java版Spring Cloud+Spring Boot+Mybatis之隐私计算 FATE - 多分类神经网络算法测试

一、说明
本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测。
- 二分类算法:是指待预测的 label 标签的取值只有两种;直白来讲就是每个实例的可能类别只有两种 (0 或者 1),例如性别只有 男 或者 女;此时的分类算法其实是在构建一个分类线将数据划分为两个类别。
- 多分类算法:是指待预测的 label 标签的取值可能有多种情况,例如个人爱好可能有 篮球、足球、电影 等等多种类型。常见算法:Softmax、SVM、KNN、决策树。
关于 Fate 的核心概念、单机部署、训练以及预测请参考以下相关文章:
- 《隐私计算 FATE - 关键概念与单机部署指南》
- 《隐私计算 FATE - 模型训练》
- 《隐私计算 FATE - 离线预测》
二、准备训练数据
上传到 Fate 里的数据有两个字段名必需是规定的,分别是主键为 id 字段和分类字段为 y 字段,y 字段就是所谓的待预测的 label 标签;其他的特征字段 (属性) 可任意填写,例如下面例子中的 x0 - x9
例如有一条用户数据为:
收入: 10000,负债: 5000,是否有还款能力: 1 ;数据中的收入和负债就是特征字段,而是否有还款能力就是分类字段。
本文只描述关键部分,关于详细的模型训练步骤,请查看文章《隐私计算 FATE - 模型训练》
2.1. guest 端
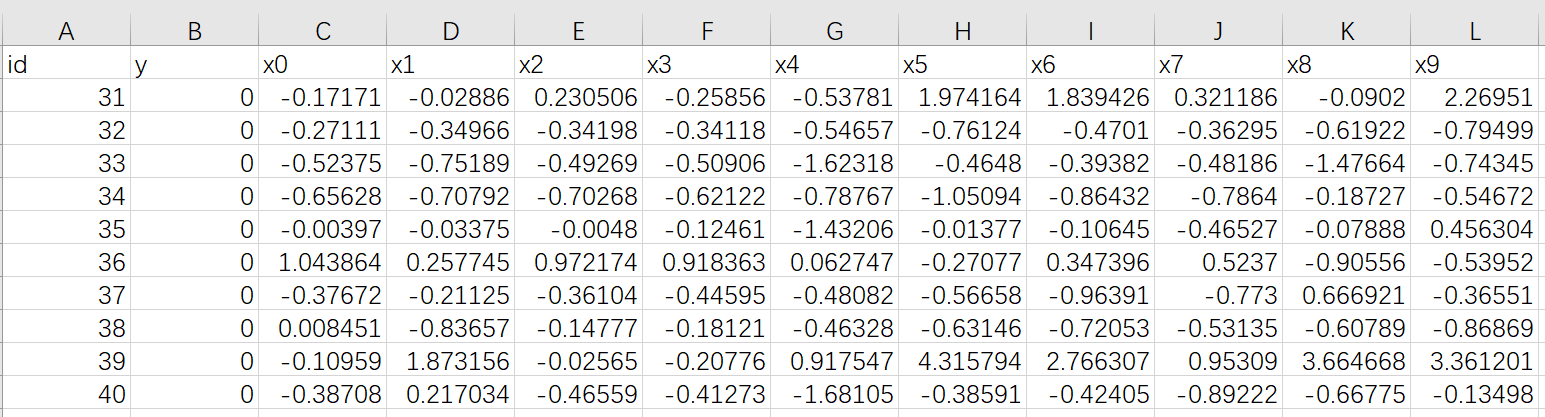
10 条数据,包含 1 个分类字段 y 和 10 个标签字段 x0 - x9
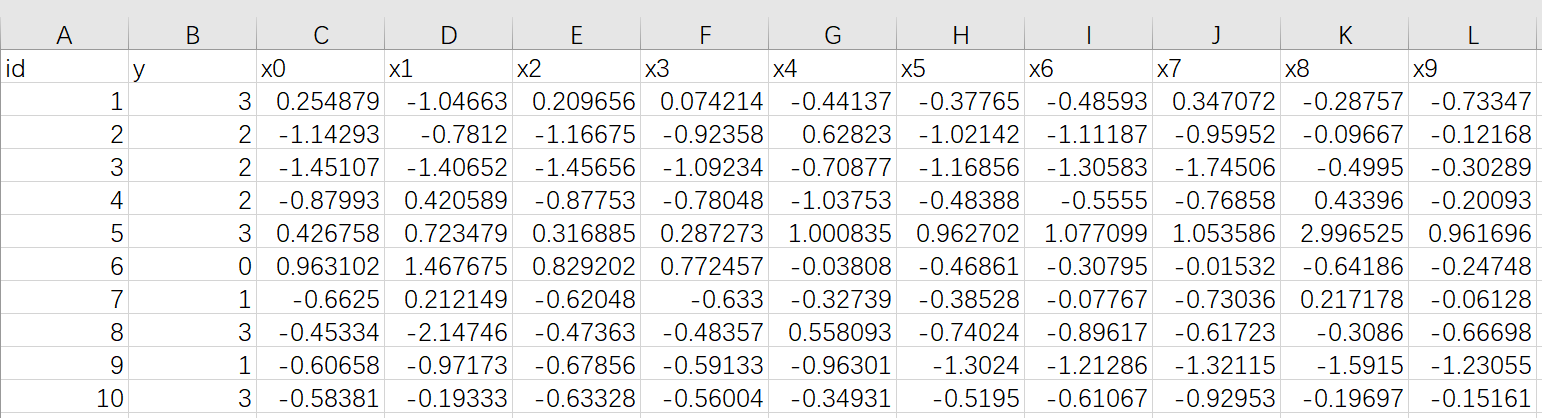
y 值有 0、1、2、3 四个分类
上传到 Fate 中,表名为 muti_breast_homo_guest 命名空间为 experiment
2.2. host 端
10 条数据,字段与 guest 端一样,但是内容不一样
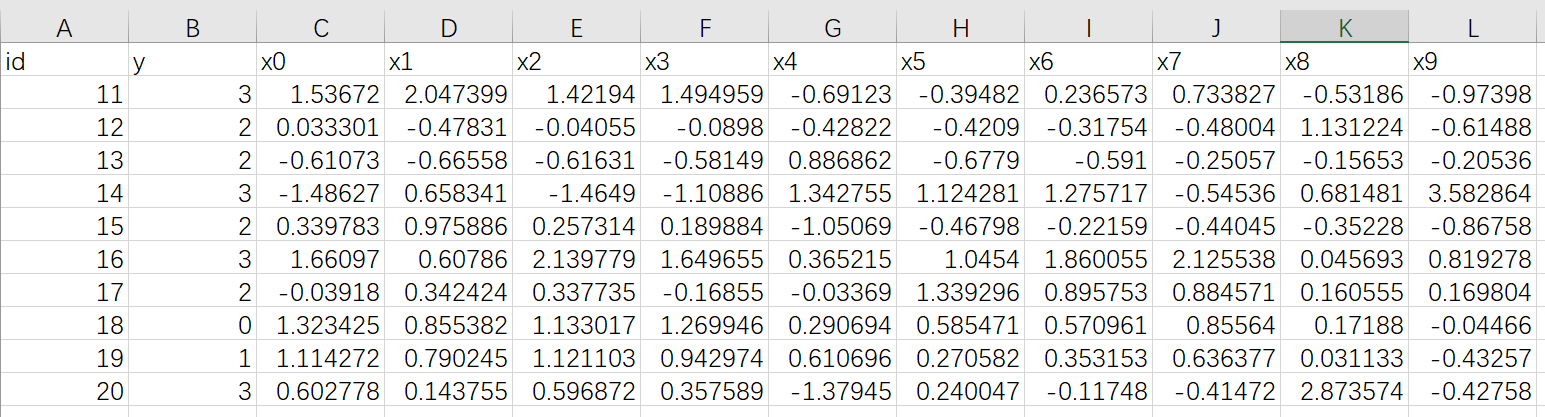
上传到 Fate 中,表名为 muti_breast_homo_host 命名空间为 experiment
三、执行训练任务
3.1. 准备 dsl 文件
创建文件 homo_nn_dsl.json 内容如下 :
{"components": {"reader_0": {"module": "Reader","output": {"data": ["data"]}},"data_transform_0": {"module": "DataTransform","input": {"data": {"data": ["reader_0.data"]}},"output": {"data": ["data"],"model": ["model"]}},"homo_nn_0": {"module": "HomoNN","input": {"data": {"train_data": ["data_transform_0.data"]}},"output": {"data": ["data"],"model": ["model"]}}}
}
3.2. 准备 conf 文件
创建文件 homo_nn_multi_label_conf.json 内容如下 :
{"dsl_version": 2,"initiator": {"role": "guest","party_id": 9999},"role": {"arbiter": [10000],"host": [10000],"guest": [9999]},"component_parameters": {"common": {"data_transform_0": {"with_label": true},"homo_nn_0": {"encode_label": true,"max_iter": 15,"batch_size": -1,"early_stop": {"early_stop": "diff","eps": 0.0001},"optimizer": {"learning_rate": 0.05,"decay": 0.0,"beta_1": 0.9,"beta_2": 0.999,"epsilon": 1e-07,"amsgrad": false,"optimizer": "Adam"},"loss": "categorical_crossentropy","metrics": ["accuracy"],"nn_define": {"class_name": "Sequential","config": {"name": "sequential","layers": [{"class_name": "Dense","config": {"name": "dense","trainable": true,"batch_input_shape": [null,18],"dtype": "float32","units": 5,"activation": "relu","use_bias": true,"kernel_initializer": {"class_name": "GlorotUniform","config": {"seed": null,"dtype": "float32"}},"bias_initializer": {"class_name": "Zeros","config": {"dtype": "float32"}},"kernel_regularizer": null,"bias_regularizer": null,"activity_regularizer": null,"kernel_constraint": null,"bias_constraint": null}},{"class_name": "Dense","config": {"name": "dense_1","trainable": true,"dtype": "float32","units": 4,"activation": "sigmoid","use_bias": true,"kernel_initializer": {"class_name": "GlorotUniform","config": {"seed": null,"dtype": "float32"}},"bias_initializer": {"class_name": "Zeros","config": {"dtype": "float32"}},"kernel_regularizer": null,"bias_regularizer": null,"activity_regularizer": null,"kernel_constraint": null,"bias_constraint": null}}]},"keras_version": "2.2.4-tf","backend": "tensorflow"},"config_type": "keras"}},"role": {"host": {"0": {"reader_0": {"table": {"name": "muti_breast_homo_host","namespace": "experiment"}}}},"guest": {"0": {"reader_0": {"table": {"name": "muti_breast_homo_guest","namespace": "experiment"}}}}}}
}
注意
reader_0组件的表名和命名空间需与上传数据时配置的一致。
3.3. 提交任务
执行以下命令:
flow job submit -d homo_nn_dsl.json -c homo_nn_multi_label_conf.json
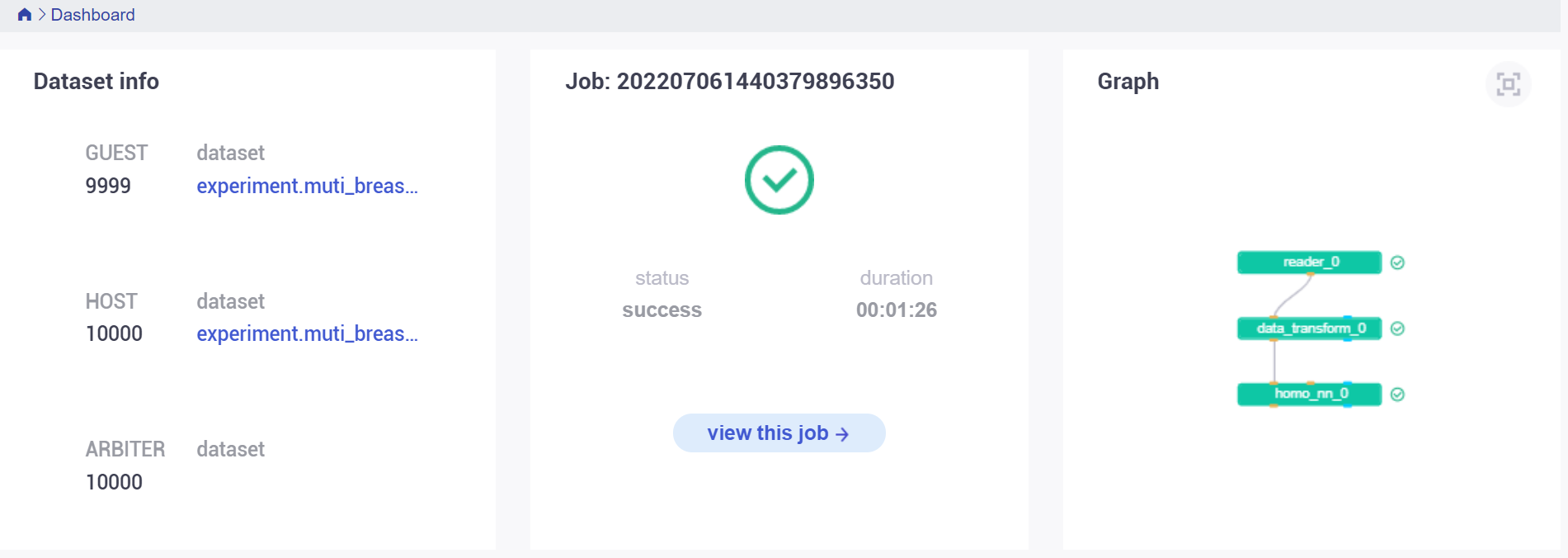
执行成功后,查看 dashboard 显示:
四、准备预测数据
与前面训练的数据字段一样,但是内容不一样,y 值全为 0
4.1. guest 端
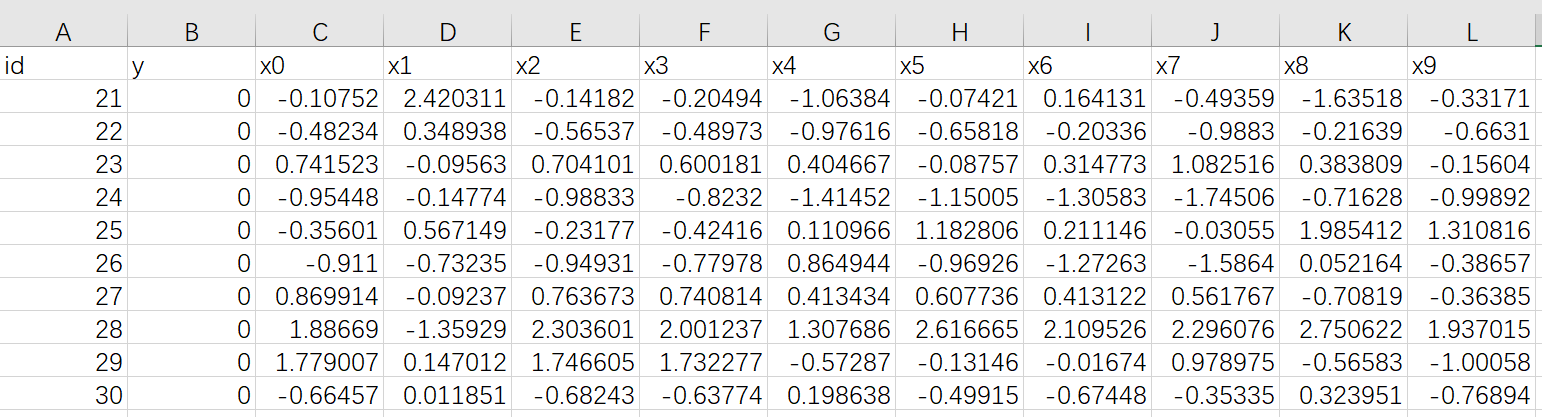
上传到 Fate 中,表名为 predict_muti_breast_homo_guest 命名空间为 experiment
4.2. host 端
上传到 Fate 中,表名为 predict_muti_breast_homo_host 命名空间为 experiment
五、准备预测配置
本文只描述关键部分,关于详细的预测步骤,请查看文章《隐私计算 FATE - 离线预测》
创建文件 homo_nn_multi_label_predict.json 内容如下 :
{"dsl_version": 2,"initiator": {"role": "guest","party_id": 9999},"role": {"arbiter": [10000],"host": [10000],"guest": [9999]},"job_parameters": {"common": {"model_id": "arbiter-10000#guest-9999#host-10000#model","model_version": "202207061504081543620","job_type": "predict"}},"component_parameters": {"role": {"guest": {"0": {"reader_0": {"table": {"name": "predict_muti_breast_homo_guest","namespace": "experiment"}}}},"host": {"0": {"reader_0": {"table": {"name": "predict_muti_breast_homo_host","namespace": "experiment"}}}}}}
}
注意以下两点:
model_id和model_version需修改为模型部署后的版本号。
reader_0组件的表名和命名空间需与上传数据时配置的一致。
六、执行预测任务
执行以下命令:
flow job submit -c homo_nn_multi_label_predict.json
执行成功后,查看 homo_nn_0 组件的数据输出:
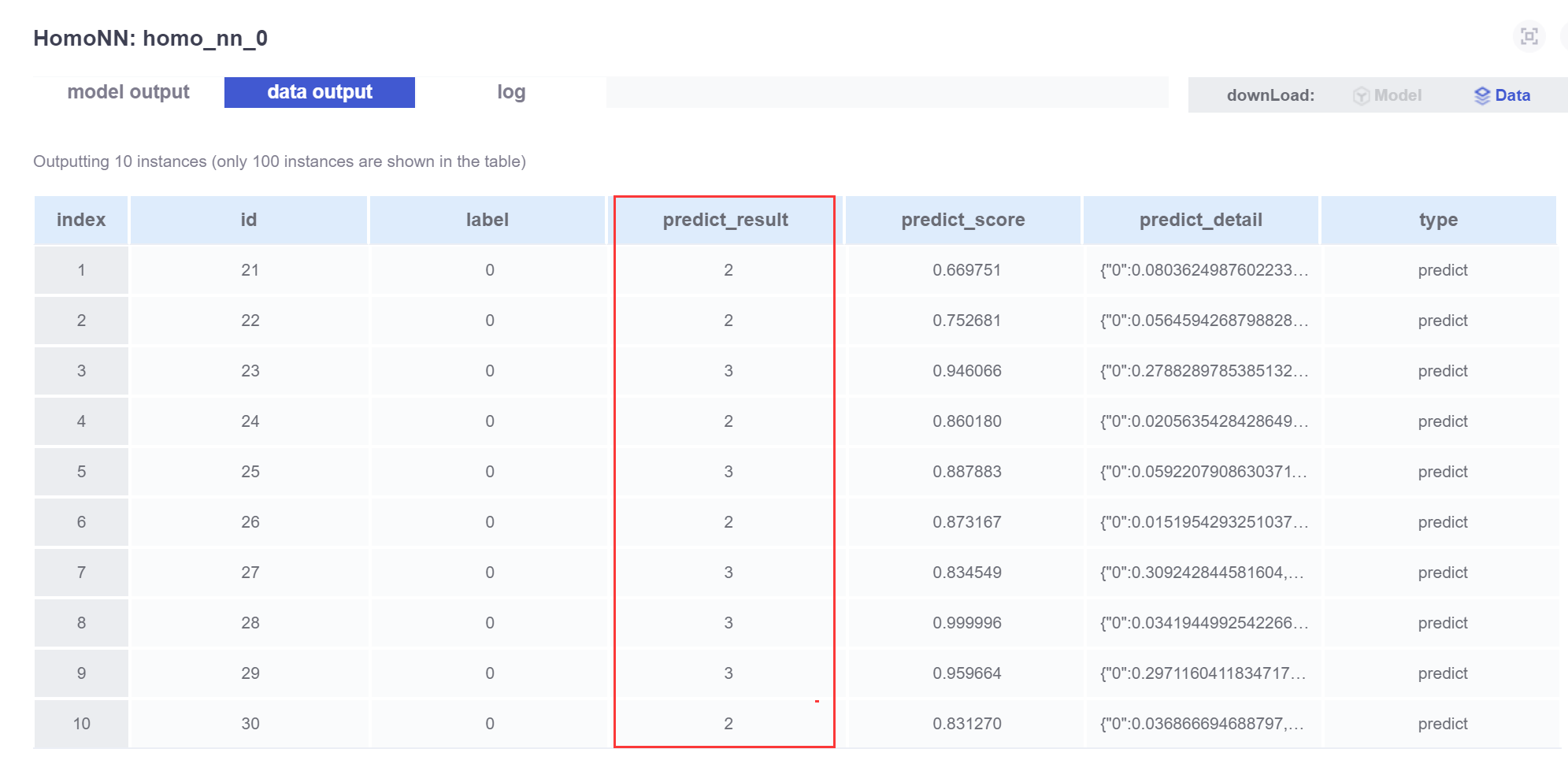
可以看到算法输出的预测结果。
相关文章:
java版Spring Cloud+Spring Boot+Mybatis之隐私计算 FATE - 多分类神经网络算法测试
一、说明 本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测。 二分类算法:是指待预测的 label 标签的取值只有两种;直白来讲就是每个实例的可能类别只有两种 (0 或者 1)&…...
)
Java之时间类2(JDK8新增)
一、Date类 (一)、ZoneId:时区 1、概述 ZoneId是Java 8中处理时区的类。它用于表示时区标识符,例如“America/New_York”或“Asia/Tokyo”。一共有600个时区。 2、常用方法: static Set<String> getAvailableZoneIds()获…...
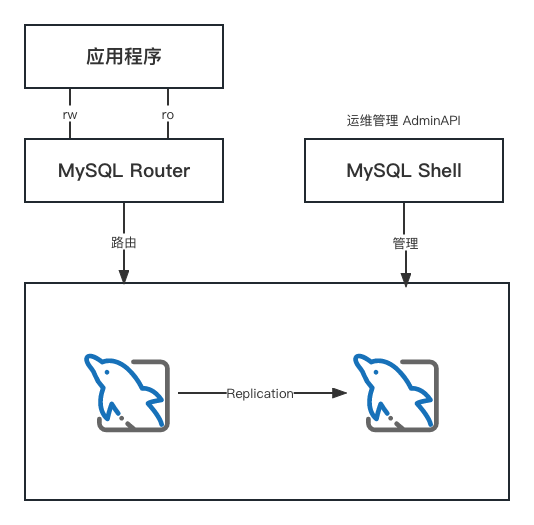
MySQL InnoDB Replication部署方案与实践
1. 概述 MySQL Innodb ReplicaSet 是 MySQL 团队在 2020 年推出的一款产品,用来帮助用户快速部署和管理主从复制,在数据库层仍然使用的是主从复制技术。 ReplicaSet 主要包含三个组件:MySQL Router、MySQL Server 以及 MySQL Shell 高级客户…...
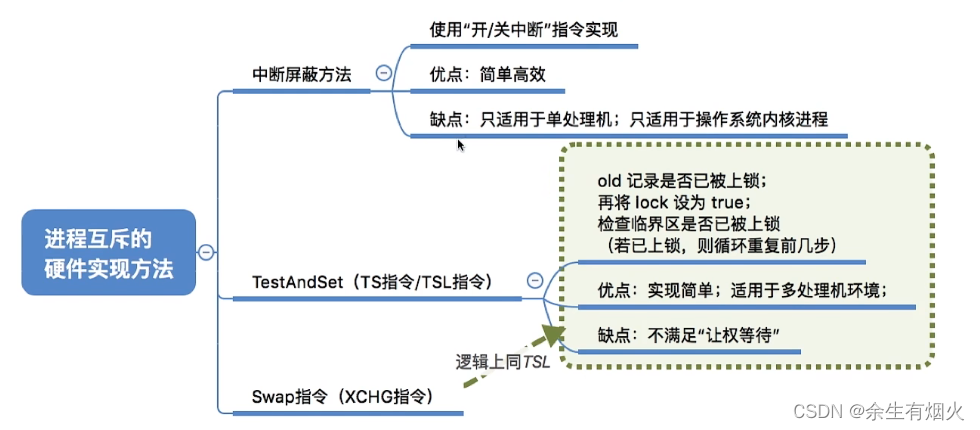
进程的同步和异步、进程互斥
一、进程同步和异步 同步(Synchronous): 同步指的是程序按照顺序执行,一个操作完成后才能进行下一个操作。在多进程或多线程的环境中,同步意味着一个进程(或线程)在执行某个任务时,…...

搞定课件录制,新手必备指南!
“有人知道课件怎么录制吗?学校要求我们师范专业的学生出去实习,现在需要录制一个课件视频,以便在课堂上播放,可是我不会录制教学视频,真的很头疼,有人能帮帮我吗。” 随着在线教育的崛起,课件…...
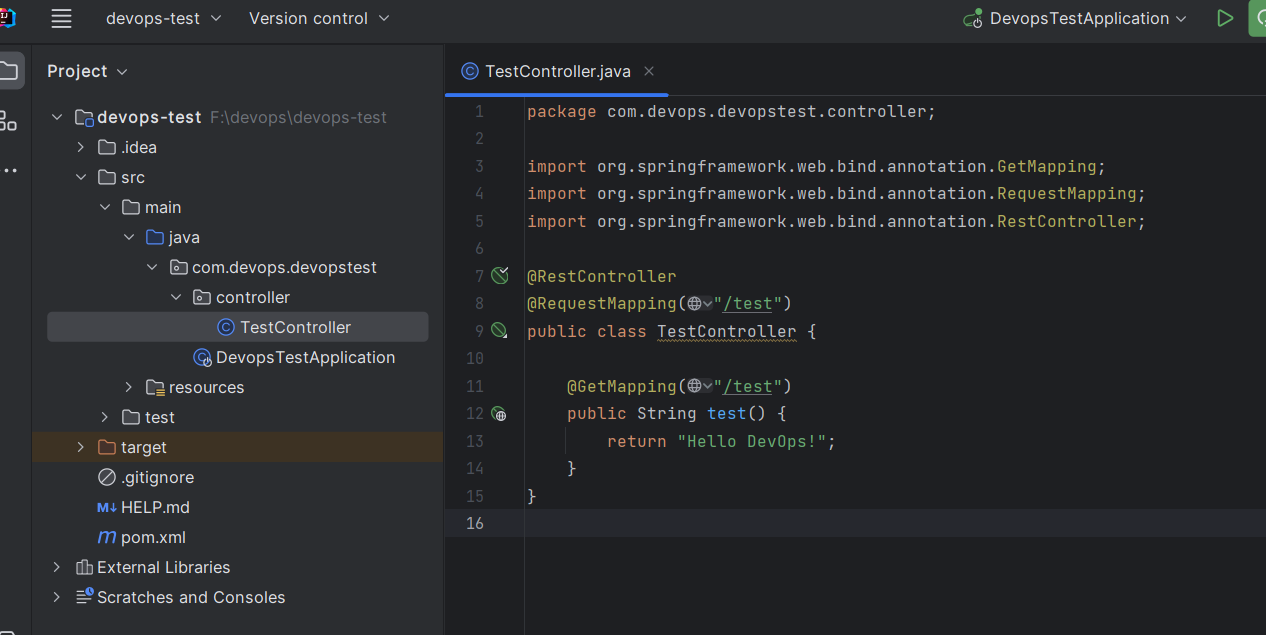
DevOps搭建(九)-Jenkins实现基础CI、CD详细操作
1、创建可运行SpringBoot项目 1.1、创建一个新工程 在idea里创建一个项目,这里叫devops-test,如下图: String Boot版本要选择2.x的,依赖直选中Spring Web选项即可: 修改pom.xml文件,在build标签中增加如下内容,目的是简化jar包名称。 <finalName>devops-test&l…...

十指波课堂:让学习编程不再是难事
十指波课堂是一家致力于发展线上私教平台的教育机构,主要的科目是计算机编程相关语言。由于学习编程的过程较为困难,学习者没有具体的学习方向,将要达到的就业水平不明,总会因为一些小问题困扰几个小时,这样会严重的影…...
IDEA卡顿,进行性能优化设置(亲测有效)——情况二
问题背景与现象 IDEA今天突然显示到期,于是从同事那边搞到一个很好用的破解方式,说实话,非常方便(后续在安前码后中分享) 破解之后呢,香了一阵子,但是突然显示开始卡顿,界面几乎是…...

利用Python和OpenCV实现将图像识别为Excel表格的便捷方法
当今社会,图像识别技术的发展为我们提供了许多便利,比如将图像中的文本信息转化为可编辑的电子表格。在本文中,我们将介绍如何利用Python结合OpenCV和pytesseract库,来实现将图像识别为Excel表格的过程。 首先,我们需…...
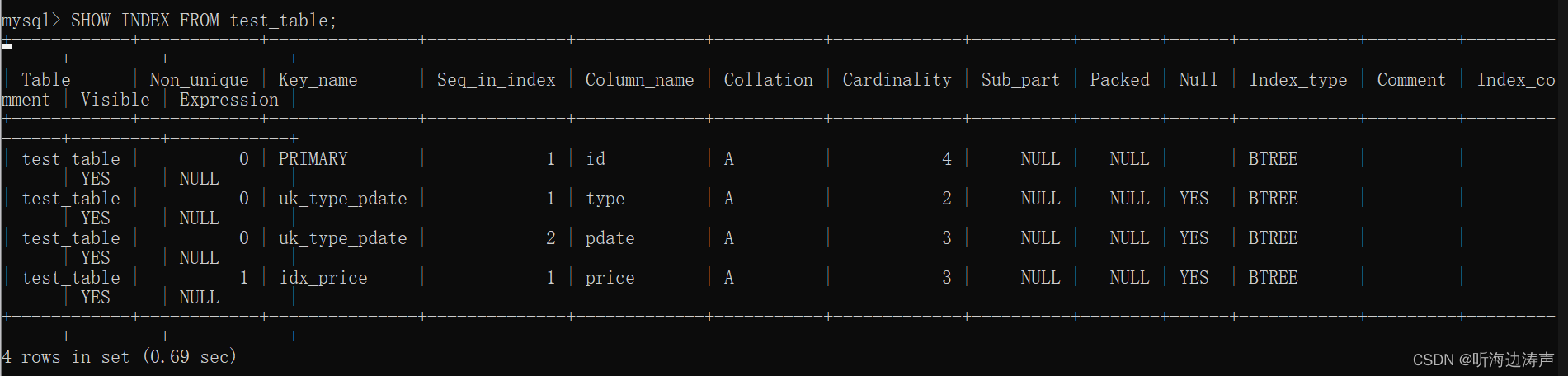
mysql:查看一个表的索引信息
可以使用命令SHOW INDEX FROM table_name;查看一个表的索引信息,例如:...
12月11日作业
完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到其他界面 如果账号和密码不匹配…...

HTTP协议在Linux上进行数据库访问代码示例
在Linux上使用HTTP协议进行数据库访问通常涉及到使用库如requests来进行HTTP请求,以及使用json或类似的库来处理返回的数据。下面是一个使用Python的简单示例,展示如何通过HTTP协议在Linux上访问数据库。 首先,你需要确保你的Linux系统上已经…...
CS.DEEP | 基于 openGauss 实现的计算机论坛项目
前言 本项目是一个基于前后端分离(后端:SpringBoot openGauss,前端:Vue3 Element Plus)实现的开源计算机博客论坛项目,旨在为用户提供一个方便、高效的博客发布和交流平台。 本平台支持 Markdown 编辑&…...

【ArcGIS Pro微课1000例】0053:基于SQL Server创建与启用地理数据库
之前的文章有讲述基于SQL Server创建企业级地理数据库,本文讲述在SQL Server中创建常规的关心数据库,然后在ArcGIS Pro中将其启用,转换为企业级地理数据库。 1. 在SQL Server中创建数据库** 打开SQL Server 2019,连接到数据库服务器。 展开数据库连接,在数据库上右键→新…...

快速排序(2)
一、快速排序有三种方法:hoare版本、挖坑法、前后指针版本 但是三种方法的核心思想都是一样的,都是将该数组分为左右两半递归式的排序。 1.hoare版本 该方法是先保存a[keyi]位置的值,然后右边先开动找小,找到小后,左…...
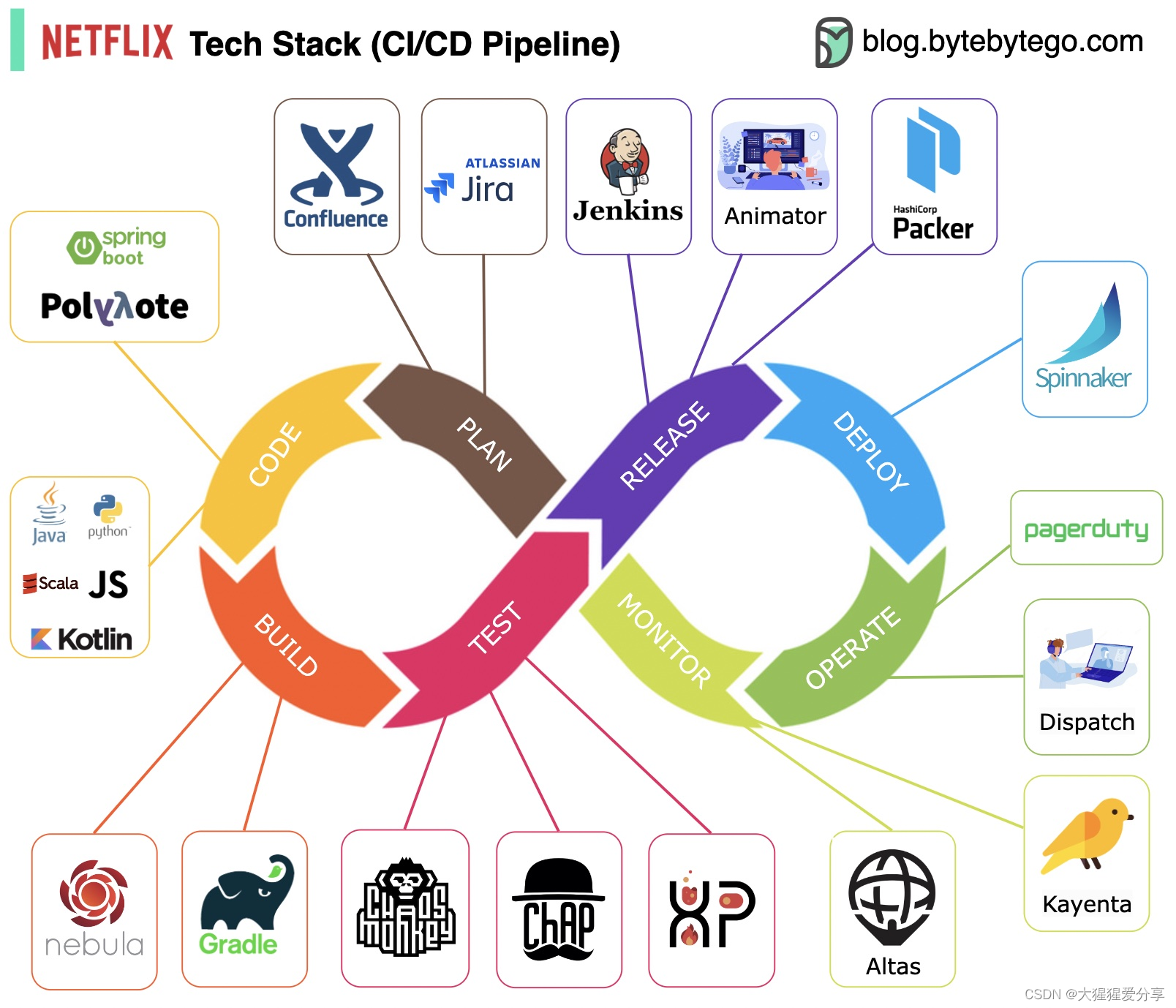
持续集成和持续交付
引言 CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。CI/CD 的核心概念是持续集成、持续交付和持续部署。作为一种面向开发和运维团队的解决方案,CI/CD 主要针对在集成新代码时所引发的问题(亦称:“集成地狱”&#…...

C#、JavaScript、VBScript解析JSON数据源码
本示例使用设备:WIFI/TCP/UDP/HTTP协议RFID液显网络读卡器可二次开发语音播报POE-淘宝网 (taobao.com) C#解析JSON数据 string dispstr "{" getChinesecode("扫码") ":}" data; //显示信息,注意中文汉字一定要转换为设备能显…...
JVM面试连环炮:你准备好迎接挑战了吗?
在Java开发领域,JVM面试一直是一个热门话题。作为一名优秀的开发者,你是否已经准备好迎接这场挑战了呢?今天,我们就来深度解析一下JVM面试的热点问题,帮助你更好地应对面试,一举拿下offer! 1、…...

Ansible通过kubernetes.core.k8s_info和kubernetes.core.k8s访问OCP
文章目录 环境OCPClient(Ansible控制节点) 步骤准备工作在client端配置ssh免密登录OCP端在client端安装Ansible kubernetes.core.k8s_info第1次尝试在OCP端安装python和pip3在OCP端安装kubernetes在OCP端安装PyYAML第2次尝试在OCP端配置config文件第3次尝…...

vscode汉化
安装插件 Chinese (Simplified) (简体中文) Language Pack for 重新打开,若还是没有汉化: 【CtrlShiftp】 输入“configure display language”,回车键 选择刚刚安装的 中文(简体)...

像素幻梦·创意工坊实操手册:批量生成任务队列管理与异步导出机制
像素幻梦创意工坊实操手册:批量生成任务队列管理与异步导出机制 1. 认识像素幻梦创意工坊 Pixel Dream Workshop(像素幻梦创意工坊)是一款基于FLUX.1-dev扩散模型的像素艺术生成工具。它采用16-bit像素风格的现代化界面设计,为创…...

seo兼职如何做外链建设_seo兼职如何进行社交媒体优化
SEO兼职如何做外链建设 在当今互联网时代,外链建设无疑是SEO(搜索引擎优化)中最重要的一环。对于SEO兼职者来说,如何有效地进行外链建设是一项必须掌握的技能。本文将从问题分析、原因说明、解决方法及注意事项四个方面ÿ…...

开箱即用!Retinaface+CurricularFace人脸识别镜像一键部署与测试
开箱即用!RetinafaceCurricularFace人脸识别镜像一键部署与测试 你是否曾对复杂的人脸识别项目望而却步?面对PyTorch、CUDA版本冲突、模型下载和环境配置的层层阻碍,是不是感觉还没开始写代码,精力就已经耗尽了?今天&…...

鸿蒙与微软:共生演进中的生态对话
在数字化浪潮席卷全球的今天,操作系统作为连接人与数字世界的“中枢神经”,其重要性不言而喻。它不仅是硬件设备的灵魂,更是数据流转与应用服务的基石,承载着数字经济发展的底层逻辑。鸿蒙操作系统(HarmonyOSÿ…...
)
C#运动控制入门:从零开始用PID算法控制伺服电机(附完整代码)
C#运动控制入门:从零开始用PID算法控制伺服电机(附完整代码) 第一次尝试用代码控制伺服电机时,我盯着那台嗡嗡作响的设备,看着它时而抽搐、时而狂奔,完全不像预期那样优雅地移动到指定位置。那一刻我意识到…...

嵌入式Linux网络状态检测方案与优化实践
1. 嵌入式设备网络状态检测实战指南 在嵌入式Linux开发中,网络连接状态的实时监测是个常见但容易被忽视的需求。想象一下,你正在开发一个智能家居网关,突然Wi-Fi断了,但设备还在傻乎乎地发送数据;或者工业现场的设备&a…...

基于STM32的简易示波器设计与实现
1. 项目概述 这个基于STM32的开源简易示波器项目,是我最近用正点原子精英板完成的一个实用工具开发。作为一个嵌入式开发者,我经常需要观察各种信号波形,但专业示波器价格昂贵且不便携。于是决定自己动手做一个成本低廉、功能实用的简易示波器…...

告别命令行恐惧:用LLaMA-Factory的Gradio WebUI,像玩积木一样微调你的大模型
告别命令行恐惧:用LLaMA-Factory的Gradio WebUI,像玩积木一样微调你的大模型 当大模型技术从实验室走向产业应用时,一个残酷的现实摆在眼前:90%的潜在使用者被命令行界面挡在门外。那些闪烁着光标的神秘终端窗口,就像一…...

Arduino嵌入式Google日历客户端:轻量级流式JSON解析
1. 项目概述 GoogleCalendarClient 是一个面向 Arduino 微控制器平台的轻量级 C 库,专为在资源受限的嵌入式系统中访问 Google Calendar REST API 而设计。其核心目标并非实现完整的 OAuth2 流程或全功能日历管理,而是提供一种 工程上可行、内存可预测…...

边缘计算与云原生集成:构建智能边缘系统
边缘计算与云原生集成:构建智能边缘系统 前言 作为一个在数据深渊里捞了十几年 Bug 的女码农,我深知边缘计算在现代 IT 架构中的重要性。随着物联网设备的爆发式增长和 5G 技术的普及,边缘计算已经成为云计算的重要补充,为实时数据…...