准确!!!在 CentOS 8 上配置 PostgreSQL 14 的主从复制
在 CentOS 8 上配置 PostgreSQL 14 的主从复制,并设置 WAL 归档到特定路径 /home/postgres/archive 的步骤如下:
主服务器配置(主机)
-
配置 PostgreSQL:
- 编辑
postgresql.conf文件:
vim /data/postgres/pgdata/postgresql.conf- 设置以下参数:
listen_addresses = '*' # 允许所有地址连接wal_level = replica # 设置 WAL 级别为 replicamax_wal_senders = 10 # 设置最大 WAL 发送者数量archive_mode = on # 打开归档模式archive_command = 'cp %p /home/postgres/archive/%f' # 设置 WAL 归档命令 - 编辑
-
配置客户端认证文件(pg_hba.conf):
- 允许从服务器连接到主服务器:
vim /data/postgres/pgdata/pg_hba.conf- 添加以下行:
host replication replica_user slave_ip/32 trust其中
replica_user是复制用户,slave_ip是从服务器的 IP 地址。 -
创建复制用户:
psql -c "CREATE USER replica_user REPLICATION LOGIN CONNECTION LIMIT 5;" -
创建归档目录:
sudo mkdir -p /home/postgres/archive sudo chown postgres:postgres /home/postgres/archive sudo chmod 700 /home/postgres/archive -
重启 PostgreSQL 服务:
sudo systemctl restart postgresql-14
从服务器配置(从机)
-
停止 PostgreSQL 服务:
sudo systemctl stop postgresql-14 -
清空数据目录:
- 确保
/data/postgres/pgdata/目录是空的。
sudo rm -rf /data/postgres/pgdata/* - 确保
-
使用 pg_basebackup 复制数据:
sudo -u postgres pg_basebackup -h master_ip -D /data/postgres/pgdata/ -U replica_user -v -P -R --wal-method=stream其中
master_ip是主服务器的 IP 地址。这里要加-R 会自动创建standby.signal文件 -
配置
postgresql.conf:vim /data/postgres/pgdata/postgresql.conf- 添加或修改以下行:
primary_conninfo = 'host=master_ip user=replica_user'hot_standby = on
以下是相应的 sed 命令:
4.1. 对于 primary_conninfo,我们将取消注释该行并设置正确的主服务器 IP 地址(在这个例子中是 192.168.1.194)和复制用户(replica_user):
sed -i "/^#primary_conninfo/c\primary_conninfo = 'host=192.168.1.194 user=replica_user'" /data/postgres/pgdata/postgresql.conf
4.2. 对于 hot_standby,我们将取消注释该行并确保它设置为 on:
sed -i "/^#hot_standby =/c\hot_standby = on" /data/postgres/pgdata/postgresql.conf
这些命令会查找以 #primary_conninfo 和 #hot_standby 开头的行,并用新的配置行替换它们。
- 启动 PostgreSQL 服务:
sudo systemctl start postgresql-14
验证复制和归档状态
-
在主服务器上验证复制状态:
sudo -u postgres psql -c "SELECT * FROM pg_stat_replication;" -
在从服务器上验证是否处于恢复模式:
sudo -u postgres psql -c "SELECT pg_is_in_recovery();" -
检查 WAL 归档:
- 确认
/home/postgres/archive目录中是否有 WAL 文件被归档。
- 确认
注意事项
- 确保归档目录
/home/postgres/archive有足够的磁盘空间。 - 定期监控和管理归档目录,以防止其过度增长。
- 在生产环境中,考虑实施更复杂的归档策略。
这些步骤涉及基本的主从复制和 WAL 归档配置,具体需求和环境可能需要额外的调整和优化。
hot_standby = on 这个配置在 PostgreSQL 中 postgresql.conf用于启用热备服务器(Hot Standby)的功能,这是在只读模式下运行的备份服务器。这个功能通常用于以下情况:
示例场景:故障转移和负载平衡
假设您有一个生产数据库环境,其中包含一个主服务器(Primary Server)和一个或多个备份服务器(Standby Servers)。在这个设置中,hot_standby = on 会在备份服务器上使用。
故障转移(Failover)
- 主服务器故障:如果主服务器出现故障,您可以迅速切换到热备服务器。由于热备服务器一直在接收并应用主服务器的 WAL 记录,因此它能够快速升级为新的主服务器,几乎不中断服务。
- 维护期间:在主服务器进行维护或升级期间,可以将流量切换到热备服务器,以保持服务的可用性。
负载平衡(Load Balancing)
- 读取操作分流:在高负载情况下,为了减轻主服务器的压力,可以将读取请求(如报告生成、数据分析等)重定向到热备服务器,从而实现读取操作的负载平衡。
如何工作
- 当
hot_standby设置为on时,备份服务器以只读模式运行,可以接受用户的查询请求,但不允许任何写操作。 - 备份服务器通过流复制(Streaming Replication)或者定期应用 WAL 日志文件来保持与主服务器的数据一致。
优点
- 高可用性:在主服务器不可用时,可以快速切换到热备服务器,保证服务的持续运行。
- 减少主服务器负载:将读取操作重定向到备份服务器,减轻主服务器的负载。
- 即时数据恢复:因为备份服务器持续同步主服务器的数据,所以在需要时可以快速恢复数据。
总之,hot_standby = on 是 PostgreSQL 中用于提高数据库可用性和灵活性的重要配置,特别是在需要高可用性和负载平衡的生产环境中。
报错解决:

要修改 PostgreSQL 中已经创建的用户的连接限制数,您可以使用 ALTER USER 命令。在您的案例中,如果您想将 replica_user 用户的连接限制从当前值更改为 5,您应该执行以下命令:
ALTER USER replica_user CONNECTION LIMIT 5;
这个命令将更新用户 replica_user 的连接限制数为 5。请确保在执行此命令时您有足够的权限来修改用户设置。
如果您需要在 psql 命令行工具中执行此命令,可以使用以下格式:
psql -c "ALTER USER replica_user CONNECTION LIMIT 5;"
请确保在适当的数据库环境中执行这个命令,或者在命令中指定需要连接的数据库。
相关结果说明:

这个命令 SELECT * FROM pg_stat_replication; 在 PostgreSQL 中用于显示关于当前正在进行的复制进程的信息。这是一种监控和管理数据库复制状态的方法。输出的每一行代表一个活动的复制进程。我将解释每个字段的含义:
-
pid: 这是负责复制的进程的进程ID。
-
usesysid: 用户的系统ID。
-
usename: 正在进行复制的用户的名称。
-
application_name: 连接到数据库的应用程序的名称。
-
client_addr: 正在进行复制的客户端的IP地址。
-
client_hostname: 客户端的主机名(如果可用)。
-
client_port: 客户端连接到服务器的端口号。
-
backend_start: 后台进程开始的时间。
-
backend_xmin: 用于复制的事务ID的最小值(如果可用)。
-
state: 复制的当前状态,例如 “streaming” 表示正在进行流式复制。
-
sent_lsn, write_lsn, flush_lsn, replay_lsn: 这些是日志序列号(LSN),分别表示服务器发送的最后一个日志位置、写入的、刷新的和重放的。
-
write_lag, flush_lag, replay_lag: 这些字段表示写入延迟、刷新延迟和重放延迟。
-
sync_priority: 同步复制的优先级。
-
sync_state: 同步状态,例如 “async” 表示异步复制。
-
reply_time: 最后一次收到复制确认的时间。
在您提供的输出中,有两个复制进程正在进行,都是由用户 replica_user 发起的,分别连接自IP地址 192.168.197.130 和 192.168.197.128。两个进程都处于 “streaming” 状态,表明它们正在活跃地进行数据复制。
相关文章:
准确!!!在 CentOS 8 上配置 PostgreSQL 14 的主从复制
在 CentOS 8 上配置 PostgreSQL 14 的主从复制,并设置 WAL 归档到特定路径 /home/postgres/archive 的步骤如下: 主服务器配置(主机) 配置 PostgreSQL: 编辑 postgresql.conf 文件: vim /data/postgres/p…...

leetcode 1466
leetcode 1466 使用dfs 遍历图结构 如图 node 4 -> node 0 -> node 1 因为节点数是n, 边长数量是n-1。所以如果是从0出发的路线,都需要修改,反之,如果是通向0的节点,例如节点4,则把节点4当作父节点的节点&…...

想学编程,但不知道从哪里学起,应该怎么办?
怎样学习任何一种编程语言 我将教你怎样学习任何一种你将来可能要学习的编程语言。本书的章节是基于我和很多程序员学习编程的经历组织的,下面是我通常遵循的流程。 1.找到关于这种编程语言的书或介绍性读物。 2.通读这本书,把…...

Python数据科学视频讲解:Python概述
2.1 Python概述 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解2.1节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学应用的全流程,包括数据科学应用和…...

数据结构之内部排序
目录 7-1 直接插入排序 输入格式: 输出格式: 输入样例: 输出样例: 7-2 寻找大富翁 输入格式: 输出格式: 输入样例: 输出样例: 7-3 PAT排名汇总 输入格式: 输出格式: 输入样例: 输出样例: 7-4 点赞狂魔 输入格式: 输出格式: 输入样例&a…...
软考高级备考-系统架构师(机考后新版教材的备考过程与资料分享)
软考高级-系统架构设计师 考试复盘1.考试结果2.备考计划3.个人心得 资料分享 考试复盘 1.考试结果 三科压线过,真是太太太太太太太幸运了。上天对我如此眷顾,那不得不分享下我的备考过程以及一些备考资料,帮助更多小伙伴通过考试。 2.备考…...

Spring Boot 整合kafka:生产者ack机制和消费者AckMode消费模式、手动提交ACK
目录 生产者ack机制消费者ack模式手动提交ACK 生产者ack机制 Kafka 生产者的 ACK 机制指的是生产者在发送消息后,对消息副本的确认机制。ACK 机制可以帮助生产者确保消息被成功写入 Kafka 集群中的多个副本,并在需要时获取确认信息。 Kafka 提供了三种…...

Java+Swing: 主界面组件布局 整理9
说明:这篇博客是在上一篇的基础上的,因为上一篇已经将界面的框架搭好了,这篇主要是将里面的组件完善。 分为三个部分,北边的组件、中间的组件、南边的组件 // 放置北边的组件layoutNorth(contentPane);// 放置中间的 Jtablelayou…...
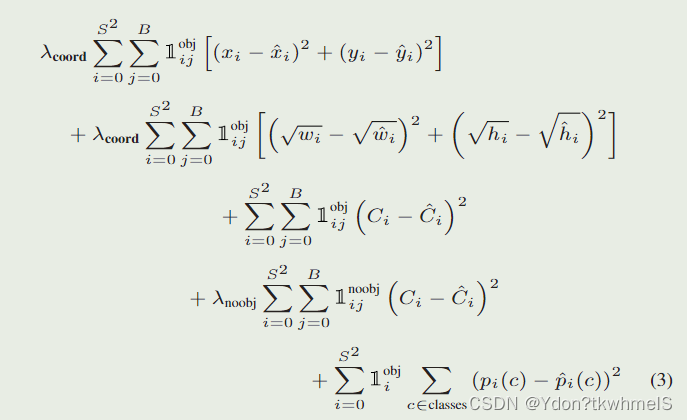
pytorch:YOLOV1的pytorch实现
pytorch:YOLOV1的pytorch实现 注:本篇仅为学习记录、学习笔记,请谨慎参考,如果有错误请评论指出。 参考: 动手学习深度学习pytorch版——从零开始实现YOLOv1 目标检测模型YOLO-V1损失函数详解 3.1 YOLO系列理论合集(Y…...

YOLOv8配置文件yolov8.yaml解读
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 位置 该文件的位置位于 ./ultralytics/cfg/models/v8/yolov8.yaml 模型参数配置 # Parameters nc: 80 # number of classes scales: #…...

4-Tornado高并发原理
核心原理就是协程epoll事件循环,再使用协程之后,开销是特别的小,那具体如何提供高并发的呢? 异步非阻塞IO 这意味我们整套开发的模式不在与原来一样,正因为不再一样,所以有时我们在理解代码时就有可能会比…...
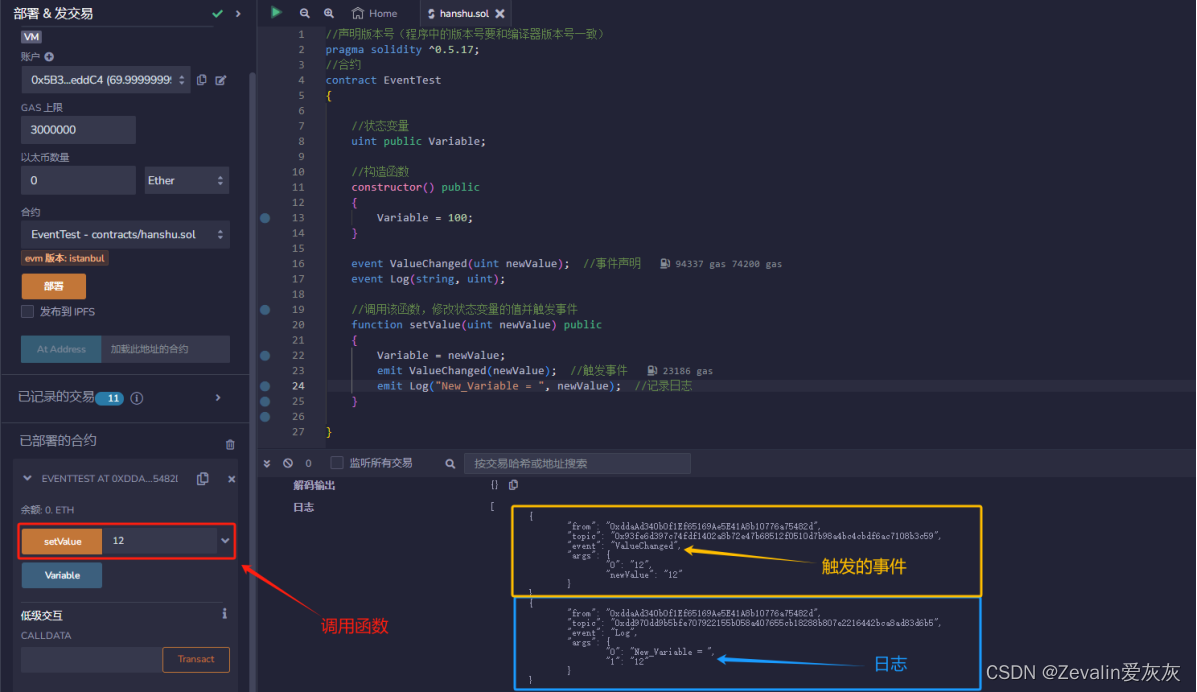
基于以太坊的智能合约开发Solidity(事件日志篇)
//声明版本号(程序中的版本号要和编译器版本号一致) pragma solidity ^0.5.17; //合约 contract EventTest {//状态变量uint public Variable;//构造函数constructor() public{Variable 100;}event ValueChanged(uint newValue); //事件声明event Log(…...
【BME2112】w11 notes
下周做老鼠实验 group analysis SPM group analysis 数据地址resting state 可以分析:correlation 计算两个脑区的相关性 静息态实验简单functional 成功的实验能看到激活区不成功的实验:比如被试头动太大,不是健康的被试 Spontaneous brain…...
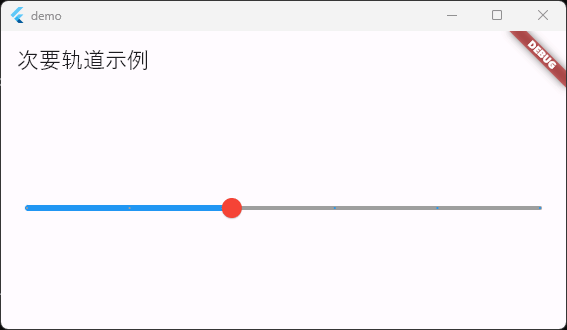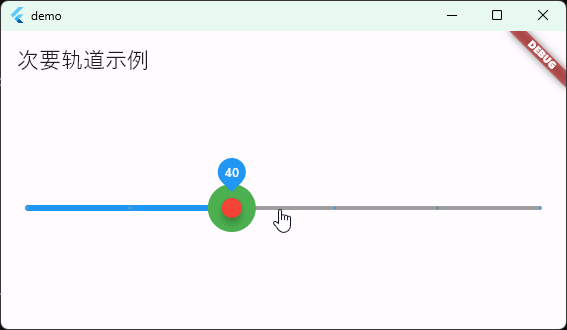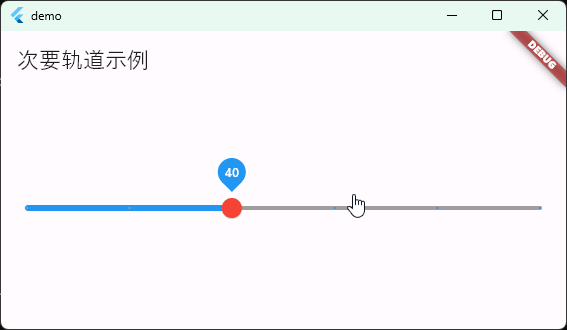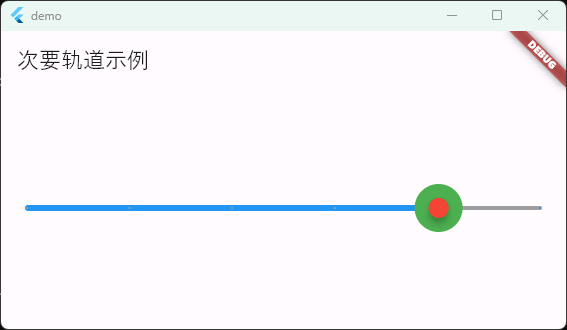
Flutter笔记:滑块及其实现分析1
Flutter笔记 滑块分析1 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134900784 本文从设计角度&#…...
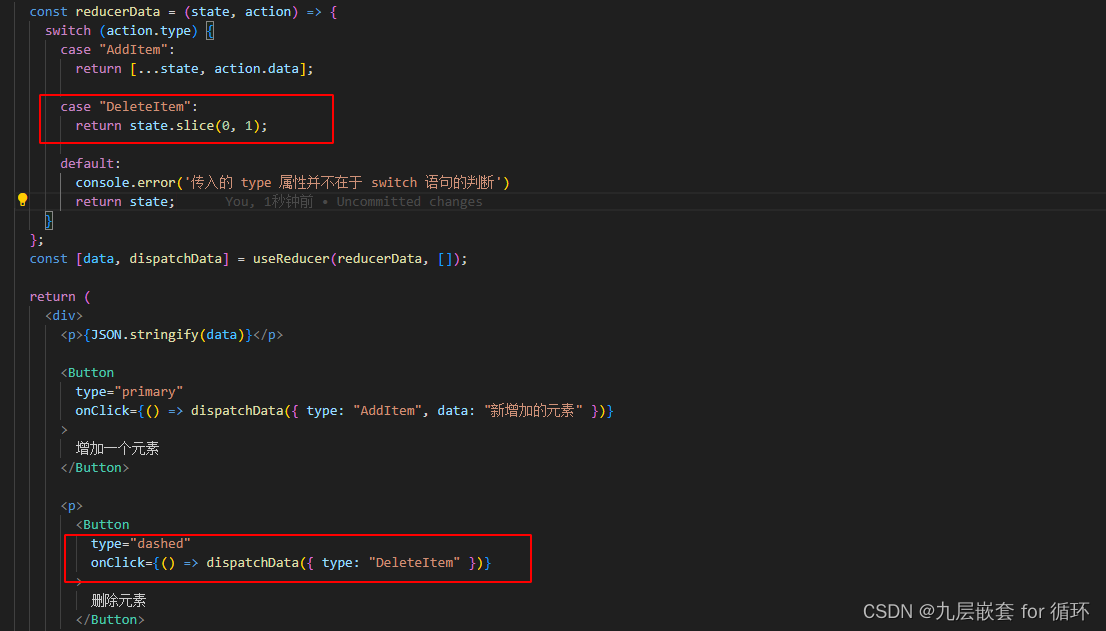
【React Hooks】useReducer()
useReducer 的三个参数是可选的,默认就是initialState,如果在调用的时候传递第三个参数那么他就会改变为你传递的参数,实际开发不建议这样写。会增加代码的不可读性。 使用方法: 必须将 useReducer 的第一个参数(函数…...

如何把kubernetes pod中的文件拷贝到宿主机上或者把宿主机上文件拷贝到kubernetes pod中
1. 创建一个 Kubernetes Pod 首先,下面是一个示例Pod的定义文件(pod.yaml): cat > nginx.yaml << EOF apiVersion: v1 kind: Pod metadata:name: my-nginx spec:containers:- name: nginximage: nginx EOF kubectl app…...
- ACodec(二))
Android 13 - Media框架(20)- ACodec(二)
这一节开始我们就来学习 ACodec 的实现 1、创建 ACodec ACodec 是在 MediaCodec 中创建的,这里先贴出创建部分的代码: mCodec mGetCodecBase(name, owner);if (mCodec NULL) {ALOGE("Getting codec base with name %s (owner%s) failed", n…...
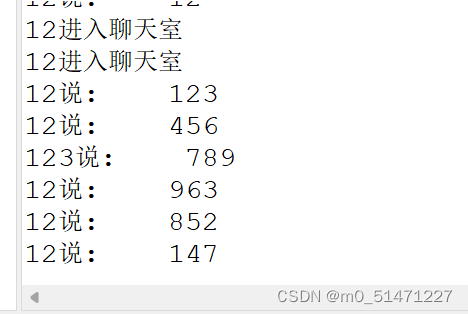
TCP单聊和UDP群聊
TCP协议单聊 服务端: import java.awt.BorderLayout; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.ServerSocket; import java.net.Socket; import java.util.V…...

智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于鲸鱼算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.鲸鱼算法4.实验参数设定5.算法结果6.参考文献7.MA…...
TortoiseGit 小乌龟svn客户端软件查看仓库地址
进入代码路径...

用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程
用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程自动驾驶感知系统的核心挑战在于如何有效融合多模态传感器数据。本文将手把手带你实现论文《CDSM: Cross-Domain Spatial Matching for Camera-Radar Fusion in 3D Object Detection》的核…...
)
别再手动跑Jupyter了!Lindy标准化流程强制接管你的分析工作流(仅剩最后23个企业未迁移)
更多请点击: https://codechina.net 第一章:Lindy数据分析自动化流程的演进逻辑与核心价值 Lindy效应指出,一个事物的预期剩余寿命与其当前已存在时间成正比——在数据分析领域,这一原理映射为:越经受住多轮业务迭代、…...

抖音无水印视频下载实战:突破平台限制的高效内容获取方案
抖音无水印视频下载实战:突破平台限制的高效内容获取方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

LeetCode 1424:对角线遍历 II | 前缀和分组
LeetCode 1424:对角线遍历 II | 前缀和分组 引言 对角线遍历 II(Diagonal Traverse II)是 LeetCode 第 1424 题,难度为 Medium。题目要求按照对角线顺序遍历一个二叉树数组,返回所有对角线上的节点值。这道题展示了前缀…...

React 性能优化:从 3 秒卡顿到 60 帧流畅,我做了这 5 件事
摘要 React 应用越做越大,卡顿问题越来越严重?本文分享 5 个亲测有效的性能优化方案,包括 React.memo 正确使用姿势、useMemo 依赖陷阱、虚拟列表实战、代码分割策略和 Profiler 调试技巧。每个方案都附带真实代码对比,帮你把页面…...

昇腾CANN manifest:仓库清单与版本管理实战
55 个独立仓库,每个仓库独立迭代——CANN 8.0 里的 ops-transformer 是哪个 commit?hccl 是 v2.1.3 还是 v2.2.0?runtime 和 driver 的版本是否兼容?manifest 仓库用一份 XML 格式的清单文件回答了所有这些问题。它是 CANN 发行版…...

校园项目 / 课程设计:如何包装成求职加分项
前言:你的校园项目,是不是写得像“课程作业汇报”? “完成课程设计《图书管理系统》,使用Java+MySQL开发,实现增删改查功能”——如果你还在这么写校园项目,恭喜你!成功加入“HR扫一眼就划走”豪华套餐。 现在的求职市场卷成什么样?某互联网大厂HR透露:“每天收到50…...

抖音无水印下载器:5分钟掌握高效批量下载的完整指南
抖音无水印下载器:5分钟掌握高效批量下载的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...
)
Codex CLI 接 Gemini 3.5 Flash 实测:代码生成、推理速度、价格三维度横评(2026)
上周 Google 发了 Gemini 3.5 Flash,我当天晚上就拿 Codex CLI 接上跑了几个项目里的真实任务。原因很简单——我们团队最近 token 开销涨得太快,老板让我找个"又快又便宜还不太拉胯"的模型顶日常编码场景。Claude Sonnet 4.6 质量没话说但贵&…...

Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁?
Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁? 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经因为Adobe Crea…...