Spring Boot 整合kafka:生产者ack机制和消费者AckMode消费模式、手动提交ACK
目录
- 生产者ack机制
- 消费者ack模式
- 手动提交ACK
生产者ack机制
Kafka 生产者的 ACK 机制指的是生产者在发送消息后,对消息副本的确认机制。ACK 机制可以帮助生产者确保消息被成功写入 Kafka 集群中的多个副本,并在需要时获取确认信息。
Kafka 提供了三种 ACK 机制的配置选项,分别是:
-
acks=0:生产者在成功将消息发送到网络缓冲区后即视为消息已被提交,不等待任何服务器响应。这种配置下,可能会出现消息丢失的情况。
-
acks=1:生产者在成功将消息发送到主题的分区 leader 后即视为消息已被提交。这种配置下,生产者会收到分区 leader
的确认,但仍有可能出现消息丢失的情况,例如当 leader 出现故障,而消息尚未复制到其他副本时。 -
acks=all 或acks=-1:生产者需要等待所有分区副本都成功写入消息后才视为消息已被提交。这种配置下,生产者会等待所有分区副本的确认,确保消息被复制到足够数量的副本后才返回提交确认。这是最安全的确认方式,但也会导致较长的等待时间。
在实际使用中,根据对消息可靠性和延迟的要求,可以选择不同的 ACKs 级别。一般来说,如果对消息的可靠性要求较高,可以选择较高的 ACKs 级别,但需要考虑相应的延迟成本。
我们可以通过spring.kafka.producer.acks来配置ack机制
spring.kafka.producer.acks=1
消费者ack模式
kafka支持的消费模式,在AbstractMessageListenerContainer.AckMode的枚举中,下面就介绍下各个模式的区别
public enum AckMode {/*** Commit after each record is processed by the listener.*/RECORD,/*** Commit whatever has already been processed before the next poll.*/BATCH,/*** Commit pending updates after* {@link ContainerProperties#setAckTime(long) ackTime} has elapsed.*/TIME,/*** Commit pending updates after* {@link ContainerProperties#setAckCount(int) ackCount} has been* exceeded.*/COUNT,/*** Commit pending updates after* {@link ContainerProperties#setAckCount(int) ackCount} has been* exceeded or after {@link ContainerProperties#setAckTime(long)* ackTime} has elapsed.*/COUNT_TIME,/*** User takes responsibility for acks using an* {@link AcknowledgingMessageListener}.*/MANUAL,/*** User takes responsibility for acks using an* {@link AcknowledgingMessageListener}. The consumer* immediately processes the commit.*/MANUAL_IMMEDIATE,}AckMode模式
RECORD:当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
当使用 RECORD 确认模式时,消息监听容器会在每个消息被单独处理后进行确认。这意味着,如果一条消息被成功处理,它将作为单独的记录进行确认;如果处理失败,也会针对该消息进行错误记录。这种确认模式适用于需要精确处理每个消息的应用场景,例如确保每个消息都被正确处理。
BATCH:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
当使用 BATCH 确认模式时,消息监听容器会在批量处理一组消息后进行确认。这意味着,消息监听容器会将多个消息合并为批次,并将它们作为一组进行处理。只有在整个批次都被成功处理后,该批次的所有消息才会被确认。这种确认模式适用于需要提高处理效率的场景,例如批量处理大量消息以减少网络传输和系统调用的开销。
TIME:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
COUNT:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
COUNT_TIME:TIME或COUNT 有一个条件满足时提交
MANUAL:这是手动确认模式,消费者需要显式地调用 Acknowledgment.acknowledge() 方法来确认消息。只有当消费者调用 acknowledge() 方法后,才会向 Kafka 服务器发送确认消息。这种模式可以保证消息的可靠性和顺序性,但需要消费者显式地处理确认逻辑。
MANUAL_IMMEDIATE:这是立即手动确认模式,与 MANUAL 模式类似,但消费者在调用 acknowledge() 方法时,会立即向 Kafka 服务器发送确认消息。这种模式可以提高消息处理的速度,但可能会增加重复消费的风险。
MANUAL和MANUAL_IMMEDIATE的区别
MANUAL 和 MANUAL_IMMEDIATE 都是 Kafka 消费者的手动确认模式,它们的区别在于确认的时机不同。
MANUAL 模式下,消费者需要显式地调用 Acknowledgment.acknowledge() 方法来确认消息,在调用该方法之后,消息才会被标记为已消费,并且确认消息会在下次 poll() 时发送到 Kafka 服务器。这种模式的优点是可以保证消息的可靠性和顺序性,但需要消费者显式地处理确认逻辑。
相比之下,MANUAL_IMMEDIATE 模式下,在消费者调用 Acknowledgment.acknowledge() 方法时,会立即向 Kafka 服务器发送确认消息。这种模式可以提高消息处理的速度,但可能会增加重复消费的风险,因为如果消息处理失败,Kafka 不会再次发送该消息,而是认为该消息已经被成功消费了。
在实际使用中,应根据业务需求和性能要求来选择合适的确认模式。如果要求消息的可靠性和顺序性比较高,可以选择 MANUAL 模式;如果要求处理速度比较高,可以选择 MANUAL_IMMEDIATE 模式。
AckMode 可以通过配置文件或代码进行设置。例如,在 Spring Boot 应用中,可以使用以下配置方式指定确认模式:
spring.kafka.listener.ack-mode=manual_immediate
手动提交ACK
kafka默认是自动提交ack的,很多时候,我们都需要手动提交,这就要进行以下配置
1、设置enable-auto-commit=false,禁止自动提交
2、设置ack-mode为manual_immediate
在配置文件进行如下配置
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.listener.ack-mode=manual_immediate
3、监听方法的入参加入Acknowledgment ack 参数,并在消费完成之后调用acknowledge方法,如下所示
@KafkaListener(topics = "my-topic2",groupId = "myGroup")public void receiveMessage2(String message, Acknowledgment ack){log.info("消费消息:"+message);//ack确认ack.acknowledge();}
相关文章:

Spring Boot 整合kafka:生产者ack机制和消费者AckMode消费模式、手动提交ACK
目录 生产者ack机制消费者ack模式手动提交ACK 生产者ack机制 Kafka 生产者的 ACK 机制指的是生产者在发送消息后,对消息副本的确认机制。ACK 机制可以帮助生产者确保消息被成功写入 Kafka 集群中的多个副本,并在需要时获取确认信息。 Kafka 提供了三种…...

Java+Swing: 主界面组件布局 整理9
说明:这篇博客是在上一篇的基础上的,因为上一篇已经将界面的框架搭好了,这篇主要是将里面的组件完善。 分为三个部分,北边的组件、中间的组件、南边的组件 // 放置北边的组件layoutNorth(contentPane);// 放置中间的 Jtablelayou…...
pytorch:YOLOV1的pytorch实现
pytorch:YOLOV1的pytorch实现 注:本篇仅为学习记录、学习笔记,请谨慎参考,如果有错误请评论指出。 参考: 动手学习深度学习pytorch版——从零开始实现YOLOv1 目标检测模型YOLO-V1损失函数详解 3.1 YOLO系列理论合集(Y…...

YOLOv8配置文件yolov8.yaml解读
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 位置 该文件的位置位于 ./ultralytics/cfg/models/v8/yolov8.yaml 模型参数配置 # Parameters nc: 80 # number of classes scales: #…...

4-Tornado高并发原理
核心原理就是协程epoll事件循环,再使用协程之后,开销是特别的小,那具体如何提供高并发的呢? 异步非阻塞IO 这意味我们整套开发的模式不在与原来一样,正因为不再一样,所以有时我们在理解代码时就有可能会比…...
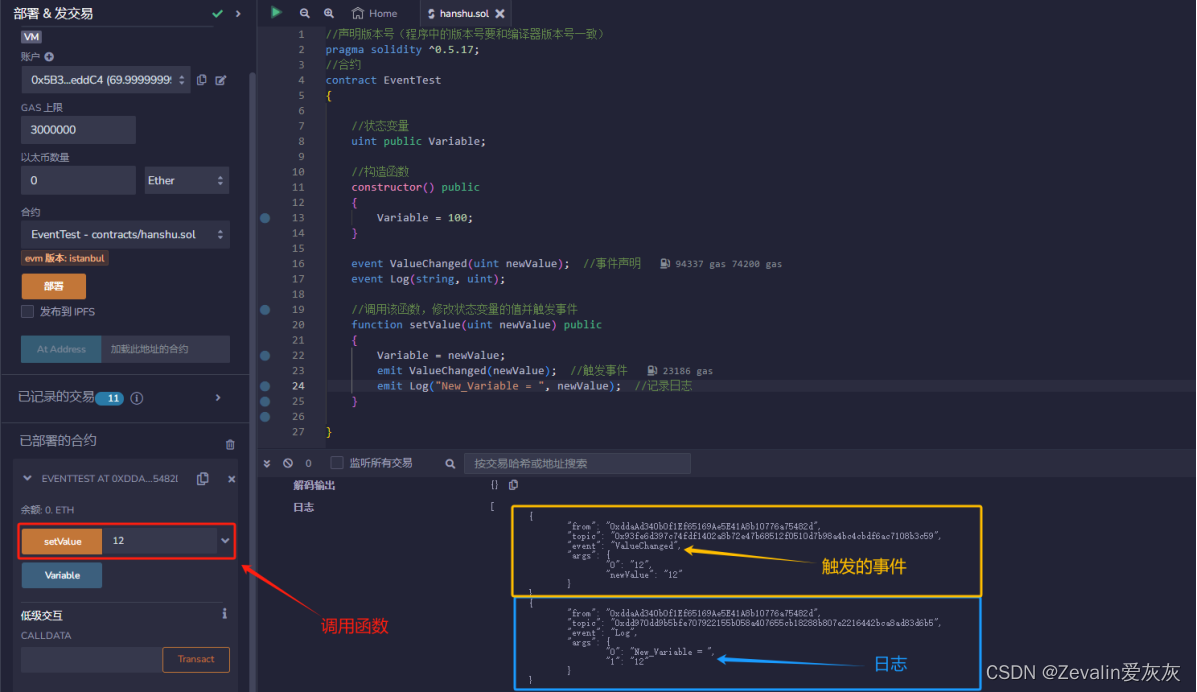
基于以太坊的智能合约开发Solidity(事件日志篇)
//声明版本号(程序中的版本号要和编译器版本号一致) pragma solidity ^0.5.17; //合约 contract EventTest {//状态变量uint public Variable;//构造函数constructor() public{Variable 100;}event ValueChanged(uint newValue); //事件声明event Log(…...
【BME2112】w11 notes
下周做老鼠实验 group analysis SPM group analysis 数据地址resting state 可以分析:correlation 计算两个脑区的相关性 静息态实验简单functional 成功的实验能看到激活区不成功的实验:比如被试头动太大,不是健康的被试 Spontaneous brain…...
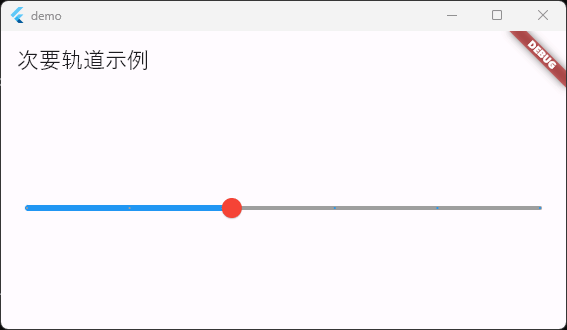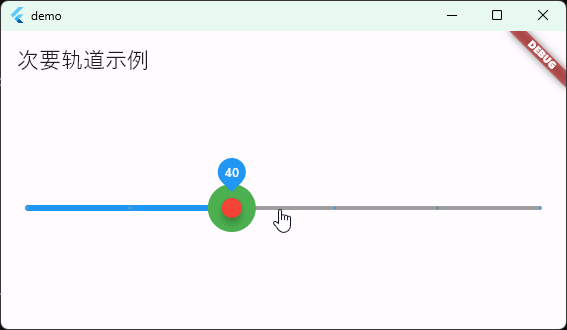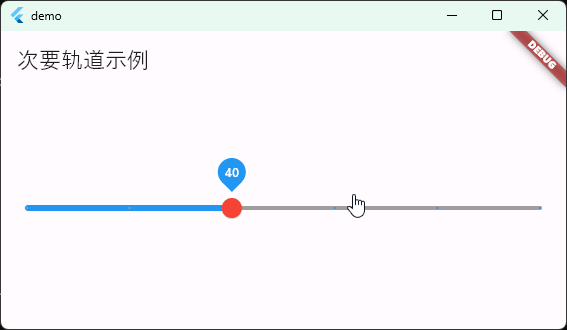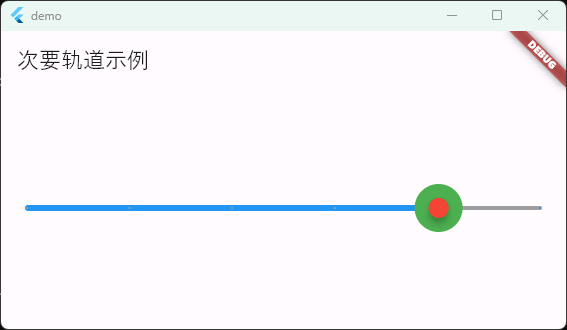
Flutter笔记:滑块及其实现分析1
Flutter笔记 滑块分析1 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134900784 本文从设计角度&#…...
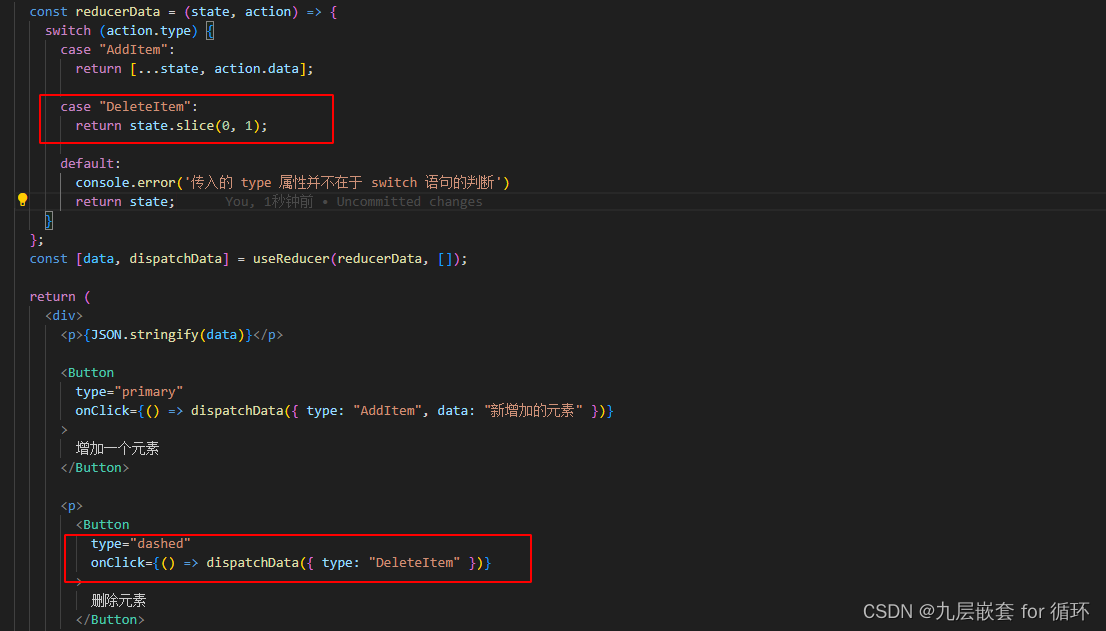
【React Hooks】useReducer()
useReducer 的三个参数是可选的,默认就是initialState,如果在调用的时候传递第三个参数那么他就会改变为你传递的参数,实际开发不建议这样写。会增加代码的不可读性。 使用方法: 必须将 useReducer 的第一个参数(函数…...

如何把kubernetes pod中的文件拷贝到宿主机上或者把宿主机上文件拷贝到kubernetes pod中
1. 创建一个 Kubernetes Pod 首先,下面是一个示例Pod的定义文件(pod.yaml): cat > nginx.yaml << EOF apiVersion: v1 kind: Pod metadata:name: my-nginx spec:containers:- name: nginximage: nginx EOF kubectl app…...
- ACodec(二))
Android 13 - Media框架(20)- ACodec(二)
这一节开始我们就来学习 ACodec 的实现 1、创建 ACodec ACodec 是在 MediaCodec 中创建的,这里先贴出创建部分的代码: mCodec mGetCodecBase(name, owner);if (mCodec NULL) {ALOGE("Getting codec base with name %s (owner%s) failed", n…...
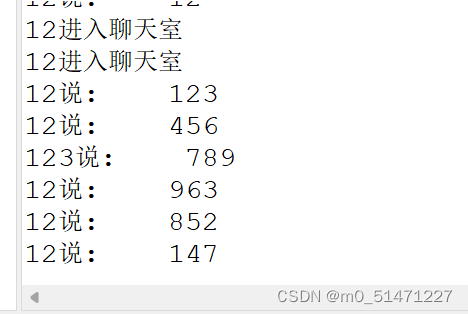
TCP单聊和UDP群聊
TCP协议单聊 服务端: import java.awt.BorderLayout; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.ServerSocket; import java.net.Socket; import java.util.V…...

智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.鲸鱼算法4.实验参数设定5.算法结果6.参考文献7.MA…...
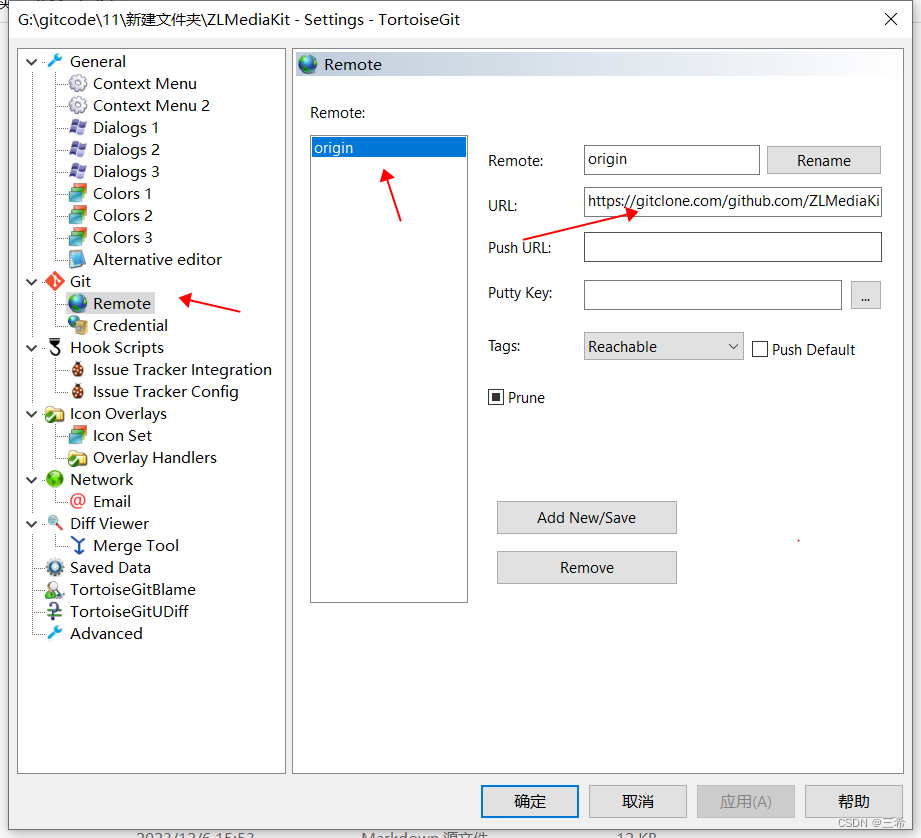
TortoiseGit 小乌龟svn客户端软件查看仓库地址
进入代码路径...

uniapp微信小程序分包,小程序分包
前言,都知道我是一个后端开发、所以今天来写一下uniapp。 起因是美工给我的切图太大,微信小程序不让了,在网上找了一大堆分包的文章,我心思我照着写的啊,怎么就一直报错呢? 错误原因 tabBar的页面被我放在分…...

『Linux升级路』进度条小程序
一、预备知识 在编写『Linux升级路』进度条小程序之前,我们需要了解一些预备知识。本文将详细介绍缓冲区和回车换行的概念。 1.1 缓冲区 缓冲区是计算机内存中的一块区域,用于临时存储数据。在编程中,我们经常使用缓冲区来临时保存数据&am…...
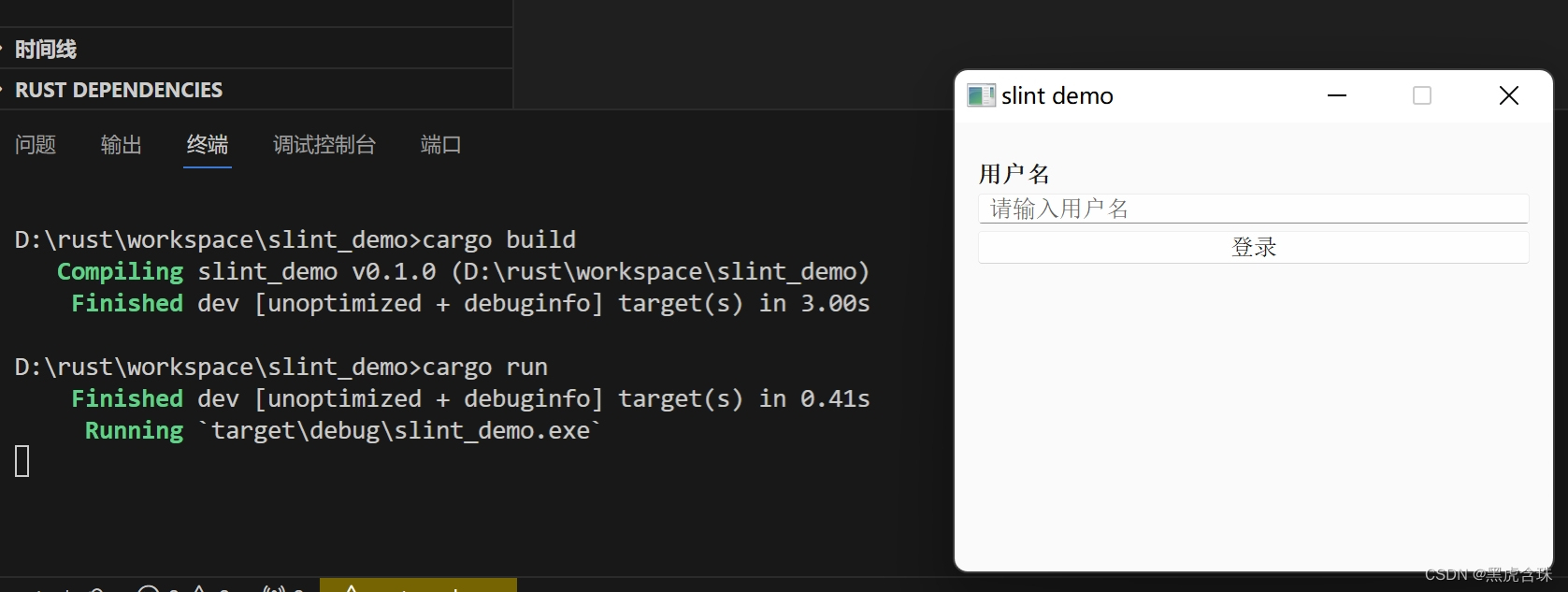
使用rust slint开发桌面应用
安装QT5,过程省略 安装rust,过程省略 创建工程 cargo new slint_demo 在cargo.toml添加依赖 [dependencies] slint "1.1.1" [build-dependencies] slint-build "1.1.1" 创建build.rs fn main() {slint_build::compile(&quo…...
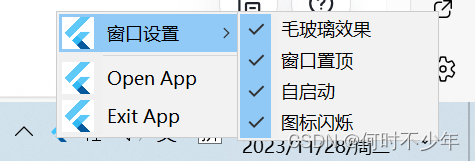
Flutter桌面应用程序定义系统托盘Tray
文章目录 概念实现方案1. tray_manager依赖库支持平台实现步骤 2. system_tray依赖库支持平台实现步骤 3. 两种方案对比4. 注意事项5. 话题拓展 概念 系统托盘:系统托盘是一种用户界面元素,通常出现在操作系统的任务栏或桌面顶部。它是一个水平的狭长区…...
docker:安装mysql以及最佳实践
文章目录 1、拉取镜像2、运行容器3、进入容器方式一方式二方式三容器进入后连接mysql和在宿主机连接mysql的区别 持久化数据持久化数据最佳实践 1、拉取镜像 docker pull mysql2、运行容器 docker run -d -p 3307:3306 --name mysql-container -e MYSQL_ROOT_PASSWORD123456 …...
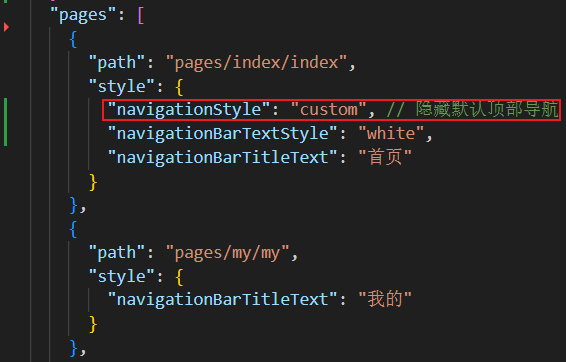
uniapp实战 —— 自定义顶部导航栏
效果预览 下图中的红框区域 范例代码 src\pages.json 配置隐藏默认顶部导航栏 "navigationStyle": "custom", // 隐藏默认顶部导航src\pages\index\components\CustomNavbar.vue 封装自定义顶部导航栏的组件(要点在于:获取屏幕边界…...
资源包的5步极速法)
紧急预警:新课标实施倒计时90天!用PlayAI快速构建跨学科项目式学习(PBL)资源包的5步极速法
更多请点击: https://kaifayun.com 第一章:紧急预警:新课标实施倒计时90天!用PlayAI快速构建跨学科项目式学习(PBL)资源包的5步极速法 距离《义务教育课程方案(2022年版)》全面落地…...

FlashAttention的OOM排查:为什么显存够了还是报内存不足?
之前有个团队在昇腾NPU上跑Llama-2-7B,模型是FP16权重,seq_len4096。他们算了算显存:模型权重13.5GB 激活值4GB KV Cache 4GB 21.5GB,昇腾910有32GB显存,绰绰有余。 结果一跑就报OOM(Out Of Memory&…...

校园项目 / 课程设计:如何包装成求职加分项
前言:你的校园项目,是不是写得像“课程作业汇报”? “完成课程设计《图书管理系统》,使用Java+MySQL开发,实现增删改查功能”——如果你还在这么写校园项目,恭喜你!成功加入“HR扫一眼就划走”豪华套餐。 现在的求职市场卷成什么样?某互联网大厂HR透露:“每天收到50…...

对比直连与通过Taotoken调用大模型API的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直连与通过Taotoken调用大模型API的延迟体感差异 在集成大模型API到应用时,开发者通常会关注请求的响应速度&#…...

Deepseek-V4-Flash 高效应用实战指南
文章目录① 高并发客服场景下的实时响应优化② 电商大促期间的海量商品描述生成③ 教育领域个性化习题与解析快速定制④ 短视频脚本批量创作与分镜规划⑤ 跨语言文档即时翻译与本地化适配⑥ 代码辅助生成与常见 Bug 自动修复⑦ 社交媒体热点内容敏捷生产流程⑧ 企业内部知识库智…...

数据结构太难了?用画图的方式理解链表和栈和树和图
别怕,把它们画出来,你会发现数据结构就是一堆积木。👋 你好,我是 Evan,一名计算机专业的学长,也是《大一突围》专栏的作者。还记得大一第一次见到“链表”时,我被指针绕晕了。后来我试着一个节点…...

华南x79-8d 支持 E5-2680 V3 或者 E5-2680 V4吗
不支持。 华南金牌 X79-8D 主板仅支持 E5-2600系列V1和V2版本的处理器,无法兼容您提到的 E5-2680 V3 或 V4。以下是关于该主板CPU支持情况的详细说明:💡 为什么不支持 V3/V4?根本原因在于CPU的接口和主板芯片组不匹配:…...

终极音乐整合方案:用MusicFree插件打造你的专属音乐中心
终极音乐整合方案:用MusicFree插件打造你的专属音乐中心 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 还在为音乐平台会员费烦恼吗?还在忍受不同平台间的歌曲版权割裂吗&…...

DNS欺骗攻击原理与Wireshark实战防御指南
1. 这不是黑客电影桥段,而是每天都在发生的网络基础层失守DNS欺骗攻击——这个词听起来像极了影视作品里黑衣人敲几行代码就让银行网站跳转到钓鱼页面的炫技桥段。但现实远比剧情更朴素、更隐蔽、更危险:它不依赖0day漏洞,不挑战防火墙规则&a…...

Chrome画中画扩展终极指南:一键实现多任务视频播放
Chrome画中画扩展终极指南:一键实现多任务视频播放 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension Chrome画中画扩展是一款基于原生Picture-in-Picture API开发的…...