链表基础知识(一、单链表)
一、链表表示和实现
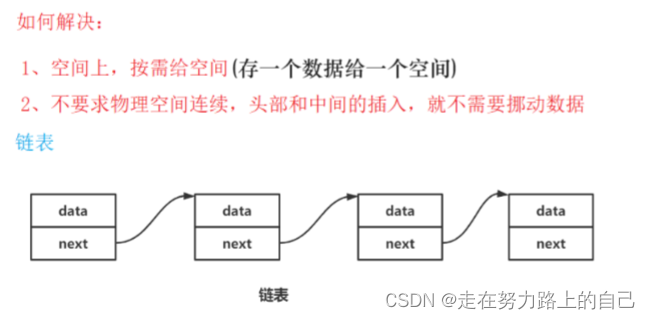
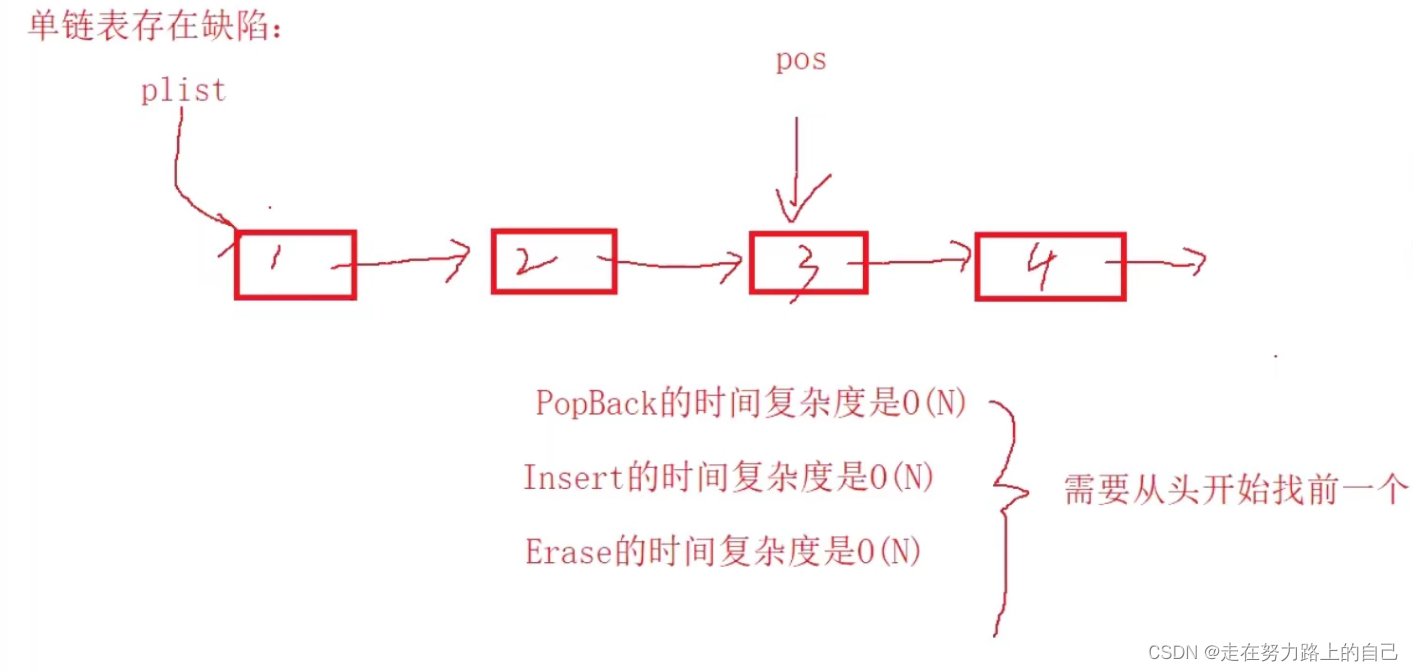
顺序表的问题及思考
问题:
1. 中间/头部的插入删除,时间复杂度为O(N)
2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到
200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
思考:
如何解决以上问题呢?下面给出了链表的结构来看看。
1.1 链表的概念及结构
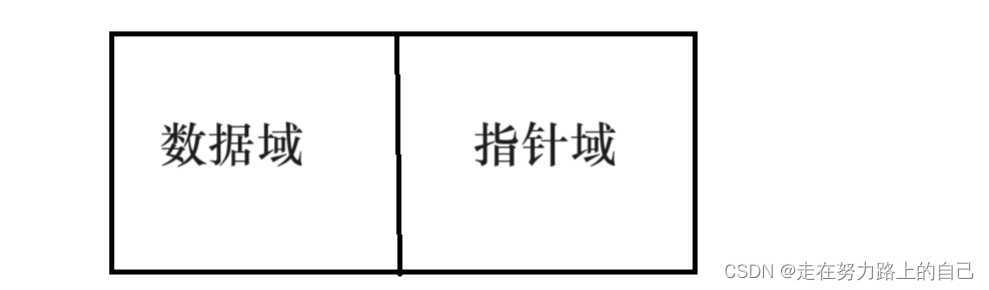
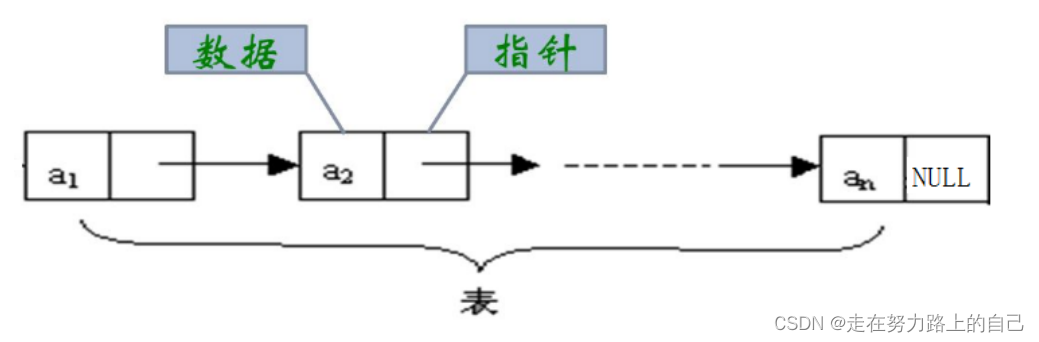
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,用于存储逻辑关系为 “一对一” 的数据。链表中每个数据的存储都由以下两部分组成:
1.数据元素本身,其所在的区域称为数据域。
2.指向直接后继元素的指针,所在的区域称为指针域。
(单链表的节点)
数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
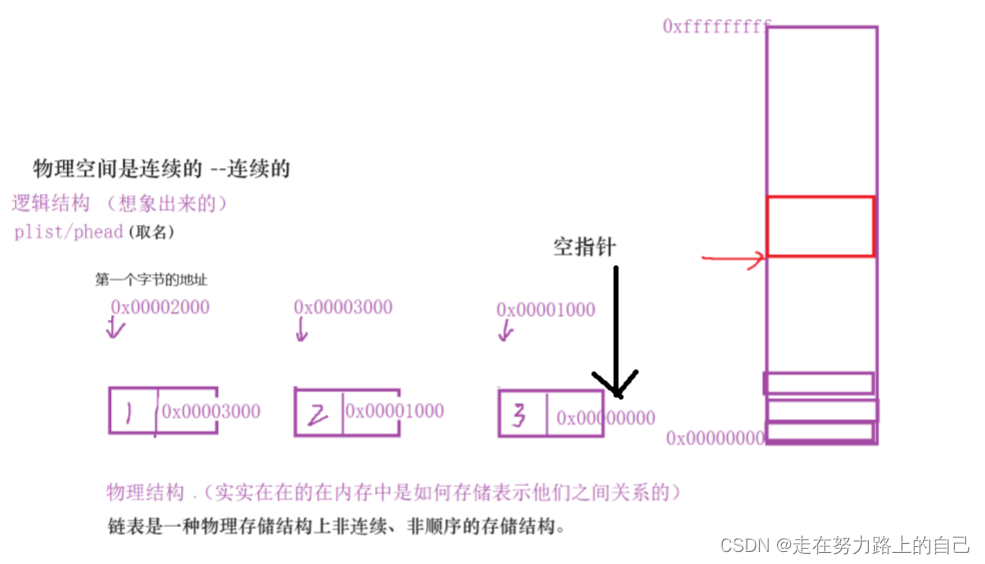
二、链表的分类:
2.1实际中要实现的链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向、双向
2. 带头、不带头
3. 循环、非循环
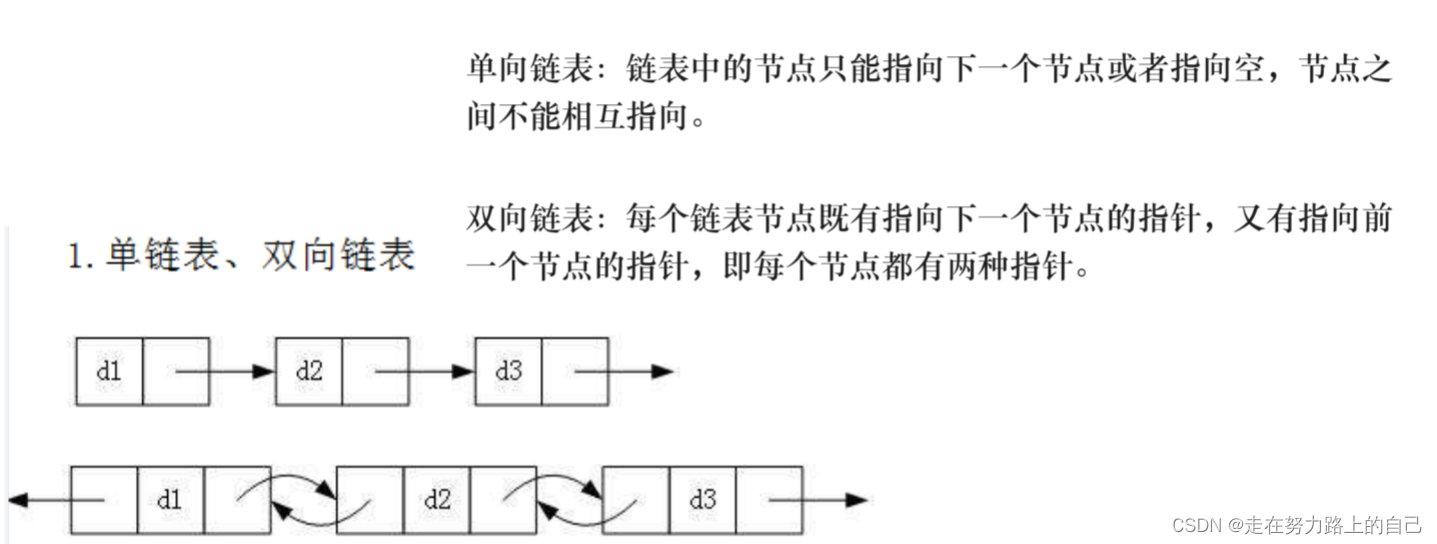
-
头节点:是一个节点,本质上是一个结构体变量,区分数据域和指针域,不存放任何数据,只存放指向链表中真正存放数据的第一个节点的地址,仅用于辅助管理整个链表的结构。
-
头指针:是一个指针,本质上是一个结构体类型的指针变量,不区分数据域和指针域,它仅存储链表中第一个节点的地址。
-
带头节点也就意味着不需要传二级指针了
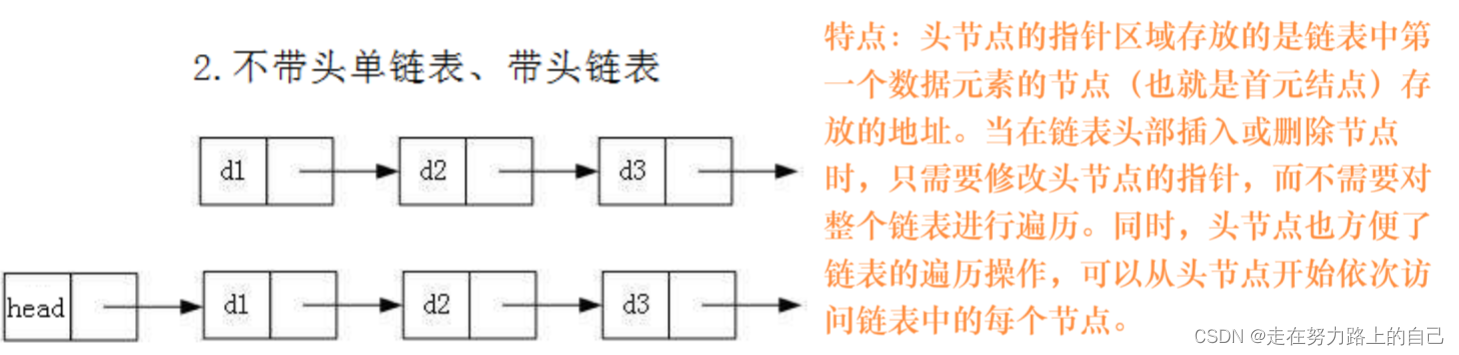
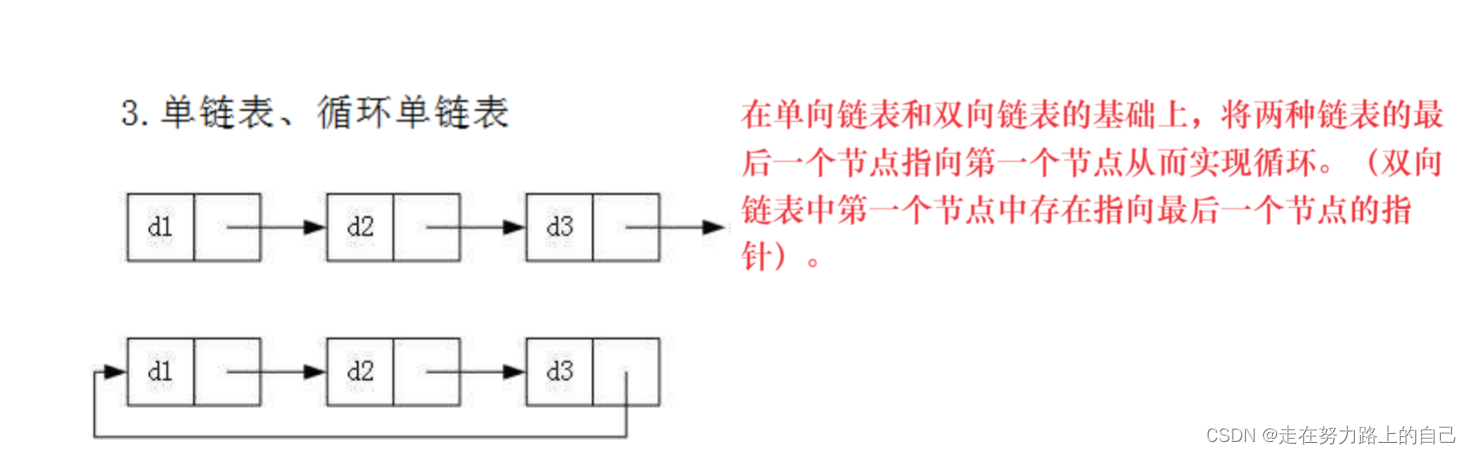
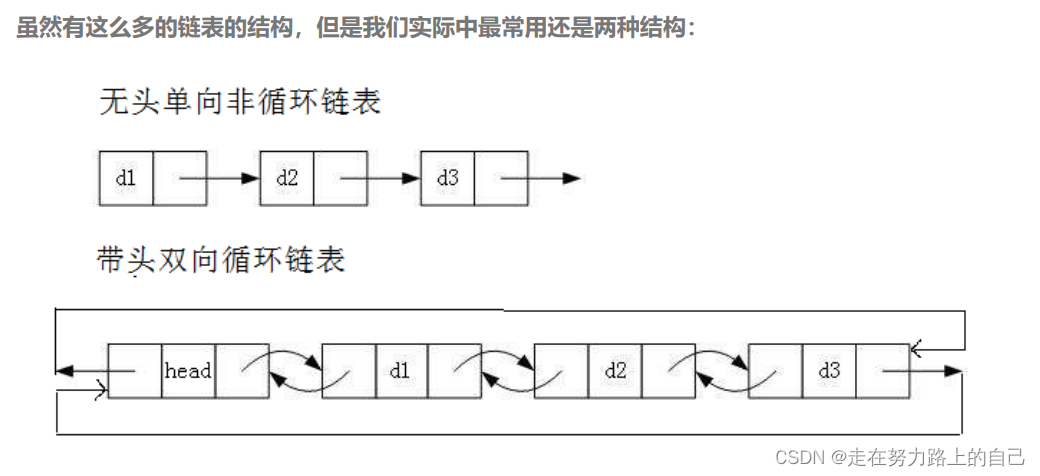
1.无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结
构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带
来很多优势,实现反而简单了,后面我们代码实现了就知道了。

2.2链表和顺序表的对比

三、单链表
3.1单链表的优劣:

1、查找速度慢
2、 不能从后往前
3、找不到前驱
4、单向链表不能自我删除,需要靠辅助节点 。
无头+单向+非循环链表增删查改实现
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结
构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
3.2SList.h
#pragma once //防止重复包含
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<assert.h>typedef int SLTDataType;//方便改变数据类型
struct SListNode
{SLTDataType data;struct SListNode* next;//下一个地址//结构体中嵌套指针,但不能嵌套自己,会死循环
}SLTNode;
typedef struct SListNode STLNode;// 不会改变链表的头指针,传一级指针
void SListPrint(STLNode* phead);// 可能会改变链表的头指针,传二级指针
void SListPushBack(STLNode** pphead, SLTDataType x);
void SListPushFront(STLNode** pphead, SLTDataType x);//分有节点头插和无节点头插,尾插得分开处理
void SListPopFront(STLNode** pphead);
void SListPopBack(STLNode** pphead);// 不会改变链表的头指针,传一级指针
STLNode* SListFind(STLNode* pphead, SLTDataType x);
// 在pos的前面插入x
void SListInsert(STLNode** pphead, STLNode* pos, SLTDataType x);
// 删除pos位置的值
void SListErase(STLNode** pphead, STLNode* pos);有些地方也有这样定义在pos的前面插入x
//void SListInsert(STLNode** phead, int i, SLTDataType x);删除pos位置的值
//void SListErase(STLNode** phead, int i);3.3打印链表
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移
第三步:以此类推,直到节点的指针域为NULL
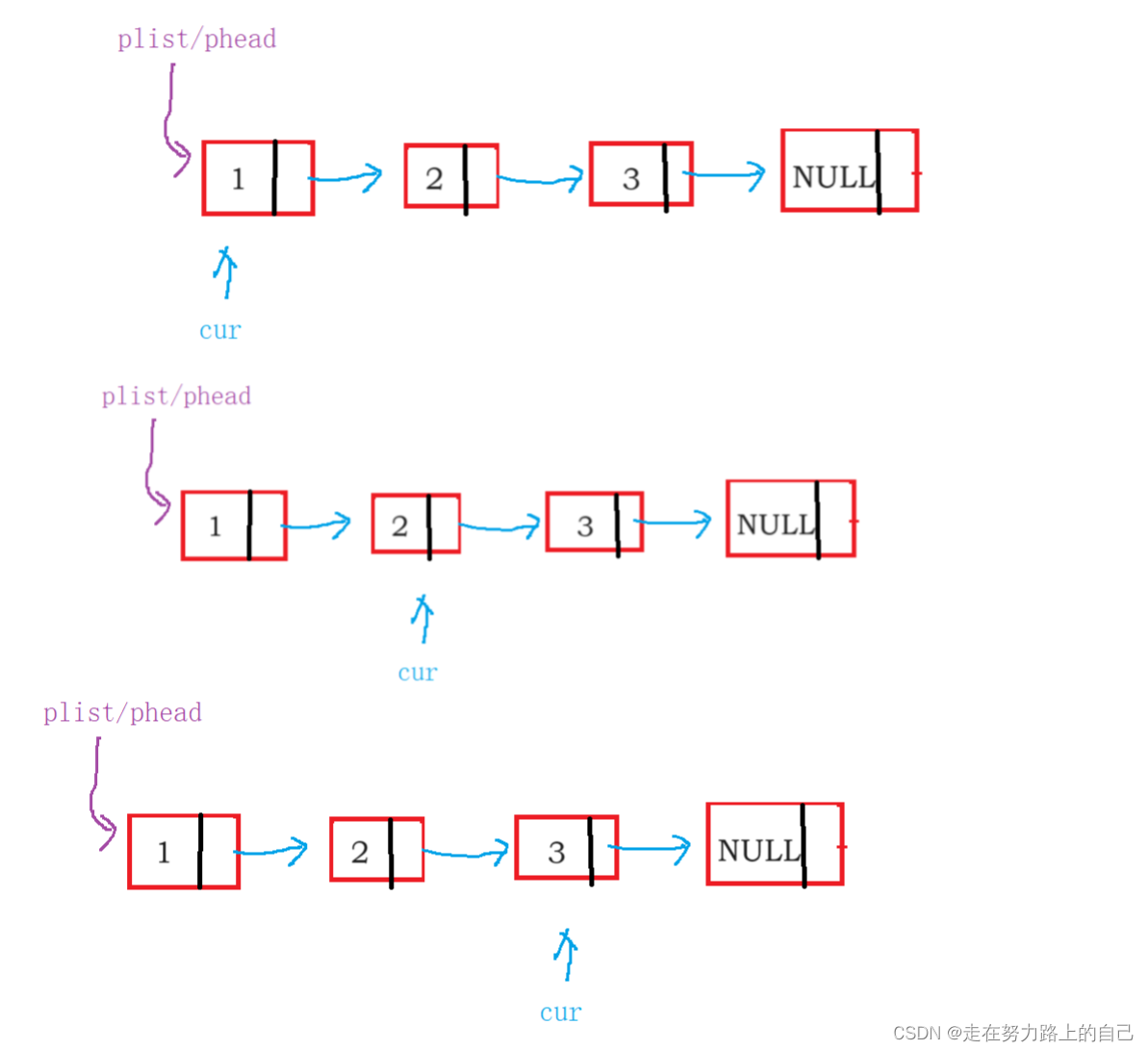
void SListPrint(STLNode* phead)
{STLNode* cur = phead;while (cur != NULL)//第一个地址不为空{printf("%d->", cur->data);cur = cur->next;//令cur下一个地址}printf("NULL\n");}3.4新建一个节点
函数中的 malloc 用于在堆上分配内存。它返回一个指向新分配内存的指针,该指针被转换为 stlNode* 类型并存储在 newnode 变量中。这个新节点被初始化为包含一个 data 字段和一个 next 字段,其中 data 字段被设置为参数 x 的值,而 next 字段被初始化为 NULL。
STLNode* BuySListNode(SLTDataType x)
{STLNode* newnode = (STLNode*)malloc(sizeof(STLNode));newnode->data = x;newnode->next = NULL;
}3.5尾插
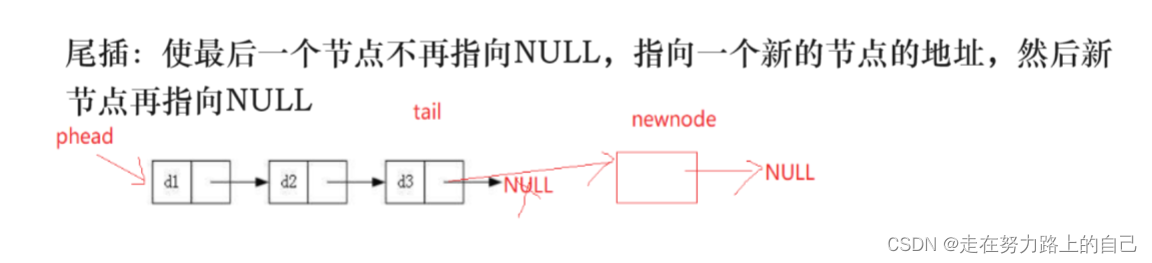
void SListPushBack(STLNode** pphead, SLTDataType x)
//void SListPushBack(STLNode*& pphead, SLTDataType x)
//在 C++语法中可以加&,引用,别名
{STLNode* newnode = (STLNode*)malloc(sizeof(STLNode));newnode->data = x;newnode->next = NULL;// 找尾节点的指针if (*pphead == NULL)//pphead是plist的地址{*pphead = newnode;//在尾部创建新节点}else {STLNode* tail = *pphead;//phead在开始时为空while (tail->next != NULL)//判断下一个指针是否为空{tail = tail->next;//指向下一个节点}// 尾节点,链接新节点tail->next = newnode;}
}3.6头插
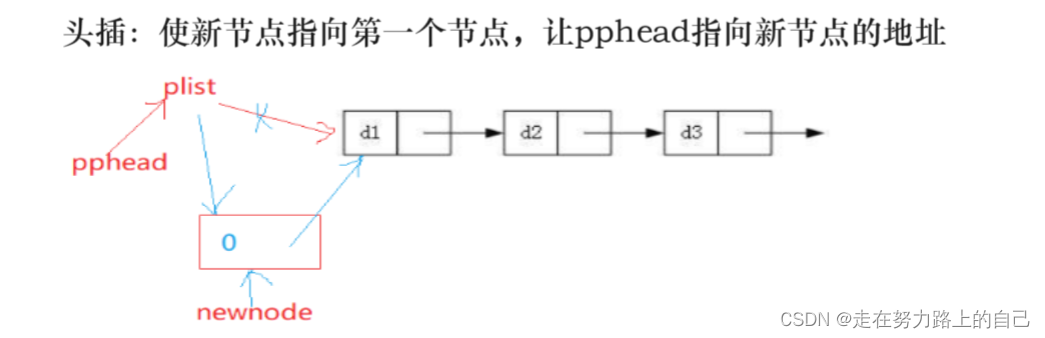
void SListPushFront(STLNode** pphead, SLTDataType x)
{STLNode* newnode = BuySListNode(x);//新建一个节点newnode->next = *pphead;//在第一个地址前建立一个新节点*pphead = newnode;//使新节点变为第一个地址
}3.7头删
void SListPopFront(STLNode** pphead)
{STLNode* next = (*pphead)->next;//保存下一个地址free(*pphead);//释放空间*pphead = next;//令其指针指向下一个地址
}3.8尾删
尾删的目的是从给定的单链表中删除最后一个节点,所以分三种情况:
1、链表为空
2、链表只有一个节点
3、链表有多个节点
链表为空:
如果链表为空(*pphead == NULL),那么就没有什么可以删除的内容,所以函数直接返回。
只有一个节点时:
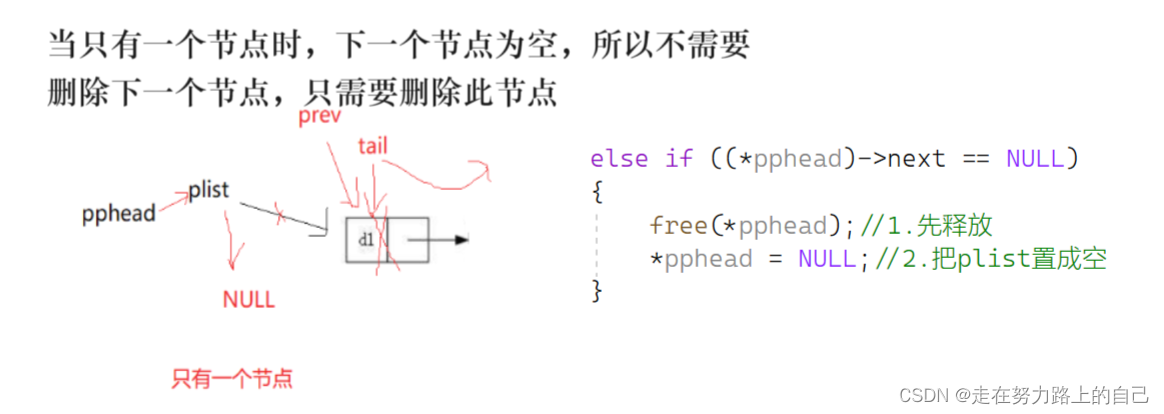
有多个节点时:
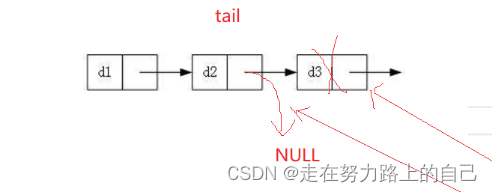
如果链表有多个节点,我们需要找到链表的最后一个节点,并删除它。为了找到最后一个节点,我们设置两个指针 prev 和 tail,开始时都指向链表头。然后我们遍历链表,直到找到最后一个节点。找到后,我们释放最后一个节点的内存,然后把倒数第二个节点的 next 设置为 NULL,表示链表最后一个节点已经被删除。
void SListPopBack(STLNode** pphead)
{//1.空//2.一个节点//3.一个以上节点if (*pphead == NULL)//1.空//如果为空,说明链表已经为NULL,没有可以删除的内容了{return;}else if ((*pphead)->next == NULL)//2.一个节点{free(*pphead);//1.先释放*pphead = NULL;//2.把plist置成空}else {//3.一个以上节点STLNode* prev = NULL;STLNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}3.9查找
其实就是遍历一遍链表,但是只能返回第一次出现的地址。我们查找到节点的地址后就可以通过地址去修改数据域中存储的数据。
TLNode* SListFind(STLNode* phead, SLTDataType x)
{STLNode* cur = phead;while (cur != NULL)//while (cur){if (cur->data = x){return cur;//找到了}cur = cur->next;}return NULL;
}3.10在pos的前面插入
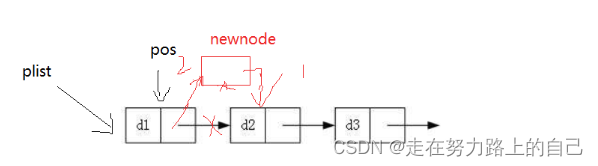
-
//创建新节点 stlNode* newnode = BuySListNode(x);
-
// 初始时,prev 指向链表的头节点 pphead。 stlNode* prev = *pphead;
-
while (cur != pos) // 这个 while 循环用于找到 pos 节点。
-
prev = prev->next; cur = cur->next; //如果 cur 不等于 pos,那么移动 prev 和 cur。prev 移动到 cur 的下一个节点。cur 移动到下一个节点。
-
prev->next = newnode;//现在,prev 指向 pos 的前一个节点,cur 指向 pos 节点本身。我们将新节点插入到 prev 和 cur 之间。
-
prev->next = newnode; // 然后,我们将新节点的 next 指向 pos,这样新节点就位于 pos 之前了。
void SListInsert(STLNode** pphead, STLNode* pos, SLTDataType x)
{if (pos == *pphead){SListPushFront(pphead, x);}else {STLNode* newnode = BuySListNode(x);STLNode* prev = *pphead;/*while (prev->next != pos)*/STLNode* cur = *pphead;while (cur != pos){prev = prev->next;}prev->next = newnode;newnode->next = pos;}
}3.11删除pos位置的值
void SListErase(STLNode** pphead, STLNode* pos)
{if (pos == *pphead)//如果要删除的是头节点{SListPopFront(pphead);//头删}else {STLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;//删除指定位置的节点free(pos);//释放要删除节点的内存}
}四、SList.c
#include"SeqList.h"void SListPrint(STLNode* phead)
{STLNode* cur = phead;while (cur != NULL)//第一个地址不为空{printf("%d->", cur->data);cur = cur->next;//令cur下一个地址}printf("NULL\n");}STLNode* BuySListNode(SLTDataType x)
{STLNode* newnode = (STLNode*)malloc(sizeof(STLNode));newnode->data = x;newnode->next = NULL;
}//尾插
void SListPushBack(STLNode** pphead, SLTDataType x)
//void SListPushBack(STLNode*& pphead, SLTDataType x)
//在 C++语法中可以加&,引用,别名
{STLNode* newnode = (STLNode*)malloc(sizeof(STLNode));newnode->data = x;newnode->next = NULL;// 找尾节点的指针if (*pphead == NULL)//pphead是plist的地址{*pphead = newnode;}else {STLNode* tail = *pphead;//phead在开始时为空while (tail->next != NULL)//判断下一个指针是否为空{tail = tail->next;}// 尾节点,链接新节点tail->next = newnode;}
}void SListPushFront(STLNode** pphead, SLTDataType x)
{STLNode* newnode = BuySListNode(x);newnode->next = *pphead;*pphead = newnode;
}void SListPopFront(STLNode** pphead)
{STLNode* next = (*pphead)->next;//保存下一个地址free(*pphead);//释放空间*pphead = next;//令其指针指向下一个地址
}void SListPopBack(STLNode** pphead)
{//1.空//2.一个节点//3.一个以上节点if (*pphead == NULL){return;}else if ((*pphead)->next == NULL){free(*pphead);//1.先释放*pphead = NULL;//2.把plist置成空}else {STLNode* prev = NULL;STLNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}STLNode* SListFind(STLNode* phead, SLTDataType x)
{STLNode* cur = phead;while (cur != NULL)//while (cur){if (cur->data = x){return cur;//找到了}cur = cur->next;}return NULL;
}// 在pos的前面插入x
void SListInsert(STLNode** pphead, STLNode* pos, SLTDataType x)
{if (pos == *pphead){SListPushFront(pphead, x);}else {STLNode* newnode = BuySListNode(x);STLNode* prev = *pphead;/*while (prev->next != pos)*/STLNode* cur = *pphead;while (cur != pos){prev = prev->next;}prev->next = newnode;newnode->next = pos;}
}
// 删除pos位置的值
void SListErase(STLNode** pphead, STLNode* pos)
{if (pos == *pphead){SListPopFront(pphead);}else {STLNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}
}五、Test.c
#include"SeqList.h"void TestSList1()
{STLNode* plist = NULL;//先让plist指向空SListPushBack(&plist, 1);SListPushBack(&plist, 2);//插入几个值,用节点存起来SListPushBack(&plist, 3);SListPushBack(&plist, 4);SListPushFront(&plist, 0);SListPrint(plist);SListPopFront(&plist);SListPopFront(&plist);SListPopFront(&plist);SListPrint(plist);SListPopFront(&plist);SListPopFront(&plist);SListPrint(plist);
}
void TestSList3()
{STLNode* plist = NULL;//先让plist指向空SListPushBack(&plist, 1);SListPushBack(&plist, 2);//插入几个值,用节点存起来SListPushBack(&plist, 3);SListPushBack(&plist, 4);SListPrint(plist);/*SListPopBack(&plist);SListPopBack(&plist);SListPrint(plist);*///想在3的前面插入一个数字STLNode* pos = SListFind(plist, 1);if (pos){SListInsert(&plist, pos, 10);}SListPrint(plist);pos = SListFind(plist, 3);if (pos){SListInsert(&plist, pos, 30);}SListPrint(plist);
}void TestSList4()
{STLNode* plist = NULL;//先让plist指向空SListPushBack(&plist, 1);SListPushBack(&plist, 2);SListPushBack(&plist, 3);SListPushBack(&plist, 4);SListPrint(plist);STLNode* pos = SListFind(plist, 3);if (pos){SListErase(&plist, pos);}SListPrint(plist);pos = SListFind(plist, 4);if (pos){SListErase(&plist, pos);}SListPrint(plist);
}int main()
{TestSList4();return 0;
}今天就先到这了!!!
看到这里了还不给博主扣个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
你们的点赞就是博主更新最大的动力!
有问题可以评论或者私信!!!

关注必回!!!
相关文章:
链表基础知识(一、单链表)
一、链表表示和实现 顺序表的问题及思考 问题: 1. 中间/头部的插入删除,时间复杂度为O(N) 2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。 3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当…...

mysql的ON DELETE CASCADE 和ON DELETE RESTRICT区别
ON DELETE CASCADE 和 ON DELETE RESTRICT 是 MySQL 中两种不同的外键约束级联操作。它们之间的主要区别在于当主表中的记录被删除时,子表中相关记录的处理方式。 ON DELETE CASCADE: 当在主表中删除一条记录时,所有与之相关的子表中…...
如何快速将图片转为excel?
一、打开金鸣表格文字识别软件。 二、点击添加文件按钮,在打开的窗口中选择目标图片,然后点击“打开”,将图片添加进待识别的列表中。 三、点击提交识别或识别全部。 四、识别完成后点击“打开文件”即可打开识别好的结果文件(EXC…...
)
元编程(Metaprogramming)
本章将介绍第8️⃣种编程范式---元编程,以及它的优缺点、案例分析和小项目的代码示例。 优点 元编程的优点: 灵活性和可重用性:元编程允许在运行时生成代码,使得程序更加灵活和可重用。可以根据需要动态生成代码片段࿰…...

IEEE Transactions on Industrial Electronics工业电子TIE论文投稿须知
一、背景 IEEE TIE作为控制领域的TOP期刊,接收机器人、控制、自动驾驶、仪器和传感等方面的论文,当然范围不止这些,感兴趣的可以自行登录TIE官网查看。所投稿论文必须经过实验验证,偏工程应用类,当然也必须有方法上的…...
Linux--操作系统
1. 常见的操作系统 Windowsmac OSLinuxiOSAndroid 2. 操作系统的定义 操作系统直接运行在计算机上的系统软件, 它是控制硬件和支持软件运行的计算机程序。 3. 操作系统的作用 向下控制硬件向上支持软件的运行,具有承上启下的作用。 4.总结 操作系统…...

HarmonyOS—实现UserDataAbility
UserDataAbility接收其他应用发送的请求,提供外部程序访问的入口,从而实现应用间的数据访问。Data提供了文件存储和数据库存储两组接口供用户使用。 文件存储 开发者需要在Data中重写FileDescriptoropenFile(Uriuri,Stringmode)方法来操作文件…...
Java实现插入排序及其动图演示
插入排序是一种简单直观的排序算法。它的基本思想是将一个待排序的元素插入到已经排序好的序列中的适当位置,从而得到一个新的、元素个数加一的有序序列。 具体的插入排序算法过程如下: 从第一个元素开始,认为第一个元素已经是有序序列。取…...
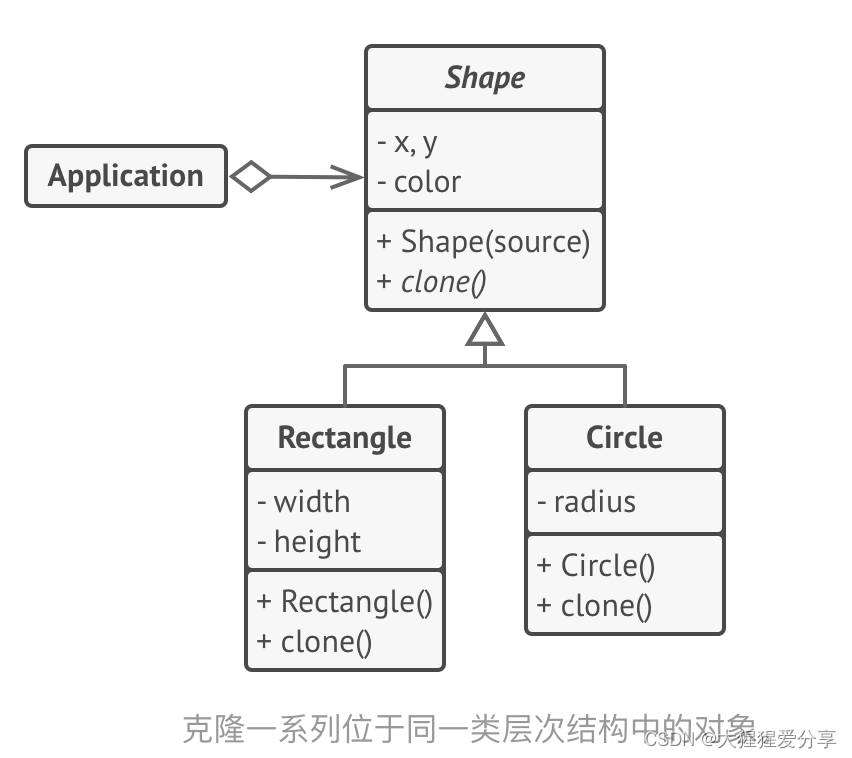
设计模式——原型模式(创建型)
引言 原型模式是一种创建型设计模式, 使你能够复制已有对象, 而又无需使代码依赖它们所属的类。 问题 如果你有一个对象, 并希望生成与其完全相同的一个复制品, 你该如何实现呢? 首先, 你必须新建一个属于…...

深眸科技以机器视觉高性能优势,为消费电子行业提供优质解决方案
机器视觉技术近年来发展迅速,基于计算机对图像的处理与分析,能够识别和辨别目标物体,被广泛应用于人工智能、智能制造等领域。 机器视觉凭借着高精度、高效率、灵活性和可靠性等优势,不断推进工业企业生产自动化和智能化进程&…...
的两种书写方法对比)
React setState()的两种书写方法对比
在React中,setState()方法是一个非常重要的函数,用于更新组件的状态。它有两种常见的书写方式:对象解构赋值和使用函数。本文将对比这两种方法,并解释它们的优缺点和适用场景。 首先,让我们来看看对象解构赋值这种方法…...

orb-slam2学习总结
目录 视觉SLAM 1、地图初始化 2、ORB_SLAM地图初始化流程 3、ORB特征提取及匹配 1、对极几何 2、对极约束 (epipolar constraint) 3、基础矩阵F、本质矩阵E 5、单目尺度不确定性 6、单应矩阵(Homography Matrix) 6.1 什么是单应矩…...

通过wireshark判断web漏洞的流量特征
sql注入 定位http协议,通过查找get请求定位到关键字 抓到关键字union select xss 定位get请求的关键字 文件上传 找到对应的上传数据包,追踪tcp流 文件包含、文件读取 查看url找到包含的关键字 在根路径写入一个phpinfo(); 使用../进行目录遍…...

Command ‘npm‘ not found, but can be installed with:sudo apt install npm 解决方案
问题描述 今天在执行 npm install -g npx 报错 Command npm not found, but can be installed with: sudo apt install npm 解决方案 sudo apt-get remove npm sudo apt-get remove nodejs-legacy sudo apt-get remove nodejs sudo rm /usr/bin/node sudo apt-get install …...
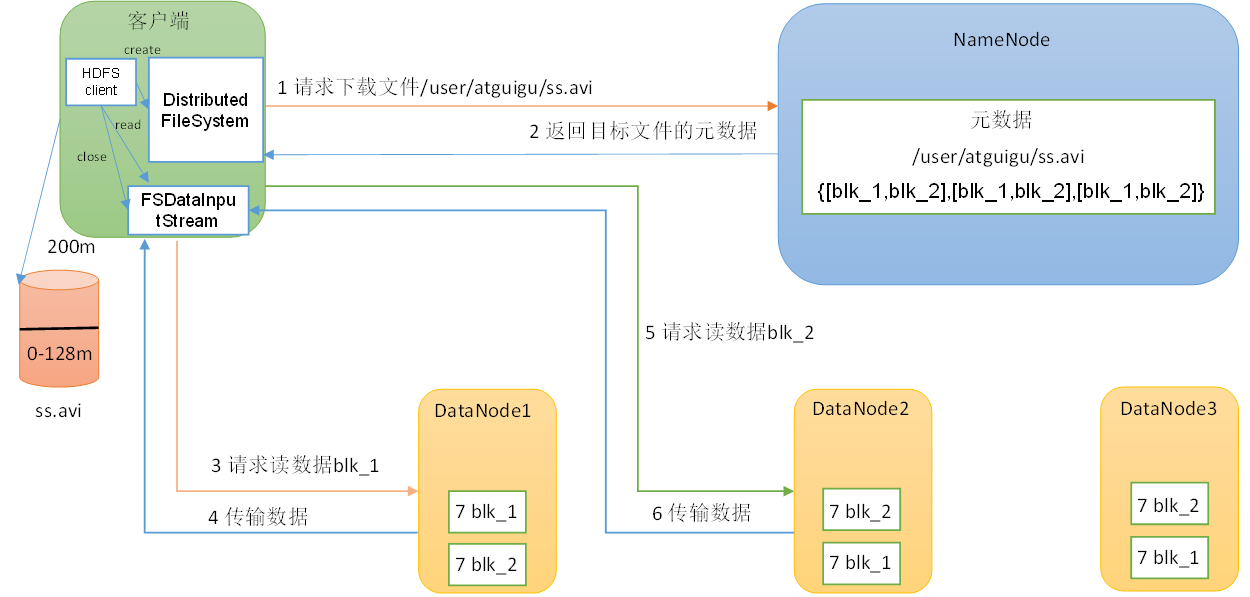
【Hadoop_04】HDFS的API操作与读写流程
1、HDFS的API操作1.1 客户端环境准备1.2 API创建文件夹1.3 API上传1.4 API参数的优先级1.5 API文件夹下载1.6 API文件删除1.7 API文件更名和移动1.8 API文件详情和查看1.9 API文件和文件夹判断 2、HDFS的读写流程(面试重点)2.1 HDFS写数据流程2.2 网络拓…...

go-zero开发入门之网关往rpc服务传递数据
go-zero 的网关往 rpc 服务传递数据时,可以使用 headers,但需要注意前缀规则,否则会发现数据传递不过去,或者对方取不到数据。 go-zero 的网关对服务的调用使用了第三方库 grpcurl,入口函数为 InvokeRPC: …...
Word插件-好用的插件-批量插入图片-大珩助手
现有100张图片,需要批量插入word中,并在word中以每页6张图片的形式呈现,请问怎样做? 使用word大珩助手,多媒体-插入图片,根据图片的长宽,选择连续图片、一行2个图或一行3个图,可一次…...
小程序域名SSL证书能用免费的吗?
众所周知,目前小程序要求域名强制使用https协议,否则无法上线。但是对于大多数开发者来说,为每一个小程序都使用上付费的SSL证书,也是一笔不小的支出。那么小程序能使用免费的SSL证书吗? 答案是肯定的。目前市面上可选…...

selenium自动化(中)
显式等待与隐式等待 简介 在实际工作中等待机制可以保证代码的稳定性,保证代码不会受网速、电脑性能等条件的约束。 等待就是当运行代码时,如果页面的渲染速度跟不上代码的运行速度,就需要人为的去限制代码执行的速度。 在做 Web 自动化时…...

uniapp app将base64保存到相册,uniapp app将文件流保存到相册
如果是文件流可以先转base64详情见>uniapp 显示文件流图片-CSDN博客 onDown(){let base64 this.qrcodeUrl ; // base64地址const bitmap new plus.nativeObj.Bitmap("test");bitmap.loadBase64Data(base64, function() {const url "_doc/" new Dat…...
)
告别手动测量!用ArcGIS+CAD搞定河道平均宽度的两种实用方法(附详细步骤)
河道平均宽度计算实战:ArcGIS与CAD高效协同方案解析 河道宽度测量是水文分析、防洪规划与生态评估中的基础工作,但传统手工测量方式在面对复杂河道形态时往往效率低下。本文将深入解析两种基于ArcGIS与CAD协同的自动化计算方法,通过技术组合实…...

TI WEBENCH滤波器设计工具:从理论到实战的电路设计加速器
1. WEBENCH滤波器设计工具:从概念到成品的“加速器”在模拟电路设计,尤其是信号调理领域,滤波器设计一直是个既基础又颇具挑战性的环节。无论是为了滤除电源噪声,还是从复杂的传感器信号中提取有效成分,一个性能优良的…...

从STM32F103到GD32F303:如何用CubeMX和Keil5低成本‘平替’升级你的项目?
从STM32F103到GD32F303:低成本高性能迁移实战指南 在嵌入式开发领域,芯片选型往往需要在性能与成本之间寻找平衡点。对于已经熟悉STM32F103系列开发但面临成本压力或性能瓶颈的工程师来说,GD32F303系列提供了一个极具吸引力的替代方案。这款国…...

别再被假密码骗了!手把手教你用010 Editor识别并破解ZIP/RAR伪加密压缩包
010 Editor实战:揭秘ZIP/RAR伪加密压缩包的技术真相 当你从某个CTF比赛下载到一个加密压缩包,输入密码却提示错误时,是否想过这可能是个精心设计的陷阱?网络安全领域存在一种特殊的"伪加密"技术,它让压缩包看…...

建模也有Skills了:MWORKS.Sysplorer Skills已开源至MoHub!
智能体能调用建模工具,并不等于它能稳定完成工程建模任务。在真实工程场景中,一个可交付的模型往往要经过需求理解、模型库选择、组件映射、参数补全、检查翻译、仿真验证、结果判读和交付归档。过去,这些环节高度依赖工程师经验;…...

SuperRDP完整指南:一键解锁Windows远程桌面多用户并发连接限制
SuperRDP完整指南:一键解锁Windows远程桌面多用户并发连接限制 【免费下载链接】SuperRDP Super RDPWrap 项目地址: https://gitcode.com/gh_mirrors/su/SuperRDP SuperRDP是基于RDPWrap技术的智能工具,专为突破Windows系统远程桌面功能限制而设计…...

告别论文焦虑:百考通AI,让你的本科毕业论文像“闯关升级”一样简单
又到了一年毕业季,对于广大本科生而言,那座名为“毕业论文”的大山,是否又一次压得你喘不过气?面对空白的Word文档,你是否感到无从下手?导师的催促、复杂的格式、浩如烟海的文献、以及令人心慌的查重……这…...

家长选择赶考小状元AI自习室还是其他品牌对孩子学习更有帮助?深度解析三大维度
随着教育智能化浪潮席卷而来,家长们在为孩子选择学习辅助工具时,面临着前所未有的多元选择。传统网课、新兴自习室品牌层出不穷,而深耕智能教育领域二十年的赶考小状元AI智能自习室,以其独特的“教育内核科技工具运营支持”三维融…...

GitLab团队协作实战:从分支策略到CI/CD流水线优化指南
1. 项目概述:为什么需要一个专属的GitLab使用指导?在团队协作开发中,版本控制系统是基石,而GitLab作为集代码托管、CI/CD、项目管理于一体的DevOps平台,其重要性不言而喻。然而,对于许多新加入团队的开发者…...

避坑指南:在Docker里部署OpenWrt做软路由,这几个macvlan和网络配置的坑你别踩
DockerOpenWrt软路由避坑实战:macvlan网络疑难解析与高阶配置 当你在双网口服务器上尝试用Docker部署OpenWrt软路由时,是否经历过这样的绝望时刻:所有配置看似正确,但客户端设备就是无法上网;宿主机与容器仿佛身处平行…...