【PyTorch】模型训练过程优化分析
文章目录
- 1. 模型训练过程划分
- 1.1. 定义过程
- 1.1.1. 全局参数设置
- 1.1.2. 模型定义
- 1.2. 数据集加载过程
- 1.2.1. Dataset类:创建数据集
- 1.2.2. Dataloader类:加载数据集
- 1.3. 训练循环
- 2. 模型训练过程优化的总体思路
- 2.1. 提升数据从硬盘转移到CPU内存的效率
- 2.2. 提升CPU的运算效率
- 2.3. 提升数据从CPU转移到GPU的效率
- 2.4. 提升GPU的运算效率
- 3. 模型训练过程优化分析
- 3.1. 定义过程
- 3.2. 数据集加载过程
- 3.3. 训练循环
- 3.3.1. 训练模型
- 3.3.2. 评估模型
1. 模型训练过程划分
- 主过程在
__main__下。
if __name__ == '__main__':...
- 主过程分为定义过程、数据集配置过程和训练循环。
1.1. 定义过程
1.1.1. 全局参数设置
| 参数名 | 作用 |
|---|---|
num_epochs | 指定在训练集上训练的轮数 |
batch_size | 指定每批数据的样本数 |
num_workers | 指定加载数据集的进程数 |
prefetch_factor | 指定每个进程的预加载因子(要求num_workers>0) |
device | 指定模型训练使用的设备(CPU或GPU) |
lr | 学习率,控制模型参数的更新步长 |
1.1.2. 模型定义
| 组件 | 作用 |
|---|---|
writer | 定义tensorboard的事件记录器 |
net | 定义神经网络结构 |
net.apply(init_weights) | 模型参数初始化 |
criterion | 定义损失函数 |
optimizer | 定义优化器 |
1.2. 数据集加载过程
1.2.1. Dataset类:创建数据集
- 作用:定义数据集的结构和访问数据集中样本的方式。定义过程中通常需要读取数据文件,但这并不意味着将整个数据集加载到内存中。
- 如何创建数据集
- 继承Dataset抽象类自定义数据集
- TensorDataset类:通过包装张量创建数据集
1.2.2. Dataloader类:加载数据集
- 作用:定义数据集的加载方式,但这并不意味着正在加载数据集。
- 数据批量加载:将数据集分成多个批次(batches),并逐批次地加载数据。
- 数据打乱(可选):在每个训练周期(epoch)开始时,DataLoader会对数据集进行随机打乱,以确保在训练过程中每个样本被均匀地使用。
- 主要参数
参数 作用 dataset指定数据集 batch_size指定每批数据的样本数 shuffle=False指定是否在每个训练周期(epoch)开始时进行数据打乱 sampler=None指定如何从数据集中选择样本,如果指定这个参数,那么shuffle必须设置为False batch_sampler=None指定生成每个批次中应包含的样本数据的索引。与batch_size、shuffle 、sampler and drop_last参数不兼容 num_workers=0指定进行数据加载的进程数 collate_fn=None指定将一列表的样本合成mini-batch的方法,用于映射型数据集 pin_memory=False是否将数据缓存在物理RAM中以提高GPU传输效率 drop_last=False是否在批次结束时丢弃剩余的样本(当样本数量不是批次大小的整数倍时) timeout=0定义在每个批次上等待可用数据的最大秒数。如果超过这个时间还没有数据可用,则抛出一个异常。默认值为0,表示永不超时。 worker_init_fn=None指定在每个工作进程启动时进行的初始化操作。可以用于设置共享的随机种子或其他全局状态。 multiprocessing_context=None指定多进程数据加载的上下文环境,即多进程库 generator=None指定一个生成器对象来生成数据批次 prefetch_factor=2控制数据加载器预取数据的数量,默认预取比实际所需的批次数量多2倍的数据 persistent_workers=False控制数据加载器的工作进程是否在数据加载完成后继续存在
1.3. 训练循环
- 外层循环控制在训练集上训练的轮数
for epoch in trange(num_epochs):...
- 循环内部主要有以下模块:
- 训练模型
for X, y in dataloader_train:X, y = X.to(device), y.to(device)loss = criterion(net(X), y)optimizer.zero_grad()loss.mean().backward()optimizer.step()- 评估模型
- 每轮训练后在数据集上损失
- 每轮训练损失
- 每轮测试损失
- 每轮训练后在数据集上损失
def evaluate_loss(dataloader):"""评估给定数据集上模型的损失"""metric = d2l.Accumulator(2) # 损失的总和, 样本数量with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)loss = criterion(net(X), y)metric.add(loss.sum(), loss.numel())return metric[0] / metric[1]
2. 模型训练过程优化的总体思路
注意: 以下只区分变量、对象是在GPU还是在CPU内存中处理。实际处理过程使用的硬件是CPU、内存和GPU,其中CPU有缓存cache,GPU有显存。忽略具体的数据传输路径和数据处理设备。谈GPU包括GPU和显存,谈CPU内存包括CPU、缓存cache和内存。
| 主过程 | 子过程 | 追踪情况 |
|---|---|---|
| 定义过程 | 全局参数设置 | 变量的定义都是由CPU完成的 |
| 模型定义 |
| |
| 数据集配置过程 | —— | 对象的定义都是由CPU完成的 |
| 训练循环 | 训练模型 |
|
| 评估模型 |
|
由此,要提升硬件资源的利用率和训练效率,总体上有以下角度:
2.1. 提升数据从硬盘转移到CPU内存的效率
- 如果数据集较小,可以一次性读入CPU内存,之后注意要将
num_workers设置为0,由主进程加载数据集。否则会增加多余的过程(数据从CPU内存到CPU内存),而且随进程数num_workers增加而增加。 - 如果数据集很大,可以采用多进程读取,
num_workers设置为大于0的数,小于CPU内核数,加载数据集的效率随着进程数num_workers增加而增加;也随着预读取因子prefetch_factor的增加而增加,之后大致不变,因为预读取到了极限。 - 如果数据集较小,但是需要逐元素的预处理,可以采用多进程读取,以稍微增加训练时间为代价降低操作的复杂度。
2.2. 提升CPU的运算效率
2.3. 提升数据从CPU转移到GPU的效率
- 数据传输未准备好也传输(即非阻塞模式):
non_blocking=True - 将张量固定在CPU内存 :
pin_memory=True
2.4. 提升GPU的运算效率
- 使用自动混合精度(AMP,要求pytorch>=1.6.0):通过将模型和数据转换为低精度的形式(如FP16),可以显著减少GPU内存使用。
3. 模型训练过程优化分析
3.1. 定义过程
- 特点:每次程序运行只需要进行一次。
- 优化思路:将模型转移到GPU,同时
non_blocking=True。
3.2. 数据集加载过程
- 特点:只是定义数据加载的方式,并没有加载数据。
- 优化思路:合理设置数据加载参数,如
batch_size:一般取能被训练集大小整除的值。过小,则每次参数更新时所用的样本数较少,模型无法充分地学习数据的特征和分布,同时参数更新频繁,模型收敛速度提高,CPU到GPU的数据传输次数增加,CPU内存的消耗总量增加;过大,则每次参数更新时所用的样本数较多,模型性能更稳定,对GPU、CPU内存的单次消耗增加,对硬件配置要求更高,同时参数更新缓慢,模型收敛速度下降。num_workers:取小于CPU内核数的合适值,比如先取CPU内核数的一半。过小,则数据加载进程少,数据加载缓慢;过大,则数据加载进程多,对CPU要求高,同时也影响效率。pin_memory:当设置为True时,它告诉DataLoader将加载的数据张量固定在CPU内存中,使数据传输到GPU的过程更快。prefetch_factor:决定每次从磁盘加载多少个batch的数据到内存中,预先加载batch越多,在处理数据时,不会因为数据加载的延迟而影响整体的训练速度,同时可以让GPU在处理数据时保持忙碌,从而提高GPU利用率;过大,则会导致CPU内存消耗增加。
3.3. 训练循环
- 优化思路:
- 训练和评估过程分离或者减少评估的次数:模型从训练到评估需要进行状态切换,模型评估过程开销很大。
- 尽量使用非局部变量:减少变量、对象的创建和销毁过程
3.3.1. 训练模型
- 特点:训练结构固定
- 优化思路:
- 将数据转移到GPU,同时
non_blocking=True。 - 优化训练结构:比如使用自动混合精度:
from torch.cuda.amp import autocast, GradScalergrad_scaler = GradScaler() for epoch in range(num_epochs):start_time = time.perf_counter()for X, y in dataloader_train:X, y = X.to(device, non_blocking=True), y.to(device, non_blocking=True)with autocast():loss = criterion(net(X), y)optimizer.zero_grad()grad_scaler.scale(loss.mean()).backward()grad_scaler.step(optimizer)grad_scaler.update() - 将数据转移到GPU,同时
3.3.2. 评估模型
- 特点:评估结构固定
- 优化思路:
- 将数据转移到GPU,同时
non_blocking=True。 - 减少不必要的运算:比如梯度计算,即:
with torch.no_grad():... - 将数据转移到GPU,同时
相关文章:

【PyTorch】模型训练过程优化分析
文章目录 1. 模型训练过程划分1.1. 定义过程1.1.1. 全局参数设置1.1.2. 模型定义 1.2. 数据集加载过程1.2.1. Dataset类:创建数据集1.2.2. Dataloader类:加载数据集 1.3. 训练循环 2. 模型训练过程优化的总体思路2.1. 提升数据从硬盘转移到CPU内存的效率…...

GO -- 设计模式
整篇文档参考了各大神对设计模式的总结,然后整理的一篇关于使用GO来实现设计模式的文档,如有问题,请批评指正! 目录 设计模式的优点 设计模式的六大原则 设计模式,即Design Patterns,是指在软件设计…...
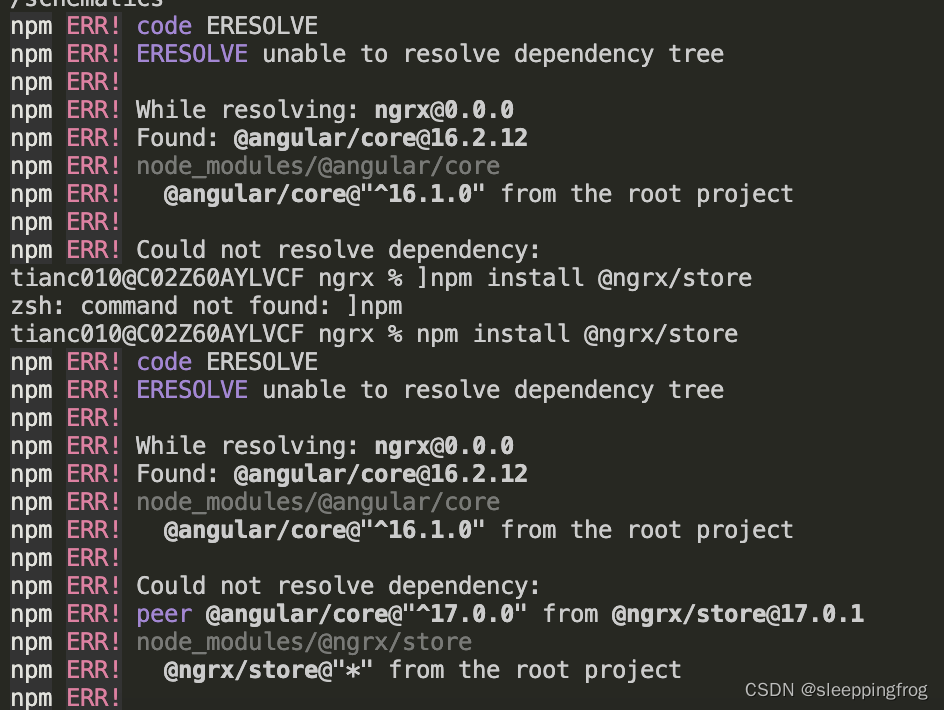
angular状态管理方案(ngrx)
完全基于redux的ngrx方案,我们看看在angular中如何实现。通过一个简单的计数器例子梳理下整个流程 一 安装 :npm i ngrx/store 这里特别要注意一点:安装 ngrx/store的时候会出现和angular版本不一致的问题 所以检查一下angular/core的版本…...

EPICS modbus 模块数字量读写练习
本文使用modbus slave软件模拟一个受控的modbus设备,此模拟设备提供如下功能: 1、线圈组1,8个线圈,起始地址为0,数量为8,软件设置如下(功能码1),用于测试功能码5,一次写一个线圈&am…...

万界星空科技低代码平台:搭建MES系统的优势
低代码MES系统:制造业数字化转型的捷径 随着制造业的数字化转型,企业对生产管理系统的需求逐渐提高。传统的MES系统实施过程复杂、成本高昂,已经无法满足现代企业的快速发展需求。而低代码搭建MES系统的出现,为企业提供了一种高…...

【ArcGIS微课1000例】0078:创建点、线、面数据的最小几何边界
本实例为专栏系统文章:讲述在ArcMap10.6中创建点数据最小几何边界(范围),配套案例数据,持续同步更新! 文章目录 一、工具介绍二、实战演练三、注意事项一、工具介绍 创建包含若干面的要素类,用以表示封闭单个输入要素或成组的输入要素指定的最小边界几何。 工具位于:数…...
 - 数据库索引损坏)
五花八门客户问题(BUG) - 数据库索引损坏
问题 曾经有个客户问题,让我们开发不知所措了很久。简单点说就是客户的index周期性的损坏,即使全部重建后经历大约1~2周数据update后也会坏掉。导致的直接结果:select出来的数据不对。问题很严重。 直接看损坏的index文件看不出什么蛛丝马迹…...

mysql select count 非常慢
MySQL select count 性能分析 问题:mysql 在count时发现非常慢 select count(*) from xxx; 无论执行多少次,查询速度基本稳定在10-12秒之间 环境说明 windows11 x64SSD硬盘MySQL8.0.35数据库引擎为InnoDB数据行数不到3万行,但是数据量将近…...
Tomcat管理功能使用
前言 Tomcat管理功能用于对Tomcat自身以及部署在Tomcat上的应用进行管理的web应用。在默认情况下是处于禁用状态的。如果需要开启这个功能,需要配置管理用户,即配置tomcat-users.xml文件。 !!!注意:测试功…...

kyuubi整合flink yarn session mode
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catlogsql测试 结束 概述 flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5 整合过程中,需要注意对应的版本。 注意以上版本 配置 ky…...
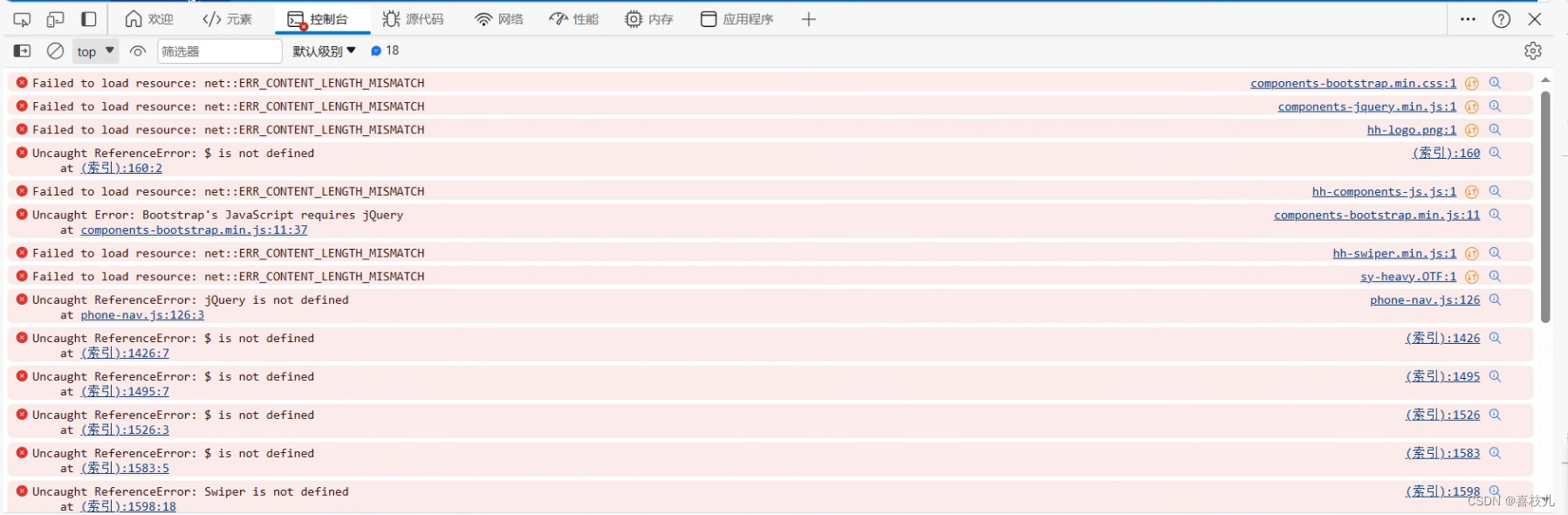
err_connect_length_mismatch错误
原因: 官网解释为:err_content_length_mismatch:错误的内容长度不匹配(请求的Heather 里content-length长度与返回的content-length不一致) 问题截图: 分析: 由截图可见,静态资源加载错误,提示err_content_length_mismatch,经排查,网络页签…...

dva的学习总结
公司的项目源码用的是react和dva,所以我必须抓紧时间学习一下dva了,一天时间,看看我学到了什么(dva官网DvaJS)[这是很久之前就打算写的了,一直没时间,一直存着草稿,今天发出来吧] 1…...

Docker部署.NET6项目
Docker的三大核心概念 1、docker仓库(repository) docker仓库(repository)类似于代码库,是docker集中存放镜像的场所。实际上,注册服务器是存放仓库的地方,其上往往存放着很多仓库。每个仓库集…...

Pandas 打开有密码的Excel
安装包 pip isntall msoffcrypto-tool msoffcrypto库的简单介绍 msoffcrypto提供了对Microsoft Office文件进行加密和解密的功能。它支持对Word、Excel和PowerPoint文件进行加密和解密操作。 msoffcrypto的原理是利用Microsoft Office文件的加密算法对文件进行加密和解密。它能…...

CCF 202104-2:邻域均值--C++
#include<iostream> #include<bits/stdc.h>using namespace std;int A[601][601]; int n;//长宽都为n个像素double FindNeighborSum(int i,int j,int r,int A[][601]) {int sum0;//像素和 int gs0;//领域 中的像素个数 for(int xi-r;x<ir;x)//找到每一个领域像素…...
基于JAVA+SpringBoot+Vue的前后端分离的医院信息智能化HIS系统
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着科技的不断发展&a…...

Kotlin Flow 操作符
前言 Kotlin 拥有函数式编程的能力,使用Kotlin开发,可以简化开发代码,层次清晰,利于阅读。 然而Kotlin拥有操作符很多,其中就包括了flow。Kotlin Flow 如此受欢迎大部分归功于其丰富、简洁的操作符,巧妙使…...
HarmonyOS4.0从零开始的开发教程08构建列表页面
HarmonyOS(六)构建列表页面 List组件和Grid组件的使用 简介 在我们常用的手机应用中,经常会见到一些数据列表,如设置页面、通讯录、商品列表等。下图中两个页面都包含列表,“首页”页面中包含两个网格布局ÿ…...

分布式环境下的session 共享-基于spring-session组件和Redis实现
1、问题概述 不是所有的项目都是单机模式的,当一个项目服务的局域比较广,用户体量比较大,数据量较大的时候,我们都会将项目部署到多台服务器上,这些个服务器都是分布在不同的区域,这样实现了项目的负载和并…...
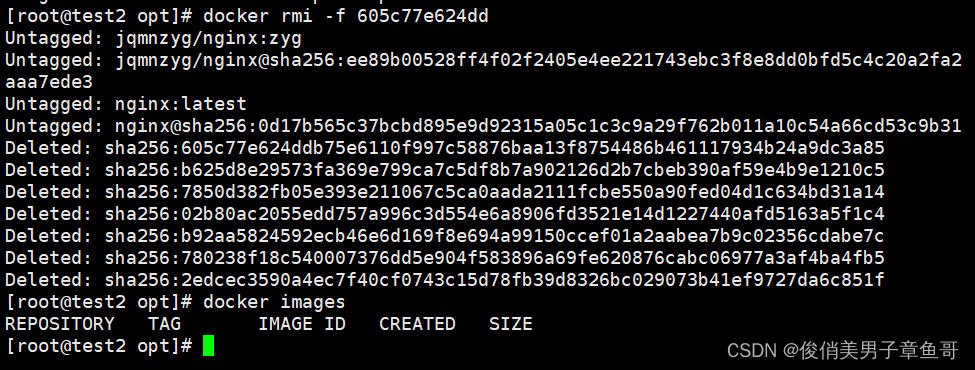
docker基本管理和相关概念
docker是什么? docker是开源的应用容器引擎。基于go语言开发的。运行在Linux系统当中开源轻量级的“虚拟机”。 docker的容器技术可以在一台主机上轻松的为任何应用创建一个轻量级的,可移植的,自给自足的容器。 docker的宿主机是Linux系统…...

QMcDump终极指南:三步解锁QQ音乐加密文件,实现音乐自由
QMcDump终极指南:三步解锁QQ音乐加密文件,实现音乐自由 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdum…...

81、CAN总线基础回顾:从诞生到经典架构
CAN总线基础回顾:从诞生到经典架构 去年冬天,我在调试一台农用机械的ECU通信时,遇到一个诡异现象:发动机转速数据偶尔跳变到65535,仪表盘直接显示“—”。用示波器抓波形,CAN_H和CAN_L的差分信号在总线空闲时居然有0.3V的直流偏置。排查了三天,最后发现是终端电阻焊盘虚…...

【Claude学术写作辅助应用】:教育部新文科AI赋能白皮书唯一推荐工具,附12所双一流高校实证数据
更多请点击: https://intelliparadigm.com 第一章:Claude学术写作辅助应用的政策定位与战略价值 Claude作为新一代大语言模型,在学术写作辅助领域已超越工具属性,成为支撑国家科研诚信建设、高等教育数字化转型与国际学术话语权提…...

显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南
显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...

CANN-NPU 显存回收策略:内存碎片整理与显存池化机制实战
一、显存碎片从哪来 1.1 碎片的两种形态 外部碎片——总空闲内存够用,但不连续。比如有 4 块 128MB 空闲,但需要一块 512MB 的连续内存,分配失败。 内部碎片——分配器按固定大小的块分配,实际使用的比分配的小。比如分配 400KB&a…...

CANN-HCCL-昇腾NPU分布式训练的通信库怎么选
8 卡 Atlas 800I A2 内部走 HCCS(带宽 200GB/s),跨机走 RoCE(带宽 100GB/s)。HCCL 是昇腾NPU的通信库,对标 NVIDIA 的 NCCL。Tensor Parallel 和 Pipeline Parallel 的 All-Reduce、All-to-All 都靠它。 HC…...

498元!某国产12代i7云终端小钢炮,仅1.7L迷你主机,可上i7-12700处理器,最大支持双M2+SATA三盘位,可惜还是准系统传家宝!
要说小主机品牌种类规格方面,最为丰富的不是个人家用消费级市场,而是云终端,痩客户机类型产品。奈何如今大环境不景气,再叠加如今处理器性能进步明显,以英特尔12代平台为例,如今依旧还是主流,所…...

PINNs赋能QSPR:将物理定律编译进分子性质预测模型
1. 这不是又一个黑箱模型:当物理规律成为神经网络的“硬约束”你有没有试过训练一个深度学习模型去预测某种新型有机分子的沸点,结果在训练集上R高达0.98,一拿到实验室刚测出来的5个新化合物数据,预测误差就飙到40℃?我…...

Unity低耦合可复用交互系统设计与实现
1. 为什么“交互系统”在Unity项目里总变成一锅粥?你有没有遇到过这样的场景:美术同事改了个按钮位置,UI脚本里硬编码的transform.Find("Button")就报空引用;策划临时加个新交互逻辑,程序员得翻遍PlayerCont…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan安装保姆级分享
2026年京东云OpenClaw/Hermes Agent配置Token Plan安装保姆级分享、OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具…...