CLIP在Github上的使用教程
CLIP的github链接:https://github.com/openai/CLIP
CLIP
Blog,Paper,Model Card,Colab
CLIP(对比语言-图像预训练)是一个在各种(图像、文本)对上进行训练的神经网络。可以用自然语言指示它在给定图像的情况下预测最相关的文本片段,而无需直接对任务进行优化,这与 GPT-2 和 3 的零镜头功能类似。我们发现,CLIP 无需使用任何 128 万个原始标注示例,就能在 ImageNet "零拍摄 "上达到原始 ResNet50 的性能,克服了计算机视觉领域的几大挑战。
Usage用法
首先,安装 PyTorch 1.7.1(或更高版本)和 torchvision,以及少量其他依赖项,然后将此 repo 作为 Python 软件包安装。在 CUDA GPU 机器上,完成以下步骤即可:
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
将上面的 cudatoolkit=11.0 替换为机器上相应的 CUDA 版本,如果在没有 GPU 的机器上安装,则替换为 cpuonly。
import torch
import clip
from PIL import Imagedevice = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)with torch.no_grad():image_features = model.encode_image(image)text_features = model.encode_text(text)logits_per_image, logits_per_text = model(image, text)probs = logits_per_image.softmax(dim=-1).cpu().numpy()print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
API
CLIP 模块提供以下方法:
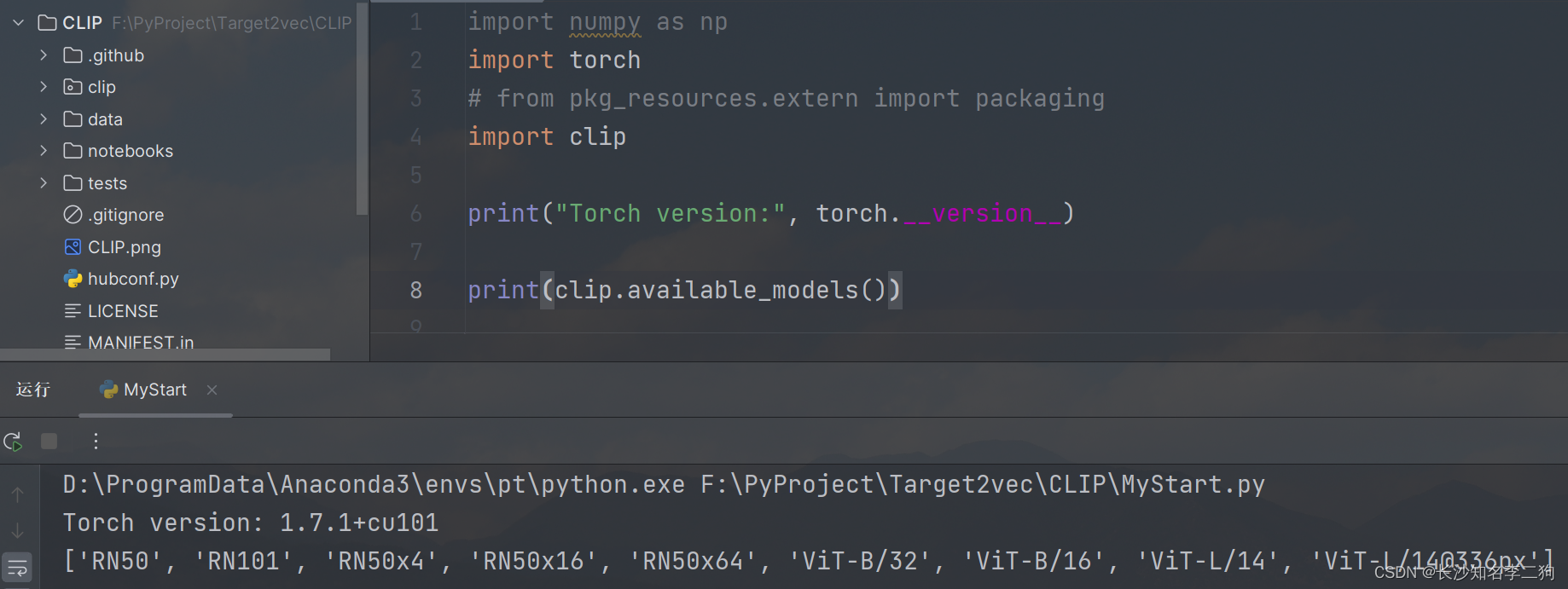
clip.available_models()
返回可用 CLIP 模型的名称。例如下面就是我执行的结果。
clip.load(name, device=..., jit=False)
返回模型和模型所需的 TorchVision 变换(由 clip.available_models() 返回的模型名称指定)。它将根据需要下载模型。name参数也可以是本地检查点的路径。
可以选择指定运行模型的设备,默认情况下,如果有第一个 CUDA 设备,则使用该设备,否则使用 CPU。当 jit 为 False 时,将加载模型的非 JIT 版本。
clip.tokenize(text: Union[str, List[str]], context_length=77)
返回包含给定文本输入的标记化序列的 LongTensor。这可用作模型的输入。
clip.load() 返回的模型支持以下方法:
model.encode_image(image: Tensor)
给定一批图像,返回 CLIP 模型视觉部分编码的图像特征。
model.encode_text(text: Tensor)
给定一批文本标记,返回 CLIP 模型语言部分编码的文本特征。
model(image: Tensor, text: Tensor)
给定一批图像和一批文本标记,返回两个张量,其中包含与每张图像和每个文本输入相对应的 logit 分数。这些值是相应图像和文本特征之间的余弦相似度乘以 100。
More Examples更多实例
Zero-Shot预测
下面的代码使用 CLIP 执行零点预测,如论文附录 B 所示。该示例从 CIFAR-100 数据集中获取一张图片,并预测数据集中 100 个文本标签中最有可能出现的标签。
import os
import clip
import torch
from torchvision.datasets import CIFAR100# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)# Prepare the inputs
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)# Calculate features
with torch.no_grad():image_features = model.encode_image(image_input)text_features = model.encode_text(text_inputs)# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
输出结果如下(具体数字可能因计算设备而略有不同):
Top predictions:snake: 65.31%turtle: 12.29%sweet_pepper: 3.83%lizard: 1.88%crocodile: 1.75%
请注意,本示例使用的 encode_image() 和 encode_text() 方法可返回给定输入的编码特征。
Linear-probe evaluation线性探针评估
下面的示例使用 scikit-learn 对图像特征进行逻辑回归。
import os
import clip
import torchimport numpy as np
from sklearn.linear_model import LogisticRegression
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR100
from tqdm import tqdm# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)# Load the dataset
root = os.path.expanduser("~/.cache")
train = CIFAR100(root, download=True, train=True, transform=preprocess)
test = CIFAR100(root, download=True, train=False, transform=preprocess)def get_features(dataset):all_features = []all_labels = []with torch.no_grad():for images, labels in tqdm(DataLoader(dataset, batch_size=100)):features = model.encode_image(images.to(device))all_features.append(features)all_labels.append(labels)return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()# Calculate the image features
train_features, train_labels = get_features(train)
test_features, test_labels = get_features(test)# Perform logistic regression
classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1)
classifier.fit(train_features, train_labels)# Evaluate using the logistic regression classifier
predictions = classifier.predict(test_features)
accuracy = np.mean((test_labels == predictions).astype(float)) * 100.
print(f"Accuracy = {accuracy:.3f}")
请注意,C 值应通过使用验证分割进行超参数扫描来确定。
See Also
OpenCLIP:包括更大的、独立训练的 CLIP 模型,最高可达 ViT-G/14
Hugging Face implementation of CLIP:更易于与高频生态系统集成
相关文章:
CLIP在Github上的使用教程
CLIP的github链接:https://github.com/openai/CLIP CLIP Blog,Paper,Model Card,Colab CLIP(对比语言-图像预训练)是一个在各种(图像、文本)对上进行训练的神经网络。可以用自然语…...
入职字节外包一个月,我离职了。。。
有一种打工人的羡慕,叫做“大厂”。 真是年少不知大厂香,错把青春插稻秧。 但是,在深圳有一群比大厂员工更庞大的群体,他们顶着大厂的“名”,做着大厂的工作,还可以享受大厂的伙食,却没有大厂…...

SpringBoot的web开发
与其明天开始,不如现在行动! 文章目录 web开发1 web场景1.1 自动配置1.2 默认效果 💎总结 web开发 SpringBoot的web开发能力是由SpringMVC提供的 1 web场景 1.1 自动配置 整合web场景 <dependency><groupId>org.springframewo…...

传染病传播速度
题干 R0值是基本传染数的简称,指的是在没有采取任何干预措施的情况下,平均每位感染者在传染期内使易感者个体致病的数量。数字越大说明传播能力越强,控制难度越大。一个人传染的人的数量可以用幂运算来计算。假设奥密克戎的R0为10࿰…...
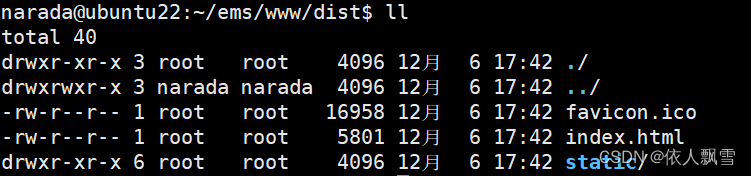
前端打包环境配置步骤
获取node安装包并解压 获取node安装包 wget https://npmmirror.com/mirrors/node/v16.14.0/node-v16.14.0-linux-x64.tar.xz 解压 tar -xvf node-v16.14.0-linux-x64.tar.xz 创建软链接 sudo ln -s 此文件夹的绝对路径/bin/node /usr/local/bin/node,具体执行如下…...
、内部样式表(<style>)、外部样式表(<link>、@import))
css的4种引入方式--内联样式(标签内style)、内部样式表(<style>)、外部样式表(<link>、@import)
1.内联样式(Inline Styles):可以直接在HTML元素的style属性中定义CSS样式。 例如: <p style"color: red; font-size: 16px;">这是一段红色的文本</p>内联样式适用于对单个元素应用特定的样式,…...

GPT-4 变懒了?官方回复
你是否注意到,最近使用 ChatGPT 的时候,当你向它提出一些问题,却得到的回应似乎变得简短而敷衍了?对于这一现象,ChatGPT 官方给出了回应。 译文:我们听到了你们所有关于 GPT4 变得更懒的反馈!我…...

编译器和 IR:LLVM IR、SPIR-V 和 MLIR
编译器通常是各种开发工具链中的关键组件,可提高开发人员的工作效率。编译器通常用作独立的黑匣子,它使用高级源程序并生成语义上等效的低级源程序。不过,它仍然是内部结构倾向的;内部之间流动的内容就称为中间表示 (IR࿰…...

蓝牙物联网对接技术难点有哪些?
#物联网# 蓝牙物联网对接技术难点主要包括以下几个方面: 1、设备兼容性:蓝牙技术有多种版本和规格,如蓝牙4.0、蓝牙5.0等,不同版本之间的兼容性可能存在问题。同时,不同厂商生产的蓝牙设备也可能存在兼容性问题。 2、…...

漫谈Uniapp App热更新包-Jenkins CI/CD打包工具链的搭建
零、写在前面 HBuilderX是DCloud旗下的IDE产品,目前只提供了Windows和Mac版本使用。本项目组在开发阶段经常需要向测试环境提交热更新包,使用Jenkins进行CD是非常有必要的一步。尽管HBuilderX提供了CLI,但Jenkins服务通常都是搭建在Linux环境…...
Axure简单安装与入门
目录 一.Axure简介 二.应用场景 三.安装与汉化 3.1.安装 3.2.汉化 四. 入门 4.1.复制、剪切及粘贴区域 4.2.选择模式 4.3. 插入形状 4.4.预览、共享 感谢大家观看!希望能帮到你哦!!! 一.Axure简介 Axure RP是一款专业的原型…...
———前端开发与后端开发有什么区别)
前端知识笔记(四十五)———前端开发与后端开发有什么区别
前端开发和后端开发是Web开发中的两个关键领域,它们负责不同的任务和功能。下面是前端开发和后端开发之间的主要区别: 前端开发: 用户界面:前端开发主要关注用户界面的开发,包括网页的布局、样式、交互等方面。前端技…...
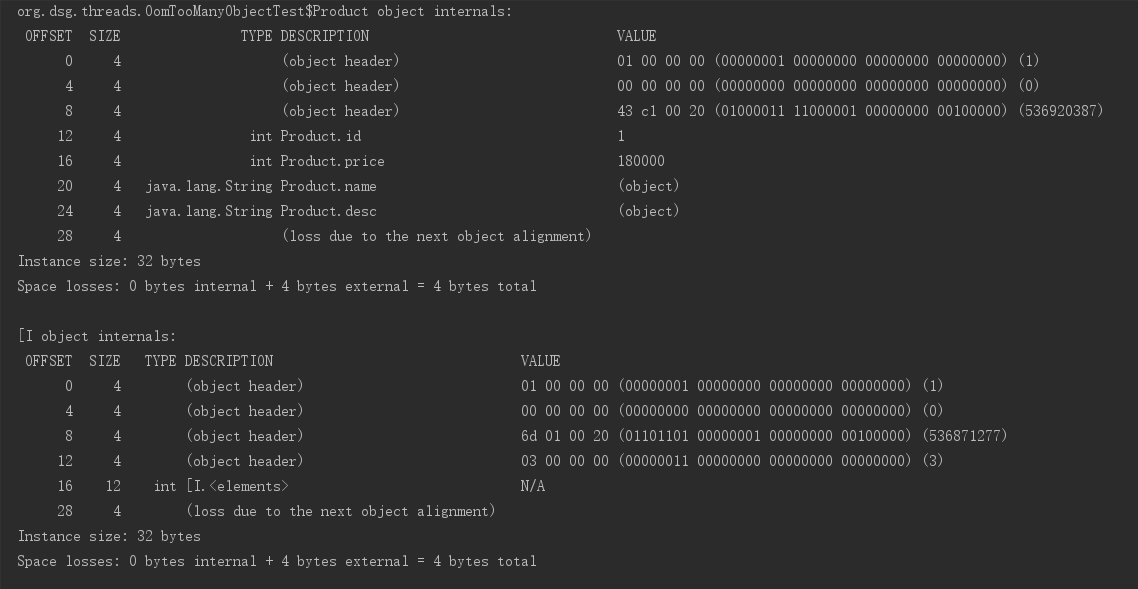
Jol-分析Java对象的内存布局
Jol-分析Java对象的内存布局 Open JDK提供的JOL(Java Object Layout)工具为我们方便分析、了解一个Java对象在内存当中的具体布局情况。本文实验环境为64位HotSpot虚拟机。 Java对象的内存布局 Java的实例对象、数组对象在内存中的组成包括:对象头、实例数据和内存…...

基于sfunction builder的c-sfunction编写及案例测试分析
目录 前言 1.前期准备工作及文件说明 1.1前期准备工作 1.2 文件说明 1.3 编译方式...
知识点总结)
【Java期末复习资料】(1)知识点总结
本文章主要是知识点,后续会出模拟卷 以下是选择、填空可能考的知识点,多看几遍,混个眼熟 面向对象程序设计的基本特征是:抽象、封装、继承、多态(后三个是三大特性)Java源文件的扩缀名是.java编译Java App…...

进程、容器与虚拟机的区别
进程、容器与虚拟机 参考:关于进程、容器与虚拟机的区别,你想知道的都在这! 进程、容器与虚拟机的结构图 进程 介绍 进程是一个正在运行的程序,它是一个个可执行文件的实例。当一个可执行文件从硬盘加载到内存中的时候…...
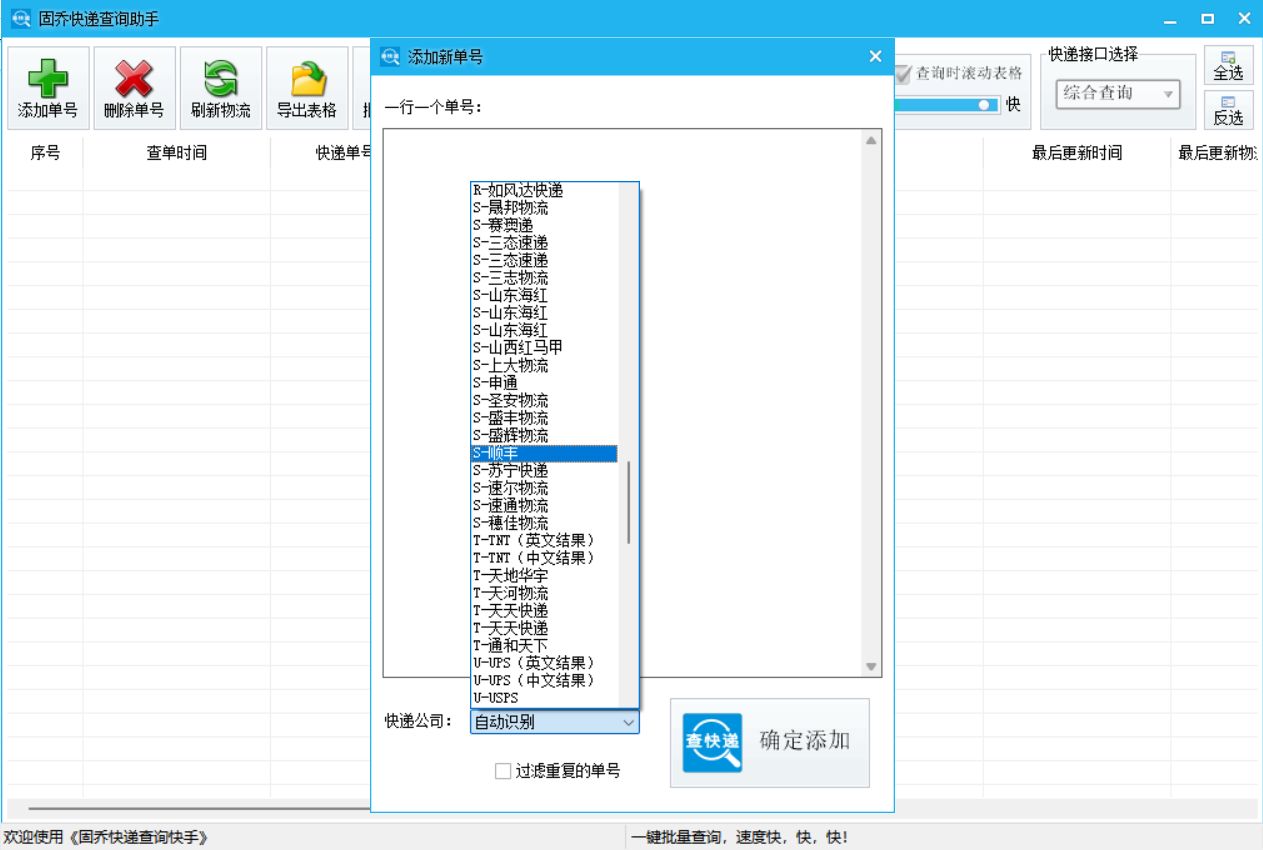
全网快递批量查询的得力助手
在当今社会,网络购物已经成为人们日常生活的重要组成部分。随着网购的普及,快递行业也迅速发展壮大。然而,这也带来了一系列问题:如何快速、准确地查询快递信息?如何批量查询多个快递?今天,我们…...
uniapp开发小程序经验记录
uniapp开发小程序的过程中会遇到很多问题,这里记录一下相关工具优化,便于后来者参考。 每次保存代码后,小程序都跳回首页 针对这个问题,常规的做法就是修改pages配置文件,但是这种方式不便于路由参数的设置ÿ…...

PR自动剪辑视频工具AI智能剪辑插件AutoPod
推荐一款可以提高剪辑效率,节约时间成本的AI人工智能自动剪辑视频制作工具pr插件Autopod,辅助你更快地完成视频内容的编辑工作。 Autopod 插件是一款应用于 Adobe Premiere Pro 软件的插件,用于自动剪辑。该插件能够识别和处理视频和音频素材…...

Visual Studio 2022+Python3.11实现C++调用python接口
大家好!我是编码小哥,欢迎关注,持续分享更多实用的编程经验和开发技巧,共同进步。 查了一些资料,不是报这个错,就是报哪个错,没有找到和我安装的环境的一致的案例,于是将自己的摸索分…...

跨境人都在用的TT跨境出海矩阵软件哪个靠谱?
你有没有过这种经历?拍十几条TT营销视频花了整整一周,上线后播放量却寥寥无几,账号矩阵的日更计划完全跟不上?做跨境TT矩阵,核心痛点从来不是多账号登录,而是内容量产、成本控制和合规风险的三重夹击。到底…...

不再依赖翻译专员:跨马翻译让运营人员也能独立完成高质量多语言出图
一、一个让中型跨境团队头疼的问题 我们团队从最初的单人作战发展到现在的十五人规模,花了大概三年时间。团队架构从最早的"运营一肩挑",逐步细分为运营组、产品组、设计组、客服组和市场组。分工越来越明确,但问题也随之而来——翻…...

北外滩餐饮新店突围战:揭秘AI大模型如何让搜索流量“精准上门”
如果你是北外滩一位新开业的餐厅老板,是否正面临这样的困境:店铺装修精美、菜品独具匠心,但门口罗雀,预期的客流迟迟不来?你试过在平台买推广、请达人探店,效果却如昙花一现,成本居高不下&#…...

**发散创新:基于Python与OpenCV的智能交通流量实时监测系统设计
发散创新:基于Python与OpenCV的智能交通流量实时监测系统设计与实现 在智慧城市建设不断深化的背景下,智能交通系统(ITS) 正成为城市治理现代化的重要突破口。传统的交通信号控制多依赖固定时长或人工经验判断,难以应对…...

Driver Store Explorer终极指南:三步清理Windows冗余驱动,快速释放数十GB空间
Driver Store Explorer终极指南:三步清理Windows冗余驱动,快速释放数十GB空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间越来越…...
proteus、原理图、流程图 1185-基于51单片机的电子秤...)
基于51单片机的电子秤(4挡)proteus、原理图、流程图 1185-基于51单片机的电子秤...
基于51单片机的电子秤(4挡)proteus、原理图、流程图 1185-基于51单片机的电子秤(4挡)proteus、原理图、流程图、物料清单、仿真图、源代码 功能介绍: 1、基本部分 (1)称重范围用开关分为三挡&am…...

具备“看屏幕”能力的Agent能解决哪些传统接口无法解决的问题?实在Agent以ISSUT视觉感知构建企业级AI智能体新高度
2026年4月,人工智能领域正经历从“文本对话”向“具身操作”的范式跨越。根据腾讯云在2026年3月27日发布的《Agent全景产品图谱》,具备“看屏幕”能力的视觉智能体已成为破除数字化转型“最后一步”僵局的核心变量。在过去的一周内,清华大学与…...
)
委托的全面知识总结(C#)
一.定义与本质委托是干什么的?委托就是用来存 方法 的容器你可以把一个方法当成 数据 一样传递1.什么是委托委托是C#中类型安全的函数指针,它是一种“类型”,可以存储,调用,传递一个或多个方法的引用2.核心本质委…...
)
保姆级教程:用PyTorch从零复现DeepLab v3+(附MobileNet v2/Xception双Backbone代码详解)
从零构建DeepLab v3语义分割模型:MobileNet v2/Xception双主干网络实战指南 1. 语义分割与DeepLab v3架构精要 语义分割作为计算机视觉领域的核心任务之一,要求模型对图像中的每个像素进行分类,实现像素级的语义理解。不同于传统的图像分类…...

Keil魔术棒设置详解:为什么你的printf在STM32上不工作?
Keil魔术棒设置详解:为什么你的printf在STM32上不工作? 调试STM32项目时,printf输出功能突然失效是许多开发者遇到的经典问题。明明代码逻辑正确,串口硬件也正常,为什么控制台就是一片寂静?这通常与Keil开…...