Kafka中的Topic

在Kafka中,Topic是消息的逻辑容器,用于组织和分类消息。本文将深入探讨Kafka Topic的各个方面,包括创建、配置、生产者和消费者,以及一些实际应用中的示例代码。
1. 介绍
在Kafka中,Topic是消息的逻辑通道,生产者将消息发布到Topic,而消费者从Topic订阅消息。每个Topic可以有多个分区(Partitions),每个分区可以在不同的服务器上,以实现横向扩展。
2. 创建和配置Topic
2.1 创建Topic
使用Kafka提供的命令行工具(kafka-topics.sh)或Kafka的API来创建Topic。下面是一个使用命令行工具创建Topic的示例:
bin/kafka-topics.sh --create --topic my_topic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
这将创建一个名为my_topic的Topic,有3个分区,复制因子为2。
2.2 配置Topic
Kafka的Topic有各种配置选项,可以通过修改Topic的属性来满足不同的需求。例如,可以设置消息保留时间、清理策略等。以下是一个配置Topic属性的示例:
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my_topic --alter --add-config max.message.bytes=1048576
这将修改my_topic的配置,将最大消息字节数设置为1 MB。
3. 生产者和消费者
3.1 生产者
生产者负责将消息发布到Topic。使用Kafka的Producer API,可以轻松地创建一个生产者。以下是一个简单的Java示例代码:
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(properties);producer.send(new ProducerRecord<>("my_topic", "key1", "value1"));
producer.close();
3.2 消费者
消费者从Topic中读取消息。Kafka的Consumer API提供了强大而灵活的方式来实现消费者。
以下是一个简单的Java示例代码:
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "my_group");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("my_topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Offset = %d, Key = %s, Value = %s%n", record.offset(), record.key(), record.value());}
}
4. 实际应用示例
4.1 实时日志处理
在实时日志处理的场景中,Kafka的Topic可以按照日志类型进行划分,每个Topic代表一种日志类型。这样的设计可以使得系统更具可维护性、可扩展性,并且允许不同类型的日志通过独立的消费者进行处理。以下是一个更详细的示例代码,展示如何在实时日志处理中使用Kafka Topic:
4.1.1 创建日志类型Topic
首先,为不同的日志类型创建各自的Topic。以错误日志和访问日志为例:
# 创建错误日志Topic
bin/kafka-topics.sh --create --topic error_logs --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092# 创建访问日志Topic
bin/kafka-topics.sh --create --topic access_logs --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
4.1.2 生产者发布日志消息
在应用中,生成错误日志和访问日志的代码可能如下:
// 错误日志生产者
Producer<String, String> errorLogProducer = new KafkaProducer<>(errorLogProperties);
errorLogProducer.send(new ProducerRecord<>("error_logs", "Error message"));// 访问日志生产者
Producer<String, String> accessLogProducer = new KafkaProducer<>(accessLogProperties);
accessLogProducer.send(new ProducerRecord<>("access_logs", "Access log message"));
4.1.3 消费者实时处理日志
创建独立的消费者来处理错误日志和访问日志:
// 错误日志消费者
Consumer<String, String> errorLogConsumer = new KafkaConsumer<>(errorLogProperties);
errorLogConsumer.subscribe(Collections.singletonList("error_logs"));while (true) {ConsumerRecords<String, String> records = errorLogConsumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理错误日志System.out.printf("Error Log - Offset = %d, Value = %s%n", record.offset(), record.value());}
}// 访问日志消费者
Consumer<String, String> accessLogConsumer = new KafkaConsumer<>(accessLogProperties);
accessLogConsumer.subscribe(Collections.singletonList("access_logs"));while (true) {ConsumerRecords<String, String> records = accessLogConsumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理访问日志System.out.printf("Access Log - Offset = %d, Value = %s%n", record.offset(), record.value());}
}
4.1.4 实时监控和分析
消费者可以通过实时处理日志来进行监控和分析。例如,可以使用流处理框架(如Kafka Streams)对日志进行聚合、过滤或转换。以下是一个简化的示例:
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> errorLogsStream = builder.stream("error_logs");
KStream<String, String> accessLogsStream = builder.stream("access_logs");// 在这里进行实时处理,如聚合、过滤等// 通过输出Topic将处理结果发送到下游系统
errorLogsStream.to("processed_error_logs");
accessLogsStream.to("processed_access_logs");KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
通过这种设计,可以根据实际需要扩展不同类型的日志处理,同时确保系统具有高度的灵活性和可扩展性。在实际应用中,可能需要更详细的配置和处理逻辑,以满足具体的监控和分析需求。
4.2 事件溯源
在事件驱动的架构中,事件溯源是一种强大的方式,通过创建一个专门的Kafka Topic来记录每个业务事件的发生,以便随时追踪和回溯整个系统的状态。以下是一个基于Kafka的事件溯源的详细示例代码:
4.2.1 创建事件Topic
首先,为每个关键的业务事件创建一个专用的Kafka Topic,例如order_created、order_shipped等:
# 创建订单创建事件Topic
bin/kafka-topics.sh --create --topic order_created --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092# 创建订单发货事件Topic
bin/kafka-topics.sh --create --topic order_shipped --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
4.2.2 发布业务事件
在应用中,当业务事件发生时,将事件发布到相应的Topic。以下是一个订单创建事件和订单发货事件的示例:
// 订单创建事件生产者
Producer<String, String> orderCreatedProducer = new KafkaProducer<>(orderCreatedProperties);
orderCreatedProducer.send(new ProducerRecord<>("order_created", "order_id", "Order created - Order ID: 123"));// 订单发货事件生产者
Producer<String, String> orderShippedProducer = new KafkaProducer<>(orderShippedProperties);
orderShippedProducer.send(new ProducerRecord<>("order_shipped", "order_id", "Order shipped - Order ID: 123"));
4.2.3 事件溯源消费者
为了实现事件溯源,我们需要一个专用的消费者来订阅所有的事件Topic,并将事件记录到一个持久化存储中(如数据库、日志文件等):
// 事件溯源消费者
Consumer<String, String> eventTraceConsumer = new KafkaConsumer<>(eventTraceProperties);
eventTraceConsumer.subscribe(Arrays.asList("order_created", "order_shipped"));while (true) {ConsumerRecords<String, String> records = eventTraceConsumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理事件,可以将事件记录到数据库或日志文件中System.out.printf("Event Trace - Offset = %d, Key = %s, Value = %s%n", record.offset(), record.key(), record.value());// 持久化处理逻辑}
}
4.2.4 事件回溯和分析
通过上述设置,可以在任何时候回溯系统中的每个事件,了解事件的发生时间、顺序和内容。通过将事件存储到持久化存储中,可以建立一个事件溯源系统,支持系统状态的分析、回滚和审计。
还可以使用流处理来实时分析事件,例如计算每个订单的处理时间、统计每个事件类型的发生频率等。以下是一个简单的流处理示例:
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> eventStream = builder.stream(Arrays.asList("order_created", "order_shipped"));// 在这里进行实时处理,如计算处理时间、统计频率等// 通过输出Topic将处理结果发送到下游系统
eventStream.to("processed_events");KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
通过这种方式,可以在事件溯源系统中实现强大的监控、分析和管理功能,提高系统的可观察性和可维护性。
5. 消息处理语义
Kafka支持不同的消息处理语义,包括最多一次、最少一次和正好一次。这些语义由消费者的配置决定,可以根据应用的要求进行选择。以下是一个使用最多一次语义的消费者示例代码:
properties.put("enable.auto.commit", "false"); // 禁用自动提交偏移量
properties.put("auto.offset.reset", "earliest"); // 设置偏移量重置策略为最早Consumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("my_topic"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理消息System.out.printf("Offset = %d, Key = %s, Value = %s%n", record.offset(), record.key(), record.value());}consumer.commitSync(); // 手动提交偏移量}
} finally {consumer.close();
}
6. 安全性和权限控制
Kafka提供了安全性特性,包括SSL加密、SASL认证等。在生产环境中,确保适当的安全性设置是至关重要的。
以下是一个使用SSL连接的生产者示例:
properties.put("security.protocol", "SSL");
properties.put("ssl.truststore.location", "/path/to/truststore");
properties.put("ssl.truststore.password", "truststore_password");Producer<String, String> producer = new KafkaProducer<>(properties);
7. 故障容忍和可伸缩性
7.1 多节点分布和分区
在Kafka中,分布式的设计允许数据分布在多个节点上,这提供了高度的可伸缩性。每个Topic可以分成多个分区,而这些分区可以分布在不同的服务器上。这种分布式设计使得Kafka可以轻松地处理大规模数据,并实现水平扩展。
7.1.1 增加分区数
要增加Topic的分区数,可以使用以下命令:
bin/kafka-topics.sh --alter --topic my_topic --partitions 5 --bootstrap-server localhost:9092
这将把my_topic的分区数增加到5,从而提高系统的吞吐量和可伸缩性。
7.2 复制因子
Kafka通过数据的复制来实现容错性。每个分区可以有多个副本,这些副本分布在不同的节点上。在节点发生故障时,其他副本可以继续提供服务。
7.2.1 增加复制因子
要增加Topic的复制因子,可以使用以下命令:
bin/kafka-topics.sh --alter --topic my_topic --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092
这将把my_topic的复制因子增加到3,确保每个分区有3个副本。增加复制因子提高了系统的容错性,因为每个分区都有多个副本,即使一个节点发生故障,其他节点上的副本仍然可用。
7.3 节点故障处理
Kafka能够处理节点故障,确保系统的可用性。当一个节点发生故障时,Kafka会自动将该节点上的分区重新分配到其他可用节点上,以保持分区的复制因子。
7.3.1 节点故障模拟
为了模拟节点故障,你可以通过停止一个Kafka broker进程来模拟。Kafka会自动感知到该节点的故障,并进行分区的重新分配。
# 停止一个Kafka broker进程
bin/kafka-server-stop.sh config/server-1.properties
7.4 性能调优
在实际应用中,通过监控系统的性能指标,你可以调整Kafka的配置以满足不同的性能需求。例如,调整日志刷写频率、调整内存和磁盘的配置等,都可以对系统的性能产生影响。
总结
Kafka的Topic是构建实时流数据处理系统的核心组件之一。通过深入了解Topic的创建、配置、生产者和消费者,以及实际应用中的示例代码,可以更好地理解和应用Kafka。在实际项目中,根据具体需求和场景进行灵活配置,以确保系统的可靠性、性能和安全性。
相关文章:
Kafka中的Topic
在Kafka中,Topic是消息的逻辑容器,用于组织和分类消息。本文将深入探讨Kafka Topic的各个方面,包括创建、配置、生产者和消费者,以及一些实际应用中的示例代码。 1. 介绍 在Kafka中,Topic是消息的逻辑通道࿰…...
LAMP部署
目录 一、安装apache 二、配置mysql 三、安装php 四、搭建论坛 4、安装另一个网站 一、安装apache 1.关闭防火墙,将安装Apache所需软件包传到/opt目录下 systemctl stop firewalld systemctl disable firewalld setenforce 0 httpd-2.4.29.tar.gz apr-1.6.2.t…...

DouyinAPI接口开发系列丨商品详情数据丨视频详情数据
电商API就是各大电商平台提供给开发者访问平台数据的接口。目前,主流电商平台如淘宝、天猫、京东、苏宁等都有自己的API。 二、电商API的应用价值 1.直接对接原始数据源,数据提取更加准确和完整。 2.查询速度更快,可以快速响应用户请求实现…...
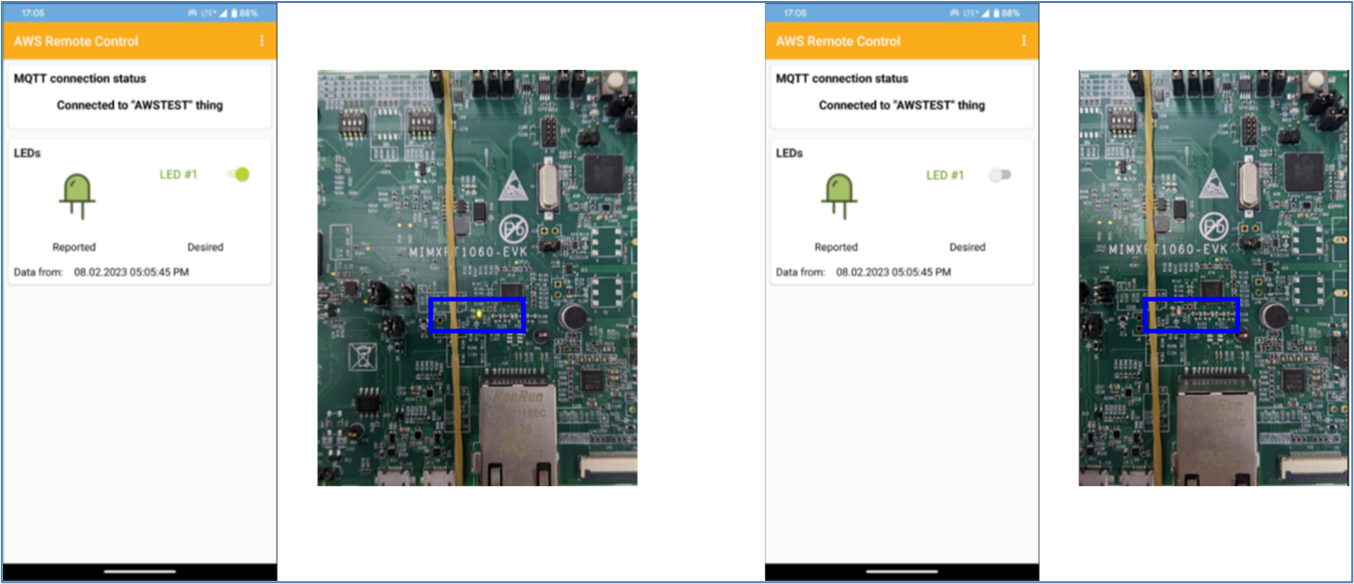
AWS Remote Control ( Wi-Fi ) on i.MX RT1060 EVK - 3 “编译 NXP i.MX RT1060”( 完 )
此章节叙述如何修改、建构 i.MX RT1060 的 Sample Code“aws_remote_control_wifi_nxp” 1. 点击“Import SDK example(s)” 2. 选择“MIMXRT1062xxxxA”>“evkmimxrt1060”,并确认 SDK 版本后,点击“Next>” 3. 选择“aws_examples”>“aw…...

5G - NR物理层解决方案支持6G非地面网络中的高移动性
文章目录 非地面网络场景链路仿真参数实验仿真结果 非地面网络场景 链路仿真参数 实验仿真结果 Figure 5 && Figure 6:不同信噪比下的BER和吞吐量 变量 SISO 2x2MIMO 2x4MIMO 2x8MIMOReyleigh衰落、Rician衰落、多径TDL-A(NLOS) 、TDL-E(LOS)(a)QPSK (b)16…...

python epub文件解析
python epub文件解析 代码BeautifulSoup 介绍解释 代码 import ebooklib from bs4 import BeautifulSoup from ebooklib import epubbook epub.read_epub("逻辑思维训练1200题.epub")# 解析 for item in book.get_items():# 提取书中的文本内容if item.get_type() …...

Visual Studio 2015 中 FFmpeg 开发环境的搭建
Visual Studio 2015 中 FFmpeg 开发环境的搭建 Visual Studio 2015 中 FFmpeg 开发环境的搭建新建控制台工程拷贝并配置 FFmpeg 开发文件测试FFmpeg 开发文件的下载链接 Visual Studio 2015 中 FFmpeg 开发环境的搭建 新建控制台工程 新建 Win32 控制台应用程序。 具体流程&…...

期末速成数据库极简版【存储过程】(5)
目录 【7】系统存储过程 【8】用户存储过程——带输出参数的存储过程 创建存储过程 存储过程调用 【9】用户存储过程——不带输出参数的存储过程 【7】系统存储过程 系统存储我们就不做过程讲解用户存储过程会考察一道大题,所以我们把重点放在用户存储过程。…...

Android Studio的代码笔记--IntentService学习
IntentService学习 IntentService常规用法清单注册服务服务内容开启服务 IntentService 一个 HandlerThread工作线程,通过Handler实现把消息加入消息队列中等待执行,通过传递的intent在onHandleIntent中处理任务。(多次调用会按顺序执行事件…...

C语言 - 字符函数和字符串函数
系列文章目录 文章目录 系列文章目录前言1. 字符分类函数islower 是能够判断参数部分的 c 是否是⼩写字⺟的。 通过返回值来说明是否是⼩写字⺟,如果是⼩写字⺟就返回⾮0的整数,如果不是⼩写字⺟,则返回0。 2. 字符转换函数3. strlen的使⽤和…...
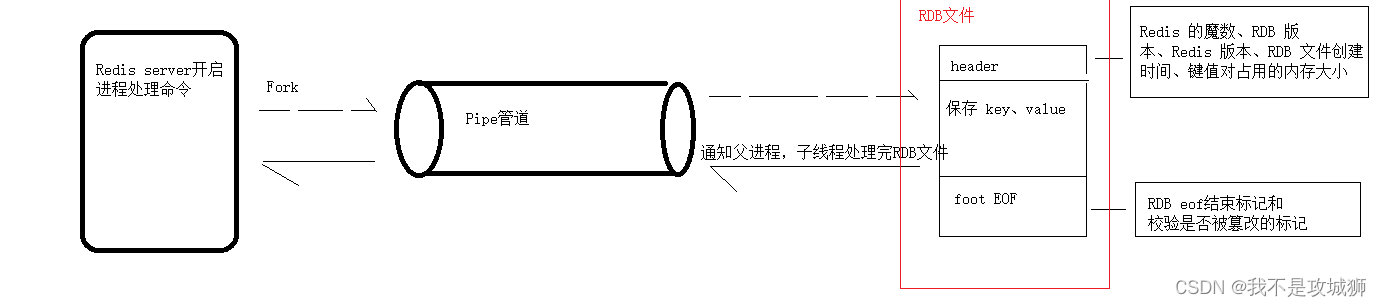
Redis rdb源码解析
前置学习:Redis server启动源码-CSDN博客 1、触发时机 1、执行save命令--->rdbSave函数 2、执行bgsave命令--->rdbSaveBackground函数或者(serverCron->prepareForShutdown) 3,主从复制-->startBgsaveForReplication…...

深入理解CyclicBarrier
文章目录 1. 概念2. CylicBarier使用简单案例3. 源码 1. 概念 CyclicBarrier 字面意思回环栅栏(循环屏障),通过它可以实现让一组线程等待至某个状态(屏障点)之后再全部同时执行。叫做回环是因为当所有等待线程都被释放…...

微信小程序 - 格式化操作 moment.js格式化常用使用方法总结大全
格式化操作使用 1. 首先,下载一个第三方库 moment npm i moment --save 注:在微信小程序中无法直接npm 下载 导入 的(安装一个就需要构建一次) 解决:菜单栏 --> 工具 --> 构建 npm 点击即可(会…...

学习pytorch18 pytorch完整的模型训练流程
pytorch完整的模型训练流程 1. 流程1. 整理训练数据 使用CIFAR10数据集2. 搭建网络结构3. 构建损失函数4. 使用优化器5. 训练模型6. 测试数据 计算模型预测正确率7. 保存模型 2. 代码1. model.py2. train.py 3. 结果tensorboard结果以下图片 颜色较浅的线是真实计算的值&#x…...

电子学会C/C++编程等级考试2021年09月(五级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:抓牛 农夫知道一头牛的位置,想要抓住它。农夫和牛都位于数轴上,农夫起始位于点N(0<=N<=100000),牛位于点K(0<=K<=100000)。农夫有两种移动方式: 1、从X移动到X-1或X+1,每次移动花费一分钟 2、从X移动到2*X,每…...
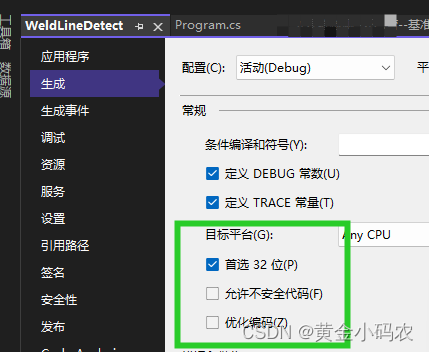
Halcon联合winform显示以及处理
在窗口中添加窗体和按钮,并在解决方案资源管理器中调加了导入Halcon导出的.cs文件,运行出现下图的问题: 问题1:CS0017 程序定义了多个入口点。使用/main(指定包含入口点的类型)进行编译。 解决方案1.: 右…...
【设计模式-4.3】行为型——责任链模式
说明:本文介绍设计模式中行为型设计模式中的,责任链模式; 审批流程 责任链模式属于行为型设计模式,关注于对象的行为。责任链模式非常典型的案例,就是审批流程的实现。如一个报销单的审批流程,根据报销单…...
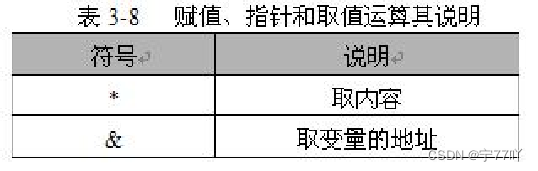
单片机语言--C51语言的数据类型以及存储类型以及一些基本运算
C51语言 本文主要涉及C51语言的一些基本知识,比如C51语言的数据类型以及存储类型以及一些基本运算。 文章目录 C51语言一、 C51与标准C的比较二、 C51语言中的数据类型与存储类型2.1、C51的扩展数据类型2.2、数据存储类型 三、 C51的基本运算3.1 算术运算符3.2 逻辑…...
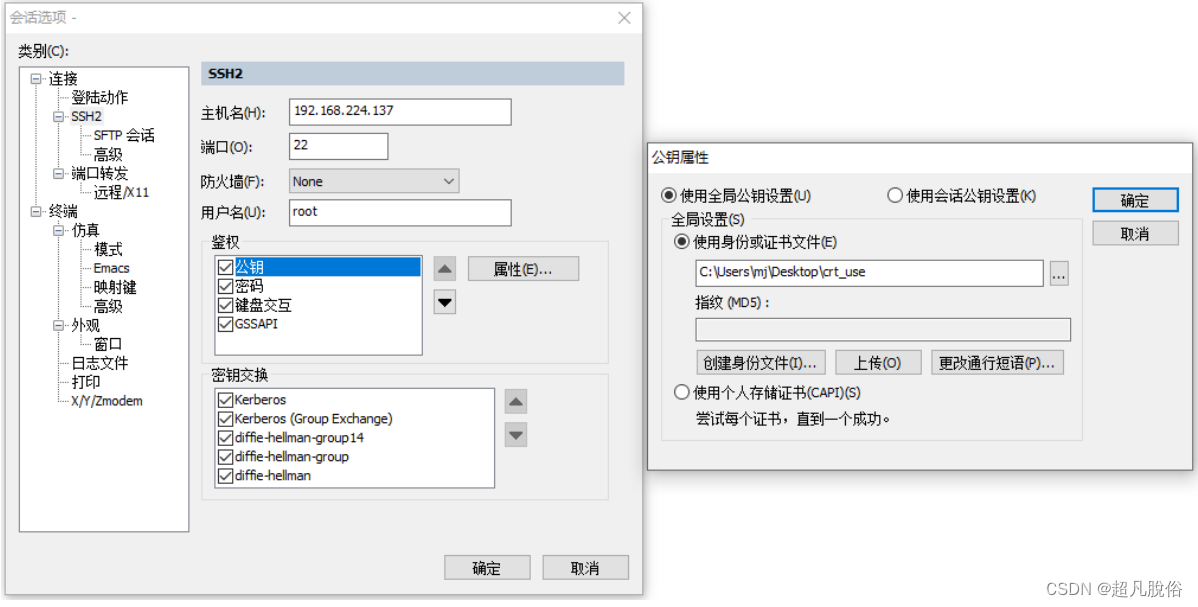
《每天一个Linux命令》 -- (5)通过sshkey密钥登录服务器
欢迎阅读《每天一个Linux命令》系列!在本篇文章中,将介绍通过密钥生成,使用公钥连接管理服务器。 概念 SSH 密钥是用于安全地访问远程服务器的一种方法。SSH 密钥由一对密钥组成:公钥和私钥。公钥存储在远程服务器上,…...
)
kubernetes的服务发现(二)
如前面的文章我们说了,kubernetes的服务发现是服务端发现模式。它有一个服务注册中心,使用DNS作为服务的注册表。每个集群都会运行一个DNS服务,默认是CoreDNS服务。每个服务都会在这个DNS中注册。注册的大致过程: 1、向kube-apise…...

嵌入式GUI设计:资源受限下的高效人机交互实践
1. 嵌入式GUI设计的核心挑战与价值定位在咖啡机、车载仪表、医疗设备等嵌入式系统中,图形用户界面(GUI)承担着人机交互的关键桥梁作用。与桌面端或移动端GUI不同,嵌入式GUI面临三大独特约束:首先,硬件资源极度受限——典型嵌入式处…...

用桌面CNC制作乐高兼容木制积木:从Fusion 360设计到精密加工全流程
1. 项目概述:当数字制造遇见经典玩具作为一名玩了十多年CNC的爱好者,我一直在寻找那些能将技术、创意和实用性完美结合的项目。最近,我成功地将工作室角落里的一块硬木废料,变成了一套可以严丝合缝地拼搭在标准乐高积木上的木制建…...

Arduino开源贡献全流程:从Fork到Pull Request的工程实践
1. 项目概述与核心价值 如果你在玩Arduino,发现某个常用库有个小bug,或者想给它加个新功能,你会怎么做?是去论坛发个帖子,还是自己改完代码藏起来用?对于很多刚接触开源的朋友来说,虽然有心贡献…...

ElevenLabs多角色对话生成性能压测报告:单实例并发超86路时语音错位率飙升至41.7%,我们找到了唯一稳定解
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs多角色对话生成性能压测报告:单实例并发超86路时语音错位率飙升至41.7%,我们找到了唯一稳定解 在真实业务场景中,ElevenLabs API 被广泛用于构建多角色交互…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...

Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent框架对接Taotoken聚合API的详细配置步骤指南 1. 准备工作 在开始配置之前,你需要准备好两样东西…...

别再只当CANoe/CANape的‘眼睛’了!VN1640A的I/O通道实战:手把手教你采集电压和开关信号
VN1640A硬件接口深度开发:从电压采集到PWM控制的工程实践 在汽车电子测试领域,Vector的VN系列接口设备早已成为行业标准配置。大多数工程师对CAN/LIN通道的应用驾轻就熟,却常常忽略设备上那个不起眼的9针I/O接口——这个被低估的硬件通道实际…...

[4G5G专题] RRU CFR技术:从“削峰”到“塑形”的算法演进与工程实践
1. 从“削峰”到“塑形”:CFR技术的本质蜕变 第一次接触CFR(Crest Factor Reduction)技术时,我把它简单理解为“信号削峰器”——就像用菜刀切掉蛋糕顶端多余的部分。早期在4G RRU(Remote Radio Unit)项目中…...

工业 DC-DC 设计|钡特电源 DF2-05S05LS 与 F0505S-2WR3 封装互通硬件适配分析
在工业控制、智能传感及嵌入式设备研发中,小功率隔离直流电源模块是板级供电的核心单元,直接影响系统稳定性与长期运行成本。硬件工程师选型时,需重点关注参数匹配、封装适配、环境耐受性及性价比,而钡特电源 DF2-05S05LS 与 F050…...

基于Taotoken构建每日大赛自动评分与反馈Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken构建每日大赛自动评分与反馈Agent工作流 对于编程大赛、算法竞赛或日常训练的组织者与教练而言,每日处理大…...