Flink 有状态流式处理
传统批次处理方法
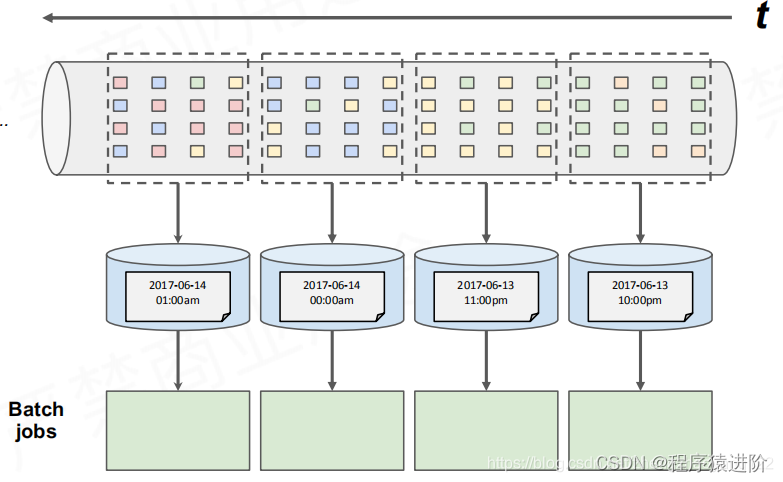
【1】持续收取数据(kafka等),以window时间作为划分,划分一个一个的批次档案(按照时间或者大小等);
【2】周期性执行批次运算(Spark/Stom等);
传统批次处理方法存在的问题:
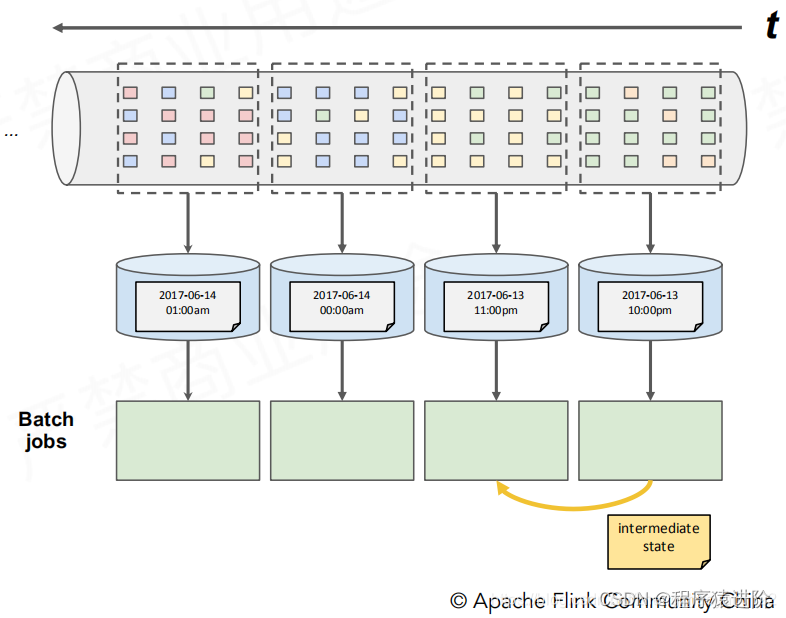
【1】假设计算每小时出现特定事件的转换次数(例如:1、2…),但某个事件正好处于1到2之间就尴尬了。需要将1点处理一半的结果带到2点这个批次中进行运算。而这个划分跟我们事件发生的时间也是有误差的。
【2】在分布式多线程的情况下,如果接收到事件的顺序颠倒了,又该如何处理?
理想方法
累积状态:表示过去历史接收过的所有事件。可以是计数或者机器模型等等。
 我们要处理一个持续维护的状态时,最适合的方式就是状态流处理(累积状态和维护状态+时间,是不是该收的结果都收到了)
我们要处理一个持续维护的状态时,最适合的方式就是状态流处理(累积状态和维护状态+时间,是不是该收的结果都收到了)
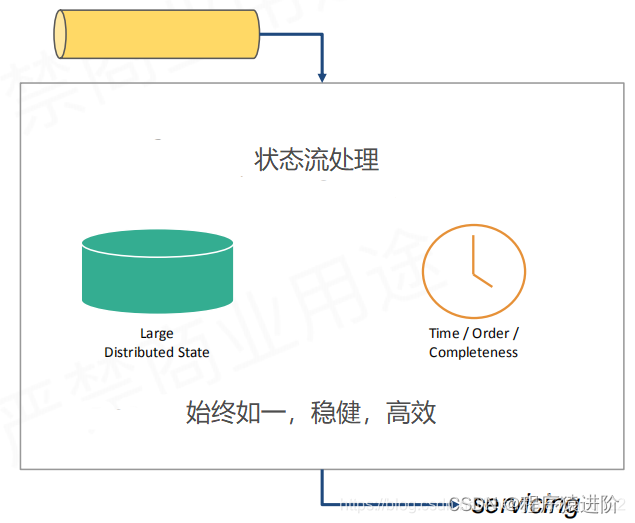
【1】有状态流处理作为一种新的持续过程范式,处理连续的数据;
【2】产生准确的结果;
【3】实时可用的结果仅为模型的自然结果;
流式处理
流处理系统或者流处理引擎都是数据驱动的,而不是定期或者人为的去触发。数据也没有物理边界。
一般系统都会把操作符放上去,等待数据的到来进行计算。如下是一个逻辑模型(DAG)
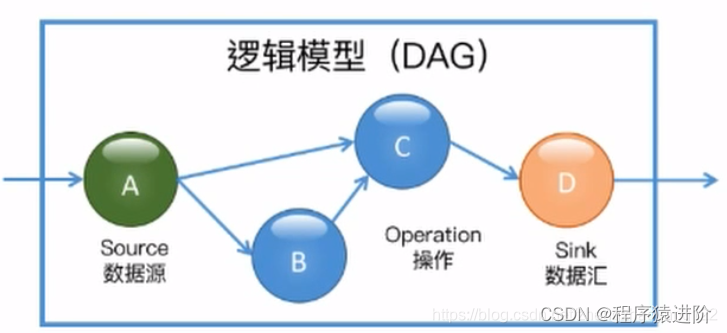
分散式流式处理
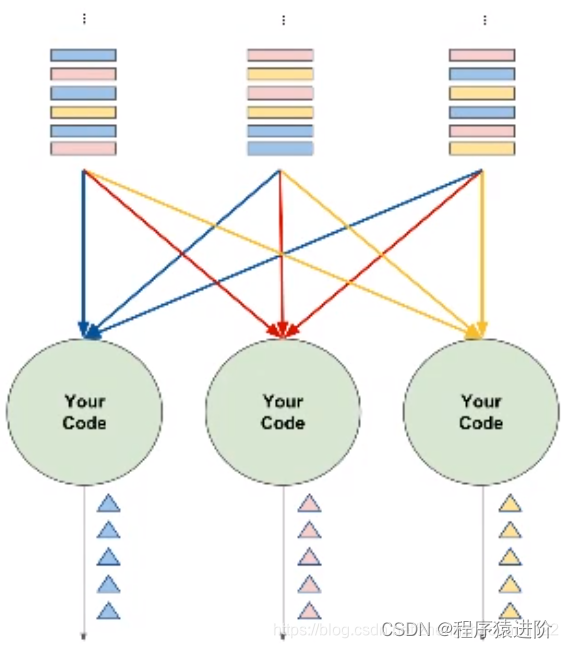
【1】从数据中选择一个属性作为key对输入流进行分区;
【2】使用多个实例,每个实例负责部分key的存储,根据Hash值,相同的key一定落在相同的分区进行处理;
【3】根据流式数据处理的DAG模型,有对应如下的分布式流处理的实例模型。例如A算子拥有两个实例,上游的实例节点可能同时与下游的一个或多个节点进行传输。这些实例根据系统或者人为的因素分配在不同的节点之上。节点与节点之间数据传输也会涉及网络之间的占用。本地的传输就不需要走网络
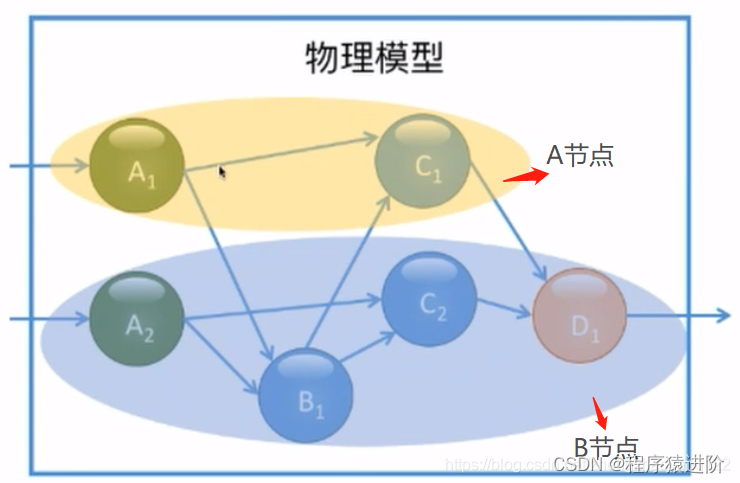
有状态分散式流式处理
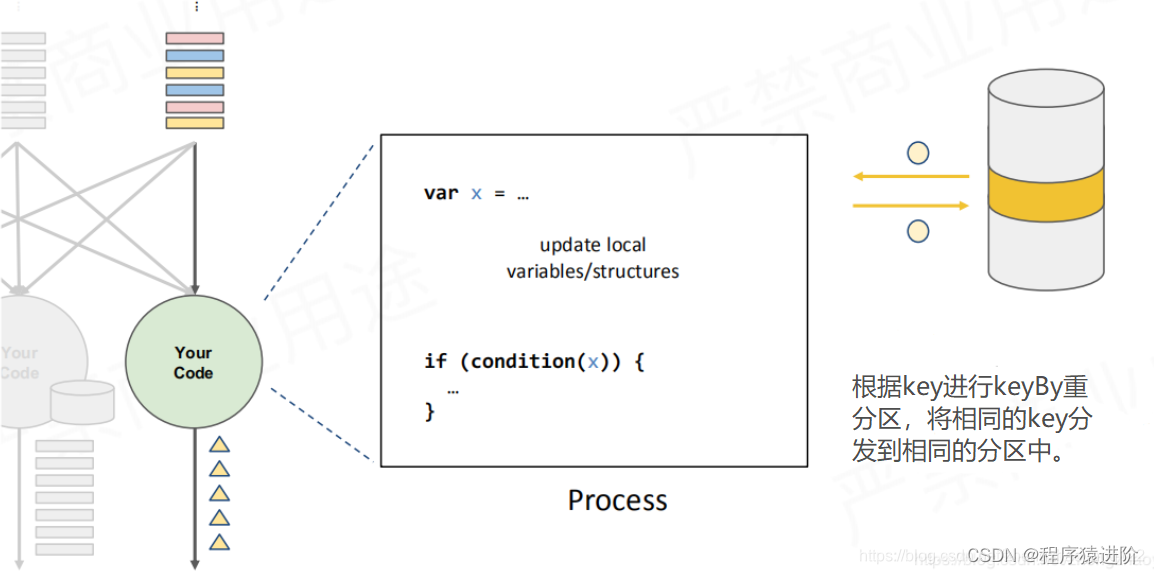
定义一个变量X,输出结果依据这个X,这个X就是一个状态。有状态分散的流失处理引擎,当状态可能会累计非常大。当key比较多的时候就会超出单台节点的负荷量。这个x就应该有状态后台使用memory去维护它。【数据倾斜】
状态容错(State Fault Tolerance)
状态挂了,如何确保状态拥有精确一次(exactly-onceguarantee)的容错保证?就是通过定期的快照+事件日志位置。我们先假设一个简单的场景,如下,一个队列在不断的传输数据。单一的process在处理数据。这个process没处理一个数据都会累计一个状态。如何为这个process做一个容错。做法就是没处理完一笔,更改完状态之后,就做一次快照(包含它处理的数据在队列中的位置和它处理到的位置以及当时的状态进行对比)
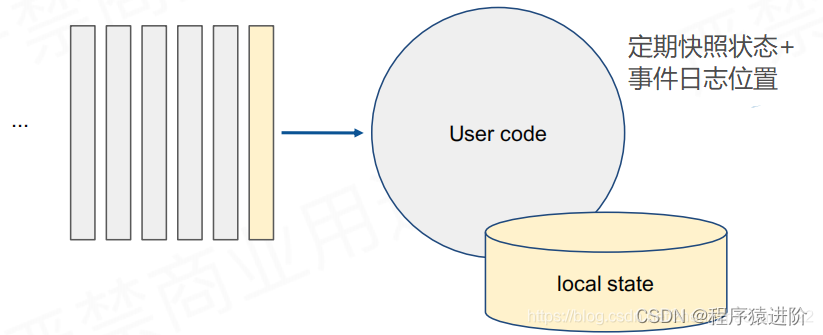
举个例子:如下我处理到第二笔数据,我就会记录下第二个位置在进入process之前的信息(位置X+状态@X)
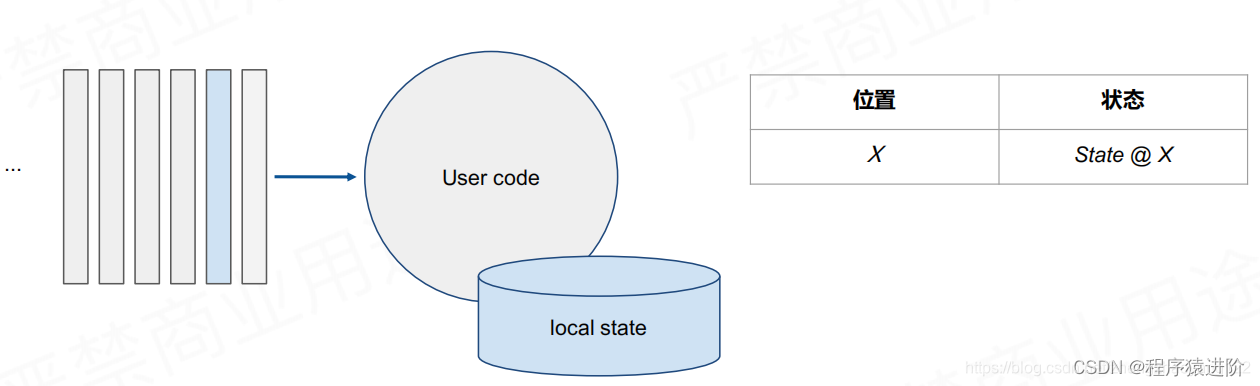
当进入process处理的时候出现了fail时,Flink就会根据上一次的位置+状态进行恢复。
如何在分散式场景下替多个拥有本地状态的运算子产生一个全域一致的快照(global consistent snapshot)?
方式一:更改该任务流过的所有运算子的状态。比较笨,有一个副作用,就是我处理完这笔数据,它应该就到了一个process,我本应该做其他数据的处理了,可是为了全局一致性快照就会停止前面和当前的process的运算来保证全局一致性。
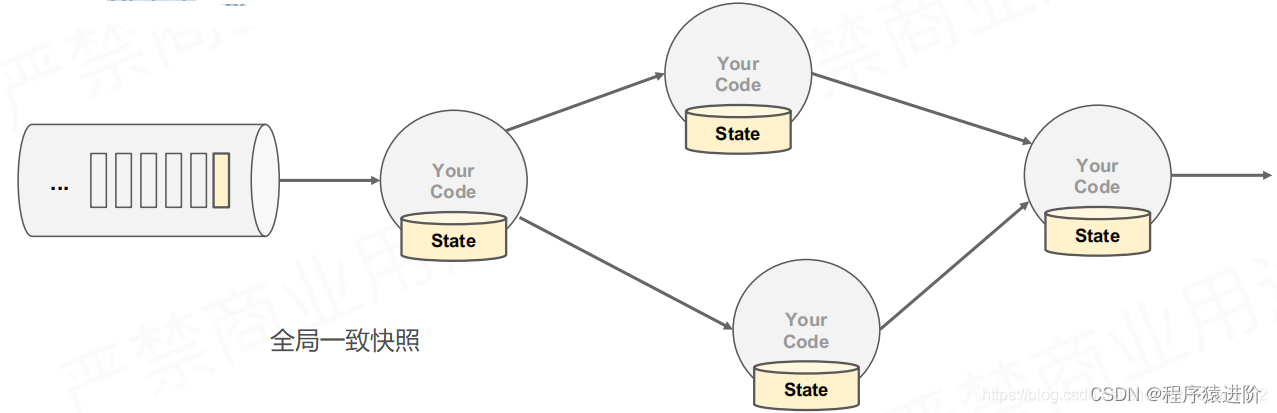
分散式状态容错
通过checkpoint实现分散式状态容错
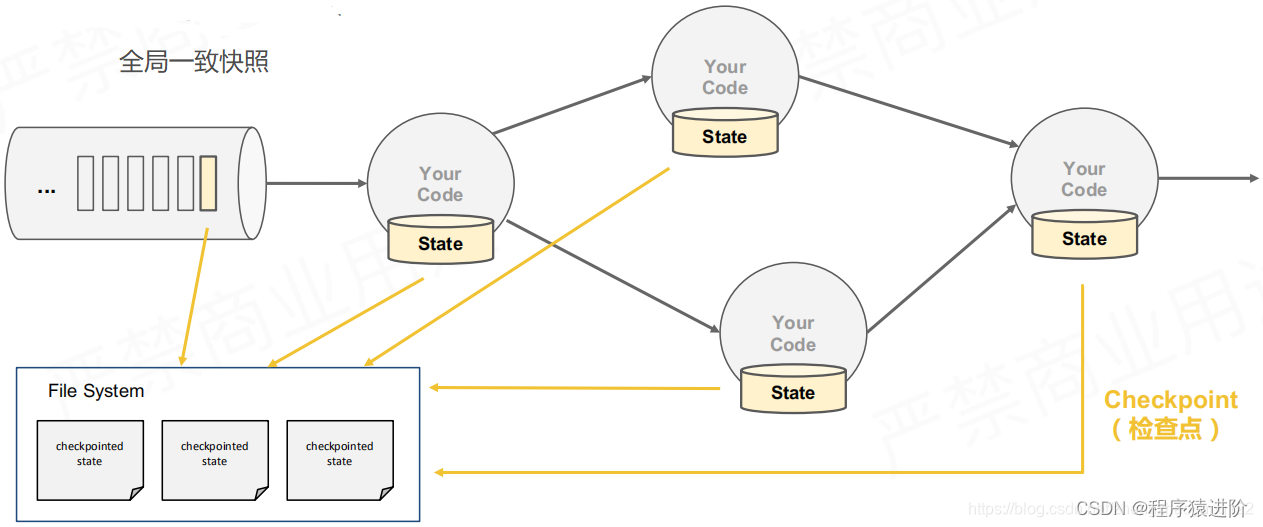
每一个运算子它本地都有一个维护一个状态,当要产生一个检查点(checkpoit)的时候,都会将这个检查点存储在一个更小的分布式文件系统DFS中。当出现某个算子fail之后,就会从所有的checkpoint中获取所有算子的上一个状态进行恢复。把消息队列的位置也进行恢复。也就是多线程工作,每一个任务在DFS中就可以看作一个线程,它们数据存储的key就是这个任务,每一个算子的处理状态都会按照处理顺序添加进去。
分布式快照(Distributed Snapshots)
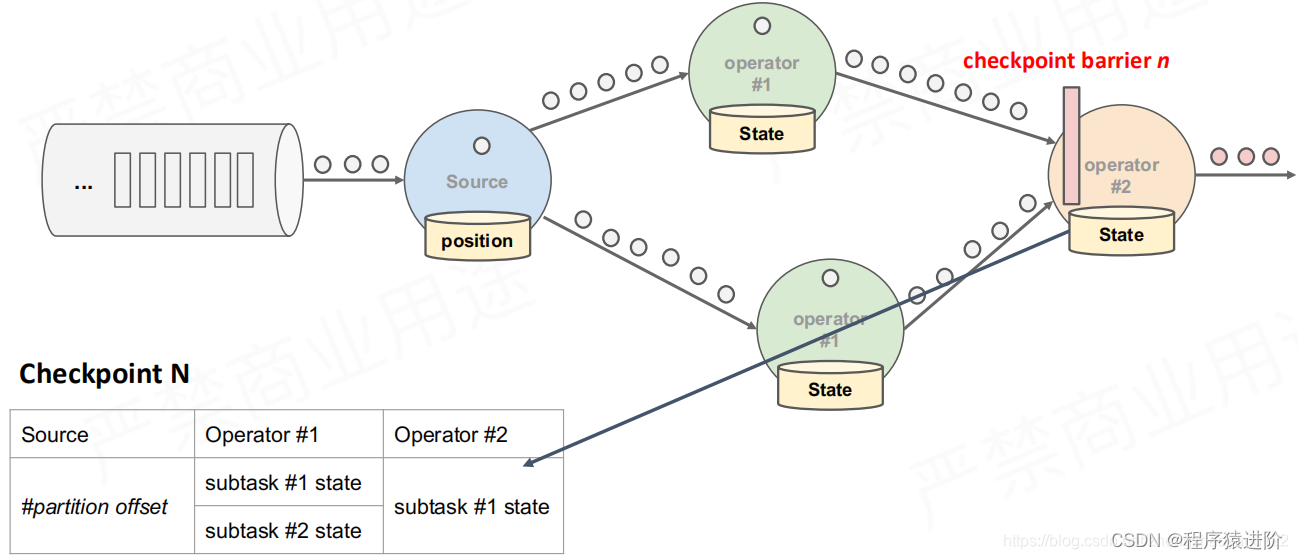
更重要是时如何在不中断运算的前提下生成快照?其实就是给每一个任务标记一个checkpoint n不同的任务这个n是不同的,相同的任务在不同的算子里面它是相同的。具体我们把这个分解后看看。
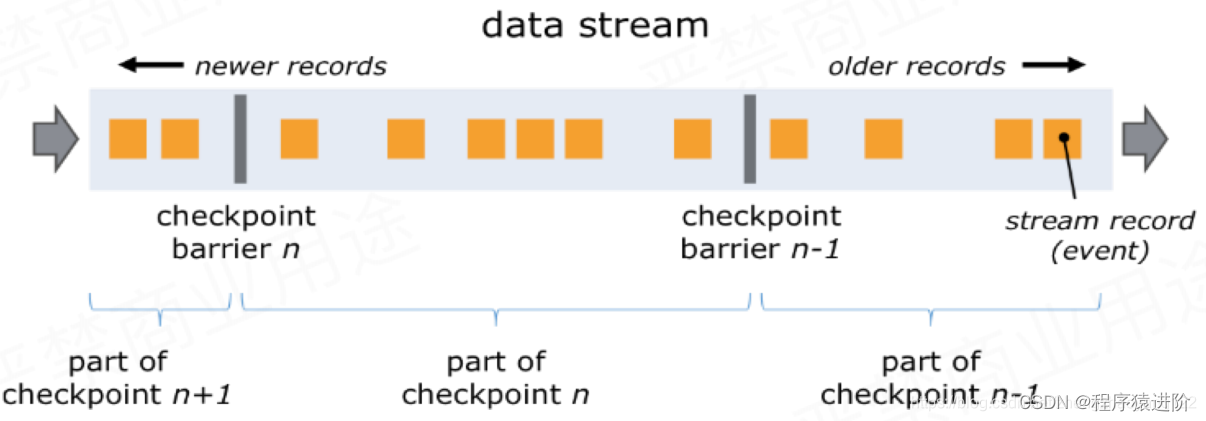
【1】如下图,当我们从数据源获取数据的时候,其实我们已经开始有状态了,这个时候我们可以把任务处理的整个过程抽象成如下图中的一张表。
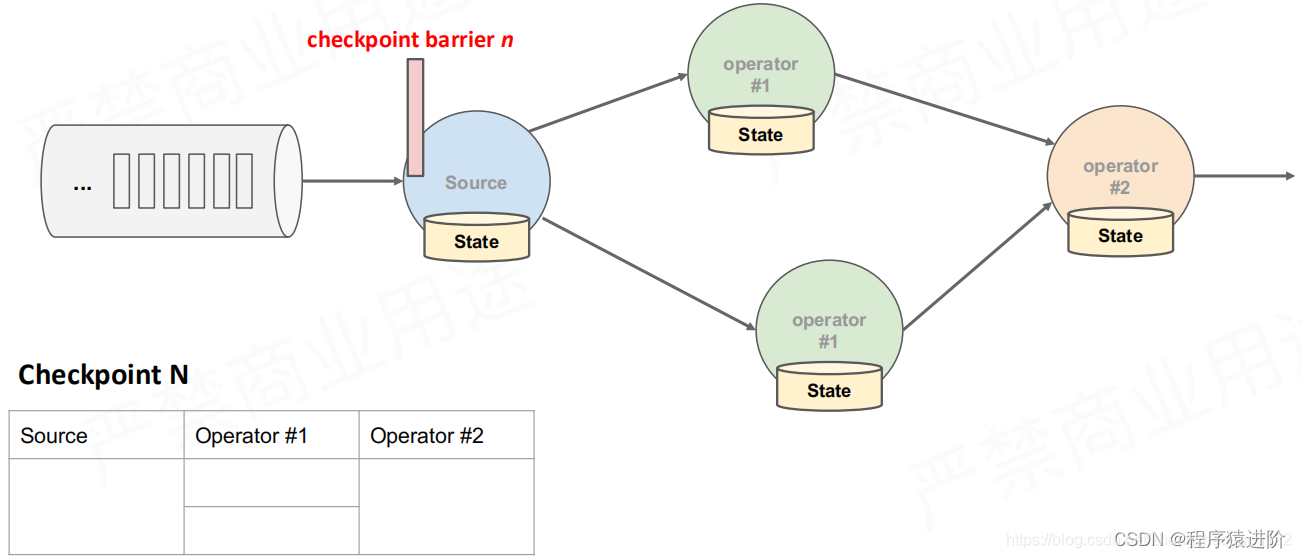
【2】首先是数据源的状态,就是数据在操作前的一个位置offset进行快照存储,如下图所示:
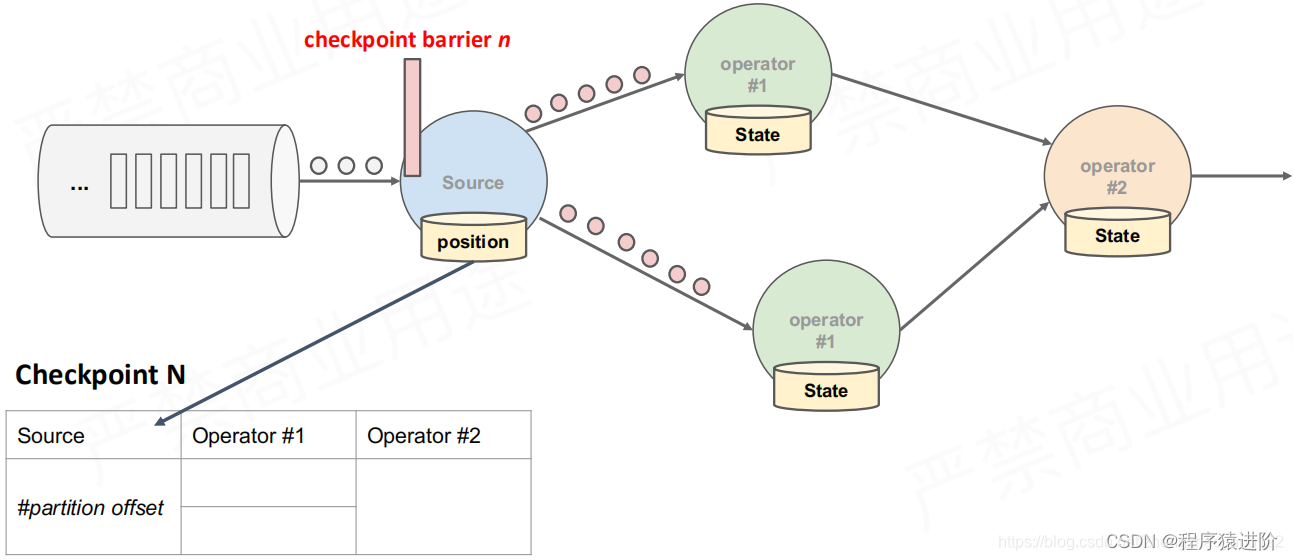
【3】当获取到数据源之后,就进入算子中进行处理,此时就会对数据进入之前的状态进行checkpoint。记录一个savepoint。
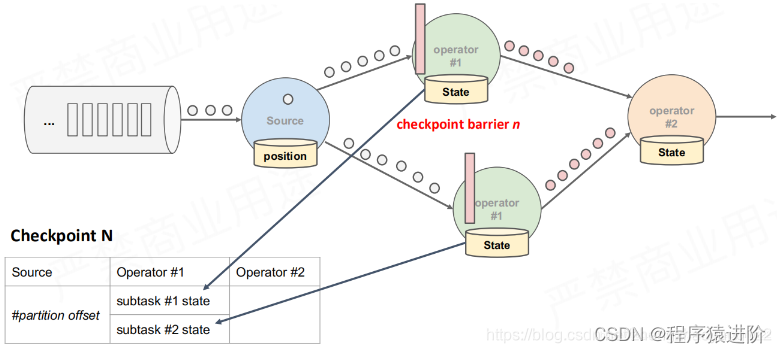
【4】在最后一次操作前(输出)也会记录checkpoint。在这个过程中,其实前面的算子也在产生不同的 checkpoint n-1 等。如果要进行恢复使用的话,必须是一个complete完整的Checkpoint。只有部分数据的Checkpoint是不能使用的。
状态维护(State Management)
本地维护的这个状态可能非常非常大。后端的管理系统一般使用内存维护这些状态。
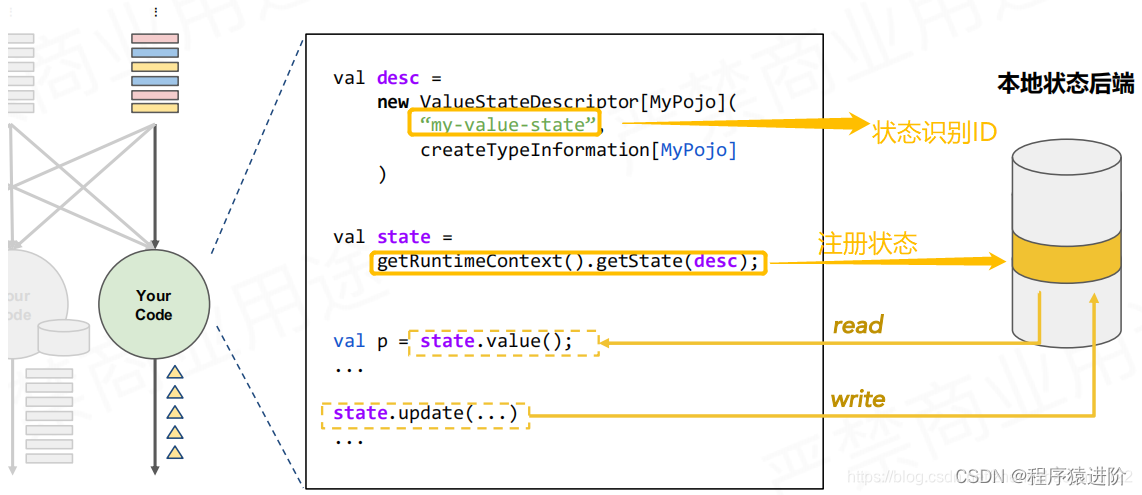
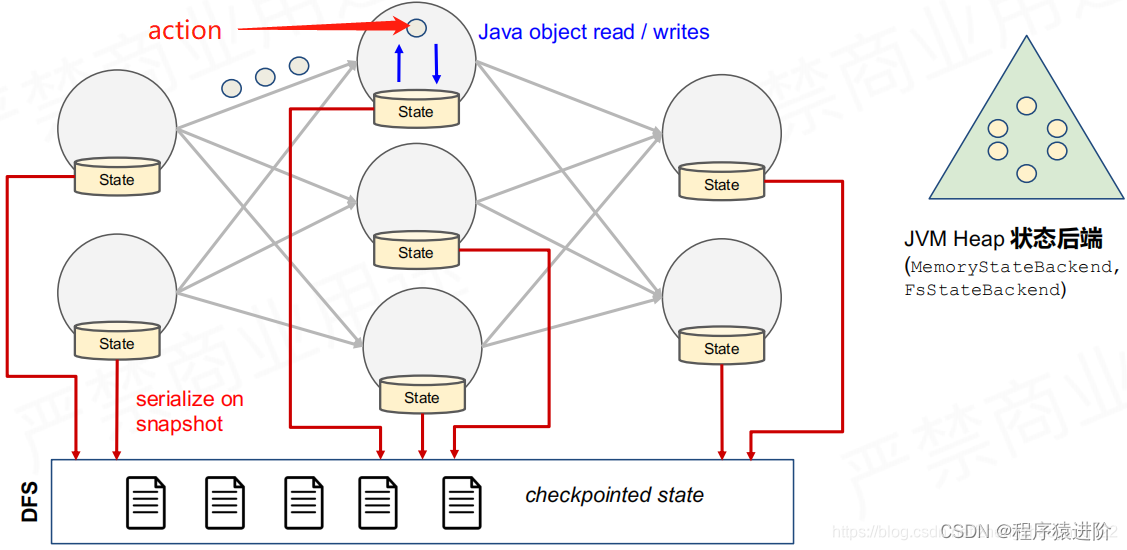
Flink提供了两种状态后端:JVM Heap状态后端,适合比较小的状态,量不要很大。当运算子action要读取状态的时候,都是一个Java对象的read或者write。当要产生一个检查点的时候,需要将每个运算子的本地状态数据通过序列化存储在DFS中,
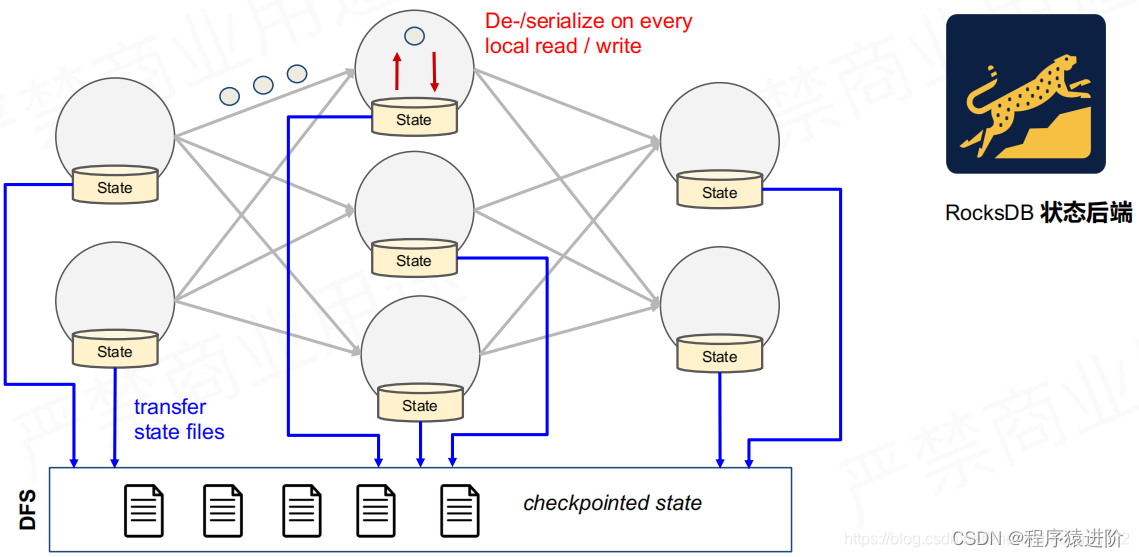
当状态非常大的时候就不能使用JVM Heap的时候,就需要用到RocksDB。当算子需要读取的时候本地state的时候需要进行序列化操作从而节省内存,同时,当需要进行checkpoint到DFS时,也少了序列化的步骤。它也会给本地存储一份,当fail的时候就可以很快恢复,提高效率。
Event-time 处理
EventTime是事件产生的时间。
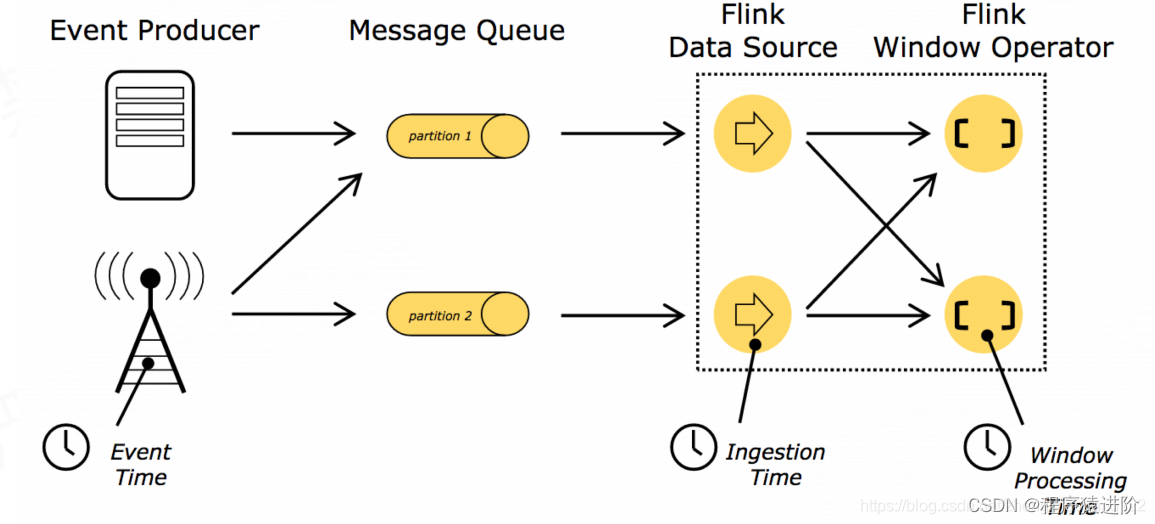
下面是一张,程序处理时间与事件发生时间的时间差的一张对比图来更好的理解EventTime。
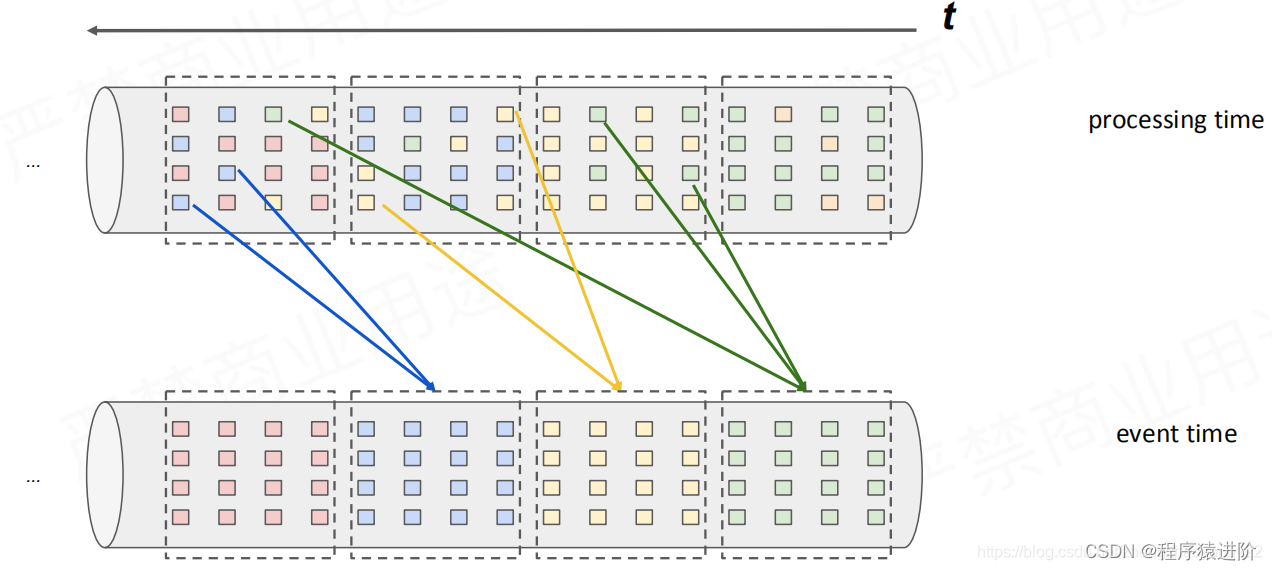
Event-Time 处理
也就是说我们要统计的3-4点之间的数据,程序4点结束这个执行不是根据window时间,而是根据event-Time。

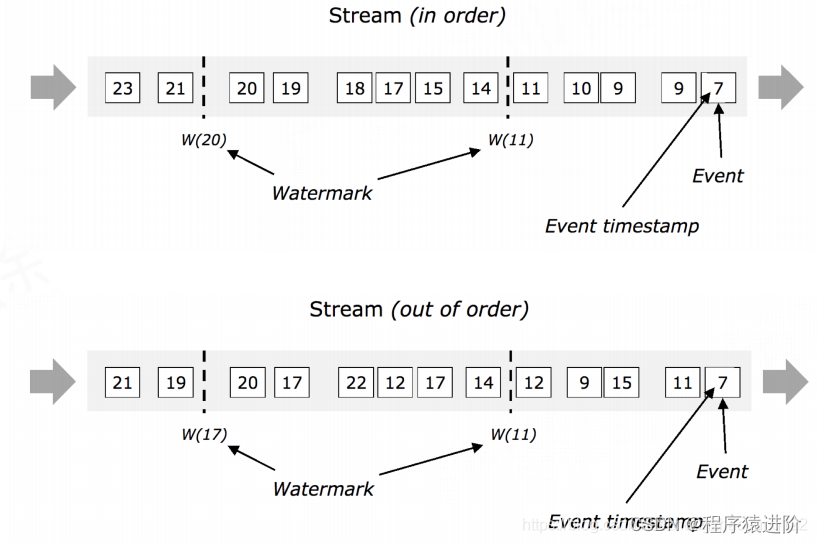
Watermarks
Flink是watermarks实现Event-Time功能的。在Flink里面也属于一个特殊事件,精髓是当某个运算子收到一个带有时间戳t的watermark后就不会再收到任何小于该时间戳的事件了。也就是当window需要统计4点的数据时,例如我们每5分钟发一次watermark,那么当window收到4.05的watermark的时候才会去统计4点之前的数据(下一次)。如果4.05收到了4点之前的数据的话,Flink1.5会把这个事件输出到旁路输出(side output),你可以获取出来,进行处理。目前有一个问题就是:如果某个Stream Partition 没有输入了,也就没有Watermarks。那么window就没办法进行处理了。当多个数据流的watermarks不相同的时候,Flink会取最小的watermarks进行运算。可以在接收到资源的时候通过代码设置watermarks。
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
状态保存与迁移(Savenpoints and Job Migration)
可以想成:一个手动产生的检查点(CheckPoint):保存点记录某一个流失应用中的所有运算中的状态。当触发SavePoint之后,Flink提供了两种选择停止消费或者继续运算,根据场景定义。
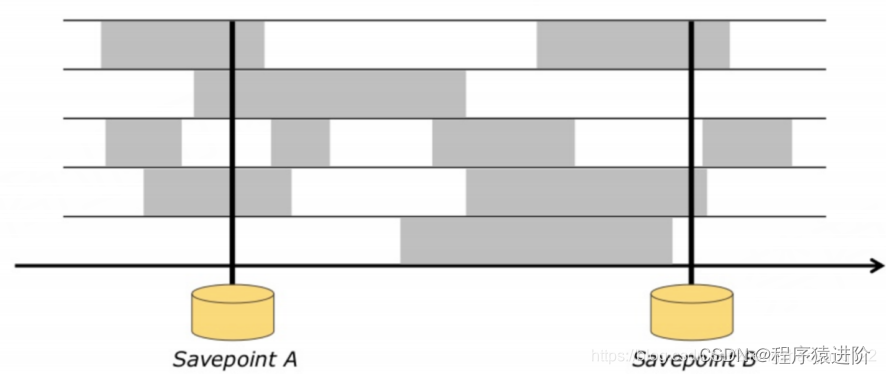
执行停止之前,产生一个保存点。就可以解决上面提到的3个问题。
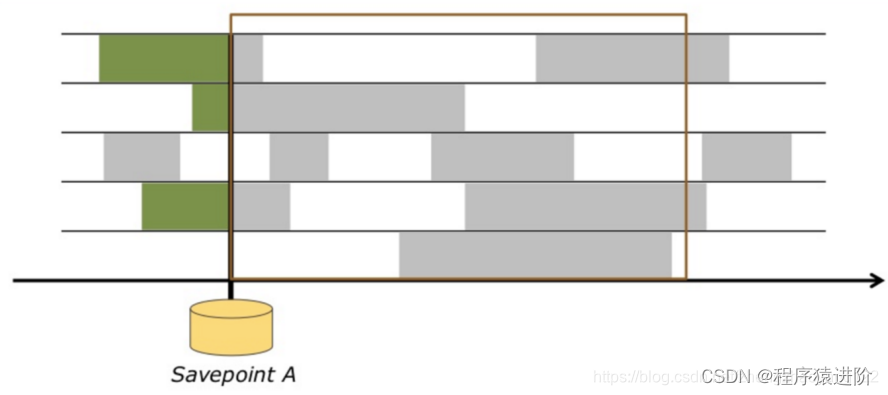
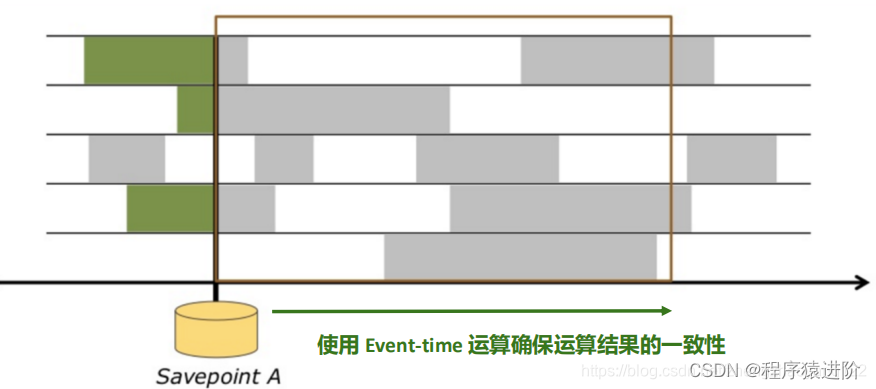
从保存点恢复新的执行,这个时候,例如我们重启花了30分钟,这段事件kafka还在不断的接收新的数据。恢复之后,Flink就需要从当时记录的kafka位置赶上最新的位置。这个时候利用Event-Time处理新的数据都是事件发生时的数据,这个时候再跟程序执行的时间比较就更能体现Event-time的价值。
相关文章:
Flink 有状态流式处理
传统批次处理方法 【1】持续收取数据(kafka等),以window时间作为划分,划分一个一个的批次档案(按照时间或者大小等); 【2】周期性执行批次运算(Spark/Stom等);…...

LeetCode //C - 1071. Greatest Common Divisor of Strings
1071. Greatest Common Divisor of Strings For two strings s and t, we say “t divides s” if and only if s t … t (i.e., t is concatenated with itself one or more times). Given two strings str1 and str2, return the largest string x such that x divides …...
智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.群居蜘蛛算法4.实验参数设定5.算法结果6.…...

AtCoder Beginner Contest 332
E - Lucky bag(简单状态压缩dp) 题目链接 题意:给你n个物品,m个福袋,让你将这n个物品用m个福袋打包(福袋可以为空),让分完之后的总方差最小,输出最小方差。 思路:其实由题目的数据…...

华为OD试题二(文件目录大小、相对开音节、找最小数)
1. 文件目录大小 题目描述: 一个文件目录的数据格式为:目录id,本目录中文件大小,(子目录id 列表)。其中目录id全局唯一,取值范围[1,200],本目录中文件大小范 围[1,1000],子目录id列表个数[0,10…...
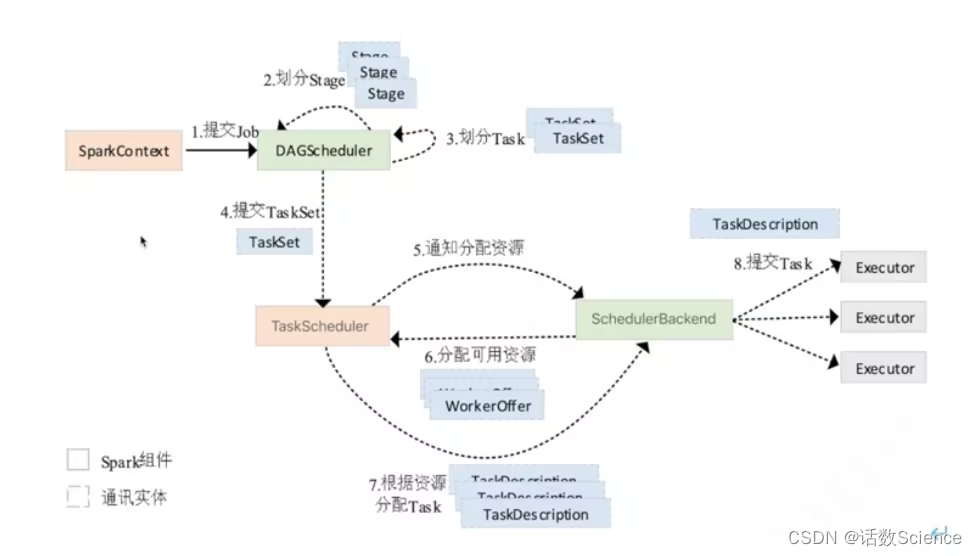
【Spark精讲】Spark作业执行原理
基本流程 用户编写的Spark应用程序最开始都要初始化SparkContext。 用户编写的应用程序中,每执行一个action操作,就会触发一个job的执行,一个应用程序中可能会生成多个job执行。一个job如果存在宽依赖,会将shuffle前后划分成两个…...
Docker容器:Centos7搭建Docker镜像私服harbor
目录 1、安装docker 1.1、前置条件 1.2、查看当前操作系统的内核版本 1.3、卸载旧版本(可选) 1.4、安装需要的软件包 1.5、设置yum安装源 1.6、查看docker可用版本 1.7、安装docker 1.8、开启docker服务 1.9、安装阿里云镜像加速器 1.10、设置docker开机自启 2、安…...

ClickHouse安装和部署
ClickHouse安装过程: ClickHouse支持运行在主流64位CPU架构(X86、AArch和PowerPC)的Linux操作 系统之上,可以通过源码编译、预编译压缩包、Docker镜像和RPM等多种方法进行安装。由于篇幅有限,本节着重讲解离线RPM的安…...

Spring Cloud Gateway中对admin端点进行认证
前言 我们被扫了一个漏洞,SpringBoot Actuator 未授权访问,漏洞描述是这样的: Actuator 是 springboot 提供的用来对应用系统进行自省和监控的功能模块,借助于 Actuator 开发者可以很方便地对应用系统某些监控指标进行查看、统计…...

2. 如何通过公网IP端口映射访问到设备的vmware虚拟机的ubuntu服务器
文章目录 1. 主机设备是Windows 11系统2. 安装vmware虚拟机3. 创建ubuntu虚拟机(据说CentOS 7 明年就不维护了,就不用这个版本的linux了)4. 安装nginx服务:默认端口805. 安装ssh服务:默认端口226. 设置主机 -> ubuntu的端口映射7. 设置路由…...
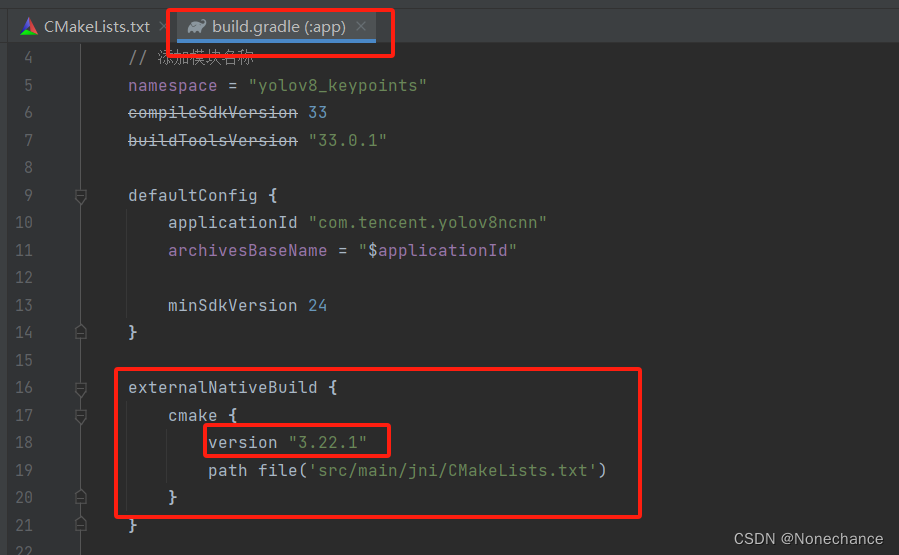
配置android sudio出现的错误
导入demo工程,配置过程参考: AndroidStudio导入项目的正确方式,修改gradle配置 错误:Namespace not specified. Specify a namespace in the module’s build file. 并定位在下图位置: 原因:Android 大括号…...

【初阶C++】前言
C前言 1. 什么是C2. C发展史3. C的重要性4. 如何学习C 1. 什么是C C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, …...
MAC IDEA Maven Springboot
在mac中,使用idea进行maven项目构建 环境配置如何运行maven项目1.直接在IDEA中运行2.使用jar打包后执行 如何搭建spring boot1.添加依赖2.创建入口类3.创建控制器4. 运行5.其他 环境配置 官网安装IDEA使用IDEA的创建新项目选择创建MAEVEN项目测试IDEA的MAVEN路径是…...

Angular13无法在浏览器debug
前言 本文将介绍如何解决在Angular 13中无法在浏览器中进行调试的问题,并提供了一种解决方法。 发生场景 根据项目需求,升级至Angular 13后,发现无法在浏览器中进行调试。 问题原因 无法进行调试的原因是,当使用Angular 13的…...
:视频编码的演进)
H.264与H.265(HEVC):视频编码的演进
目录 H.264的发展历程 1. 标准发布 2. 广泛应用 3. 专业化应用 H.265的出现...
Python从入门到精通九:Python异常、模块与包
了解异常 什么是异常 当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG bug单词的诞生 早期计算机采用大量继电器工作,马克二型计算机就是这样的。 19…...
无需公网IP联机Minecraft,我的世界服务器本地搭建教程
目录 前言 1.Mcsmanager安装 2.创建Minecraft服务器 3.本地测试联机 4. 内网穿透 4.1 安装cpolar内网穿透 4.2 创建隧道映射内网端口 5.远程联机测试 6. 配置固定远程联机端口地址 6.1 保留一个固定TCP地址 6.2 配置固定TCP地址 7. 使用固定公网地址远程联机 8.总…...
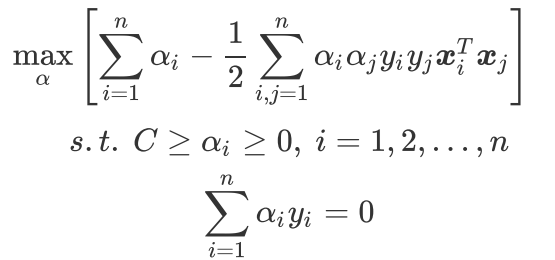
机器学习-SVM(支持向量机)
推荐课程:【机器学习实战】第5期 支持向量机 |数据分析|机器学习|算法|菊安酱_哔哩哔哩_bilibili 赞美菊神ヾ ( ゜ⅴ゜)ノ 一、什么是支持向量机? 支持向量机(Support Vector Machine, SVM)是一类按监督学习࿰…...
保姆级:Windows Server 2012上安装.NET Framework 3.5
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Windows》。🎯🎯 🚀无论你是编程小白,还是有…...
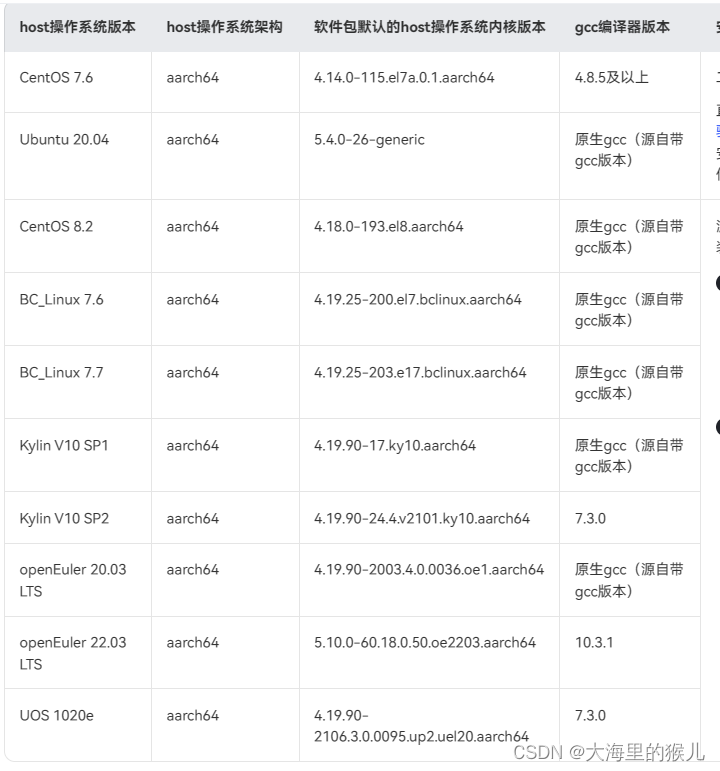
昇腾910安装驱动出错,降低Centos7.6的内核版本
零、问题描述: 在安装Atlas800-9000服务器的驱动的时候,可能会出现错误:Dkms install failed, details in : /var/log/ascend_seclog/ascend_install.log 如下所示: [rootlocalhost ~]# ./Ascend-hdk-910-npu-driver_23.0.rc3_l…...

operation backup
operation & backup 运维备份(多地)...
)
【独家逆向分析】:Perplexity招聘页埋点数据如何被提取?附Python自动化脚本(限24小时领取)
更多请点击: https://kaifayun.com 第一章:Perplexity薪资数据查询 Perplexity 作为一家以 AI 原生搜索和研究工具著称的科技公司,其薪酬结构长期未公开披露,但可通过多源交叉验证方式获取合理估算。目前主流可信渠道包括 Levels…...

Windows终极HEIC预览方案:免费解锁苹果照片缩略图
Windows终极HEIC预览方案:免费解锁苹果照片缩略图 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPhone拍摄的…...

【最新v2.7.5 版本安装包】OpenClaw 2.7.5 保姆级教程,零基础无需命令一键部署不踩坑
🚀 OpenClaw 一键安装包|一键部署甩掉复杂环境配置 【点击下载最新安装包】https://xiake.yun/api/download/package/16?promoCodeIVBE1F235167 📌 适配信息 适配系统:Windows10/11 64 位 当前版本:v2.7.5ÿ…...

手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量
手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量 在射频和微波测试领域,网络分析仪是工程师不可或缺的工具,而E5071C作为一款经典的中端矢量网络分析仪,广泛应用于通信、雷达、天线等领域的研发和测试。对于刚接触这款设备的新手工…...

产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则
产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则 在互联网产品的世界里,每天都有无数场看不见的博弈正在上演——司机与乘客的匹配、商家与消费者的互动、创作者与平台的共生。这些看似复杂的商业行为背后,往往遵循着…...

Vue3后台管理系统终极指南:V3 Admin Vite 5.0全面解析
Vue3后台管理系统终极指南:V3 Admin Vite 5.0全面解析 【免费下载链接】v3-admin-vite ☀️ A crafted Vue3 admin template | Vue Admin | Vue Template | Vue3 Admin | Vue3 Template | Vue 后台 | Vue 模板 | Vue3 后台 | Vue3 模板 项目地址: https://gitcode…...

Auto Edit 日常迭代踩坑实录:OpenAI Codex CLI 三种权限模式配置差异与 2 类高频报错修复
1. Auto Edit 模式不是“全自动”,而是最易失控的权限模式 大多数人第一次在项目里启用 codex cli --mode=auto-edit,是冲着“自动改代码”去的。我也是。直到某天凌晨两点,CI 流水线突然报出 17 个 test failure,而 git diff 显示——它把一个 if (user.role === admin) …...

深入SmoothL1Loss:从Faster R-CNN到YOLO,看一个损失函数如何影响模型精度
深入解析SmoothL1Loss:目标检测模型中的边框回归利器 在目标检测领域,边框回归(Bounding Box Regression)是决定模型定位精度的关键环节。当我们翻阅Faster R-CNN、YOLOv3等经典模型的源码时,会发现一个反复出现的损失…...

Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时
更多请点击: https://codechina.net 第一章:Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时 Perplexity AI 技术团队于 2024 年 6 月 18 日凌晨通过后台策略悄然撤销了所有第三方 Ch…...