postgresql-effective_cache_size参数详解
在 PostgreSQL 中,effective_cache_size 是一个配置参数,用于告诉查询规划器关于系统中可用缓存的估计信息。这个参数并不表示实际的内存量,而是用于告诉 PostgreSQL 查询规划器系统中可用的磁盘缓存和操作系统级别的文件系统缓存的大小。它用于帮助 PostgreSQL 优化器估计特定查询所需的成本,以选择最佳的查询计划。
effective_cache_size 参数的设置可以在 PostgreSQL 的配置文件 (postgresql.conf) 中进行,也可以使用 ALTER SYSTEM 命令在运行时动态修改,但需要重新加载 PostgreSQL 的配置以使更改生效。
这个参数的值通常设置为系统可用缓存的大致大小。一般情况下,你可以设置为系统可用内存的一部分,但不要超过系统实际可用内存的大小。
例如:
effective_cache_size = 4GB
这个设置表示 PostgreSQL 会假设系统中大约有 4GB 的缓存可用于数据块的读取。这个值的设置可以因系统的实际硬件和负载情况而异,需要进行一些试验和性能测试来确定最佳的值。
调整 effective_cache_size 可以影响查询优化器对索引扫描、排序和连接等操作的成本估计,进而影响 PostgreSQL 执行计划的选择。
记住,修改这些参数时最好在测试环境中进行,并且需要仔细监控系统的性能变化,以确定最佳的设置。
这个参数主要用于Postgre查询优化器。是单个查询可用的磁盘高速缓存的有效大小的一个假设,是一个估算值,它并不占据系统内存。由于优化器需要进行估算成本,较高的值更有可能使用索引扫描,较低的值则有可能使用顺序扫描。一般这个值设置为内存的1/2是正常保守的设置,设置为内存的3/4是比较推荐的值。通过free命令查看操作系统的统计信息,您可能会更好的估算该值。
调整effective_cache_size参数可以控制Postgresql必须在buffer cache中提取查询数据的频率,从而提升查询性能。
1. 案例一
以下转载自:本文来自博客园,作者:[abce](https://www.cnblogs.com/abclife/),转载请注明原文链接:[https://www.cnblogs.com/abclife/p/14565691.html](https://www.cnblogs.com/abclife/p/14565691.html)
优化器假设可以用于单个查询的磁盘缓存的有效大小。这个因素会被用到使用索引的成本考虑中:值越大,使用索引扫描的可能性就越大;值越小,使用顺序扫描的可能性就越大。
设置该参数的时候,需要同时考虑到shared buffer和内核对磁盘缓存的使用,尽管有些数据会同时存在shared buffer和内核的磁盘缓存中。同时要考虑到在不同的表上并发查询的数量,因为他们也会使用到共享空间。
该参数不会影响分配给postgresql的共享内存,也不保留内核磁盘缓存。只是用于优化器的评估目的。系统也不会假设不同查询之间的数据保留在磁盘缓存上。默认是4GB。
指定值的时候,如果不指定unit,默认就是block。
select name, setting, unit from pg_settings where name like 'effective_cache_size';
| name | setting | unit |
|---|---|---|
| effective_cache_size | 524288 | 8kB |
成本评估要考虑很多因素:i/o数量、操作调用次数、处理的元组的数量、选择性等等。但是i/o的成本是什么呢?很显然,如果数据已经在cache中或数据在磁盘上,代价显然是不同的。
参数effective_cache_size就是用来告诉优化器,系统可以提供多大的cache。这里的cache不仅仅是内存的cache,也考虑了文件系统cache、cpu的cache等。effective_cache_size是这些cache的总和。
postgres=# create table t_random as select id,random() as r from generate_series(1,1000000) as id order by random();
SELECT 1000000postgres=# create table t_ordered as select id,random() as r from generate_series(1,1000000) AS id;
SELECT 1000000postgres=# create index idx_random on t_random(id);
CREATE INDEXpostgres=# create index idx_ordered on t_ordered(id);
CREATE INDEXpostgres=# vacuum analyze t_random;
VACUUMpostgres=# vacuum analyze t_ordered;
VACUUMpostgres=#
两个表都包含相同的数据,一个表是有序的,一个是无序的。
将effective_cache_size设置一个较小的值。优化器会认为系统的内存不是很多:
postgres=# set effective_cache_size to '1 MB';
SETpostgres=# show effective_cache_size;effective_cache_size
----------------------1MB
(1 row)postgres=# set enable_bitmapscan to on;
SETpostgres=# explain SELECT * FROM t_random WHERE id < 1000;QUERY PLAN
----------------------------------------------------------------------------Bitmap Heap Scan on t_random (cost=19.71..2453.44 rows=940 width=12)Recheck Cond: (id < 1000)-> Bitmap Index Scan on idx_random (cost=0.00..19.48 rows=940 width=0)Index Cond: (id < 1000)
(4 rows)postgres=# set enable_bitmapscan to off;
SETpostgres=# explain SELECT * FROM t_random WHERE id < 1000;QUERY PLAN
---------------------------------------------------------------------------------Index Scan using idx_random on t_random (cost=0.42..3732.86 rows=940 width=12)Index Cond: (id < 1000)
(2 rows)postgres=#
通常pg会走bitmap索引扫描,但是这里我们想看看索引扫描会发生什么。所以关闭了bitmap索引扫描。
postgres=# SET effective_cache_size TO '1000 GB';
SETpostgres=# explain SELECT * FROM t_random WHERE id < 1000;QUERY PLAN
---------------------------------------------------------------------------------Index Scan using idx_random on t_random (cost=0.42..3488.86 rows=940 width=12)Index Cond: (id < 1000)
(2 rows)postgres=#
可以看到,索引扫描的成本降低了。
我们必须把成本看作是“相对的”。绝对的数字并不重要——重要的是一个计划与其他计划相比有多贵。
如果顺序扫描的成本保持不变,而索引扫描的价格相对于顺序扫描下降了,PostgreSQL会更倾向于索引。这正是effective_cache_size的核心内容:在有大量RAM的情况下,更有可能进行使用索引扫描。
当谈及如何配置postgres.conf文件中的effective_cache_size的设置的时候,往往没有意识到并不会有什么神奇的效果。
postgres=# set effective_cache_size to '1 MB';
SET
postgres=# explain SELECT * FROM t_ordered WHERE id < 1000;QUERY PLAN
---------------------------------------------------------------------------------Index Scan using idx_ordered on t_ordered (cost=0.42..38.85 rows=996 width=12)Index Cond: (id < 1000)
(2 rows)postgres=# SET effective_cache_size TO '1000 GB';
SET
postgres=# explain SELECT * FROM t_ordered WHERE id < 1000;QUERY PLAN
---------------------------------------------------------------------------------Index Scan using idx_ordered on t_ordered (cost=0.42..38.85 rows=996 width=12)Index Cond: (id < 1000)
(2 rows)postgres=#
优化器使用的表统计信息包含关于物理“相关性”的信息。如果相关性是1,即所有数据是有序的在磁盘上。effective_cache_size并不会改变什么。
如果只有一个列,同样也不会有什么效果:
postgres=# ALTER TABLE t_random DROP COLUMN r;
ALTER TABLE
postgres=# SET effective_cache_size TO '1 MB';
SET
postgres=# explain SELECT * FROM t_random WHERE id < 1000;QUERY PLAN
-----------------------------------------------------------------------------------Index Only Scan using idx_random on t_random (cost=0.42..28.88 rows=940 width=4)Index Cond: (id < 1000)
(2 rows)postgres=# SET effective_cache_size TO '1000 GB';
SET
postgres=# explain SELECT * FROM t_random WHERE id < 1000;QUERY PLAN
-----------------------------------------------------------------------------------Index Only Scan using idx_random on t_random (cost=0.42..28.88 rows=940 width=4)Index Cond: (id < 1000)
(2 rows)postgres=#
调优建议:
effective_cache_size = RAM * 0.7
如果是pg专用服务器,也可以考虑设置为RAM*0.8。
2. 案例二
effective_cache_size 是一个用于告诉 PostgreSQL 查询规划器关于系统中可用缓存的估计信息的配置参数。它的设置影响着 PostgreSQL 查询优化器对于不同查询计划的成本估算,从而影响了 PostgreSQL 查询优化器选择最佳执行计划的方式。
下面是一个使用 effective_cache_size 参数的案例:
假设你有一个数据库,其中包含大量的表和数据。在某次查询中,你需要从一个包含大量数据的表中检索信息,比如一个产品销售表。
SELECT * FROM sales_data WHERE product_id = 'XYZ';
在没有充足的缓存情况下,数据库可能需要频繁地从磁盘读取数据块以满足查询需求,这会增加查询的执行时间。
通过配置 effective_cache_size 参数,你可以告诉 PostgreSQL 查询优化器关于系统中可用缓存的估计信息,从而影响查询优化器的成本估算,这可能导致选择不同的查询执行计划。
假设你的系统有足够的内存,并且已经对 effective_cache_size 进行了适当的设置,PostgreSQL 查询优化器会认为系统中有更多的缓存可用。在这种情况下,它可能更倾向于选择全表扫描而不是索引扫描,因为它认为大部分数据已经在缓存中,并且全表扫描可能更快。
然而,如果 effective_cache_size 设置得太小,查询优化器会认为系统中的缓存较少,可能会倾向于选择索引扫描,因为它认为从磁盘中读取少量数据会更快。
因此,effective_cache_size 参数的调整会影响查询执行计划的选择。合理设置这个参数可以帮助 PostgreSQL 优化器更准确地估计查询成本,选择更有效的执行计划,提高查询性能。
需要注意的是,这个参数的最佳设置取决于实际的硬件资源、负载和数据库工作负载等因素。通常需要进行实际测试和性能监控来确定最佳的配置值。
2.1. 如果字段上增加了索引也不一定
在正常情况下,如果 product_id 字段上存在合适的数据索引,PostgreSQL 应该会倾向于使用该索引来执行与 product_id 相关的查询。使用索引可以大大提高查询性能,因为它允许 PostgreSQL 快速定位到符合条件的数据行,而不必进行全表扫描。
然而,即使存在索引,有时候 PostgreSQL 也可能会选择不使用索引而是进行全表扫描。这种情况可能出现在以下情况下:
-
成本估算错误: 如果查询优化器错误地估计了索引扫描和全表扫描的成本,它可能会选择全表扫描而不是索引扫描。这种情况下,调整
effective_cache_size参数可能会影响优化器的估算,使其更倾向于选择索引扫描。 -
索引不适用: 在某些情况下,即使存在索引,PostgreSQL 也可能选择不使用索引。例如,如果查询条件不是索引的前缀,或者查询条件使用了函数,这可能导致索引无法被使用。此外,如果统计信息不准确或者索引被损坏,也可能导致索引不被选择。
-
数据分布不均匀: 如果数据分布不均匀,即索引列上的值分布不均匀,有时候优化器可能会认为全表扫描更有效率,尤其是当需要检索大部分数据行时。
在这些情况下,虽然有索引但可能仍然会进行全表扫描。这种情况下可以考虑重新分析索引、收集统计信息、优化查询语句或者调整 PostgreSQL 的配置参数来影响查询规划器的行为。
总的来说,虽然索引可以大幅提高查询性能,但 PostgreSQL 的查询规划器决定执行计划的选择不仅取决于索引的存在,还受到多种因素的影响。合适地配置索引、收集统计信息、优化查询语句以及调整配置参数都是优化查询性能的重要步骤。
相关文章:

postgresql-effective_cache_size参数详解
在 PostgreSQL 中,effective_cache_size 是一个配置参数,用于告诉查询规划器关于系统中可用缓存的估计信息。这个参数并不表示实际的内存量,而是用于告诉 PostgreSQL 查询规划器系统中可用的磁盘缓存和操作系统级别的文件系统缓存的大小。它用…...

CUDA锁页内存的使用
1.定义指针变量 float *host_Weights; // 锁页内存 float *dev_Weights; // 设备端内存2.分配内存 cudaHostAlloc((void**)&host_Weights, numInputs * sizeof(float), cudaHostAllocDefault); // 用锁页内存,可以有效加快数据传递速度 cudaMalloc((vo…...

python常见代码用法
1.result [[]] * n 和 result [[] for _ in range(n)] 辨析 n 3 result [[]] * nprint(result) # 输出:[[], # [], # []]print(result[0] is result[1] is result[2]) # 输出:True* 运算符进行复制,这些空列表实际…...

MTU TCP-MSS(转载)
MTU MTU 最大传输单元(Maximum Transmission Unit,MTU)用来通知对方所能接受数据服务单元的最大尺寸,说明发送方能够接受的有效载荷大小。 是包或帧的最大长度,一般以字节记。如果MTU过大,在碰到路由器时…...
 高级篇 20 -- SNOOPer 使用介绍】)
【ARM Trace32(劳特巴赫) 高级篇 20 -- SNOOPer 使用介绍】
请阅读【Trace32 ARM 专栏导读】 文章目录 Trace32 SNOOPer 介绍SNOOPer 主要功能:SNOOPer 使用场景SNOOPer.ERRORSTOPSNOOPer.ModeSNOOPer.PCSNOOPer.RateSNOOPer.SELectSNOOPer.SIZESNOOPer.TDelaySNOOPer.TOutSNOOPer.TValueSNOOPer PC 采样Trace32 SNOOPer 介绍 在 Laut…...

MySQL笔记-第11章_数据处理之增删改
视频链接:【MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板】 文章目录 第11章_数据处理之增删改1. 插入数据1.1 实际问题1.2 方式1:VALUES的方式添加1.3 方式2:将查询结果插入到表中 2. 更…...
)
ANSYS常见error解答(转)
根据SimC结构工作室这段时间的答疑总结,给出了部分关于ANSYS常见error的解释说明,希望对大家有所帮助。 1.KBC is not a recognized BEGIN command, abbreviation, or macro.This command will be ignored. 答:ANSYS 对命令的使用有严格的规…...

【Let‘s Encrypt SSL】使用 acme.sh 给 Nginx 安装 Let’s Encrypt 提供的免费 SSL 证书
安装acme.sh 安装 acme.sh 并设置邮箱用来接受重要通知,如证书快过期未更新通知 curl https://get.acme.sh | sh -s emailmyexample.com执行命令后几秒就安装好了,如果半天没有反应请 CtrlC 后重新执行命令。acme.sh 安装在 ~/.acme.sh 目录下…...

XML学习及应用
介绍XML语法及应用 1.XML基础知识1.1什么是XML语言1.2 XML 和 HTML 之间的差异1.3 XML 用途 2.XML语法2.1基础语法2.2XML元素2.3 XML属性2.4XML命名空间 3.XML验证3.1xml语法验证3.2自定义验证3.2.1 XML DTD3.2.2 XML Schema3.2.3PCDATA和CDATA区别3.2.4 参考 4.xml解析4.1准备…...
Docker部署Nacos集群并用nginx反向代理负载均衡
首先找到Nacos官网给的Github仓库,里面有docker compose可以快速启动Nacos集群。 文章目录 一. 脚本概况二. 自定义修改1. example/cluster-hostname.yaml2. example/.env3. env/mysql.env4. env/nacos-hostname.env 三、运行四、nginx反向代理,负载均衡…...

C++STL的stack和queue(超详解)
文章目录 前言stack栈的题目最小栈JZ31 栈的压入、弹出序列150. 逆波兰表达式求值 stack的模拟实现queue的模拟实现dequedeque底层设计 前言 栈和队列这一块其实有数据结构的基础,学起来非常简单。 stack 栈的成员函数就这么写,除了emplace其他都已经非…...

【C语言实现windows环境下Socket编程TCP/IP协议】
C语言实现windows环境下Socket编程TCP/IP协议 主要是记录解决一些在我本地编译运行时出现的问题connect :No error关于头文件关于stray /xxx和socket:No error问题千万记得是服务器先启动哦,客户端后启动下面附上我改好的代码 主要是记录解决…...

CGAL的3D简单网格数据结构
由具有多个曲面面片的多面体曲面生成的多域四面体网格。将显示完整的三角剖分,包括属于或不属于网格复合体、曲面面片和特征边的单元。 1、网格复合体、 此软件包致力于三维单纯形网格数据结构的表示。 一个3D单纯形复杂体由点、线段、三角形、四面体及其相应的组合…...

正则表达式(9):扩展正则表达式
正则表达式(9):扩展正则表达式 小结 本博文转载自 前文中一直在说,在Linux中,正则表达式可以分为”基本正则表达式”和”扩展正则表达式”。 我们已经认识了”基本正则表达式”,现在,我们来认…...

静态SOCKS5:了解基本概念和协议
SOCKS5是一种网络协议,是SOCKS协议的第五个版本,它提供了一种安全的、加密的网络连接,可以帮助用户在互联网上保护自己的隐私和安全。静态SOCKS5是指使用静态IP地址和端口的SOCKS5代理服务器,这种代理服务器可以提供更稳定、更快速…...
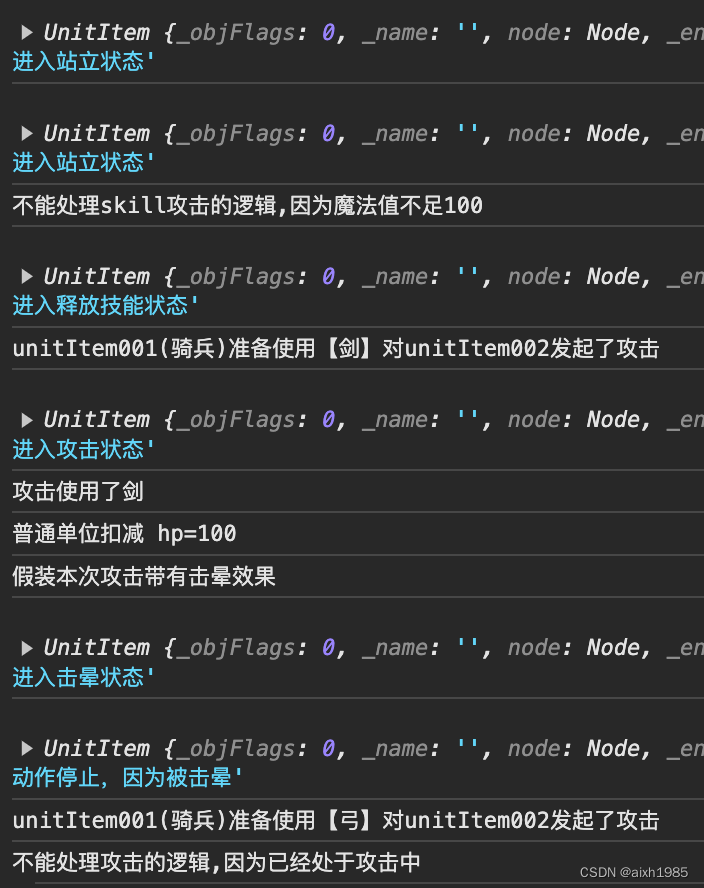
用23种设计模式打造一个cocos creator的游戏框架----(十二)状态模式
1、模式标准 模式名称:状态模式 模式分类:行为型 模式意图:允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 结构图: 适用于: 1、一个对象的行为决定于它的状态,并且它必须…...

js 转换为数组并返回(Array.of())
Array提供了方法直接将一组值转换为数组并返回 Array.of()方法 Array.of(1,2,3) 结果...

git上传文件夹后打不开,有@.....
这种情况是你上传的这个文件夹也是个git仓库,需要删除.git文件。 如果你删除.git文件后,上传git还是不行,文件夹还是…,那就需要清理以下整个项目的缓存: git rm -r --cached ....

31、应急响应——Windows
文章目录 一、账户排查1.1 登录服务器的途径1.2 弱口令1.3 可疑账号 二、网络排查三、进程排查四、注册表排查五、内存分析 一、账户排查 1.1 登录服务器的途径 3389smb 445httpftp数据库中间件 1.2 弱口令 弱口令途径:3389、smb 445、http、ftp、数据库、中间件…...

QT linux下使用Qt Creator调试附加进程,加快调试
文章目录 一、调试附加进程二、配置流程(1)开放linux内核配置项(2)命令行直接启动程序(3)调试附加到进程 一、调试附加进程 使用附加进程调试要比直接调试速度要快,但是不足之处是,…...

客户月亏30万才醒悟:低价模具,才是最昂贵的选择
一、客户困境:贪小利省2万,终致月亏30万、天天停机一位专注小家电外壳生产的客户,在模具采购时,一心想压缩成本,最终选择了比常规方案便宜2万元的低价模具。初期试模阶段,产品外观、尺寸看似无异常…...
)
从‘亮灯’到‘定位’:一个真实商用车J1939故障排查全记录(含DM1多包传输解析)
从‘亮灯’到‘定位’:一个真实商用车J1939故障排查全记录(含DM1多包传输解析) 1. 故障现象与初步诊断 那是一个普通的周二早晨,维修车间接到一辆6x4牵引车的报修单——仪表盘上的MIL(故障指示灯)持续点亮。…...

量子计算中SIMD编译优化与离子阱架构实践
1. 量子计算中的SIMD编译优化概述量子计算正逐步从理论走向实践,而离子阱架构因其长相干时间和高保真度操作成为当前最有前景的物理实现方案之一。在传统量子编译器中,指令调度往往采用串行执行模式,导致离子传输和量子门操作存在大量等待时间…...
,解决黑砖 / Bootloop 难题)
1.解锁 Bootloader + 线刷 + 基带恢复,高通 EDL 模式自动化刷机(Python 脚本),解决黑砖 / Bootloop 难题
摘要 本文以工程化视角系统阐述主流品牌手机刷机维修的底层原理与标准化操作流程。覆盖高通、联发科、苹果A系列芯片平台的刷机协议、分区表结构、恢复模式触发机制及底层通信协议。提供可复现的Python自动化刷机脚本与adb/fastboot命令矩阵,解决变砖、Bootloop、基…...

基础知识丨JAVA序列化与反序列化漏洞
今天在学习的时候又接触到了JAVA反序列化漏洞。一直只知道JAVA反序列化就是利用反序列化工具进行攻击,在目标系统中执行命令,利用的就是传输对象时采用JAVA序列化。但是也只知道这么多了。所以,就想着今天再了解一下反序列化漏洞。顺便&#…...

2026届必备的五大AI科研神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术迅猛发展,论文AI工具在学术研究领域正慢慢变成重要辅助,…...

微控制器自检技术:从原理到实践,构建嵌入式系统的可靠性基石
1. 为什么微控制器自检不是“可有可无”的选项?如果你是一名嵌入式开发者,或者你的产品里用到了单片机,那你一定遇到过这样的场景:产品在实验室里跑得好好的,一到客户现场就莫名其妙死机;或者设备运行了几个…...

如何用Win11Debloat轻松优化Windows系统:完整指南
如何用Win11Debloat轻松优化Windows系统:完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...
)
linux内核源码内存管理(7)
一、 引言:冲破冯诺依曼瓶颈的壁障在传统的单处理器(UMA,Uniform Memory Access)架构中,所有CPU核心通过同一条总线平等地访问所有内存。这种对称性带来了编程模型的简洁,但也埋下了致命的可扩展性陷阱&…...
M.2 SSD系统迁移实战:从克隆到无缝启动)
【玩转Jetson TX2 NX】(四)M.2 SSD系统迁移实战:从克隆到无缝启动
1. 为什么需要将系统迁移到M.2 SSD? Jetson TX2 NX作为一款嵌入式AI计算设备,默认搭载的eMMC存储空间往往捉襟见肘。我在实际项目中发现,16GB的eMMC在安装完JetPack系统后,剩余空间连一个中等规模的深度学习模型都放不下。更不用…...