kyuubi整合flink yarn application model
目录
- 概述
- 配置
- flink 配置
- kyuubi 配置
- kyuubi-defaults.conf
- kyuubi-env.sh
- hive
- 验证
- 启动kyuubi
- beeline 连接
- 使用hive catalog
- sql测试
- 结束
概述
flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5
整合过程中,需要注意对应的版本。
注意以上版本

姊妹篇 kyuubi yarn session model 整合链接在此
配置
kyuubi flink yarn application mode 官网文档
flink 配置
#jobManager 的 IP 地址
jobmanager.rpc.address: localhost#jobManager 的端口,默认为 6123
jobmanager.rpc.port: 6123#jobManager 的 JVM heap 大小,生产环境4G起步
jobmanager.heap.size: 1600m#taskManager 的 jvm heap 大小设置,低于 1024M 不能启动
taskmanager.memory.process.size: 8094m
taskmanager.memory.managed.size: 64m#taskManager 中 taskSlots 个数,最好设置成 work 节点的 CPU 个数相等
taskmanager.numberOfTaskSlots: 2#taskmanager 是否启动时管理所有的内存
taskmanager.memory.preallocate: false#并行计算数
parallelism.default: 2#控制类加载策略,可选项有 child-first(默认)和 parent-first
classloader.resolve-order: parent-first
classloader.check-leaked-classloader: falsestate.backend.incremental: true
state.backend: rocksdb
execution.checkpointing.interval: 300000
state.checkpoints.dir: hdfs://ks2p-hadoop01:9000/dinky-ckps
state.savepoints.dir: hdfs://ks2p-hadoop01:9000/dinky-savepoints
heartbeat.timeout: 180000
akka.ask.timeout: 60s
web.timeout: 5000
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
kyuubi 配置
- 官网下载:https://kyuubi.apache.org/releases.html
- kyuubi conf下三个配置文件去 template后缀
- 配置 kyuubi-defaults.conf、kyuubi-env.sh
kyuubi-defaults.conf
此处配置引擎类型, flink 的模式,这两个重要的。
kyuubi.engine.type FLINK_SQL
flink.execution.target yarn-application
kyuubi.ha.namespace kyuubi
kyuubi-env.sh
没有采用 hadoop 集群默认的配置,java 及 flink 使用的都是定制的版本。
export JAVA_HOME=/data/jdk-11.0.20
export FLINK_HOME=/data/soft/flink-1.17.1
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
export FLINK_HADOOP_CLASSPATH=${HADOOP_HOME}/share/hadoop/client/hadoop-client-runtime-3.2.4.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-api-3.2.4.jar
hive
生产上 paimon 的 catlog 信息是 hive 存储的。
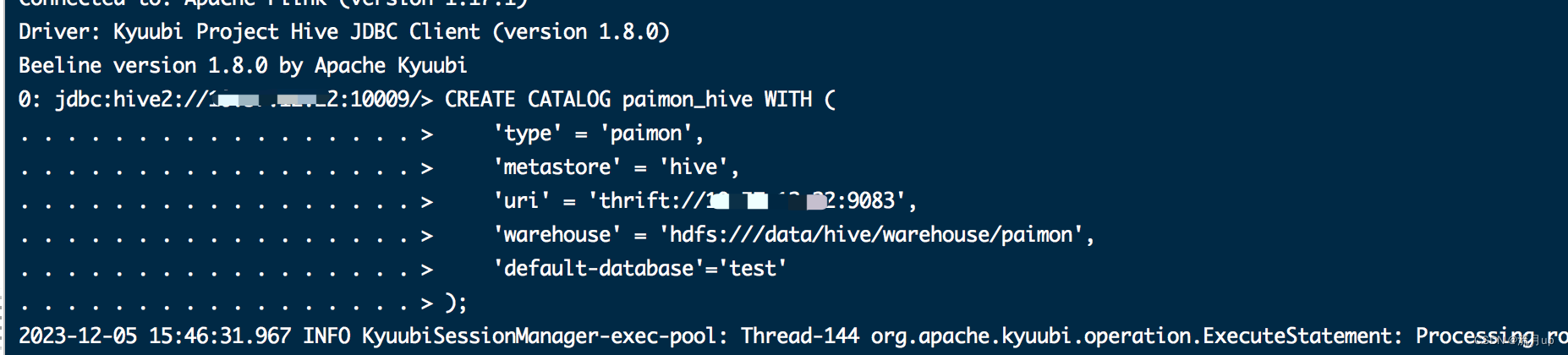
CREATE CATALOG paimon_hive WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://10.xx.xx.22:9083','warehouse' = 'hdfs:///data/hive/warehouse/paimon','default-database'='test'
);USE CATALOG paimon_hive;
验证
**注意:**下面启动相应的组件,进行相关的验证。
启动kyuubi

验证一下正常启动如下:
[root@ksxx-hadoop06 apache-kyuubi-1.8.0-bin]# netstat -nlp | grep :10009
tcp 0 0 10.xx.xx.22:10009 0.0.0.0:* LISTEN 218311/java
beeline 连接
[root@ks2p-hadoop06 apache-kyuubi-1.8.0-bin]# bin/beeline -u 'jdbc:hive2://10.xx.xx.22:10009/' -n tableau
Connecting to jdbc:hive2://10.xx.xx.22:10009/
2023-12-06 10:55:48.247 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.operation.LaunchEngine: Processing tableau's query[6bab2d9e-c7f5-4438-bcd7-8f1e2fd98020]: PENDING_STATE -> RUNNING_STATE, statement:
LaunchEngine
2023-12-06 10:55:48.279 WARN KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.shaded.curator.utils.ZKPaths: The version of ZooKeeper being used doesn't support Container nodes. CreateMode.PERSISTENT will be used instead.
2023-12-06 10:55:48.304 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.ProcBuilder: Creating tableau's working directory at /data/soft/apache-kyuubi-1.8.0-bin/work/tableau
2023-12-06 10:55:48.317 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.EngineRef: Launching engine:
/data/soft/flink-1.17.1/bin/flink run-application -t yarn-application -Dyarn.ship-files=/data/soft/flink-1.17.1/opt/flink-sql-client-1.17.1.jar;/data/soft/flink-1.17.1/opt/flink-sql-gateway-1.17.1.jar -Dyarn.application.name=kyuubi_USER_FLINK_SQL_tableau_default_e29cfc98-f864-4bb9-a430-2d3eceeeac24 -Dyarn.tags=KYUUBI,e29cfc98-f864-4bb9-a430-2d3eceeeac24 -Dcontainerized.master.env.FLINK_CONF_DIR=. -Dexecution.target=yarn-application -c org.apache.kyuubi.engine.flink.FlinkSQLEngine /data/soft/apache-kyuubi-1.8.0-bin/externals/engines/flink/kyuubi-flink-sql-engine_2.12-1.8.0.jar \--conf kyuubi.session.user=tableau \--conf kyuubi.client.ipAddress=10.xx.xx.22 \--conf kyuubi.client.version=1.8.0 \--conf kyuubi.engine.submit.time=1701831348298 \--conf kyuubi.engine.type=FLINK_SQL \--conf kyuubi.ha.addresses=10.xx.xx.22:2181 \--conf kyuubi.ha.engine.ref.id=e29cfc98-f864-4bb9-a430-2d3eceeeac24 \--conf kyuubi.ha.namespace=/kyuubi_1.8.0_USER_FLINK_SQL/tableau/default \--conf kyuubi.ha.zookeeper.auth.type=NONE \--conf kyuubi.server.ipAddress=10.xx.xx.22 \--conf kyuubi.session.connection.url=ks2p-hadoop06:10009 \--conf kyuubi.session.real.user=tableau
2023-12-06 10:55:48.321 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.ProcBuilder: Logging to /data/soft/apache-kyuubi-1.8.0-bin/work/tableau/kyuubi-flink-sql-engine.log.02023-12-06 10:55:59,647 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2023-12-06 10:55:59,648 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface ks2p-hadoop06:1655 of application 'application_1694575187997_0427'.
Connected to: Apache Flink (version 1.17.1)
Driver: Kyuubi Project Hive JDBC Client (version 1.8.0)
Beeline version 1.8.0 by Apache Kyuubi
0: jdbc:hive2://10.xx.xx.22:10009/>
使用hive catalog
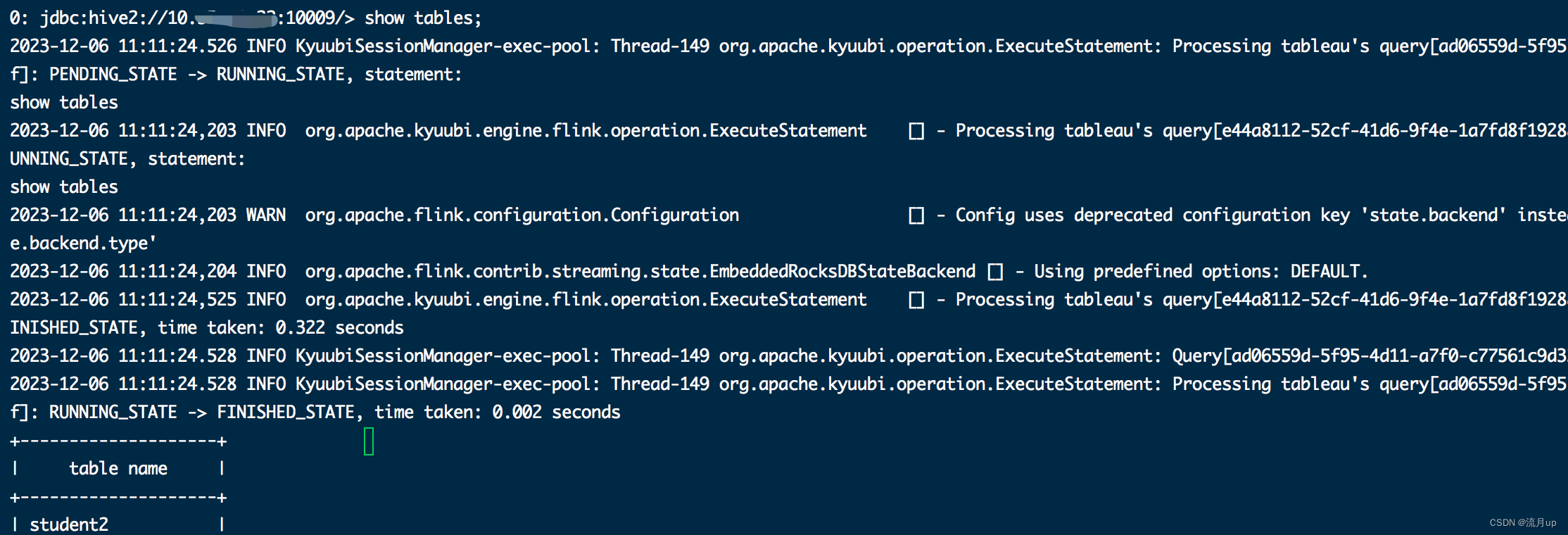
sql测试
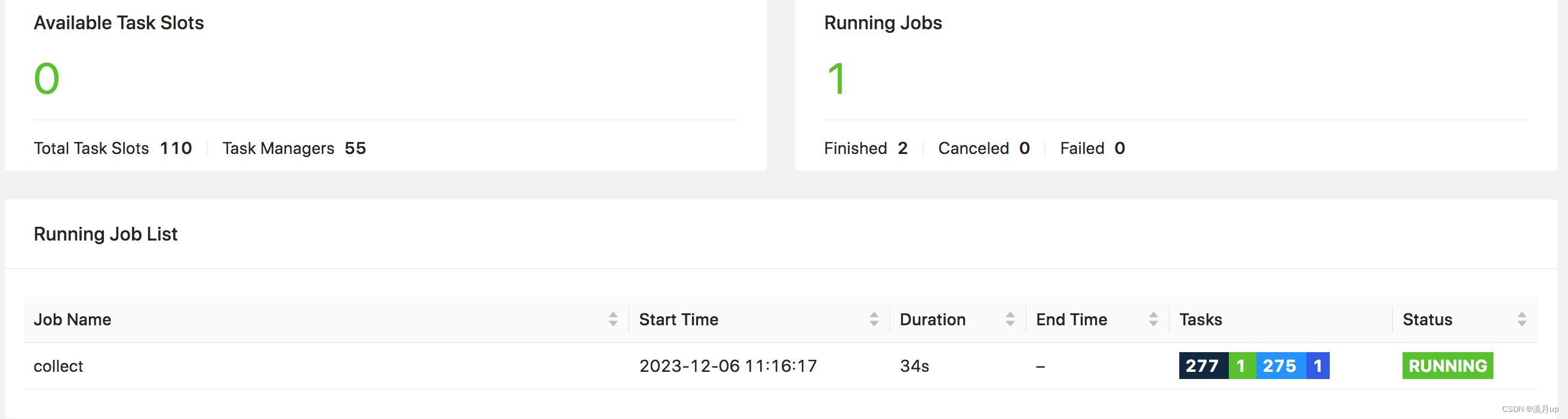
重要的步骤:
设置
flink为批模式
SET execution.runtime-mode=batch;


业务稍大的数据处理:

结束
kyuubi整合flink yarn application model 至此结束,如有问题,欢迎评论区留言。
相关文章:
kyuubi整合flink yarn application model
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catalogsql测试 结束 概述 flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5 整合过程中,需要注意对应的版本。 注意以上版本 姊妹篇 k…...

使用openpyxl调整Excel的宽度
逐行加载Excel,并将行宽调整为行中的最大字符数。 希望在打开 Excel 时能够看到所有字符。 失败代码: #失败代码: wb openpyxl.load_workbook(./targetExcelFile.xlsx) ws wb.worksheets[0]for col in ws.iter_cols():max_length 0colum…...

前端面试——CSS面经(持续更新)
1. CSS选择器及其优先级 !important > 行内样式 > id选择器 > 类/伪类/属性选择器 > 标签/伪元素选择器 > 子/后台选择器 > *通配符 2. 重排和重绘是什么?浏览器的渲染机制是什么? 重排(回流):当增加或删除dom节点&…...
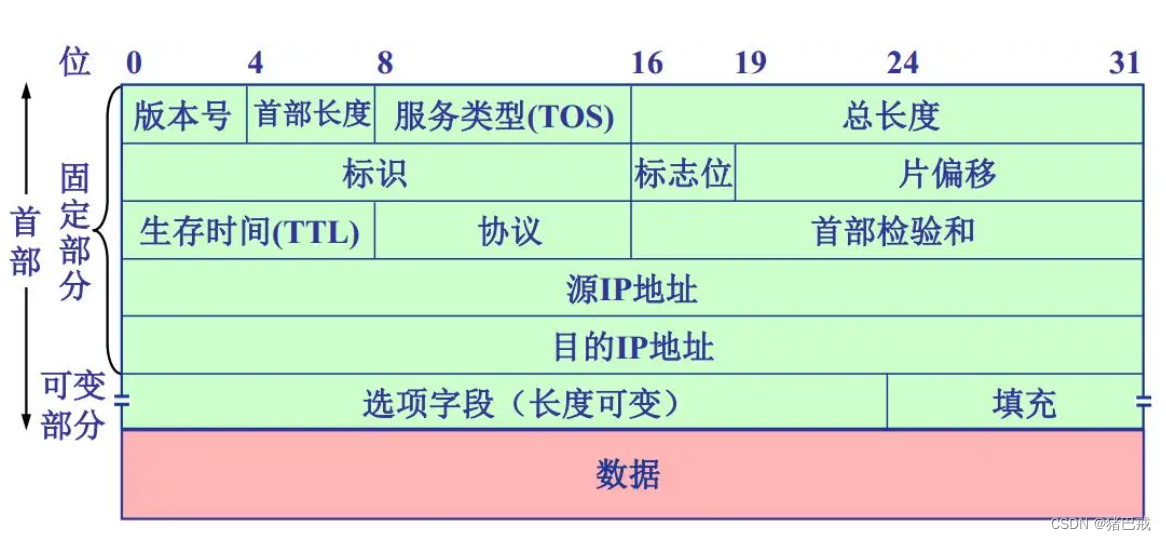
【C语言】结构体实现位段
引言 对位段进行介绍,什么是位段,位段如何节省空间,位段的内存分布,位段存在的跨平台问题,及位段的应用。 ✨ 猪巴戒:个人主页✨ 所属专栏:《C语言进阶》 🎈跟着猪巴戒,…...
学习资料)
IEEE RAS 机器人最优控制(Model-based Optimization for Robotics)学习资料
系列文章目录 前言 电气和电子工程师学会机器人模型优化技术委员会 一、学习资料 1.1 教程和暑期学校 2020 年 Memmo 欧盟项目暑期班2019年Memmo欧盟项目冬季学校Matthias Gerdts(德国慕尼黑联邦国防军大学)在拜罗伊特 OMPC 2013 上举办的最优控制教程…...
redis中缓存雪崩,缓存穿透,缓存击穿等
缓存雪崩 由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,…...

C_8练习题答案
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中,选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) 编写C语言程序一般需经过的几个步骤依次是(B)。A.编辑、调试、编译、连接 B.编辑、编译、连接、运行 C.编译、调试、编辑、连…...
Web漏洞分析-文件解析及上传(中)
随着互联网的迅速发展,网络安全问题变得日益复杂,而文件解析及上传漏洞成为攻击者们频繁攻击的热点之一。本文将深入研究文件解析及上传漏洞,通过对文件上传、Web容器IIS、命令执行、Nginx文件解析漏洞以及公猫任意文件上传等方面的细致分析&…...

使用Node.js创建接口
当使用Node.js创建接口时,有两种主要方式:使用Express框架和使用Node.js的HTTP模块。 Express框架方式: 总的来说,使用Express框架可以更快速地搭建和管理接口,而使用Node.js的HTTP模块则提供了更多底层控制和灵活性&…...

【起草】人人都应该有一个chatGPT助手
第一章:ChatGPT 简介 - 介绍 ChatGPT 的基本概念和工作原理 - 讨论 ChatGPT 在自然语言处理领域的重要性和应用价值 【起草】章节 1-1 介绍 ChatGPT 的基本概念和工作原理-CSDN博客 【起草】1-2 讨论 ChatGPT 在自然语言处理领域的重要性和应用价值-CSDN博客…...
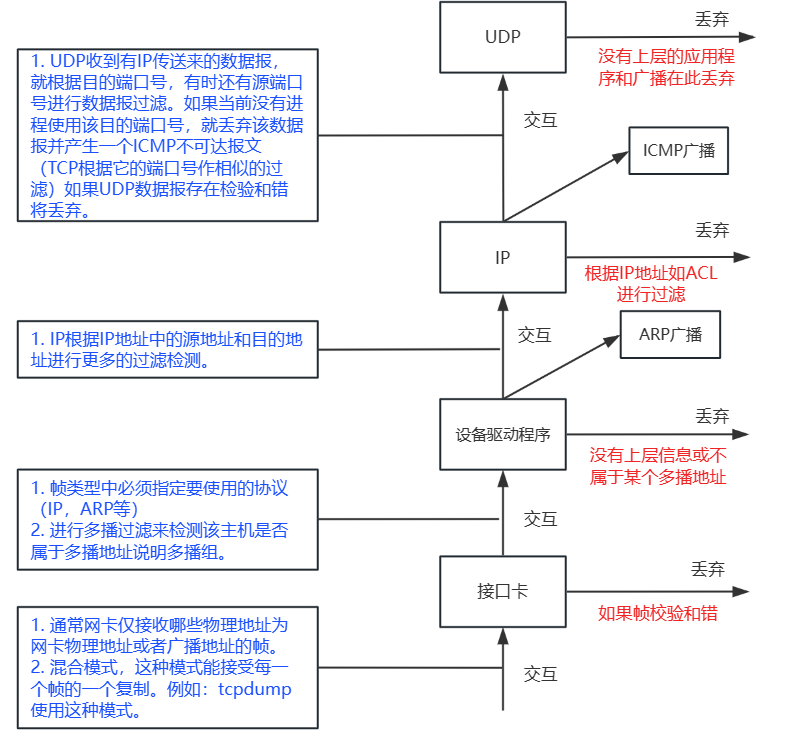
TCP/IP详解——网络基本概念
文章目录 一、网络基本概念1. OSI 7层模型1.1 每层对应的协议1.2 每层涉及的设备1.2.1 物理层设备1.2.2 数据链路层设备1.2.3 网络层设备1.2.4 传输层设备1.2.5 交换机和路由器的应用1.2.6 问题 2. TCP/IP 4层模型3. 物理层传输介质3.1 冲突域 4. 数据链路层4.1 以太网帧结构4.…...

[Linux] ps命令详解
ps命令 ps命令用于显示当前系统中的进程状态信息。以下是ps命令的一些常见参数及其作用: ps命令的基本形式: ps这将显示当前用户自己的运行中的进程的快照。 参数选项: -a: 显示所有进程,包括其他用户的进程。 -u: 显示与用户相…...

QT 中基于 TCP 的网络通信 (备查)
基础 基于 TCP 的套接字通信需要用到两个类: 1)QTcpServer:服务器类,用于监听客户端连接以及和客户端建立连接。 2)QTcpSocket:通信的套接字类,客户端、服务器端都需要使用。 这两个套接字通信类…...
使用MIB builder自定义物联网网关的MIB结构
文章目录 物联网网关初识(了解即可)IoT的通用MIB库结构MIB Builder开发流程指导问题总结子叶没所属分组值范围不为0 物联网网关初识(了解即可) 网关又称网间连接器、协议转换器。简单说,物联网网关是一台智能计算机&a…...

特权FPGA学习笔记
C/C/system C-----vivado HLS------------->RTL门电路,省去了HDL语言的中间转换,可以看作是C向C#的演进,基于zynq面向以前使用C的开发人员,但是个人觉得,HDL存在且未被C取代,工具的着眼点就是面向底层调…...
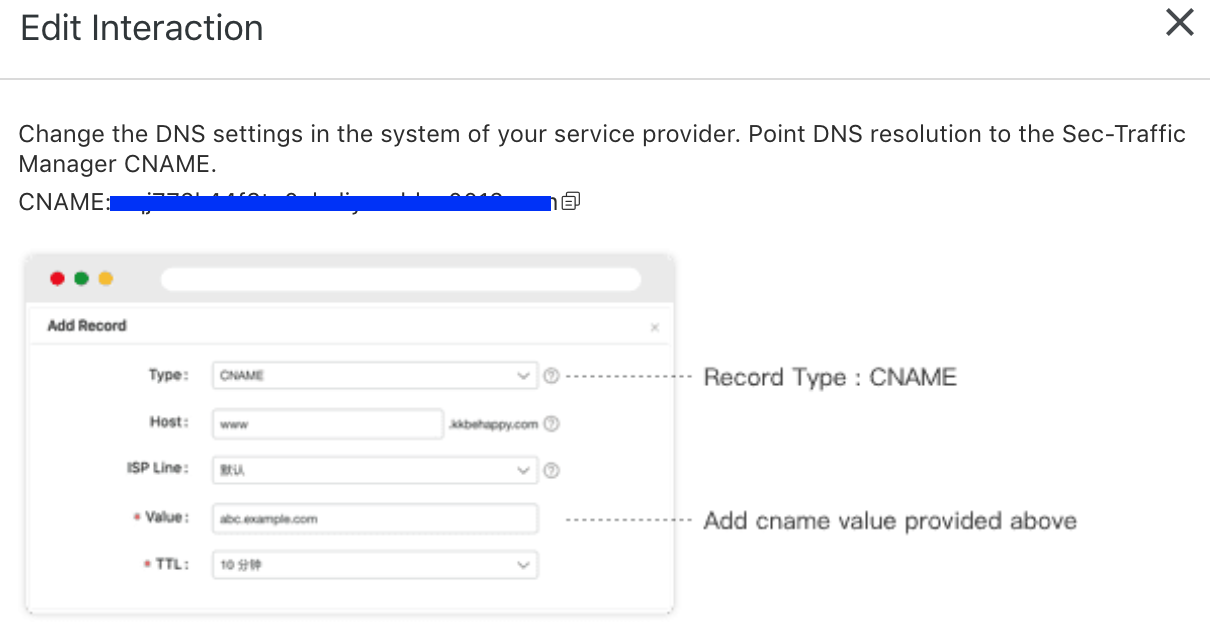
利用阿里云 DDoS、WAF、CDN 和云防火墙为在线业务赋能
在这篇博客中,我们将详细讨论使用阿里云 CDN 和安全产品保护您的在线业务所需的步骤。 方案描述 创新技术的快速发展为世界各地的在线业务带来了新的机遇。今天的人们不仅习惯了,而且依靠互联网来开展他们的日常生活,包括购物、玩游戏、看电…...
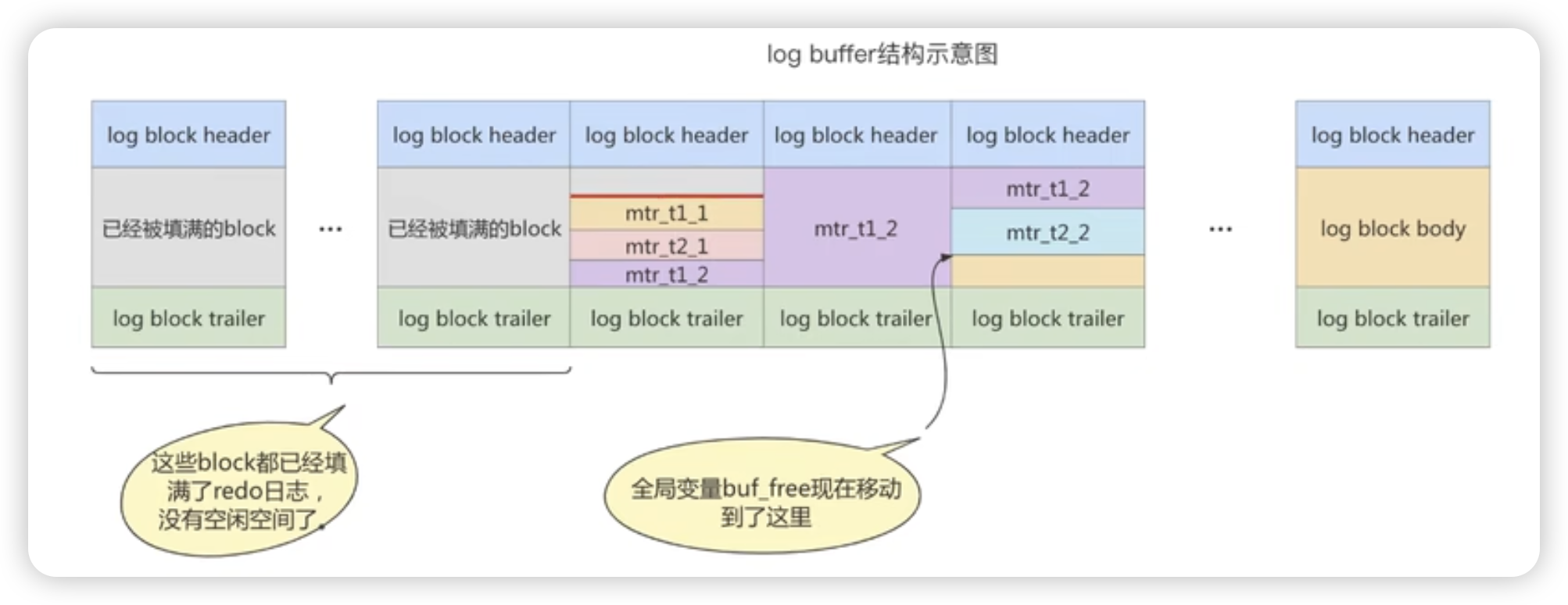
Mysql的事务日志
Mysql的事务具有四个特性:原子性、一致性、隔离性、持久性。那么事务的四种特性分别是靠什么机制实现的呢? 事务的隔离性由锁机制来保证 事务的原子性、一致性、持久性则由redo log和Undo log来保证。 - redo log是重做日志,提供再写入操作&…...
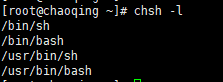
三、Shell 环境
一、Linux 系统分类 在 Linux 中,常见的 Shell 有以下几种: Bourne Shell(sh):最早的 Shell,由 Stephen Bourne 开发。它是大多数其他 Shell 的基础。Bourne Again Shell(bash)&am…...

2023年第三届产业数字化【金铲奖】重磅来袭!
做具备产业数字化价值的企业、案例标杆、资本机构的见证者、发现者、陪伴者。 出品|产业家 一年一度的金铲奖来了! 在过去的一年时间里,我们清晰地看到,产业数字化的潮水更加汹涌澎湃且势不可挡,越来越多的企业开始寻求数字化…...
node.js安装和配置
软件介绍 Node.js是一个免费的、开源的、跨平台的JavaScript运行时环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本。 Node.js是一个基于Chrome JavaScript运行时建立的一个平台。 Node.js是一个事件驱动I/O服务端JavaScript环境,基于Googl…...

如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南
如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

Android Studio中文界面完整指南:5分钟快速汉化教程
Android Studio中文界面完整指南:5分钟快速汉化教程 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android St…...

缤纷夏日 心有所“暑”
邻聚美好时光,在升腾的烟火气里我们共同收藏了夏日的N种欢乐回顾七月光影流转的坝坝电影唤醒了儿时记忆孩子们在飞舞的泡泡大作战里嬉闹篮球场上矫健的身姿瞬间定格更有贴心的便民服务磨亮生活锋刃、洗净门前地垫,便捷直达家门这个缤纷夏日,因…...

A-29P深度解析:100dB回音消除与AI降噪的硬件设计实战
摘要:在可视门禁、车载蓝牙、远程会议等设备中,结构空间狭小与高音量需求往往导致严重的回声和啸叫问题。本文基于A-29P纯模拟回音消除模块,深入解析其100dB消回音能力、AI降噪特性及7种硬件应用模式,为工程师提供一套无需代码的快…...

2个实测免费的AI简历神器,简历回复率翻3倍,顺利过ATS机筛!
当前的求职市场,投简历简直像往海里扔石头。很多同学吐槽:明明自己挺优秀,投了100份简历却连一个面试邀请都没有。 其实,大厂HR第一轮根本不看简历,全是靠ATS(简历筛选系统)关键词过滤。如果你…...

保姆级教程:用STM32+ESP8266+微信小程序,5分钟搞定Onenet数据上传与设备控制
零基础实战:STM32ESP8266微信小程序极速对接Onenet全指南 在物联网技术快速普及的今天,许多嵌入式开发者都希望快速搭建一个完整的智能设备系统。本文将带你用最简单的方式,通过STM32微控制器、ESP8266 WiFi模块和微信小程序,实现…...

巅峰共鸣,实力同频|盖茨中国热烈祝贺张雪机车WSBK捷克站双冠耀世,改写37年垄断史!
引擎轰鸣震彻赛道,中国红闪耀世界舞台!2026 年 5 月 17 日,WSBK 捷克莫斯特站 WorldSSP 组别圆满落幕,中国品牌张雪机车再创历史,车手 Valentin Debise 驾驶自研 ZX820RR 赛车,包揽两回合冠军,斩…...

MXFP混合精度注意力机制优化LLM推理性能
1. 低比特MXFP混合精度注意力机制解析在大型语言模型(LLM)推理过程中,自注意力机制的计算开销一直是主要瓶颈。传统FP16/BF16精度计算虽然能保证模型质量,但存在显著的内存带宽浪费和计算资源利用率不足问题。MXFP(Microscaling Floating-Poi…...

别再被Nginx的rewrite循环搞懵了!一个真实Vue项目部署的500错误排查实录
从Nginx重定向死循环到优雅解决:Vue项目部署的深度排错指南 凌晨三点,服务器监控突然告警——刚上线的Vue企业门户网站出现大面积500错误。查看日志时,那个令人窒息的rewrite or internal redirection cycle错误信息让整个运维团队陷入沉思。…...

杰理之把音量调到最高后暂停蓝牙音乐,再按播放后,音量会变小问题处理参考【篇】
由于苹果手机音量等级只有16级,当近端耳机音量调超过16级后(比如20级)...