YOLOv8改进 | 2023主干篇 | 利用RT-DETR特征提取网络PPHGNetV2改进YOLOv8(超级轻量化精度更高)
一、本文介绍
本文给大家带来利用RT-DETR模型主干HGNet去替换YOLOv8的主干,RT-DETR是今年由百度推出的第一款实时的ViT模型,其在实时检测的领域上号称是打败了YOLO系列,其利用两个主干一个是HGNet一个是ResNet,其中HGNet就是我们今天来讲解的网络结构模型(亲测这个HGNet网络比YOLO的主干更加轻量化和精度更高的主干,非常适合轻量化研究的读者),这个网络结构目前还没有推出论文,所以其理论知识在网络上也是非常的少,我也是根据网络结构图进行了分析(亲测替换之后主干GFLOPs降低到7.7,精度mAP提高0.05)。
轻量化效果:⭐⭐⭐⭐⭐
涨点效果:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
训练结果对比图->
这次试验我用的数据集大概有七八百张照片训练了150个epochs,虽然没有完全拟合但是效果有很高的涨点幅度,所以大家可以进行尝试毕竟不同的数据集上效果也可能差很多,同时我在后面给了多种yaml文件大家可以分别进行实验来检验效果。
可以看到这个图片的mAP50和mAP50-95都有一定程度的上涨。

目录
一、本文介绍
二、HGNetV2原理讲解
三、HGNetV2的代码
四、手把手教你添加HGNetV2
4. 1 HGNetV2-l的yaml文件(此为对比试验版本)
4.2 HGNetV2-x的yaml文件
五、运行成功记录
六、本文总结
二、HGNetV2原理讲解

论文地址:RT-DETR论文地址
本文代码来源:HGNetV2的代码来源

PP-HGNet 骨干网络的整体结构如下:

其中,PP-HGNet是由多个HG-Block组成,HG-Block的细节如下:
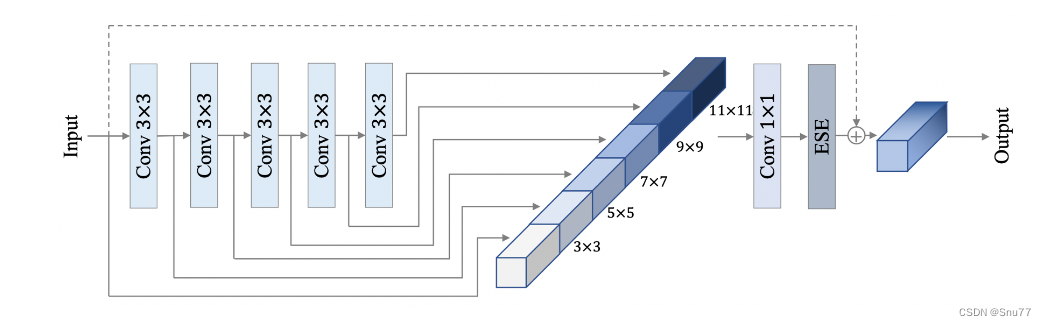
上面的图表是PP-HGNet神经网络架构的概览,下面我会对其中的每一个模块进行分析:
1. Stem层:这是网络的初始预处理层,通常包含卷积层,开始从原始输入数据中提取特征。
2. HG(层次图)块:这些块是网络的核心组件,设计用于以层次化的方式处理数据。每个HG块可能处理数据的不同抽象层次,允许网络从低级和高级特征中学习。
3. LDS(可学习的下采样)层:位于HG块之间的这些层可能执行下采样操作,减少特征图的空间维度,减少计算负载并可能增加后续层的感受野。
4. GAP(全局平均池化):在最终分类之前,使用GAP层将特征图的空间维度减少到每个特征图一个向量,有助于提高网络对输入数据空间变换的鲁棒性。
5. 最终的卷积和全连接(FC)层:网络以一系列执行最终分类任务的层结束。这通常涉及一个卷积层(有时称为1x1卷积)来组合特征,然后是将这些特征映射到所需输出类别数量的全连接层。
这种架构的主要思想是利用层次化的方法来提取特征,其中复杂的模式可以在不同的规模和抽象层次上学习,提高网络处理复杂图像数据的能力。
这种分层和高效的处理对于图像分类等复杂任务非常有利,在这些任务中,精确预测至关重要的是在不同规模上识别复杂的模式和特征。图表还显示了HG块的扩展视图,包括多个不同滤波器大小的卷积层,以捕获多样化的特征,然后通过一个元素级相加或连接的操作(由+符号表示)在数据传递到下一层之前。
三、HGNetV2的代码
需要注意的是HGNetV2这个版本的所需组件已经集成在YOLOv8的仓库了,所以我们无需做任何的代码层面的改动,只需要设计yaml文件来配合Neck部分融合特征即可了,但是我还是把代码放在这里,供有兴趣的读者看一下,也和上面的结构进行一个对照。主要的三个结构HGStem,HGBlock,DWConv。
class HGStem(nn.Module):"""StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py"""def __init__(self, c1, cm, c2):"""Initialize the SPP layer with input/output channels and specified kernel sizes for max pooling."""super().__init__()self.stem1 = Conv(c1, cm, 3, 2)self.stem2a = Conv(cm, cm // 2, 2, 1, 0)self.stem2b = Conv(cm // 2, cm, 2, 1, 0)self.stem3 = Conv(cm * 2, cm, 3, 2)self.stem4 = Conv(cm, c2, 1, 1)self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)def forward(self, x):"""Forward pass of a PPHGNetV2 backbone layer."""x = self.stem1(x)x = F.pad(x, [0, 1, 0, 1])x2 = self.stem2a(x)x2 = F.pad(x2, [0, 1, 0, 1])x2 = self.stem2b(x2)x1 = self.pool(x)x = torch.cat([x1, x2], dim=1)x = self.stem3(x)x = self.stem4(x)return xclass HGBlock(nn.Module):"""HG_Block of PPHGNetV2 with 2 convolutions and LightConv.https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py"""def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=True):"""Initializes a CSP Bottleneck with 1 convolution using specified input and output channels."""super().__init__()block = LightConv if lightconv else Convself.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # squeeze convself.ec = Conv(c2 // 2, c2, 1, 1, act=act) # excitation convself.add = shortcut and c1 == c2def forward(self, x):"""Forward pass of a PPHGNetV2 backbone layer."""y = [x]y.extend(m(y[-1]) for m in self.m)y = self.ec(self.sc(torch.cat(y, 1)))return y + x if self.add else ydef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class DWConv(Conv):"""Depth-wise convolution."""def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation"""Initialize Depth-wise convolution with given parameters."""super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)四、手把手教你添加HGNetV2
这里不需要改动什么,如果你的版本是老版本的,没有集成RT-DETR的版本,那么大家可以下载一个新版本可以参考其中的怎么改,我这里就不在描述,否则拉下某一步在导致大家报错。
4. 1 HGNetV2-l的yaml文件(此为对比试验版本)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, HGStem, [32, 48]] # 0-P2/4- [-1, 6, HGBlock, [48, 128, 3]] # stage 1- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8- [-1, 6, HGBlock, [96, 512, 3]] # stage 2- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut- [-1, 6, HGBlock, [192, 1024, 5, True, True]]- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4- [-1, 1, SPPF, [1024, 5]] # 10# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 7], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 3], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2 HGNetV2-x的yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]
backbone:# [from, repeats, module, args]- [-1, 1, HGStem, [32, 64]] # 0-P2/4- [-1, 6, HGBlock, [64, 128, 3]] # stage 1- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8- [-1, 6, HGBlock, [128, 512, 3]]- [-1, 6, HGBlock, [128, 512, 3, False, True]] # 4-stage 2- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 5-P3/16- [-1, 6, HGBlock, [256, 1024, 5, True, False]] # cm, c2, k, light, shortcut- [-1, 6, HGBlock, [256, 1024, 5, True, True]]- [-1, 6, HGBlock, [256, 1024, 5, True, True]]- [-1, 6, HGBlock, [256, 1024, 5, True, True]]- [-1, 6, HGBlock, [256, 1024, 5, True, True]] # 10-stage 3- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 11-P4/32- [-1, 6, HGBlock, [512, 2048, 5, True, False]]- [-1, 6, HGBlock, [512, 2048, 5, True, True]] # 13-stage 4- [-1, 1, SPPF, [1024, 5]] # 14# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 15- [[-1, 10], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 16- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 19 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 16], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 22 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 14], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 25 (P5/32-large)- [[19, 22, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
五、运行成功记录
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 2023主干篇 | 利用RT-DETR特征提取网络PPHGNetV2改进YOLOv8(超级轻量化精度更高)
一、本文介绍 本文给大家带来利用RT-DETR模型主干HGNet去替换YOLOv8的主干,RT-DETR是今年由百度推出的第一款实时的ViT模型,其在实时检测的领域上号称是打败了YOLO系列,其利用两个主干一个是HGNet一个是ResNet,其中HGNet就是我们…...
笔记——<stdarg.h>、<stdlib.h>和<time.h>标准库)
C现代方法(第26章)笔记——<stdarg.h>、<stdlib.h>和<time.h>标准库
文章目录 第26章 <stdarg.h>、<stdlib.h>和<time.h>标准库26.1 <stdarg.h>: 可变参数26.1.1 调用带有可变参数列表的函数26.1.2 v...printf函数26.1.3 v...scanf函数(C99) 26.2 <stdlib.h>: 通用的实用工具26.2.1 数值转换函数26.2.1.1 测试数值…...
CCKS2023-面向金融领域的主体事件检测-亚军方案分享
赛题分析 大赛地址 https://tianchi.aliyun.com/competition/entrance/532098/introduction?spma2c22.12281925.0.0.52b97137bpVnmh 任务描述 主体事件检测是语言文本分析和金融领域智能应用的重要任务之一,如在金融风控领域往往会对公司主体进行风险事件的检测…...
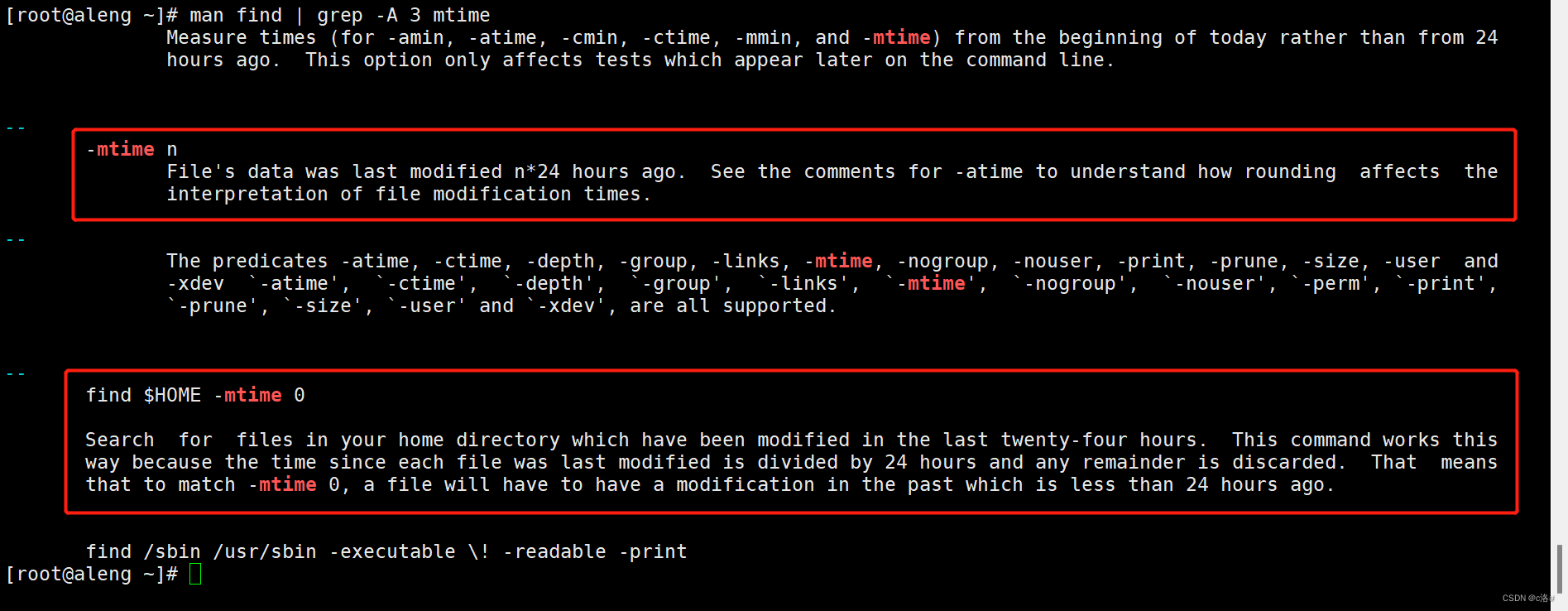
Linux下通过find找文件---通过修改时间查找(-mtime)
通过man手册查找和-mtime选项相关的内容 man find | grep -A 3 mtime # 这里简单介绍了 -mtime ,还有一个简单的示例-mtime n Files data was last modified n*24 hours ago. See the comments for -atime to understand how rounding affects the interpretati…...

图文教程:stable-diffusion的基本使用教程 txt2img(多图)
之前我介绍了SD的安装过程,那么这篇将介绍怎么使用SD 使用模型 SD安装好之后,我们只有一个默认的模型。这个模型很难满足我们的绘图需求,那么有2种方法。 1是自己训练一个模型(有门槛)2是去网站上找一个别人练好的模…...
VisualSVN Server的安装全过程
目录 背景: 安装过程: 步骤1: 步骤2: 步骤3: 步骤4: 步骤5: 安装出现的bug: 问题: 解决办法: 总结: 背景: VisualSVN Server 是一款免费的 SVN (Subversion) 服务器软件,…...

Python 进阶(十六):二进制和ASCII码的转换(binascii 模块)
大家好,我是水滴~~ 本文详细介绍了Python中的binascii模块及其使用方法。通过binascii模块,我们可以方便地进行二进制和ASCII字符串之间的转换操作。文章中包含大量的示例代码,希望能够帮助新手同学快速入门。 《Python入门核心技术》专栏总…...
CSS Grid布局入门:从零开始创建一个网格系统
CSS Grid布局入门:从零开始创建一个网格系统 引言 在响应式设计日益重要的今天,CSS Grid布局系统是前端开发中的一次革新。它使得创建复杂、灵活的布局变得简单而直观。本教程将通过分步骤的方式,让你从零开始掌握CSS Grid,并在…...
java--Collection的遍历方式
1.迭代器概述 迭代器是用来遍历集合的专用方式(数组没有迭代器),在java中迭代器是Iterator。 2.Collection集合获取迭代器的方法 3.Iterator迭代器中的常用方法 4.增强for循环 ①增强for可以用来遍历集合或数组。 ②增强for遍历集合,本质就是迭代器遍…...
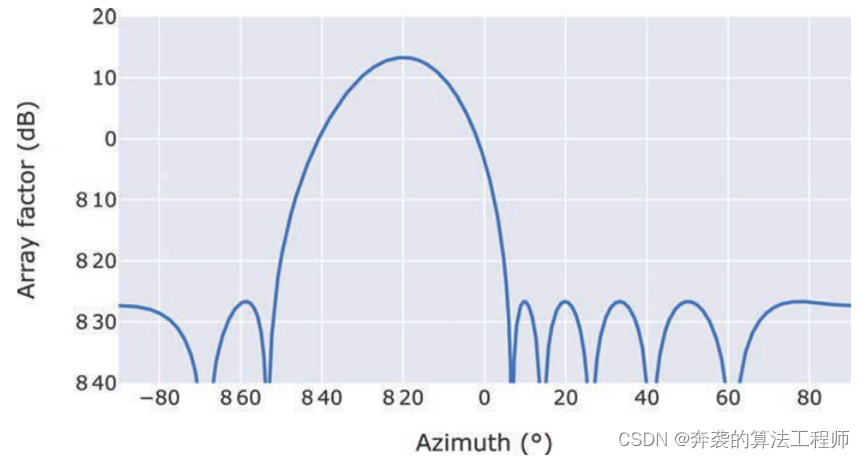
现代雷达车载应用——第2章 汽车雷达系统原理 2.2节
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。 2.2 汽车雷达架构 从顶层来看,基本的汽车雷达由发射器,接收器和天线组成。图2.2给出了一种简化的单通道连续波雷达结构[2]。这…...
Ajax跨域请求
最近使用js构造请求时发生了CORS跨域问题,mark一下 ajax跨域,这应该是最全的解决方案了 | Dailc的个人主页Everything about dailchttps://dailc.github.io/2017/03/22/ajaxCrossDomainSolution.htmlAJAX - 廖雪峰的官方网站研究互联网产品和技术&#…...

python 中Windows编程一些心得
主要思路 当我们显示所有消息的信息时,我们可以知道Windows后台是如何传递消息给我们,但是并不会把所有东西写进开发文档 ,这有一定的原因 但是 我们要自己去理解或者猜想开发者思路或者根据反馈结果来分析消息的作用,不然永远只…...
)
android 13.0 系统属性控制音量键功能是否可用开关(屏蔽音量加减功能)
1.概述 在13.0的系统定制化开发中,要求屏蔽掉音量+ 音量-的功能,根据系统属性来判断是否响应音量加减的功能,在系统上层中是由PhoneWindowManage来管理音量键的功能, 所以就要看是PhoneWindowManage.java中怎么处理的音量键的功能 首选看的源码关于音量键的处理 2.系统属…...
hive自定义函数及案例
一.自定义函数 1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。 2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。 3.根据用户自定义…...

2023亚太五岳杯量子计算挑战赛数学建模思路代码模型论文
2023五岳杯数学建模思路:比赛开始后第一时间更新,获取见文末名片 今年,APMCM亚太地区大学生数学建模竞赛组委会正式和玻色量子、中国移动云能力中心等多家单位达成合作。 开展APMCM校企合作高校巡回学术讲座活动,为企业、高校搭…...
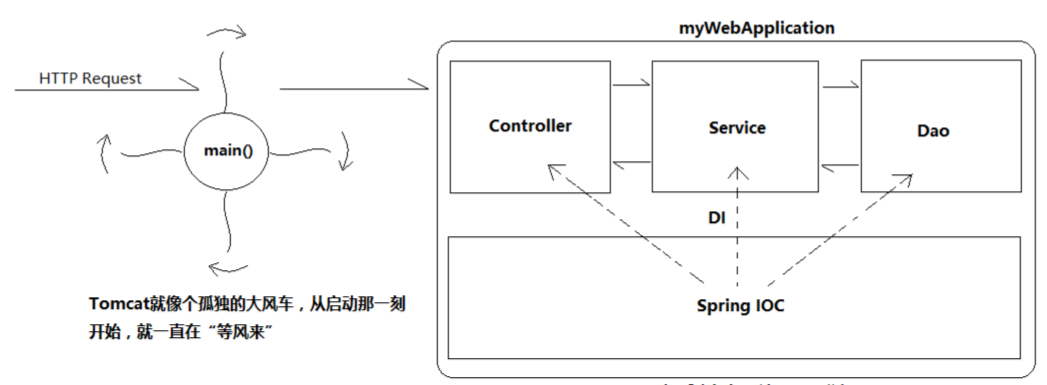
Tomcat的结构分析和请求处理原理解析
目录 Tomcat服务器?Tomcat结构处理请求流程Tomcat作用其他的web服务器 Tomcat服务器? 我们经常开口闭口“服务器”、“服务器”的,其实“服务器”是个很容易引发歧义的概念 其实,Tomcat服务器 Web服务器 Servlet/JSP容器&#…...

FastAPI之响应模型
前言 响应模型我认为最主要的作用就是在自动化文档的显示时,可以直接给查看文档的小伙伴显示返回的数据格式。对于后端开发的伙伴来说,其编码的实际意义不大,但是为了可以不用再额外的提供文档,我们只需要添加一个 response_mod…...

Python数据科学视频讲解:数据清洗、特征工程和数据可视化的注意事项
1.6 数据清洗、特征工程和数据可视化的注意事项 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.6节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学应用的全流程…...
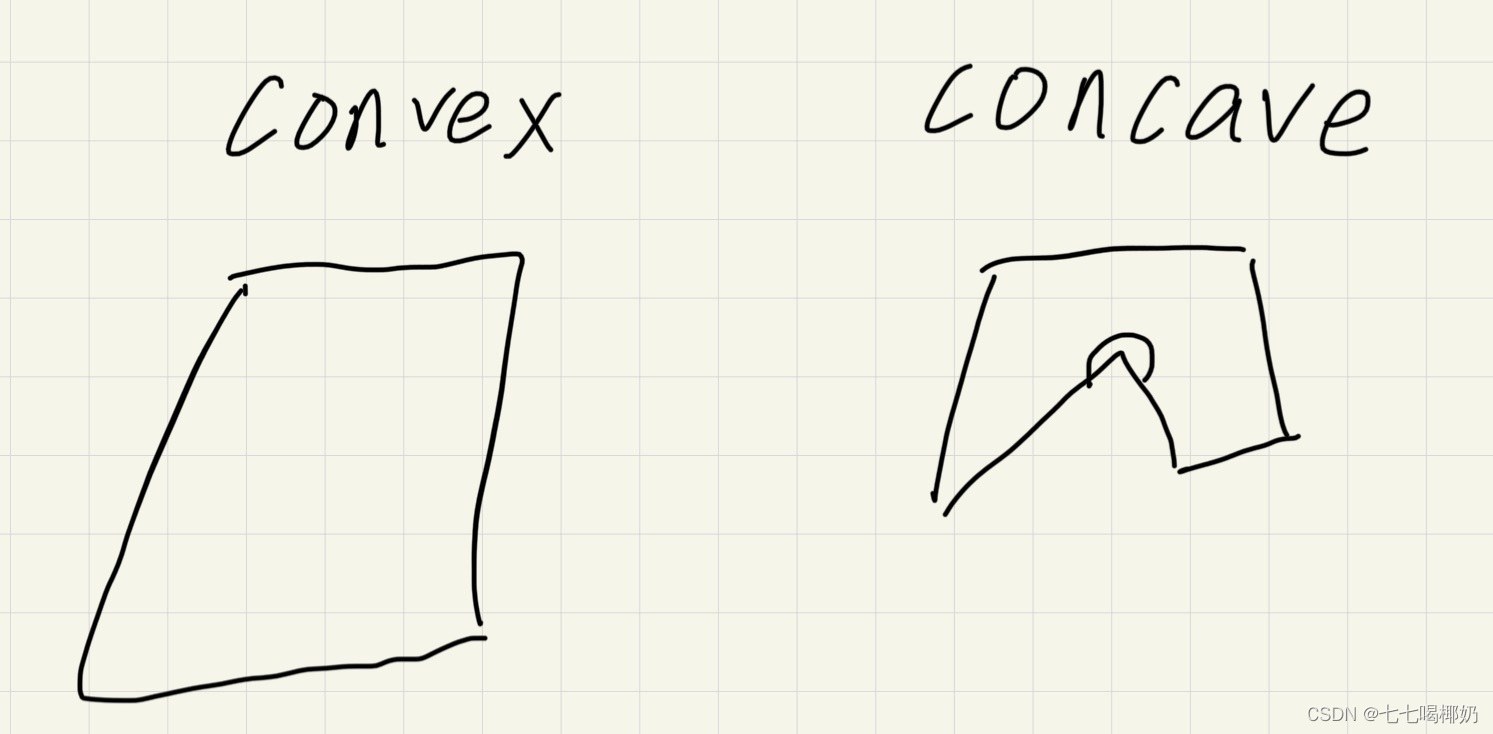
Unity优化——加速物理引擎1
大家好,这里是七七,今天开始更新物理引擎相关的优化部分了,本文介绍的是物理引擎内部工作情况。 Unity技术有两种不同的物理引擎:用于3D物理的Nvidia的PhysX和用于2D物理的开源项目Box2D。然而,Unity对它们的实现是高…...

PHP的最新版本是多少?有什么新特性?
截至日期(2022年1月),PHP的最新稳定版本是PHP 8.0。以下是PHP 8.0的一些主要新特性: JIT 编译器: 引入了即时编译(Just-In-Time,JIT)引擎,提升了PHP脚本的执行性能。 命…...

哔咔漫画下载器:如何轻松构建个人离线漫画图书馆?
哔咔漫画下载器:如何轻松构建个人离线漫画图书馆? 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.…...

MaterialSkin架构解析:现代化WinForms界面重构的技术实现
MaterialSkin架构解析:现代化WinForms界面重构的技术实现 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin MaterialSkin是一个专为…...

Folcolor:让你的Windows文件夹告别“黄脸婆“,用色彩提升3倍工作效率
Folcolor:让你的Windows文件夹告别"黄脸婆",用色彩提升3倍工作效率 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 想象一下这样的场景:你的电…...
)
别再只抄datasheet了!TPS5430降压电路PCB布局的5个实战避坑点(附15V转12V/负压案例)
TPS5430降压电路PCB布局的5个实战避坑指南:从理论到15V转12V/负压案例 在硬件设计领域,TPS5430作为一款经典的Buck型DC-DC转换芯片,其性能表现与PCB布局质量密切相关。许多工程师虽然能正确绘制原理图,却在PCB实现阶段因忽视关键…...
)
Perplexity物理检索突然失灵?2024Q3模型更新引发的3类知识断层(附中科院物理所认证的降级兼容方案)
更多请点击: https://intelliparadigm.com 第一章:Perplexity物理知识查询 Perplexity 是一款基于大语言模型的实时知识检索工具,其核心能力在于融合权威学术资源(如 arXiv、APS、IOP、NASA ADS 等)与动态网页索引&am…...

观察Taotoken用量看板如何帮助团队精打细算每一分token
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助团队精打细算每一分token 对于依赖大模型进行开发的团队而言,成本控制与预算规划是日常运…...

D1016UK,1MHz至1GHz宽带适用的低噪声高效率射频功率晶体管
简介今天我要向大家介绍的是 TT Electronics/Semelab 的DMOS RF FET晶体管——D1016UK。这是一款专为VHF/UHF通信频段(1 MHz至1GHz)设计的金金属化多用途硅RF功率场效应管,采用推挽式架构,在28V工作电压下可提供40W的输出功率。作…...

TrollInstallerX完整教程:3分钟搞定iOS越狱神器TrollStore一键安装
TrollInstallerX完整教程:3分钟搞定iOS越狱神器TrollStore一键安装 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 还在为iOS设备上安装TrollStore而烦恼吗&…...

Android Studio中文界面汉化教程:3步实现母语开发环境
Android Studio中文界面汉化教程:3步实现母语开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android …...

面试必问:AI 医疗平台怎么设计?这次彻底讲透
AI 医疗平台怎么设计?一次讲清医生辅助、知识库、问答系统与安全边界 大家好,我是一名有 4 年工作经验的 Java 后端开发。 AI 和医疗结合这个方向这两年非常热,但也正因为它太敏感,所以最怕两种极端:一种是把它吹成“万…...