hive自定义函数及案例
一.自定义函数
1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。
3.根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function) 一进一出。
(2)UDAF(User-Defined Aggregation Function) 用户自定义聚合函数,多进一出 。
(3)UDTF(User-Defined Table-Generating Functions) 用户自定义表生成函数,一进多出。
4.编程步骤
(1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
(2)实现类中的抽象方法
(3)在hive的命令行窗口创建函数
(4) 创建临时函数
需要把jar包上传到服务器上面
添加jar。
add jar linux_jar_path
创建function
create temporary function dbname.function_name AS class_name;
删除函数
drop temporary function if exists dbname.function_name;
(5)创建永久函数
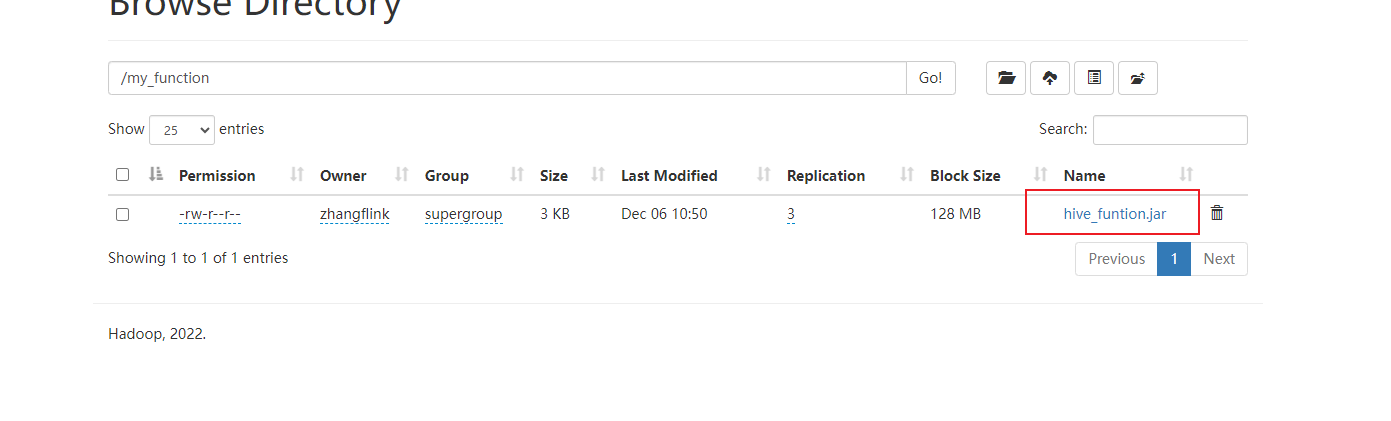
需要把jar包上传到hdfs上面,创建函数时jar包的位置使用hdfs的地址。
创建function
create function if exists my_udtf as "com.zxl.hive.udf.ExplodeJSONArray" using jar "hdfs://flinkv1:8020/my_function/hive_udtf_funtion.jar";
删除函数
drop function if exists my_udtf ;
注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。 永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
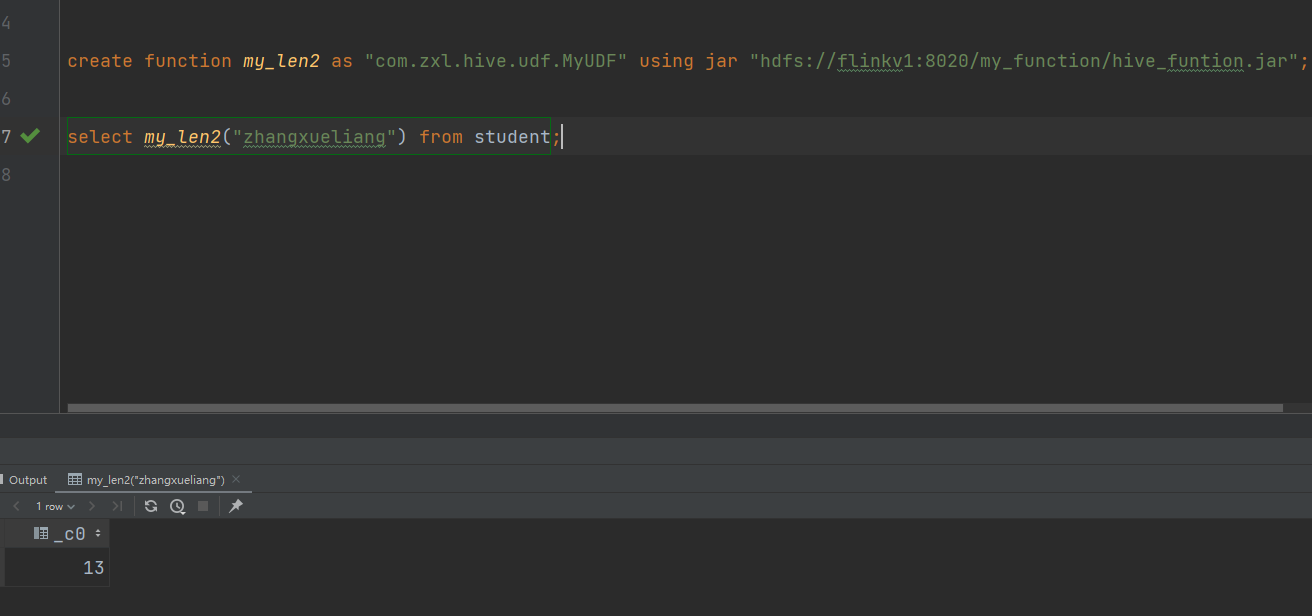
二.UDF
官方案例:https://cwiki.apache.org/confluence/display/Hive/HivePlugins#HivePlugins-CreatingCustomUDFs
计算给定基本数据类型的长度
package com.zxl.hive.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;public class MyUDF extends GenericUDF {/** 判断传进来的参数的类型和长度* 约定返回的数据类型* */@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {//判断传进来的参数的长度if (arguments.length !=1) {throw new UDFArgumentLengthException("please give me only one arg");}//判断传进来的参数的类型if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){throw new UDFArgumentTypeException(1, "i need primitive type arg");}// 约定返回的数据类型return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}/** 具体解决逻辑* */@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {Object o = arguments[0].get();if(o==null){return 0;}return o.toString().length();}/** 用于获取解释的字符串* */@Overridepublic String getDisplayString(String[] strings) {return "";}
}
(1)创建永久函数
注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
三.UDTF
官网案例:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide+UDTF
执行步骤
要实现UDTF,我们需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息,返回个数,类型;
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数;
最后close()方法调用,对需要清理的方法进行清理。
关于HIVE的UDTF自定义函数使用的更多详细内容请看:
转载原文链接:https://blog.csdn.net/lidongmeng0213/article/details/110877351
下面是json日志解析案例:
package com.zxl.hive.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;import java.util.ArrayList;
import java.util.List;public class ExplodeJSONArray extends GenericUDTF {/*** 初始化方法,里面要做三件事* 1.约束函数传入参数的个数* 2.约束函数传入参数的类型* 3.约束函数返回值的类型*/@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {// TODO: 2023/12/6 返回结构体类型。udtf函数,有可能炸开之后形成多列。所以用返回结构体来封装。属性名:属性值。属性名就是列名;属性值就是列的类型。//用结构体,来约束函数传入参数的个数//List<? extends StructField> allStructFieldRefs = argOIs.getAllStructFieldRefs(); --见名知意,获取结构体所有属性的引用 可以看见返回值是个list类型.if(argOIs.getAllStructFieldRefs().size()!=1){ //只要个数不等于1,就抛出异常throw new UDFArgumentLengthException("explode_json_array()函数的参数个数只能为1");}//2.约束函数传入参数的类型// StructField structField = argOIs.getAllStructFieldRefs().get(0);//只能有一个参数,所以index给0 可以看见,是获得结构体的属性//ObjectInspector fieldObjectInspector = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector();//获得属性的对象检测器 。通过检查器我们才能知道是什么类型.String typeName = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector().getTypeName();//我们要确保传入的类型是stringif(!"string".equals(typeName)){throw new UDFArgumentTypeException(0,"explode_json_array函数的第1个参数的类型只能为String."); //抛出异常}//3.约束函数返回值的类型List<String> fieldNames = new ArrayList<>(); //② 表示我建立了一个String类型的集合。表示存储的列名List<ObjectInspector> fieldOIs = new ArrayList<>(); //②fieldNames.add("item"); //炸裂之后有个列名,如果不重新as,那这个item就是列名fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); //表示item这一列是什么类型.基本数据类型工厂类,获取了个string类型的检查器//用一个工厂类获取StructObjectInspector类型。return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);//①获取标准结构体检查器。fieldNames,fieldOI是两个变量名}//这里是实现主逻辑的方法。首先分析下需求:把json array字符串变成一个json字符串@Overridepublic void process(Object[] args) throws HiveException {//1 获取函数传入的jsonarray字符串String jsonArrayStr = args[0].toString(); //我要把jsonArrayStr字符串划分为一个一个的json,通过字符串这种类型是不好划分的。不知道如何split切分//2 将jsonArray字符串转换成jsonArray数组。正常情况下我们要引入依赖,比如fastjson啥的。JSONArray jsonArray = new JSONArray(jsonArrayStr); //通过JSONArray这种类型,我们就比较容易获得一条条的json字符串//3 得到jsonArray里面的一个个json,并把他们写出。将actions里面的一个个action写出for (int i = 0; i < jsonArray.length(); i++) { //普通for循环进行遍历String jsonStr = jsonArray.getString(i);//前面定义了,要返回String//forward是最后收集数据返回的方法forward(jsonStr);}}@Overridepublic void close() throws HiveException {}
}
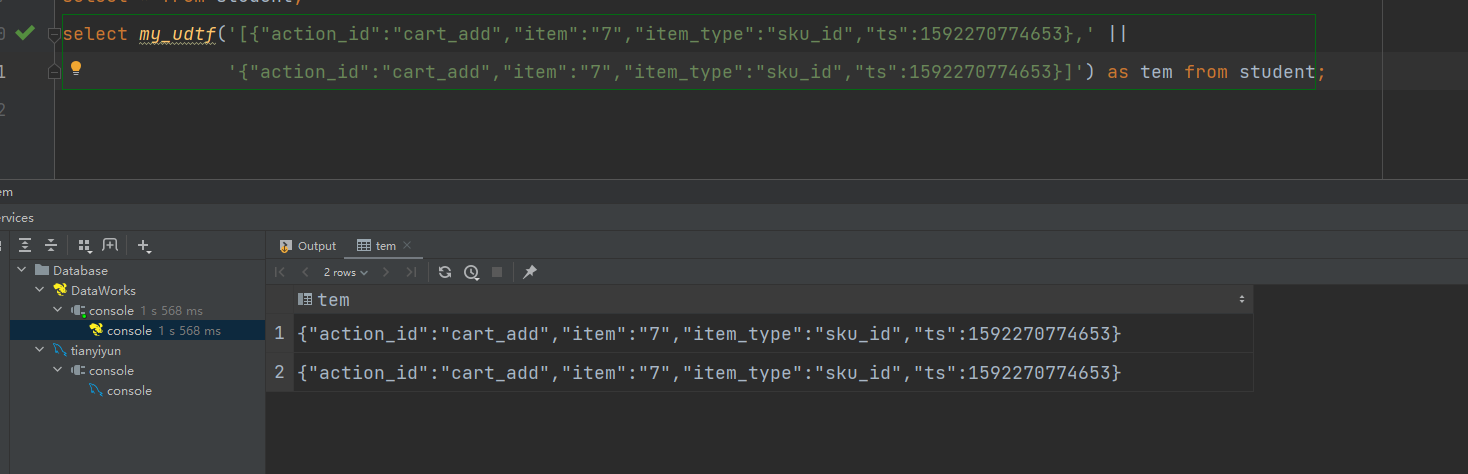
注意:UDTF函数不能和其他字段同时出现在select语句中,负责SQL会执行失败
三.UDAF
官网案例:https://cwiki.apache.org/confluence/display/Hive/GenericUDAFCaseStudy#GenericUDAFCaseStudy-Writingtheresolver
执行步骤:
编写自定义函数需要创建三个类:
1.继承 AbstractGenericUDAFResolver重写 getEvaluator方法,对传入的值进行判断。
2.创建数据缓存区,创建一些变量来进行调用赋值,作为中间值,类似于flink的checkpoints。
3.继承GenericUDAFEvaluator类重写方法即可,实现具体逻辑的类。
参考文章:
UDAF重要的类及原理分析(UDAF继承类的各个方法的用法)
原文链接:https://blog.csdn.net/lidongmeng0213/article/details/110869457
Hive之ObjectInspector详解(UDAF中用到的类型详解)
原文链接:https://blog.csdn.net/weixin_42167895/article/details/108314139
一个类似于SUM的自定义函数:
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;// TODO: 2023/12/9 继承 AbstractGenericUDAFResolver重写 getEvaluator方法
public class FieldSum extends AbstractGenericUDAFResolver {@Overridepublic GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {// TODO: 2023/12/9 判断传入的参数是否为一个if (info.length != 1) {throw new UDFArgumentLengthException("只能传入一个参数, 但是现在有 " + info.length + "个参数!");}/*TypeInfoUtils是一个Java类,它提供了一些用于处理Hive数据类型的实用方法。以下是TypeInfoUtils类中的一些方法及其功能:getTypeInfoFromTypeString(String typeString) - 将类型字符串转换为Hive数据类型信息对象。getStandardJavaObjectInspectorFromTypeInfo(TypeInfo typeInfo) - 从Hive数据类型信息对象中获取标准Java对象检查器。isExactNumericType(PrimitiveTypeInfo typeInfo) - 检查给定的Hive原始数据类型是否为精确数值类型。getCategoryFromTypeString(String typeString) - 从类型字符串中获取Hive数据类型的类别。getPrimitiveTypeInfoFromPrimitiveWritable(Class<? extends Writable> writableClass) -从Hadoop Writable类中获取Hive原始数据类型信息对象。*/ObjectInspector objectInspector = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(info[0]);// TODO: 2023/12/9 判断是不是标准的java Object的primitive类型if (objectInspector.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentTypeException(0, "Argument type must be PRIMARY. but " +objectInspector.getCategory().name() + " was passed!");}// 如果是标准的java Object的primitive类型,说明可以进行类型转换PrimitiveObjectInspector inputOI = (PrimitiveObjectInspector) objectInspector;// 如果是标准的java Object的primitive类型,判断是不是INT类型,因为参数只接受INT类型if (inputOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.INT) {throw new UDFArgumentTypeException(0, "Argument type must be INT, but " +inputOI.getPrimitiveCategory().name() + " was passed!");}return new FieldSumUDAFEvaluator();}@Overridepublic GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {return super.getEvaluator(info);}
}
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;// TODO: 2023/12/9 创建数据缓存区,创建一些变量来进行调用赋值,作为中间值,类似于flink的checkpoints。
public class FieldSumBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {Integer num = 0;// TODO: 2023/12/9 实现变量的get,set方法方便后面赋值,取值public Integer getNum() {return num;}public void setNum(int num) {this.num = num;}// TODO: 2023/12/9 创建累加的方法,方便对变量进行累加public Integer addNum(int aum) {num += aum;return num;}
}
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;// TODO: 2023/12/9 实现具体逻辑的地方 直接继承GenericUDAFEvaluator类重写方法即可
public class FieldSumUDAFEvaluator extends GenericUDAFEvaluator {// TODO: 2023/12/9 初始输入的变量 PrimitiveObjectInspector是Hadoop里面原始数据类别PrimitiveObjectInspector inputNum;PrimitiveObjectInspector middleNum;// TODO: 2023/12/9 最终输出的变量ObjectInspector outputNum;// TODO: 2023/12/9 最终统计值的变量int sumNum;// TODO: 2023/12/7 Model代表了UDAF在mapreduce的各个阶段。//* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合//* 将会调用iterate()和terminatePartial()//* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合://* 将会调用merge() 和 terminatePartial()//* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合//* 将会调用merge()和terminate()//* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合//* 将会调用 iterate()和terminate()// TODO: 2023/12/7 确定各个阶段输入输出参数的数据格式ObjectInspectors@Overridepublic ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {super.init(m, parameters);// TODO: 2023/12/9 COMPLETE或者PARTIAL1,输入的都是数据库的原始数据所以要确定输入的数据格式if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {inputNum = (PrimitiveObjectInspector) parameters[0];} else {middleNum = (PrimitiveObjectInspector) parameters[0];}// TODO: 2023/12/9 ObjectInspectorFactory是创建新的ObjectInspector实例的主要方法:一般用于创建集合数据类型。输出的类型是Integer类型,java类型outputNum = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,ObjectInspectorFactory.ObjectInspectorOptions.JAVA);return outputNum;}// TODO: 2023/12/9 保存数据聚集结果的类@Overridepublic AggregationBuffer getNewAggregationBuffer() throws HiveException {return new FieldSumBuffer();}// TODO: 2023/12/9 重置聚集结果@Overridepublic void reset(AggregationBuffer agg) throws HiveException {//重新赋值为零((FieldSumBuffer) agg).setNum(0);}// TODO: 2023/12/9 map阶段,迭代处理输入sql传过来的列数据,不断被调用执行的方法,最终数据都保存在agg中,parameters是新传入的数据@Overridepublic void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {// TODO: 2023/12/9 判断如果传入的值是空的直接返回if (parameters == null || parameters.length < 1) {return;}Object javaObj = inputNum.getPrimitiveJavaObject(parameters[0]);((FieldSumBuffer) agg).addNum(Integer.parseInt(javaObj.toString()));}// TODO: 2023/12/9 map与combiner结束返回结果,得到部分数据聚集结果@Overridepublic Object terminatePartial(AggregationBuffer agg) throws HiveException {return terminate(agg);}// TODO: 2023/12/9 combiner合并map返回的结果,还有reducer合并mapper或combiner返回的结果。@Overridepublic void merge(AggregationBuffer agg, Object partial) throws HiveException {((FieldSumBuffer) agg).addNum((Integer) middleNum.getPrimitiveJavaObject(partial));}// TODO: 2023/12/9 map阶段,迭代处理输入sql传过来的列数据@Overridepublic Object terminate(AggregationBuffer agg) throws HiveException {Integer num = ((FieldSumBuffer) agg).getNum();return num;}
}
打包上传,注册函数进行测试:
可以看到实现了对参数的判断和参数类型的判断
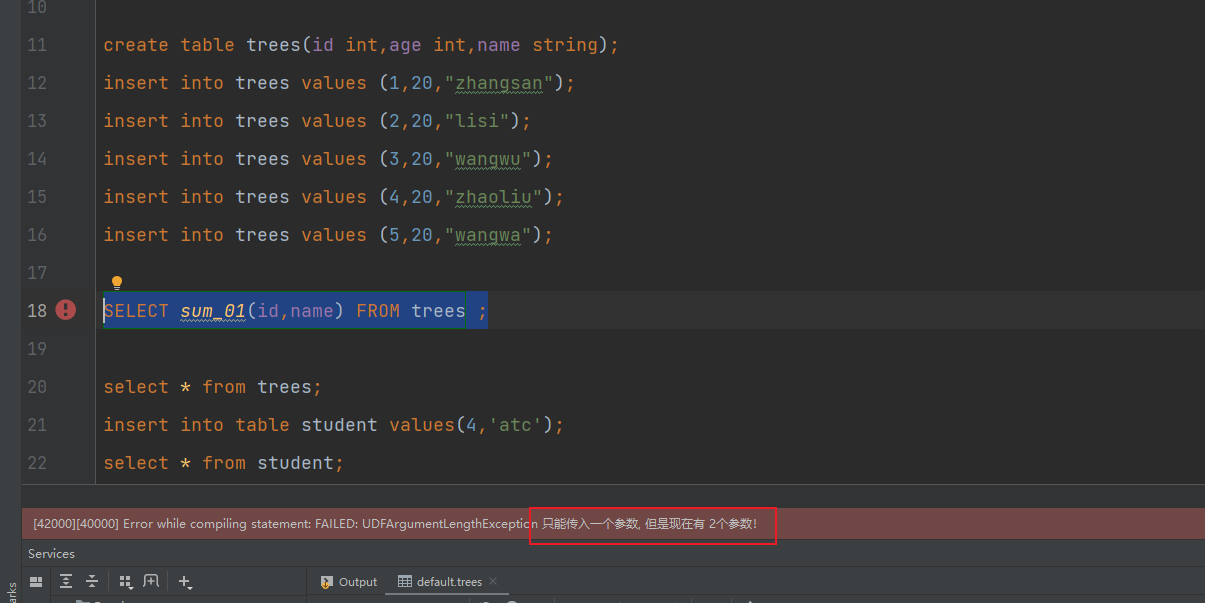
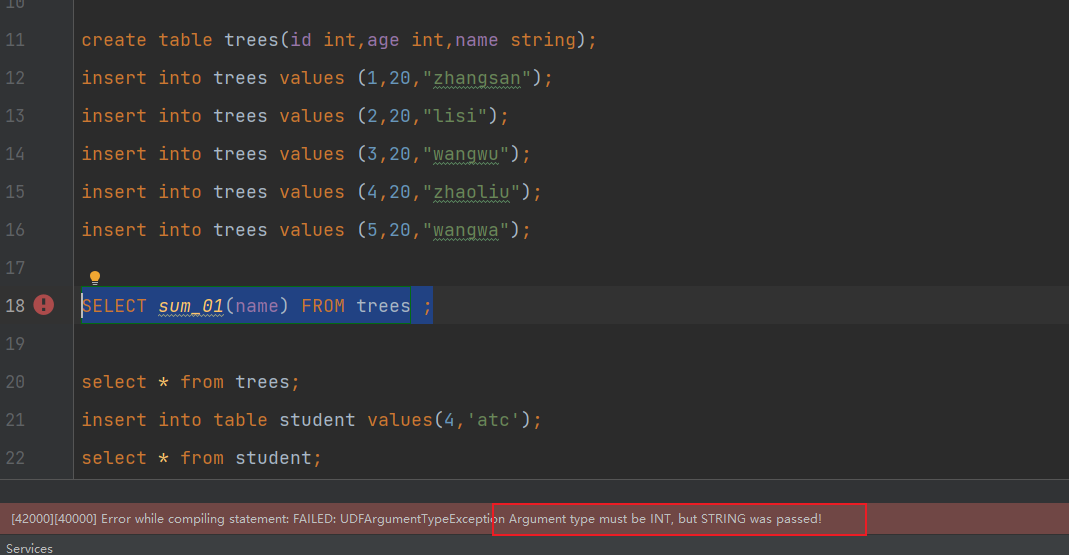
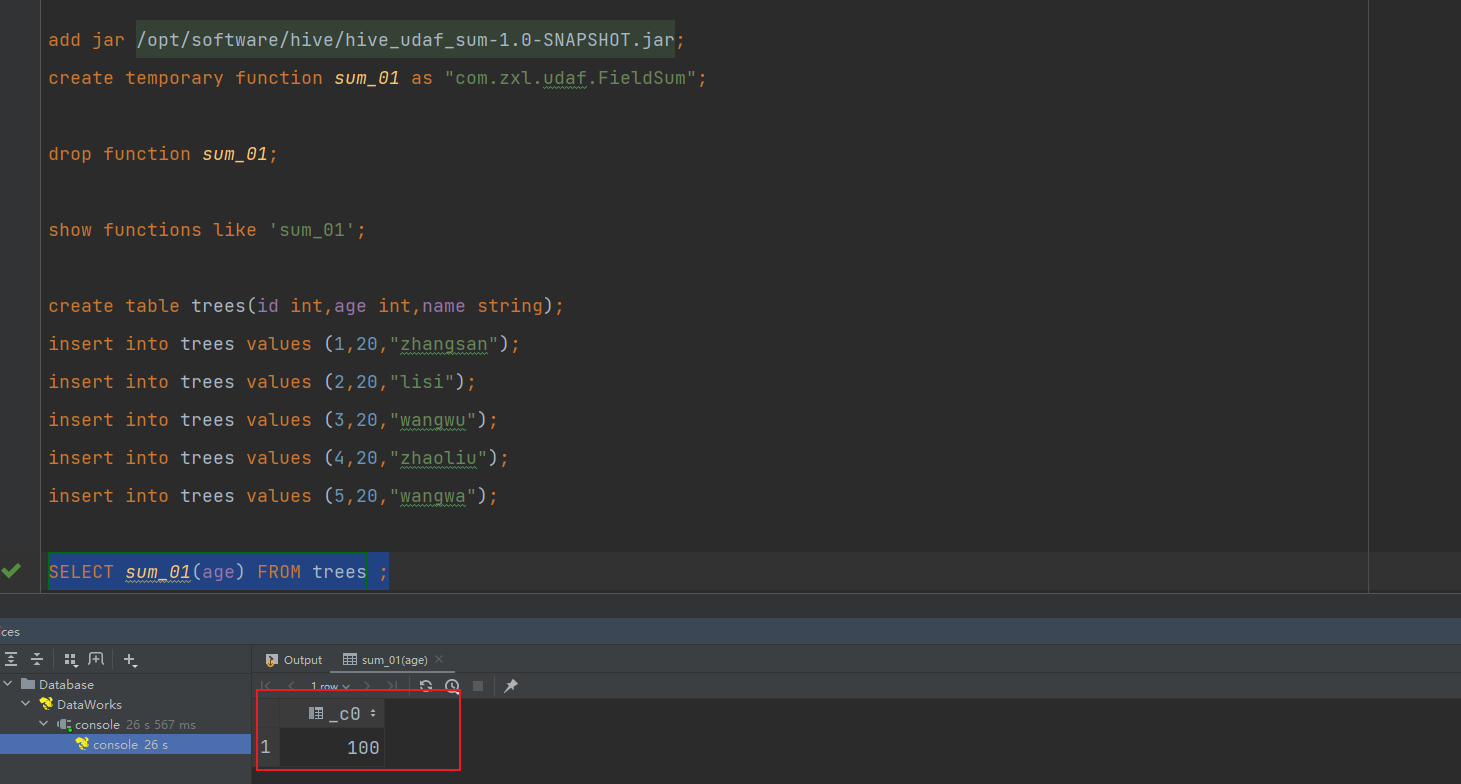
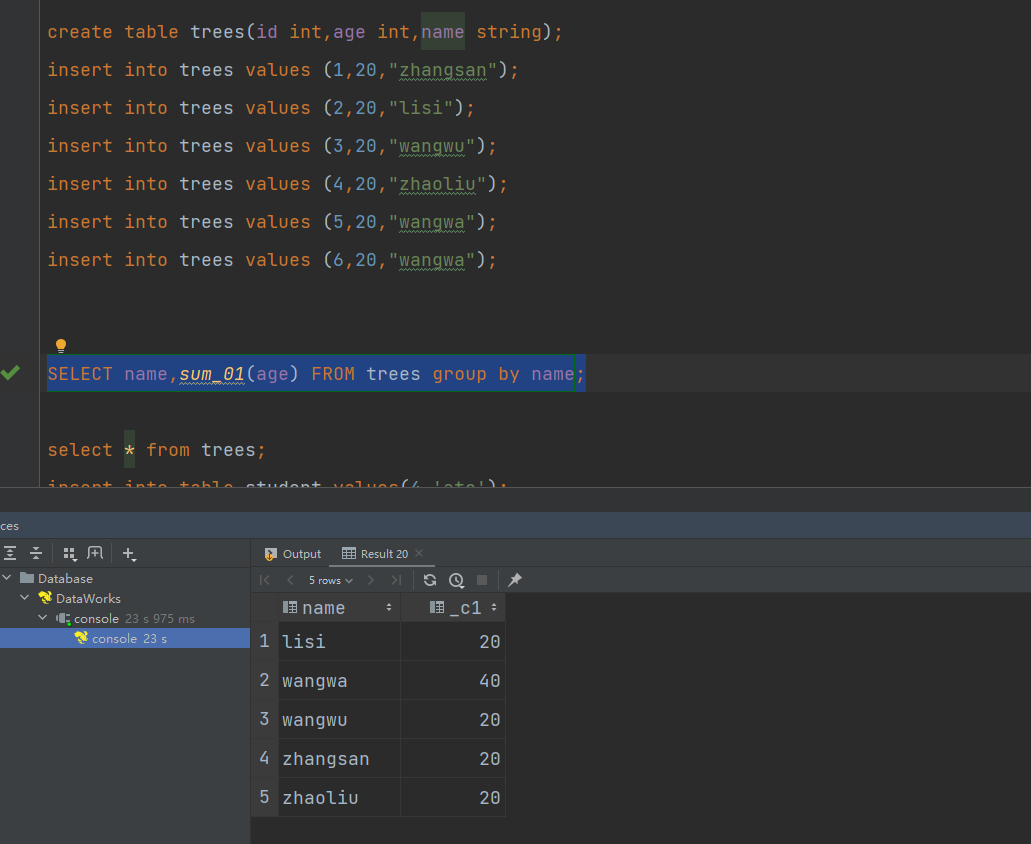
执行查询测试:
相关文章:
hive自定义函数及案例
一.自定义函数 1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。 2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。 3.根据用户自定义…...

2023亚太五岳杯量子计算挑战赛数学建模思路代码模型论文
2023五岳杯数学建模思路:比赛开始后第一时间更新,获取见文末名片 今年,APMCM亚太地区大学生数学建模竞赛组委会正式和玻色量子、中国移动云能力中心等多家单位达成合作。 开展APMCM校企合作高校巡回学术讲座活动,为企业、高校搭…...
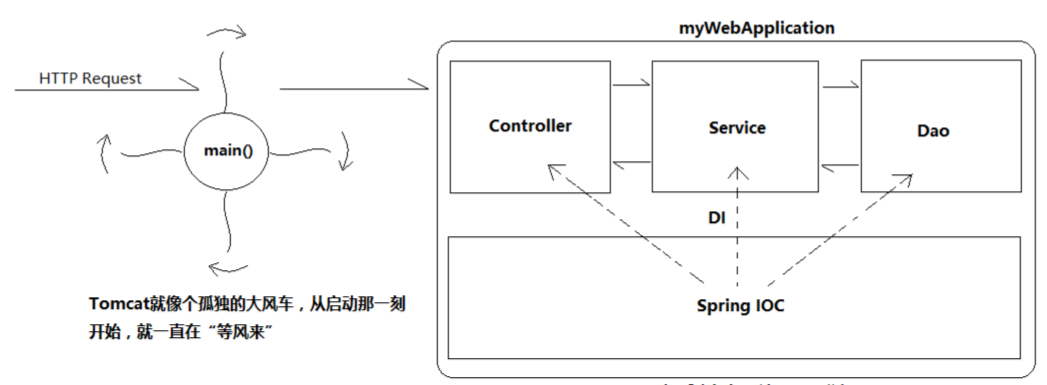
Tomcat的结构分析和请求处理原理解析
目录 Tomcat服务器?Tomcat结构处理请求流程Tomcat作用其他的web服务器 Tomcat服务器? 我们经常开口闭口“服务器”、“服务器”的,其实“服务器”是个很容易引发歧义的概念 其实,Tomcat服务器 Web服务器 Servlet/JSP容器&#…...

FastAPI之响应模型
前言 响应模型我认为最主要的作用就是在自动化文档的显示时,可以直接给查看文档的小伙伴显示返回的数据格式。对于后端开发的伙伴来说,其编码的实际意义不大,但是为了可以不用再额外的提供文档,我们只需要添加一个 response_mod…...

Python数据科学视频讲解:数据清洗、特征工程和数据可视化的注意事项
1.6 数据清洗、特征工程和数据可视化的注意事项 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.6节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学应用的全流程…...
Unity优化——加速物理引擎1
大家好,这里是七七,今天开始更新物理引擎相关的优化部分了,本文介绍的是物理引擎内部工作情况。 Unity技术有两种不同的物理引擎:用于3D物理的Nvidia的PhysX和用于2D物理的开源项目Box2D。然而,Unity对它们的实现是高…...

PHP的最新版本是多少?有什么新特性?
截至日期(2022年1月),PHP的最新稳定版本是PHP 8.0。以下是PHP 8.0的一些主要新特性: JIT 编译器: 引入了即时编译(Just-In-Time,JIT)引擎,提升了PHP脚本的执行性能。 命…...
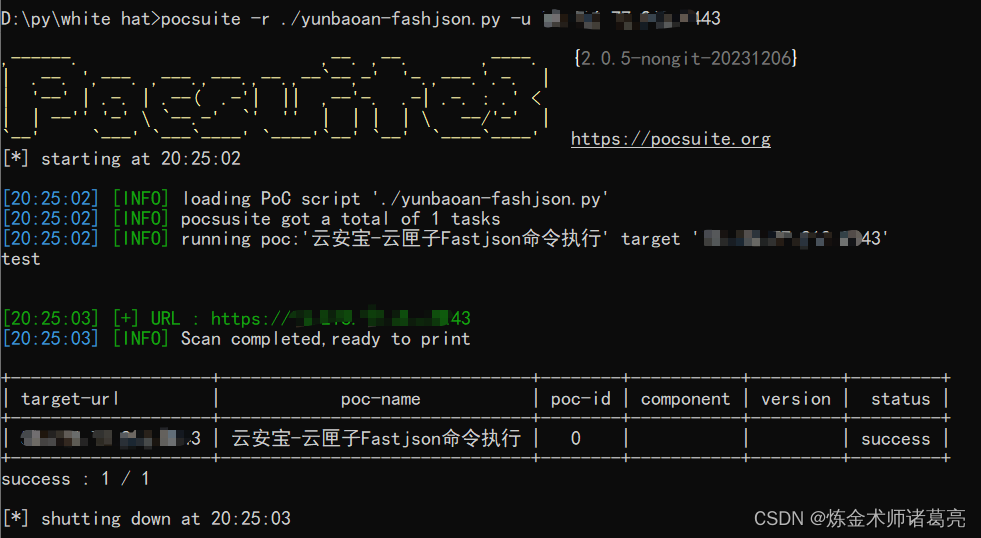
漏洞复现-云安宝-云匣子Fastjson命令执行(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

oh-my-zsh 安装和配置
安装zsh sudo apt update sudo apt install zsh安装oh-my-zsh sh -c "$(curl -fsSL https://gitee.com/mirrors/oh-my-zsh/raw/master/tools/install.sh)"配置~/.zshrc sudo vim ~/.zshrc添加以下内容 ZSH_THEME"steeef" HISTFILE~/.zsh_history HISTS…...

LinuxBasicsForHackers笔记 -- 日志系统
日志文件存储有关操作系统和应用程序运行时发生的事件的信息,包括任何错误和安全警报。 rsyslog 日志守护进程 Linux 使用名为 syslogd 的守护进程自动记录计算机上的事件。 rsyslog 配置文件 与 Linux 中的几乎所有应用程序一样,rsyslog 由位于 /et…...

WPS Office JS宏实现批量处理Word中的标题和正文的样式
该篇讲解下word文档中的标题和正文批量修改样式,如下图: 前面一篇已讲解了WPS Office宏编辑器操作方法,这里不细讲了,如有不清楚可以查看该篇:https://blog.csdn.net/jiciqiang/article/details/134653657?spm1001.20…...

论文怎么改才能降低重复率
一、引言:智能工具助力,轻松降低论文重复率 论文的重复率是学术写作中的重要问题,如何有效降低重复率成为了许多研究者的关注焦点。如今,智能工具的发展为我们提供了更多选择。本文将介绍几种实用的智能工具,包括快码…...

【从零开始学习JVM | 第六篇】快速了解 直接内存
前言: 当谈及Java虚拟机(JVM)的内存管理时,我们通常会想到堆内存和栈内存。然而,还有一种被称为"直接内存"的特殊内存区域,它在Java应用程序中起着重要的作用。直接内存提供了一种与Java堆内存和…...
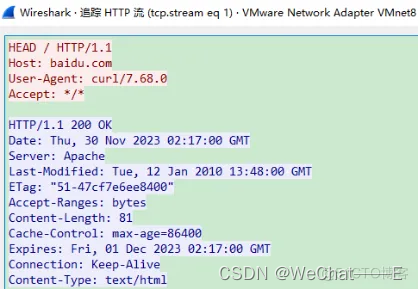
Wireshark中的http协议包分析
Wireshark可以跟踪网络协议的通讯过程,本节通过http协议,在了解Wireshark使用的基础上,重温http协议的通讯过程。 TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于 字节流…...
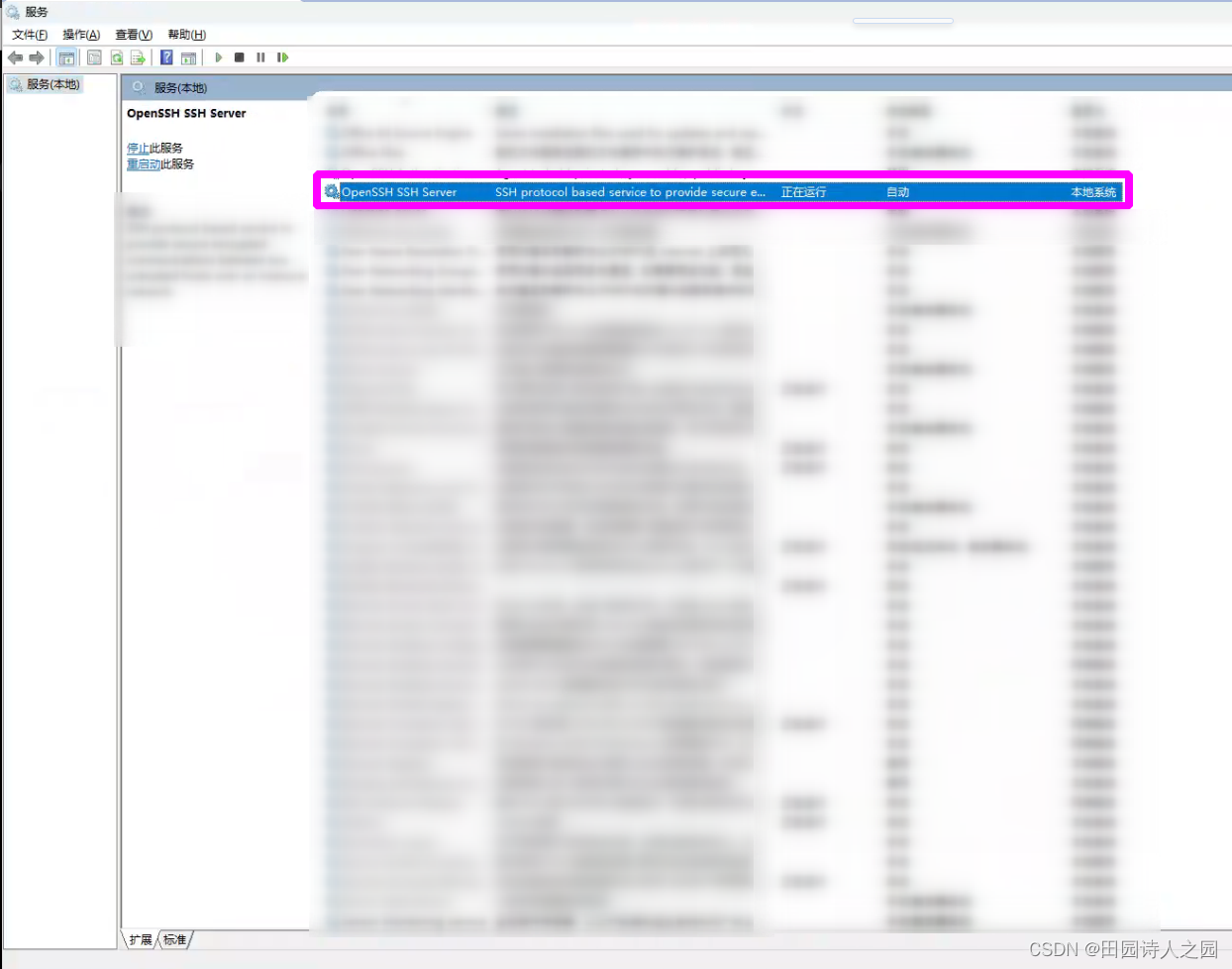
ubuntu如何远程ssh登录Windows环境并执行测试命令
ubuntu如何远程ssh登录Windows环境并执行测试命令 1 paramiko模块简介1.1 安装paramiko1.2 paramiko基本用法1.2.1 创建SSHClient实例1.2.2 设置主机密钥策略1.2.3 连接SSH服务器1.2.4 执行命令1.2.5 关闭SSH连接1.2.6 异常处理 2 windows的配置2.1 启动OpenSSH服务2.2 配置防火…...

人工智能应用专栏----专栏介绍
文章目录 本专栏主要记录人工智能的应用方面的内容,包括chatGPT、AI绘图等等; 订阅后可私聊我获取 《从零注册并登录使用ChatGPT》 《从零开始使用chatGPT的API;通过chatgpt-next-web部署自己chatGPT web网页;无需翻墙,…...
【lesson11】表的约束(4)
文章目录 表的约束的介绍唯一键约束测试建表插入测试建表插入测试建表插入测试修改表插入测试 表的约束的介绍 真正约束字段的是数据类型,但是数据类型约束很单一,需要有一些额外的约束,更好的保证数据的合法性,从业务逻辑角度保…...
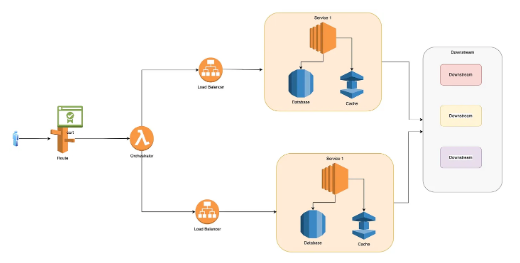
将单体应用程序迁移到微服务
多年来,我处理过多个单体应用,并将其中一些迁移到了微服务架构。我打算写下我所学到的东西以及我从经验中用到的策略,以实现成功的迁移。在这篇文章中,我将以AWS为例,但基本原则保持不变,可用于任何类型的基…...
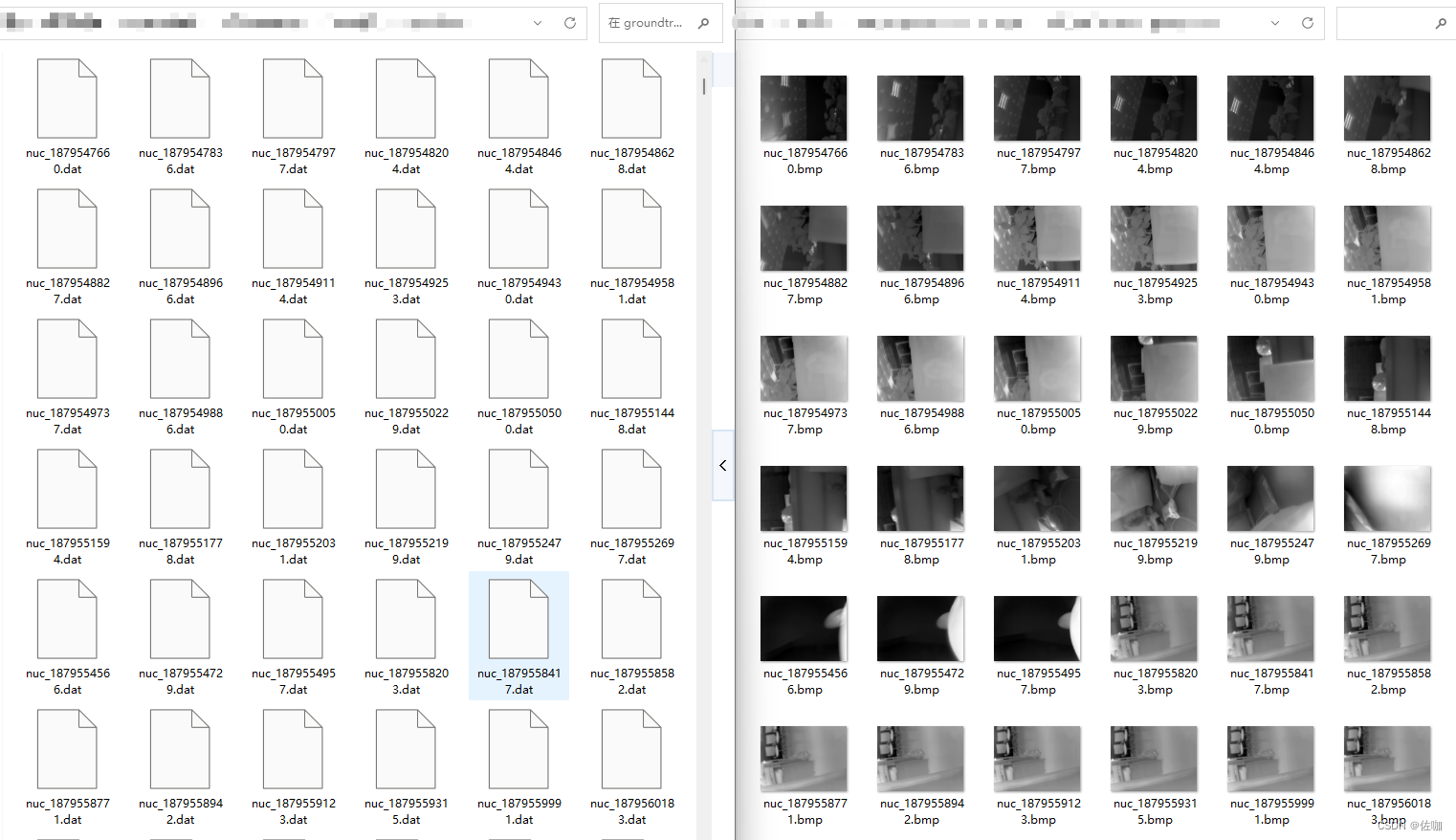
Python读取.dat格式数据并转为.png,.jpg,.bmp等可视化格式(附代码)
.dat文件的命名规则没有统一的规定,但通常以.dat为扩展名。 目录 一、 .dat格式数据1.1 .dat数据用途1.2 常见的.dat文件格式1.3 .dat文件示例 二、读取.dat格式数据2.1 单个.dat文件读取并转换2.1.1 代码2.1.2 查看数据2.1.3 输出查看8Bit图片 2.2 批量.dat文件读取…...
matplotlib 默认属性和绘图风格
matplotlib 默认属性 一、绘图风格1. 绘制叠加折线图2. Solarize_Light23. _classic_test_patch4. _mpl-gallery5. _mpl-gallery-nogrid6. bmh7. classic8. fivethirtyeight9. ggplot10. grayscale11. seaborn12. seaborn-bright13. seaborn-colorblind14. seaborn-dark15. sea…...

从代码到生活:技术人的自我成长之路
从代码到生活:技术人的自我成长之路 引言 作为一名技术人,我们的成长不仅体现在技术能力的提升上,更体现在个人生活的方方面面。今天就来分享一下我的自我成长之路,希望能给你一些启发。 技术成长 持续学习 技术发展很快ÿ…...

LeetCode 数据流中第K大元素题解
LeetCode 数据流中第K大元素题解 题目描述 设计一个数据流,找到数据流中第 k 大的元素。 示例: 输入:k 3, arr [4,6,5]输出:5 解题思路 方法:堆 思路: 使用最小堆维护前 k 大的元素。遍历数据流ÿ…...

从FPS相机到无人机控制:在Unity中实战Pitch、Yaw、Roll角的应用与调试技巧
从FPS相机到无人机控制:在Unity中实战Pitch、Yaw、Roll角的应用与调试技巧 在游戏开发中,相机控制和物体旋转是构建沉浸式体验的核心技术。无论是第一人称射击游戏中玩家视角的流畅转动,还是飞行模拟器中飞机的真实运动,都离不开对…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...
到底怎么选?)
IPv6网络规划必看:华为设备上DHCPv6与SLAAC(无状态地址分配)到底怎么选?
IPv6网络规划实战:华为设备地址分配方案深度解析 在IPv6网络部署的浪潮中,地址分配策略的选择往往成为困扰网络架构师的首要难题。当传统IPv4的DHCP方式遇上IPv6全新的SLAAC(无状态地址自动配置)机制,技术决策的复杂性…...

Nodejs后端服务集成Taotoken实现AI对话功能的具体配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs后端服务集成Taotoken实现AI对话功能的具体配置指南 1. 准备工作:获取API密钥与模型ID 在开始编写代码之前&…...

终极AMD Ryzen调试指南:简单三步掌握硬件性能调优
终极AMD Ryzen调试指南:简单三步掌握硬件性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

polars导入csv文件时指定列数据类型
polars导入csv文件时指定列数据类型schema {column1: pl.Int64,column2: pl.Float64,column3: pl.Utf8}df pl.read_csv(data.csv, schemaschema)def pddaoru_csv(filedir):order_5G[承建方,厂家,市名称,统计局区县,数据时间,小区名称,基站ID,小区ID,小区覆盖类别,频段,带宽,小…...

DLSS Swapper终极指南:如何免费智能管理游戏DLSS文件,提升游戏性能
DLSS Swapper终极指南:如何免费智能管理游戏DLSS文件,提升游戏性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否厌倦了每次游戏更新后手动替换DLSS文件的繁琐操作?你是否希…...

多平台矩阵账号防关联技术深度解析:2026年IP隔离与设备指纹的攻防战
一、问题背景:矩阵运营最大的风险不是限流,是封号做矩阵的人都知道一个残酷的事实:你不是被限流死的,你是被关联死的。2025年某MCN机构一次封号事件:32个抖音账号、18个小红书账号、7个视频号账号,一夜之间…...