Elasticsearch mapping 之 性能相关配置
ES 常见类型
通用类型:
二进制: binary
布尔型: boolean
字符串: keyword, constant_keyword, wildcard, text
别名: alias
对象: object, flattened, nested, join
结构化数据类型: Range, ip, version, murmur3
空间数据类型: geo_point, geo_shape, point, shape
性能相关参数
_all
_all 字段的索引方式是将所有其他字段的值作为一个大字符串索引的,通过include_in_all参数指定哪些字段的内容放入_all 字段,_all 字段在v6.0+已经废弃,v7.0正式移除,但是可以通过copy_to来实现_all相同功能.
PUT /test_index
{"mappings": {"properties": {"field1": {"type": "text","copy_to": "field_all"},"field2": {"type": "text","copy_to": "field_all"},"field_all": {"type": "text"}}}
}POST /test_index/_doc/1
{"field1": "smith","field2": "John@example.com"
}GET /test_index/_search
{"query": {"match": {"field_all": "smith"}}
}现在field_all存的是[“smith”, “John@example.com”].
优点: 当我们想要查询field1或者field2中包含“smith”的时候,只要查询field_all字段就行. 不需要从两个字段的倒排索引中查询两遍.
缺点: 我们不清楚“smith”是在field1还是field2, 需要按照字段或者“smith”在字段中的占比算score的时候就不支持了. 额外需要硬盘空间存储field_all字段内容.
_source
_source 字段用于存储 post 到 ES 的原始 json 文档。为什么要存储原始文档呢?因为 ES 采用倒排索引对文本进行搜索,而倒排索引无法存储原始输入文本。一段文本交给ES后,首先会被分析器(analyzer)打散成单词,为了保证搜索的准确性,在打散的过程中,会去除文本中的标点符号,统一文本的大小写,甚至对于英文等主流语言,会把发生形式变化的单词恢复成原型或词根,然后再根据统一规整之后的单词建立倒排索引,经过如此一番处理,原文已经面目全非。因此需要有一个地方来存储原始的信息,以便在搜到这个文档时能够把原文返回给查询者。和所有被存储的字段一样, _source 字段在被写入磁盘之前先会被压缩。
那么一定要存储原始文档吗?不一定!如果没有取出整个原始 json 结构体的需求,可以在 mapping 中关闭 source 字段或者只在 source 中存储部分字段(使用store)。但是这样做有些负面影响:
(1)不能获取到原文
(2)无法reindex:如果存储了 source,当 index 发生损坏,或需要改变 mapping 结构时,由于存在原始数据,ES可以通过原始数据自动重建index,如果不存 source 则无法实现
(3)无法在查询中使用script:因为 script 需要访问 source 中的字段
(4)如果没有 _source 字段,部分 update 请求不会生效。
如果不需要如上功能,可以禁用_source,减少空间或者指定字段储存到_source, 一般不建议禁用_source,可以通过设置best_compression高压缩比来代替禁用_source.
PUT test_index
{"mappings": {"_source": {"enabled": false}}
}PUT /test_index
{"mappings": {"_source": {"includes": ["field1"],"excludes": ["field2"]}}
}store
store 决定一个字段是否要被单独存储。大家可能会有疑问,_source 里面不是已经存储了原始的文档嘛,为什么还需要一个额外的 store 属性呢?原因如下:
(1)如果禁用了 _source 保存,可以通过指定 store 属性来单独保存某个或某几个字段,而不是将整个输入文档保存到 _source 中。
(2)如果 _source 中有长度很长的文本(如一篇文章)和较短的文本(如文章标题),当只需要取出标题时,如果使用 _source 字段,ES需要读取整个 _source 字段,然后返回其中的 title,由此会引来额外的IO开销,降低效率。此时可以选择将 title 的 store 设置为true,在 _source 字段外单独存储一份。读取时不必在读取整 _source 字段了。但是需要注意,应该避免使用 store 查询多个字段,因为 store 的存储在磁盘上不连续,ES在读取不同的 store 字段时,每个字段的读取均需要在磁盘上进行查询操作,而使用 _source 字段可以一次性连续读取多个字段。
PUT /test_index
{"mappings": {"properties": {"field1": {"type": "text","copy_to": "field_all","store": true},"field2": {"type": "text","copy_to": "field_all"},"field_all": {"type": "text","store": true}},"_source": {"enabled": false}}
}GET /test_index/_search
{"stored_fields": ["field1", "field_all"]
}doc_values
倒排索引可以提供全文检索能力,但是无法提供对排序和数据聚合的支持。如果没有doc_values, 聚合A字段流程如下:
- 通过倒排索引查询到匹配的docId列表
- 根据docId列表去各个分片获取到Doc的_source字段
- 解压缩_source字段获取json字符串里面的A字段
- 统一在内存中进行A字段的聚合
doc_values 本质上是一个序列化的列式存储结构,适用于聚合(aggregations)、排序(Sorting)、脚本(scripts access to field)等操作。当A字段开启doc_values时, 聚合A字段流程如下:
- 通过倒排索引查询到匹配的docId列表
- 根据docId列表去各个分片获取到Doc的doc_values里面的A字段, 由于doc_values是列存储,A字段在内存中是连续的,获取方便
- 统一在内存中进行A字段的聚合
默认情况下,ES几乎会为所有类型的字段存储doc_value,但是 text 或 text_annotated 等可分词字段不支持 doc values 。如果不需要对某个字段进行排序或者聚合,则可以关闭该字段的doc_value存储(doc_values: false),关闭后不能进行聚合和排序操作。
PUT /test_index
{"mappings": {"properties": {"field1": {"type": "keyword","copy_to": "field_all","store": true},"field2": {"type": "keyword","copy_to": "field_all","doc_values": false},"field_all": {"type": "text","store": true}},"_source": {"enabled": false}}
}GET /test_index/_search
{"query": {"match_all": {}},"aggregations": {"terms_field2": {"terms": {"field": "field1"}}}
}index
控制倒排索引,用于标识指定字段是否需要被索引。默认情况下是开启的,如果关闭了 index,则该字段的内容不会被 analyze 分词,也不会存入倒排索引,即意味着该字段无法被搜索。
PUT /test_index
{"mappings": {"properties": {"field1": {"type": "keyword","copy_to": "field_all","store": true,"index": false},"field2": {"type": "keyword","copy_to": "field_all","doc_values": false},"field_all": {"type": "text","store": true}},"_source": {"enabled": true}}
}GET /test_index/_search
{"query": {"match": {"field1": "smith"}}
}enabled
这是一个 index 和 doc_value 的总开关,如果 enabled 设置为false,则这个字段将会仅存在于 source 中,其对应的 index 和 doc_value 都不会被创建。这意味着,该字段将不可以被搜索、排序或者聚合,但可以通过 source 获取其原始值。
相关文章:

Elasticsearch mapping 之 性能相关配置
ES 常见类型 通用类型: 二进制: binary 布尔型: boolean 字符串: keyword, constant_keyword, wildcard, text 别名: alias 对象: object, flattened, nested, join 结构化数据类型: Range, ip, version, murmur3 空间数据类型: geo_point, geo_shape, point, shape 性…...

adb push报错:remote couldn‘t create file: Is a directory
adb push报错:remote couldn‘t create file: Is a directory 出现这个问题可能是电脑本地目录中包含中文或者是目录地址中多包含了一个/ 比如说以下两种路径 1. test/测试音频文件1/a.mp3 2.test/test_audio/ 这两种都是不可以的(我是在as中执行的…...

GitLab 服务更换了机器,IP 地址或域名没有变化时,可能会出现无法拉取或提交代码的情况。
当 GitLab 服务更换了机器,但 IP 地址或域名没有变化时,可能会出现无法拉取或提交代码的情况。 这可能是由于 SSH 密钥或 SSL 证书发生了变化。以下是一些可能的解决步骤: 这可能是由于 SSH 密钥或 SSL 证书发生了变化。以下是一些可能的解决…...

【华为OD题库-076】执行时长/GPU算力-Java
题目 为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务。 假设GPU最多一次执行n个任务,一次执行耗时1秒,在保证GPU不空闲情况下&…...

持续集成交付CICD:Jenkins使用GitLab共享库实现前后端项目Sonarqube
目录 一、实验 1.Jenkins使用GitLab共享库实现后端项目Sonarqube 2.优化GitLab共享库 3.Jenkins使用GitLab共享库实现前端项目Sonarqube 4.Jenkins通过插件方式进行优化 二、问题 1.sonar-scanner 未找到命令 2.npm 未找到命令 一、实验 1.Jenkins使用GitLab共享库实现…...
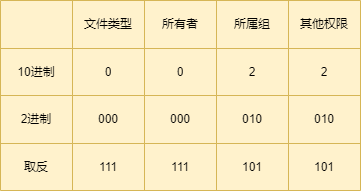
Linux文件结构与文件权限
基于centos了解Linux文件结构 了解一下文件类型 Linux采用的一切皆文件的思想,将硬件设备、软件等所有数据信息都以文件的形式呈现在用户面前,这就使得我们对计算机的管理更加方便。所以本篇文章会对Linux操作系统的文件结构和文件权限进行讲解。 首先…...

CentOS上安装和配置Apache HTTP服务器
在CentOS系统上安装和配置Apache HTTP服务器可以为您的网站提供可靠的托管环境。Apache是开源的Web服务器软件,具有广泛的支持和强大的功能。下面是在CentOS上安装和配置Apache HTTP服务器的步骤: 步骤一:安装Apache HTTP服务器 打开终端&am…...
———ES6迭代器)
前端知识(十二)———ES6迭代器
ES6中的迭代器是一种新的对象,它具有一个next()方法。next()方法返回一个对象,这个对象包含两个属性:value和done。value属性是迭代器中的下一个值,done属性是一个布尔值,表示迭代器是否已经遍历完所有的值。迭代器是一…...
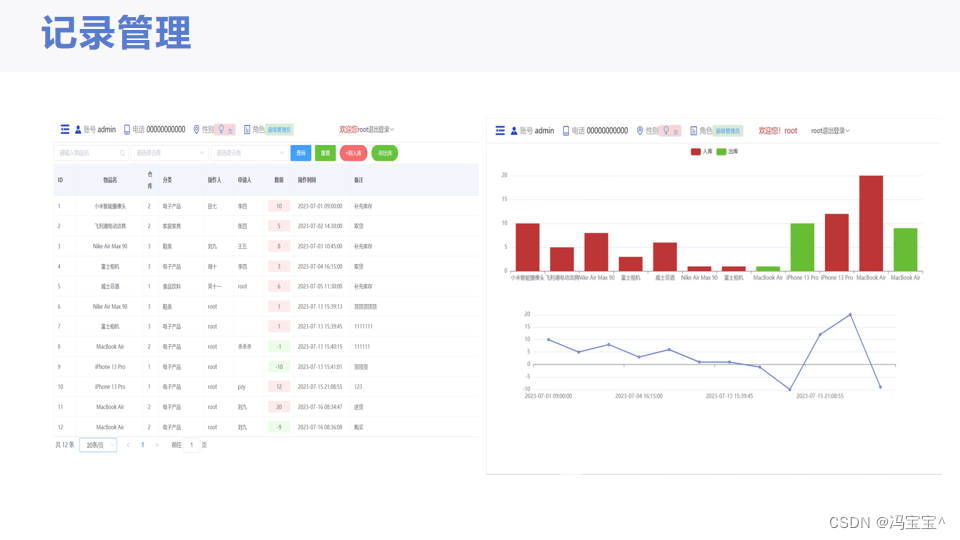
云端仓库平台
SpringBoot MySQL Vue 等技术实现的云端仓库 技术栈 核心框架:SpringBoot 持久层框架:MyBatis-Plus 前端框架:Vue 数据库:MySQL 项目包含源码和数据库文件。 效果图如下:...

php第三方skd自动加载
把mugou-sdk复制到项目下在composer.josn找到classmap加入sdk "autoload": {"classmap": ["mugou-sdk"] },在composer.josn找到files加入sdk "autoload": {"files":[mugou-sdk] },项目目录下运行 composer dump-autoload…...

Golang channle(管道)基本介绍、快速入门
channel(管道)-基本介绍 为什么需要channel?前面使用全局变量加锁同步来解决goroutine的通讯,但不完美 1)主线程在等待所有goroutine全部完成的时间很难确定,我们这里设置10秒,仅仅是估算。 2)如果主线程休眠时间长了,…...

盘点六款颇具潜力的伪原创AI工具
写作作为信息传递的主要媒介,在庞大的信息海洋中,为了在激烈的竞争中脱颖而出,伪原创AI工具成为越来越多写手的神秘利器。在本文中,我们将深入盘点六款颇具潜力的伪原创AI工具,为你揭开它们神秘的面纱。 1. 文心一言 …...
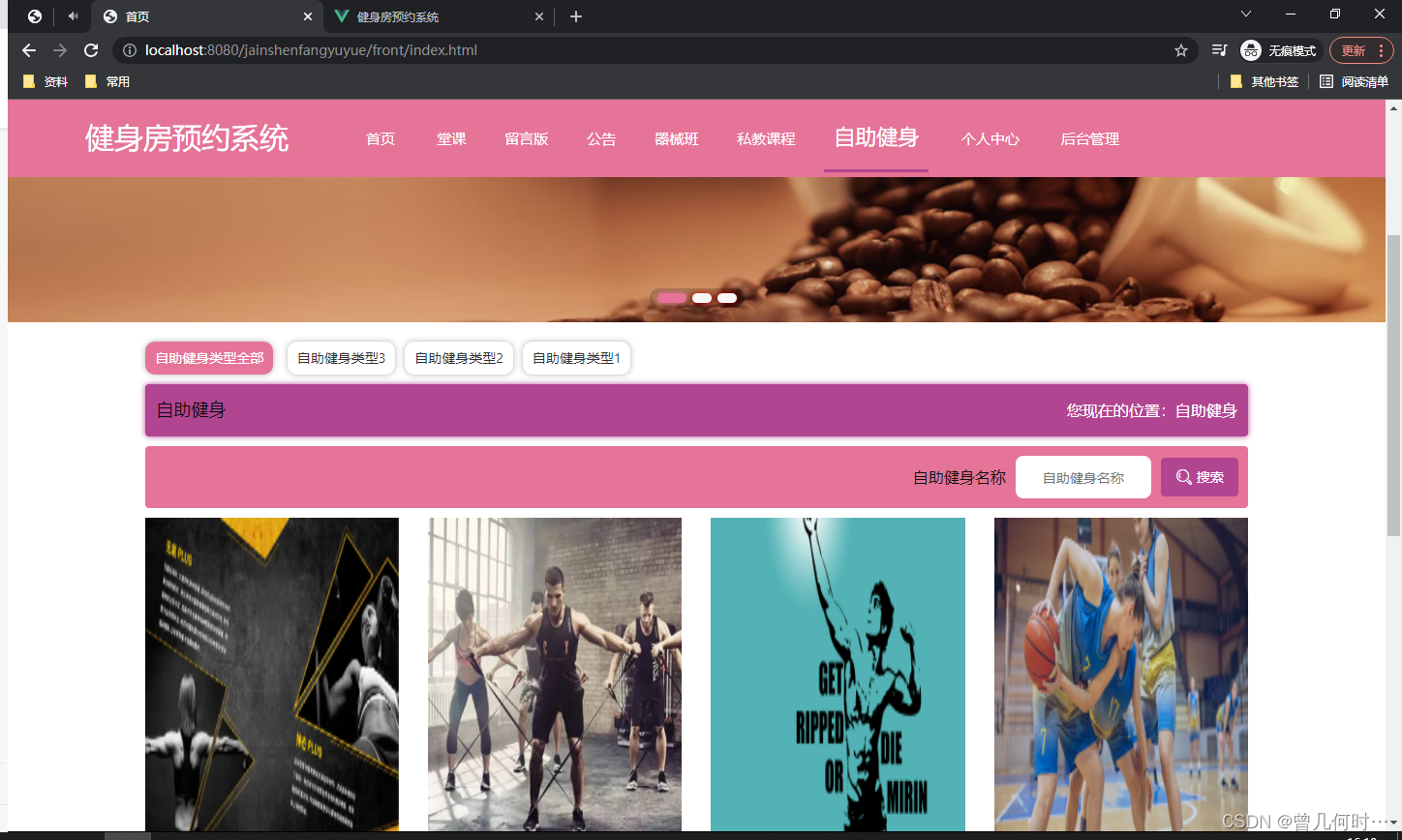
基于SSM的健身房预约系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
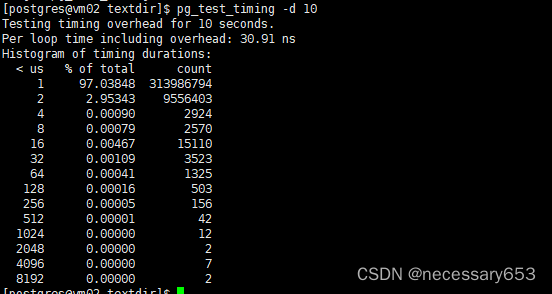
postgresql自带指令命令系列二
简介 在安装postgresql数据库的时候会需要设置一个关于postgresql数据库的PATH变量 export PATH/home/postgres/pg/bin:$PATH,该变量会指向postgresql安装路径下的bin目录。这个安装目录和我们在进行编译的时候./configure --prefix [指定安装目录] 中的prefix参…...
ABAP - Function ALV 02 简单开发一个Function ALV
了解Function ALV: https://blog.csdn.net/HeathlX/article/details/134879766?spm1001.2014.3001.5501程序开发步骤:① TCODE:SE38创建程序 ② 编写程序 DATA gt_spfli TYPE TABLE OF spfli.** Layout 变量定义 (固定使用 直接粘贴复制即可) DATA gs…...

IDEA启动失败报错解决思路
IDEA启动失败报错解决思路 背景:在IDEA里安装插件失败,重启后直接进不去了,然后分析问题解决问题的过程记录下来。方便下次遇到快速解决。也是一种解决问题的思路,分享出去。 启动报错信息 Internal error. Please refer to https…...
密码学学习笔记(二十三):哈希函数的安全性质:抗碰撞性,抗第一原象性和抗第二原象性
在密码学中,哈希函数是一种将任意长度的数据映射到固定长度输出的函数,这个输出通常称为哈希值。理想的哈希函数需要具备几个重要的安全性质,以确保数据的完整性和验证数据的来源。这些性质包括抗碰撞性、抗第一原象性和抗第二原象性。 抗碰…...

STM32-GPIO编程
一、GPIO 1.1 基本概念 GPIO(General-purpose input/output)通用输入输出接口 --GP 通用 --I input输入 --o output输出 通用输入输出接口GPIO是嵌入式系统、单片机开发过程中最常用的接口,用户可以通过编程灵活的对接口进行控制,…...
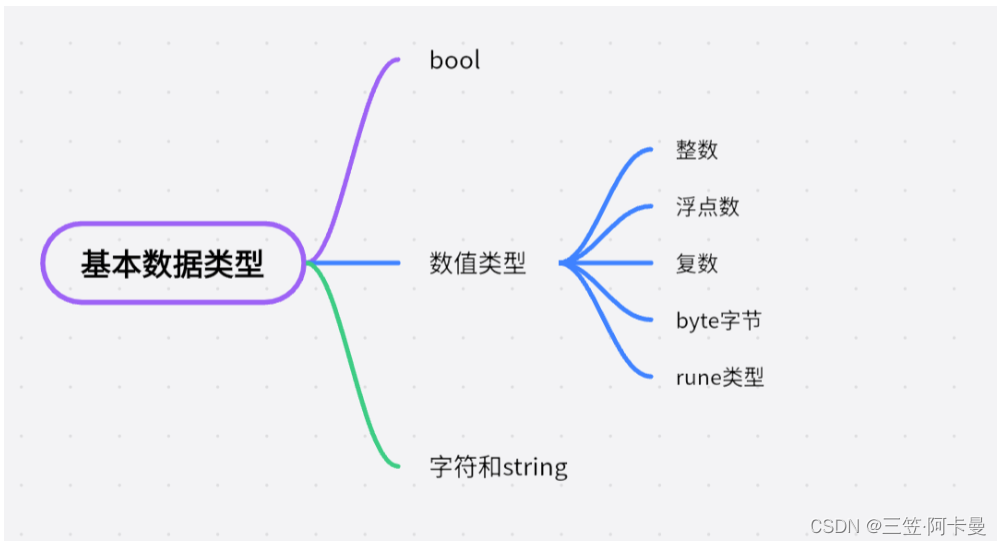
Go语言基础知识学习(一)
Go基本数据类型 bool bool型值可以为true或者false,例子: var b bool true数值型 类型表示范围int8有符号8位整型-128 ~ 127int16有符号16位整型-32768 ~ 32767int32有符号32位整型-2147783648 ~ 2147483647int64有符号64位整型uint8无符号8位整型0 ~ 255uint16…...

Vue 3项目的目录结构
使用vite创建完VUE项目后,使用VS Code编辑器打开项目目录,可以看到一个默认生成的项目目录结构 下图是目录结构: 详细介绍.vscode:存放VS Code编辑器的相关配置。 node_modules:存放项目的各种依赖和安装的插件。…...

DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库!
DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库! 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾经为了下载GitHub上的一个配置文件,却被…...
3分钟让Windows任务栏变透明:TranslucentTB完全指南
3分钟让Windows任务栏变透明:TranslucentTB完全指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Windows系统…...

SpinalHDL流水线设计:从时序抽象到工程实践
1. 项目概述:从Verilog的“线”到SpinalHDL的“流”在数字电路设计里,时序逻辑的流水线(Pipeline)是个老生常谈但又至关重要的概念。无论是为了提升系统主频,还是为了平衡组合逻辑路径的延迟,我们总免不了要…...

冬季施工安全措施,附: 冬季施工总安全技术交底
冬季施工安全措施,附: 冬季施工总安全技术交底 冬季施工特点 1 冬季施工由于施工条件及环境不利,是工程质量事故的多发季节,尤以混凝土工程、钢结构工程居多。如何在冬季施工、抢赶工期的条件下保证项目的质量目标,是施工技术和施工组织的难点。 3 质量事故出现的隐蔽性…...

Arty S7 FPGA开发板:从入门到进阶的硬件加速与嵌入式开发实战
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计的学生,或者对硬件加速、实时信号处理感兴趣,那么“FPGA开发板”这个词对你来说一定不陌生。但面对市场上琳琅满目的开发板,从几百元到上万元不等…...

第一学期结果
关注 1.从安涛老师前三期视频中了解了方向2.从b站了解了555的内部结构3.仿真。4.低通滤波器的基本原理:一、核心定义只允许低频信号顺利通过,阻挡、衰减高频信号的电路。 你电路里作用:滤掉方波里的高频谐波,留下低频基波…...
稀疏记忆微调:在Transformer权重中编码任务专属结构化记忆
1. 这不是又一篇“加个正则就叫持续学习”的水文——我们来拆解这篇真正动了底层参数结构的稀疏记忆微调如果你最近刷过arxiv或者NeurIPS、ICLR的预印本列表,大概率见过标题里带“Continual Learning”“Sparse”“Memory”这几个词组合出现的论文。但说实话&#x…...

UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案
UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案 【免费下载链接】UxPlay AirPlay Unix mirroring server 项目地址: https://gitcode.com/gh_mirrors/uxp/UxPlay UxPlay是一款功能强大的AirPlay Unix镜像服务器,它让Linux、macOS和Unix系统能…...

CANN/cannbot-skills Skill测试框架
Skill 测试框架 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills 基于变更文件识别受影响的 skills,执行对应…...

Pure Live:3大平台聚合,打造你的专属纯净直播空间
Pure Live:3大平台聚合,打造你的专属纯净直播空间 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否厌倦了在多个直播应用间来回切换?…...