Flink Flink数据写入Kafka
一、环境准备
官网地址
flink官方集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version><spark.version>2.4.3</spark.version><hadoop.version>2.8.5</hadoop.version><hbase.version>1.4.9</hbase.version><hive.version>2.3.5</hive.version><java.version>1.8</java.version><scala.version>2.11.8</scala.version><mysql.version>8.0.22</mysql.version><scala.binary.version>2.11</scala.binary.version><maven.compiler.source>${java.version}</maven.compiler.source><maven.compiler.target>${java.version}</maven.compiler.target></properties>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency>
二、KafkaSink介绍
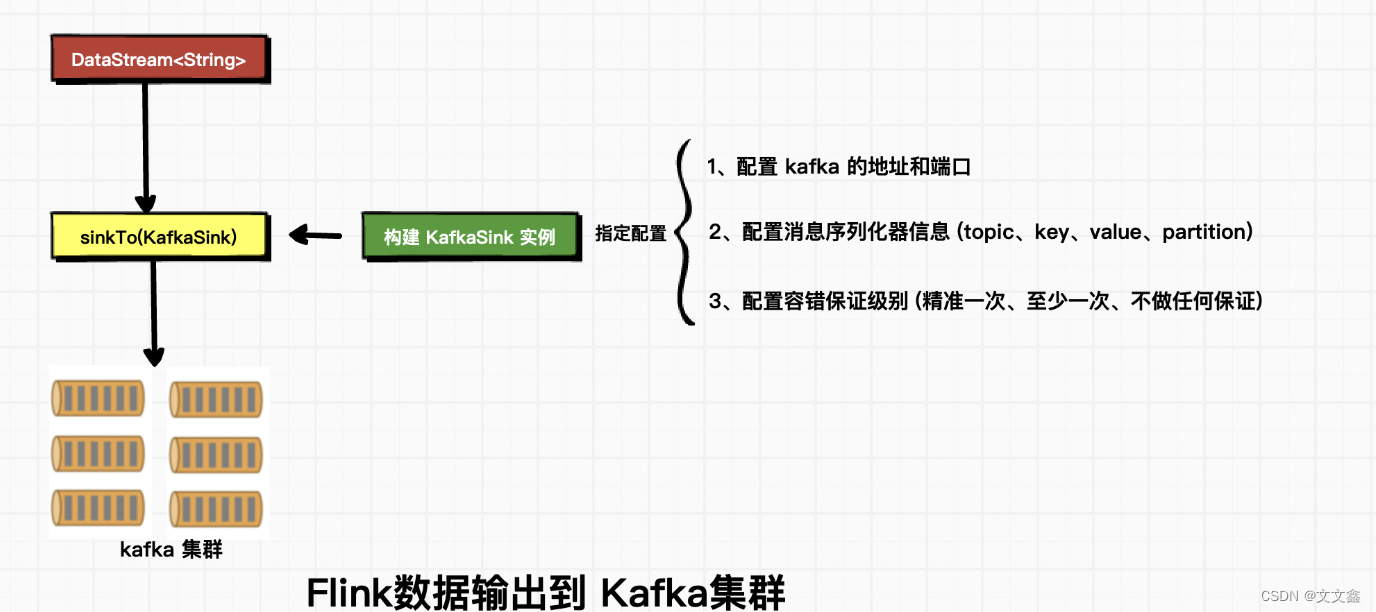
三、正确理解序列化器
什么叫序列化和反序列化?
1.序列化:把对象转换为字节序列的过程称为对象的序列化.
2.反序列化:把字节序列恢复为对象的过程称为对象的反序列化.
序列化器的作用是将flink数据转换成 kafka的ProducerRecord
Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者 Scala 对象;
那么,Flink Kafka Producer 需要知道如何将 Java/Scala 对象转化为二进制数据。
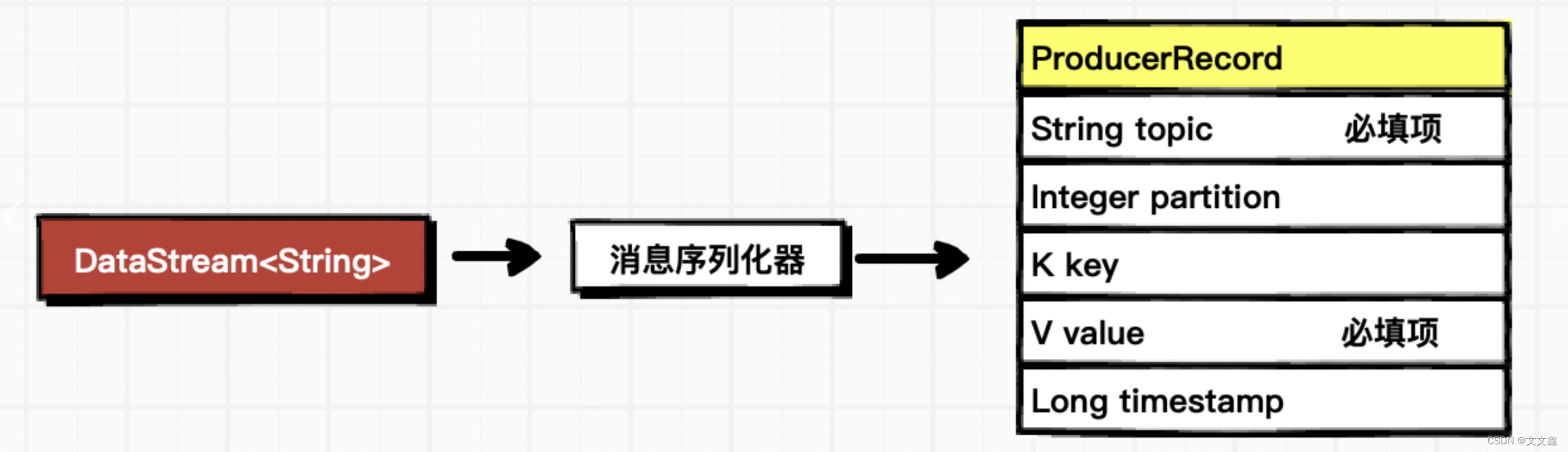
使用预定义的序列化器
将 DataStream 数据转换为 Kafka消息中的value,key为默认值null,timestamp为默认值
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// 指定 kafka 的地址和端口.setBootstrapServers("localhost:9092")// 指定序列化器:指定Topic名称、具体的序列化(产生方需要序列化,接收方需要反序列化).setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("testtopic01")// 指定value的序列化器.setValueSerializationSchema(new SimpleStringSchema()).build())
源码解析
public <T extends IN> KafkaRecordSerializationSchemaBuilder<T> setValueSerializationSchema(SerializationSchema<T> valueSerializationSchema) {this.checkValueSerializerNotSet();KafkaRecordSerializationSchemaBuilder<T> self = this.self();self.valueSerializationSchema = (SerializationSchema)Preconditions.checkNotNull(valueSerializationSchema);return self;}
使用自定义的序列化器
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// TODO 必填项:配置 kafka 的地址和端口.setBootstrapServers("localhost:9092")// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型.setRecordSerializer(new KafkaRecordSerializationSchema<String>() {...............}).build();
四、容错保证级别
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)
启用 Flink 的 checkpointing 后,FlinkKafkaProducer 可以提供精确一次的语义保证。
除了启用 Flink 的 checkpointing,你也可以通过将适当的 semantic 参数传递给 FlinkKafkaProducer 来选择三种不同的操作模式:
Semantic.NONE:Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。
Semantic.AT_LEAST_ONCE(默认设置):可以保证不会丢失任何记录(但是记录可能会重复)
Semantic.EXACTLY_ONCE:使用 Kafka 事务提供精确一次语义。无论何时,在使用事务写入 Kafka 时,都要记得为所有消费 Kafka 消息的应用程序设置所需的 isolation.level(read_committed 或 read_uncommitted - 后者是默认值)。
注意事项
Semantic.EXACTLY_ONCE 模式依赖于事务提交的能力。事务提交发生于触发 checkpoint 之前,以及从 checkpoint 恢复之后。如果从 Flink 应用程序崩溃到完全重启的时间超过了 Kafka 的事务超时时间,那么将会有数据丢失(Kafka 会自动丢弃超出超时时间的事务)。考虑到这一点,请根据预期的宕机时间来合理地配置事务超时时间。
默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。此属性不允许为大于其值的 producer 设置事务超时时间。 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时,因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
在 KafkaConsumer 的 read_committed 模式中,任何未结束(既未中止也未完成)的事务将阻塞来自给定 Kafka topic 的未结束事务之后的所有读取数据。 换句话说,在遵循如下一系列事件之后:
用户启动了 transaction1 并使用它写了一些记录
用户启动了 transaction2 并使用它编写了一些其他记录
用户提交了 transaction2
即使 transaction2 中的记录已提交,在提交或中止 transaction1 之前,消费者也不会看到这些记录。这有 2 层含义:
首先,在 Flink 应用程序的正常工作期间,用户可以预料 Kafka 主题中生成的记录的可见性会延迟,相当于已完成 checkpoint 之间的平均时间。
其次,在 Flink 应用程序失败的情况下,此应用程序正在写入的供消费者读取的主题将被阻塞,直到应用程序重新启动或配置的事务超时时间过去后,才恢复正常。此标注仅适用于有多个 agent 或者应用程序写入同一 Kafka 主题的情况。
注意:Semantic.EXACTLY_ONCE 模式为每个 FlinkKafkaProducer 实例使用固定大小的 KafkaProducer 池。每个 checkpoint 使用其中一个 producer。如果并发 checkpoint 的数量超过池的大小,FlinkKafkaProducer 将抛出异常,并导致整个应用程序失败。请合理地配置最大池大小和最大并发 checkpoint 数量。
注意:Semantic.EXACTLY_ONCE 会尽一切可能不留下任何逗留的事务,否则会阻塞其他消费者从这个 Kafka topic 中读取数据。但是,如果 Flink 应用程序在第一次 checkpoint 之前就失败了,那么在重新启动此类应用程序后,系统中不会有先前池大小(pool size)相关的信息。因此,在第一次 checkpoint 完成前对 Flink 应用程序进行缩容,且并发数缩容倍数大于安全系数 FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR 的值的话,是不安全的。同样,在这种情况使用 setTransactionalIdPrefix() 改变 transactional.id 也是不安全的,因为系统也不知道先前使用的 transactional.id 前缀。
五、案例—Flink将Socket数据写入Kafka(精准一次)
注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可
1、开启 checkpoint
2、设置事务前缀
3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟
package com.flink.DataStream.Sink;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class flinkSinkKafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);// 如果是精准一次,必须开启 checkpointstreamExecutionEnvironment.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);/*** TODO Kafka Sink* TODO 注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可* 1、开启 checkpoint* 2、设置事务前缀* 3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟*/Properties properties=new Properties();properties.put("transaction.timeout.ms",10 * 60 * 1000 + "");KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// 指定 kafka 的地址和端口.setBootstrapServers("localhost:9092")// 指定序列化器:指定Topic名称、具体的序列化(产生方需要序列化,接收方需要反序列化).setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("testtopic01")// 指定value的序列化器.setValueSerializationSchema(new SimpleStringSchema()).build())// 写到 kafka 的一致性级别: 精准一次、至少一次.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)// 如果是精准一次,必须设置 事务的前缀.setTransactionalIdPrefix("flinkkafkasink-")// 如果是精准一次,必须设置 事务超时时间: 大于 checkpoint间隔,小于 max 15 分钟.setKafkaProducerConfig(properties)//.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "").build();streamSource.sinkTo(kafkaSink);streamExecutionEnvironment.execute();}
}
理解ProduceerConfig配置源码
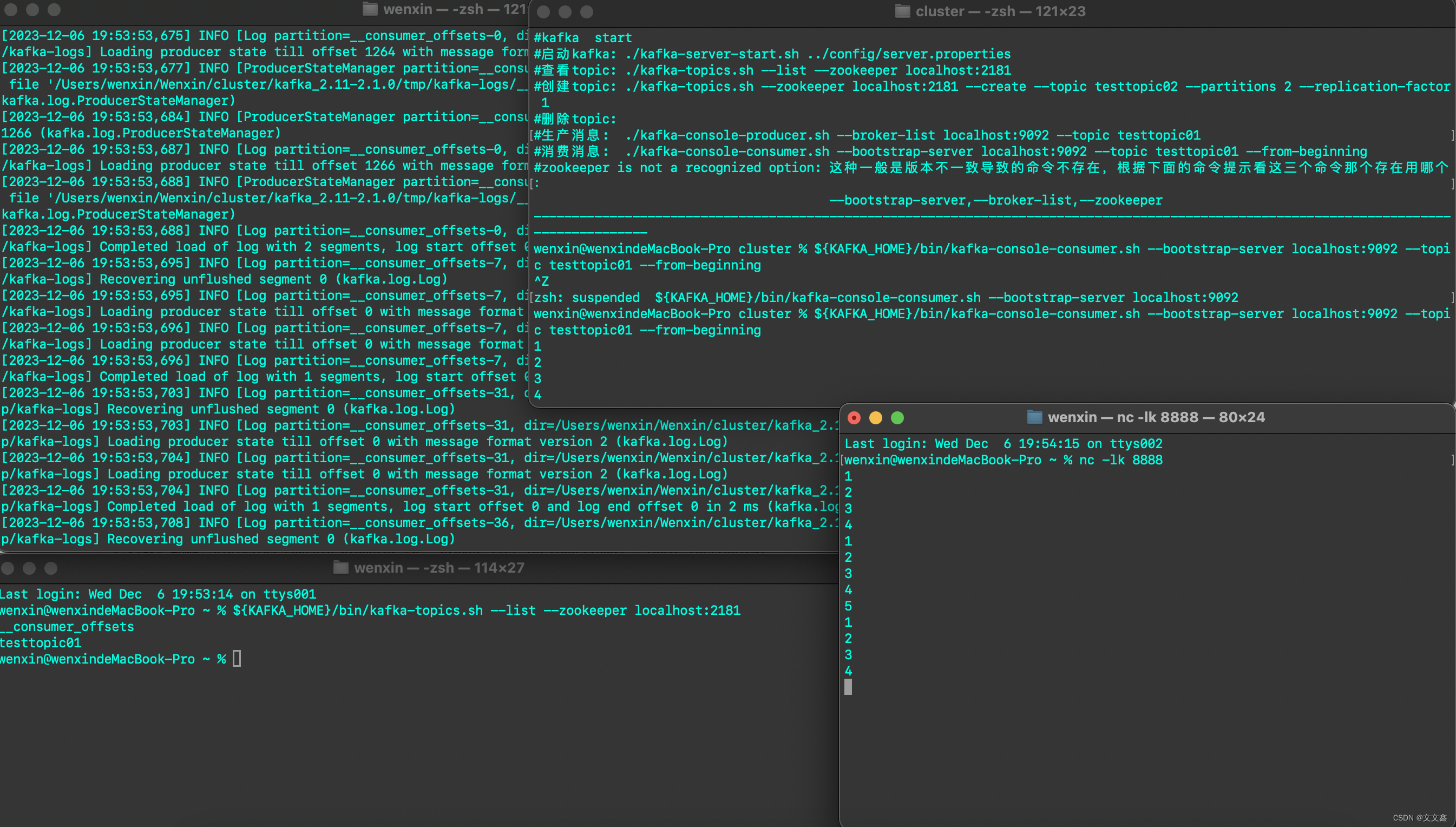
六、启动Zookeeper、Kafka
#启动zookeeper
${ZK_HOME}/bin/zkServer.sh start
#查看zookeeper状态
${ZK_HOME}/bin/zkServer.sh status
#启动kafka
${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties
#查看topic
${KAFKA_HOME}/bin/kafka-topics.sh --list --zookeeper localhost:2181
#创建topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic testtopic02 --partitions 2 --replication-factor 1
#删除topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic testtopic02
#生产消息
${KAFKA_HOME}/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testtopic01
#消费消息
${KAFKA_HOME}/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testtopic01 --from-beginning
通过socket模拟数据写入Flink之后,Flink将数据写入Kafka
相关文章:
Flink Flink数据写入Kafka
一、环境准备 官网地址 flink官方集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖 <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version&g…...

《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 Affective Computing 2021
《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 前言简介模型结构实验结果总结前言 今天为大家带来的是《Emotion-Regularized Conditional Variational Autoencoder for Emotional Response Generation》 出版:IEEE Transactions on Affective Computing 时间…...

Pytorch CIFAR10图像分类 Swin Transformer篇
Pytorch CIFAR10图像分类 Swin Transformer篇 文章目录 Pytorch CIFAR10图像分类 Swin Transformer篇4. 定义网络(Swin Transformer)Swin Transformer整体架构Patch MergingW-MSASW-MSARelative position biasSwin Transformer 网络结构Patch EmbeddingP…...
【vim】常用操作
用的时候看看,记太多也没用,下面都是最常用的,更多去查文档vim指令集。 以下均为正常模式下面操作,正在编辑的,先etc一下. 1/拷贝当前行 yy,5yy为拷贝包含当前行往下五行 2/p将拷贝的东西粘贴到当前行下…...

oracle、误操作删除数据库 数据恢复。
–查询 执行 delete 的语句 ,拿到删除的时间 FIRST_LOAD_TIME ,删除行数可参考 ROWS_PROCESSED select t.FIRST_LOAD_TIME,t.ROWS_PROCESSED,t.* from v$sql t where t.sql_text like %delete from trade% ;select *from trade as of timestamp to_time…...
【Angular开发】Angular在2023年之前不是很好
做一个简单介绍,年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】…...
 但是 3.0.8-1ubuntu1.2 正要被安装)
记录 | 报错:libssl-dev : 依赖: libssl3 (= 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装
ubuntu 上安装 libssl-dev 失败的报错解决 报错: 下列软件包有未满足的依赖关系: libssl-dev : 依赖: libssl3 ( 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装 E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破…...

MySQL联合查询、最左匹配、范围查询导致失效
服务器版本 客户端:navicat premium16.0.11 联合索引 假设有如下表 联合索引就是同时把多列设成索引,如(empno,ename)在查询的时候就会先按照empno进行查询,再按照ename进行查询其中empno是全局有序,ename是局部有…...

部署zabbix
源码下载地址: Download Zabbix sources nginx: download 防火墙和selinux都需要关闭 1、部署监控服务器 1)安装LNMP环境 Zabbix监控管理控制台需要通过Web页面展示出来,并且还需要使用MySQL来存储数据,因此需要先为Zabbix准备基础…...

服务器感染了.locked、.locked1勒索病毒,如何确保数据文件完整恢复?
尊敬的读者: locked、.locked1勒索病毒的威胁如影随形,深刻影响着数字世界的安全。本文将深入揭示locked、.locked1的狡猾特征,为您提供实用的数据恢复方法,并分享一系列特别定制的预防措施,旨在使您的数字生活摆脱勒…...
【Linux系统化学习】命令行参数 | 环境变量的再次理解
个人主页点击直达:小白不是程序媛 Linux专栏:Linux系统化学习 代码仓库:Gitee 目录 mian函数传参获取环境变量 手动添加环境变量 导出环境变量 environ获取环境变量 本地变量和环境变量的区别 Linux的命令分类 常规命令 内建命令 …...
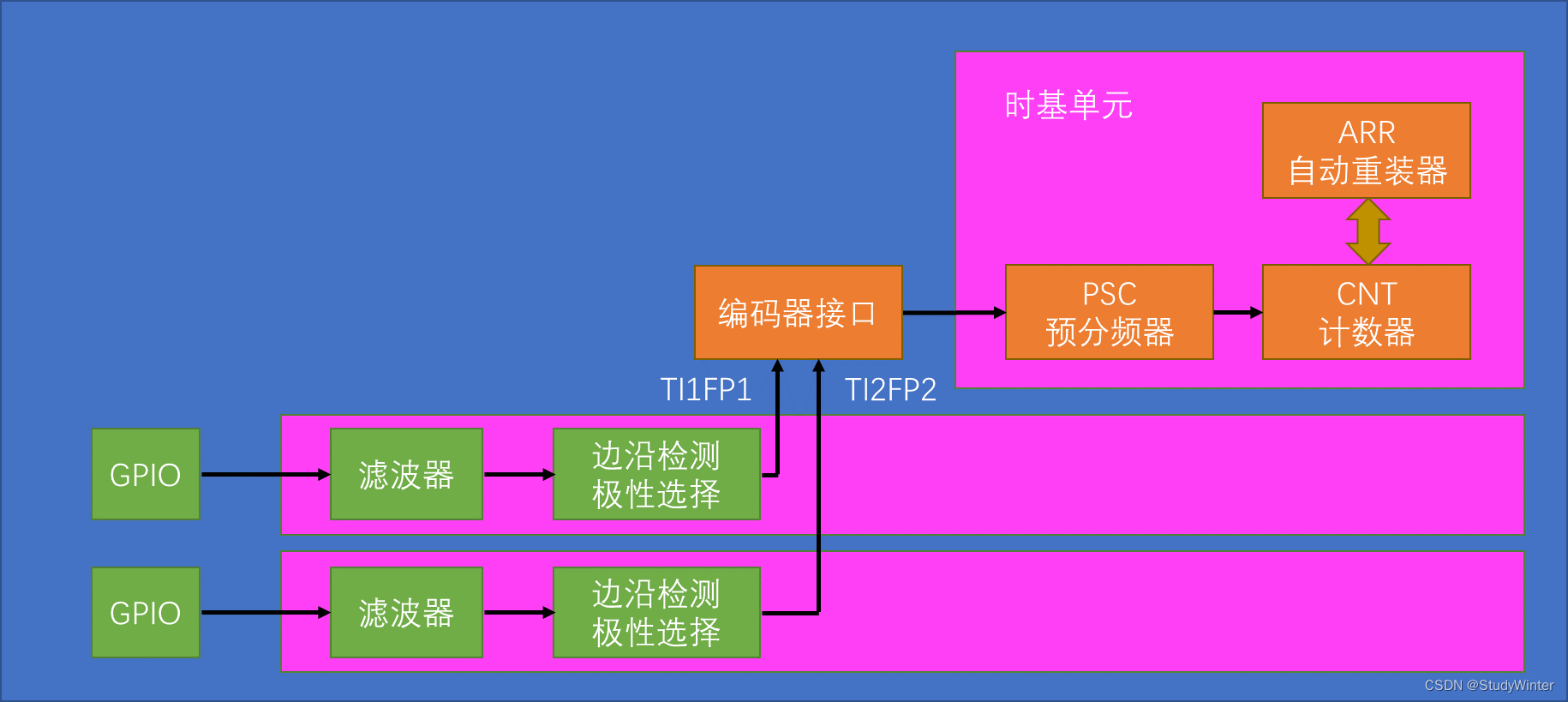
【STM32】TIM定时器编码器
1 编码器接口简介 Encoder Interface 编码器接口 编码器接口可接收增量(正交)编码器的信号,根据编码器旋转产生的正交信号脉冲,自动控制CNT自增或自减,从而指示编码器的位置、旋转方向和旋转速度 接收正交信号&#…...

力扣44题通配符匹配题解
44. 通配符匹配 - 力扣(LeetCode) 给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。* 可以匹配任意字符序列(包括空字符序列)。 …...
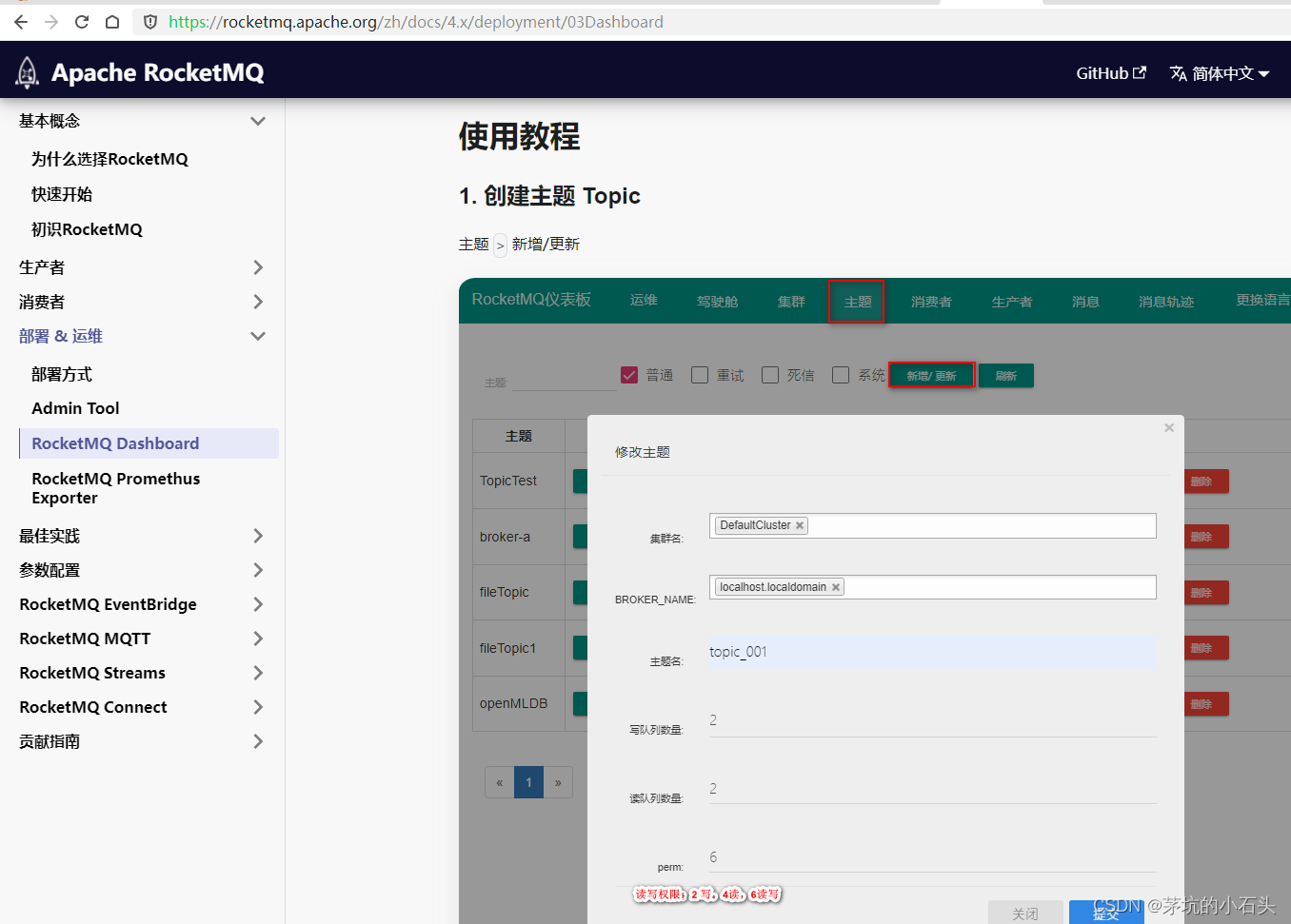
windows系统安装RocketMQ_dashboard
1.下载源码 按照官网说明下载源码 官网 官网文档 2.源码安装 2.1.① 编译rocketmq-dashboard 注释掉报错的maven插件frontend-maven-plugin、maven-antrun-plugin mvn clean package -Dmaven.test.skiptrue2.2.② 运行rocketmq-dashboard java -jar target/rocketmq-…...

ATECLOUD电源自动测试系统打破传统 助力新能源汽车电源测试
随着新能源汽车市场的逐步扩大,技术不断完善提升,新能源汽车测试变得越来越复杂,测试要求也越来越严格。作为新能源汽车的关键部件之一,电源为各个器件和整个电路提供稳定的电源,满足需求,确保新能源汽车的…...

如何教会小白使用淘宝API接口获取商品数据
随着互联网的普及,越来越多的人开始接触网络购物,而淘宝作为中国最大的电商平台之一,成为了众多消费者首选的购物平台。然而,对于一些小白用户来说,如何通过淘宝API接口获取商品数据可能是一个难题。本文将详细介绍如何…...
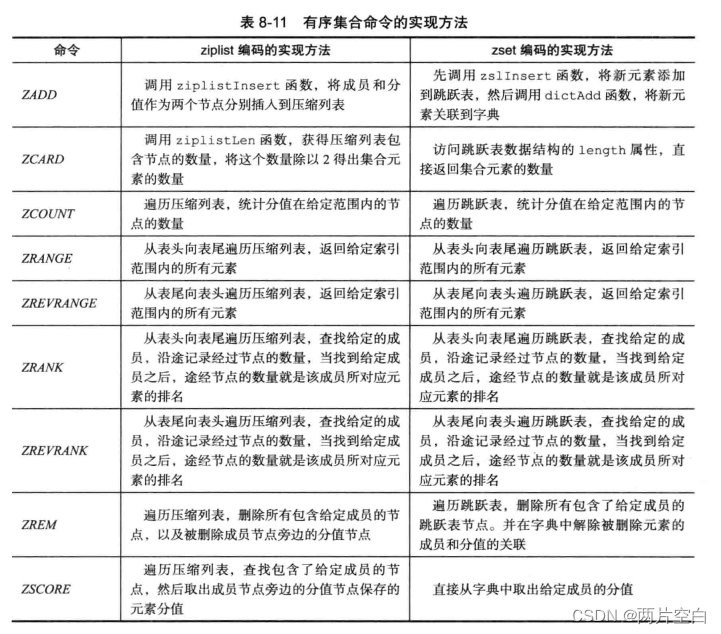
Redis有序集合对象
一.编码 有序集合的编码可以是ziplist或者skiplist。 ziplist编码的有序集合对象使用压缩列表作为底层实现,每一个集合元素使用紧挨在一起的两个压缩列表节点来保存。第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。 127.0.0.…...

【C++数据结构 | 字符串速通】10分钟秒杀字符串相关操作 | 字符串的增删改查 | 字符串与数组相互转换
字符串 by.Qin3Yu 文中所有代码默认已使用std命名空间且已导入部分头文件: #include <iostream> #include <string> using namespace std;概念速览 字符串是一种非常好理解的数据类型,它用于存储和操作文本数据。字符串可以包含任意字符…...
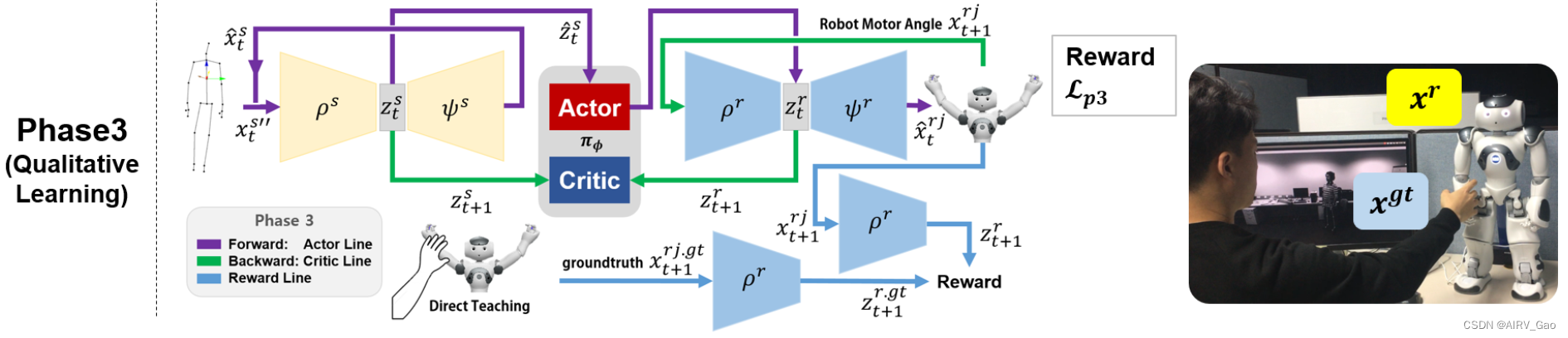
运动重定向:C-3PO
C-3PO: Cyclic-Three-Phase Optimization for Human-Robot Motion Retargeting based on Reinforcement Learning解析 摘要1. 简介2. 相关工作2.1 运动重定向(Motion Retargeting)2.2 强化学习(Reinforcement Learning) 3. 预备知…...
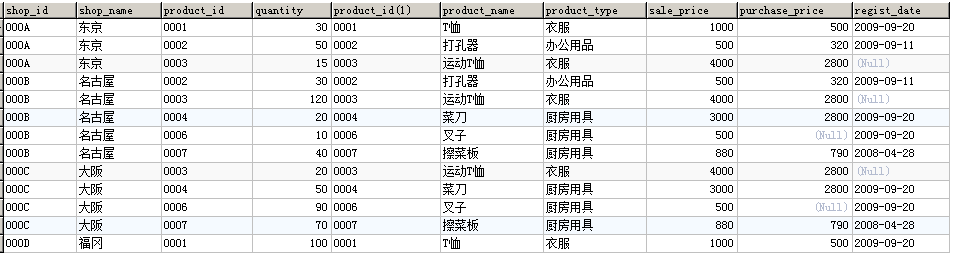
天池SQL训练营(四)-集合运算-表的加减法和join等
-天池龙珠计划SQL训练营 4.1表的加减法 4.1.1 什么是集合运算 集合在数学领域表示“各种各样的事物的总和”, 在数据库领域表示记录的集合. 具体来说,表、视图和查询的执行结果都是记录的集合, 其中的元素为表或者查询结果中的每一行。 在标准 SQL 中, 分别对检索结果使用 U…...

498元!某国产12代i7云终端小钢炮,仅1.7L迷你主机,可上i7-12700处理器,最大支持双M2+SATA三盘位,可惜还是准系统传家宝!
要说小主机品牌种类规格方面,最为丰富的不是个人家用消费级市场,而是云终端,痩客户机类型产品。奈何如今大环境不景气,再叠加如今处理器性能进步明显,以英特尔12代平台为例,如今依旧还是主流,所…...

ThingsVis v1.1.15 版本更新:补齐嵌入与运维体验短板,多场景集成更可靠
ThingsVis v1.1.15:嵌入与运维体验的全面升级ThingsVis v1.1.15 版本以 ThingsVis 嵌入能力和设备详情页体验为核心进行更新。在 ThingsVis 嵌入方面,支持全屏、自动播放、剪贴板写入权限,修复 iframe 无法全屏问题;在设备详情页&…...

从录制到规划:手把手教你用CARLA录制点云,在Autoware中构建完整自动驾驶仿真闭环
从CARLA到Autoware:构建自定义自动驾驶仿真场景的完整实践指南 在自动驾驶技术快速迭代的今天,仿真测试已成为算法验证不可或缺的环节。CARLA与Autoware作为开源仿真平台和自动驾驶框架的黄金组合,为研究者提供了高度灵活的测试环境。本文将深…...

门店数据采集如何做质量控制:LBS、图片质检、去重和人工复核
门店数据采集项目的难点,不是“采不到数据”,而是采回来的数据能不能被业务相信、被系统处理、被管理层复盘。质量控制通常要覆盖位置与时间校验、图片质量检测、图片去重、字段标准化和人工复核。一个全国项目可能涉及几百到几万家门店,图片…...

为内部培训系统集成Taotoken提供个性化学习内容生成与答疑
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部培训系统集成Taotoken提供个性化学习内容生成与答疑 在企业内部培训领域,技术部门常面临一个需求:如…...

AI大模型学习顺序_七步掌握大模型精髓:从入门到精通的进阶秘籍!
本文以“七层关系”为框架,系统地阐述了学习大模型的最佳路径。从基础概念入手,逐步深入到模型架构、训练技巧、应用场景等核心内容,旨在帮助读者构建完整的知识体系,最终实现从入门到精通的全面提升。按“七层关系”学大模型&…...

LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代
LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代 【免费下载链接】LeetDown a macOS app that downgrades A6 and A7 iDevices to OTA signed firmwares 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 还记得iPhone 5s的Touch I…...

如何用Playnite打造终极游戏库:统一管理20+平台游戏
如何用Playnite打造终极游戏库:统一管理20平台游戏 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your games. 项目地址: https:…...

2026年实用降AIGC工具:亲测AI率从90%降至4%的靠谱方案
一、前言:2026年毕业必过AIGC检测门槛 2026年国内高校对学术论文的AIGC疑似度审核全面收紧,绝大多数院校都发布了明确的AIGC检测数值要求:985、211院校规定本科论文AI率需低于20%,硕士论文AI率不得高于15%,普通高校也普…...

华硕笔记本G-Helper显示管理全攻略:从色彩异常到专业校准的5步解决方案
华硕笔记本G-Helper显示管理全攻略:从色彩异常到专业校准的5步解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivob…...