【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note
- SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量回复。
- 启发1:像可以用6b、66b依次得到差一点、好一点的target构造排序数据集,进行DPO直接偏好学习或者其他RLHF替代方法(RAILF、ReST等),比直接RLHF更方便训练
- 启发2:为了减少幻觉(如拒绝回答),可以构造排序数据集(如good response为拒绝话术,bad response是没拒绝的胡乱回答)进行RLHF
- 实验:基于chatglm 6b、gpt4构造排序数据集,然后对微调6b后的sft模型进行dpo直接偏好学习训练
- 奖励模型训练:奖励模型通常也采用基于 Transformer 架构的预训练语言模型。在奖励模型中,移除最后一个
非嵌入层,并在最终的 Transformer 层上叠加了一个额外的线性层。无论输入的是何种文本,奖励
模型都能为文本序列中的最后一个标记分配一个标量奖励值,样本质量越高,奖励值越大。 - 在RLHF中(比如MOSS-RLHF)是使用奖励模型来初始化评论家模型(critic model)和奖励模型(reward model),评论家模型也使用奖励模型初始化,便于在早期提供较准确的状态值估计;但是注意PPO会对策略模型、评论家模型训练并更新;奖励模型、参考模型不参与训练。
- 异策略:固定一个演员和环境交互(不需要更新),将交互得到的轨迹交给另一个负责学习的演员训练。PPO就是策略梯度的异策略版本。通过重要性采样(这里使用KL散度)进行策略梯度的更新。PPO解决了传统策略梯度方法的缺点:高方差、低数据效率、易发散等问题。
- PPO-clip算法通过引入裁剪机制来限制策略更新的幅度,使得策略更新更加稳定
文章目录
- note
- 零、强化学习基础知识
- 1. 强化学习框架的六要素
- 一、RLHF对齐
- 1. 训练奖励模型和RL
- 2. RLHF
- 3. 常见的公开偏好数据集
- 二、PPO近端策略优化
- 1. PPO介绍
- 2. PPO效果
- 三、Llama2中的RLHF
- 1. 两个奖励模型
- 2. 拒绝采样步骤
- 四、RLHF的替代技术
- (一)DPO直接偏好优化
- 1. DPO模型
- 2. DPO实验
- 3. 微软的PPO实践
- 4. DPO、PPO、BPO区别
- (二)RLAIF模型
- (三)ReST模型
- (四)Constitutional AI
- (五)RRHF模型
- (六)ReMax模型
- (七)RSO模型
- Reference
零、强化学习基础知识
1. 强化学习框架的六要素
(1)一句话:RL是研究agent智能体和环境交互的问题,目标是使agent在复杂而不确定的环境中最大化奖励值。
- 智能体(Agent):强化学习的主体也就是作出决定的“大脑”;
- 环境(Environment):智能体所在的环境,智能体交互的对象;
- 行动(Action):由智能体做出的行动;
- 奖励(Reward):智能体作出行动后,该行动带来的奖励;
- 状态(State):智能体自身当前所处的状态;
- 目标(Objective):指智能体希望达成的目标。
串起6要素:一个在不断变化的【环境】中的【智能体】,为了达成某个【目标】,需要不断【行动】,行动给予反馈即【奖励】,智能体对这些奖励进行学习,改变自己所处的【状态】,再进行下一步行动,即持续这个【行动-奖励-更新状态】的过程,直到达到目标。
(2)策略与价值:
- agent在尝试各种行为时,就是在学习一个策略policy(一套指导agent在特定状态下行动的规则)
- agent会估计价值value,即预测未来采取某个行为后所能带来的奖励
任何一个有智力的个体,它的学习过程都遵循强化学习所描述的原理。比如说,婴儿学走路就是通过与环境交互,不断从失败中学习,来改进自己的下一步的动作才最终成功的。再比如说,在机器人领域,一个智能机器人控制机械臂来完成一个指定的任务,或者协调全身的动作来学习跑步,本质上都符合强化学习的过程。
(3)奖励模型(Reward Model)和评论模型(Critic Model):
-
奖励模型(Reward Model):奖励模型是强化学习中一个基本元素,它定义了智能体执行特定动作后将得到的奖励。换句话说,奖励模型为智能体在其环境中执行的每个动作提供奖励(正面)或惩罚(负面)。这个模型帮助智能体理解哪些动作是有利的,哪些不是,因此,智能体尝试通过最大化获得的总奖励来找到最优策略。
-
评论模型(Critic Model):评论模型是一种基于值迭代的方法,它在每个状态或动作上评估(或者"评论")期望的未来奖励。评论者用来估计一个动作或状态的长期价值,通常在演员-评论者模型(Actor-Critic Models)中使用,演员选择动作,评论者评估动作。
两者的主要区别在于,奖励模型直接反映了每个动作的即时反馈,而评论模型是对未来奖励的一个预测或估计,关注的是长期价值,通常基于数学期望来进行评估。
一、RLHF对齐
1. 训练奖励模型和RL
用奖励模型训练sft模型,生成模型使用奖励或惩罚来更新策略,以便生成更高质量、符合人类偏好的文本。
| 奖励模型 | RL强化学习 | |
|---|---|---|
| 作用 | (1)学习人类兴趣偏好,训练奖励模型。由于需要学习到偏好答案,训练语料中含有response_rejected不符合问题的答案。 (2)奖励模型能够在RL强化学习阶段对多个答案进行打分排序。 | 根据奖励模型,训练之前的sft微调模型,RL强化学习阶段可以复用sft的数据集 |
| 训练语料 | {‘question’: ‘土源性线虫感染的多发地区是哪里?’, ‘response_chosen’: ‘苏北地区;贵州省剑河县;西南贫困地区;桂东;江西省鄱阳湖区;江西省’, ‘response_rejected’: ‘在热带和亚热带地区的农村。’}, | {‘qustion’:‘这是一个自然语言推理问题:\n前提:要继续做好扶贫工作,帮助贫困地区脱贫致富\n假设:中国有扶贫工作\n选项:矛盾,蕴含,中立’ ‘answer’:‘蕴含。因为前提中提到了要继续做好扶贫工作,这表明中国存在扶贫工作。因此,前提蕴含了假设。’} |
2. RLHF
RLHF(reinforcement learning from human feedback)
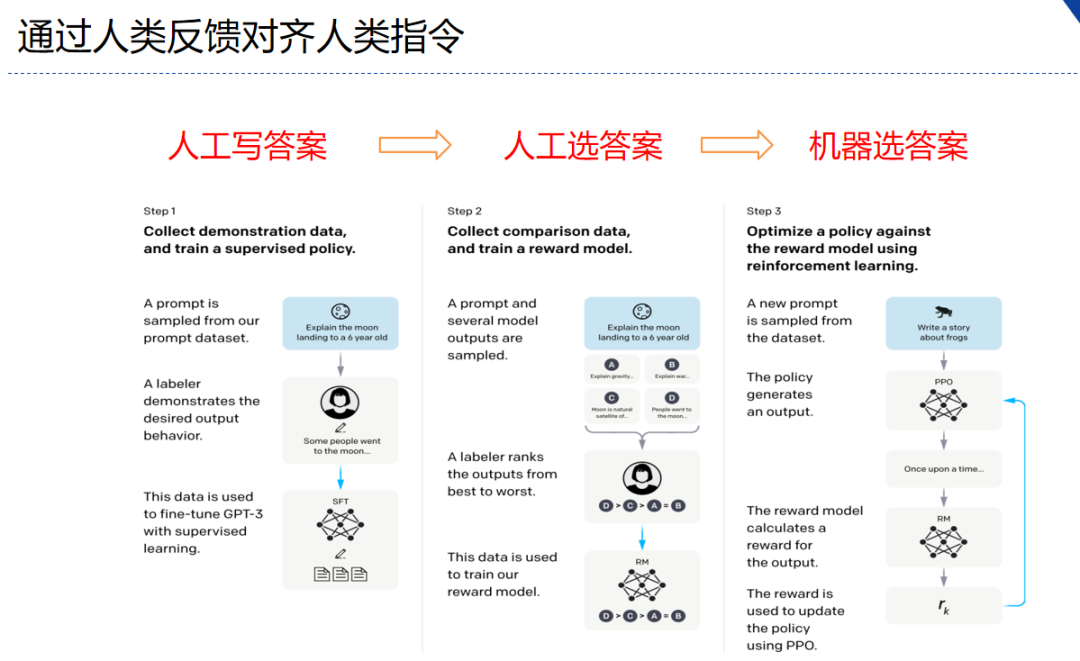
- 分为三个步骤
- step1 我做你看:有监督学习,从训练集中挑出一批prompt,人工对prompt写答案。其实就是构造sft数据集进行微调。
- step2 你做我看:奖励模型训练,这次不人工写答案了,而是让GPT或其他大模型给出几个候选答案,人工对其质量排序,Reward model学习一个打分器;这个让机器学习人类偏好的过程就是【对齐】,但可能会导致胡说八道,可以通过KL Divergence等方法解决。
- instructGPT中奖励模型的损失函数如下,其中 rθ(x,y) 是奖励模型对提示x和完成y的标量输出,具有参数θ, y w y_w yw是 y w y_w yw和 y l y_l yl中更受欢迎的补全,D是人类比较的数据集。 loss ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] \operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_w, y_l\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_w\right)-r_\theta\left(x, y_l\right)\right)\right)\right] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
- 每个样本包括
question、response_chosen、response_rejected键值对,每对样本的loss定义: L ( ψ ) = log σ ( r ( x , y w ) − r ( x , y l ) ) \mathcal{L}(\psi)=\log \sigma\left(r\left(x, y_w\right)-r\left(x, y_l\right)\right) L(ψ)=logσ(r(x,yw)−r(x,yl))- 其中上面的符号: σ \sigma σ 是 sigmoid 函数, r r r 代表参数为 ψ \psi ψ 的奖励模型的值, r ( x , y ) r(x, y) r(x,y) 表示针对输入提示 x x x 和输出 y y y所预测出的单一标量奖励值。
- 上面是instructGPT的ranking loss,但是llama2中增加一个离散函数 m ( r ) m(r) m(r)

- step3 自学成才:PPO训练,利用第二阶段的奖励模型RM计算奖励分数,同时使用PPO(近端策略优化)更新第一步训练得到的sft模型,最大优化该目标函数: objective ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \begin{aligned} \text { objective }(\phi)= & E_{(x, y) \sim D_{\pi_\phi^{\mathrm{RL}}}}\left[r_\theta(x, y)-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right]+ \\ & \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right] \end{aligned} objective (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain [log(πϕRL(x))]
- π φ R L π^{RL}_φ πφRL是学习到的RL策略,
- π S F T π^{SFT} πSFT是监督训练模型,
- D p r e t r a i n D_pretrain Dpretrain 是预训练分布。
- KL奖励系数β和预训练损失系数γ分别控制KL惩罚和预训练梯度的强度。对于“PPO”模型,γ 设为 0。

3. 常见的公开偏好数据集
源自《Llama 2: Open Foundation and Fine-Tuned Chat Models》Table 6:
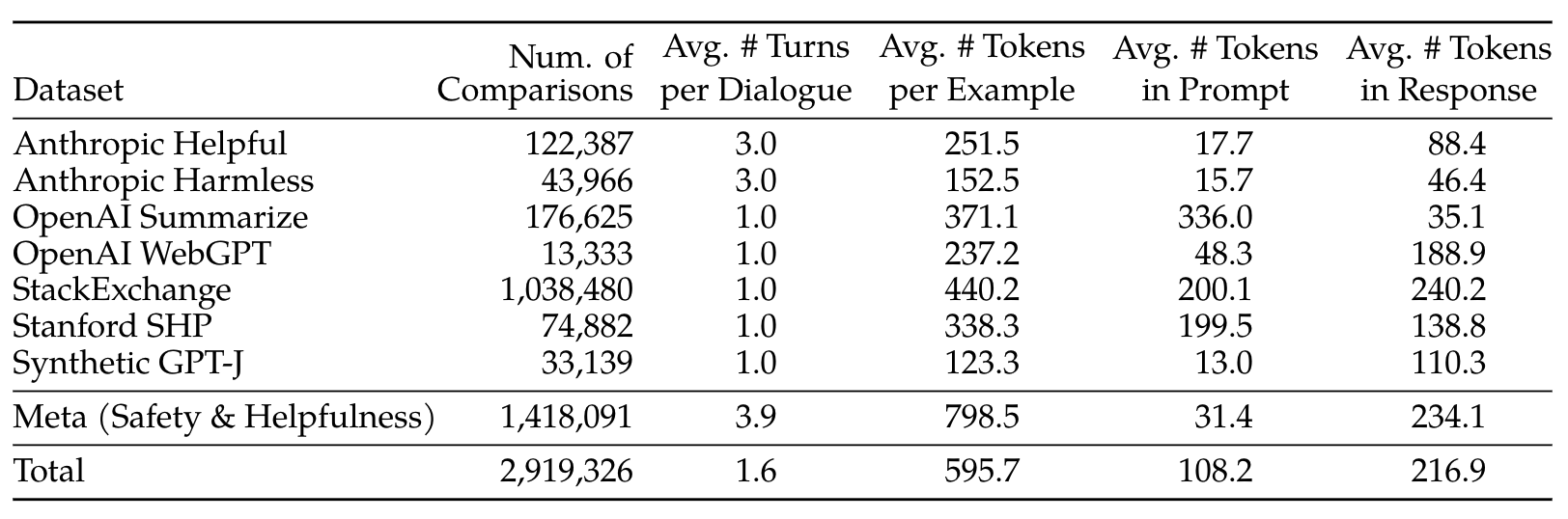
如:https://huggingface.co/datasets/lvwerra/stack-exchange-paired
二、PPO近端策略优化
1. PPO介绍
- 思想:保证策略改进同时,通过一些约束来控制策略更新的幅度;在每次迭代中,通过采样多个轨迹数据来更新策略:
- 使用当前策略对环境交互,收集多个轨迹数据
- 利用第一步的轨迹数据计算当前策略和旧策略之间的KL散度,通过控制KL散度大小来限制策略更新的幅度
- 使用优化器对策略进行更新,使其更加接近当前的样本策略

- 近端策略优化PPO涉及到四个模型:
- (1)策略模型(Policy Model),生成模型回复。
- (2)奖励模型(Reward Model),输出奖励分数来评估回复质量的好坏。
- (3)评论模型(Critic Model/value model),来预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为。
- (4)参考模型(Reference Model)提供了一个 SFT 模型的备份,帮助模型不会出现过于极端的变化。
- 近端策略优化PPO的实施流程如下:
- 环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
- 优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(Generalized Advantage Estimation,GAE)算法来估计优势函数,能够有助于更准确地评估每次行动的好处。
- GAE:基于优势函数加权估计的GAE可以减少策略梯度估计方差
- 优化调整:使用优势函数来优化和调整策略模型,同时利用参考模型确保更新的策略不会有太大的变化,从而维持模型的稳定性。
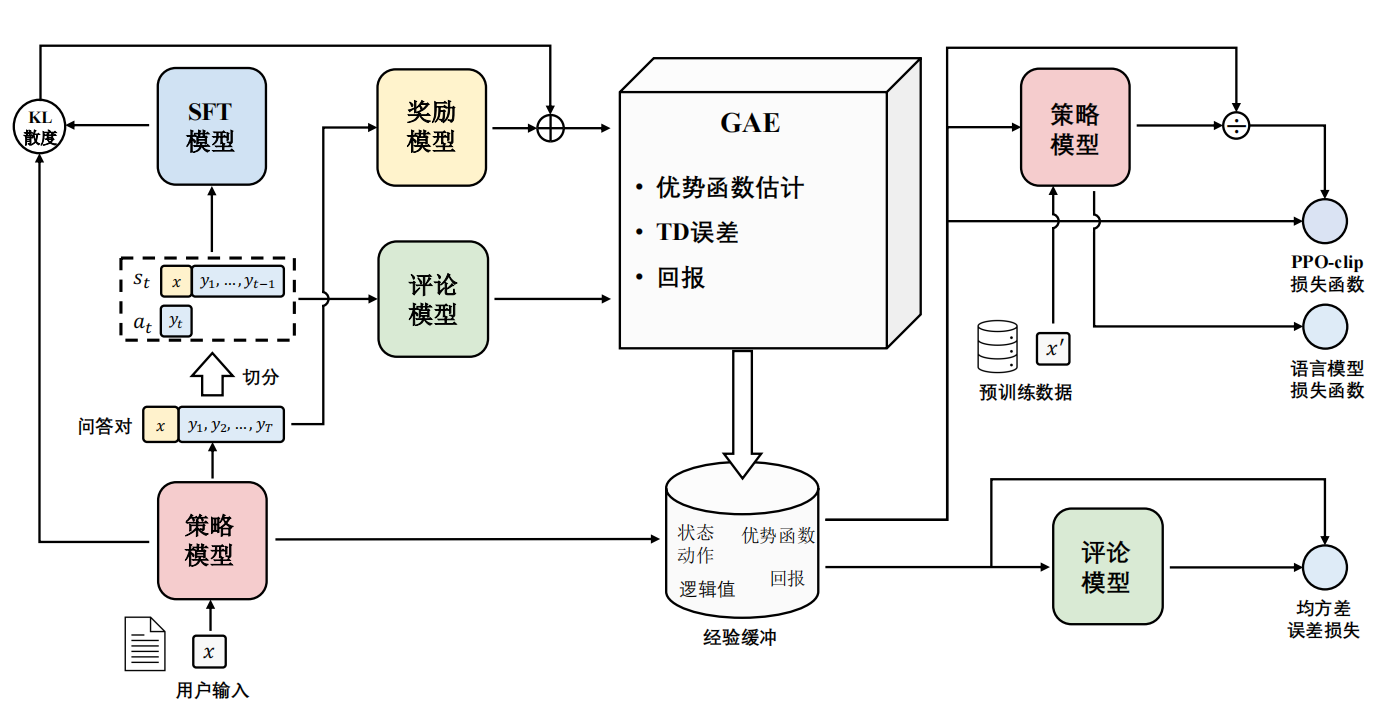
- 相关强化学习概念对应:
- Policy:现有LLM接受输入,进行输出的过程。
- State:当前生成的文本序列。
- Action Space:即vocab,也就是从vocab中选取一个作为本次生成的token。
- KL散度(Kullback-Leibler Divergence),可以衡量两个概率分布之间的差异程度。在 PPO 算法中,KL 散度(Kullback-Leibler Divergence)的计算公式如下:
K L ( π o l d ∣ ∣ π n e w ) = ∑ i π o l d ( i ) l o g ( π o l d ( i ) / π n e w ( i ) ) KL(π_old || π_new) = ∑i π_old(i) log(π_old(i) / π_new(i)) KL(πold∣∣πnew)=∑iπold(i)log(πold(i)/πnew(i))- 其中,π_old 表示旧的策略,π_new 表示当前的样本策略。KL 散度的含义是用 π_old 的分布对 π_new 的分布进行加权,然后计算两个分布之间的差异程度。
- 具体来说,KL 散度的计算方法是首先计算 π_old(i) / π_new(i) 的比值,然后对其取对数并乘以 π_old(i) 来进行加权。最后将所有加权后的结果相加,即可得到 KL 散度的值。这里的KL散度值是一个【惩罚项】,即经过RL训练后模型和SFT后模型的KL散度(繁殖两个模型偏差太多,导致模型效果下降,RLHF的主要目的是alignment)。
注意:KL 散度是一个非对称的度量,即 KL(π_old || π_new) 与 KL(π_new || π_old) 的值可能不相等。在 PPO 算法中,我们通常使用 KL(π_old || π_new) 来控制策略更新的幅度,因为 KL(π_old || π_new) 的值通常比 KL(π_new || π_old) 更容易控制,并且更能够反映出策略改变的方向。
2. PPO效果
在instructGPT论文实验中,效果最好的是GPT-3 + supervised finetuning + RLHF的模型:

三、Llama2中的RLHF
1. 两个奖励模型
- 核心一:两个奖励模型。Llama-2-chat 遵循与 InstructGPT 的 RLHF 第 1 步相同的基于指令数据的监督式微调步骤。然而,在 RLHF 第 2 步,Llama-2-chat 是创建两个奖励模型,而不是一个(因为有用性、安全性某种程度上是对立关系)。
- 一个是基于有用性
- 一个是基于安全性

2. 拒绝采样步骤
- 核心二:拒绝采样(rejection sampling)。Llama-2-chat 模型会经历多个演进阶段,奖励模型也会根据 Llama-2-chat 中涌现的错误而获得更新。它还有一个额外的拒绝采样步骤。即有多个输出,选择奖励函数值最高的一个用于梯度更新。即用RM筛选出当前模型最好的结果进行sft。实验中是将llama2-chat迭代了5轮(前4轮采用拒绝采样,最后一轮使用PPO)。
- 拒绝采样:是蒙特卡洛方法的一种
- 下图:左边是llama2的reward model,右边是gpt4进行judge;都是基于llama2-chat模型进行微调或PPO。
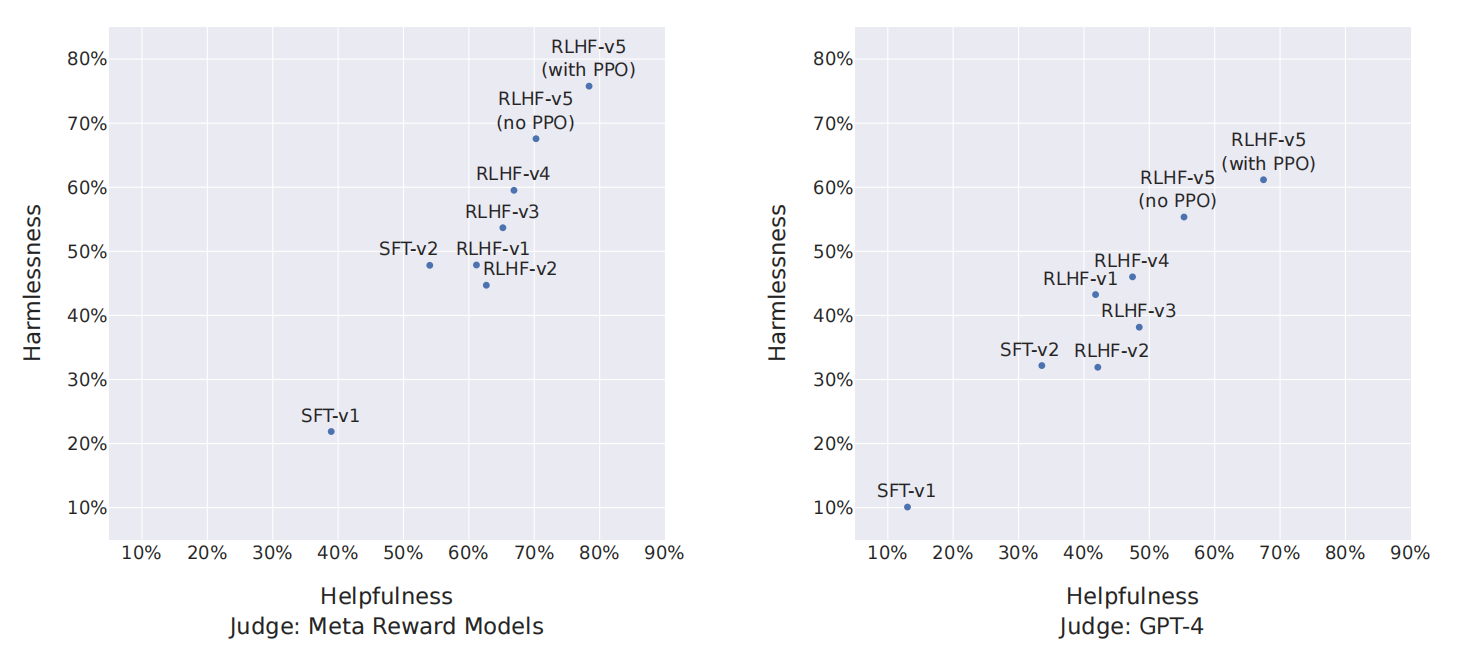
参考维基百科:https://en.wikipedia.org/wiki/Rejection_sampling
四、RLHF的替代技术
(一)DPO直接偏好优化
1. DPO模型
- 论文:《Direct Preference Optimization: Your Language Model is Secretly a Reward Model 》
- 论文地址:https://arxiv.org/abs/2305.18290
- 背景:RLHF是一个复杂、不稳定、难训练的过程(用reward model进行ppo强化学习等),而DPO可以避开训练奖励模型这个步骤,直接对排序数据集进行直接偏好学习。将对奖励函数的损失转为对策略的损失,优化和RLHF相同的目标函数(KL散度限制下,最大化reward)。
- 相关原理: 和RRHF相似,但带有一个sft模型约束(KL散度),保证不加sft Loss情况下训练不崩溃。原本基于RL的目标,现在通过BCE二元交叉熵来优化(不需要再训练期间明确学习奖励函数or从策略中采样)。
- 有监督损失函数,DPO优化的目标函数: max π θ E π θ ( y ∣ x ) [ r ϕ ( x , y ) − β log ∑ y π r e f exp ( 1 β r ϕ ( x , y ) ) ⏟ f ( r ϕ , π r e f , β ) − β log π θ ( y ∣ x ) π r e f ( y ∣ x ) ⏟ K L ] \max _{\pi_\theta} \mathbb{E}_{\pi_\theta(y \mid x)}[\underbrace{r_\phi(x, y)-\beta \log \sum_y \pi_{\mathrm{ref}} \exp \left(\frac{1}{\beta} r_\phi(x, y)\right)}_{f\left(r_\phi, \pi_{\mathrm{ref}}, \beta\right)}-\underbrace{\beta \log \frac{\pi_\theta(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}}_{\mathrm{KL}}] πθmaxEπθ(y∣x)[f(rϕ,πref,β) rϕ(x,y)−βlogy∑πrefexp(β1rϕ(x,y))−KL βlogπref(y∣x)πθ(y∣x)]
- DPO更新参数,目标函数: L D P O ( π θ ; π r e f ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) − β log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ) ] \mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)=-\mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_\theta\left(y_w \mid x\right)}{\pi_{\mathrm{ref}}\left(y_w \mid x\right)}-\beta \log \frac{\pi_\theta\left(y_l \mid x\right)}{\pi_{\mathrm{ref}}\left(y_l \mid x\right)}\right)\right] LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
- 注意:奖励函数 r r r和策略 π π π的关系推倒出来后,就能把ranking loss中的奖励函数 r r r替换
- 目标函数含义:如果是好答案,则尽可能增大被policy策略模型生成的概率
- 对上面的目标函数的梯度: ∇ θ L D P O ( π θ ; π r e f ) = − β E ( x , y w , y l ) ∼ D [ σ ( r ^ θ ( x , y l ) − r ^ θ ( x , y w ) ) ⏟ higher weight when reward estimate is wrong [ ∇ θ log π ( y w ∣ x ) ⏟ increase likelihood of y w − ∇ θ log π ( y l ∣ x ) ⏟ decrease likelihood of y l ] ] , \begin{aligned} & \nabla_\theta \mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)= \\ & -\beta \mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}[\underbrace{\sigma\left(\hat{r}_\theta\left(x, y_l\right)-\hat{r}_\theta\left(x, y_w\right)\right)}_{\text {higher weight when reward estimate is wrong }}[\underbrace{\nabla_\theta \log \pi\left(y_w \mid x\right)}_{\text {increase likelihood of } y_w}-\underbrace{\nabla_\theta \log \pi\left(y_l \mid x\right)}_{\text {decrease likelihood of } y_l}]], \end{aligned} ∇θLDPO(πθ;πref)=−βE(x,yw,yl)∼D[higher weight when reward estimate is wrong σ(r^θ(x,yl)−r^θ(x,yw))[increase likelihood of yw ∇θlogπ(yw∣x)−decrease likelihood of yl ∇θlogπ(yl∣x)]],
- 启发思想:利用chatglm6b、s66b依次得到差一点的target、好一点的target的排序数据集,在这个排序数据集上对sft model直接进行dpo直接偏好学习,比直接rlhf更方便训练(绕过训练reward model的步骤)
# 数据样例
{"question": "我的女儿快两岁了好动是怎么回事,我的女儿快两岁了,还不会坐的时候,当大人抱着坐时(90度),她会把两条腿抬起来使劲,绷直腿和脚尖,累了就放下来歇一下,然后再绷,表情专注还会累得出汗,当时人们说是孩子长身体呢,没有在意。",
"response_chosen": "你好,有的孩子可能会有些小问题,但是大多数孩子是无大碍的,因为这个年龄段正是孩子好动的年龄段,而且每个孩子的性格和秉性不一样,有的孩子天生就是活泼,但是也有极少数可能会有关,至于出汗多,晚上睡眠出汗多,那可能是缺乏钙或其它营养元素。可以给宝宝进行一下和缺钙有关的检查,微量元素和血铅镉化验也很重要。",
"response_rejected": "这个现象可能是由于婴儿发育过程中的骨骼生长造成的。"}
结果:在 RLHF 用于拟合奖励模型的交叉熵损失也可用于直接微调 LLM。根据他们的基准测试,使用 DPO 的效率更高,而且在响应质量方面也通常优于 RLHF/PPO。

2. DPO实验
实验:
- 论文中的实验:探索DPO在参考策略中权衡奖励最大化和 KL-divergence 最小化的效率;并且评估DPO在更大模型和更困难的 RLHF 任务 (包括摘要和对话) 上的性能
- 我的简单实验:直接使用bloomz-560m模型(预训练权重选择Bloom-560m(pretrain),不是Bloomz-560m(pretrain+ft on xP3)),不需要reward_model,使用dpo直接偏好优化,loss如下图,仅100条偏好数据集就能较好收敛。

- 可以使用trl库中的DPOTrainer库:
- 数据:准备排序数据集(我在bloom模型上实验是用的100条公开数据集)
- 原本基于RL的目标,现在通过BCE二元交叉熵来优化
- 有监督损失函数,DPO优化的目标函数: max π θ E π θ ( y ∣ x ) [ r ϕ ( x , y ) − β log ∑ y π r e f exp ( 1 β r ϕ ( x , y ) ) ⏟ f ( r ϕ , π r e f , β ) − β log π θ ( y ∣ x ) π r e f ( y ∣ x ) ⏟ K L ] \max _{\pi_\theta} \mathbb{E}_{\pi_\theta(y \mid x)}[\underbrace{r_\phi(x, y)-\beta \log \sum_y \pi_{\mathrm{ref}} \exp \left(\frac{1}{\beta} r_\phi(x, y)\right)}_{f\left(r_\phi, \pi_{\mathrm{ref}}, \beta\right)}-\underbrace{\beta \log \frac{\pi_\theta(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}}_{\mathrm{KL}}] πθmaxEπθ(y∣x)[f(rϕ,πref,β) rϕ(x,y)−βlogy∑πrefexp(β1rϕ(x,y))−KL βlogπref(y∣x)πθ(y∣x)]
实验结果分析:
(1)文中在多个数据集任务上进行对比实验(下图):
- 使用偏好数据集 D = { x ( i ) , y w ( i ) , y l ( i ) } i = 1 N \mathcal{D}=\left\{x^{(i)}, y_w^{(i)}, y_l^{(i)}\right\}_{i=1}^N D={x(i),yw(i),yl(i)}i=1N
- 左图(情感分类任务):在sentiment generation任务中,在所有的KL散度下,DPO都取得了最大的reward;
- 右图(文本摘要任务):在DR summarization任务中,DPO也超过PPO(使用了GPT4进行评估),并且在不同的temperature下,鲁棒性也更好。
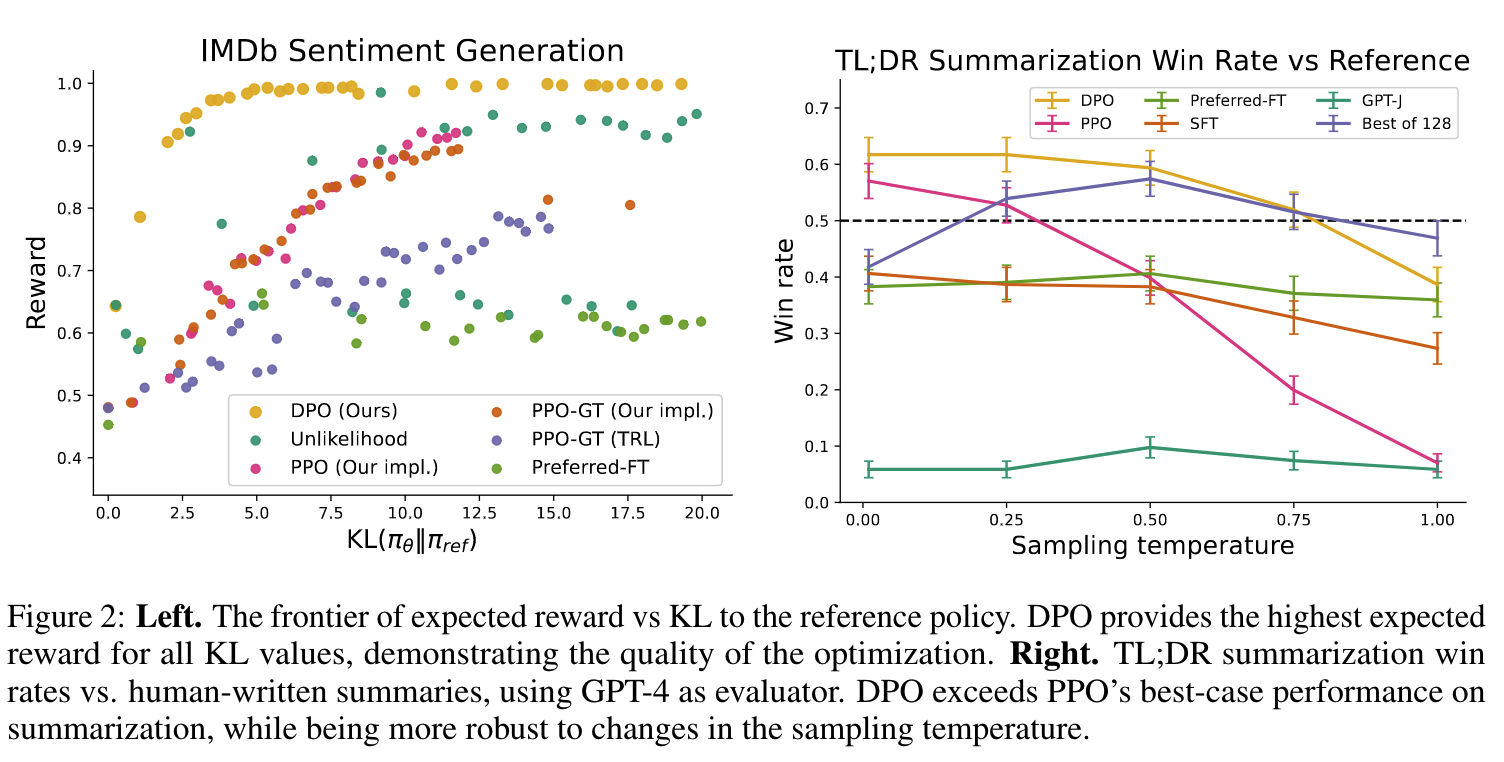
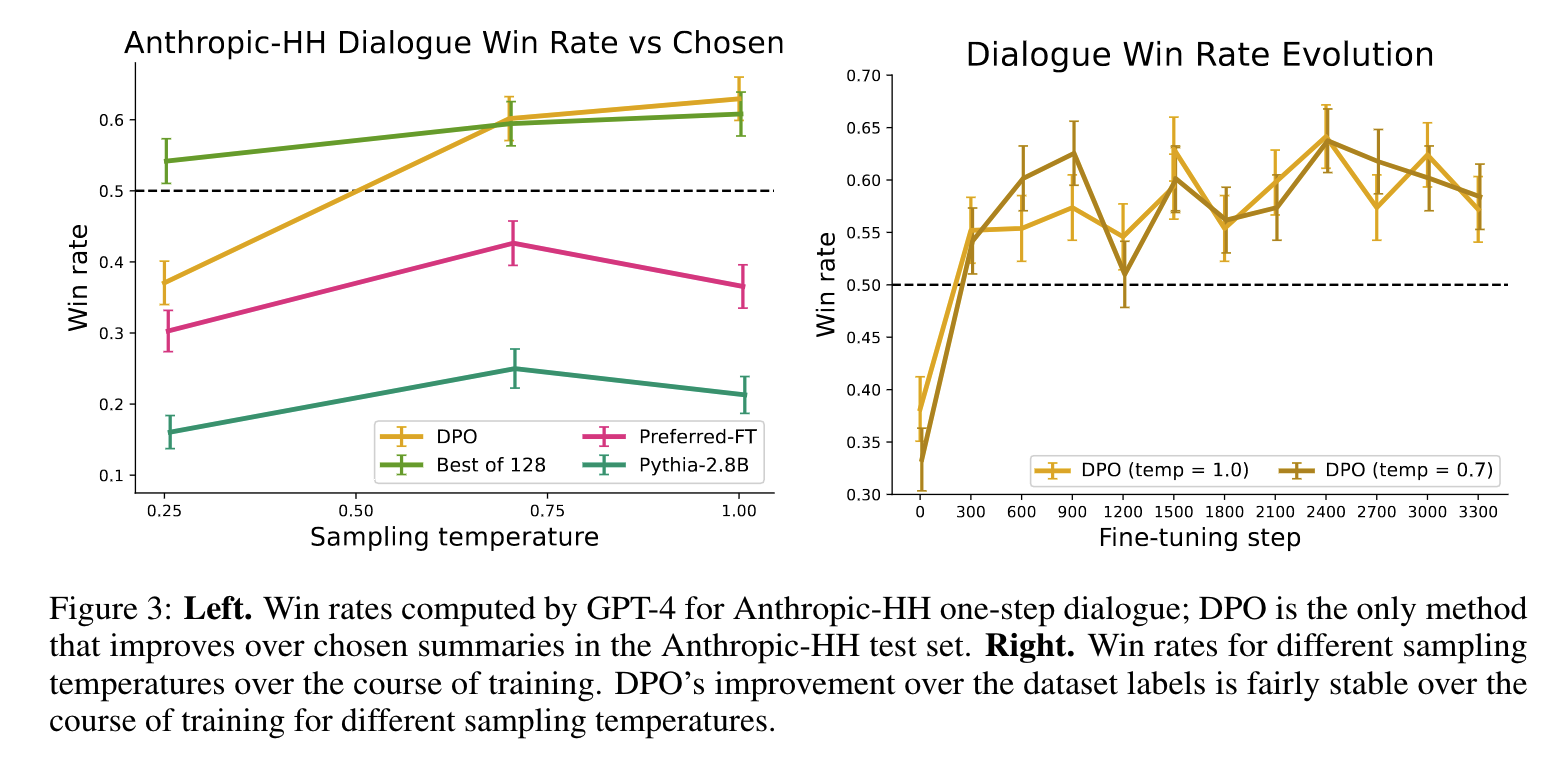
(2)结果分析(下图):
- 左图:在单轮对话任务中,采用GPT-4计算win rate,DPO在temperature=0.75-1.00时,均取得了最好的win rate
- 右图:DPO在训练过程中,表现出了较快的收敛速度,训练较为平稳;在不同temperature(实验分别取0.7和1.0)时DPO的胜率都是接近的,证明了DPO的可靠性。
3. 微软的PPO实践
论文:Contrastive Post-training Large Language Models on Data Curriculum
链接:https://arxiv.org/abs/2310.02263
核心:考虑到排序数据成本,他们直接默认GPT4 > ChatGPT > InstructGPT的效果顺序构造排序数据集,实验后得到以下结论:
(1)用DPO在 GPT4 vs InstructGPT 上训练的效果 > 直接在GPT-4数据精调的效果
(2)先在简单的pair上训练后,再在困难的pair上训练会有更好的效果
实验细节:
(1)训练参数:
- model:llama-7b
- deepspeed zero-3
- temp=0.1
(2)实验结果:
- 排序数据集使用GPT-4 vs. InstructGPT作为pair时效果最好(因为大部分gpt4生成的target都好于后者)
- 用sft model训练DPO,比llama base model直接进行DPO效果好

4. DPO、PPO、BPO区别
BPO实验结果:在 VicunaEval 上使用 GPT-4 进行自动评估,BPO 能够大幅提升 ChatGPT、Claude 等模型的人类偏好,并助力 llama2-13b 模型大幅超过 llama2-70b 的版本。

(二)RLAIF模型
谷歌-RLAIF:Scaling Reinforcement Learning from Human Feedbak with AI Feadback
论文地址:https://arxiv.org/abs/2309.00267
![[图片]](https://img-blog.csdnimg.cn/92effdca27cf4baeb8ba1f4544189bf9.png)
- 核心:之前的是RLHF,这里将H(human)替换为AI给予reward;在Constitutional AI中就提出过RLAIF了(通过混合使用人类与AI偏好,组合Constitutional AI自我修正技术);deepmind贡献则是做实验比较RLAIF和RLHF在文本摘要任务的表现。
- 解决的问题:收集高质量人类偏好标签的瓶颈问题。在 RLHF 中用于训练奖励模型的评分并不一定非要由人类提供,也可以使用 LLM(这里是 PaLM 2)生成。在人类评估者看来,用传统 RLHF 方法和 RLAIF 方法训练的模型得到的结果都差不多。
实验过程:
(1)通过LLM(实验直接使用了PaLM)对两个target按照一定的prompt确定所偏好的target(对应的prompt如下,few-shot):

(2)实验细节:
- position bias:将两个target调换位置再判断一次,最后结果求平均值(经过LLM后得到的是target1和target2的概率)
- 实验细节:labeling preference LLM=PaLM 2;temp=0,top-k的k=40
- RL:使用reward model进行RL,RL没有使用复杂的PPO,而是使用更简单的A2C(Actor Critic)进行RL。
(3)实验结果:
- 证明AI反馈的有效性,当比较RLAIF和RLHF摘要时,人类对两者都表示出相同的偏好。这意味着使用AI反馈进行训练可以达到与使用人类反馈相似的性能,从而为RLHF的可扩展性问题提供了一个潜在的解决方案
- 提供一个潜在的替代方案:RLAIF使用现成的LLM来标记偏好,而不是依赖人类。研究发现,RLAIF和RLHF在改进方面产生了类似的结果。具体来说,对于摘要任务,人类评估者在大约70%的情况下更喜欢RLAIF和RLHF的输出,而不是基线的有监督微调模型。
- 3个评测指标:AI Labeler Alignment、Pairwise Accuracy、WinRate

(三)ReST模型
论文:《Reinforced Self-Training (ReST) for Language Modeling》谷歌 deepmind
论文地址:https://arxiv.org/abs/2308.08998
核心:在之前人类对序列的偏好是使用学得的奖励函数来建模的。ReST 算法将典型 RL pipeline 的数据集增长(Grow)和策略改进(Improve)解耦成两个单独的离线阶段。避免了在线RL方法计算成本高、易受到攻击的问题
ReST优势:
- 与在线 RL 相比,ReST 由于在 Improve step 中利用了 Grow step 的输出,因此计算负担大大减少;
- 策略的质量不在受原始数据集质量的限制(如离线 RL),因为新的训练数据是从 Grow step 中经过采样得到的;
- 检查数据质量并判断对齐变得更加容易,因为 Improve step 和 Grow step 这两个过程是解耦的;
- ReST 简单、稳定,并且只有少量的超参数需要调优。

- ReST能用于对齐 LLM 与人类偏好。ReST 使用一种采样方法来创建一个改进版数据集,然后在质量越来越高的子集上不断迭代训练,从而实现对奖励函数的微调。
- ReST 的效率高于标准的在线 RLHF 方法(比如使用 PPO 的 RLHF),因为其能以离线方式生成训练数据集,但他们并未全面地比较这种方法与 InstructGPT 和 Llama 2 等中使用的标准 RLHF PPO 方法。
算法过程:

(四)Constitutional AI
论文:《Constitutional AI: Harmlessness from AI Feedback》
链接:https://arxiv.org/abs/2212.08073
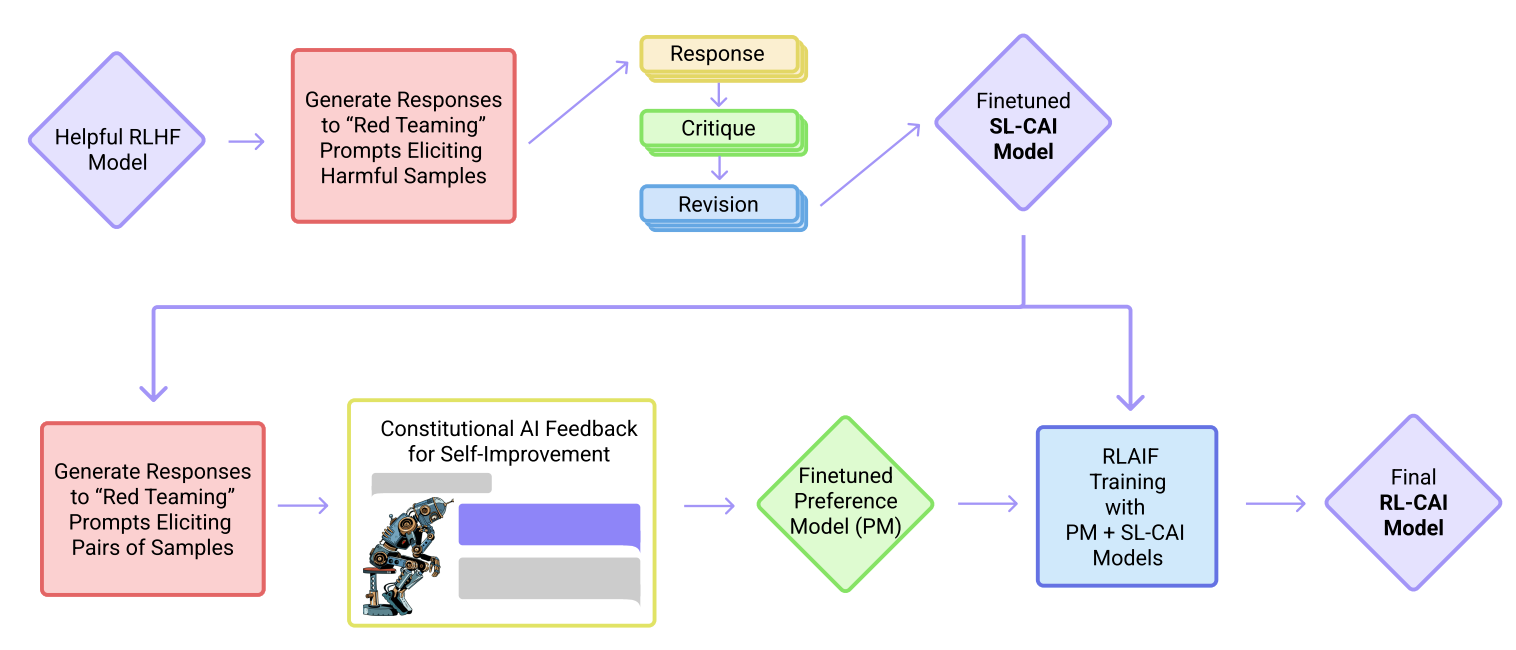
(五)RRHF模型
RRHF(Rank Responses to align Human Feedback)
论文:RRHF: Rank Responses to Align Language Models with Human Feedback without tears 阿里、清华 NeurIPS 2023
链接:https://arxiv.org/pdf/2304.05302.pdf
核心:在RM数据上优化LM,让chosen回答的概率大于rejected回答的概率。在计算句子的条件概率后加上一个ranking loss
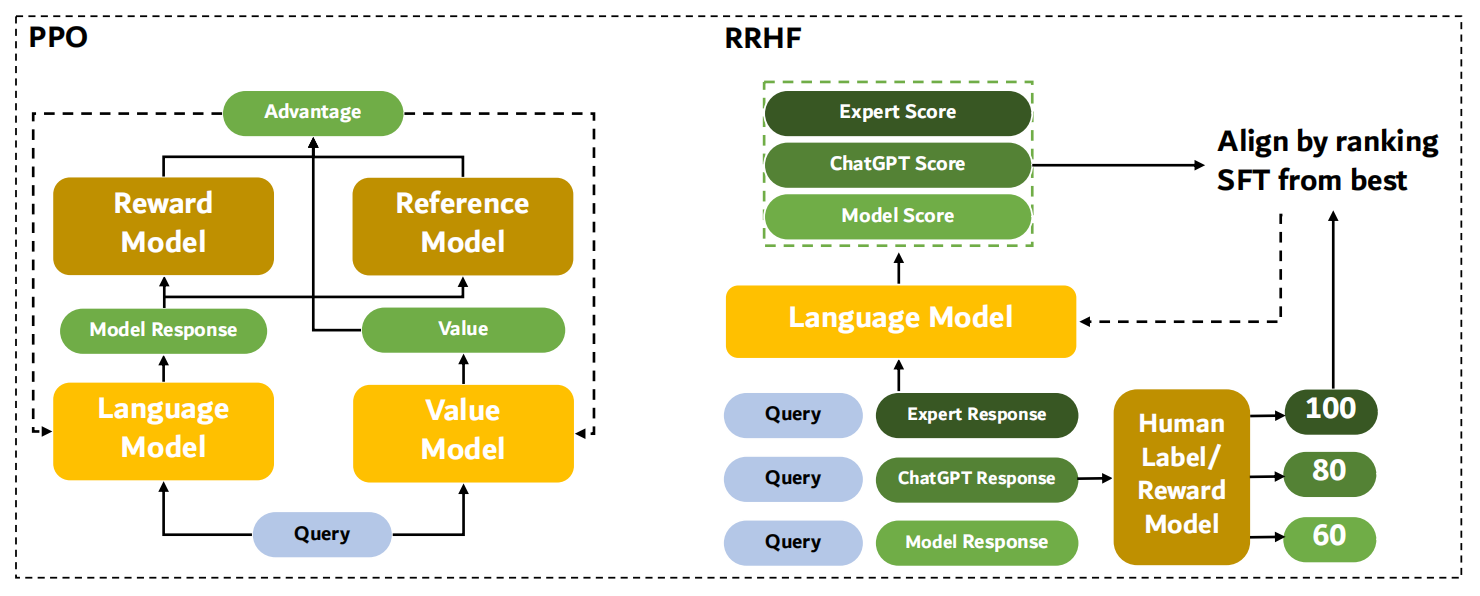
(2)数据实验:尝试了不同的数据采样策略:
- 直接用开源RM的数据
- 用自己的模型生成response,用开源RM进行排序,做出新的RM数据
- 循环执行2,类似强化的思维不断靠自身采样到更好的答案
最后的结论也比较符合直接,是3>2>1。
(六)ReMax模型
论文:ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models 香港大学
核心:RL难点,将多步后的最终目标转为模型loss。传统RL中可能会导致学习不稳定,所以PPO中使用Actor-Critic网络(引入一个助教给模型的每一步打分)。作者提出用强化中的REINFORCE算法来代替PPO,去掉了Critic模型,但作者在实验中同样发现了梯度方差较大优化不稳定的问题,于是增加了一项bias来降低方差。

实验效果:经过ReMax的1.3b模型超过了只经过sft的llama2-7b模型。
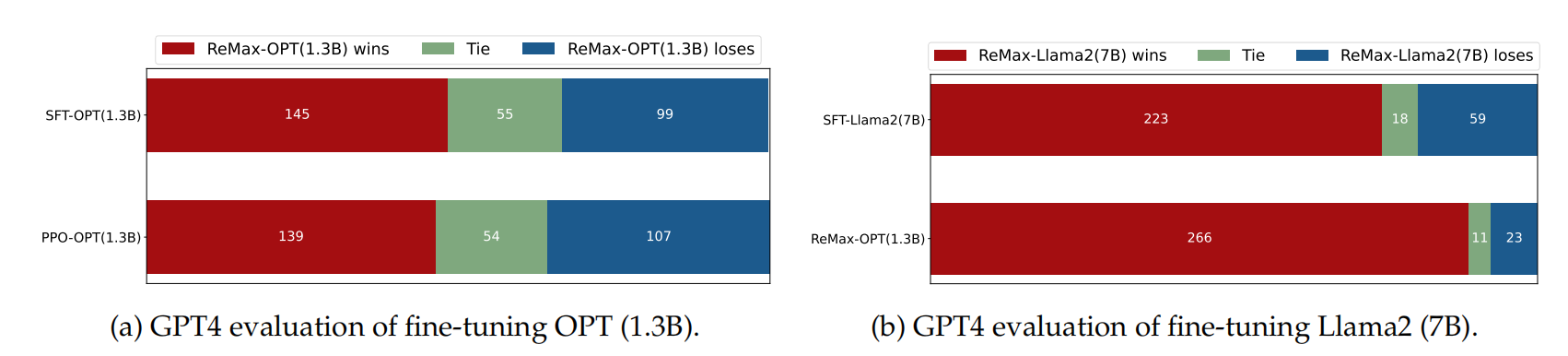
(七)RSO模型
论文:Statistical rejection sampling improves preference optimization
Reference
[1] Rafael Rafailov, Archit Sharma, Eric Mitchell, StefanoErmon, Christopher D Manning, and Chelsea Finn.2023. Direct preference optimization: Your language model is secretly a reward model.arXiv preprintarXiv:2305.18290
[2] DPO(Direct Preference Optimization):LLM的直接偏好优化. 笔记
[3] https://github.com/LAION-AI/Open-Assistant/discussions/3347
[4] DPO——RLHF 的替代之《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》论文阅读
[5] RLAIF细节分享&个人想法
[6] RLHF中的PPO算法原理及其实现
[7] InstructGPT pairwise logloss: https://arxiv.org/abs/2203.02155
[8] DPO:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
[9] RLAIF:Scaling Reinforcement Learning from Human Feedbak with AI Feadback
[10] BPO:灵活的 Prompt 对齐优化技术
[11] LLM成功不可或缺的基石:RLHF及其替代技术
[12] Reinforced Self-Training (ReST) for Language Modeling翻译
[13] 大规模语言模型人类反馈对齐–RLAIF
[14] 谷歌团队提出用AI反馈强化学习 (RLAIF) ,替代人类进行偏好标注,这会对AI研究产生什么影响
[15] 大规模语言模型从理论到实践.第六章.复旦大学
[16] A Survey of Large Language Models.人大综述
[17] LLM Training: RLHF and Its Alternatives. SEBASTIAN RASCHKA, PHD
[18] Llama 2: Open Foundation and Fine-Tuned Chat Models:https://huggingface.co/papers/2307.09288#64c6961115bd12e5798b9e3f
[19] spinningup中文文档:https://spinningup.qiwihui.com/zh_CN/latest/
[20] RLHF中的「RL」是必需的吗?有人用二进制交叉熵直接微调LLM,效果更好
[21] RLHF的替代算法之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr
[22] DPO: Direct Preference Optimization训练目标推导
[23] 强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
[24] KL-Divergence详解
[25] ChatGPT调研报告.哈工大实验室HIT-NLP
[26] 多 Agent 深度强化学习综述.《自动化学报》
[27] 一些RLHF的平替汇总
[28] Contrastive Post-training Large Language Models on Data Curriculum: https://arxiv.org/abs/2310.02263
[29] 理解Rejection Sampling: https://gaolei786.github.io/statistics/reject.html
[30] DeepMind新研究:ReST让大模型与人类偏好对齐,比在线RLHF更有效
[31] 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
[32] 论文阅读-MOSS-RLHF:PPO
[33] https://github.com/GanjinZero/RRHF
[34] 论文阅读-MOSS-RLHF:PPO
[35] https://github.com/OpenLMLab/MOSS-RLHF
[36] 添加链接描述影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
[37] DPO——RLHF 的替代之《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》论文阅读
[38] Llama 2:开源RHLF微调对话模型
[39] Secrets of RLHF in Large Language Models Part I: PPO
[40] 大模型训练的一些坑点和判断.包包
[41] Fine-tuning OpenAI GPT-3 using a custom reward model
基础:
[1] 强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
[2] “StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程.huggingface
[3] ChatGPT的RLHF:AI时代的“调速器”,让AI真正可用的关键
[4] 【他山之石】如何正确复现 Instruct GPT / RLHF?
[5] https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback
[7] Training language models to follow instructions with human feedback(2022)
[8] InstructGPT论文解读.李响
[9] ChatGPT训练三阶段与RLHF的威力.oneflow
在 InstructGPT 论文之前的这四篇论文中找到PPO的相关数学细节:
(1) 《Asynchronous Methods for Deep Reinforcement Learning》引入了策略梯度方法来替代基于深度学习的强化学习中的 Q 学习。
(2) 《Proximal Policy Optimization Algorithms》提出了一种基于修改版近端策略的强化学习流程,其数据效率和可扩展性均优于上面的基础版策略优化算法。
(3) 《Fine-Tuning Language Models from Human Preferences》阐释了 PPO 的概念以及对预训练语言模型的奖励学习,包括 KL 正则化,以防止策略偏离自然语言太远。
(4) 《Learning to Summarize from Human Feedback》引入了现在常用的 RLHF 三步流程,后来的 InstructGPT 论文也使用了该流程。
相关文章:
【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量…...

Spring Boot监听redis过期的key
Redis支持过期监听,可以实现监听过期数据,实现过程如下 1、pom依赖 <!-- Redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></depend…...

day01、什么是数据库系统?
数据库系统介绍 1.实例化与抽象化数据库系统2.从用户角度看数据库管理系统的功能2.1 数据库定义功能2.2 数据库操纵2.3 数据库控制2.4 数据库维护功能2.5 数据库语言与高级语言 3.从系统:数据库管理系统应具有什么功能 来源于战德臣的B站网课 1.实例化与抽象化数据库…...
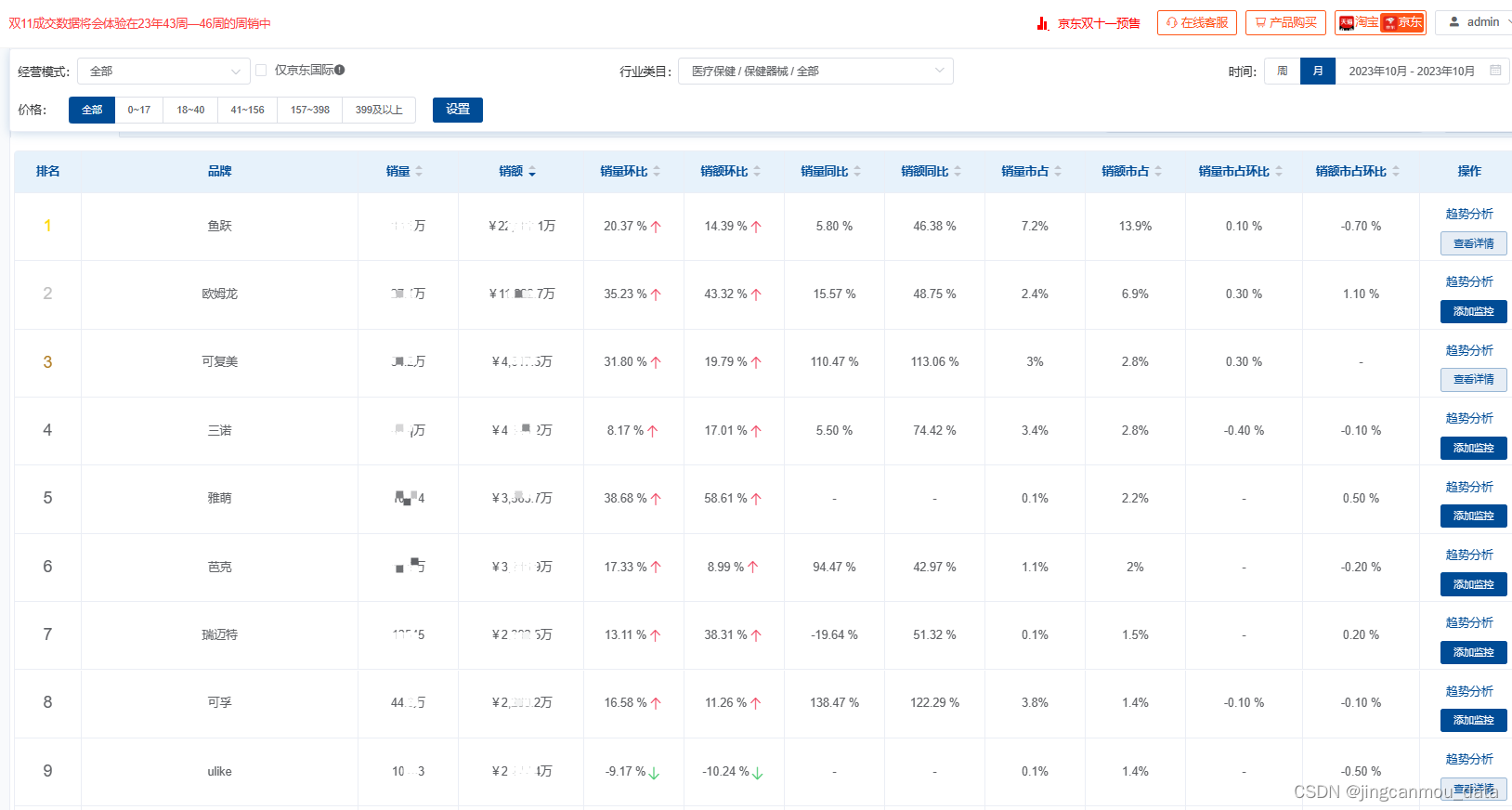
2023年医疗器械行业分析(京东医疗器械运营数据分析):10月销额增长53%
随着我国整体实力的增强、国民生活水平的提高、人口老龄化、医疗保障体系不断完善等因素的驱动,我国的医疗器械市场增长迅速。 根据鲸参谋电商数据分析平台的相关数据显示,今年10月份,京东平台上医疗器械市场的销量将近1200万,环比…...

MISRA C++ 2008 标准解析
MISRA C 2008是《汽车专用软件的C语言编程指南》,是针对C语言的安全编码标准,适用C 03标准,是汽车行业公认的C语言编码规范,目的是在研发生命周期早期发现软件中的缺陷,预防成本投入会大幅度降低投产后的售后维护成本。…...
Linux16 ftp文件服务区、vsftpd文件系统服务安装、lftp客户端安装、NFS远程共享存储
目录 一、FTP基础ftp主动模式ftp被动模式 二、vsftpd配置共享目录编辑配置文件使用windows 访问 三、客户端安装 (lftp)匿名用户的一些操作(lftp {ip})ftp配置本地用户登录配置本地用户ftp配置文件 lftp操作 NFS远程共享存储安装n…...
[排序篇] 冒泡排序
目录 一、概念 二、冒泡排序 2.1 冒泡降序(从大到小排序) 2.2 冒泡升序(从小到大排序) 三、冒泡排序应用 总结 一、概念 冒泡排序核心思想:每次比较两个相邻的元素,如果它们不符合排序规则(升序或降序)则把它们交换过来。…...
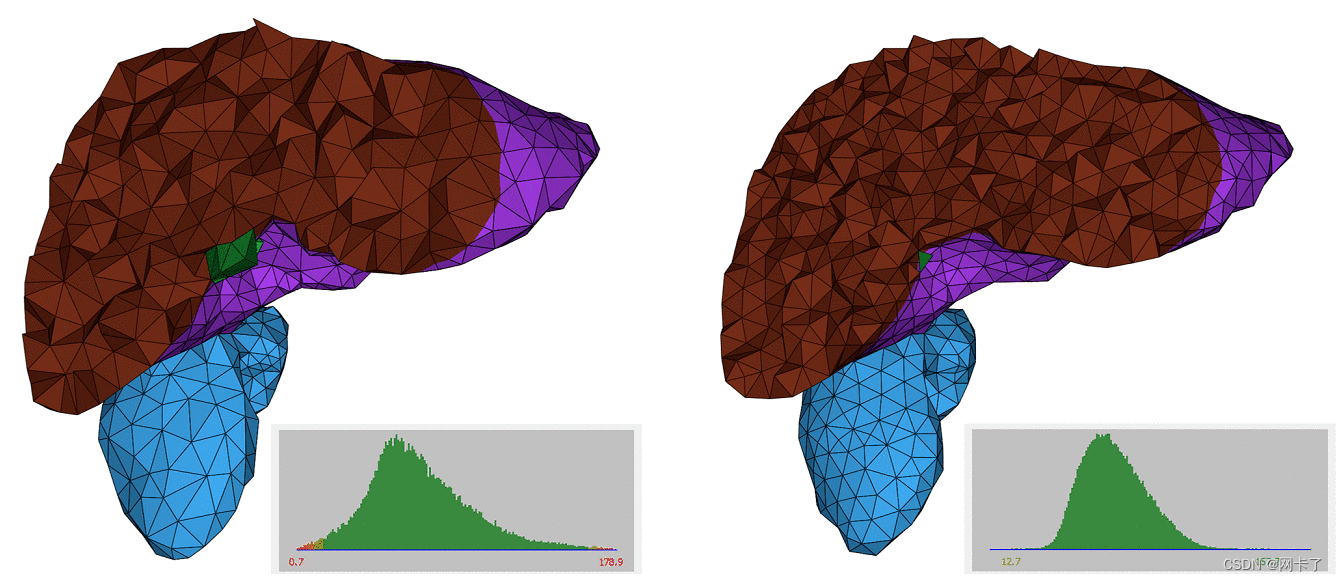
CGAL的四面体网格重构
1、多材料各向同性四面体网格重构 此软件包实现了等人提出的四边形网格质量重分算法。这种实用的迭代重分网格算法旨在通过迭代执行一系列基本操作来重分多材料四边形网格,这些操作包括边缘分裂、边缘折叠、边缘翻转和顶点重定位,这些操作是在拉普拉斯平…...
排序-选择排序与堆排序
文章目录 一、选择排序二、堆排序三、时间复杂度四、稳定性 一、选择排序 思想: 将数组第一个元素作为min,然后进行遍历与其他元素对比,找到比min小的数就进行交换,直到最后一个元素就停止,然后再将第二个元素min&…...
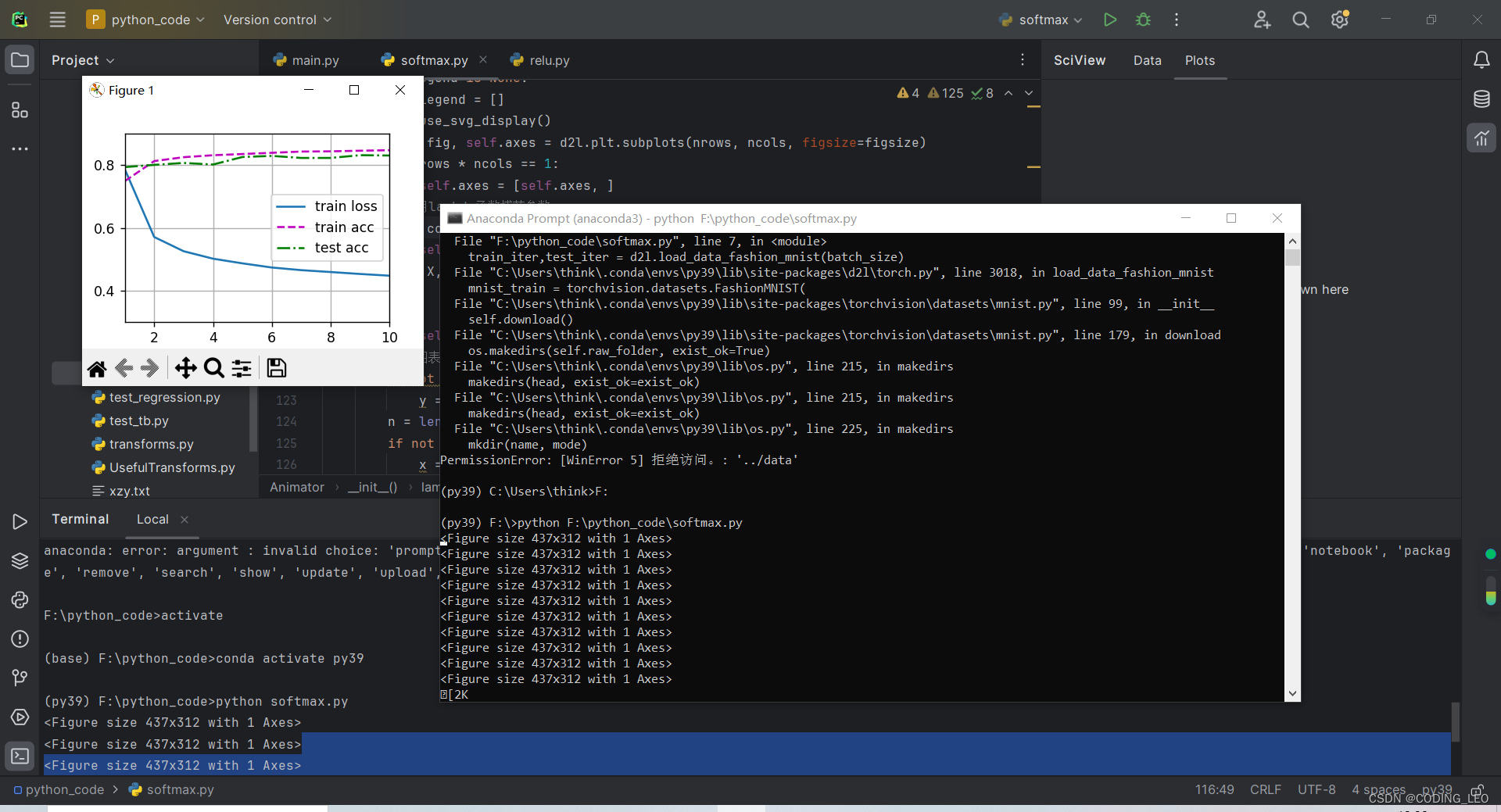
d2l绘图不显示的问题
之前试了各种方法都不行 在pycharm中还是不行,但是在anaconda中的命令行是可以的 anaconda prompt conda activaye py39 #进入f盘 F: #运行文件 python F:\python_code\softmax.py...

智能优化算法应用:基于人工蜂群算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于人工蜂群算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于人工蜂群算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.人工蜂群算法4.实验参数设定5.算法结果6.…...
云原生的 CI/CD 框架tekton - Trigger(二)
上一篇为大家详细介绍了tekton - pipeline,由于里面涉及到的概念比较多,因此需要好好消化下。同样,今天在特别为大家分享下tekton - Trigger以及案例演示,希望可以给大家提供一种思路哈。 文章目录 1. Tekton Trigger2. 工作流程3…...
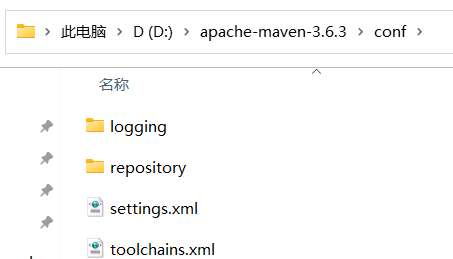
maven环境搭建
maven历史版本下载:https://archive.apache.org/dist/maven/ 新建系统变量编辑Path,添加bin目录mvn -v测试查看版本号conf目录下新建repository文件夹,作为本地仓库 settings.xml <?xml version"1.0" encoding"UTF-8&…...
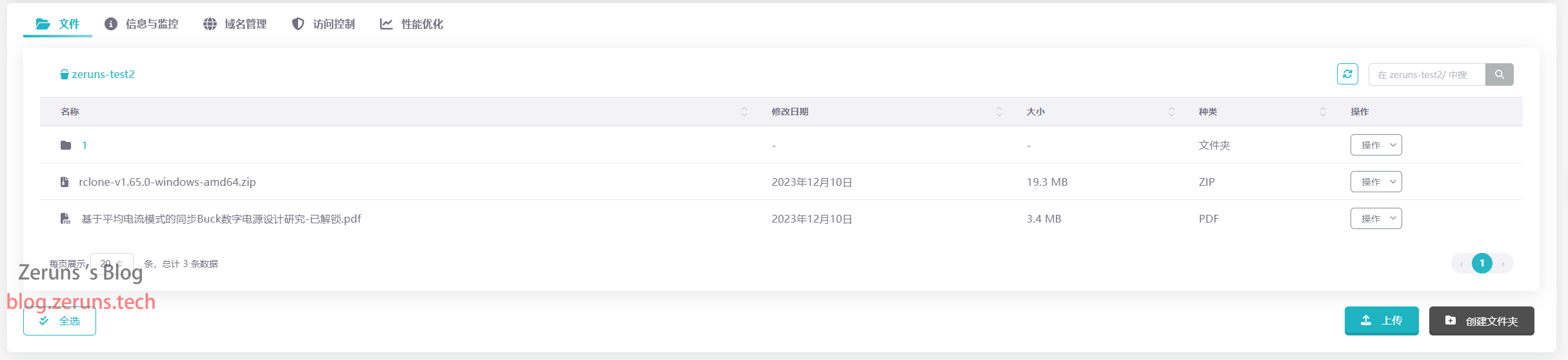
利用Rclone将阿里云对象存储迁移至雨云对象存储的教程,对象存储数据迁移教程
使用Rclone将阿里云对象存储(OSS)的文件全部迁移至雨云对象存储(ROS)的教程,其他的对象存储也可以参照本教程。 Rclone简介 Rclone 是一个用于和同步云平台同步文件和目录命令行工具。采用 Go 语言开发。 它允许在文件系统和云存储服务之间或在多个云存储服务之间…...

二叉树的前序遍历
问题描述: 给你二叉树的根节点root,返回节点值的前序遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,2,3]示例 2: 输入:root [] 输出:[]示例 3: 输入:ro…...

final的安全发布
final的安全发布 两个关键字“发布”“安全” 所谓发布通俗一点的理解就是创建一个对象,使这个对象能被当前范围之外的代码所使用 比如Object o new Object(); 然后接下来使用对象o 但是对于普通变量的创建,之前分析过,大致分为三个步骤&am…...
生成对抗网络 优化算法进化算法)
3易懂AI深度学习算法:长短期记忆网络(Long Short-Term Memory, LSTM)生成对抗网络 优化算法进化算法
继续写:https://blog.csdn.net/chenhao0568/article/details/134920391?spm1001.2014.3001.5502 1.https://blog.csdn.net/chenhao0568/article/details/134931993?spm1001.2014.3001.5502 2.https://blog.csdn.net/chenhao0568/article/details/134932800?spm10…...
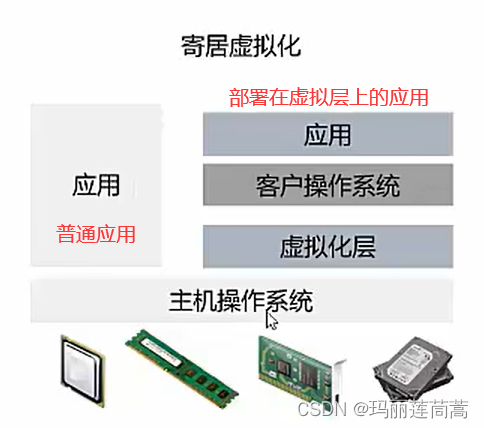
云计算 云原生
一、引言 云计算需要终端把信息上传到服务器,服务器处理后再返回给终端。在之前人手一台手机的情况下,云计算还是能handle得过来的。但是随着物联网的发展,什么东西都要联网,那数据可就多了去了,服务器处理不过来&…...

深拷贝、浅拷贝 react的“不可变值”
知识获取源–晨哥(现实中的人 嘿嘿) react中如果你想让一个值始终不变 或者说其他操作不影响该值 它只是作用初始化的时候 使用了浅拷贝–改变了初始值 会改变初始值(selectList1) 都指向同一个地址 const selectList1 { title: 大大, value: 1 };con…...

赛宁网安多领域亮相第三届网络空间内生安全发展大会
2023年12月8日,第三届网络空间内生安全发展大会在宁开幕。两院院士、杰出专家学者和知名企业家相聚南京,围绕数字经济新生态、网络安全新范式进行广泛研讨,为筑牢数字安全底座贡献智慧和力量。 大会围绕“一会、一赛、一展”举办了丰富多彩的…...

多模态实践:OpenClaw+千问3.5-27B分析截图中的图表数据
多模态实践:OpenClaw千问3.5-27B分析截图中的图表数据 1. 为什么需要自动化图表分析 作为一名数据分析师,我每天需要处理大量来自股票、销售报表的截图。传统做法是手动录入数据到Excel,既耗时又容易出错。直到我发现OpenClaw与千问3.5-27B…...

Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题
Windows 10 PL-2303串口驱动终极修复指南:告别老旧芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下PL-2303串口适配器…...

ViPER4Windows终极修复指南:让Windows音效神器重获新生
ViPER4Windows终极修复指南:让Windows音效神器重获新生 【免费下载链接】ViPER4Windows-Patcher Patches for fix ViPER4Windows issues on Windows-10/11. 项目地址: https://gitcode.com/gh_mirrors/vi/ViPER4Windows-Patcher 你是否曾为ViPER4Windows在Wi…...

别再死记硬背了!用这个动画+仿真,5分钟搞懂CMOS反相器到底怎么‘反’的
别再死记硬背了!用动画仿真5分钟搞懂CMOS反相器的翻转奥秘 第一次翻开数字电路教材时,那个由PMOS和NMOS组成的对称结构总让我困惑——为什么PMOS必须在上方?为什么输入高电平反而输出低电平?直到我在实验室里用仿真软件亲眼看到电…...

技术解析 | 【ECCV2022】MuLUT:多级查找表协同优化在图像超分中的高效实践
1. MuLUT技术背景与核心价值 图像超分辨率(Super-Resolution)技术一直是计算机视觉领域的热门研究方向,简单来说就是让低分辨率图像变清晰的过程。传统基于卷积神经网络(CNN)的方法虽然效果不错,但计算量大…...
)
Cloudflare Tunnel零基础教程:5分钟搞定内网穿透(附移动网络解决方案)
Cloudflare Tunnel零基础实战指南:从内网穿透到移动网络优化 在数字化办公与远程协作成为常态的今天,如何安全高效地访问内网资源成为许多技术爱好者和小型企业IT人员的刚需。传统的内网穿透方案往往需要复杂的端口映射、动态DNS配置,甚至面临…...

烽火HG680-MC全分区TTL救砖指南:从黑屏到流畅运行的完整解决方案
1. 烽火HG680-MC救砖前的准备工作 遇到黑屏、卡LOGO的烽火HG680-MC盒子别急着扔,TTL线刷能救回90%的"砖机"。我经手过上百台同型号设备,先说说你手头要准备的"救命工具包": 硬件三件套:CH340G芯片的TTL转USB模…...

Phi-3-mini-4k-instruct-gguf快速部署:7860端口网页服务+独立venv隔离环境实录
Phi-3-mini-4k-instruct-gguf快速部署:7860端口网页服务独立venv隔离环境实录 1. 模型简介 Phi-3-mini-4k-instruct-gguf 是微软 Phi-3 系列中的轻量级文本生成模型 GGUF 版本。这个模型特别适合以下场景: 智能问答文本改写与润色内容摘要生成简短创意…...
)
【HTTP】HTTP协议核心体系:请求方法与状态码全结构化解析(附《思维导图》)
文章目录HTTP协议核心体系:请求方法与状态码全结构化解析一、核心基础概念1.1 HTTP方法的两大核心属性(规范级定义)1.2 HTTP状态码分类规则二、HTTP请求方法2.1 标准核心方法(RFC 7231 定义)2.1.1 只读类方法ÿ…...

CES Asia 2026打造低空经济生态圈:从整机到核心部件全链覆盖
北京,2026年3月31日电——低空经济产业正迈向全链协同、规模化落地的关键阶段。CES Asia 2026将于6月10—12日在北京举办,以全产业链覆盖精准供需对接资本赋能为核心,构建从整机到核心部件的完整低空经济生态圈,助力企业一站式打通…...