间,并修改 g_val 的值,最后修改 g_val 虚拟地址映射的物理地址!完成写时拷贝!

写时拷贝的本质就是重新开辟空间,但是这个过程中,左侧的虚拟地址是 0 感知的,虚拟地址不关心,也不会被影响!
现在我们就能解决当初遗留的问题啦:为啥 fork 之后的 id 有两个值?
fork()函数在return之前就将子进程创建好了!return的本质也是写入!也就是说会发生写时拷贝!父子进程虽然在访问同一个id,但是根据页表访问的是不同的物理地址(物理内存),这就是一个id变量能够读出两个值的原因!
地址空间
以 32 位的 Linux 操作系统为例,地址空间就是地址排列组合形成的地址范围: [ 0 , 2 32 ) [0, 2^{32}) [0,232)。
在 32 位操作系统中,有 32 位的地址总线和数据总线,CPU 和 内存通过系统总线相连,每一根总线有 0,1 两种状态(高电平,低电平,那么 32 根总线,就有 2 32 2^{32} 232 种组合!通过 CPU 与 内存相连的总线,CPU 能读取内存的数据! 2 32 2^{32} 232 对应 4 G B 4GB 4GB 的内存大小!因此想要映射出来 4 G B 4GB 4GB 的物理内存,就需要同等范围的虚拟内存!
如何理解地址空间的区域划分
这篇文章的开头我们看到的内存区域划分就是地址空间的区域划分!我们又知道了地址空间就是地址排列组形成的地址范围!地址空间的本质是内核的一个数据结构对象,地址空间也是要被操作系统管理起来的!
因此我们就能以一种较为简单的方式对地址空间进行区域划分:

只要维护两个指针用来标识一个区域划分的起始地址和结束地址就是对地址空间做划分啦!
对虚拟地址的空间做出这样的划分之后,我们就能够粗略判断访问变量的时候是否发生越界访问啦!
在地址空间中最小单位就是一个地址,这个地址是可以被直接使用的!
为了检验我们的结论正确性,可以看看 Linux 内核的源代码是不是这个样子:
我们可以看到在 task_struct 中有一个 struct mm_struct,跳转到 mm_struct 内部,我们看到了诸如 start_code end_code 这样的字段,证明我们得出的结论是没有问题的!

为什么要有进程地址空间
让所有的进程以统一的视角看待内存
任何一个进程都有自己的地址空间,地址空间上的虚拟地址通过页表的映射访问物理内存!
这就是任何一个进程访问物理内存的逻辑!在访问内存的方式做到了统一!
如果没有进程地址空间,task_struct 中就得维护进程的代码和数据在内存中的位置,一旦进程的状态发生切换,就会修改 task_struct 中的内容,太过麻烦!
保护物理内存
增加进程地址空间后,我们想要访问物理内存就必须通过页表的转换,在这个转化的过程,我们就可以对寻址进行审查,一旦出现访问异常,操作系统就能及时拦截!使得请求不会到达内存,能够有效地保护物理内存
事实上页表中还维护了一个字段,表示对物理内存的读写权限!
如图,在代码区有一段代码,虚拟地址是 0x11 物理地址是 0x22 通过页表他们之间就存在映射关系!代码区的代码权限标志位都是 r。当我们尝试对代码区做修改时,根据 CPU 中的 cr3 寄存器找到页表,发现我们想要对权限标志位为 r 的物理内存做修改,操作系统会直接拦截!保证了物理内存的安全!
根据上面的现象,我们能够得出结论:
- ==物理内存根本没有权限管理的概念!==不然可执行程序是如何被加载到内存中的?
cr3寄存器为何能够直接访问物理内存,而不做权限的检查? - 凭什么代码是只读的?程序加载到内存中就是对物理内存进行写入!物理内存本身并没有只读一说!因此,是虚拟地址通过页表映射到物理地址上时,页表中权限标志位为
r,即只读!当我们对代码区做修改,操作系统能够根据权限标志位进行拦截!所以才说代码区是只读的!
实现进程管理模块与内存管理模块的解耦
- 虚拟化: 进程地址空间提供了虚拟化的抽象,使得每个进程都以为它拥有整个系统的内存。这使得进程可以独立运行,而无需关心其他进程的内存布局。
- 独立的页表: 每个进程都有自己的页表,负责将其虚拟地址空间映射到物理地址。这样,不同进程可以有不同的页表,实现了内存空间的隔离。页表的管理成为内存管理模块的责任。
- 惰性加载:
Linux操作系统可以采用懒加载的策略,只在需要时将进程的部分地址空间加载到物理内存中。这种分页和惰性加载的方式使得内存管理更加灵活。
进程之间的地址空间是隔离的,一个进程的内存操作不会直接影响其他进程。这有助于提高系统的安全性和稳定性。
换句话说,进程之间可以有完全相同的虚拟地址,但是能根据相同的虚拟地址访问到不同的物理地址!
程序的惰性加载
不知道大家是否有一个疑问:我们完的电脑游戏下载 下来可能就是几十个 GB,但是我们的物理内存就那么一点儿大!这是怎么做到将游戏运行起来的呢?
在学习进程的状态时,我们知道在操作系统学科中有挂起的状态,进程处于挂起状态时,他的代码和数据会被放在磁盘中,只保留 PCB 在物理内存!
可是 Linux 操作系统中并没有挂起状态啊,如何知道当前进程的代码和数据在不在内存中呢?
- 首先,我们需要达成一个共识:现代操作系统,几乎不会做浪费时间和空间的事情!
- 假设我们有一个可执行程序,他的代码和数据有 20 MB,在加载可执行程序的时候,我们加载了
5MB的代码和数据!于是这个进程跑起来了!结果发现在这个进程被调度的过程中,只用到了1MB的代码和数据,可是当初加载可执行程序的时候加载了5MB哇!于是就产生了内存空降的浪费!这是不被允许的!!因为现代操作系统中,几乎不会做浪费时间和空间的事情!
事实上在页表中还有一个字段,用来标识某个虚拟地址的代码和数据是否加载到内存!比如该标志位为 1 代表代码和数据已经加载到内存中啦!
当我们执行代码时,CPU 通过 cr3 寄存器找到页表,发现该虚拟地址并未加载代码,就会引发缺页中断,进程发生缺页中断就会再加载一部分代码和数据,先分配内存空间。然后将物理地址填充到对应的虚拟地址,就可以继续执行代码啦!
正是因为有页表和虚拟内存的存在,进程不需要关系内存的事儿!当发生缺页中断的时候,操作系统就会自动调用内存管理模块的相关功能!也就实现了进程管理与内存管理的解耦!
现在我们就可以回答上面的问题啦!不管你的代码和数据有多少,加载可执行程序的时候我就加载一点点,剩下的代码和数据往页表中填充虚拟地址就行,当我们要访问这些为加载的代码和数据就会引发缺页中断!再次加载一部分代码和数据!这也提高了内存的使用效率!
知识巩固
-
什么是进程呢?学到这里,内核数据结构又多了一部分啦!
进程 = 内核数据结构 ( t a s k s t r u c t m m s t r u c t 页表 ) + 代码和数据 进程 = 内核数据结构(task_struct mm_struct 页表) + 代码和数据 进程=内核数据结构(taskstructmmstruct页表)+代码和数据 -
进程切换:因为
mm_struct是被维护在task_struct中的,cr3寄存器指向当前进程的页表,cr3寄存器中的内容属于进程的上下文!因此进程地址空间与页表都是自动切换的! -
进程之间具有独立性!怎么做到的?
- 每个进程都有自己独立的内核数据结构。
- 每个进程的虚拟地址可以完全一样,只要通过页表映射出来的物理地址不一样就行!实现了代码和数据层面的解耦!进程资源的释放并不会影响其他进程!
因此,进程的代码和数据加载到物理内存的位置并不重要
知识点总结:
- 什么是进程地址空间
- 为什么要有地址空间
相关文章:

Linux 进程地址空间
知识回顾 在 C 语言的学习过程中,我们知道内存是可以被划分为栈区,堆区,全局数据区,字符常量区,代码区的。他的空间排布可能是下面的样子: 其中,全局数据区,可以划分为已初始化全局…...

websocket vue操作
let websocket: WebSocket; /** websocket测试 */ function connectWebsocket() {if (typeof WebSocket "undefined") {console.log("您的浏览器不支持WebSocket");return;}// let ip window.location.hostname ":8080";let ip "10.192…...
腾讯云CentOS8 jenkins war安装jenkins步骤文档
腾讯云CentOS8 jenkins war安装jenkins步骤文档 一、安装jdk 1.1 上传jdk-11.0.20_linux-x64_bin.tar.gz 1.2 解压jdk安装包文件 tar -zxvf jdk*.tar.gz 1.3 在/usr/local 目录下创建java目录 cd /usr/local mkdir java 1.4 切到java目录,把jdk解压文件改名为jd…...

Linux: glibc: net/if.h vs linux/if.h
最近看到一段代码改动,用net/if.h替换了linux/if.h。仔细看了看这两个的区别: https://stackoverflow.com/questions/20082433/what-is-the-difference-between-linux-if-h-and-net-if-h 从网上搜了一下看到如下的一个编译错误,如果同时使用这两个if.h文件,需要将net/if.h…...
使用Android Studio导入Android源码:基于全志H713 AOSP,方便解决编译、编码问题
文章目录 一、 篇头二、 操作步骤2.1 编译AOSP AS工程文件2.2 将AOSP导入Android Studio2.3 切到Project试图2.4 等待index结束2.5 下载缺失的JDK 1.82.6 导入完成 三、 导入AS的好处3.1 本文案例演示源码编译错误AS对比同文件其余地方的调用AS错误提示依赖AS做错误修正 一、 篇…...

python random详解
文章目录 random简单示例1. 生成随机浮点数:2. 生成指定范围内的随机整数:3. 从序列中随机选择元素:4. 打乱序列顺序: 常用的方法及其解释和例子:1. random():该方法返回一个0到1之间的随机浮点数。例如&am…...
java-两个列表进行比较,判断那些是需要新增的、删除的、和更新的
文章目录 前言两个列表进行比较,判断那些是需要新增的、删除的、和更新的 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实…...
【WPF.NET开发】WPF中的对话框
目录 1、消息框 2、通用对话框 3、自定义对话框 实现对话框 4、打开对话框的 UI 元素 4.1 菜单项 4.2 按钮 5、返回结果 5.1 模式对话框 5.2 处理响应 5.3 非模式对话框 Windows Presentation Foundation (WPF) 为你提供了自行设计对话框的方法。 对话框是窗口&…...

NLP项目实战01之电影评论分类
介绍: 欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。 展示: 训练展示如下…...

一款可无限扩展的软件定时器开源框架项目代码
摘自链接 时间片轮询架构如何稳定高效实现,取代传统的标志位判断方式,更优雅更方便地管理程序的时间触发操作。 可以在STM32单片机上运行。...

GRE与顺丰圆通快递盒子
1. DNS污染 随想: 在输入一串网址后,会发生如下变化如果你在系统中配置了 Hosts 文件,那么电脑会先查询 Hosts 文件如果 Hosts 里面没有这个别名,就通过域名服务器查询域名服务器回应了,那么你的电脑就可以根据域名服…...
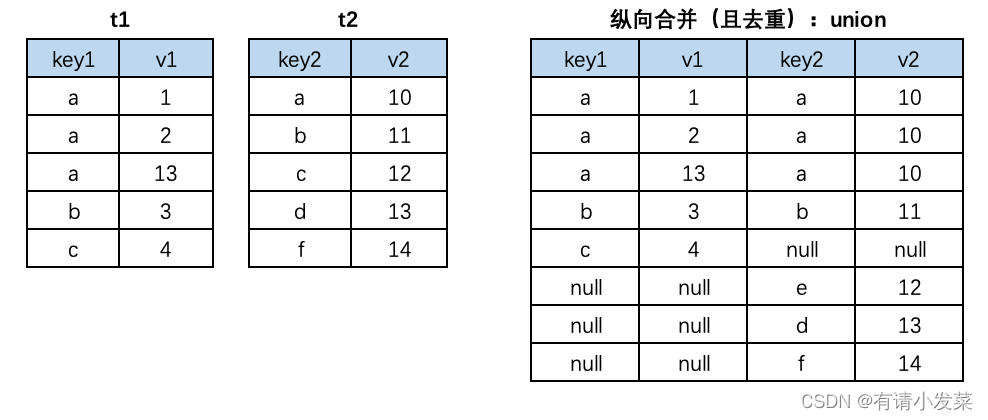
12.Mysql 多表数据横向合并和纵向合并
Mysql 函数参考和扩展:Mysql 常用函数和基础查询、 Mysql 官网 Mysql 语法执行顺序如下,一定要清楚!!!运算符相关,可前往 Mysql 基础语法和执行顺序扩展。 (8) select (9) distinct (11)<columns_name…...

线性回归与逻辑回归:深入解析机器学习的基石模型
目录 一、线性回归 二、逻辑回归 逻辑回归算法和 KNN 算法的区别 分类算法评价维度...

电脑待机怎么设置?让你的电脑更加节能
在日常使用电脑的过程中,合理设置待机模式是一项省电且环保的好习惯。然而,许多用户对于如何设置电脑待机感到困扰。那么电脑待机怎么设置呢?本文将深入探讨三种常用的电脑待机设置方法,通过详细的步骤,帮助用户更好地…...
数据库对象介绍与实践:视图、函数、存储过程、触发器和物化视图
文章目录 一、视图(View)1、概念2、基本操作1)创建视图2)修改视图3)删除视图4)使用视图 3、使用场景4、实践 二、函数(Function)1、概念2、基本操作1)创建函数2ÿ…...

arm平台编译so文件回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、几个点二、回顾过程 1.上来就执行Makefile2.编译第三方开源库.a文件 2.1 build.sh脚本2.2 Makefile3.最终编译三、其它知识点总结 前言 提示:这…...
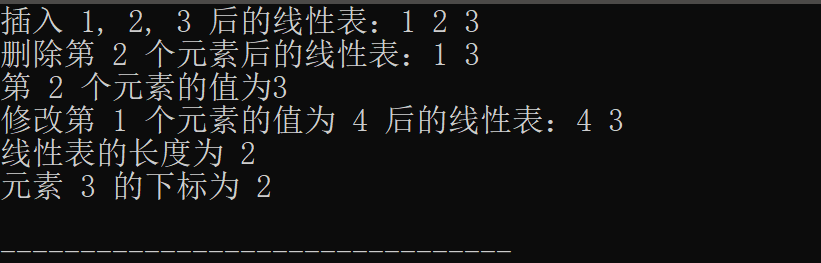
【数据结构】顺序表的定义和运算
目录 1.初始化 2.插入 3.删除 4.查找 5.修改 6.长度 7.遍历 8.完整代码 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 &…...
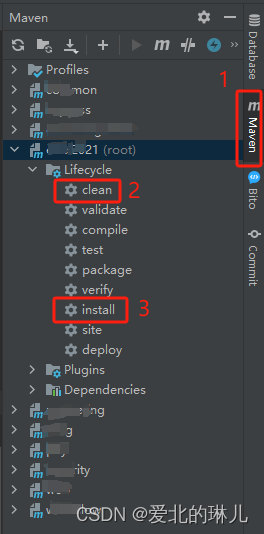
idea使用maven的package打包时提示“找不到符号”或“找不到包”
介绍:由于我们的项目是多模块开发项目,在打包时有些模块内容更新导致其他模块在引用该模块时不能正确引入。 情况一:找不到符号 情况一:找不到包 错误代码部分展示: Failure to find com.xxx.xxxx:xxx:pom:0.5 in …...

MetricBeat监控MySQL
目录 一、安装部署 二、开启mysql监控模块 三、编辑mysql配置文件 四、启动Metricbeat 五、查看监控图表 一、安装部署 metriceat的安装部署参考章节: Metricbeat安装使用,这里不再赘述。 二、开启mysql监控模块 进入metricbeat安装目录 ./metricb…...
Child Mind Institute - Detect Sleep States(2023年第一次Kaggle拿到了银牌总结)
感谢 感谢艾兄(大佬带队)、rich师弟(师弟通过这次比赛机械转码成功、耐心学习)、张同学(也很有耐心的在学习),感谢开源方案(开源就是银牌),在此基础上一个月…...

AI模型GUI开发实战:从架构设计到部署的完整指南
1. 项目概述:一个为AI模型打造的图形化交互界面最近在GitHub上看到一个挺有意思的项目,叫GrahamMiranda-AI/openclaw-model-gui。光看名字,就能猜个八九不离十:这大概率是一个为某个名为“OpenClaw”的AI模型配套开发的图形用户界…...

Arm CoreLink PCK-600电源管理套件解析与应用实践
1. Arm CoreLink PCK-600电源控制套件概述在现代SoC设计中,电源管理已经成为一个关键的技术挑战。随着移动设备和物联网应用的普及,如何在保证性能的同时最大限度地降低功耗,成为芯片设计者面临的核心问题。Arm CoreLink PCK-600电源控制套件…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...

基于CircuitPython的Fruit Jam OS:在RP2350上构建复古微型计算机系统
1. 项目概述:当复古计算精神遇见现代微控制器如果你和我一样,对早期个人计算机那种开机即用、一切尽在掌控的纯粹体验抱有怀念,同时又痴迷于现代开源硬件带来的无限可能,那么Fruit Jam OS绝对是一个会让你眼前一亮的项目。它不是一…...

2026 私域救命玩法!90% 的老板赚不到钱,根本不是产品不行
我在杭州做电商、做私域、做投资这么多年,见过各行各业的起起伏伏。这些年接触过的实体老板,没有一百也有八十。手里握着工厂的、拿着自主知识产权的、有正规生产资质的,比比皆是。但 90% 的人都在亏钱。他们天天抱怨流量太贵、同行乱价、客户…...

用Circuit Playground Express制作可穿戴互动闪光T恤:零焊接图形化编程入门
1. 项目概述:一件会“跳舞”的闪光T恤几年前,当我第一次把微控制器缝进衣服里时,那感觉既兴奋又麻烦——满桌子的电线、烙铁,还有对洗衣机深深的恐惧。但现在,像Adafruit的Circuit Playground Express(后面…...
)
【独家首发】ElevenLabs马拉雅拉姆文支持状态实测报告(含ISO 639-2代码验证、音素对齐误差率<0.8%)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs马拉雅拉姆文支持的现状与战略意义 ElevenLabs 作为全球领先的语音合成平台,自2023年11月起正式将马拉雅拉姆语(Malayalam,ISO 639-1: ml)纳入…...

2026年十大最佳地区搜索排名优化工具:权威榜单赋能企业高效增长
本文全面梳理了2026年十大主流地区搜索排名优化工具的核心功能与应用价值,旨在为本地企业提供客观、实用的选型参考。通过对各工具地域关键词布局、多平台同步能力及实时数据监控等关键模块的解析,结合具体参数指标与套餐定价,系统呈现不同场…...

自学 Vibe Coding 这三个网站就够了!
背景 我之前想学 Vibe Coding,刷到各种"AI 编程神器"、"零基础用 AI 写代码"的文章,看得心潮澎湃。 结果一上手就懵了:装了插件、开了 AI、对着编辑器发呆,不知道下一步干嘛。 网上搜教程,要么…...

【多目标进化优化】MOEA测试函数:从经典到前沿的挑战与演进
1. MOEA测试函数的起源与核心价值 我第一次接触多目标进化优化(MOEA)测试函数是在2013年的一次算法对比实验中。当时为了验证新设计的NSGA-II改进版本,需要一组标准测试函数作为基准。ZDT系列函数成为了我的首选,但很快就发现这些…...