【起草】1-2 讨论 ChatGPT 在自然语言处理领域的重要性和应用价值
【小结:ChatGPT 在自然语言处理领域的八种典型应用】
ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式在海量无标注数据集上进行预训练,能够实现对人类语言自然、流畅、连贯的生成和理解。作为自然语言处理技术中的一种重要模型,ChatGPT受到了广泛的关注。它不仅具有高度的自主性和智能性,还可以进行多轮对话、文案创作等方面的工作。
在聊天、问答、翻译、语音识别等方面表现出色,具有很高的应用价值。具体来说,ChatGPT的应用主要体现在以下几个方面:
1. 聊天机器人:ChatGPT可以理解用户的意图,并生成符合用户意图的多轮回复,增强用户在对话互动模式下的体验。
2. 文本生成:ChatGPT可以生成高质量的自然语言文本,用于各种场景,如文章写作、广告文案等。
3. 自动摘要:ChatGPT可以对长篇文章进行理解和分析,提取出关键信息,并生成简洁、准确的摘要。
4. 文本分类:ChatGPT可以理解文本的主题和内容,对文本进行分类。
5. 命名实体识别:ChatGPT可以识别文本中的实体,如人名、地名、机构名等。
6. 情感分析:ChatGPT可以理解文本中的情感倾向,对文本进行情感分析。
7. 机器翻译:ChatGPT可以理解源语言和目标语言,实现高质量的机器翻译。
8. 语音识别:ChatGPT可以理解用户的语音输入,将语音转换为文本。
具体应用场景展开如下:
1. 聊天机器人:ChatGPT是一种基于深度学习的聊天机器人模型,能够理解用户输入的自然语言,并生成相应的回复。它通过预训练的方式学习了大量的语言知识,包括语法、语义和上下文等,从而能够进行多轮对话,并提供准确、流畅的回答。
2. 文本生成:ChatGPT可以用于生成各种类型的自然语言文本,如文章、故事、广告文案等。它可以根据给定的上下文或主题,自动生成连贯、有逻辑的文本内容,帮助用户节省时间和精力。
3. 自动摘要:ChatGPT可以将长篇文章或文档进行理解和分析,提取出关键信息,并生成简洁、准确的摘要。它可以识别文章中的主题句和关键词,并根据这些信息生成概括性的摘要,方便用户快速了解文章的内容。
4. 文本分类:ChatGPT可以理解文本的主题和内容,对文本进行分类。它可以将文本分为不同的类别,如新闻、体育、娱乐等,帮助用户快速浏览和筛选感兴趣的内容。
5. 命名实体识别:ChatGPT可以识别文本中的实体,如人名、地名、机构名等。它可以从文本中提取出这些实体,并进行标注和分类,帮助用户更好地理解和分析文本。
6. 情感分析:ChatGPT可以理解文本中的情感倾向,对文本进行情感分析。它可以判断文本是正面、负面还是中性的情感,帮助用户了解文本的情感色彩和态度。
7. 机器翻译:ChatGPT可以实现高质量的机器翻译。它可以理解源语言和目标语言之间的语义差异,并生成准确、流畅的翻译结果,帮助用户进行跨语言交流和理解。
8. 语音识别:ChatGPT可以理解用户的语音输入,将语音转换为文本。它可以将用户的语音指令或对话转化为可处理的文本形式,实现语音交互和语音控制等功能。
【2-1 聊天机器人的系统逻辑】
聊天机器人的系统逻辑主要包括以下几个步骤:
1. 用户输入自然语言文本。
2. 聊天机器人接收到用户的输入。
3. 聊天机器人使用预训练模型对用户输入进行理解。
4. 聊天机器人根据理解的结果生成回复。
5. 聊天机器人将回复发送给用户。
6. 用户收到回复并继续与聊天机器人交互。
具体来说,聊天机器人的系统逻辑可以按照以下方式实现:
1. 用户输入自然语言文本:用户通过键盘或语音等方式输入自然语言文本,例如:“你好,我想了解一下天气情况。”
2. 聊天机器人接收到用户的输入:聊天机器人接收到用户的输入后,将其存储在内存中,以便后续处理。
3. 聊天机器人使用预训练模型对用户输入进行理解:聊天机器人使用预训练模型对用户输入进行理解。预训练模型是一种基于大量无标注数据进行训练的模型,可以学习到自然语言的语义和语法知识。通过使用预训练模型,聊天机器人可以理解用户输入的意图和需求。
4. 聊天机器人根据理解的结果生成回复:聊天机器人根据理解的结果生成回复。这通常包括从预先定义的对话模板中选择适当的回复,或者根据理解的结果生成自定义的回复。例如,如果聊天机器人理解到用户想要查询天气情况,它可能会生成类似于“今天的天气是晴朗,最高温度为28摄氏度”的回复。
5. 聊天机器人将回复发送给用户:聊天机器人将生成的回复发送给用户。用户可以通过屏幕、语音或其他方式接收到回复。
6. 用户收到回复并继续与聊天机器人交互:用户收到回复后,可以继续与聊天机器人进行交互。例如,用户可以继续询问其他问题,或者结束对话。
【2-2 文本生成流程的系统逻辑】
ChatGPT是一种基于深度学习的自然语言生成模型,其文本生成流程和逻辑可以分为以下几个步骤:
1. 数据预处理:首先,需要对输入的文本进行预处理。这包括将文本转换为模型可接受的格式,例如分词、去除停用词等。同时,还需要将文本转换为对应的向量表示,以便模型能够理解和处理。
2. 编码器:在预处理完成后,输入的文本将被送入一个编码器中。编码器的作用是将输入的文本序列转化为一个固定长度的向量表示,这个向量包含了输入文本的语义信息。常用的编码器有循环神经网络(RNN)、长短时记忆网络(LSTM)和Transformer等。
3. 解码器:编码器的输出将作为解码器的输入,解码器的作用是根据编码器的输出生成目标文本序列。解码器通常也是一个循环神经网络,它可以逐个生成目标文本的单词或字符。
4. 训练模型:在模型训练阶段,使用大量的文本数据来训练模型。这些数据可以是人工标注的数据集,也可以是未标注的大规模文本数据。通过训练模型,使其能够学习到输入文本和目标文本之间的映射关系,从而能够根据输入生成相应的目标文本。
5. 生成文本:当模型训练完成后,可以使用它来生成新的文本。给定一个初始的输入文本,模型将通过编码器将其转化为向量表示,然后通过解码器逐个生成目标文本的单词或字符。这个过程可以持续进行,直到生成完整的目标文本序列。
需要注意的是,ChatGPT是基于预训练的语言模型,它在大规模的文本数据上进行了预训练,学习到了丰富的语言知识和语义信息。这使得它能够在各种自然语言生成任务中表现出色,如对话生成、文章摘要生成等。此外,ChatGPT还具有一定的上下文理解能力,可以根据上下文信息生成连贯、合理的文本。
在自然语言处理(NLP)中,"Token"是文本中的一个基本单位,具体可以是单词、词组、标点符号或字符等,这根据文本处理的需求和方法而定。在将文本划分为若干个token的过程中,我们称之为“tokenization”。
对于深度学习生成序列数据的方法,通常使用前面的token作为输入,训练一个网络(如RNN或CNN)来预测序列中接下来的一个或多个token。这个过程可以看作是对下一个token的概率进行建模,完成这个任务的网络被称为语言模型(language model)。
特别地,如果我们谈论的是像GPT这样的模型,它的内部逻辑会稍有不同。GPT模型使用字节对编码 (Byte Pair Encoding, BPE) 来进行tokenization。BPE是一种 subword tokenization 方法,它将文本分解为子词或字符的序列,这些子词或字符的组合可以更有效地捕获语言的语义信息。
总的来说,文本生成Token的内在逻辑包括了文本预处理(tokenization)、使用特定网络结构(如RNN、LSTM或Transformer)进行训练和预测,以及可能使用的特定的tokenization方法(例如BPE)。这些步骤共同构成了模型理解和生成语言的基础。
总的来说,ChatGPT的文本生成流程和逻辑是通过编码器将输入文本转化为向量表示,然后通过解码器逐个生成目标文本的单词或字符。通过训练模型使其能够学习到输入文本和目标文本之间的映射关系,从而能够根据输入生成相应的目标文本。ChatGPT具有强大的语言理解和生成能力,可以在各种自然语言生成任务中取得优秀的效果。
【2-3 文章生成自动摘要的系统逻辑】
ChatGPT是一种基于深度学习的自然语言处理模型,其生成摘要的内在逻辑主要包括了理解、提取和生成三个步骤。
在理解阶段,ChatGPT会对输入的文章进行分析和理解,自动提取出关键信息和要点。这一步骤可能涉及到对文章的主题、结构以及重要观点的理解。例如,对于商品评论,模型需要理解每一条评论是在描述商品的哪个方面,如品质、物流等。
接下来是提取阶段,这一阶段的目标是从原文中抽取出重要的信息,同时保留原文的逻辑结构和语境含义。这个阶段可能需要根据上一个阶段的理解结果,对文章的关键信息进行提取。
最后是生成阶段,ChatGPT利用之前提取的关键信息生成摘要。生成的摘要需要简洁明了,能够准确地反映出原文的主要内容。此外,生成的摘要还需要保持与原文相同的语境和语义,以使读者可以通过阅读摘要来了解原文的主要信息。
需要注意的是,这个过程并不是简单的复制粘贴或替换,而是需要模型具备对自然语言的深度理解和处理能力。这也是为什么ChatGPT能够在文本摘要、推断和转换这些常见的NLP任务中表现出色的原因。
【2-4 文本分类的系统逻辑】
ChatGPT在执行互联网文本分类任务时,其内在逻辑主要涉及到数据预处理、模型定义、训练和评估等环节。
首先,数据预处理是整个流程的开始,包括将原始文本数据进行清洗、格式化,并将文本划分成一个个的句子或段落。然后,这些句子或段落会被转换为单词的编码序列。
接下来是模型定义阶段,这一步骤涉及到确定Transformer模型的结构。Transformer是一种广泛应用于自然语言处理任务的深度学习模型,由编码器和解码器两部分组成,并使用了多头注意力机制等技术。
在模型定义完成后,下一步是训练模型。在训练过程中,模型会输入一段文本,预测输出结果,并通过计算损失函数(通常是交叉熵损失函数)来评估模型预测值与真实值的差距。随后通过反向传播算法更新模型参数,使模型逐渐学习和理解文本的内在规律和结构。
最后,在训练过程中,需要定期对模型在验证集上的表现进行评估。如果模型表现不佳,可能需要调整模型结构或者增大训练量。当模型达到预期的效果后,就可以保存训练好的模型参数,为后续的互联网文本分类任务提供支持。
值得一提的是,虽然ChatGPT是一款强大的预训练语言模型,但在面对新的领域或者话题时,它可能还需要进一步的微调才能达到最好的效果。
使用ChatGPT进行网络爬取内容的自动分类,主要涉及到数据抓取、文本预处理和模型训练等步骤。
首先,可以利用ChatGPT编写Python代码来实现自动抓取网站数据的功能。具体来说,可以模仿人类浏览网页的行为,通过模拟发送网络请求,获取到目标网页的HTML源代码。此外,还可以将网络请求导出为HAR文件后上传至ChatGPT Code Interpreter插件,让ChatGPT自主完成爬虫代码的编写。
接下来是文本预处理阶段,需要对爬取到的原始文本数据进行清洗和格式化,例如去除HTML标签、去掉停用词等。同时,还需要将文本划分成一个个的句子或段落,并将这些句子或段落转换为单词的编码序列。
然后,利用ChatGPT的强大代码能力,可以根据预处理后的文本数据训练一个文本分类模型。这个模型可以是任何适用于文本分类任务的深度学习模型,例如基于Transformer的模型。在训练过程中,模型会输入一段文本,预测输出结果,并通过计算损失函数来评估模型预测值与真实值的差距。随后通过反向传播算法更新模型参数,使模型逐渐学习和理解文本的内在规律和结构。
最后,在训练过程中,需要定期对模型在验证集上的表现进行评估。如果模型表现不佳,可能需要调整模型结构或者增大训练量。当模型达到预期的效果后,就可以保存训练好的模型参数,为后续的网络爬取内容进行自动分类提供支持。
【2-5 命名实体的系统逻辑】
ChatGPT在进行命名实体识别(NER)时,主要通过学习和理解文本中的上下文信息,识别出具有特定意义的实体,如人名、地名、组织机构名等。
首先,ChatGPT会接收一段输入文本,并对其进行编码处理,将每个单词转化为向量形式以便于计算机进行数学运算。然后,模型会对这段文本进行分析和理解,提取出关键信息和实体类型。
接下来,模型会根据上一步提取的实体类型信息,在文本中标注出对应的实体。例如,如果模型判断出一段文本中的"苹果"是指代一个公司而非水果,那么它就会将"苹果"标注为组织机构名。
最后,模型会输出标注后的文本,即完成了命名实体识别的任务。值得一提的是,ChatGPT的强大预训练能力使得它可以自动进行标注任务,无需额外的人工标注。此外,模型对于新的领域或者话题可能需要进一步的微调才能达到最好的效果。
以下是三个使用ChatGPT进行命名实体识别(NER)的应用例子:
1. 新闻摘要生成:通过将一篇新闻文章输入到ChatGPT中,模型可以自动提取出文章中的关键信息和实体,如人名、地名、组织机构名等。然后,模型可以根据这些信息生成一个简洁的新闻摘要,帮助读者快速了解新闻内容。
2. 智能问答系统:在智能问答系统中,用户可能会提出一些包含实体的问题,如"苹果公司的创始人是谁?"。通过将问题输入到ChatGPT中,模型可以自动识别出问题中的实体,并给出相应的答案。
3. 情感分析:在情感分析任务中,需要对一段文本的情感倾向进行分析。通过将文本输入到ChatGPT中,模型可以自动提取出文本中的实体,并根据这些实体的情感倾向来判断整段文本的情感倾向。例如,如果一段评论中提到了多个负面的人名或组织机构名,那么模型可能会判断这段评论是负面的。
【2-6. 情感分析】
ChatGPT在进行情感分析时,首先会对输入的文本进行深度理解和编码处理,将每个ChatGPT在进行情感分析时,首先会对输入的文本进行深度理解和编码处理,将每个单词转化为向量形式以便于计算机进行数学运算。模型会通过捕捉上下文信息以及学习语言模式来理解文本的情感色彩。
然后,模型会根据它对文本内容的理解,确定文本的整体情感倾向,如正面、负面或中性等。例如,在分析一段评论时,如果评论中出现了许多正面的词汇,那么模型可能会判断这段评论是正面的。
此外,ChatGPT还具备处理复杂对话和多轮对话的能力,这意味着它可以基于前文的对话内容来理解和生成回复,使得其生成的结果更为连贯和相关。然而,这也可能导致一个问题,即同一个文本在不同上下文中可能会得到不同的情感分析结果。
以下是五个使用ChatGPT进行情感分析的应用场景:
1. 社交媒体监控:企业可以使用ChatGPT来监控社交媒体上关于其品牌或产品的评论和反馈,以了解公众对其的看法。如果发现负面评论较多,企业可以及时采取措施改进产品或服务。
2. 客户服务:在处理客户投诉时,ChatGPT可以帮助客服人员快速理解客户的情绪,从而提供更为个性化的服务。例如,如果客户的语气非常愤怒,那么客服人员可能需要采取更为冷静和专业的态度来处理问题。
3. 市场研究:通过分析消费者对某个产品或服务的评论,ChatGPT可以帮助企业了解市场需求和趋势,从而制定更有效的市场策略。
4. 舆情分析:政府和非营利组织可以使用ChatGPT来监控公众对其政策或活动的反应,以便及时调整策略。
5. 产品开发:在产品开发过程中,ChatGPT可以帮助团队理解用户的需求和期望,从而设计出更符合用户需求的产品。
【2-7. 机器翻译】
ChatGPT是一种基于深度学习的自然语言处理模型,可以用于机器翻译任务。其内部逻辑主要包括以下几个步骤:
1. 数据预处理:在进行机器翻译之前,需要对原始文本进行预处理,包括分词、去除停用词、构建词汇表等操作。这些操作可以帮助模型更好地理解输入文本,并提高翻译质量。
2. 编码器-解码器结构:ChatGPT采用了编码器-解码器结构来进行机器翻译。编码器将输入文本编码成一个固定长度的向量表示,解码器则根据这个向量生成输出文本。这种结构可以使模型在处理长句子时更加高效,并且能够捕捉到输入和输出之间的上下文信息。
3. 自注意力机制:在编码器和解码器中,ChatGPT使用了自注意力机制来帮助模型关注输入文本中的不同部分。自注意力机制可以让模型在生成输出文本时,根据当前位置和之前的上下文信息来选择最合适的单词或短语。这种机制可以提高模型的翻译质量和流畅度。
4. 预训练和微调:为了提高模型的性能,ChatGPT使用了预训练和微调的方法。在预训练阶段,模型会在大规模的无标签数据上进行训练,以学习自然语言处理的基本知识和语言规律。在微调阶段,模型会在有标签的数据上进行训练,以适应具体的机器翻译任务。这种方法可以使模型更好地适应不同的语言和领域,并提高翻译质量。
5. 生成式翻译:ChatGPT采用了生成式翻译方法来进行机器翻译。与传统的统计机器翻译方法不同,生成式翻译方法可以直接生成输出文本,而不需要依赖于大量的人工规则和特征工程。这种方法可以使模型更加灵活和自适应,并且能够生成更加自然和流畅的翻译结果。
以下是三个中文翻译成英文的例子:
1. 例子一:你好,我是小明。你叫什么名字?Hello, I'm Xiaoming. What's your name?
2. 例子二:今天天气很好,我们去公园玩吧。Today the weather is very good, let's go to the park and play.
3. 例子三:我喜欢吃中餐,比如炒饭和面条。I like to eat Chinese food, such as fried rice and noodles.
在中文翻译英文的,进行分词翻译:
在中文翻译成英文的例子中,GPT首先会将输入的中文文本进行分词,将其标注为一系列的token。例如,“你好,我是小明。你叫什么名字?”这句话会被分成三个token:“你好”、“我是小明”和“你叫什么名字”。
然后,GPT会将这些token编码成一个固定长度的向量表示,这个向量可以捕捉到每个token的语义信息。接下来,GPT会使用自注意力机制来帮助模型关注输入文本中的不同部分,并根据当前位置和之前的上下文信息来选择最合适的单词或短语。最后,GPT会根据这个向量生成输出文本,并将其翻译成英文。
以第一个例子为例,GPT可能会将“你好”翻译为“Hello”,将“我是小明”翻译为“I'm Xiaoming”,将“你叫什么名字”翻译为“What's your name”。最终生成的英文翻译就是:“Hello, I'm Xiaoming. What's your name?”
【2-8. 语音识别】
相关文章:

【起草】1-2 讨论 ChatGPT 在自然语言处理领域的重要性和应用价值
【小结:ChatGPT 在自然语言处理领域的八种典型应用】 ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式ChatGPT是一种基于Transformer模型的端到端生成式对话系统,采用自监督学习的方式在海量无标注数据集上进…...

Mapreduce小试牛刀(1)
1.与hdfs一样,mapreduce基于hadoop框架,所以我们首先要启动hadoop服务器 --------------------------------------------------------------------------------------------------------------------------------- 2.修改hadoop-env.sh位置JAVA_HOME配…...
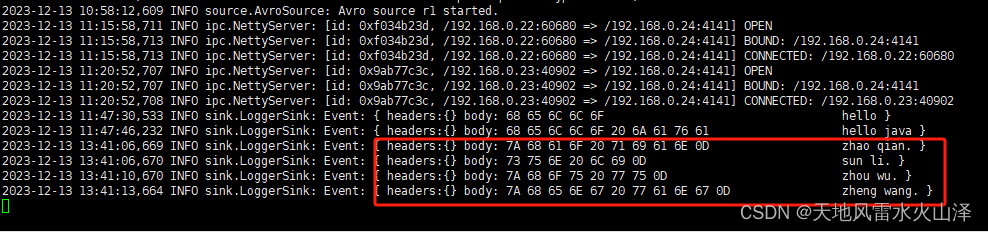
二百一十七、Flume——Flume拓扑结构之聚合的开发案例(亲测,附截图)
一、目的 对于Flume的聚合拓扑结构,进行一个开发测试 二、聚合 (一)结构含义 这种模式是我们最常见的,也非常实用。日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器产生的日志,处理起来…...

vue3+ts+vite+element plus 实现table勾选、点击单行都能实现多选
需求:table的多选栏太小,点击的时候要瞄着点,不然选不上,要求实现点击单行实现勾选 <ElTableborder:data"tableDataD"style"width: 100%"max-height"500"ref"multipleTableRef"selec…...
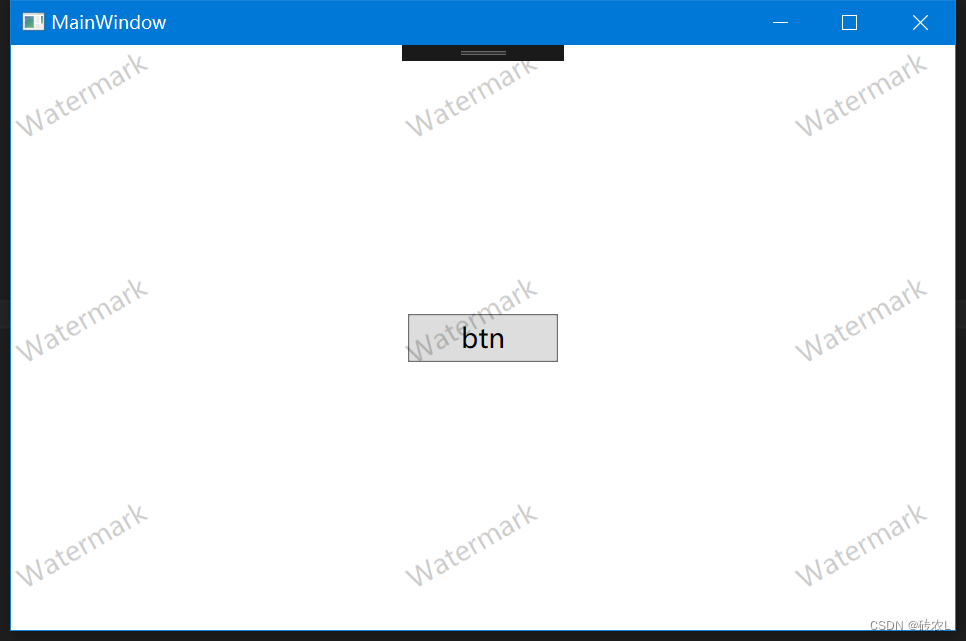
在WPF窗口中增加水印效果
** 原理: ** 以Canvas作为水印显示载体,在Canvas中创建若干个TextBlock控件用来显示水印文案,如下图所示 然后以每一个TextBlock的左上角为中心旋转-30,最终效果会是如图红线所示: 为了达到第一行旋转后刚好与窗口…...

wget下载到一半断了,重连方法
我是使用wget去下载 data.tar.gz 压缩包 wget https://deepgo.cbrc.kaust.edu.sa/data/deepgozero/data.tar.gz一开始下载的挺快,然后随着下载继续,下载速度就一直在下滑 下了大概2个小时后,已经下载了78%(6G/7.7G)就断了。无奈c…...

Docker笔记:docker compose部署项目, 常用命令与负载均衡
docker compose的作用 docker-compose是docker官方的一个开源项目可以实现对docker容器集群的快速编排docker-compose 通过一个配置文件来管理多个Docker容器在配置文件中,所有的容器通过 services来定义然后使用docker-compose脚本来启动,停止和重启容…...

Java单元测试:JUnit和Mockito的使用指南
引言: 在软件开发过程中,单元测试是一项非常重要的工作。通过单元测试,我们可以验证代码的正确性、稳定性和可维护性,帮助我们提高代码质量和开发效率。本文将介绍Java中两个常用的单元测试框架:JUnit和Mockito&#x…...

缓存雪崩问题与应对策略
目录 1. 缓存雪崩的原因 1.1 缓存同时失效 1.2 缓存层无法应对高并发 1.3 缓存和后端系统之间存在紧密关联 2. 缓存雪崩的影响 2.1 系统性能下降 2.2 数据库压力激增 2.3 用户请求失败率增加 3. 应对策略 3.1 多级缓存 3.2 限流与降级 3.3 异步缓存更新 3.4 并发控…...

python编程需要的电脑配置,python编程用什么电脑
大家好,小编来为大家解答以下问题,python编程对笔记本电脑配置的要求,python编程对电脑配置的要求有哪些,现在让我们一起来看看吧! 学习python编程需要什么配置的电脑 简单的来讲,Python的话普通电脑就可以…...
)
目标检测YOLO实战应用案例100讲-基于深度学习的跌倒检测(续)
目录 3.3 基于YOLOv7算法的损失函数优化 3.3.1 IoU损失策略 3.3.2 GIoU回归策略 3.3.3...
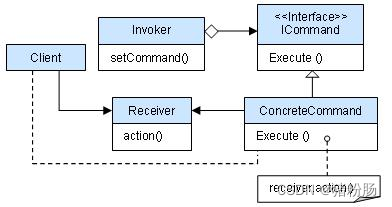
05-命令模式
意图(GOF定义) 将一个请求封装为一个对象,从而使你可用不同的请求对客户端进行参数化,对请求排队或者记录日志,以及可支持撤销的操作。 理解 命令模式就是把一些常用的但比较繁杂的工作归类为成一组一组的动作&…...

Docker安全及日志管理
DockerRemoteAPI访问控制 默认只开启了unix socket,如需开放http,做如下操作: 1、dockerd -H unix:///var/run/docker.sock -H tcp://192.168.180.210:2375 2、vim /usr/lib/systemd/system/docker.service ExecStart/usr/bin/dockerd -H uni…...

【LeetCode每日一题】152. 乘积最大子数组
题目: 给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。 思路 由于做了53. 最大子数组和 下意识觉得求出所有元素的以该元素结尾的连续…...
Python 反射
Python 反射是什么? 学习了几天,做个总结留给自己看。 感觉跟 SQL 入门要掌握的原理一样,Python 反射看起来也会做4件事,“增删查获” 增 - 增加属性,方法 setattr 删 - 删除属性,方法 delattr 查 - …...
HTML基本网页制作
一、制作工商银行电子表单 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>第一个网页的标题</ti…...

Tcl语言语法精炼总结
一、置换符号 1.变量置换 $ TCl解释器会将认为$后面为变量名,将变量名置换成它的值 2.命令置换 [] []内是一个独立的TCL语句 3.反斜杠置换 \ 换行符、空格、[、$等被TCL解释器当作特殊符号处理。加上反斜杠后变成普通字符 \t TAB \n 换行符 4.双引号 “” “…...

[GPT]Andrej Karpathy微软Build大会GPT演讲(下)--该如何使用GPT助手
该如何使用GPT助手--将GPT助手模型应用于问题 现在我要换个方向,让我们看看如何最好地将 GPT 助手模型应用于您的问题。 现在我想在一个具体示例的场景里展示。让我们在这里使用一个具体示例。 假设你正在写一篇文章或一篇博客文章,你打算在最后写这句话。 加州的人口是阿拉…...

路由器静态路由的配置
路由器静态路由的配置步骤如下: 进入系统视图。输入命令sys进入系统视图。配置路由器的接口IP地址。命令格式为int g0/0/0,其中g0/0/0表示路由器的接口,可以根据实际情况进行修改。然后使用命令ip add配置接口的IP地址。配置下一跳地址。在静…...

[Firefly-Linux] RK3568在Ubuntu上安装内核头文件实现本地编译驱动程序
文章目录 一、介绍二、安装三、编译驱动四、自行编译debian包一、介绍 在 Linux 操作系统中,linux-headers.deb 和 linux-images.deb 分别用于安装内核头文件和内核二进制文件。 linux-headers.deb: 内核头文件包,通常以 linux-headers-x.x.x-x 的形式命名。包含编译内核模…...

微信好友检测终极指南:快速发现谁删除了你的免费解决方案
微信好友检测终极指南:快速发现谁删除了你的免费解决方案 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...
)
手把手教你用C#和NetToPLCSim连接西门子S7-1200仿真PLC(含虚拟网卡配置避坑)
从零实现C#与西门子S7-1200仿真PLC通信全指南 当第一次尝试用C#与西门子PLC建立通信时,我盯着屏幕上反复出现的连接失败提示,深刻理解了什么是"工控开发入门劝退三连"——IP配置玄学、端口占用谜团、虚拟网卡黑洞。本文将用真实踩坑经验&…...

告别繁琐:Windows平台I2C总线高效调试实战
1. Windows平台I2C调试痛点解析 第一次在Windows下调试I2C设备时,我对着示波器抓到的杂乱波形发呆了整整两小时。与Linux系统自带i2c-tools的便利性相比,Windows环境确实像个"二等公民"——直到我发现CH341A这个神器。这个售价不到20元的USB转…...

英雄联盟LCU自动化工具:3步打造你的专属智能游戏伴侣
英雄联盟LCU自动化工具:3步打造你的专属智能游戏伴侣 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中重复繁琐的操…...

LabVIEW与单片机协同开发:构建可交互硬件原型的通信与事件驱动架构
1. 项目概述与核心思路上次我们聊了用LabVIEW制作一个“iPhone”的初步构想和界面设计,很多朋友反馈说对如何将虚拟界面与实际硬件联动起来特别感兴趣。这第二集,我们就来深入聊聊这块硬骨头——如何让LabVIEW这个强大的图形化编程工具,真正驱…...

告别Excel文件大海捞针!QueryExcel批量检索工具终极指南
告别Excel文件大海捞针!QueryExcel批量检索工具终极指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 你是否曾在数十个Excel文件中苦苦寻找某个关键数据?就像在茫茫大海中寻…...
仿真)
学Simulink——光伏储能系统双向DC-AC逆变器恒功率控制(PQ控制)仿真
目录 手把手教你学Simulink——光伏储能系统双向DC-AC逆变器恒功率控制(PQ控制)仿真 一、背景与挑战 1.1 为什么 PQ 控制?光伏与储能的“任务本质” 1.2 核心痛点与设计目标 二、系统架构与核心控制推导 2.1 整体架构:功率指令 → 电流跟踪 → 电网注入 2.2 核心数学…...

NotebookLM协作效能临界点预警:当团队超8人时,必须立即启用的3项动态共享策略
更多请点击: https://intelliparadigm.com 第一章:NotebookLM协作效能临界点的本质洞察 NotebookLM 的协作效能并非随用户数量线性增长,而是在特定交互密度与知识对齐度交汇时触发跃迁式提升——这一拐点即为“协作效能临界点”。其本质并非…...

通过curl命令直接调用Taotoken大模型API的排错指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调用Taotoken大模型API的排错指南 对于需要在无SDK环境下进行快速测试、调试或集成的开发者而言,直接…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...