初识人工智能,一文读懂强化学习的知识文集(5)

🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。
🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。
🎉欢迎 👍点赞✍评论⭐收藏
人工智能知识专栏学习
| 人工智能云集 | 访问地址 | 备注 |
|---|---|---|
| 人工智能(1) | https://blog.csdn.net/m0_50308467/article/details/134830998 | 人工智能专栏 |
| 人工智能(2) | https://blog.csdn.net/m0_50308467/article/details/134861601 | 人工智能专栏 |
| 人工智能(3) | https://blog.csdn.net/m0_50308467/article/details/134882273 | 人工智能专栏 |
| 人工智能(4) | https://blog.csdn.net/m0_50308467/article/details/134882497 | 人工智能专栏 |
| 人工智能(5) | https://blog.csdn.net/m0_50308467/article/details/134896307 | 人工智能专栏 |
文章目录
- 🏆初识人工智能领域(强化学习)
- 🔎一、强化学习
- 🍁1. 什么是强化学习?
- 🍁1.1 什么是蒙特卡洛?
- 🍁1.2 蒙特卡洛常见算法?
- 🍁1.3 什么是动态规划?
- 🍁1.4 动态规划常见算法?
- 🍁1.5 什么是深度强化学习?
- 🍁1.6 深度强化学习算法公式有哪些以及使用?
- 🍁2. 强化学习的特点?
- 🍁3. 强化学习和机器学习的区别?
- 🍁4. 强化学习的要素和结构?
- 🍁5. 为什么要强化学习?
- 🍁6. 强化学习的方式有哪些?
- 🍁7. 强化学习给人类文明带来的影响有哪些?
- 🍁8. 强化学习有哪些存在的问题?
- 🍁9. 强化学习在人工智能中的应用场景是什么?
- 🍁10. 强化学习的主流算法有哪些?

🏆初识人工智能领域(强化学习)
🔎一、强化学习
🍁1. 什么是强化学习?

强化学习(Reinforcement Learning)是机器学习的一个分支,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习算法可以被训练来执行各种任务,包括游戏、机器人控制和投资组合管理。
强化学习与监督学习和无监督学习不同。在监督学习中,算法被提供带有标签的数据,这些数据告诉它哪些输入是正确的。在无监督学习中,算法被提供没有标签的数据,它必须从中学习模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。
强化学习算法通常使用一种称为价值函数的方法来学习。价值函数是一个函数,它给出了在给定状态下采取某一行动的价值。强化学习算法通过试验和错误来学习价值函数。它在环境中采取行动,并根据其行为获得的奖励或惩罚来更新价值函数。
强化学习算法已被成功应用于各种任务。例如,它们已被用于训练游戏玩家、机器人控制器和投资组合管理器。强化学习算法还被用于开发新的药物和材料。
强化学习是一个非常活跃的研究领域,新的算法和应用不断被开发。强化学习有望在未来发挥越来越重要的作用。
以下是一些强化学习算法的例子:
- 蒙特卡洛方法
- 动态规划
- 深度强化学习
蒙特卡洛方法是一种基于随机采样的强化学习算法。它通过在环境中随机采取行动并收集奖励来学习价值函数。
动态规划是一种基于状态转移方程的强化学习算法。它通过计算所有可能的状态转移并选择最佳行动来学习价值函数。
深度强化学习是一种使用深度学习技术的强化学习算法。它通过将状态和奖励数据输入到神经网络中来学习价值函数。
强化学习是一种非常强大的机器学习技术,它可以被应用于各种任务。随着新算法和应用的不断开发,强化学习有望在未来发挥越来越重要的作用。
强化学习是机器学习的一个分支,它通过智能体与环境的交互来学习如何采取行动以最大化累积奖励。在强化学习中,智能体通过观察环境的状态、采取行动并接收奖励来学习策略,目标是使智能体在环境中获得最大的长期回报。
强化学习的核心是智能体与环境的交互过程。智能体观察环境的当前状态,根据其学习到的策略选择一个行动,并将其应用于环境。环境接收行动并转移到新的状态,并返回给智能体一个奖励信号,表示该行动的好坏。智能体根据这个奖励信号来更新自己的策略,以便在未来的交互中做出更好的决策。
一个经典的强化学习例子是马尔可夫决策过程(Markov Decision Process,MDP)。在MDP中,智能体通过与环境的交互来学习最佳策略。智能体在每个时间步选择一个行动,环境根据当前状态和行动转移到下一个状态,并返回给智能体一个奖励信号。智能体的目标是通过学习价值函数或策略函数来最大化累积奖励。
例如,考虑一个智能体玩迷宫游戏的情况。智能体在迷宫中的位置可以被视为环境的状态,智能体可以选择向上、向下、向左或向右移动作为行动。当智能体达到迷宫的出口时,它会获得一个正的奖励,而当它撞到墙壁时,它会获得一个负的奖励。智能体的目标是通过与环境的交互学习一个策略,使得它能够以最短的路径到达迷宫的出口。
在这个例子中,智能体可以使用蒙特卡洛方法来学习策略。它可以随机选择行动并观察环境的反馈,然后根据获得的奖励来更新策略。通过多次迭代,智能体可以逐渐学习到哪些行动在给定状态下是最佳的。
另一个例子是AlphaGo,这是一个使用深度强化学习的计算机围棋程序。AlphaGo通过与自己下棋进行训练,学习如何在不同的棋局状态下采取最佳的行动。它使用深度神经网络来估计每个行动的价值,并通过蒙特卡洛树搜索来选择最佳的行动。通过大量的自我对弈和反馈,AlphaGo能够在围棋比赛中战胜世界冠军选手。
这些例子说明了强化学习在不同领域的应用。强化学习可以用于训练智能体玩游戏、控制机器人、优化资源分配等。它是一种强大的学习方法,能够处理复杂的决策问题,并在不断的交互中不断改进策略。
🍁1.1 什么是蒙特卡洛?
蒙特卡洛方法(Monte Carlo Method)是一种利用概率统计方法来求解问题的计算方法,它通过利用大量的随机样本,用计算机模拟的方法来求解问题。蒙特卡洛方法可以用于各种学科,例如金融、物理、工程、计算机科学等。
蒙特卡洛方法的基本思想是利用概率统计的思想,通过大量的随机样本来估计问题的解。它的主要步骤如下:
- 建立模型:首先需要建立问题的数学模型,将问题转化为一个概率统计问题。
- 生成随机样本:根据模型,生成大量的随机样本。
- 计算样本的统计量:根据生成的随机样本,计算样本的统计量,例如期望、方差等。
- 估计问题的解:根据样本的统计量,估计问题的解。
蒙特卡洛方法的主要优势在于它可以用于求解各种复杂的问题,而且它的解的精度可以通过增加随机样本的数量来提高。此外,蒙特卡洛方法还可以用于求解一些难以解析的问题。
蒙特卡洛方法的常见应用包括金融风险评估、物理模拟、工程设计、计算机图形学等。在金融领域,蒙特卡洛方法可以用于期权定价、风险管理等;在物理模拟领域,蒙特卡洛方法可以用于分子动力学模拟、量子计算等;在工程设计领域,蒙特卡洛方法可以用于可靠性分析、优化设计等;在计算机图形学领域,蒙特卡洛方法可以用于光线追踪、全局照明等。
蒙特卡洛方法的缺点是它的计算量很大,需要大量的计算资源和时间。此外,蒙特卡洛方法的解具有一定的随机性,因此它的解的精度也受到随机样本的影响。
🍁1.2 蒙特卡洛常见算法?
常用的蒙特卡洛算法包括:
1. 蒙特卡洛积分(Monte Carlo Integration) 蒙特卡洛积分是一种通过生成随机样本,利用样本的统计特性来估计积分值的方法。其公式为:
I = ∫ a b f ( x ) d x ≈ b − a N ∑ i = 1 N f ( x i ) I = \int_{a}^{b} f(x) dx \approx \frac{b-a}{N} \sum_{i=1}^{N} f(x_i) I=∫abf(x)dx≈Nb−a∑i=1Nf(xi)
其中, I I I表示被积函数的值, a a a和 b b b表示积分的下限和上限, f ( x ) f(x) f(x)表示被积函数, N N N表示随机样本的数量, x i x_i xi表示第 i i i个随机样本的值。使用蒙特卡洛积分时,需要先确定积分的上下限和被积函数,然后生成大量的随机样本,计算每个样本的函数值并求和,最后根据公式计算出积分的估计值。

下面是一个蒙特卡洛积分的示例:
假设要求解函数 f ( x ) = 1 2 π e − x 2 / 2 f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2} f(x)=2π1e−x2/2 在 x ∈ [ − 1 , 1 ] x \in [-1, 1] x∈[−1,1] 区间上的积分。可以使用蒙特卡洛积分方法来求解。
-
生成大量的随机数 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn,这些随机数在 [ − 1 , 1 ] [-1, 1] [−1,1] 之间均匀分布。
-
计算每个随机数的函数值 f ( x 1 ) , f ( x 2 ) , ⋯ , f ( x n ) f(x_1), f(x_2), \cdots, f(x_n) f(x1),f(x2),⋯,f(xn)。
-
计算这些函数值的平均值 f ˉ = 1 n ∑ i = 1 n f ( x i ) \bar{f} = \frac{1}{n} \sum_{i=1}^{n} f(x_i) fˉ=n1∑i=1nf(xi)。
-
利用平均值 f ˉ \bar{f} fˉ 乘以区间的宽度 2 2 2,得到估计的积分值: I ≈ 2 f ˉ I \approx 2\bar{f} I≈2fˉ。
这个估计的积分值是一个无偏估计,即 E [ I ] = ∫ − 1 1 f ( x ) d x E[I] = \int_{-1}^{1} f(x) dx E[I]=∫−11f(x)dx。 通过增加随机数的数量 n n n,可以提高估计的精确度。
2. 蒙特卡洛最优化(Monte Carlo Optimization) 蒙特卡洛最优化是一种通过生成随机样本,在样本中寻找最优解的方法。其公式为:
argmin x ∈ X f ( x ) = argmin x ∈ X 1 N ∑ i = 1 N f ( x i ) \text{argmin}_{x \in X} f(x) = \text{argmin}_{x \in X} \frac{1}{N} \sum_{i=1}^{N} f(x_i) argminx∈Xf(x)=argminx∈XN1∑i=1Nf(xi)
其中, f ( x ) f(x) f(x)表示目标函数, X X X表示样本的取值范围, N N N表示随机样本的数量, x i x_i xi表示第 i i i个随机样本的值。使用蒙特卡洛最优化时,需要先确定目标函数和样本的取值范围,然后生成大量的随机样本,计算每个样本的目标函数值并求和,最后根据公式计算出最优解。

下面是一个蒙特卡洛最优化的示例:
假设要求解函数 f ( x ) = − x 1 2 − x 2 2 f(x) = -x_1^2 - x_2^2 f(x)=−x12−x22 在 x 1 , x 2 ∈ [ − 1 , 1 ] x_1, x_2 \in [-1, 1] x1,x2∈[−1,1] 区间上的最小值。
-
生成大量的随机数 x 1 , x 2 x_1, x_2 x1,x2,这些随机数在 [ − 1 , 1 ] [-1, 1] [−1,1] 之间均匀分布。
-
根据这些随机数计算函数 f ( x 1 , x 2 ) f(x_1, x_2) f(x1,x2) 的值。
-
计算这些函数值的最小值,即为最小化目标函数的结果。 通过增加随机数的数量,可以提高估计的精确度。
这个示例中,最小值出现在 f ( 0 , 0 ) = 0 f(0, 0) = 0 f(0,0)=0 处。通过蒙特卡洛最优化方法,可以快速找到函数的最小值。
3. 蒙特卡洛路径积分(Monte Carlo Path Integration) 蒙特卡洛路径积分是一种通过生成随机样本,利用样本的统计特性来估计路径积分的方法。其公式为:
I = ∫ a b L ( x , x ˙ ) d x ≈ b − a N ∑ i = 1 N L ( x i , x ˙ i ) I = \int_{a}^{b} L(x, \dot{x}) dx \approx \frac{b-a}{N} \sum_{i=1}^{N} L(x_i, \dot{x}_i) I=∫abL(x,x˙)dx≈Nb−a∑i=1NL(xi,x˙i)
其中, I I I表示路径积分的值, a a a和 b b b表示路径的起点和终点, L ( x , x ˙ ) L(x, \dot{x}) L(x,x˙)表示路径积分的被积函数, N N N表示随机样本的数量, x i x_i xi和 x ˙ i \dot{x}_i x˙i表示第 i i i个样本的路径点和速度。使用蒙特卡洛路径积分时,需要先确定路径的起点和终点以及被积函数,然后生成大量的随机样本,计算每个样本的路径积分并求和,最后根据公式计算出路径积分的估计值。

蒙特卡洛路径积分是一种通过随机模拟来计算路径积分的方法。下面是一个蒙特卡洛路径积分的示例:
假设要求解函数 f ( x ) = x 1 2 + x 2 2 f(x) = x_1^2 + x_2^2 f(x)=x12+x22 在 x 1 , x 2 ∈ [ − 1 , 1 ] x_1, x_2 \in [-1, 1] x1,x2∈[−1,1] 区间上的路径积分,其中路径为 x 1 = t , x 2 = t 2 x_1 = t, x_2 = t^2 x1=t,x2=t2。
-
生成大量的随机数 t 1 , t 2 , ⋯ , t N t_1, t_2, \cdots, t_N t1,t2,⋯,tN,这些随机数在 [ − 1 , 1 ] [-1, 1] [−1,1] 之间均匀分布。
-
根据路径方程计算每个随机数对应的 x 1 , x 2 x_1, x_2 x1,x2 值。
-
根据这些 x 1 , x 2 x_1, x_2 x1,x2 值计算函数 f ( x ) f(x) f(x) 的值。
-
计算这些函数值的平均值,即为路径积分的估计值。 通过增加随机数的数量 N N N,可以提高估计的精确度。
这个示例中,路径积分的估计值为 I ≈ 1.5625 I \approx 1.5625 I≈1.5625。通过蒙特卡洛路径积分方法,可以快速计算路径积分的估计值。
4. 蒙特卡洛辐射传输(Monte Carlo Radiation Transport) 蒙特卡洛辐射传输是一种通过生成随机样本,模拟辐射在介质中的传输过程,从而估计辐射的分布和传输特性的方法。其公式为:
I ( r , r ′ , ω , ω ′ , t ) = ∫ 4 π d ω ′ ′ ∫ t − 1 2 Δ t t + 1 2 Δ t d t ′ ∫ 4 π d ω ′ Q ( r ′ , ω ′ , t ′ ) d f d ω ( ω ′ → ω , r ′ , ω ′ , t ′ ) d σ d ω ( ω ′ → ω ′ ′ , r ′ , ω ′ , t ′ ) I ( r ′ , ω ′ ′ , t ′ ) 4 π 1 Δ t I(\mathbf{r}, \mathbf{r}^{\prime}, \omega, \omega^{\prime}, t) = \int_{4 \pi} d \omega^{\prime \prime} \int_{t-\frac{1}{2} \Delta t}^{t+\frac{1}{2} \Delta t} d t^{\prime} \int_{4 \pi} d \omega^{\prime} \, Q\left(\mathbf{r}^{\prime}, \omega^{\prime}, t^{\prime}\right) \frac{d f}{d \omega}\left(\omega^{\prime} \rightarrow \omega, \mathbf{r}^{\prime}, \omega^{\prime}, t^{\prime}\right) \frac{d \sigma}{d \omega}\left(\omega^{\prime} \rightarrow \omega^{\prime \prime}, \mathbf{r}^{\prime}, \omega^{\prime}, t^{\prime}\right) \frac{I\left(\mathbf{r}^{\prime}, \omega^{\prime \prime}, t^{\prime}\right)}{4 \pi} \frac{1}{\Delta t} I(r,r′,ω,ω′,t)=∫4πdω′′∫t−21Δtt+21Δtdt′∫4πdω′Q(r′,ω′,t′)dωdf(ω′→ω,r′,ω′,t′)dωdσ(ω′→ω′′,r′,ω′,t′)4πI(r′,ω′′,t′)Δt1
其中, I ( r , r ′ , ω , ω ′ , t ) I(\mathbf{r}, \mathbf{r}^{\prime}, \omega, \omega^{\prime}, t) I(r,r′,ω,ω′,t)表示辐射的强度, r \mathbf{r} r和 r ′ \mathbf{r}^{\prime} r′表示辐射的源点和检测点的位置, ω \omega ω和 ω ′ \omega^{\prime} ω′表示辐射的入射角和传出角, t t t表示时间, Q ( r ′ , ω ′ , t ′ ) Q\left(\mathbf{r}^{\prime}, \omega^{\prime}, t^{\prime}\right) Q(r′,ω′,t′)表示辐射的源项, d f / d ω d f / d \omega df/dω表示辐射的散射系数, d σ / d ω d \sigma / d \omega dσ/dω表示辐射的传输系数, Δ t \Delta t Δt表示时间步长。使用蒙特卡洛辐射传输时,需要先确定辐射的源点、检测点和时间等参数,然后模拟辐射在介质中的传输过程,计算辐射的强度并估计辐射的分布和传输特性。

蒙特卡洛辐射传输(Monte Carlo Radiation Transport)是一种使用随机模拟方法求解辐射传输方程的数值方法。它通过模拟粒子(如光子)的传输路径和相互作用来计算辐射的分布和传输。 以下是一个蒙特卡洛辐射传输的示例:
假设有一个半径为1m的球形房间,房间内充满空气。房间的一个面上有一个光源,向房间内发出一束平行光。需要计算房间内的光照分布情况。 解决这个问题的步骤如下:
-
创建一个蒙特卡洛辐射传输模拟程序。
-
建立房间的几何模型,并定义光源的位置和发射的光束方向。
-
生成一组初始光子的发射位置和方向,这些光子代表了辐射束。
-
对每个光子,按照蒙特卡洛方法模拟其在房间内的传输路径: - 根据光子的方向和位置,计算其与房间几何模型的相互作用,包括光线的散射、吸收和透射。 - 根据相互作用的类型,更新光子的传输方向和状态(如是否被吸收)。 - 重复上述步骤,直到光子与探测器发生相互作用或者达到最大模拟次数。
-
统计每个探测器接收到的光子数,从而计算光照分布情况。 通过模拟大量的光子传输路径,可以得到一个相对准确的光照分布情况。 蒙特卡洛辐射传输方法可以应用于各种辐射传输问题,如医学成像、核反应堆设计、环境科学等。
🍁1.3 什么是动态规划?
动态规划(Dynamic Programming, DP)是一种通过将原问题划分为更小的子问题,并将子问题的解组合起来求解原问题的算法策略。它通过保存子问题的解,避免了重复计算,从而提高了算法的效率。
动态规划通常包含以下几个步骤:
-
定义问题的状态:将原问题划分为更小的子问题,并定义子问题的状态。
-
定义状态转移方程:确定子问题之间的关系,建立状态转移方程。
-
确定初始条件:确定最小子问题的解,即初始条件。
-
从底向上计算:根据状态转移方程,从底向上计算子问题的解,并保存在表格中。
-
结合子问题的解:根据状态转移方程,将子问题的解组合起来,得到原问题的解。
动态规划算法通常用于求解最优化问题,例如最长公共子序列、背包问题、最短路径等问题。它具有高效、精确等优点,在计算机科学、数学、经济学等领域有广泛应用。
🍁1.4 动态规划常见算法?
动态规划是一种用于求解最优化问题的算法策略,常见的动态规划算法包括:
1. 最长公共子序列(Longest Common Subsequence, LCS):给定两个序列,求它们的最长公共子序列的长度。
算法公式:
状态转移方程:lcs[i] = lcs[i-1] + dp[i-1][j-1] (如果x[i-1] == y[j-1])
初始条件:lcs[0..m-1] = 0, lcs[0..n-1] = 0
2. 背包问题(Knapsack Problem):给定一组物品和一个背包,每个物品有自己的重量和价值,在不超过背包容量的情况下,选择一些物品放入背包,使装入的物品总价值最大。
算法公式:
状态转移方程:dp[i][j] = max(dp[i-1][j-w[i]] + w[i], dp[i][j])
初始条件:dp[0][j] = 0, dp[i][0] = 0
3. 最短路径问题(Shortest Path Problem):在有向图或无向图中,找到源节点到目标节点的最短路径。
算法公式:
状态转移方程:dp[i][j] = max(dp[i-1][j-w[i]] + w[i], dp[i][j])
初始条件:dp[0][j] = 0, dp[i][0] = 0
4. 最大子段和(Maximum Subarray Problem):给定一个整数数组,找到一个具有最大和的连续子数组。
算法公式:
状态转移方程:dp[i] = max(dp[i-1] + a[i], a[i])
初始条件:dp[0] = a[0]
5. 最大子矩阵和(Maximum Submatrix Problem):给定一个整数矩阵,计算其所有元素子矩阵中的最大和。
算法公式:
状态转移方程:dp[i][j] = max(dp[i][j-1] + a[i][j], dp[i-1][j] + a[i][j], dp[i-1][j-1] + a[i][j])
初始条件:dp[i][0] = dp[0][j] = 0
6. 最长递增子序列(Longest Increasing Subsequence, LIS):给定一个整数序列,找到其中最长的递增子序列的长度。
算法公式:
状态转移方程:dp[i] = max(dp[i], dp[j] + 1 (0 <= j < i and a[j] < a[i]))
初始条件:dp[0] = 1
7. 最大流量问题(Maximum Flow Problem):在有向图中,确定从源节点到汇节点的最大流量。
算法公式:
状态转移方程:dp[i][j] = max(dp[i][j], dp[i][k] + dp[k+1][j] - C[k+1][j])
初始条件:dp[i][j] = infinity (除非j = s)
8. 最小生成树问题(Minimum Spanning Tree Problem):在无向图中,找到一棵包含所有节点且总权值最小的树。
算法公式:
状态转移方程:dp[i] = min(dp[i], dp[j] + w[i][j] (0 <= j < n and w[i][j] < infinity))
初始条件:dp[0] = 0
以上是动态规划常见的一些算法,实际应用中还有许多其他问题可以使用动态规划策略解决。
🍁1.5 什么是深度强化学习?
深度强化学习(RL)是一种将深度学习与强化学习相结合的机器学习类型。深度学习是一种机器学习类型,它使用人工神经网络从数据中学习。强化学习是一种机器学习类型,它通过与环境交互并根据其行为获得奖励或惩罚来学习如何做出决策。
深度强化学习结合了深度学习的强大功能和强化学习从环境中学习的能力来解决复杂问题。深度强化学习已被用于解决各种问题,包括玩视频游戏、控制机器人和设计自动驾驶汽车。
深度强化学习是一种强大的工具,它有可能解决各种各样的问题。然而,深度强化学习也是一项复杂的技术,很难实现。因此,深度强化学习仍在开发中,尚未得到广泛使用。
以下是深度强化学习的一些优点:
- 深度强化学习可以从大量数据中学习。
- 深度强化学习可以学习输入和输出之间的复杂关系。
- 深度强化学习可以学习实时做出决策。
以下是深度强化学习的一些挑战:
- 深度强化学习的计算成本很高。
- 深度强化学习很难训练。
- 深度强化学习很难调试。
尽管存在挑战,但深度强化学习是一种有前途的技术,它有可能解决各种各样的问题。随着技术的不断发展,深度强化学习可能会得到更广泛的应用。
🍁1.6 深度强化学习算法公式有哪些以及使用?
深度强化学习算法有很多种,其中最常见的是:
- 深度 Q 学习(DQN)
- 深度策略梯度(DPG)
- 深度确定性策略梯度(DDPG)
- 深度强化学习 Actor-Critic(A2C)
- 深度强化学习 Actor-Critic 算法 with Experience Replay(A2C with ER)
- 深度强化学习 Actor-Critic 算法 with Multi-Agent Reinforcement Learning(A2C with MARL)
这些算法都使用深度学习来学习环境中的状态和动作之间的关系,并通过试错来找到最佳的策略。它们已经被用于解决各种各样的问题,包括游戏、机器人控制和自然语言处理。
以下是这些算法的公式:
* 深度 Q 学习(DQN):
Q(s, a) = r + γmaxa'Q(s', a')
* 深度策略梯度(DPG):
θ = θ + α∇θJ(θ)
* 深度确定性策略梯度(DDPG):
θ = θ + α∇θJ(θ)
* 深度强化学习 Actor-Critic(A2C):
θ = θ + α∇θJ(θ)
* 深度强化学习 Actor-Critic 算法 with Experience Replay(A2C with ER):
θ = θ + α∇θJ(θ)
* 深度强化学习 Actor-Critic 算法 with Multi-Agent Reinforcement Learning(A2C with MARL):
θ = θ + α∇θJ(θ)
这些公式都很复杂,但它们都基于相同的基本原理:使用深度学习来学习环境中的状态和动作之间的关系,并通过试错来找到最佳的策略。
🍁2. 强化学习的特点?
强化学习是一种机器学习算法,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习算法可以被训练来执行各种任务,包括游戏、机器人控制和投资组合管理。
强化学习与监督学习和无监督学习不同。在监督学习中,算法被提供带有标签的数据,这些数据告诉它哪些输入是正确的。在无监督学习中,算法被提供没有标签的数据,它必须从中学习模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。
强化学习算法通常使用一种称为价值函数的方法来学习。价值函数是一个函数,它给出了在给定状态下采取某一行动的价值。强化学习算法通过试验和错误来学习价值函数。它在环境中采取行动,并根据其行为获得的奖励或惩罚来更新价值函数。
强化学习算法的一个特点是它可以处理不确定性。在监督学习中,算法被提供带有标签的数据,这些数据告诉它哪些输入是正确的。在无监督学习中,算法被提供没有标签的数据,它必须从中学习模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。环境可能不完全可预测,因此强化学习算法必须能够处理不确定性。
强化学习算法的一个优点是它可以学习长期奖励。在监督学习中,算法只能学习短期奖励。在无监督学习中,算法可以学习长期奖励,但它必须能够从数据中提取模式。在强化学习中,算法可以学习长期奖励,因为它可以与环境交互并根据其行为获得奖励。
强化学习算法的一个缺点是它可能需要很长时间才能学习。在监督学习中,算法可以很快学习,因为它被提供带有标签的数据。在无监督学习中,算法可以很快学习,因为它可以从数据中提取模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。这可能需要很长时间,因为环境可能不完全可预测。
强化学习算法是一种强大的机器学习算法,它可以被训练来执行各种任务。它可以处理不确定性,并且可以学习长期奖励。然而,它可能需要很长时间才能学习。
🍁3. 强化学习和机器学习的区别?
强化学习和机器学习都是人工智能领域的重要分支,但它们在许多方面都存在差异。
强化学习
强化学习是一种机器学习算法,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习算法可以被训练来执行各种任务,包括游戏、机器人控制和投资组合管理。
机器学习
机器学习是一种计算机科学分支,它使用统计和数学方法从数据中学习。机器学习算法可以被训练来执行各种任务,包括分类、回归、聚类和预测。
强化学习和机器学习的区别
强化学习和机器学习的主要区别在于它们的学习方式。机器学习算法在训练期间使用数据来学习如何执行任务。强化学习算法在训练期间使用数据来学习如何采取行动,以最大化累积奖励。
强化学习和机器学习的应用
强化学习和机器学习在许多领域都有应用,包括游戏、机器人控制、投资组合管理和医疗保健。
强化学习和机器学习的未来
强化学习和机器学习都是人工智能领域的重要分支,它们在未来都有很大的发展潜力。强化学习算法可以被训练来执行各种复杂的任务,而机器学习算法可以被训练来处理大量的数据。
总结
强化学习和机器学习都是人工智能领域的重要分支,但它们在许多方面都存在差异。强化学习算法在训练期间使用数据来学习如何采取行动,以最大化累积奖励。机器学习算法在训练期间使用数据来学习如何执行任务。强化学习和机器学习在许多领域都有应用,包括游戏、机器人控制、投资组合管理和医疗保健。强化学习和机器学习在未来都有很大的发展潜力。
以下是强化学习和机器学习的区别:
| 特征 | 强化学习 | 机器学习 |
|---|---|---|
| 学习方式 | 通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动 | 使用统计和数学方法从数据中学习 |
| 目标 | 最大化累积奖励 | 执行任务 |
| 应用 | 游戏、机器人控制、投资组合管理、医疗保健等 | 分类、回归、聚类、预测等 |
| 未来 | 有很大的发展潜力 | 有很大的发展潜力 |
强化学习和机器学习都是人工智能领域的重要分支,它们在许多领域都有应用。随着技术的不断发展,强化学习和机器学习在未来将发挥越来越重要的作用。
🍁4. 强化学习的要素和结构?

强化学习(Reinforcement Learning)是机器学习的一个分支,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习算法可以被训练来执行各种任务,包括游戏、机器人控制和投资组合管理。
强化学习的要素包括:
- 智能体:智能体是强化学习算法的主体,它在环境中与环境交互并根据其行为获得奖励或惩罚。
- 环境:环境是智能体所处的环境,它可以是物理环境,也可以是虚拟环境。
- 状态:状态是环境的一种描述,它可以是环境的物理状态,也可以是环境的逻辑状态。
- 行动:行动是智能体在环境中采取的行动,它可以是物理行动,也可以是逻辑行动。
- 奖励:奖励是智能体在环境中采取行动后获得的奖励,它可以是正奖励,也可以是负奖励。
- 惩罚:惩罚是智能体在环境中采取行动后获得的惩罚,它可以是正惩罚,也可以是负惩罚。
强化学习的结构包括:
- 价值函数:价值函数是一个函数,它给出了在给定状态下采取某一行动的价值。
- 策略函数:策略函数是一个函数,它给出了在给定状态下采取某一行动的概率。
- 学习算法:学习算法是强化学习算法用来学习价值函数和策略函数的算法。
强化学习算法可以分为两大类:
- 离散强化学习:离散强化学习算法处理离散状态和离散行动的环境。
- 连续强化学习:连续强化学习算法处理连续状态和连续行动的环境。
强化学习算法在许多领域都有应用,包括游戏、机器人控制和投资组合管理。
🍁5. 为什么要强化学习?
强化学习是一种机器学习算法,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习算法可以被训练来执行各种任务,包括游戏、机器人控制和投资组合管理。
强化学习有许多优点,包括:
- 它可以处理不确定性。在监督学习中,算法被提供带有标签的数据,这些数据告诉它哪些输入是正确的。在无监督学习中,算法被提供没有标签的数据,它必须从中学习模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。环境可能不完全可预测,因此强化学习算法必须能够处理不确定性。
- 它可以学习长期奖励。在监督学习中,算法只能学习短期奖励。在无监督学习中,算法可以学习长期奖励,但它必须能够从数据中提取模式。在强化学习中,算法可以学习长期奖励,因为它可以与环境交互并根据其行为获得奖励。
- 它可以学习从经验中。在监督学习中,算法被提供带有标签的数据,这些数据告诉它哪些输入是正确的。在无监督学习中,算法被提供没有标签的数据,它必须从中学习模式。在强化学习中,算法必须在与环境交互时学习如何采取行动。环境可能不完全可预测,因此强化学习算法必须能够从经验中学习。
强化学习在许多领域都有应用,包括游戏、机器人控制和投资组合管理。它是一种强大的机器学习算法,可以被训练来执行各种复杂的任务。
🍁6. 强化学习的方式有哪些?
强化学习有几种常见的方式,包括:
-
基于价值的强化学习(Value-Based Reinforcement Learning):这种方式的目标是学习一个价值函数,用于评估在给定状态下采取不同行动的价值。常见的算法包括Q-Learning和Deep Q-Network(DQN)。
-
策略优化(Policy Optimization):这种方式的目标是直接学习一个策略函数,用于在给定状态下选择最优的行动。常见的算法包括Policy Gradient和Proximal Policy Optimization(PPO)。
-
深度强化学习(Deep Reinforcement Learning):这种方式结合了深度学习和强化学习的技术,使用深度神经网络来近似价值函数或策略函数。常见的算法包括DQN、Deep Deterministic Policy Gradient(DDPG)和Soft Actor-Critic(SAC)。
-
模型基础强化学习(Model-Based Reinforcement Learning):这种方式使用环境模型来预测状态转移和奖励,然后使用这些预测结果进行决策。常见的算法包括Model Predictive Control(MPC)和Monte Carlo Tree Search(MCTS)。
-
多智能体强化学习(Multi-Agent Reinforcement Learning):这种方式涉及多个智能体同时学习和协作,以达到共同的目标。常见的算法包括Independent Q-Learning和Deep Deterministic Policy Gradient for Multi-Agent (DDPG-MADDPG)。
这些是强化学习中常见的几种方式,每种方式都有其独特的优势和适用场景。选择合适的方式取决于具体的问题和需求。
基于价值的强化学习
基于价值的强化学习(Value-Based Reinforcement Learning)是一种强化学习方法,其目标是学习一个价值函数,用于评估在给定状态下采取不同行动的价值。价值函数通常被定义为在给定状态下采取某一行动后获得的期望奖励。
基于价值的强化学习算法通常使用一种称为价值迭代(Value Iteration)的方法来学习价值函数。价值迭代算法从一个初始价值函数开始,然后不断更新价值函数,直到它收敛到一个稳定的值。
策略优化
策略优化(Policy Optimization)是一种强化学习方法,其目标是直接学习一个策略函数,用于在给定状态下选择最优的行动。策略函数通常被定义为在给定状态下选择某一行动的概率。
策略优化算法通常使用一种称为策略梯度(Policy Gradient)的方法来学习策略函数。策略梯度算法从一个初始策略函数开始,然后不断更新策略函数,以使其在给定状态下选择最优的行动。
深度强化学习
深度强化学习(Deep Reinforcement Learning)是一种强化学习方法,其使用深度学习技术来学习价值函数或策略函数。深度学习技术可以帮助强化学习算法更好地学习价值函数或策略函数,从而提高算法的性能。
深度强化学习算法通常使用一种称为深度强化学习(Deep Reinforcement Learning)的方法来学习价值函数或策略函数。深度强化学习算法从一个初始价值函数或策略函数开始,然后不断更新价值函数或策略函数,直到它收敛到一个稳定的值。
模型基础强化学习
模型基础强化学习(Model-Based Reinforcement Learning)是一种强化学习方法,其使用环境模型来预测状态转移和奖励。环境模型可以是概率模型,也可以是确定性模型。
模型基础强化学习算法通常使用一种称为模型预测控制(Model Predictive Control)的方法来进行决策。模型预测控制算法从一个初始状态开始,然后使用环境模型来预测未来的状态转移和奖励。基于这些预测,模型预测控制算法选择一个行动,以最大化未来的奖励。
多智能体强化学习
多智能体强化学习(Multi-Agent Reinforcement Learning)是一种强化学习方法,其涉及多个智能体同时学习和协作,以达到共同的目标。多智能体强化学习算法通常使用一种称为独立 Q 学习(Independent Q-Learning)的方法来进行决策。独立 Q 学习算法从一个初始 Q 表开始,然后不断更新 Q 表,以使每个智能体在给定状态下选择最优的行动。
🍁7. 强化学习给人类文明带来的影响有哪些?
强化学习是机器学习的一个分支,它通过在环境中与其交互并根据其行为获得的奖励或惩罚来学习如何采取行动。强化学习在许多领域都有应用,包括游戏、机器人控制和投资组合管理。
强化学习给人类文明带来的影响是巨大的。它可以帮助我们解决许多现实世界的问题,例如:
- 自动驾驶汽车:强化学习可以帮助自动驾驶汽车在复杂的交通环境中安全行驶。
- 医疗诊断:强化学习可以帮助医生诊断疾病,并制定治疗方案。
- 金融投资:强化学习可以帮助投资者在金融市场中做出更好的决策。
- 工业制造:强化学习可以帮助工厂提高生产效率。
- 能源管理:强化学习可以帮助我们更有效地利用能源。
强化学习还可以帮助我们解决许多其他现实世界的问题。随着强化学习技术的不断发展,我们可以期待它在未来发挥越来越重要的作用。
以下是强化学习给人类文明带来的一些具体影响:
- 强化学习可以帮助我们解决许多现实世界的问题,例如自动驾驶汽车、医疗诊断、金融投资、工业制造和能源管理。
- 强化学习可以帮助我们提高生产效率和降低成本。
- 强化学习可以帮助我们开发新的药物和治疗方法。
- 强化学习可以帮助我们创建更安全的交通系统。
- 强化学习可以帮助我们更好地理解人类行为。
强化学习是一项非常强大的技术,它可以帮助我们解决许多现实世界的问题。随着强化学习技术的不断发展,我们可以期待它在未来发挥越来越重要的作用。
🍁8. 强化学习有哪些存在的问题?
强化学习虽然是一种强大的机器学习方法,但也存在一些问题和挑战:
-
高度依赖环境:强化学习算法的性能受到环境的影响。如果环境复杂或不完全可预测,算法可能面临困难。此外,如果环境发生变化,算法可能需要重新学习适应新环境。
-
需要大量的交互:强化学习算法通常需要与环境进行大量的交互才能学到有效的策略。这可能需要大量的时间和资源,尤其是在复杂任务中。
-
高度敏感的超参数选择:强化学习算法通常有很多超参数需要调整,例如学习率、折扣因子等。选择合适的超参数对算法的性能至关重要,但这往往需要经验和实验。
-
采样效率低:在许多强化学习算法中,需要进行大量的采样来估计价值函数或策略函数。这可能导致采样效率低下,尤其是在连续状态和行动空间中。
-
奖励设计困难:为了训练强化学习算法,需要设计合适的奖励函数来指导学习过程。但奖励函数的设计往往是一个挑战,因为它需要平衡长期和短期奖励,以及避免奖励稀疏和误导。
-
传递学习的挑战:在某些情况下,强化学习算法可能难以将先前学到的知识应用于新的任务或环境中。传递学习(Transfer Learning)在强化学习中仍然是一个具有挑战性的问题。
-
伦理和安全问题:强化学习算法在某些情况下可能会面临伦理和安全问题。例如,在自动驾驶汽车中,如何确保算法的决策是安全和可靠的是一个重要问题。
这些问题和挑战使得强化学习在实际应用中仍然具有一定的局限性。然而,随着研究的不断推进和技术的发展,我们可以期待这些问题得到更好的解决,从而使强化学习在更广泛的领域中发挥作用。
🍁9. 强化学习在人工智能中的应用场景是什么?
强化学习在人工智能中有广泛的应用场景,包括但不限于以下几个方面:
-
游戏:强化学习在游戏领域有着重要的应用。例如,AlphaGo使用强化学习算法在围棋比赛中战胜人类世界冠军选手。此外,强化学习还可用于训练智能体玩电子游戏,如Atari游戏、星际争霸等。
-
机器人控制:强化学习可应用于机器人控制,使机器人能够在复杂和动态的环境中做出智能决策。例如,强化学习可用于训练机器人在不同场景下执行任务,如自主导航、物体抓取和协作操作等。
-
自动驾驶:强化学习在自动驾驶领域具有重要应用。它可以帮助自动驾驶汽车在复杂的交通环境中做出决策和规划路径,以确保安全和高效的驾驶。
-
金融和投资:强化学习可应用于金融和投资领域,帮助分析市场数据、预测股票价格、优化投资组合和制定交易策略。
-
资源管理:强化学习可用于优化资源管理,如能源管理、水资源分配、网络流量控制等。它可以帮助优化资源利用效率,提高系统性能和可持续性。
-
医疗保健:强化学习可应用于医疗保健领域,如医学诊断、药物发现和治疗方案优化。它可以帮助医生做出更准确的诊断和治疗决策,提高医疗效果。
-
自然语言处理:强化学习可用于自然语言处理任务,如机器翻译、对话系统和语音识别。它可以帮助系统从用户反馈中学习,并改进其语言处理能力。
这些只是强化学习在人工智能中的一些应用场景,随着技术的不断进步,我们可以预见强化学习在更多领域的应用和创新。
🍁10. 强化学习的主流算法有哪些?
强化学习有许多主流算法,下面是其中一些常见的算法:

1. Q学习(Q-Learning):Q学习是一种基于值函数的强化学习算法,用于学习最优策略。它通过维护一个Q值表来估计每个状态行动对的价值,并使用贝尔曼方程进行更新。

2. SARSA:SARSA算法也是一种基于值函数的强化学习算法,类似于Q学习。不同的是,SARSA在更新Q值时采用了当前策略下的行动,而不是选择最优行动。

3. DQN(Deep Q-Network):DQN是一种基于深度神经网络的强化学习算法。它将Q学习与深度神经网络相结合,用于处理具有高维状态空间的问题。

4. A3C(Asynchronous Advantage Actor-Critic):A3C是一种基于策略梯度的强化学习算法。它使用多个并行的智能体来学习策略,并通过优势函数来估计行动的优势。

5. PPO(Proximal Policy Optimization):PPO是一种基于策略梯度的强化学习算法,用于优化策略。它通过近端政策优化方法来更新策略,以避免更新过大的问题。

6. TRPO(Trust Region Policy Optimization):TRPO也是一种基于策略梯度的强化学习算法。它通过限制策略更新的KL散度来保证策略的稳定性。
这些算法只是强化学习中的一部分,还有许多其他算法和变体。选择合适的算法取决于具体的问题和应用场景。

相关文章:
初识人工智能,一文读懂强化学习的知识文集(5)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...
视频封面提取:精准截图,如何从指定时长中提取某一帧图片
在视频制作和分享过程中,一个有吸引力的封面或截图往往能吸引更多的观众点击观看。有时候要在特定的时间段内从视频中提取一帧作为封面或截图。如果每个视频都手动提取的话就会耗费很长时间,那么如何智化能批量提取呢?现在一起来看下云炫AI智…...

Shopify 开源 WebAssembly 工具链 Ruvy
最近,Spotify 开源了Ruvy,一个 WebAssembly 工具链,能够将 Ruby 代码转换为 Wasm 模块。Ruvy 基于ruby.wasm, 用 Rust 实现,提升了性能并简化了 Wasm 模块的执行。 Ruvy 利用了ruby.wasm提供的 Ruby 解释器模块,并使用wasi-vfs (WASI 虚拟文件系统)将其与所有指定的 Rub…...

zxjy008- 项目集成Swagger
Swagger可以生成在线文档,还可以进行接口测试。 1、创建common模块(maven类型) 为了让所有的微服务子子模块都可以使用,可以在guli_parent父工程下面创建公共模块 1.1 在guli_parent父工程下面创建公共模块 配置: groupId:com…...

使用linux CentOS本地部署SQL Server数据库
🌈个人主页:聆风吟 🔥系列专栏:数据结构、Cpolar杂谈 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. 安装sql server二. 局域网测试连接三. 安装cpolar内网穿透四. 将sqlserver映射…...
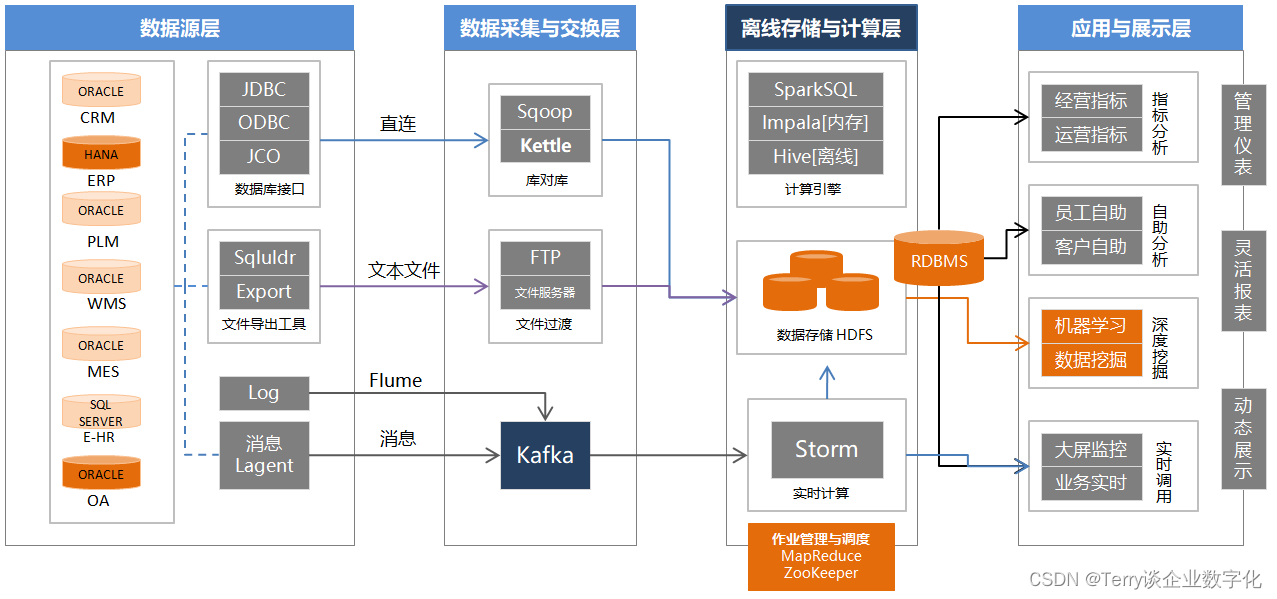
理解基于 Hadoop 生态的大数据技术架构
转眼间,一年又悄然而逝,时光荏苒,岁月如梭。当回首这段光阴,不禁感叹时间的匆匆,仿佛只是一个眨眼的瞬间,一年的旅程已成为过去,而如今又到了画饼的时刻了 ! 基于 Hadoop 生态的大数…...

【Go】Go语言基础内容
变量声明: 变量声明:在Go中,变量必须先声明然后再使用。声明变量使用 var 关键字,后面跟着变量名和类型,如下所示: var age int这行代码声明了一个名为 age 的整数变量。 变量初始化:您可以在声…...

HP-UNIX 系统安全基线 安全加固操作
目录 账号管理、认证授权 账号 ELK-HP-UX-01-01-01 ELK -HP-UX-01-01-02 ELK -HP-UX-01-01-03 ELK-HP-UX-01-01-04 ELK-HP-UX-01-01-05 口令 ELK-HP-UX-01-02-01 ELK-HP-UX-01-02-02 ELK-HP…...
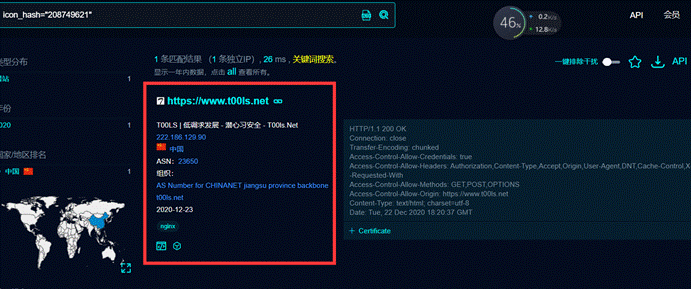
第九天:信息打点-CDN绕过篇amp;漏洞回链amp;接口探针amp;全网扫描amp;反向邮件
信息打点-CDN绕过篇 cdn绕过文章:https://www.cnblogs.com/qiudabai/p/9763739.html 一、CDN-知识点 1、常见访问过程 1、没有CDN情况下传统访问:用户访问域名-解析服务器IP–>访问目标主机 2.普通CDN:用户访问域名–>CDN节点–>…...
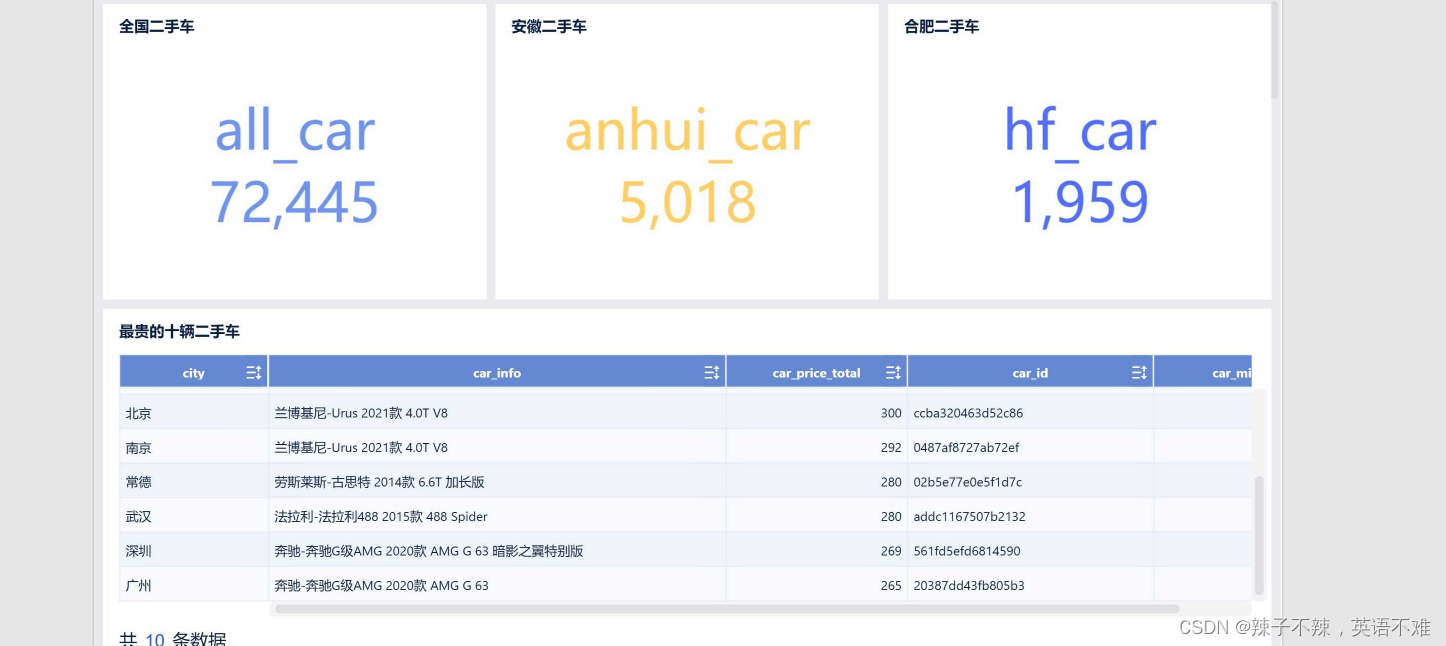
【利用二手车数据进行可视化分析】
利用二手车数据进行可视化分析 查看原始数据去除重复数据需求分析1.统计全国总共有多少量二手车,用KPI图进行展示2.统计安徽总共有多少量二手车,用KPI图进行展示3.统计合肥总共有多少量二手车,用KPI图进行展示4.取最贵的10辆二手车信息&#…...

快速测试 3节点的redis sentinel集群宕机2个节点以后是否仍能正常使用
有同事问我,三个redis sentinel节点,宕机两个节点以后,是否还能够正常的通过redis sentinel正常访问redis的数据。我想了想,理论上是可以的,但是我没试过,今天有时间就测试了一下。搭建环境和测试代码的过程…...

echarts词云图echarts-wordcloud使用方法
1、echarts5.0以下的版本使用 echarts-wordcloud 1.0 的词云 1. 安装 wordCloud 1.0 依赖包npm install echarts-wordcloud12. man.js 注入import echarts-wordcloud 2、echarts5.0及以上的下载 echarts-wordcloud 2.0 版本 注意:npm install echarts-wordcloud …...
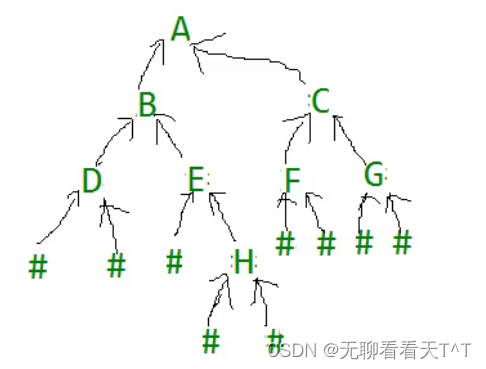
二叉树的OJ练习(二)
通过前序遍历数组构建二叉树 题目:通过前序遍历的数组(ABD##E#H##CF##G##)构建二叉树 TreeNode* TreeCreat(char* a,int* pi) {if(a[*pi] #){(*pi);return NULL; }TreeNode* root (TreeNode*)malloc(sizeof(TreeNode));if(root NULL){p…...
uni-app 微信小程序之自定义navigationBar顶部导航栏
文章目录 1. 实现效果2. App.vue3. pages.json 配置自定义4. 顶部导航栏 使用 微信小程序自定义 navigationBar 顶部导航栏,兼容适配所有机型 1. 实现效果 2. App.vue 在App.vue 中,设置获取的 StatusBar,CustomBar 高度(实现适配…...

前端入门:HTML初级指南,网页的简单实现!
代码部分: <!DOCTYPE html> <!-- 上方为DOCTYPE声明,指定文档类型为HTML --> <html lang"en"> <!-- html标签为整个页面的根元素 --> <head> <!-- title标签用于定义文档标题 --> <title>初始HT…...
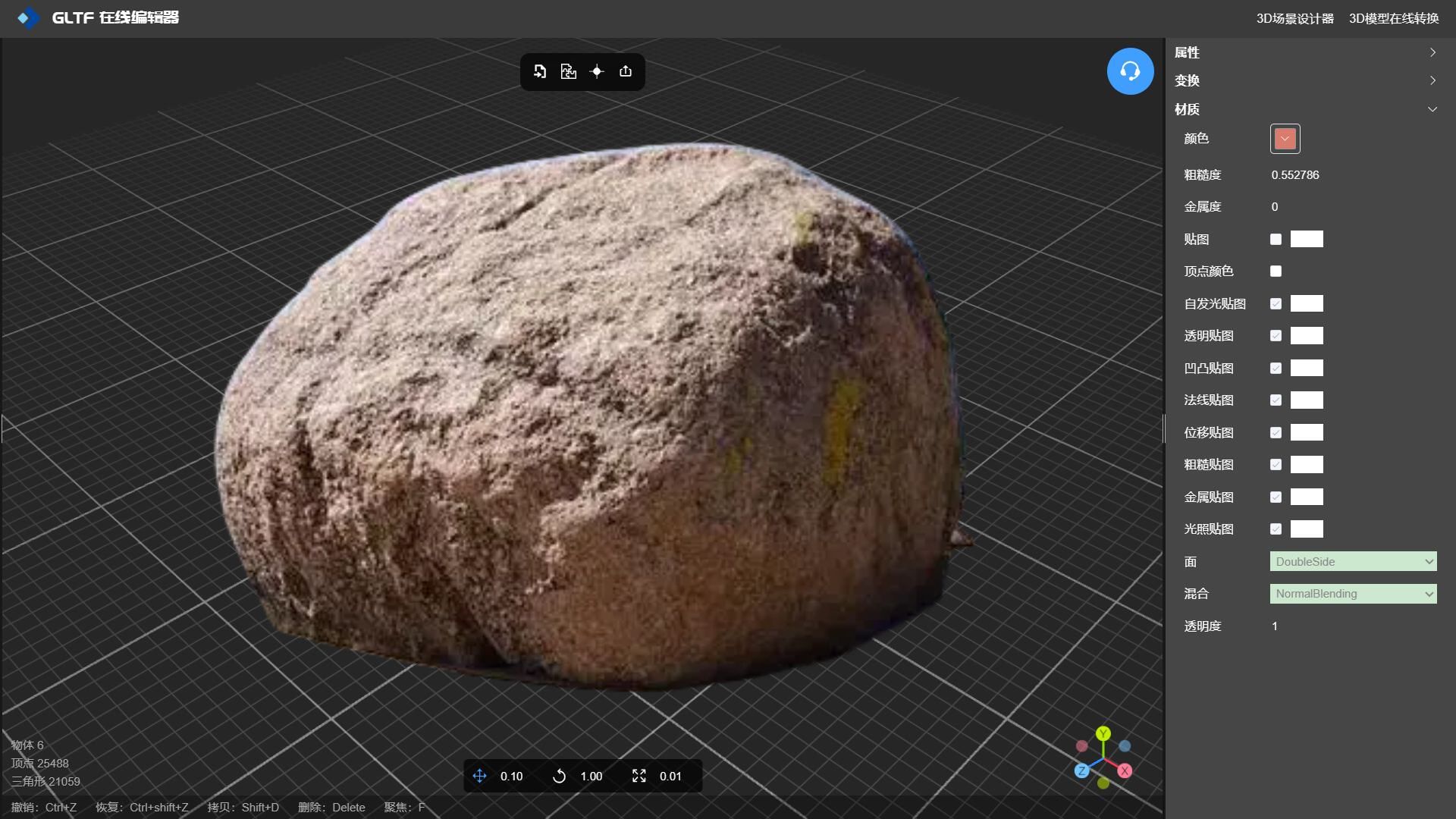
低多边形3D建模石头材质纹理贴图
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 当谈到游戏角色的3D模型风格时,有几种不同的风格…...

【华为OD题库-081】最长的元音子串长度-Java
题目 题目描述: 定义当一个字符串只有元音字母一(a,e,i,o,u,A,E,l,O,U)组成, 称为元音字符串,现给定一个字符串,请找出其中最长的元音字符串,并返回其长度,如果找不到请返回0, 字符串中任意一个连续字符组成…...

第9节:Vue3 指令
如何在UniApp中使用Vue3的指令: <template> <view> <!-- 使用指令 --> <text v-show"isVisible" click"toggleVisibility">点击隐藏/显示</text> <button v-on:click"incrementCount">点击…...

B028-JDBC基础
目录 什么是JDBCJDBC引入持久化JDBC规范 使用JDBC完成CRUDJDBC创建表JDBC CRUD和优化 DAO层的实现 什么是JDBC JDBC引入 Java代码操作数据库的唯一技术:-- JDBC ( java database connection ) 持久化 持久化(persistence):把数据保存到可掉电式存储设…...

ngixn 准备
确认yum可用,确认防火墙,确认SELinux 一项安装 yum -y install gcc make automake pcre-devel zlib zlib-devel openssl openssl-devel参数: gcc:编译依赖gcc环境 pcre:PCRE(Perl Compatible Regular Expressions)是一…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI终极转换指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI终极转换指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&…...

终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求
终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求 【免费下载链接】uncle-novel 📖 Uncle小说,PC版,一个全网小说下载器及阅读器,目录解析与书源结合,支持有声小说与文本小说,可下载mob…...

农业Agent不是“加个模型”,而是重写作业流程:3张架构图讲透农机调度、病虫害预警、供应链匹配的Agent协同范式
更多请点击: https://intelliparadigm.com 第一章:农业Agent不是“加个模型”,而是重写作业流程:3张架构图讲透农机调度、病虫害预警、供应链匹配的Agent协同范式 农业智能化的真正瓶颈,从来不在单点AI能力的强弱&…...

深度解析 | SRE 核心机制:如何通过“错误预算”平衡速度与稳定性?
在网站可靠性工程 (SRE) 的世界中,在创新的速度与系统的稳定性之间找到完美的平衡是一项持续的挑战。虽然开发团队致力于快速发布新功能,但运维团队和 SRE 的目标则是保持系统平稳运行且不中断。这种利益冲突常常导致团队之间的摩擦。而这正是错误预算 (…...

简单说明--程序系统如何对用户身份证实名认证接口api
程序系统对注册用户身份认证,接口将【身份证号码、姓名】上传至接口API判断是否匹配 请求数据: bodys.put("idNo", "330421190210182345"); bodys.put("name", "张某某");响应数据: {"name&quo…...

COMET:基于深度学习的翻译质量评估技术革命
COMET:基于深度学习的翻译质量评估技术革命 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET 在机器翻译技术快速发展的今天,翻译质量评估已成为连接技术研发与实际应用的关键…...

Apache Camel 企业级集成框架技术深度解析
Apache Camel 企业级集成框架技术深度解析 【免费下载链接】camelinaction2 :camel: This project hosts the source code for the examples of the Camel in Action 2nd ed book :closed_book: written by Claus Ibsen and Jonathan Anstey. 项目地址: https://gitcode.com/…...

2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解
2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解 智能侦查赛道概述 2025 睿抗机器人大赛智能侦察赛道是 CAIR 工程竞技赛道下的专业国防装备赛项,以无人侦察车为载体、模拟巷战环境开展军事侦察任务,核心培养学生国防意识与科技创新能力且核心硬件…...

[模型解析] GPT: 模型演进分析从GPT-3到GPT-5.5
GPT 模型演进分析:从 GPT-3 到 GPT-5.5 OpenAI 的 GPT 系列模型在过去几年经历了快速演进,从 2020 年的 GPT-3 到 2026 年的 GPT-5.5,每一次迭代都带来了显著的能力提升和架构创新。本文将系统分析 GPT 模型的演进路径与技术特点。 一、GPT 模…...

三步突破原神60FPS限制:安全高效的游戏性能优化方案
三步突破原神60FPS限制:安全高效的游戏性能优化方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock genshin-fps-unlock 是一款专为《原神》PC版玩家设计的开源帧率解锁工具&…...