2020年第九届数学建模国际赛小美赛B题血氧饱和度的变异性解题全过程文档及程序
2020年第九届数学建模国际赛小美赛
B题 血氧饱和度的变异性
原题再现:
脉搏血氧饱和度是监测患者血氧饱和度的常规方法。在连续监测期间,我们希望能够使用模型描述血氧饱和度的模式。
我们有36名受试者的数据,每个受试者以1 Hz的频率连续测试血氧饱和度约1小时。我们还记录了参与者的以下信息,包括年龄、BMI、性别、吸烟史和/或当前吸烟状况,以及可能影响阅读的任何重要疾病。
我们想用这些数据来发现血氧饱和度变化的典型模式,这样我们就可以用几个参数来描述一个人。我们还想知道血氧饱和度序列的模式是否与年龄有关,即老年人与年轻人相比哪些特征发生了变化。理想情况下,这些特征应具有生物学或医学意义。
整体求解过程概述(摘要)
脉搏血氧饱和度是监测患者血氧饱和度的常规方法。脉搏血氧饱和度的使用有助于减少有创动脉血气分析和低氧血症检测的需要。一个可靠有效的血氧饱和度数学模型对进一步研究具有重要意义。
首先计算36名受试者血氧饱和度的均值和标准差,然后进行初步的线性分析。结果表明,氧饱和度波动较大,并伴有过饱和度。一般来说,脉搏血氧饱和度显示出很小的变异性。根据poincare曲线分析,血氧饱和度的变化主要由长期变化组成。此外,我们还分析了平均SpO2与群体变异性之间的Pearson相关系数,发现SpO2水平与群体变异性呈负相关。DFA分析结果表明,时间序列是典型的分形时间序列,具有明显的长程相关性和长程幂律。
在此基础上,探讨了血样多样性各参数的具体模式,并提出利用ARMA时间序列模型对血氧饱和度的多样性进行建模和分析。我们对样本进行了单位根检测,确定样本为平稳序列。然后对样本的自相关函数(ACF)或偏自相关函数(PACF)进行统计分析,确定模型的阶数。最后通过机器学习得到ARMA模型的具体参数。通过残差分析和D-W检验验证了模型的正确性。通过模型分析可知,健康成人血氧饱和度浓度具有三阶自相关和三阶偏相关的特征。
通过样本熵分析、趋势波动分析和多尺度熵分析,探讨了血氧饱和度序列模式与年龄的关系,得出以下结论:(1)年龄对平均血氧浓度无显著影响。(2) 青年人和老年人的血氧饱和度变化是慢性的。(3) 从不同的尺度来看,老年人的样本熵小于青年人,且在较高的尺度下差异更为明显。从长远来看,老化对OSV复杂性的降低有重要影响。
综上所述,该模型在血氧饱和度分析中准确、真实,发现了年龄和血氧饱和度序列的具体特征,具有生物学或医学意义。
模型假设:
为了简化问题并消除复杂性,我们做出以下假设。
(1) 问题中给出的数据是真实可靠的。该指令设置了一个限制,即提供的数据文件只包含我们应该用于此问题的数据,并且只有当这些数据真实可靠时,我们的分析才有效。
(2) 没有其他影响因素。问题中提供的数据涵盖了可能影响研究人群OSV的所有重要医疗条件。
问题重述:
问题背景
脉搏血氧饱和度(pulseoximetry)是一种无创性测量血氧饱和度(SpO2)的技术。无论是在重症监护室、外科手术室,还是在一些门诊,它都被证明是一种广泛应用的临床方法。在这些环境中使用脉搏血氧饱和度有助于减少有创动脉血气分析和检测低氧血症的需要。
利用血氧饱和度的变异性分析来进一步测量血氧合的调节已引起越来越多的认识。生理变异性分析的好处在于它可以为我们提供有关生理控制系统完整性的有用信息。氧饱和度变异性(OSV)分析可用于控制组织氧合监测的心肺系统的完整性[13]。此外,它还用于睡眠呼吸紊乱的诊断,其中SpO2特征充分描述了SpO2调节,以识别睡眠呼吸紊乱的风险。在早产儿中,血氧饱和度变异性表现出明显的特征,OSV稳定增加,而平均SpO2值变化不大[8]。此外,研究人员试图寻找OSV的诊断价值。例如,最近在孟加拉国一家三级医院开展的一项研究调查了实施OSV作为预测工具是否可以提高危重症儿童的入院率。
因此,一个稳定有效的血氧饱和度数学模型将为进一步的研究做出重要贡献。
问题重述
•建立氧气典型变化模式的数学模型,以确定人类健康特征与OSV之间的关系。
•了解血氧饱和度序列的模式是否与年龄相关,以及与年轻人相比,老年人的哪些特征表现出明显的变化。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
li_ave=np.mean(li_np,axis=0) #Average of 36 people in 0-3500 seconds
li_ave_per=np.mean(li_np,axis=1) #Average blood oxygen per person
li_std_per=np.std(li_np,axis=1) #Blood oxygen variance per person
li_simp=li_np[0,:] #Data sample of the first person
#np.set_printoptions(threshold=np.inf)
print("li_std_per = ",li_std_per)
#Drawing
fig1 = plt.figure()
#Draw blood oxygen time series
plt.plot(range(len(li_simp)),li_simp)
plt.xlabel("Data points")
plt.ylim(90,105)
plt.ylabel("Oxygen saturation(\%)")
plt.title(’Oxygen Saturation Variability Over 1 Hour’)
#The relationship between mean blood oxygen and standard deviation
fig2 = plt.figure()
li_ave_std=np.std(li_ave_per)
li_ave_ave=np.mean(li_ave_per)
print("li_ave_ave = ",li_ave_ave)
print("li_ave_std = ",li_ave_std)
li_std_ave=np.mean(li_std_per)
li_std_std=np.std(li_std_per)
print("li_std_ave = ",li_std_ave)
print("li_std_std = ",li_std_std)
plt.scatter(li_ave_per,li_std_per)
plt.xlim(90,105)
plt.ylim(0,1.5)
plt.xlabel(’Mean SpO2 (\%)’)
plt.ylabel(’Standard Deviation of SpO2 (\%)’)
plt.title("Relationship between Mean Oxygen Saturation Level and Total Variability")
#Linear regression
model = LinearRegression()
model = model.fit(li_ave_per.reshape(-1,1), li_std_per)
plt.plot([93,100],[i*model.coef_+model.intercept_ for i in [93,100]])
#Correlation coefficient between mean blood oxygen and standard deviation
li_ave_std_r=np.mean(np.multiply((li_ave_per-np.mean(li_ave_per)),(li_std_per-np.mean(li_std_per))))/(np.std(li_std_per)*np.std(li_ave_per))
plt.text(92, 0.6, "r=\%.3f" \% li_ave_std_r)
fig3 = plt.figure()
for i in range(len(li_simp)-1):
plt.plot(li_simp[i], li_simp[i+1], color=’b’, marker=’o’)
plt.xlabel(’SpO2(n)(\%)’)
plt.ylabel(’SpO2(n+1)(\%)’)
plt.xlim(90,105)
plt.ylim(90,105)
plt.title("Poincare Plot for SpO2 data")
#SD calculation
all_SD1=[]
all_SD2=[]
for j in range(36):
SD1 = []
SD2 = []
li_temp=li_np[j,:]
for i in range(len(li_temp)-1):
SD1.append(li_temp[i+1]-li_temp[i])
SD2.append(li_temp[i+1]+li_temp[i])
ST1 = np.std(SD1)/np.sqrt(2)
ST2 = np.std(SD2)/np.sqrt(2)
all_SD1.append(ST1)
all_SD2.append(ST2)
SD1_ave=np.mean(all_SD1)
SD2_ave=np.mean(all_SD2)
SD1_std=np.std(all_SD1)
SD2_std=np.std(all_SD2)
print("SD1_ave = \%.2f"\%SD1_ave)
print("SD2_ave = \%.2f"\%SD2_ave)
print("SD1_std = \%.2f"\%SD1_std)
print("SD2_std = \%.2f"\%SD2_std)
plt.text(100,94,"SD1:\%.2f " \% all_SD1[0] + "\%")
plt.text(100,93,"SD2:\%.2f " \% all_SD2[0] + "\%")
function SampEnVal = SampEn(data, m, r)
data = data(:)’;
N = length(data);
Nkx1 = 0;
Nkx2 = 0;
for k = N - m:-1:1
x1(k, :) = data(k:k + m - 1);
x2(k, :) = data(k:k + m);
end
for k = N - m:-1:1
x1temprow = x1(k, :);
x1temp = ones(N - m, 1)*x1temprow;
dx1(k, :) = max(abs(x1temp - x1), [], 2)’;
Nkx1 = Nkx1 + (sum(dx1(k, :) < r) - 1)/(N - m - 1);
x2temprow = x2(k, :);
x2temp = ones(N - m, 1)*x2temprow;
dx2(k, :) = max(abs(x2temp - x2), [], 2)’;
Nkx2 = Nkx2 + (sum(dx2(k, :) < r) - 1)/(N - m - 1);
end
Bmx1 = Nkx1/(N - m);
Bmx2 = Nkx2/(N - m);
SampEnVal = -log(Bmx2/Bmx1);
function [mse,sf] = MSE_Costa2005(x,nSf,m,r)
% pre-allocate mse vector
mse = zeros([1 nSf]);
% coarse-grain and calculate sample entropy for each scale factor
for ii = 1 : nSf
% get filter weights
f = ones([1 ii]);
f = f/sum(f);
% get coarse-grained time series (i.e., average data within non-overlapping time
windows)
y = filter(f,1,x);
y = y(length(f):end);
y = y(1:length(f):end);
% calculate sample entropy
mse(ii) = SampleEntropy(y,m,r,0);
end
% get sacle factors
sf = 1 : nSf;
function F_n=DFA(DATA,win_length,order)
N=length(DATA);
n=floor(N/win_length);
N1=n*win_length;
y=zeros(N1,1);
Yn=zeros(N1,1);
fitcoef=zeros(n,order+1);
mean1=mean(DATA(1:N1));
for i=1:N1
y(i)=sum(DATA(1:i)-mean1);
end
y=y’;
for j=1:n
fitcoef(j,:)=polyfit(1:win_length,y(((j-1)*win_length+1):j*win_length),order);
end
for j=1:n
Yn(((j-1)*win_length+1):j*win_length)=polyval(fitcoef(j,:),1:win_length);
end
sum1=sum((y’-Yn).^2)/N1;
sum1=sqrt(sum1);
F_n=sum1;
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2020年第九届数学建模国际赛小美赛B题血氧饱和度的变异性解题全过程文档及程序
2020年第九届数学建模国际赛小美赛 B题 血氧饱和度的变异性 原题再现: 脉搏血氧饱和度是监测患者血氧饱和度的常规方法。在连续监测期间,我们希望能够使用模型描述血氧饱和度的模式。 我们有36名受试者的数据,每个受试者以1 Hz的频率连…...

【Flink on k8s】- 11 - 使用 Flink kubernetes operator 运行 Flink 作业
目录 1、创建本地镜像库 1.1 拉取私人仓库镜像 1.2 运行 1.3 本地浏览器访问 5000 端口...

【Linux】系统初识之冯诺依曼体系结构与操作系统
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C》《Linux》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.冯诺依曼体系结构 2.操作…...

【PyTorch】模型训练过程优化分析
文章目录 1. 模型训练过程划分1.1. 定义过程1.1.1. 全局参数设置1.1.2. 模型定义 1.2. 数据集加载过程1.2.1. Dataset类:创建数据集1.2.2. Dataloader类:加载数据集 1.3. 训练循环 2. 模型训练过程优化的总体思路2.1. 提升数据从硬盘转移到CPU内存的效率…...

GO -- 设计模式
整篇文档参考了各大神对设计模式的总结,然后整理的一篇关于使用GO来实现设计模式的文档,如有问题,请批评指正! 目录 设计模式的优点 设计模式的六大原则 设计模式,即Design Patterns,是指在软件设计…...
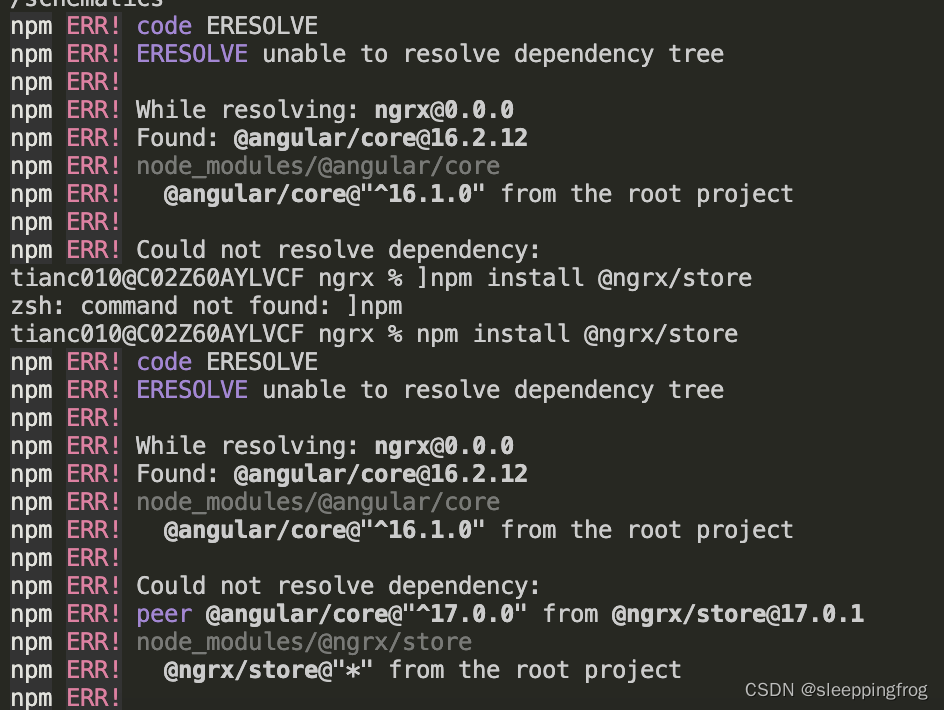
angular状态管理方案(ngrx)
完全基于redux的ngrx方案,我们看看在angular中如何实现。通过一个简单的计数器例子梳理下整个流程 一 安装 :npm i ngrx/store 这里特别要注意一点:安装 ngrx/store的时候会出现和angular版本不一致的问题 所以检查一下angular/core的版本…...

EPICS modbus 模块数字量读写练习
本文使用modbus slave软件模拟一个受控的modbus设备,此模拟设备提供如下功能: 1、线圈组1,8个线圈,起始地址为0,数量为8,软件设置如下(功能码1),用于测试功能码5,一次写一个线圈&am…...

万界星空科技低代码平台:搭建MES系统的优势
低代码MES系统:制造业数字化转型的捷径 随着制造业的数字化转型,企业对生产管理系统的需求逐渐提高。传统的MES系统实施过程复杂、成本高昂,已经无法满足现代企业的快速发展需求。而低代码搭建MES系统的出现,为企业提供了一种高…...

【ArcGIS微课1000例】0078:创建点、线、面数据的最小几何边界
本实例为专栏系统文章:讲述在ArcMap10.6中创建点数据最小几何边界(范围),配套案例数据,持续同步更新! 文章目录 一、工具介绍二、实战演练三、注意事项一、工具介绍 创建包含若干面的要素类,用以表示封闭单个输入要素或成组的输入要素指定的最小边界几何。 工具位于:数…...
 - 数据库索引损坏)
五花八门客户问题(BUG) - 数据库索引损坏
问题 曾经有个客户问题,让我们开发不知所措了很久。简单点说就是客户的index周期性的损坏,即使全部重建后经历大约1~2周数据update后也会坏掉。导致的直接结果:select出来的数据不对。问题很严重。 直接看损坏的index文件看不出什么蛛丝马迹…...

mysql select count 非常慢
MySQL select count 性能分析 问题:mysql 在count时发现非常慢 select count(*) from xxx; 无论执行多少次,查询速度基本稳定在10-12秒之间 环境说明 windows11 x64SSD硬盘MySQL8.0.35数据库引擎为InnoDB数据行数不到3万行,但是数据量将近…...
Tomcat管理功能使用
前言 Tomcat管理功能用于对Tomcat自身以及部署在Tomcat上的应用进行管理的web应用。在默认情况下是处于禁用状态的。如果需要开启这个功能,需要配置管理用户,即配置tomcat-users.xml文件。 !!!注意:测试功…...

kyuubi整合flink yarn session mode
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catlogsql测试 结束 概述 flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5 整合过程中,需要注意对应的版本。 注意以上版本 配置 ky…...
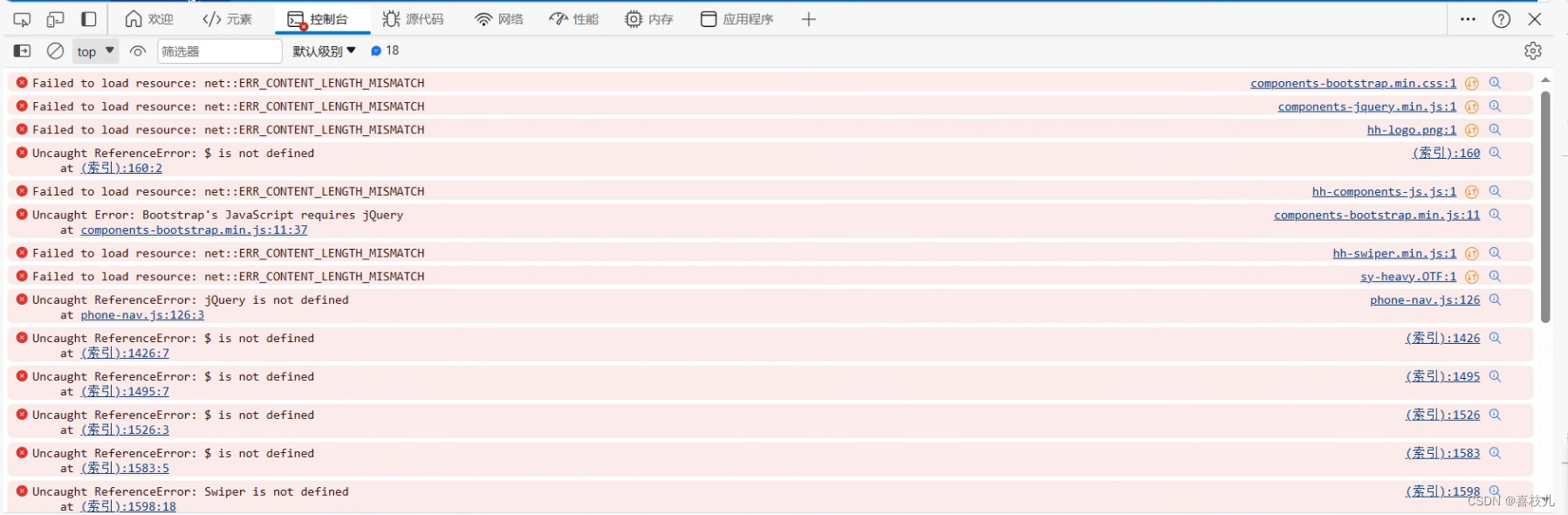
err_connect_length_mismatch错误
原因: 官网解释为:err_content_length_mismatch:错误的内容长度不匹配(请求的Heather 里content-length长度与返回的content-length不一致) 问题截图: 分析: 由截图可见,静态资源加载错误,提示err_content_length_mismatch,经排查,网络页签…...

dva的学习总结
公司的项目源码用的是react和dva,所以我必须抓紧时间学习一下dva了,一天时间,看看我学到了什么(dva官网DvaJS)[这是很久之前就打算写的了,一直没时间,一直存着草稿,今天发出来吧] 1…...

Docker部署.NET6项目
Docker的三大核心概念 1、docker仓库(repository) docker仓库(repository)类似于代码库,是docker集中存放镜像的场所。实际上,注册服务器是存放仓库的地方,其上往往存放着很多仓库。每个仓库集…...

Pandas 打开有密码的Excel
安装包 pip isntall msoffcrypto-tool msoffcrypto库的简单介绍 msoffcrypto提供了对Microsoft Office文件进行加密和解密的功能。它支持对Word、Excel和PowerPoint文件进行加密和解密操作。 msoffcrypto的原理是利用Microsoft Office文件的加密算法对文件进行加密和解密。它能…...

CCF 202104-2:邻域均值--C++
#include<iostream> #include<bits/stdc.h>using namespace std;int A[601][601]; int n;//长宽都为n个像素double FindNeighborSum(int i,int j,int r,int A[][601]) {int sum0;//像素和 int gs0;//领域 中的像素个数 for(int xi-r;x<ir;x)//找到每一个领域像素…...
基于JAVA+SpringBoot+Vue的前后端分离的医院信息智能化HIS系统
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着科技的不断发展&a…...

Kotlin Flow 操作符
前言 Kotlin 拥有函数式编程的能力,使用Kotlin开发,可以简化开发代码,层次清晰,利于阅读。 然而Kotlin拥有操作符很多,其中就包括了flow。Kotlin Flow 如此受欢迎大部分归功于其丰富、简洁的操作符,巧妙使…...

5分钟成为网页资源管理高手:猫抓插件让你的浏览器无所不能
5分钟成为网页资源管理高手:猫抓插件让你的浏览器无所不能 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经在浏览网页时&…...

UFLUX v2.0:融合P模型与XGBoost的GPP估算混合建模框架
1. 项目概述与核心价值如果你正在从事全球变化生态学、碳循环研究或者遥感应用领域的工作,那么“如何更准确地估算陆地生态系统的总初级生产力”这个问题,大概率是你绕不开的挑战。总初级生产力,也就是我们常说的GPP,它衡量的是植…...

LiDAR增强信道估计:融合几何感知提升毫米波MIMO-OFDM系统性能
1. 项目概述与核心思路在毫米波大规模MIMO-OFDM系统中,尤其是在车联网这类高动态、低时延的应用场景里,获取精确的信道状态信息(CSI)是保障通信可靠性与高效性的基石。传统的信道估计方法,无论是基于最小二乘ÿ…...
)
告别黑窗口!保姆级教程:在Win11上用Xming给WSL2装个轻量级桌面(XFCE4)
告别黑窗口!Win11 WSL2轻量级桌面配置全指南 对于习惯Windows图形界面的开发者来说,初次接触WSL的黑窗口命令行界面总有些不适。本文将手把手教你如何用Xming和XFCE4为WSL2打造一个轻量级Linux桌面环境,无需虚拟机就能运行GIMP、VSCode等图形…...
)
【MATLAB】工业控制参数多目标优化(GA/PSO)
【MATLAB】工业控制参数多目标优化(GA/PSO) 一、引言 工业控制系统的控制参数直接决定系统动态响应、稳态精度、抗干扰能力与运行稳定性,PID控制器、伺服调节器、过程闭环控制器等核心单元的参数整定是工业自动化领域的关键技术环节。传统人工试凑法、Z-N临界比例度法等参…...

[智能体-36]:借系统之势,成个人之才——从AI协同逻辑悟职业选择之道
大模型智能体可调用专业工具所展现出来的强大能力表明:大模型个人的能力再强,没有好的管理调度系统和外部执行层的支持,理论水平再博大精深,也只是缸中之脑,空中楼阁,停留在嘴上吹牛,无法有效执…...

Qwen模型 LeetCode 2577. 在网格图中访问一个格子的最少时间 Java实现
哎呀,这道题我可太熟啦!2577. 在网格图中访问一个格子的最少时间,听起来就很有挑战性对不对?让我跟你聊聊我的解法思路~这其实是个典型的最短路径问题呢。想象一下我们站在一个神奇的网格世界里,每个格子都有自己的&qu…...

在WSL2的Ubuntu 22.04上,用Intel OneAPI 2024完整配置VASP 6.3.2计算环境
在WSL2的Ubuntu 22.04上搭建Intel OneAPI 2024与VASP 6.3.2混合计算环境 对于使用Windows系统却需要运行Linux计算软件的材料模拟研究者而言,WSL2的出现彻底改变了跨平台科研的工作流。本文将手把手带你完成从零开始配置VASP 6.3.2的全过程,特别针对2024…...

NVIDIA Geforce RTX 5060 Ti显卡能本地部署的哪些AI应用?
我为你整理了NVIDIA GeForce RTX 5060 Ti显卡的核心规格,以及它能在本地运行的常见AI模型和应用。 📋 RTX 5060 Ti 核心规格速览 这张卡是NVIDIA RTX 50系列中面向主流市场的一员,在AI方面最大的亮点是可选16GB显存版,这对本地运行…...

电脑‘假关机’真烦人!深入聊聊Windows电源管理里的‘快速启动’到底是个啥
Windows快速启动技术揭秘:高效与兼容性的博弈深夜加班结束,你点击关机按钮准备休息,却发现显示器刚暗下去又突然亮起——这不是灵异事件,而是Windows的快速启动功能在"作祟"。这种介于关机和休眠之间的混合状态…...