arXiv学术速递笔记12.8
文章目录
- 一、GSGFormer: Generative Social Graph Transformer for Multimodal Pedestrian Trajectory Prediction(GSGFormer:用于多通道行人轨迹预测的产生式社会图转换器)
- 二、AnimateZero: Video Diffusion Models are Zero-Shot Image Animators(AnimateZero:视频扩散模型是Zero-Shot图像动画师)
- 三、Camera Height Doesn't Change: Unsupervised Monocular Scale-Aware Road-Scene Depth Estimation(摄像机高度不变:无监督单目尺度感知道路场景深度估计)
- 四、On the Robustness of Large Multimodal Models Against Image Adversarial Attacks(大型多模模型对图像攻击的稳健性研究)
- 五、Towards Knowledge-driven Autonomous Driving(走向知识驱动的自动驾驶)
- 六、Receding Horizon Re-ordering of Multi-Agent Execution Schedules
- 参考文献
一、GSGFormer: Generative Social Graph Transformer for Multimodal Pedestrian Trajectory Prediction(GSGFormer:用于多通道行人轨迹预测的产生式社会图转换器)
标题: GSGFormer:用于多通道行人轨迹预测的产生式社会图转换器
链接: https://arxiv.org/abs/2312.04479
作者: Zhongchang Luo,Marion Robin,Pavan Vasishta
摘要: 行人轨迹预测对于自动驾驶汽车和具有社会意识的机器人至关重要,由于行人、他们的环境和其他弱势道路使用者之间的复杂互动,因此非常复杂。本文介绍了GSGFormer,一个创新的生成模型,善于预测行人轨迹,考虑这些复杂的相互作用,并提供了大量的潜在的模态行为。我们结合了一个异构的图神经网络来捕捉行人,语义地图和潜在目的地之间的交互。Transformer模块提取时间特征,而我们新的CVAE残差GMM模块促进了多样化的行为模态生成。通过对多个公共数据集的评估,GSGFormer不仅在数据充足的情况下优于领先的方法,而且在数据有限的情况下仍然具有竞争力。
摘要: Pedestrian trajectory prediction, vital for selfdriving cars and socially-aware robots, is complicated due to intricate interactions between pedestrians, their environment, and other Vulnerable Road Users. This paper presents GSGFormer, an innovative generative model adept at predicting pedestrian trajectories by considering these complex interactions and offering a plethora of potential modal behaviors. We incorporate a heterogeneous graph neural network to capture interactions between pedestrians, semantic maps, and potential destinations. The Transformer module extracts temporal features, while our novel CVAE-Residual-GMM module promotes diverse behavioral modality generation. Through evaluations on multiple public datasets, GSGFormer not only outperforms leading methods with ample data but also remains competitive when data is limited.
二、AnimateZero: Video Diffusion Models are Zero-Shot Image Animators(AnimateZero:视频扩散模型是Zero-Shot图像动画师)
标题: AnimateZero:视频扩散模型是Zero-Shot图像动画师
链接: https://arxiv.org/abs/2312.03793
作者: Jiwen Yu,Xiaodong Cun,Chenyang Qi,Yong Zhang,Xintao Wang,Ying Shan,Jian Zhang
备注: Project Page: this https URL
摘要: 近年来,大规模文本到视频(T2V)扩散模型在视觉质量、运动和时间一致性方面取得了很大进展。然而,生成过程仍然是一个黑盒子,其中所有属性(例如,外观、运动)被联合地学习和生成,除了粗略的文本描述之外,没有精确的控制能力。受图像动画的启发,将视频作为一个特定的外观与相应的运动相结合,我们提出了AnimateZero来揭示预先训练的文本到视频扩散模型,即:AnimateDiff,并为其提供更精确的外观和运动控制能力。对于外观控制,我们从文本到图像(T2I)生成中借用中间潜伏期及其特征,以确保生成的第一帧等于给定的生成图像。对于时间控制,我们将原始T2V模型的全局时间注意力替换为我们提出的位置校正窗口注意力,以确保其他帧与第一帧对齐。通过所提出的方法,AnimateZero可以成功地控制生成进度,而无需进一步的训练。作为给定图像的zero-shot图像动画制作器,AnimateZero还支持多个新应用,包括交互式视频生成和真实图像动画。详细的实验证明了该方法在T2V及相关应用中的有效性。
摘要:Large-scale text-to-video (T2V) diffusion models have great progress in recent years in terms of visual quality, motion and temporal consistency. However, the generation process is still a black box, where all attributes (e.g., appearance, motion) are learned and generated jointly without precise control ability other than rough text descriptions. Inspired by image animation which decouples the video as one specific appearance with the corresponding motion, we propose AnimateZero to unveil the pre-trained text-to-video diffusion model, i.e., AnimateDiff, and provide more precise appearance and motion control abilities for it. For appearance control, we borrow intermediate latents and their features from the text-to-image (T2I) generation for ensuring the generated first frame is equal to the given generated image. For temporal control, we replace the global temporal attention of the original T2V model with our proposed positional-corrected window attention to ensure other frames align with the first frame well. Empowered by the proposed methods, AnimateZero can successfully control the generating progress without further training. As a zero-shot image animator for given images, AnimateZero also enables multiple new applications, including interactive video generation and real image animation. The detailed experiments demonstrate the effectiveness of the proposed method in both T2V and related applications.
三、Camera Height Doesn’t Change: Unsupervised Monocular Scale-Aware Road-Scene Depth Estimation(摄像机高度不变:无监督单目尺度感知道路场景深度估计)
标题: 摄像机高度不变:无监督单目尺度感知道路场景深度估计
链接: https://arxiv.org/abs/2312.04530
作者: Genki Kinoshita,Ko Nishino
摘要: 单目深度估计器要么需要通过辅助传感器进行明确的尺度监督,要么存在尺度模糊性,这使得它们难以在下游应用中部署。缩放的一个可能来源是场景中发现的对象的大小,但不准确的定位使它们难以利用。在本文中,我们介绍了一种新的尺度感知的单目深度估计方法,称为StableCamH,不需要任何辅助传感器或监督。其关键思想是利用场景中物体高度的先验知识,但将高度线索聚合成道路视频序列中所有帧共同的单个不变测度,即相机高度。通过将单目深度估计公式化为相机高度优化,我们实现了鲁棒且准确的无监督端到端训练。为了实现StableCamH,我们设计了一种新的基于学习的尺寸先验,可以直接将汽车外观转换为尺寸。在KITTI和Cityscapes上的大量实验表明了StableCamH的有效性,与相关方法相比,其最先进的准确性及其通用性。StableCamH的训练框架可用于任何单目深度估计方法,并有望成为进一步工作的基本构建块。
摘要:Monocular depth estimators either require explicit scale supervision through auxiliary sensors or suffer from scale ambiguity, which renders them difficult to deploy in downstream applications. A possible source of scale is the sizes of objects found in the scene, but inaccurate localization makes them difficult to exploit. In this paper, we introduce a novel scale-aware monocular depth estimation method called StableCamH that does not require any auxiliary sensor or supervision. The key idea is to exploit prior knowledge of object heights in the scene but aggregate the height cues into a single invariant measure common to all frames in a road video sequence, namely the camera height. By formulating monocular depth estimation as camera height optimization, we achieve robust and accurate unsupervised end-to-end training. To realize StableCamH, we devise a novel learning-based size prior that can directly convert car appearance into its dimensions. Extensive experiments on KITTI and Cityscapes show the effectiveness of StableCamH, its state-of-the-art accuracy compared with related methods, and its generalizability. The training framework of StableCamH can be used for any monocular depth estimation method and will hopefully become a fundamental building block for further work.
四、On the Robustness of Large Multimodal Models Against Image Adversarial Attacks(大型多模模型对图像攻击的稳健性研究)
标题: 大型多模态模型对图像攻击的稳健性研究
链接: https://arxiv.org/abs/2312.03777
作者: Xuanimng Cui,Alejandro Aparcedo,Young Kyun Jang,Ser-Nam Lim
摘要: 指令调优方面的最新进展导致了最先进的大型多模态模型(Large Multimodal Models,LMM)的发展。鉴于这些模型的新颖性,视觉对抗性攻击对LMM的影响尚未得到彻底研究。我们全面研究了各种Linux对不同对抗性攻击的鲁棒性,评估了包括图像分类、图像字幕和视觉问答(VQA)在内的任务。我们发现,在一般情况下,Lebron是不鲁棒的视觉对抗性输入。然而,我们的研究结果表明,通过提示向模型提供的上下文,例如QA对中的问题,有助于减轻视觉对抗输入的影响。值得注意的是,评估的Lencil在ScienceQA任务中表现出了对此类攻击的出色弹性,与视觉同行相比,性能仅下降了8.10%,而视觉同行下降了99.73%。我们还提出了一种新的方法来现实世界的图像分类,我们术语查询分解。通过将存在查询纳入我们的输入提示中,我们观察到攻击有效性降低和图像分类准确性提高。这项研究突出了LMM鲁棒性的一个以前未被充分探索的方面,并为未来旨在加强多模态系统在对抗环境中的弹性的工作奠定了基础。
摘要:Recent advances in instruction tuning have led to the development of State-of-the-Art Large Multimodal Models (LMMs). Given the novelty of these models, the impact of visual adversarial attacks on LMMs has not been thoroughly examined. We conduct a comprehensive study of the robustness of various LMMs against different adversarial attacks, evaluated across tasks including image classification, image captioning, and Visual Question Answer (VQA). We find that in general LMMs are not robust to visual adversarial inputs. However, our findings suggest that context provided to the model via prompts, such as questions in a QA pair helps to mitigate the effects of visual adversarial inputs. Notably, the LMMs evaluated demonstrated remarkable resilience to such attacks on the ScienceQA task with only an 8.10% drop in performance compared to their visual counterparts which dropped 99.73%. We also propose a new approach to real-world image classification which we term query decomposition. By incorporating existence queries into our input prompt we observe diminished attack effectiveness and improvements in image classification accuracy. This research highlights a previously under-explored facet of LMM robustness and sets the stage for future work aimed at strengthening the resilience of multimodal systems in adversarial environments.
五、Towards Knowledge-driven Autonomous Driving(走向知识驱动的自动驾驶)
标题: 走向知识驱动的自动驾驶
链接: https://arxiv.org/abs/2312.04316
作者: Xin Li,Yeqi Bai,Pinlong Cai,Licheng Wen,Daocheng Fu,Bo Zhang,Xuemeng Yang,Xinyu Cai,Tao Ma,Jianfei Guo,Xing Gao,Min Dou,Botian Shi,Yong Liu,Liang He,Yu Qiao
摘要: 本文探讨了新兴的知识驱动的自动驾驶技术。我们的调查强调了当前自动驾驶系统的局限性,特别是它们对数据偏差的敏感性,处理长尾场景的困难以及缺乏可解释性。知识驱动的方法具有认知、概括和终身学习的能力,是克服这些挑战的一种有前途的方法。本文深入研究了知识驱动的自动驾驶的本质,并研究了其核心组件:数据集\基准,环境和驱动程序代理。通过利用大型语言模型、世界模型、神经渲染和其他先进的人工智能技术,这些组件共同为更全面、自适应和智能的自动驾驶系统做出了贡献。本文系统地整理和回顾了这一领域的研究成果,并为自动驾驶的未来研究和实际应用提供了见解和指导。我们将持续分享知识驱动自动驾驶领域的最新发展动态以及相关的宝贵开源资源,网址为:https//github.com/PJLab-ADG/awesome-knowledge-driven-AD。
摘要:This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset & benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.
六、Receding Horizon Re-ordering of Multi-Agent Execution Schedules
标题: 多智能体执行调度的后退视界重排序
*链接: *https://arxiv.org/abs/2312.04190
作者: Alexander Berndt,Niels van Duijkeren,Luigi Palmieri,Alexander Kleiner,Tamás Keviczky
备注: IEEE Transactions on Robotics (T-Ro) preprint, 17 pages, 32 figures
摘要: 在路线图上为自动引导车辆(AGV)车队进行轨迹规划通常被称为多智能体路径查找(MAPF)问题,该问题的解决方案决定了每个AGV的空间和时间位置,直到它到达目标而不发生碰撞。在动态调度中执行MAPF计划时,AGV可能会频繁延迟,例如,由于遇到人类或第三方车辆。如果其余的AGV继续遵循各自的计划,则车队的同步性会丢失,并且某些AGV可能会以与原始计划不同的顺序通过路线图交叉点。虽然这可以减少AGV的累计路径完成时间,但通常,原始顺序的更改可能会导致冲突,例如死锁。因此,在实践中,通常通过使用MAPF执行策略来强制同步,该MAPF执行策略采用例如,一个动作依赖图(ADG)来维持顺序。为了在不引入死锁的情况下安全地重新排序,我们提出了可切换动作依赖图(SADG)的概念。使用的SADG,我们制定了一个相对低维的混合线性规划(MILP),反复重新排序AGV在递归可行的方式,从而保持无死锁的保证,同时动态地最小化所有AGV的累计路线完成时间。各种模拟验证了我们的方法相比,原始ADG方法以及强大的MAPF解决方案的方法的效率。
摘要: The trajectory planning for a fleet of Automated Guided Vehicles (AGVs) on a roadmap is commonly referred to as the Multi-Agent Path Finding (MAPF) problem, the solution to which dictates each AGV’s spatial and temporal location until it reaches it’s goal without collision. When executing MAPF plans in dynamic workspaces, AGVs can be frequently delayed, e.g., due to encounters with humans or third-party vehicles. If the remainder of the AGVs keeps following their individual plans, synchrony of the fleet is lost and some AGVs may pass through roadmap intersections in a different order than originally planned. Although this could reduce the cumulative route completion time of the AGVs, generally, a change in the original ordering can cause conflicts such as deadlocks. In practice, synchrony is therefore often enforced by using a MAPF execution policy employing, e.g., an Action Dependency Graph (ADG) to maintain ordering. To safely re-order without introducing deadlocks, we present the concept of the Switchable Action Dependency Graph (SADG). Using the SADG, we formulate a comparatively low-dimensional Mixed-Integer Linear Program (MILP) that repeatedly re-orders AGVs in a recursively feasible manner, thus maintaining deadlock-free guarantees, while dynamically minimizing the cumulative route completion time of all AGVs. Various simulations validate the efficiency of our approach when compared to the original ADG method as well as robust MAPF solution approaches.
参考文献
- 计算机视觉与模式识别学术速递[12.8]
相关文章:

arXiv学术速递笔记12.8
文章目录 一、GSGFormer: Generative Social Graph Transformer for Multimodal Pedestrian Trajectory Prediction(GSGFormer:用于多通道行人轨迹预测的产生式社会图转换器)二、AnimateZero: Video Diffusion Models are Zero-Shot Image An…...

大模型元年压轴盛会定档12月28日,第十届WAVE SUMMIT即将启航
文章目录 1. 前言2. WAVE SUMMIT五载十届,AI开发者热血正当时3. 酷炫前沿、星河共聚!大模型技术生态发展正当时 1. 前言 回望2023年,大语言模型或许将是科技史上最浓墨重彩的一笔。从技术、产业到生态,大语言模型在突飞猛进中加速…...
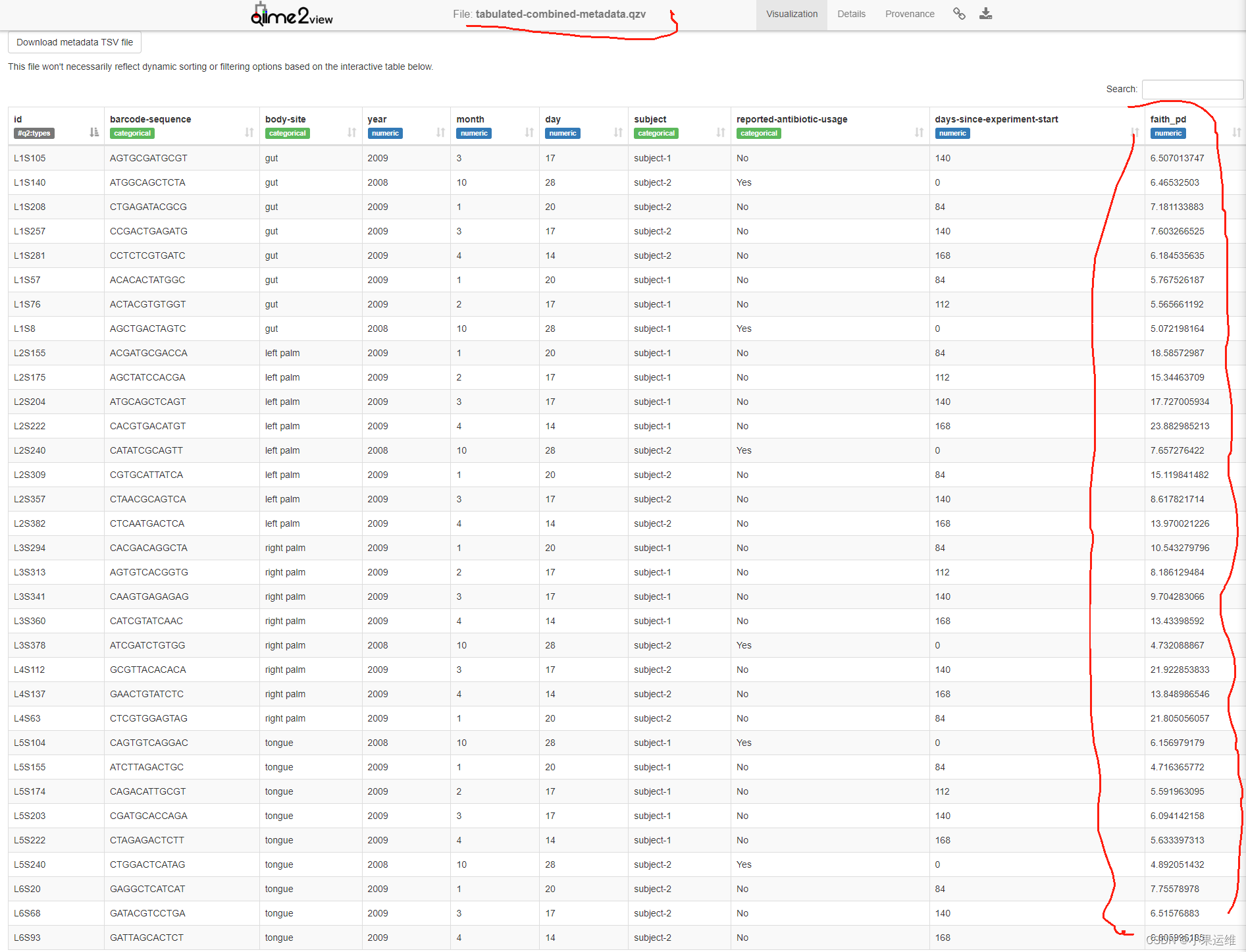
基于conda环境使用mamba/conda安装配置QIIME 2 2023.9 Amplicon扩增子分析环境,q2cli主要功能模块介绍及使用
QIIME 2 2023.9 Amplicon Distribution介绍: 概述 qiime团队专门针对高通量扩增子序列分析退出的conda集成环境,包括了主要和常见的扩增子分析模块,用户可以单独使用各个模块,也可以使用各模块组成不同的分析流程。从2023.09版本…...

腾讯-轻量应用服务器centos7中宝塔安装MySQL8.0出现内存不足
目录 前言 出现的问题: 解决方法: 编译安装: 极速安装 其他 我的其他博客 前言 说实话,本人也就是个穷学生买不起啥大的服务器啥的,整了个2核 2内存的服务器 用宝塔按mysql5.5是没问题的,一切换8.0就提醒内存不足…...
调用Win10隐藏的语音包
起因 在做一个文本转语音的Demo的时候,遇到了语音包无法正确被Unity识别的问题。明明电脑上安装了语音包但是代码就是识别不出来 原因 具体也不是非常清楚,但是如果语言包是在的话,大概率是Win10系统隐藏了。 确定语言包 首先查看%windi…...

【WPF】应用程序和已知安卓设备的局域网IP之间进行通信
要在WPF应用程序和已知安卓设备的局域网IP之间进行通信,可以使用Socket通信。以下是一个基本的示例: 在WPF应用程序中创建一个Socket对象并连接到安卓设备的IP地址和端口号: using System.Net.Sockets;// 创建一个Socket对象 Socket socket…...
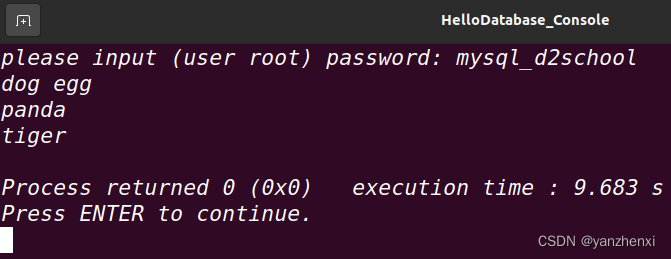
linux Ubuntu下,第一个C++程序访问数据库,遇到的问题,及解决办法
在ubuntu下安装了mysql,mysql以后,编写了第一个访问数据库的程序: #include <iostream> #include <string> #include <cstdlib> //for system #include <mysql.h>using namespace std;int main() {mysqlpp::Connect…...

【Flink on k8s】- 7 - 在本地运行第一个 flink wordcount job
目录 1、环境准备 2、代码开发 3、启动运行 4、在控制台找到 web ui,查看监控...

velocity-engine-core是什么?Velocity模板引擎的使用
velocity-engine-core是什么?Velocity模板引擎的使用 1. 常见的模板引擎2. Velocity 的语法3.Velocity的使用 相信在日常开发中或多或少都听过或者使用过模板引擎,比如熟知的freemarker, thymeleaf等。而模板引擎就是为了实现View和Data分离而产生的。 而…...

【华为od】存在一个m*n的二维数组,其成员取值范围为0,1。其中值为1的元素具备扩散性,每经过1S,将上下左右值为0的元素同化为1。
存在一个m*n的二维数组,其成员取值范围为0,1。其中值为1的元素具备扩散性,每经过1S,将上下左右值为0的元素同化为1。将数组所有成员初始化为0,将矩阵的[i, j]和[m,n]位置上元素修改成1后,在经过多长时间所有元素变为1。 输入描述 输入的前两个数字是矩阵大小。后面是数字…...
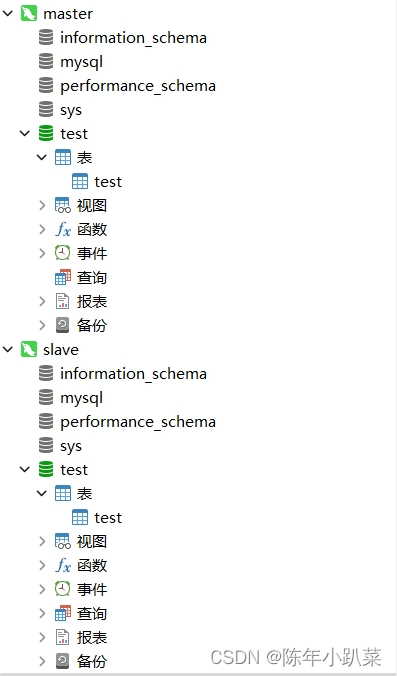
docker学习(七、搭建mysql8.2主从)
一、主库搭建 1.构建主库镜像 # 运行mysql镜像,配置端口3307为主库 docker run -p 3307:3306 --name mysql-master --privilegedtrue -v /mydata/mysql-master/log:/var/log/mysql -v /mydata/mysql-master/data:/var/lib/mysql -v /mydata/mysql-master/conf:/etc…...

消费升级:无人零售的崛起与优势
消费升级:无人零售的崛起与优势 随着人们生活水平的提高,消费内容正在从生存型消费转向以精神体验和享乐为主的发展型消费。社会居民的消费结构不断变迁,明显呈现消费升级趋势。个性化和多元化消费势头正在崛起,特别是无人零售的自…...

【开题报告】基于SpringBoot的煤炭企业安全宣传学习平台的设计与实现
1.选题背景 煤炭企业作为我国能源行业的重要组成部分,承担着国民经济的支撑和推动作用。然而,煤炭生产过程中存在较高的安全风险,煤矿事故频发,给人员生命财产安全带来严重威胁,也给社会稳定和经济发展带来不利影响。…...

机器连接和工业边缘计算
软件应用和IT创新是制造业投资的主要驱动力。解决方案架构应围绕特定标准进行整合,并采用架构蓝图和最佳实践来满足最终用户的需求。此外,边缘计算(Edge Computing)也将在制造业中加速部署。 边缘计算是制造业的下一个变革驱动力。…...
java系列-LinkedHashMap
1.插入新节点时,会将该节点加到链表尾部 public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{/*** The head (eldest) of the doubly linked list.*/transient LinkedHashMapEntry<K,V> head;/*** The tail (young…...

【linux】查看CPU和内存信息
之前咱们一起学习了查看内存的和CPU的命令。 mpstat : 【linux】 mpstat 使用 uptime:【Linux】 uptime命令使用 CPU的使用率:【linux】查看CPU的使用率 nmon :【linux】nmon 工具使用 htop :【linux】htop 命令…...

【产品经理】产品专业化提升路径
产品专业化就是上山寻路,梳理一套作为产品经理的工作方法。本文作者从设计方法、三基座、专业强化、优秀产品拆解、零代码这五个方面,对产品经理的产品专业化进行了总结归纳,一起来看一下吧。 产品专业化就是上山寻路,梳理一套作为…...
卸载与安装指定版本的 openssl)
Ubuntu(WSL)卸载与安装指定版本的 openssl
卸载 openssl 1)查找并删除 openssl 关联的目录与文件 whereis opensslwhich opensslrm -rf /a/b/c/ // 使用 rm 命令删除所有 openssl 相关目录 2)删除软件安装包 apt-get purge openssl 3)删除配置文件 rm -rf /etc/ssl 安装 ope…...

leetcode1115. 交替打印 FooBar
题目 1115. 交替打印 FooBar 给你一个类: class FooBar {public void foo() {for (int i 0; i < n; i) {print("foo");}}public void bar() {for (int i 0; i < n; i) {print("bar");}} }两个不同的线程将会共用一个 FooBar 实例&am…...

qt有哪些常用控件
Qt 是一个跨平台的应用程序开发框架,提供了许多不同类型的控件来构建用户界面。以下是一些常见的 Qt 控件: 按钮(Button):用于执行操作或触发事件。文本框(TextBox):用于输入和显示文…...

终极指南:告别鼠标!Spectacle窗口动作组合让复杂布局一键生成 [特殊字符]
终极指南:告别鼠标!Spectacle窗口动作组合让复杂布局一键生成 🚀 【免费下载链接】spectacle Spectacle allows you to organize your windows without using a mouse. 项目地址: https://gitcode.com/gh_mirrors/sp/spectacle 想要提…...

3步驯服锐龙:RyzenAdj性能调校实战指南
3步驯服锐龙:RyzenAdj性能调校实战指南 【免费下载链接】RyzenAdj Adjust power management settings for Ryzen APUs 项目地址: https://gitcode.com/gh_mirrors/ry/RyzenAdj 问题诊断:你的锐龙处理器是否被"封印"? 场景一…...
TranslucentTB高效配置指南:场景化方案实现Windows任务栏个性化
TranslucentTB高效配置指南:场景化方案实现Windows任务栏个性化 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 作为一款开源…...

李慕婉-仙逆-造相Z-Turbo应用:自动化小说解析与视觉化内容生成系统
李慕婉-仙逆-造相Z-Turbo应用:自动化小说解析与视觉化内容生成系统 想象一下,你是一家网络文学平台的内容运营。每天,海量的新章节需要配图,作者们渴望看到自己笔下的人物和世界被具象化,读者则期待更沉浸的阅读体验。…...

Infect工具完整教程:快速掌握Android设备病毒传播技术
Infect工具完整教程:快速掌握Android设备病毒传播技术 【免费下载链接】infect Infect Any Android Device With Virus From Link In Termux 项目地址: https://gitcode.com/gh_mirrors/in/infect Infect是一款基于Bash的Android病毒传播工具,专为…...

OpenClaw模型微调:让Phi-3-mini适配你的专属工作流
OpenClaw模型微调:让Phi-3-mini适配你的专属工作流 1. 为什么需要微调Phi-3-mini? 当我第一次将Phi-3-mini接入OpenClaw时,发现这个"聪明"的小模型在处理我的专业领域任务时总有些力不从心。它能够理解通用指令,但当我…...

如何在 React 中正确绑定 onClick 事件以避免类型错误
React 中 onClick 期望接收一个函数,若传入字符串或直接执行表达式(如 window.href...)会导致“Expected onclick listener to be a function”报错;正确做法是使用箭头函数包裹逻辑。 react 中 onclick 期望接收一个函数&am…...
)
【面板数据】A股上市公司研发投入数据(2000-2024年)
数据简介:作为评估企业创新能力与可持续发展潜力的关键维度,上市公司研发投入呈现显著的行业差异化特征,但总体保持稳健增长态势。随着信息披露监管要求的持续强化,研发投入透明度已成为提升企业市场信誉的重要抓手。值得注意的是…...

c++如何利用C++23的std--expected重构文件操作的错误管理代码【实战】
std::expected<T, E> 是 C23 提供的零成本错误处理机制,强制调用方显式处理成功与失败分支,适用于预期会失败且需响应的场景(如文件操作、网络请求),优于 errno 返回值、std::optional 或异常滥用。std::expect…...
的5个常见错误与正确写法)
GX Works2编程避坑指南:PLC数据传输指令(MOV/FMOV/BMOV)的5个常见错误与正确写法
GX Works2编程避坑指南:PLC数据传输指令的5个致命陷阱与工业级解决方案 在自动化产线的深夜调试现场,一个看似简单的MOV指令错误可能导致整条生产线异常停机——这种场景对PLC工程师来说绝不陌生。三菱GX Works2作为工业控制领域的标杆软件,其…...