【Pytorch】学习记录分享2——Tensor基础,数据类型,及其多种创建方式
pytorch 官方文档
Tensor基础,数据类型,及其多种创建方式
- 1. 创建 Creating Tensor: 标量、向量、矩阵、tensor
- 2. 三种方法可以创建张量,一是通过列表(list),二是通过元组(tuple),三是通过Numpy的数组(array),基本创建代码如下:
- 3. 张量类型, pytorch下的数组类型
- 4. 张量特殊类型及其创建方法
1. 创建 Creating Tensor: 标量、向量、矩阵、tensor
#标量 scalar
scalar = torch.tensor(7)
scalar.ndim # 查看维度
scalar.item() # 转换成 python中的整数 #向量 vector
vector = torch.tensor([7, 7])
vector.shape #查看形状#矩阵 matrix
MATRIX = torch.tensor([[7, 8], [9, 10]])#随机tensor,下面是一些生成随机tensor的方法:[更多详细方法见博客](https://blog.csdn.net/Darlingqiang/article/details/134946446?spm=1001.2014.3001.5501)
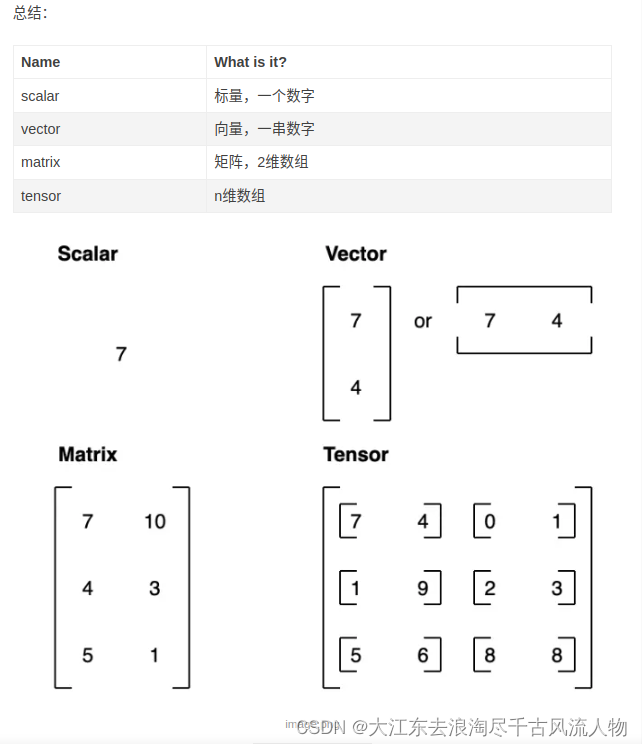
2. 三种方法可以创建张量,一是通过列表(list),二是通过元组(tuple),三是通过Numpy的数组(array),基本创建代码如下:
import torch # 导入pytorch
import numpy as np # 导入numpyprint(torch.__version__) # 查看torch版本
t1 = torch.tensor([1,1]) # 通过列表创建
t1 = torch.tensor((1,1)) # 通过元组创建
t1 = torch.tensor(np.array([1,1]) # 通过数组创建
t1 # tensor([1, 1])
张量相关属性查看的基本操作,后期遇到的张量结构都比较复杂,难以用肉眼直接看出,因此相关方法用的也比较频繁
| 方法 | 描述 | 栗子🌰 |
|---|---|---|
| ndim | 查看张量的维度,也可使用dim() | t.ndim /t.dim() |
| dtype | 查看张量的数据结构 | t.dtype |
| shape | 查看张量的形状 | t.shape |
| size | 查看张量的形状,和shape方法相同 | t.size() |
| numel | 查看张量内元素的元素 | t.numel() |
注:size()和numel()是需要加括号, 实例
t2 = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
t2.ndim # 2
t2.dtype # torch.int64
t2.shape # torch.Size([3, 3])
t2.size() # torch.Size([3, 3])
t2.numel() # 返回9
3. 张量类型, pytorch下的数组类型
python作为动态语言,很少去注意到变量的类型,因为我们编写代码时并不需要声明变量类型,但是细心的小伙伴会发现,调用dtype后返回的是torch.int64, 这说明pytorch对于数组的类型是很严谨,因此我们还要了解在pytorch下的数组类型
注: 只需要记住有整数,浮点数,布尔型和复数即可
| 类型 | dtype |
|---|---|
| 32bit浮点数 | torch.float32 或 torch.float |
| 64bit浮点数 | torch.float64 或 torch.double |
| 16bit浮点数 | torch.float16 |
| 8bit无符号整数 | torch.uint8 |
| 8bit有符号整数 | torch.int8 |
| 16bit有符号整数 | torch.int16 或 torch.short |
| 32bit有符号整数 | torch.int32 或 torch.int |
| 64bit有符号整数 | torch.int64 或 torch.long |
| 布尔型 | torch.bool |
| 复数型 | torch.complex64 |
在pytorch中,默认的张量整数类型是int64,使用浮点数类型是float32【不同版本pytorch可能不同】;
双精度double能存储的有效位数比单精度float更多,但相应的需要的存储空间越多
int16,int32,int64的区别主要在于表示值的范围不同,数字越大所能表示的范围越大
在pytorch中,可以使用在创建时指定数据类型,也可以后期进行修改,实例如下
t3 = torch.tensor([True, 1.0]) # tensor([1., 1.])隐式转换
t3 = torch.tensor([1,1,1,1],dtype=float)
t3.dtype # torch.float64
t3.int() # tensor([1, 1, 1, 1], dtype=torch.int32)
t3.byte() # tensor([1., 1., 1., 1.], dtype=torch.float64)
t3.short() # tensor([1, 1, 1, 1], dtype=torch.int16)
t3.bool() # tensor([True, True, True, True])
4. 张量特殊类型及其创建方法
| 方法 | 描述 |
|---|---|
| torch.zeros() | 创建全为0的张量 |
| torch.ones() | 创建全为1的张量 |
| torch.eye() | 创建对角为1的单位矩阵 |
| torch.diag(t) | 创建对角矩阵,需要传入1维张量 |
| torch.rand() | 创建服从0-1均匀分布的张量 |
| torch.randn() | 创建服从标准正态分布的张量 |
| torch.normal() | 创建服从指定正态分布的张量 |
| torch.randn | 创建服从标准正态分布的张量 |
| torch.randint() | 创建由指定范围随机抽样整数组成的张量 |
| torch.arange() | 创建给定范围内的连续整数组成的张量 |
| torch.linspace() | 创建给定范围内等距抽取的数组成的张量 |
| torch.empty() | 创建未初始化的指定形状的张量 |
| torch.full() | 创建指定形状,指定填充数值的张量 |
需要注意有哪些方法是传入代表结构的列表,有哪些是传入张量,有哪些是传入数字,实例如下
torch.zeros([3,3]) # 创建3行3列,元素全为0的2维张量
torch.ones([3,3]) # 创建3行3列,元素全为1的2维张量
torch.eye(4) # 创建4行4列的单位矩阵t = torch.tensor([1,2,3,4]) # 创建需要传入的1维张量
torch.diag(t) # 创建对角元素为1,2,3,4的对角矩阵
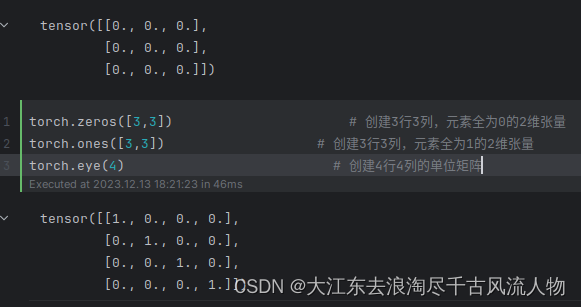
torch.rand([3,4]) # 创建元素为0-1分布的3行4列张量
torch.normal(3, 4, [2, 2]) # 创建服从均值为3,标准差为4的正态分布元素组成的张量
torch.randn([3,4]) # 创建元素为标准正态分布的3行4列张量
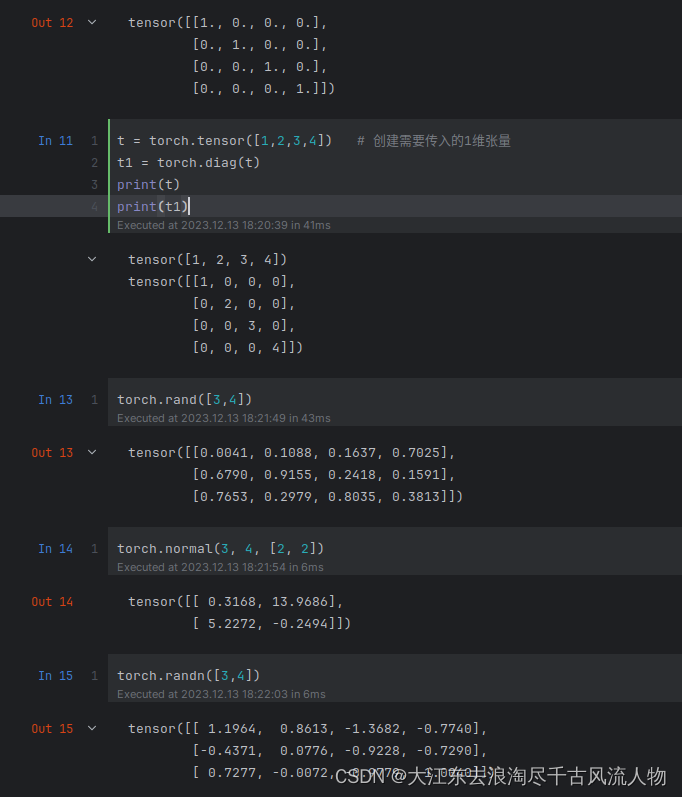
torch.randint(0,20,[3,4]) # 创建由0-20间的随机整数组成的3行4列的张量
torch.arange(1,20) # 创建0-20内连续整数组成的张量
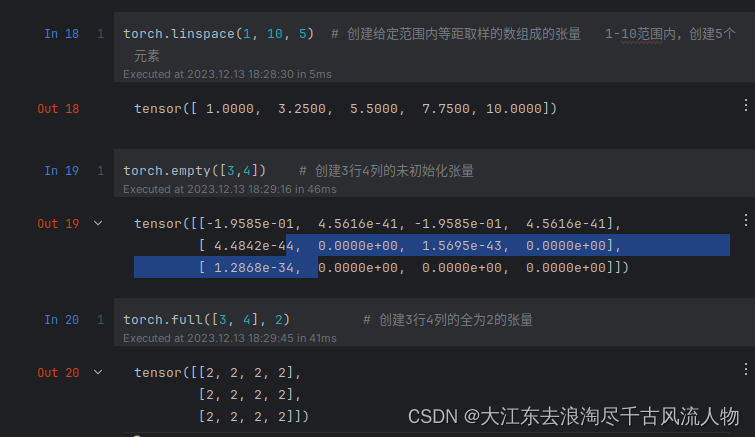
torch.linspace(1, 10, 5) # 创建给定范围内等距取样的数组成的张量 1-10范围内,创建5个元素
torch.empty([3,4]) # 创建3行4列的未初始化张量
torch.full([3, 4], 2) # 创建3行4列的全为2的张量
相关文章:
【Pytorch】学习记录分享2——Tensor基础,数据类型,及其多种创建方式
pytorch 官方文档 Tensor基础,数据类型,及其多种创建方式 1. 创建 Creating Tensor: 标量、向量、矩阵、tensor2. 三种方法可以创建张量,一是通过列表(list),二是通过元组(tuple),三是通过Numpy的数组(arra…...
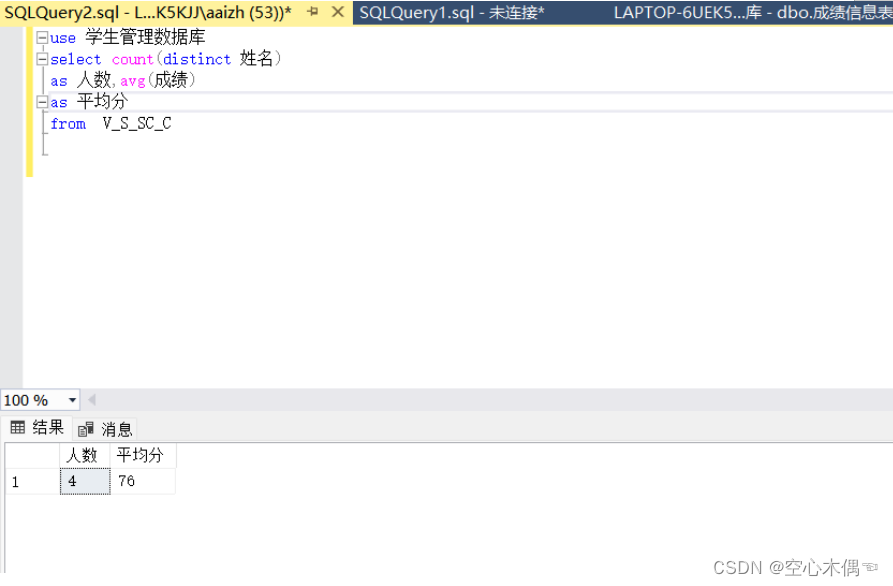
实验7:索引和视图定义
【实验目的】 1、了解索引和视图的含义 2、熟悉索引和视图的创建规则 3、掌握索引和视图的创建和管理 【实验设备及器材】 1、硬件:PC机; 2、软件:(1)Windows7; (2)Microsoft SQL Server 2012。 【主要内容】 索引的创建、删除、重建…...
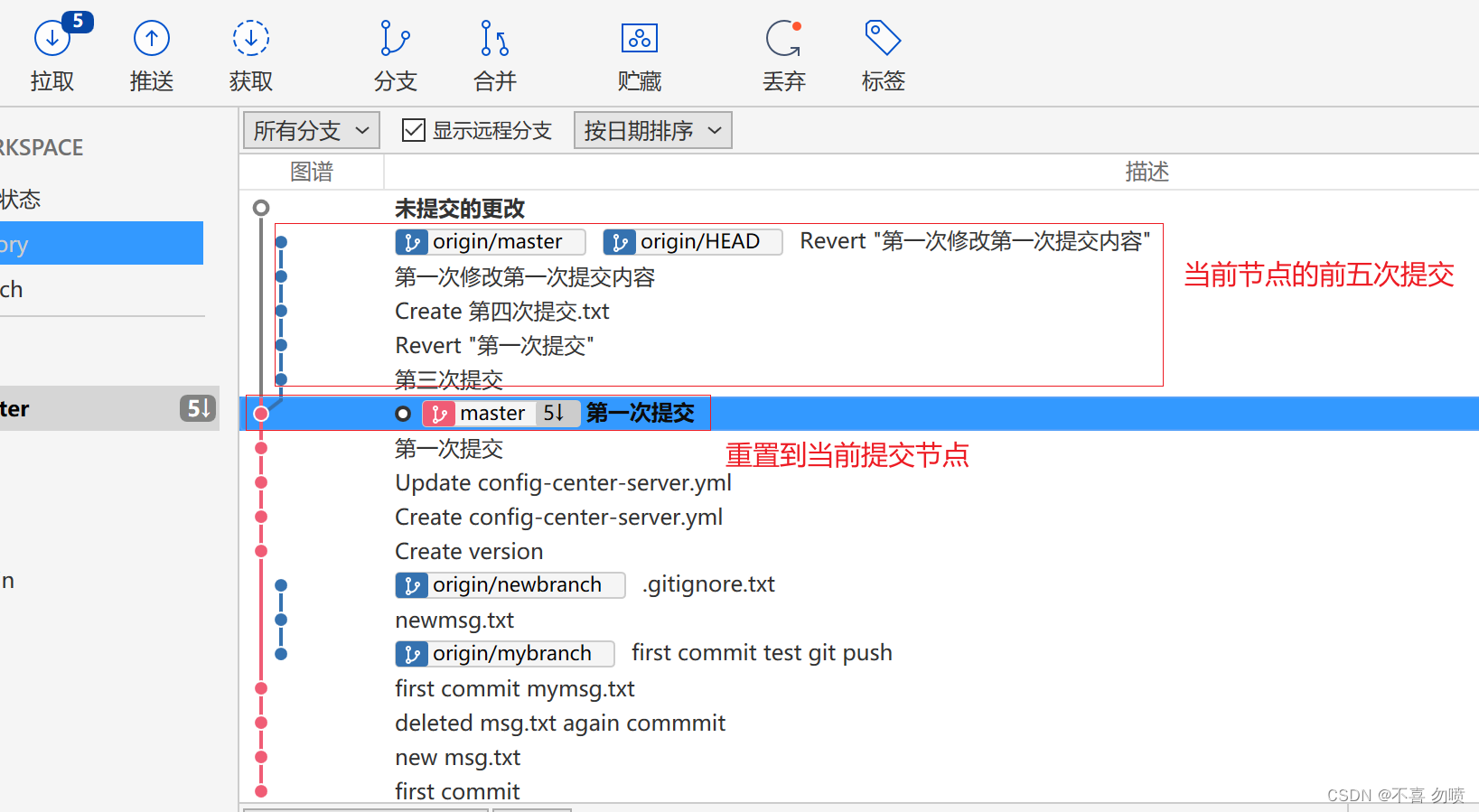
Source Tree回滚 重置 贮藏操作
回滚提交 source tree的回滚提交: 在执行该操作时将会对history中提交的指定节点直接进行回滚,将该节点执行的提交操作撤销(如当前节点是提交文件,执行回滚提交时将会删除该文件,如果当前节点的前面的节点对该节点内容进行修改后,执行回滚提交时需要执行冲突解决),同时生成一次…...

Android13 不能静态注册的几个广播
Android13 不能静态注册的几个广播 文章目录 Android13 不能静态注册的几个广播一、不能静态注册的广播:二、静态注册无法生效的分析1、Intent.java2、其他地方声明了不能静态注册的广播3、为啥静态注册的广播无效?4、其他静态注册无法生效的广播5、其他Android fra…...

吴恩达深度学习L2W1作业1
初始化 欢迎来到“改善深度神经网络”的第一项作业。 训练神经网络需要指定权重的初始值,而一个好的初始化方法将有助于网络学习。 如果你完成了本系列的上一课程,则可能已经按照我们的说明完成了权重初始化。但是,如何为新的神经网络选择…...
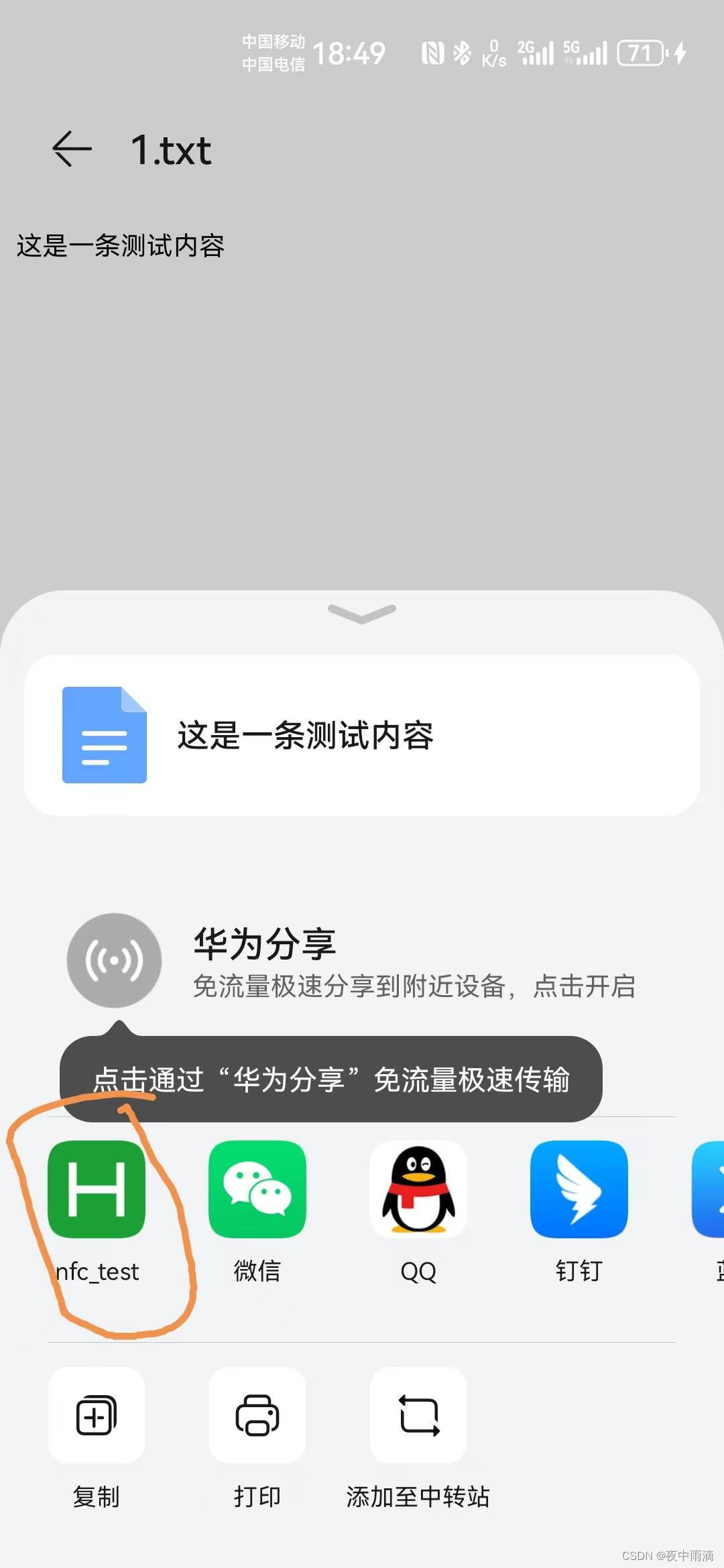
uniapp原生插件之安卓app添加到其他应用打开原生插件
插件介绍 安卓app添加到其他应用打开原生插件,接收分享的文本和文件,支持获取和清空剪切板内容 插件地址 安卓app添加到其他应用打开原生插件,支持获取剪切板内容 - DCloud 插件市场 超级福利 uniapp 插件购买超级福利 详细使用文档 u…...

scala编码
1、Scala高级语言 Scala简介 Scala是一门类Java的多范式语言,它整合了面向对象编程和函数式编程的最佳特性。具体来讲Scala运行于Java虚拟机(JVM)之上,井且兼容现有的Java程序,同样具有跨平台、可移植性好、方便的垃圾回收等特性…...

智慧路灯杆如何实现雪天道路安全监测
随着北方区域连续发生暴雪、寒潮、大风等气象变化,北方多地产生暴雪和低温雨雪冰冻灾害风险,冬季雨雪天气深度影响人们出行生活,也持续增加道路交通风险。 智慧路灯杆是现代城市不可或缺的智能基础设施,凭借搭载智慧照明、环境监测…...
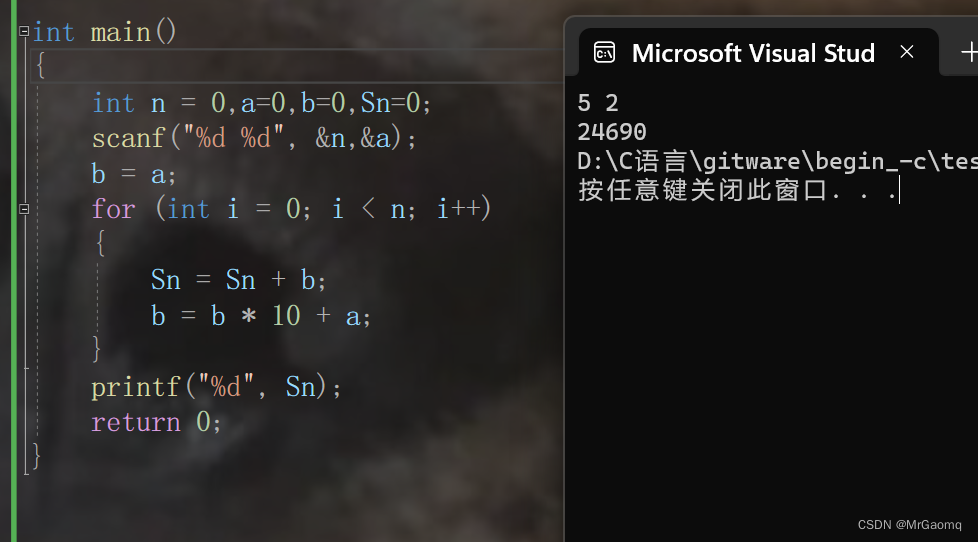
C语言指针基础题(二)
目录 例题一题目解析及答案 例题二题目解析及答案 例题三题目解析及答案 例题四题目解析及答案 例题五题目解析及答案 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸🥸…...
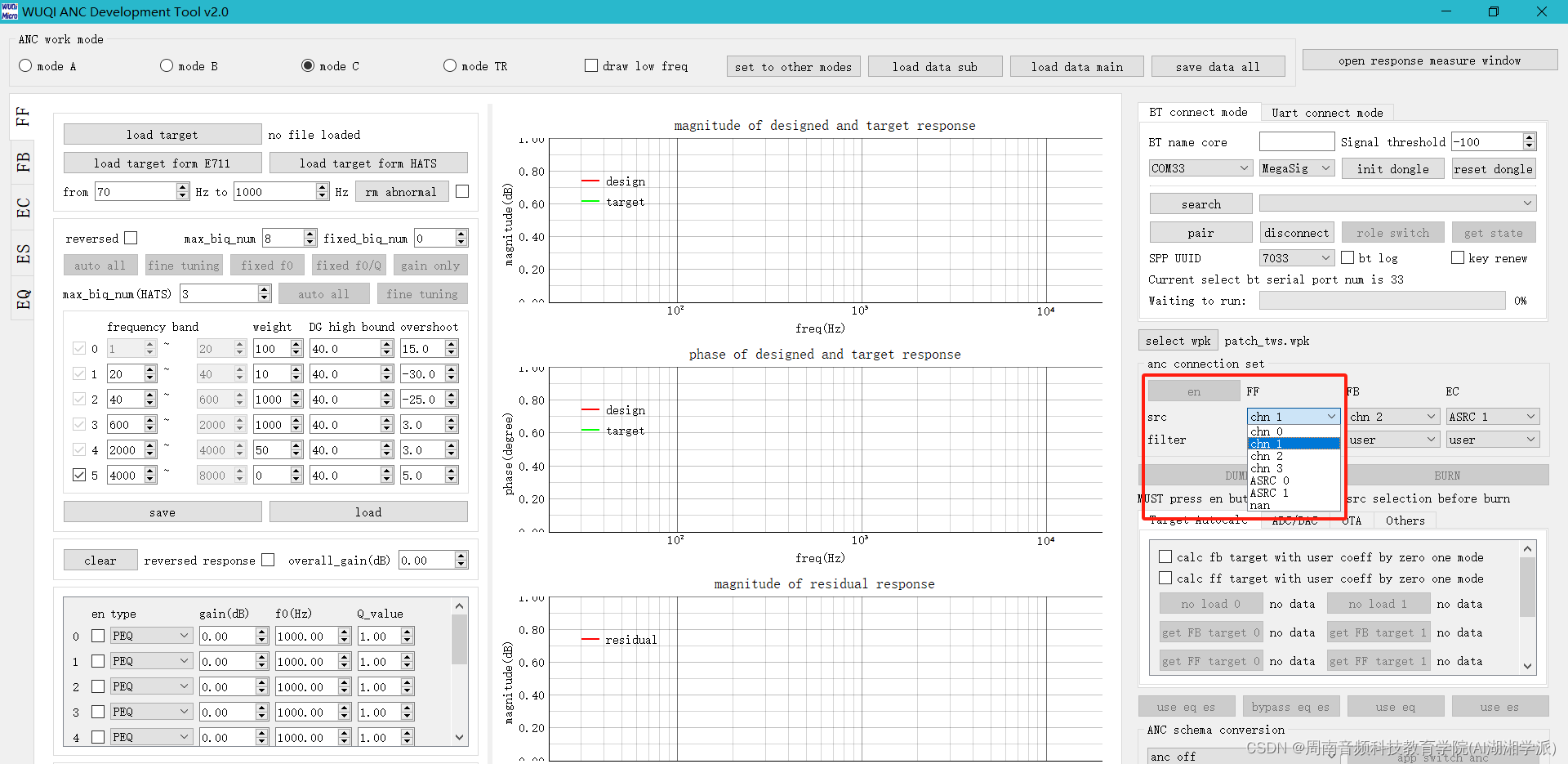
物奇平台MIC配置与音频通路关系
物奇平台MIC配置与音频通路关系 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, 1 255代表无效&am…...
外包干了3年,技术退步太明显了。。。。。
先说一下自己的情况,本科生生,18年通过校招进入武汉某软件公司,干了差不多3年的功能测试,今年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能…...

阶段十-java新特性
JDK9新特性 1.模块化系统 jar包结构的变化 jar -》model -》package -》class 通过不同的模块进行开发 每个模块都有自己的模块配置文件module-info.java 2.JShell JDK9自带的命令行开发,在进行简单的代码调试时可以直接编译使用 可以定义变量,方法&…...

win10重装系统历程
win10系统更新出问题了,重置系统卡死,遂决定重装。 微软官方工具制作U盘启动盘, 进行到分区时,一冲动把盘都格式化了, 后面了解到,即便进不了系统也有办法备份数据的... 进行到安装时,提示W…...
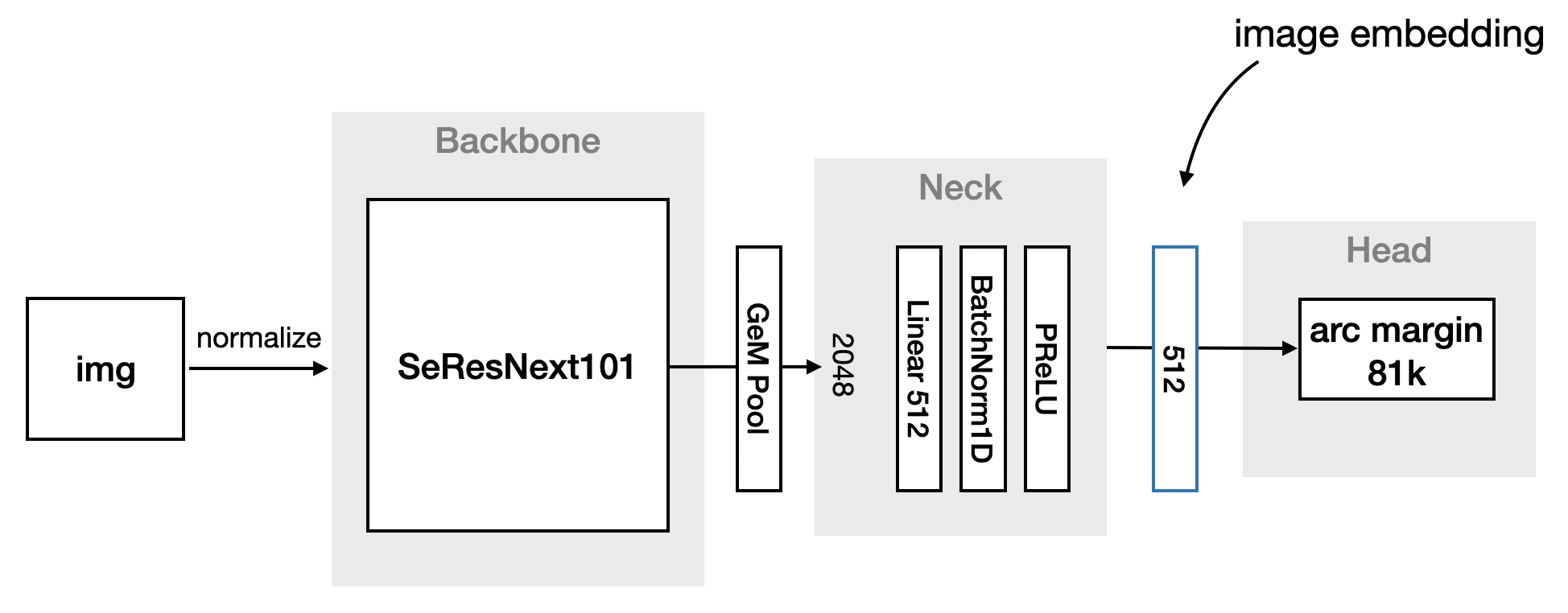
【知识积累】深度度量学习综述
原文指路:https://hav4ik.github.io/articles/deep-metric-learning-survey Problem Setting of Supervised Metric Learning 深度度量学习是一组旨在衡量数据样本之间相似性的技术。 Contrastive Approaches 对比方法的主要思想是设计一个损失函数,直…...
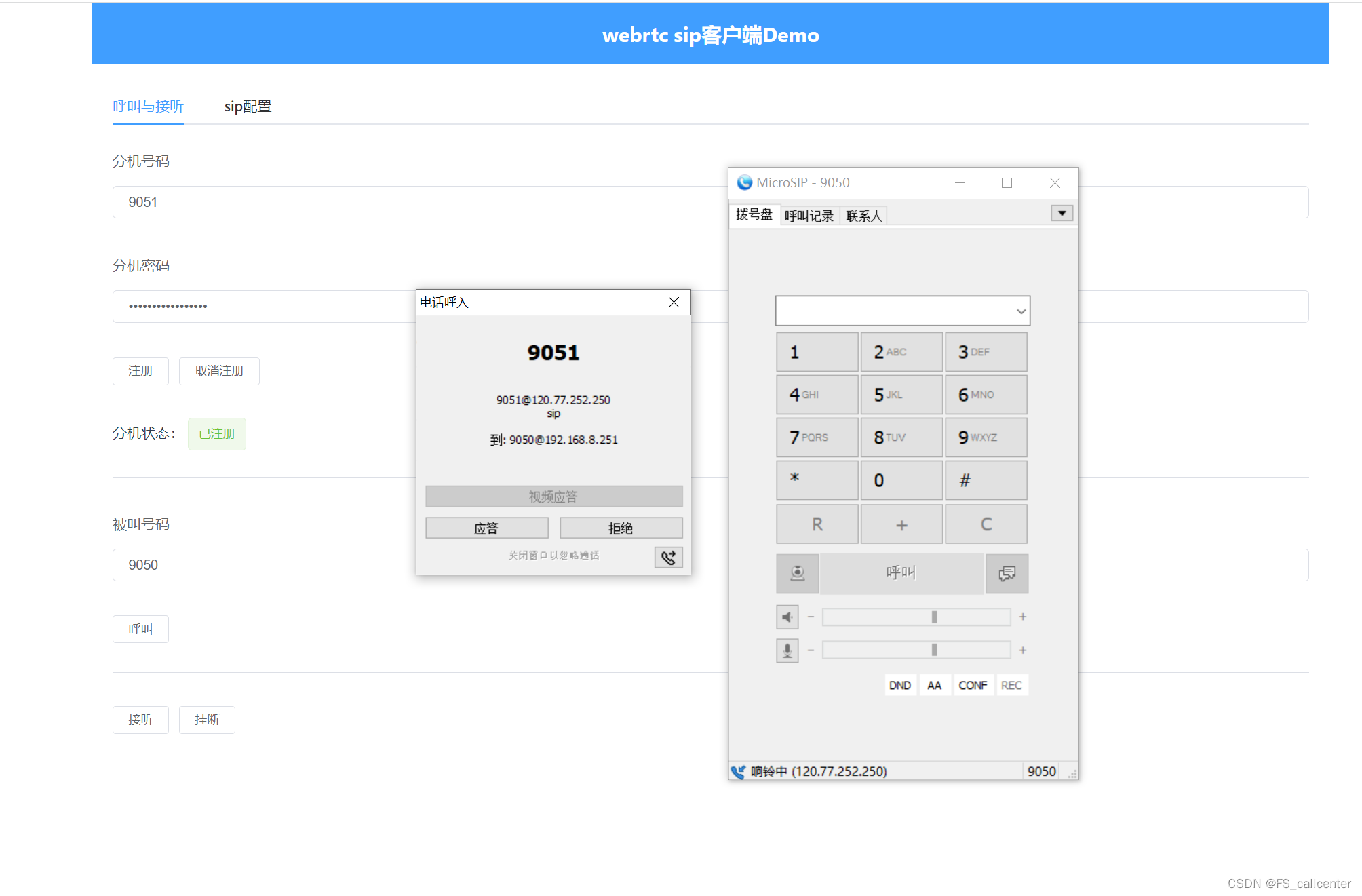
webrtc网之sip转webrtc
OpenSIP是一个开源的SIP(Session Initiation Protocol)服务器,它提供了一个可扩展的基础架构,用于建立、终止和管理VoIP(Voice over IP)通信会话。SIP是一种通信协议,用于建立、修改和终止多媒体…...
【Spring】依赖注入之属性注入详解
前言: 我们在进行web开发时,基本上一个接口对应一个实现类,比如IOrderService接口对应一个OrderServiceImpl实现类,给OrderServiceImpl标注Service注解后,Spring在启动时就会将其注册成bean进行统一管理。在Co…...
)
6-tornado配置文件的使用(命令行解析、文件设置)
tornado.options options 可以让服务运行前提前设置参数,而常见的2种设置参数方式为:1. 命令行设置 2. 文件设置命令行解析 使用tornado.options.define前定义,通常在模块的顶层。 然后,可以将这些选项作为以下属性的属性进行访…...
k8s ingress service endpoints 解决微信服务器验证问题(内网穿透)
最近公司要搞微信公众号开发,想用自己公司内网的电脑调试,但涉及到微信服务器地址(URL)验证的问题(内网穿透),查了网上一堆文章有推荐ngrok的,但被微信墙了;有推荐sunny-ngrok的,免费…...

postgresql-effective_cache_size参数详解
在 PostgreSQL 中,effective_cache_size 是一个配置参数,用于告诉查询规划器关于系统中可用缓存的估计信息。这个参数并不表示实际的内存量,而是用于告诉 PostgreSQL 查询规划器系统中可用的磁盘缓存和操作系统级别的文件系统缓存的大小。它用…...

CUDA锁页内存的使用
1.定义指针变量 float *host_Weights; // 锁页内存 float *dev_Weights; // 设备端内存2.分配内存 cudaHostAlloc((void**)&host_Weights, numInputs * sizeof(float), cudaHostAllocDefault); // 用锁页内存,可以有效加快数据传递速度 cudaMalloc((vo…...

换背景照片怎么制作?一篇全网最全的AI抠图工具对比指南
最近经常有朋友问我:"怎样才能快速换背景照片啊?"确实,随着自媒体时代的到来,无论是做电商展示产品、准备证件照,还是制作社交媒体内容,都离不开换背景这个需求。今天我就把这两年用过的所有抠图…...
打造丝滑下拉刷新(附Paging3联动实战))
告别传统SwipeRefreshLayout!用Compose的pullRefresh()打造丝滑下拉刷新(附Paging3联动实战)
用Compose的pullRefresh()重构Android下拉刷新体验:从基础封装到Paging3深度集成 下拉刷新作为移动端最基础的用户交互之一,在Jetpack Compose时代迎来了全新的设计范式。传统Android开发中,我们习惯使用SwipeRefreshLayout包裹RecyclerView的…...

通过curl命令快速测试Taotoken的ChatGPT接口是否通畅
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的ChatGPT接口是否通畅 对于开发者而言,在集成大模型API时,一个快速、直接的…...
)
NotebookLM+遥感影像分析实战:水稻倒伏预警模型搭建(含Landsat-8元数据自动标注技巧)
更多请点击: https://kaifayun.com 第一章:NotebookLM农业科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作设计。在农业科学研究中,它能高效整合多源异构文献(如 FAO 报告、PubMed…...

Elsevier投稿追踪插件:科研工作者的智能审稿管家
Elsevier投稿追踪插件:科研工作者的智能审稿管家 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 当您的论文投稿到Elsevier期刊后,漫长的审稿等待期往往成为科研工作者的焦虑来源。Elsevier投…...

编程分析企业奖罚制度执行数据,优化奖罚标准,做到赏罚分明,调动全体员工职场工作积极性。
定位是:商务智能(BI) Python 人力资源数据分析,可直接用于课程设计、技术博客或企业内部管理优化原型。⚠️ 说明:本方案不评价企业文化优劣、不站队劳资任何一方,仅提供数据建模与分析框架。一、实际应用…...

告别手动标注!R语言ggplot2+ggannotate高效绘制组间差异柱状图保姆级教程
R语言科研绘图革命:ggplot2ggannotate自动化差异标注全攻略 科研图表的美观程度直接影响论文的第一印象,而统计显著性标注更是数据可视化的灵魂所在。传统手动添加p值和星号的方式不仅效率低下,还容易出错——标注位置偏移、字体大小不一、连…...

基于SpringBoot的共享汽车管理系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的共享汽车管理系统以解决当前共享汽车行业在资源调度效率、用户服务体验以及数据安全等方面存在的核心问题。随着城…...
)
NotebookLM文化遗产研究不可逆断层预警:当AI开始“发明”不存在的碑刻铭文(含3类幻觉检测SOP)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文化遗产研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的私有文档进行深度语义理解与上下文关联推理。在文化遗产研究领域,该…...
)
【小白适用】2026 最新 Win11 OpenClaw 一键安装步骤(包含安装包)
OpenClaw(小龙虾)Windows 11 一键部署教程|2026 最新版|零代码・免配置・解压即用 适用系统:Windows 11 专业版 / 家庭版 / 正式版(全版本兼容)项目介绍:OpenClaw 是 GitHub 星标 2…...