深度模型训练时CPU或GPU的使用model.to(device)
一、使用device控制使用CPU还是GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 单GPU或者CPU.先判断机器上是否存在GPU,没有则使用CPU训练
model = model.to(device)
data = data.to(device)#或者在确定有GPU的情况下,直接使用
model = model.cuda()
data = data.cuda()#在确定没有GPU的情况下,直接使用
model = model.cpu()
data = data.cpu()注意:
1.tensor和numpy都是矩阵,前者能在GPU上运行,后者只能在CPU运行,所以要注意数据类型的转换。
2.当你使用model.to(device)时,它会将模型的参数和缓冲区移动到指定的设备上。而当你使用model = model.to(device)时,它会将整个模型移动到指定的设备上。
二、.to(device)和.cuda()设置GPU的区别
建议使用model.to(device)的方式,这样可以显示指定需要使用的计算资源,特别是有多个GPU的情况下,可以并行处理,加快速度。
参考.to(device)和.cuda()设置GPU的区别_.cuda()和to(device)-CSDN博客
.to(device) 可以指定CPU 或者GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 单GPU或者CPU
model.to(device)
#如果是多GPU
if torch.cuda.device_count() > 1:model = nn.DataParallel(model,device_ids=[0,1,2])
model.to(device)
.cuda() 只能指定GPU
#指定某个GPU
os.environ['CUDA_VISIBLE_DEVICES']="1"
model.cuda()
#如果是多GPU
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1,2,3"
device_ids = [0,1,2,3]
net = torch.nn.Dataparallel(net, device_ids =device_ids)
net = torch.nn.Dataparallel(net) # 默认使用所有的device_ids
net = net.cuda()model.cuda()
#如果是多GPU
os.environment['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
device_ids = [0,1,2,3]
net = torch.nn.Dataparallel(net, device_ids =device_ids)
net = torch.nn.Dataparallel(net) # 默认使用所有的device_ids
net = net.cuda()
三、指定使用的GPU
使用方式
import os# 给服务器上的GPU编号
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3'# 指定要使用哪张卡
device_ids = [0, 1] #假设只用两张卡# 将模型搬到GPU上,并行化处理
model = torch.nn.DataParallel(model, device_ids=device_ids)
model = model.cuda()
# 或者直接
model = torch.nn.DataParallel(model, device_ids=device_ids).cuda()四、GPU利用率很低的可能原因分析
训练中GPU利用率很低4%,CPU利用率很高80%左右,原因分析:
(1)CPU性能不足,没有ssd加速;
(2)电脑只有一张显卡,无法并行训练model;——转移到服务器上多卡一起并行训练
(3)模型太复杂,要训练的参数多;——优化模型
(4)且Dataloader读入数据的时候numworks=0,单线程读入比较慢;——numworks=4,适当增大,观察GPU的提升,但CPU跑满就没法再继续增加了
(5)程序中每次迭代训练都采用日志保存所有的训练结果,频繁I/O读取;——先不记录,调好参数之后再训练时记录;
小结:主要考虑优化数据读取(I/O速度);数据传输;数据GPU上预处理;优化算法;调整硬件资源;
在不改变硬件条件的情况下,最能够努力的就是增加数据读取的进程,以及尽量把数据预处理操作能移到GPU上进行的就都移到GPU上。

GPU利用率低解决方案
跑深度学习模型的时候我的gpu利用率很低_mob64ca12d2a342的技术博客_51CTO博客
相关文章:
深度模型训练时CPU或GPU的使用model.to(device)
一、使用device控制使用CPU还是GPU device torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 单GPU或者CPU.先判断机器上是否存在GPU,没有则使用CPU训练 model model.to(device) data data.to(device)#或者在确定有GPU的…...
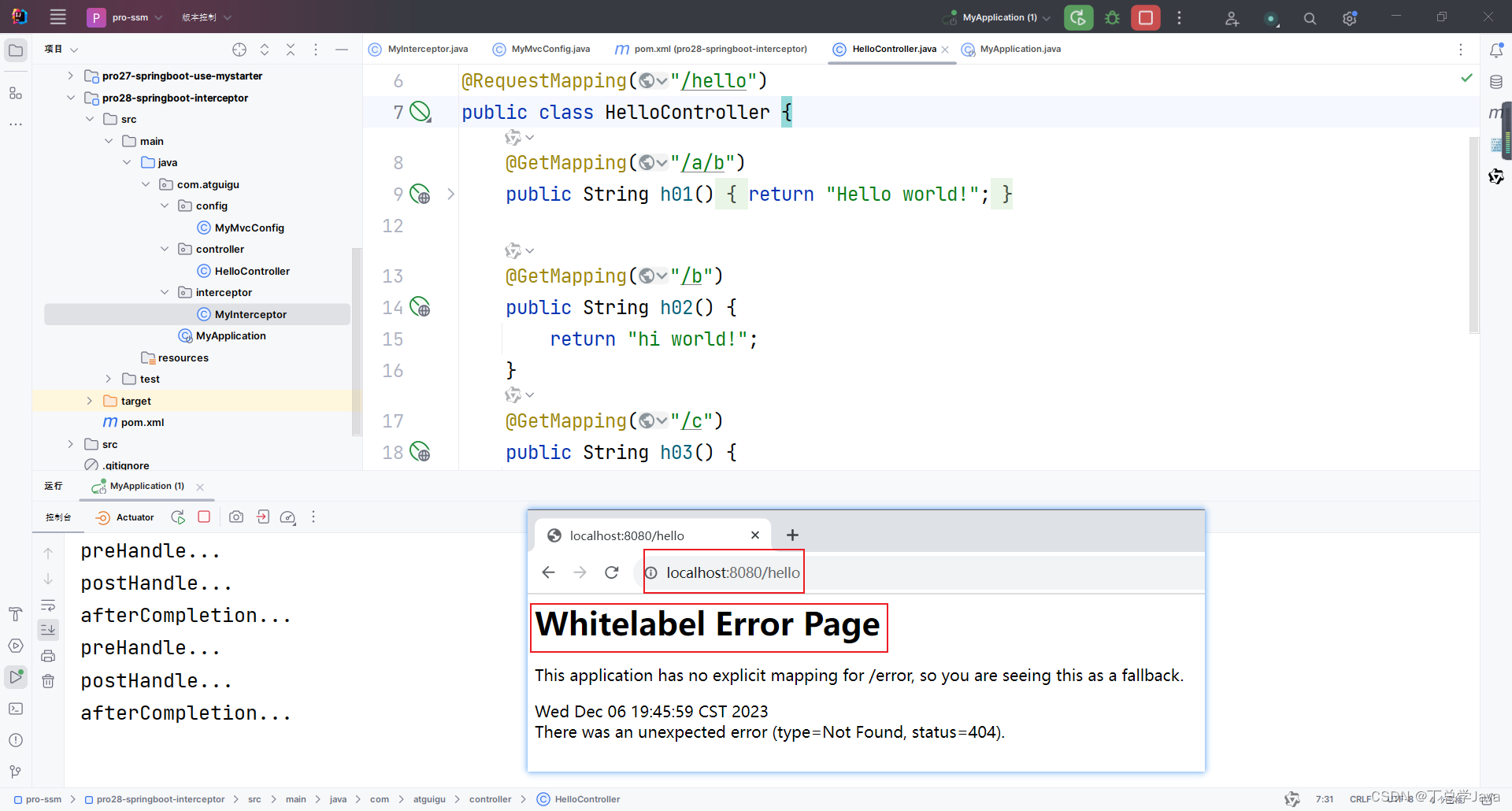
SpringBoot3-实现和注册拦截器
1、pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.…...

Ubuntu 22.04源码安装yasm 1.3.0
sudo lsb_release -r看到操作系统的版本是22.04,sudo uname -r可以看到内核版本是5.15.0-86-generic,sudo gcc --version可以看到版本是11.2.0,sudo make --version可以看到版本是GNU Make 4.3。 下载yasm http://yasm.tortall.net/Downlo…...

LeetCode [中等]矩阵置零
73. 矩阵置零 - 力扣(LeetCode) 暴力解法 用两个标记数组分别记录每一行和每一列是否有零出现。 遍历该数组一次,如果某个元素为 0,那么就将该元素所在的行和列所对应标记数组的位置置为 true。再次遍历该数组,用标…...

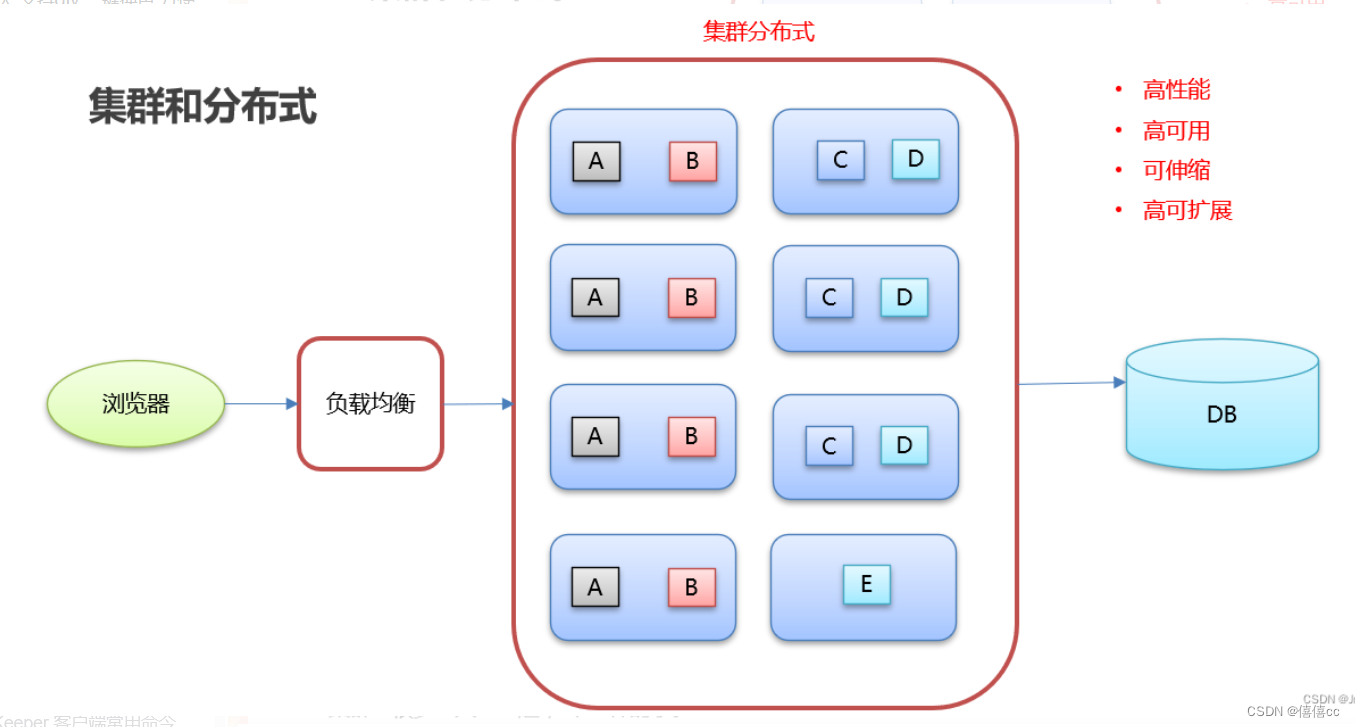
十一、了解分布式计算
1、什么是(数据)计算? 2、分布式(数据)计算 (1)概念 顾名思义,分布式计算,即以分布式的形式完成数据的统计,得到需要的结果。 分布式数据计算,顾名思义,就是…...

数据结构和算法专题---2、算法思想
上文讲到算法的概念、复杂度,本文给大家介绍具体的算法思想,让大家对算法设计理念有个认识,后续再分别介绍各种算法。 算法思想 算法是解决问题的一种思想和方法,其基本思想是将一个复杂问题分解为多个简单的子问题,…...

在AWS Lambda上部署标准FFmpeg工具——自定义层的方案
大纲 1 确定Lambda运行时环境1.1 Lambda系统、镜像、内核版本1.2 运行时1.2.1 Python1.2.2 Java 2 打包FFmpeg3 创建Lambda的Layer4 测试4.1 创建Lambda函数4.2 附加FFmpeg层4.3 添加测试代码4.4 运行测试 参考文献 FFmpeg被广泛应用于音/视频流处理领域。对于简单的需求&#…...

prometheus服务发现之consul
文章目录 前言一、Consul 在这里的作用二、原理三、实现过程安装 consul节点信息(exporter)注册进去consul节点信息(exporter)从consul解除注册:prometheus配置consul地址 总结 前言 我们平时使用 prometheus 收集监控…...

基于SSM的鞍山职业技术学院图书借阅管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SSM的鞍山职业技术学院图书借阅管理…...
分布式数据库HBase
文章目录 前言 一、HBase概述 1.1.1 什么是HBase HBase是一个分布式的、面向列的开源数据库HBase是Google BigTable的开源实现HBase不同于一般的关系数据库, 适合非结构化数据存储HBase是一种分布式、可扩展、支持海量数据存储的 NoSQL数据库。HBase是依赖Hadoop的。为什么HBa…...

快捷切换raw页面到repo页面-Raw2Repo插件
Raw2Repo By Rick 📖快捷切换代码托管平台raw页面到repo页面 🔗github链接 https://github.com/rickhqh/Raw2Repo ✨Features 功能: ✅单击 Raw2Repo 插件按钮,即可跳转到相应的代码仓库页面。✅支持 GitHub、Gitee、GitCode …...
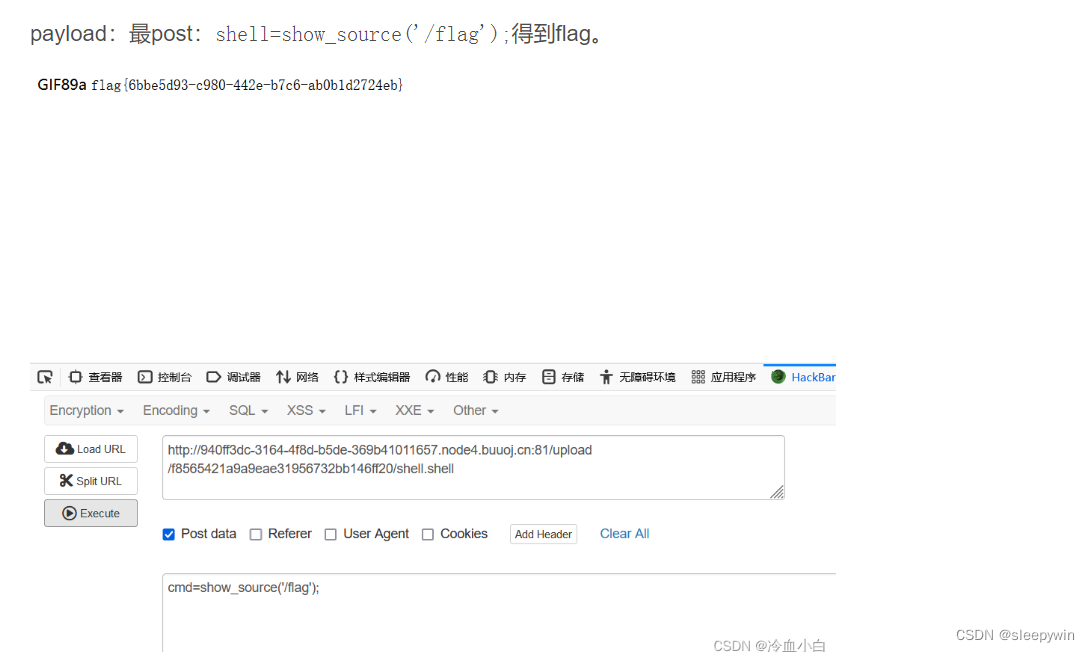
web:[GXYCTF2019]BabyUpload(文件上传、一句话木马、文件过滤)
题目 页面显示为文件上传 随便上传一个文件看看 上传一个文本文件显示 上传了一个图片显示 上传包含一句话木马的图片 上传了一个包含php一句话木马的文件,显示如上 换一个写法 上传成功 尝试上传.htaccess,上传失败,用抓包修改文件后缀 …...
)
C++ Div3、Sqrt 函数高性能实现(带汇编指令集)
均采用魔法数字(Magic Number)实现,一个是经典求平方根函数所使用的魔法数字:0x5f375a86、0x5f3759df。 float Sqrt(float x) noexcept { /* 0x5f3759df */float xhalf 0.5f * x;int32_t i *(int32_t*)&x;i 0x5f375a86 - …...
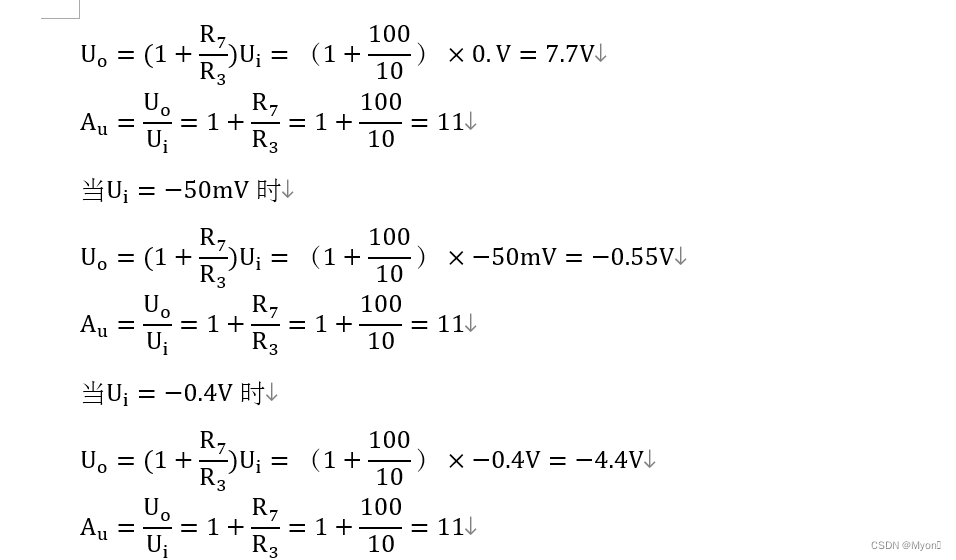
西南科技大学模拟电子技术实验四(集成运算放大器的线性应用)预习报告
一、计算/设计过程 说明:本实验是验证性实验,计算预测验证结果。是设计性实验一定要从系统指标计算出元件参数过程,越详细越好。用公式输入法完成相关公式内容,不得贴手写图片。(注意:从抽象公式直接得出结果,不得分,页数可根据内容调整) 反相比例运算电路(1)实验…...

【五分钟】学会利用cv2.resize()函数实现图像缩放
引言 在numpy知识库:深入理解numpy.resize函数和数组的resize方法中,小编较为详细地探讨了numpy的resize函数背后的机理。从结果来看,numpy.resize函数并不适合对图像进行缩放操作。而opencv中的resize函数虽然和numpy的resize函数同名&…...
vuepress-----18、图片缩放
图片引入两种方式 地址 # 图片缩放插件 # 实战 md文件引入图片 <img class"zoom-custom-imgs" :src"$withBase(/favicon.ico)" alt"favicon">安装配置插件 vuepress/medium-zoom: {selector: img.zoom-custom-imgs,},效果展示...

前端开发_移动Web+动画
平面转换 作用:为元素添加动态效果,一般与过渡配合使用 概念:改变盒子在平面内的形态(位移、旋转、缩放、倾斜) 平面转换又叫 2D 转换 平移 属性:transform: translate(X轴移动距离,Y轴移动…...

【Python】 生成二维码
创建了一个使用 python 创建二维码的程序。 下面是生成的程序的图像。 功能描述 输入网址(URL)。 输入二维码的名称。 当单击 QR 码生成按钮时,将使用 QRname 中输入的字符将 QR 码生成为图像。 程序代码 import qrcode import tkinterd…...

Qt与Sqlite3
操作流程: (1)与数据库连接 (2)进行增删改查操作 (3)关闭数据库 示例: 参考:Qt 操作SQLite数据库_qt sqlite数据库操作_houxian1103的博客-CSDN博客 再谈QSqlQuery::exec: database not open问题的解决_qt database not open-CSDN博客…...
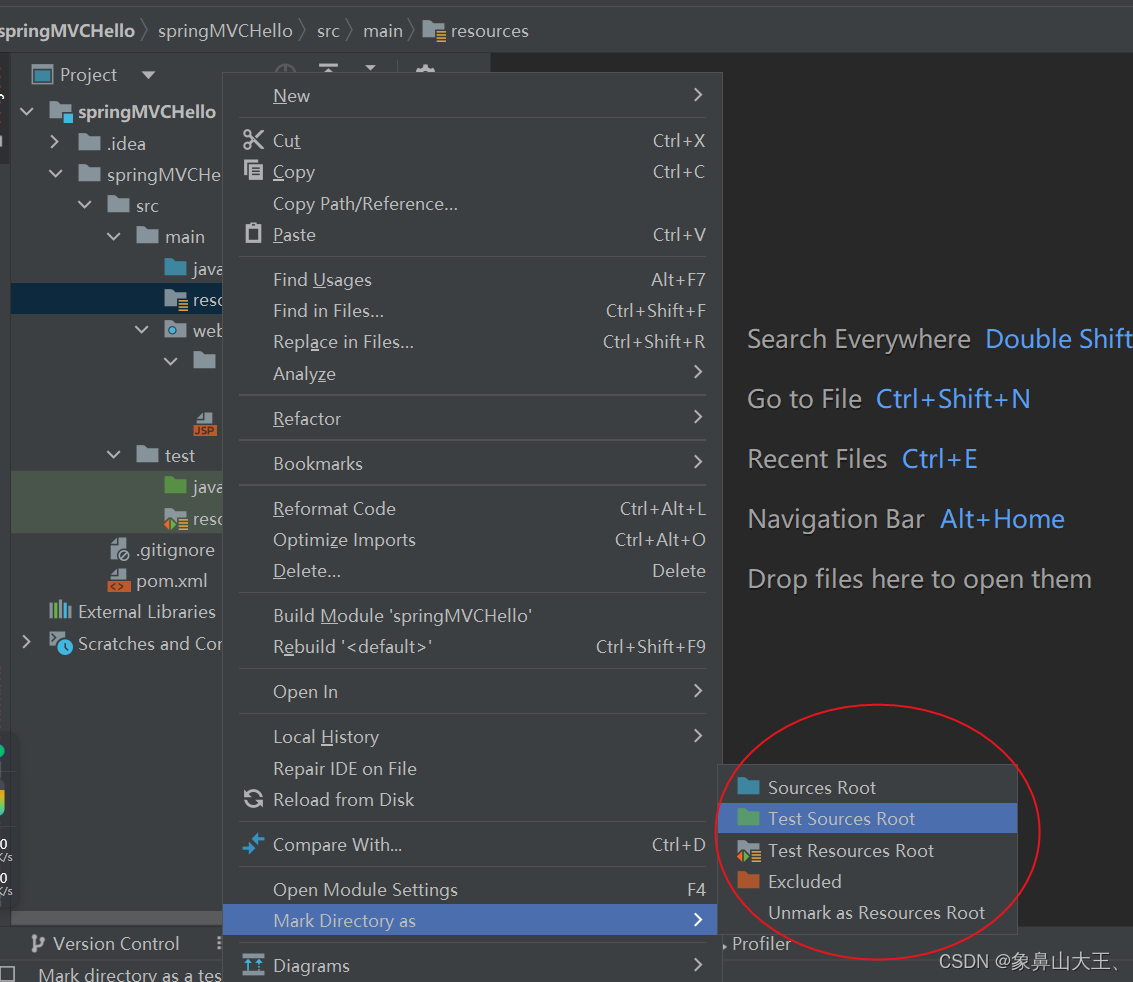
在idea中使用maven创建dynamic web project
1、先创建一个empty project 2、添加一个module , 核心是选择maven archetype webapp, 这个是maven提供的创建web工程的模版。 3、添加完等自动安装好即可 4、目录可能不完整 右键src---->点击New---->点击Directory (注意:这是笔者所缺失的结…...

Claude Code 接入 DeepSeek
安装 Claude Code DeepSeek 文档: 使用如下命令安装 Claude Code: npm install -g anthropic-ai/claude-code安装完成后,可以输入下面的命令检查是否安装成功。 claude --version购买 DeepSeek API 创建 Api Key 点击如下链接创建 DeepSeek API Ke…...
)
从HaGRID到自定义:手部关键点数据集标注、转换与可视化实战(Python代码)
从HaGRID到自定义:手部关键点数据集标注、转换与可视化实战(Python代码)在计算机视觉领域,手部关键点检测正逐渐成为人机交互、虚拟现实和手势识别等应用的核心技术。不同于简单的目标检测任务,手部关键点检测需要精确…...

告别卡顿:用微PE给旧电脑无损重装Win11,顺便教你用分区工具合理分配C盘空间
旧电脑焕新指南:用微PE无损重装Win11与智能分区实战 当你的旧电脑开始频繁卡顿、开机时间超过两分钟,甚至打开浏览器都要等待十几秒时,先别急着换新机。很多情况下,这只是系统长期使用积累的"垃圾"和不当分区导致的性能…...

前端可访问性:键盘导航的无障碍设计实践
前端可访问性:键盘导航的无障碍设计实践 前言 各位前端小伙伴,今天咱们来聊聊键盘导航的无障碍问题。想象一下: 你设计了一个漂亮的网站,所有交互都需要鼠标视力正常的用户觉得"交互流畅"但键盘用户完全无法使用视障用户…...

CSS伪类详解:从基础到高级应用
CSS伪类详解:从基础到高级应用 一、什么是CSS伪类 CSS伪类是一种选择器,用于选择处于特定状态的元素。它们以冒号 : 开头,可以为元素的不同状态设置不同的样式。伪类的强大之处在于它们能够根据用户交互、文档结构或元素状态来动态改变样式&a…...

每日热门skill:你的AI终于有“脑子“了!Memory MCP Server让Claude记住你的一切
告别"金鱼记忆",打造真正懂你的AI助手 一、开篇:那个让你崩溃的瞬间 你有没有遇到过这种情况? 昨天刚跟Claude说过:“我是做后端开发的,对Python比较熟悉,前端不太行。” 今天再问:“帮我写个React组件。” 它热情洋溢地回复:“好的!这是一个完整的全栈…...

【信息科学与工程学】计算机科学与自动化 ——第六十五篇 虚拟化/MIG 系列02
编号 类型 领域 虚拟化/MIG模式 算法名称 算法逐步推理思考的数学方程式及参数/常量/向量/常数/数字/数值列表 算法的时序数学方程式 关联知识 401 性能优化 GPU虚拟化+容器 MIG+容器 基于GPU内存带宽隔离的容器化AI训练任务调度算法 1. 带宽模型:每个MIG实例带宽…...

等保2.0三级Linux服务器合规基线重建实战指南
1. 为什么等保2.0整改不是“打补丁”,而是重装操作系统级的系统工程你刚接手一台跑了三年的CentOS 7服务器,业务跑得稳,监控没告警,运维日志里连个WARNING都少见——但等保测评报告第一页就写着:“操作系统未满足等保2…...

【限时公开】ChatGPT演讲稿写作的“三秒钩子公式”:前3秒抓住注意力,已助867位技术管理者拿下关键汇报
更多请点击: https://intelliparadigm.com 第一章:【限时公开】ChatGPT演讲稿写作的“三秒钩子公式”:前3秒抓住注意力,已助867位技术管理者拿下关键汇报 在技术汇报场景中,听众平均注意力窗口仅剩2.8秒——这是微软研…...

Pseudogen:让代码说人话,你的智能代码翻译官
Pseudogen:让代码说人话,你的智能代码翻译官 【免费下载链接】pseudogen A tool to automatically generate pseudo-code from source code. 项目地址: https://gitcode.com/gh_mirrors/ps/pseudogen 你是否曾面对一段复杂的代码,感觉…...