『 MySQL数据库 』聚合统计
文章目录
- 前言 🥑
- 🥝 聚合函数
- 🍓 COUNT( ) 查询数据数量
- 🍓 SUM( ) 查询数据总和
- 🍓 AVG( ) 查询数据平均值
- 🍓 MAX( ) 查询数据最大值
- 🍓 MIN( ) 查询数据最小值
- 🥝 数据分组GROUP BY子句
- 🍓 GROUP BY示例
- 🍓 HAVING语句
前言 🥑

在MySQL中存在一种查询方式叫做聚合查询;
聚合查询顾名思义就是将一组数据的同种类型进行聚合,那么既然是一组同类型的数据那么即必须要对该数据进行分组同时再对这组数据进行聚合;
所以对于聚合查询来说时应该有两部分组合:
- 将数据进行分组;
- 将数据进行聚合统计;
需要配合SELECT语句进行使用;
🥝 聚合函数

在MySQL中存在一些高频操作:查询数量个数,查询数据总和…
而在MySQL中存在着一些函数,这些函数即用来对表内数据进行这些比较高频的操作,这些函数叫做聚合函数,当然这些函数存在的意义也是聚合查询中的重要操作;
存在一张表(Point):
+----+---------+---------+------+---------+
| id | name | chinese | math | english |
+----+---------+---------+------+---------+
| 1 | Lihua | 100 | 118 | 180 |
| 2 | Liming | 57 | 58 | 140 |
| 3 | Zhaolao | 66 | 80 | 94 |
| 4 | Wu | 76 | 70 | 94 |
| 5 | Wuqi | 88 | 43 | 160 |
| 6 | Liqiang | 89 | 122 | 180 |
| 7 | Qinsu | 90 | 104 | 134 |
| 8 | Zhaoli | 54 | 74 | 200 |
+----+---------+---------+------+---------+
🍓 COUNT( ) 查询数据数量
语法:
COUNT([DISTINCT] expr)
-- 返回查询到的数据的数量
-- 其中[]内为可选项
该函数能查询对应数据的数量;
- 示例1:查询该表中人数个数:
mysql> select count(*) from Point; +----------+ | count(*) | +----------+ | 8 | +----------+ 1 row in set (0.00 sec)
- 示例2:查询该表中
math字段数据>100的个数:mysql> select count(math) from Point where math>100; +-------------+ | count(math) | +-------------+ | 3 | +-------------+ 1 row in set (0.00 sec)
- 示例3:查询该表中
english字段数据个数mysql> select count(distinct english) from Point; -- 利用distinct进行去重 +-------------------------+ | count(distinct english) | +-------------------------+ | 6 | +-------------------------+ 1 row in set (0.00 sec)
🍓 SUM( ) 查询数据总和
语法:
COUNT([DISTINCT] expr)
该函数能够算出一组数据的总和;
- 示例:计算出
english字段所有数据的总和:mysql> select sum(english) from Point; +--------------+ | sum(english) | +--------------+ | 1182 | +--------------+ 1 row in set (0.00 sec)mysql> select sum(distinct english) from Point; +-----------------------+ | sum(distinct english) | +-----------------------+ | 908 | +-----------------------+ 1 row in set (0.00 sec)
🍓 AVG( ) 查询数据平均值
语法:
AVG([DISTINCT] expr)
该函数能够算出一组数据的平均值;
- 示例:计算出表中
english+math+chinese字段的平均值:mysql> select AVG(english+chinese+math) from Point; +---------------------------+ | AVG(english+chinese+math) | +---------------------------+ | 308.8750 | +---------------------------+ 1 row in set (0.00 sec)
🍓 MAX( ) 查询数据最大值
语法:
MAX([DISTINCT] expr)
该函数能够算出一组数据的最大值;
- 示例:计算出表中
chinese字段的最大值:mysql> select max(chinese) from Point; +--------------+ | max(chinese) | +--------------+ | 100 | +--------------+ 1 row in set (0.00 sec)
🍓 MIN( ) 查询数据最小值
语法:
MIN([DISTINCT] expr)
该函数能够算出一组数据的最小值(用法与MAX()函数相同);
🥝 数据分组GROUP BY子句
聚合统计讲究的是一个先将数据进行分组在将数据进行聚合统计,在MySQL中可以使用GPOUP BY子句将数据进行分组;
在SELECT中使用GROUP BY子句对指定列进行分组查询;
语法:
SELECT column1 ,column2, ... FROM table_name GROUP BY column1,column2...;
在进行聚合查询的演示前需要准备一个来自Oralce 9i的测试用表 - 雇员表(该表在本篇博客中存在资源);
下载该表后使用
SOURCE /路径的方式将表至于MySQL当中;
该文件为一个数据库,库中共有三张表: dept部门表,emp员工表,salgrade工资等级表 ;
其中三张表的表结构分别为:
-
deptTable: dept Create Table: CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT ' 部门编号 ',`dname` varchar(14) DEFAULT NULL COMMENT ' 部门名称 ',`loc` varchar(13) DEFAULT NULL COMMENT ' 部门所在地点 ' ) ENGINE=MyISAM DEFAULT CHARSET=utf8
-
empTable: emp Create Table: CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号' ) ENGINE=MyISAM DEFAULT CHARSET=utf8
salgradeTable: salgrade Create Table: CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资' ) ENGINE=MyISAM DEFAULT CHARSET=utf8
该表的对应数据分别为:
############## 表dept ##############
mysql> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+############## 表emp ##############
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+############## 表salgrade ##############
mysql> select * from salgrade;
+-------+-------+-------+
| grade | losal | hisal |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
🍓 GROUP BY示例
-
显示每个部门的最高工资与平均工资:
该在示例中需要显示每个每个部门的最高工资,说明需要将 每个部分进行分组, 即
GROUP BY deptno;
同时要求计算出每个部门的最高工资与最低工资,说明需要对每个部门进行聚合统计,即MAX(sal)与AVG(sal);
将其组合即为:select max(sal),avg(sal) from emp group by deptno;由于是以
deptno进行分组,所以可以SELECT出分组的名;
即:mysql> select deptno,max(sal),avg(sal) from emp group by deptno; +--------+----------+-------------+ | deptno | max(sal) | avg(sal) | +--------+----------+-------------+ | 10 | 5000.00 | 2916.666667 | | 20 | 3000.00 | 2175.000000 | | 30 | 2850.00 | 1566.666667 | +--------+----------+-------------+
-
显示每个部门的每种岗位的平均工资与最低工资:
在该示例中需要显示每个部门与每种岗位,说明该示例中需要对数据进行两类分组,即为
GROUP BY deptno , job;
且需要聚合统计出该类数据的平均值与最高值,即为AVG(sal)与MIN(sal);
在该条件中由于是对部门deptno与岗位job进行分组,所以在SELECT时可以分别显示出他们的值;
即为:mysql> SELECT deptno,job,avg(sal),min(sal) from emp group by deptno,job; +--------+-----------+-------------+----------+ | deptno | job | avg(sal) | min(sal) | +--------+-----------+-------------+----------+ | 10 | CLERK | 1300.000000 | 1300.00 | | 10 | MANAGER | 2450.000000 | 2450.00 | | 10 | PRESIDENT | 5000.000000 | 5000.00 | | 20 | ANALYST | 3000.000000 | 3000.00 | | 20 | CLERK | 950.000000 | 800.00 | | 20 | MANAGER | 2975.000000 | 2975.00 | | 30 | CLERK | 950.000000 | 950.00 | | 30 | MANAGER | 2850.000000 | 2850.00 | | 30 | SALESMAN | 1400.000000 | 1250.00 | +--------+-----------+-------------+----------+ 9 rows in set (0.00 sec)# 也可将其进行重命名 mysql> SELECT deptno 部门,job 岗位,avg(sal) 最大工资,min(sal) 最小工资 from emp group by deptno,job; +--------+-----------+--------------+--------------+ | 部门 | 岗位 | 最大工资 | 最小工资 | +--------+-----------+--------------+--------------+ | 10 | CLERK | 1300.000000 | 1300.00 | | 10 | MANAGER | 2450.000000 | 2450.00 | | 10 | PRESIDENT | 5000.000000 | 5000.00 | | 20 | ANALYST | 3000.000000 | 3000.00 | | 20 | CLERK | 950.000000 | 800.00 | | 20 | MANAGER | 2975.000000 | 2975.00 | | 30 | CLERK | 950.000000 | 950.00 | | 30 | MANAGER | 2850.000000 | 2850.00 | | 30 | SALESMAN | 1400.000000 | 1250.00 | +--------+-----------+--------------+--------------+ 9 rows in set (0.00 sec)
🍓 HAVING语句
HAVING语句为条件筛选语句的一种,其使用方式类似于WHERE;
大部分情况下HAVING子句是用来配合GROUP BY语句进行使用,即对分组聚合后的数据进行筛选;
HAVING子句可以做到与WHERE子句一样的事,但是WHERE子句的功能却不能与HAVING子句相当;
由于HAVING语句是用来针对聚合统计而产生的,所以在MySQL中不能使用HAVING子句来代替WHERE子句,即这两个语句不能混为一谈;
-
示例:显示平均工资低于2000的部门和它的平均工资:
在该示例中要求了
平均工资低于2000的部门,即需要对部门进行GROUP BY分类,即GROUP BY deptno;
同时示例要求显示平均工资,即为AVG(sal);
将其组合在一起即能显示出各个部门的平均工资:mysql> select deptno,avg(sal) from emp group by deptno; +--------+-------------+ | deptno | avg(sal) | +--------+-------------+ | 10 | 2916.666667 | | 20 | 2175.000000 | | 30 | 1566.666667 | +--------+-------------+ 3 rows in set (0.00 sec)其又要求显示平均工资低于2000的部门与它的平均工资,则可以使用
HAVING子句对聚合统计后的数据进行筛选;mysql> select deptno as 部门,avg(sal) as 平均工资 from emp group by deptno having 平均工资<2000; +--------+--------------+ | 部门 | 平均工资 | +--------+--------------+ | 30 | 1566.666667 | +--------+--------------+ 1 row in set (0.00 sec)##当使用where子句代替having子句时将会报错; mysql> select deptno as 部门,avg(sal) as 平均工资 from emp group by deptno where 平均工资<2000; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'where 平均工资<2000' at line 1
相关文章:
『 MySQL数据库 』聚合统计
文章目录 前言 🥑🥝 聚合函数🍓 COUNT( ) 查询数据数量🍓 SUM( ) 查询数据总和🍓 AVG( ) 查询数据平均值🍓 MAX( ) 查询数据最大值🍓 MIN( ) 查询数据最小值 🥝 数据分组GROUP BY子句…...

Redis - 事务隔离机制
Redis 的事务的本质是 一组命令的批处理 。这组命令在执行过程中会被顺序地、一次性 全部执行完毕,只要没有出现语法错误,这组命令在执行期间是不会被中断。 当事务中的命令出现语法错误时,整个事务在 exec 执行时会被取消。 如果事务中的…...

android项目实战之编辑器图片上传预览
现状分析 项目的需求用到编辑器,编辑器中又可能用到图片上传功能。 实现方案 1. 增加依赖库,可以参考前面的几篇文章,都有描述。 2. 核心代码实现 PictureSelector.create(GoodItemContentFragment.this) .openGallery(SelectMimeType.…...
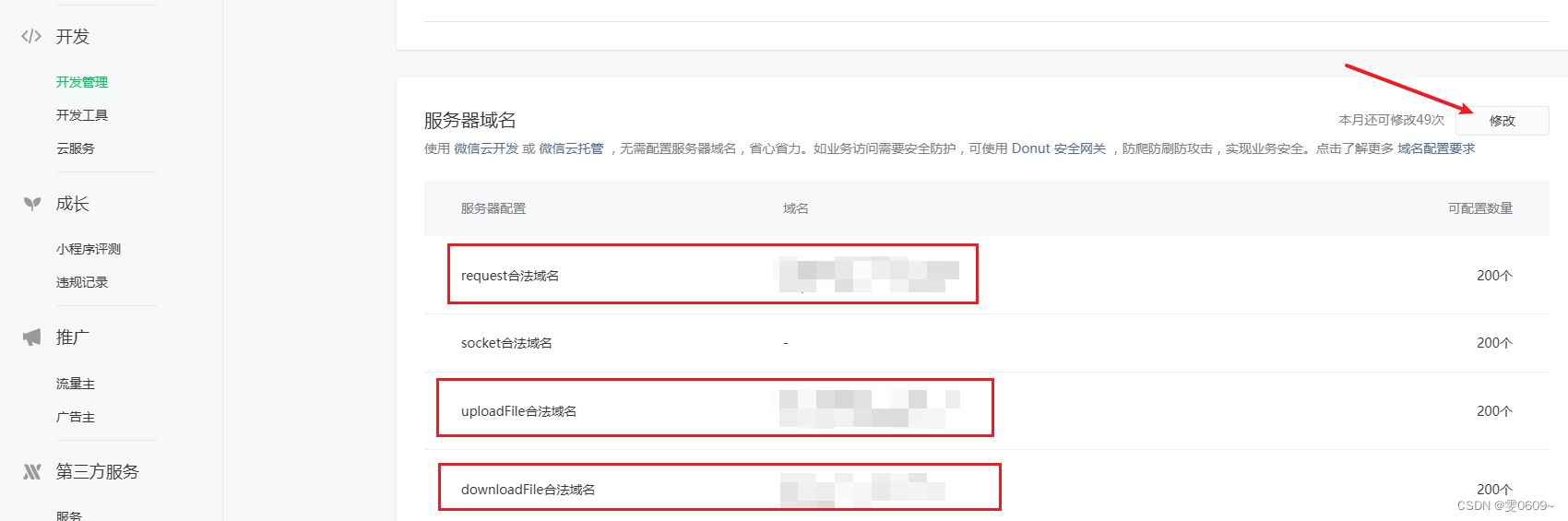
微信小程序:上传图片到别的域名文件下
效果 wxml <!-- 上传照片 --> <view class"addbtn"><view classpic name"fault_photo" wx:for"{{imgs}}" wx:for-item"item" wx:key"*this"><image classweui-uploader_img src"{{item}}"…...

Linux----内核及发行版
1. Linux内核 Linux内核是操作系统内部操作和控制硬件设备的核心程序,它是由芬兰人林纳斯开发的。 内核效果图: 说明: 真正操作和控制硬件是由内核来完成的,操作系统是基于内核开发出来的。 2. Linux发行版 是Linux内核与各种常用软件的组合产品&am…...
设备制造行业CRM:提升客户满意度,驱动业务增长
设备制造行业客户需求多样化、服务链路长,企业在关注APS、EMS等工业软件之余还要以客户为中心,做好客户服务。设备制造行业CRM管理系统是企业管理客户关系的利器,设备制造行业CRM的作用有哪些?一文带您看懂。 设备制造行业需要解…...

JavaScript实现复制功能函数
function copyUrl() {var copyText document.getElementById("url");copyText.select();document.execCommand("copy"); }其中,copyUrl()函数用于复制,document.getElementById(“url”)用于获取链接的DOM元素,select()…...
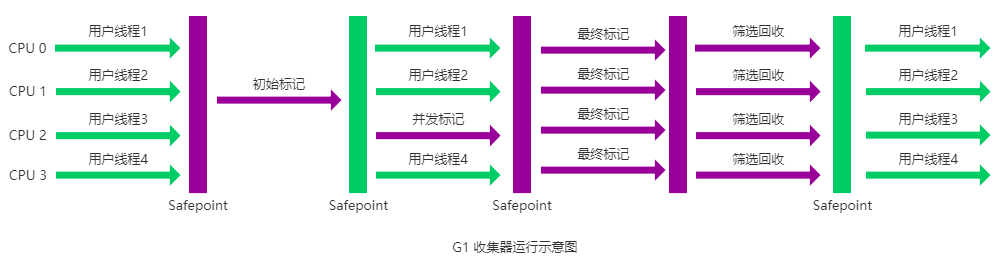
JVM垃圾收集器
主要垃圾收集器如下,图中标出了它们的工作区域、垃圾收集算法,以及配合关系。 HotSpot虚拟机垃圾收集器 这些收集器里,面试的重点是两个——CMS和G1。 Serial 收集器 Serial(串行)收集器是最基本、历史最悠久的垃圾…...
LeetCode(58)随机链表的复制【链表】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 随机链表的复制 1.题目 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节…...

JVM源码剖析之registerNatives方法
目录 版本信息: 写在前面: 源码论证: 总结: 版本信息: jdk版本:jdk8u40 写在前面: 在Java类库中很多类都有一个registerNatives的native方法,并且写在static静态代码块中进行初…...
HarmonyOS鸿蒙应用开发——数据持久化Preferences
文章目录 数据持久化简述基本使用与封装测试用例参考 数据持久化简述 数据持久化就是将内存数据通过文件或者数据库的方式保存到设备中。HarmonyOS提供两两种持久化方案: Preferences:主要用于保存一些配置信息,是通过文本的形式存储的&…...
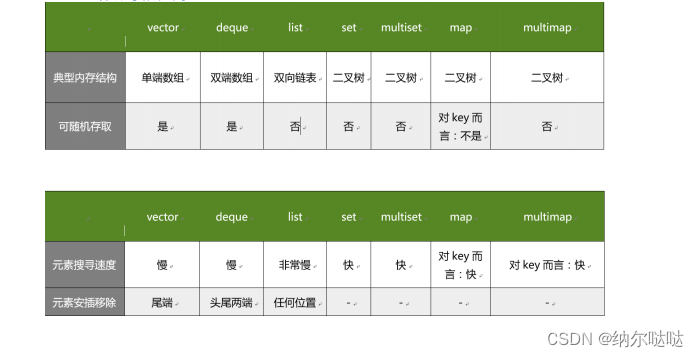
C++STL库的 deque、stack、queue、list、set/multiset、map/multimap
deque 容器 Vector 容器是单向开口的连续内存空间, deque 则是一种双向开口的连续线性空 间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作,当然, vector 容器也可以在头尾两端插入元素,但是在其…...

Vuex快速上手
一、Vuex 概述 目标:明确Vuex是什么,应用场景以及优势 1.是什么 Vuex 是一个 Vue 的 状态管理工具,状态就是数据。 大白话:Vuex 是一个插件,可以帮我们管理 Vue 通用的数据 (多组件共享的数据)。例如:购…...

计网 - LVS 是如何直接基于 IP 层进行负载平衡调度
文章目录 模型LVS的工作机制初探LVS的负载均衡机制初探 模型 大致来说,可以这么理解(只是帮助我们理解,实际上肯定会有点出入),对于我们的 PC 机来说,物理层可以看成网卡,数据链路层可以看成网卡…...

GEE机器学习——利用支持向量机SVM进行土地分类和精度评定
支持向量机方法 支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,主要用于分类和回归问题。SVM的目标是找到一个最优的超平面,将不同类别的样本点分隔开来,使得两个类别的间隔最大化。具体来说,SVM通过寻找支持向量(即距离超平面最近的样本点),确定…...

【ARM Trace32(劳特巴赫) 使用介绍 13 -- Trace32 断点 Break 命令篇】
文章目录 1. Break.Set1.1 TRACE32 Break1.1.1 Break命令控制CPU的暂停1.2 Break.Set 设置断点1.2.1 Trace32 程序断点1.2.2 读写断点1.2.2.1 变量被改写为特定值触发halt1.2.2.2 设定非值触发halt1.2.2.4 变量被特定函数改写触发halt1.2.3 使用C/C++语法设置断点条件1.2.4 使用…...
【JVM入门到实战】(三) 查看字节码文件的工具
一、 javap -v命令 javap是JDK自带的反编译工具,可以通过控制台查看字节码文件的内容。适合在服务器上查看字节码文件内容。直接输入javap查看所有参数。输入javap -v 字节码文件名称 查看具体的字节码信息。(如果jar包需要先使用 jar –xvf 命令解压&a…...
9:00面试,9:05就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到12月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40…...
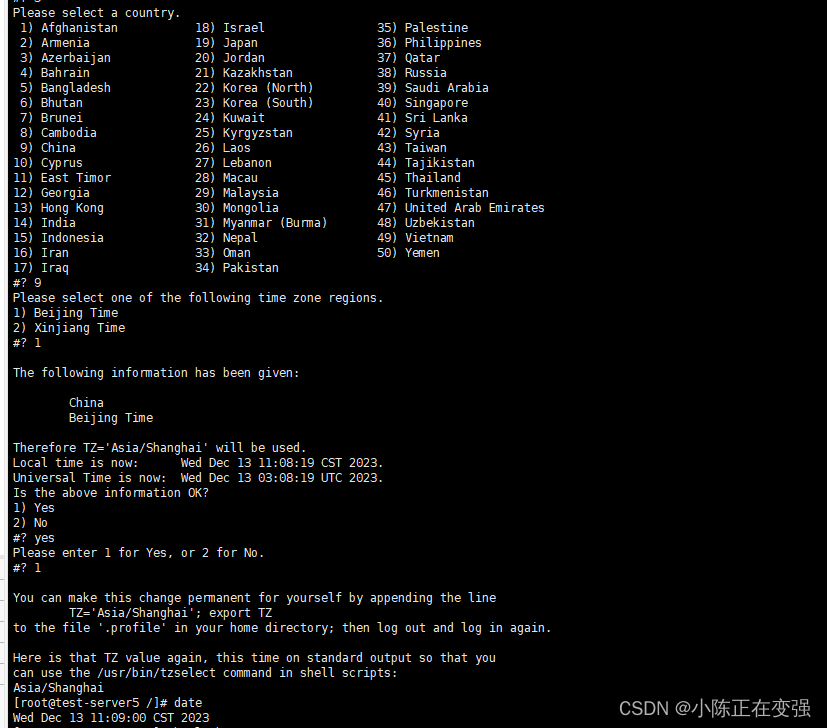
无需重启,修改Linux服务器时区
Linux修改服务器时区(无需重启) 1、复制命令:2、使用tzselect命令:3、使用date查看是否修改正确 1、复制命令: cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime2、使用tzselect命令: tzselect按照要…...

【Android嵌入式开发及实训课程实验】【项目1】 图形界面——计算器项目
【项目1】 图形界面——计算器项目 需求分析界面设计实施1、创建项目2、 界面实现实现代码1.activity_main.xml2.Java代码 - MainActivity.java 3、运行测试 注意点结束~ 需求分析 开发一个简单的计算器项目,该程序只能进行加减乘除运算。要求界面美观,…...

嵌入式ADC性能评估:CDBCAPTURE系统改造与实战调试指南
1. 项目概述:CDBCAPTURE系统与嵌入式ADC性能评估在嵌入式系统开发,尤其是涉及模拟信号采集的领域,工程师们常常面临一个核心挑战:如何准确、高效地评估模数转换器(ADC)在真实系统环境下的性能?是…...

从OpenMV2到4代,我踩过的那些坑:画面变绿、传感器接触不良与内存擦除的避坑实录
从OpenMV2到4代:硬件升级中的稳定性挑战与实战解决方案 作为一名长期使用OpenMV系列开发视觉项目的工程师,我从OpenMV2一路升级到4代,见证了硬件性能的飞跃,也深刻体会到稳定性问题带来的困扰。其中最令人头疼的莫过于"画面变…...

如何在Windows电脑上直接运行安卓应用:APK安装器终极解决方案
如何在Windows电脑上直接运行安卓应用:APK安装器终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运行安卓应…...

KMS_VL_ALL_AIO:一站式智能激活工具,彻底解决Windows与Office激活难题
KMS_VL_ALL_AIO:一站式智能激活工具,彻底解决Windows与Office激活难题 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款开源的智能激活脚本ÿ…...

探索中医数字化:基于深度学习的舌苔检测项目推荐
探索中医数字化:基于深度学习的舌苔检测项目推荐 【下载地址】基于深度学习的舌苔检测毕设留档 本项目是针对中医领域中舌象分析的一项研究,通过应用深度学习技术来实现自动的舌苔检测。随着人工智能在医疗健康领域的深入发展,利用计算机视觉…...

量子安全与后量子密码学:awesome-quantum-software中的加密工具
量子安全与后量子密码学:awesome-quantum-software中的加密工具 【免费下载链接】awesome-quantum-software Curated list of open-source quantum software projects. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-quantum-software 在后量子计算时…...

Sparrow比特币钱包:终极桌面安全钱包完全指南
Sparrow比特币钱包:终极桌面安全钱包完全指南 【免费下载链接】sparrow Desktop Bitcoin Wallet focused on security and privacy. Free and open source. 项目地址: https://gitcode.com/gh_mirrors/sparr/sparrow Sparrow比特币钱包是一款专注于安全与隐私…...

基于Arduino与VS1053的宠物智能服装DIY:嵌入式系统集成实践
1. 项目概述与核心思路给宠物做一件会发光、会发声的智能服装,听起来像是科幻电影里的情节,但用今天触手可及的硬件和开源工具,这完全是一个可以亲手实现的周末项目。这个项目的核心,是将一个微小的“智能大脑”和一套声光系统&am…...

ASML财报解析:EUV光刻机如何驱动半导体产业高增长
1. 财报数据深度拆解:高毛利与利润倍增的背后ASML刚刚发布的第二季度财报,无疑是全球半导体产业的一剂强心针。当看到毛利率稳稳站在50%以上,每股净利润几乎翻倍增长时,我第一反应不是惊讶,而是“果然如此”。这组数据…...

抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案
抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...