mysql一条sql语句的执行过程
sql的具体执行过程
- 客户端发送一条查询给服务器
- 服务器下先检查查询缓存,如果命中了缓存,返回缓存中的结果
- 否则就需要服务器端进行sql的解析、预处理,再由优化器生成对应的执行计划
- 根据执行计划,调用存储引擎的api来执行查询
- 将结果返回给客户端
客户端发送sql给服务器:
- mysql的通信协议简单快速,但是也有很多限制了,比如无法进行流量控制,一旦开始发送数据,另一端需要完整的接收数据才能响应它,所以在必要的时候,查询一定要加 limit 进行限制
- 如果有很长的查询语句,可能需要设置mysql服务器和客户端在一次传送数据包的过程中最大允许的数据包大小(max_allowed_packet)
查询缓存:
-
应用程序不需要关心是通过查询缓存返回的结果还是实际执行查询返回的结果,因为两者的结果是完全相同的,而且查询缓存也不需要使用任何语法
-
在解析一个查询语句之前,如果查询缓存是打开的,那么会优先检查这个查询是否命中查询缓存中的数据,如果命中,就立刻返回结果,跳过解析、优化和执行阶段
-
在判断缓存是否命中的时候,mysql不会解析sql语句,而是直接使用客户端发送过来的原始信息进行对比,任何字符上的不同,都会导致缓存不命中
-
缓存未命中的可能情况有:
- 首先查询语句本身可能无法被缓存。例如查询中包含任意用户自定义函数、用户变量等,都不会被缓存
- 或者数据库第一次处理这个查询,也有可能缓存没有预热,mysql还没有机会把查询结果都缓存起来
- 还有可能是缓存失效了:表被更新了,或者虽然缓存了查询结果,但是内存不足,会将某些缓存剔除
-
查询缓存适用的情况
- 只有当缓存带来的资源节约大于本身资源消耗才会带来性能提升
- 查询缓存可以降低查询的执行时间,但是不能降低查询结果传输的网络消耗,如果系统的瓶颈是网络传输,那么查询缓存的意义不大
- 对于复杂的查询语句,每次执行的消耗非常大,返回的结果集却很小,而且表更新不频繁,这种情况比较适合查询缓存
查询缓存的缺点:
- 查询缓存有可能成为服务器的资源竞争点,所以默认应该关闭查询缓存
- 查询缓存系统会跟踪查询中涉及的每个表,如果这些表发生变化,和这个表相关的所有缓存数据都会失效,如果查询缓存使用了大量的内存,缓存失效可能是一个非常严重的问题,会导致整个系统的卡顿
- 另外打开查询缓存会带来额外的消耗,例如:
- 查询开始之前必须先检查是否命中缓存
- 如果这个查询可以被缓存,会将结果存入查询缓存,这会有额外的系统消耗
- 对于写操作来说,向某个表写入数据的时候,还需要额外把这个表所有的缓存都要设置为失效
- 如果缓存的结果再失效前没有被任何其他查询使用,这次缓存就是浪费时间和内存
查询缓存的优化:
- 用多个小表代替一个大表
- 写入时采用批量写入,这样查询缓存就只需要一次失效
- 合理设置缓存空间大小,缓存空间太大,过期操作可能会导致服务器卡死
- 写密集型应用,直接禁用缓存查询
innodb的查询缓存
- innodb因为有mvcc机制,和查询缓存的交互会更加麻烦
- innodb会控制再一个事务中,是否可以使用查询缓存,可以同时控制对查询缓存的读和写(向查询缓存写入数据)
- 事务是否可以访问查询缓存,取决于当前事务id,以及对应表上是否有锁,每一个innodb表的内存数据字典都会保存一个事务id号,如果当前事务id小于该事务id,就无法访问查询缓存
- 如果表上有锁,这个表的任何查询语句都是无法被缓存的
sql的解析、预处理,优化器:
- 语法解析器和预处理,也就是mysql通过关键字把sql语句进行解析,生成一颗解析树,这里会检查语法规则是否正确,表和列是否存在等
- 查询优化器会将语法树转换为执行计划
-
一条sql有很多种执行方式,虽然最后都会返回相同结果,但是执行过程并不一样,优化器的作用就是找到其中最好的执行计划
-
mysql使用的是基于成本的优化器,它会预测执行一个某种执行计划的成本,然后选择最小的一个
-
但是又很多种原因会导致mysql优化器选择错误的执行计划,比如:
-
mysql的最优只是基于成本模型的最优执行计划,并不一定是最快的,而且预估成本不等于实际成本
-
mysql也不考虑其他并发执行的查询,这有可能会影响到当前的查询速度
-
另外mysql不会考虑用户自定义的函数成本,如果包含全文搜索match()的字句,就会使用全文索引
-
-
mysql能处理的优化类型有:
- 重新定义关联表的顺序
- 优化count(),max(),min()等
- 如果一个表达式能转换为常数,就会一直把表达式作为常数处理
- 当索引中的列包含查询需要使用的所有列,可以使用索引返回需要的数据,也就是覆盖索引
- 如果发现已经满足查询要求的时候,能够立刻终止查询
- 如果两个列通过等式关联,mysql能够把其中一个列的条件传递到另一个列上
- mysql将 in() 列表中的数据先进行排序,然后通过二分查找的方式来确定列表中的值是否满足条件,所以mysql中的 in() 不完全等于多尔 or 条件字句,in() 的速度会更快
-
对于查询优化器,最好不要做多余的工作,不仅可能带不来收益,还会增加维护的难度
-
查询状态:
- 对于一个mysql的连接,任何时刻都有一个状态。可以使用show full processlist 来查看这个状态
- sleep :正在等待客户端发送新的请求
- query : 正在执行查询或者正在将结果发送给客户端
- locked : 在mysql服务层正在等待表锁,在innodb不会出现这个状态
- Copying to tmp table : 正在执行查询,并将结果集复制到临时表中
- sorting result : 正在对
- 结果集进行排序
相关文章:

mysql一条sql语句的执行过程
sql的具体执行过程 客户端发送一条查询给服务器服务器下先检查查询缓存,如果命中了缓存,返回缓存中的结果否则就需要服务器端进行sql的解析、预处理,再由优化器生成对应的执行计划根据执行计划,调用存储引擎的api来执行查询将结果…...

SaaS是什么,和多租户有什么关系?
空间数据又称几何数据,用来表示物体的位置,形态,大小分布等各方面的信息,是对现实世界中存在的具有定位意义的事物和现象的定量描述。 多租户是SaaS领域特有的产物。 SaaS服务是部署在云上的,客户可以按需购买&#…...

C语言---字符串函数总结
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...

MySQL-表的基本操作
一、创建数据表创建数据表是指在已经创建好的数据库中建立新表。创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性约束的过程。创建表之前应先使用语句{use 数据库名} 进入到指定的数据库,再执行表操作。创建表语法:CREATE TABLE <表…...

开篇之作—闲聊几句AUTOSAR
背景信息 步入职场已有些许年头,遇到过不少的人,经历过不算多的事情,也走过一些地方。现在坐下来想想,觉得一路走过总是行色匆匆,都来不及停下来驻足路边的风景,抑或是回头看看身后的精彩。 现在有些庆幸的是,加入了这个汽车这个行业,从事着汽车电子开发领域,也因此…...
02- 天池工业蒸汽量项目实战 (项目二)
忽略警告: warnings.filterwarnings("ignore") import warnings warnings.filterwarnings("ignore") 读取文件格式: pd.read_csv(train_data_file, sep\t) # 注意sep 是 , , 还是\ttrain_data.info() # 查看是否存在空数据及数据类型train_data.desc…...

LeetCode-111. 二叉树的最小深度
目录题目分析递归法题目来源111. 二叉树的最小深度题目分析 这道题目容易联想到104题的最大深度,把代码搬过来 class Solution {public int minDepth(TreeNode root) {return dfs(root);}public static int dfs(TreeNode root){if(root null){return 0;}int left…...

git常用命令
(一)克隆代码(clone):将远程仓库代码克隆到本地仓库 克隆远程仓库某个分支 git clone -b 远程分支名称 https://github.com/master/master.git 本地文件名称 克隆远程仓库默认分支 git clone https://github.com/mas…...

2022年12月电子学会Python等级考试试卷(一级)答案解析
青少年软件编程(Python)等级考试试卷(一级) 一、单选题(共25题,共50分) 1. 关于Python语言的注释,以下选项中描述错误的是?( ) A. Python语言有两种注释方式&…...

大数据未来会如何发展
大数据应用的重要性,自全国提出“数据中国”的概念以来,我们周围默默地在发挥作用的大数据逐渐深入人们的心中,大数据的应用也越来越广泛,具体到金融、汽车、餐饮、电信、能源、体育和娱乐等领域 为什么大数据技术那么火…...

2022黑马Redis跟学笔记.基础篇(一)
2022黑马Redis跟学笔记.基础篇 一1.Redis入门1.1.认识NoSQL1.1.1.结构化与非结构化1.1.2.关联和非关联1.1.3.查询方式1.1.4.事务1.1.5.总结1.2.认识Redis1.3.安装Redis步骤一:安装Redis依赖步骤二:上传安装包并解压步骤三:启动(1).默认启动(2…...
【Spring(十一)】万字带你深入学习面向切面编程AOP
文章目录前言AOP简介AOP入门案例AOP工作流程AOP切入点表达式AOP通知类型AOP通知获取数据总结前言 今天我们来学习AOP,在最初我们学习Spring时说过Spring的两大特征,一个是IOC,一个是AOP,我们现在要学习的就是这个AOP。 AOP简介 AOP:面向切面编程,一种编程范式&#…...

基于Java+SpringBoot+Vue+uniapp前后端分离图书阅读系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建、毕业项目实战、项目定制✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《S…...

2021年新公开工业控制系统严重漏洞汇总
声明 本文是学习ITOT一体化工业信息安全态势报告(2019). 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 工业互联网安全威胁 2021年新公开工业控制系统严重漏洞 缓冲区溢出漏洞 缓冲区溢出(buffer overflow&…...
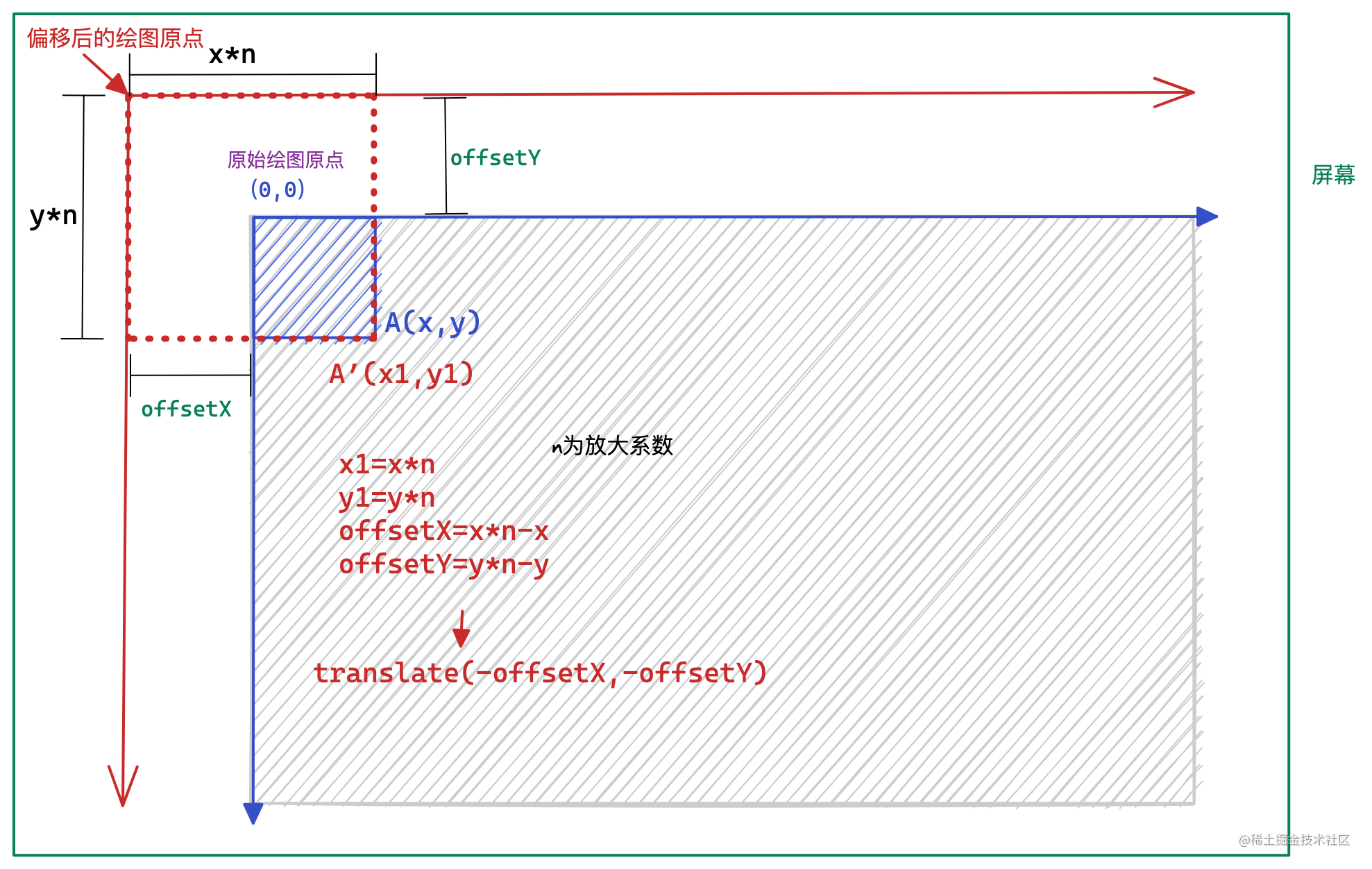
Canvas鼠标滚轮缩放以及画布拖动(图文并茂版)
Canvas鼠标滚轮缩放以及画布拖动 本文会带大家认识Canvas中常用的坐标变换方法 translate 和 scale,并结合这两个方法,实现鼠标滚轮缩放以及画布拖动功能。 Canvas的坐标变换 Canvas 绘图的缩放以及画布拖动主要通过 CanvasRenderingContext2D 提供的 …...

[ECCV 2020] FGVC via progressive multi-granularity training of jigsaw patches
Contents IntroductionProgressive Multi-Granularity (PMG) training frameworkExperimentsReferencesIntroduction 不同于显式地寻找特征显著区域并抽取其特征,作者充分利用了 CNN 不同 stage 输出的特征图的语义粒度信息,并使用 Jigsaw Puzzle Generator 进行数据增强来帮…...
Python推导式
列表(list)推导式 [remove for source in xx_list]或者[remove for source in xx_list if condition] 实例: names[Bob,Mark,Mausk,Johndan,Wendy] new_names[name.upper() for name in names if len(name)<5] print(new_names)即迭代列…...

Java列表List的定查改增删操作
Java列表List的定查改增删操作定义查找遍历元素与下标互查修改增加删除java.util中提供了三种常用的集合类,列表List、集合Map和字典Set。这些集合类相较于数组有更多功能,并且都可以通过Iterator(迭代器)来访问。 在这篇博客中&…...

day03java语言特性 JDK、JRE、JVM
1、Java语言的特性 1.1、简单性在Java语言当中真正操作内存的是:JVM(Java虚拟机)所有的java程序都是运行在Java虚拟机当中的。而Java虚拟机执行过程中再去操作内存。对于C或者C来说程序员都是可以直接通过指针操作内存的。C或者C更灵活&…...

HydroD 实用教程(二)有限元模型
目 录一、前言二、模型种类三、单元类型四、FEM文件五、参考文献一、前言 SESAM (Super Element Structure Analysis Module)是由挪威船级社(DNV-GL)开发的一款有限元分析(FEA)系统,它以 GeniE、…...

基于MCP协议的Windows桌面AI自动化控制:Copaw Control实战指南
1. 项目概述与核心价值最近在折腾AI智能体开发,特别是想让它们能更“听话”地操作我的电脑,比如帮我整理文件、截图、或者自动处理一些重复性的桌面任务。在这个过程中,我发现了tompaineclaw/copaw-control-mcp这个项目。简单来说,…...

第三方令牌泄露引发的供应链数据泄露治理研究 —— 以 Zara 事件为例
摘要 2026 年 4 月,黑客组织 ShinyHunters 通过入侵云分析服务商 Anodot 并窃取其身份认证令牌,非法访问下游多家企业云数据平台,导致快时尚品牌 Zara 近 19.7 万名用户信息泄露,泄露字段含电子邮箱、订单 ID、商品 SKU 及客服工单…...

如何让猫抓资源嗅探插件效率翻倍:5个实用配置技巧
如何让猫抓资源嗅探插件效率翻倍:5个实用配置技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)是一款功能强大的浏览…...

ExifToolGUI终极指南:告别繁琐,用图形界面批量管理照片元数据
ExifToolGUI终极指南:告别繁琐,用图形界面批量管理照片元数据 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾面对成百上千张照片,想要批量修改拍摄时间、统一添…...

AI自动化不是接工具就行,得补缺点搭轨道
你有没有过这种经历? 点了一杯定制奶茶,本来想着 “全自动机器做,我啥也不用管,等着拿就行”。 结果呢? 机器煮茶到一半,弹出来问你:“我要开始煮茶了哦,确认一下?” 加珍…...

3分钟让键盘操作在屏幕上“跳舞“:Keyviz完全指南 [特殊字符]
3分钟让键盘操作在屏幕上"跳舞":Keyviz完全指南 🎯 【免费下载链接】keyviz Keyviz is a free and open-source tool to visualize your keystrokes ⌨️ and 🖱️ mouse actions in real-time. 项目地址: https://gitcode.com/g…...

如何高效获取金融数据:Python通达信接口的完整指南
如何高效获取金融数据:Python通达信接口的完整指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,获取准确、及时且成本可控的市场数据一直…...
)
告别CNN!用PyG Temporal和GC-LSTM搞定动态社交网络的好友推荐(附完整代码)
动态社交网络好友推荐的工程实践:基于GC-LSTM与PyG Temporal的完整解决方案 社交网络的动态特性为传统推荐系统带来了巨大挑战。当用户关系每分每秒都在变化时,静态的协同过滤或内容推荐方法往往显得力不从心。本文将分享如何利用PyG Temporal库和GC-LST…...

AI应用安全新挑战:基于模糊测试的提示词注入漏洞自动化检测
1. 项目概述:当AI提示词成为攻击目标最近在跟几个做AI应用安全的朋友聊天,大家不约而同地提到了一个词:“提示词攻击”。听起来有点抽象,对吧?简单来说,就是有人不直接黑你的系统,而是通过精心构…...
Elsevier Tracker:科研工作者必备的智能投稿状态追踪工具
Elsevier Tracker:科研工作者必备的智能投稿状态追踪工具 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 作为科研工作者,您是否曾因频繁登录Elsevier投稿系统查看审稿进度而感到疲惫&#x…...