SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析
. # 📑前言
本文主要是SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析,如果有什么需要改进的地方还请大佬指出⛺️
🎬作者简介:大家好,我是青衿🥇
☁️博客首页:CSDN主页放风讲故事
🌄每日一句:努力一点,优秀一点

目录
文章目录
- **目录**
- 一、说明
- 二、自然语言处理简介
- 三、Hanlp文本分类与情感分析基本概念
- 语料库
- 用Map描述
- 用文件夹描述
- 数据集实现
- 训练
- 分词
- 特征提取
- 调参调参
- 训练
- 模型
- 分类
- 情感分析
- 四、具体流程
- 特征提取
- 训练
- 测试结果
- 📑文章末尾
一、说明
自然语言处理已经进入大模型时代,然而从业人员必须了解整个知识体系、发展过程、知识结构,应用范围等一系列知识。本篇将报道此类概况。
二、自然语言处理简介
自然语言处理,或简称NLP,是处理和转换文本的计算机科学学科。它由几个任务组成,这些任务从标记化开始,将文本分成单独的意义单位,应用句法和语义分析来生成抽象的知识表示,然后再次将该表示转换为文本,用于翻译、问答或对话等目的。

三、Hanlp文本分类与情感分析基本概念
语料库
本文语料库特指文本分类语料库,对应IDataSet接口。而文本分类语料库包含两个概念:文档和类目。一个文档只属于一个类目,一个类目可能含有多个文档。
用Map描述
这种关系可以用Java的Map<String, String[]>来描述,其key代表类目,value代表该类目下的所有文档。用户可以利用自己的文本读取模块构造一个Map<String, String[]>形式的中间语料库,然后利用IDataSet#add(java.util.Map<java.lang.String,java.lang.String[]>)接口将其加入到训练语料库中。
用文件夹描述
这种树形结构也很适合用文件夹描述,即:
/*** 加载数据集** @param folderPath 分类语料的根目录.目录必须满足如下结构:<br>* 根目录<br>* ├── 分类A<br>* │ └── 1.txt<br>* │ └── 2.txt<br>* │ └── 3.txt<br>* ├── 分类B<br>* │ └── 1.txt<br>* │ └── ...<br>* └── ...<br>*
每个分类里面都是一些文本文档。任何满足此格式的语料库都可以直接加载。
数据集实现
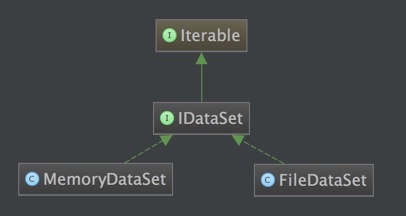
考虑到大规模训练的时候,文本数量达到千万级,无法全部加载到内存中,所以本系统实现了基于文件系统的FileDataSet。同时,在服务器资源许可的情况下,可以使用基于内存的MemoryDataSet,提高加载速度。两者的继承关系如下:
训练
训练指的是,利用给定训练集寻找一个能描述这种语言现象的模型的过程。开发者只需调用train接口即可,但在实现中,有许多细节。
分词
目前,本系统中的分词器接口一共有两种实现: 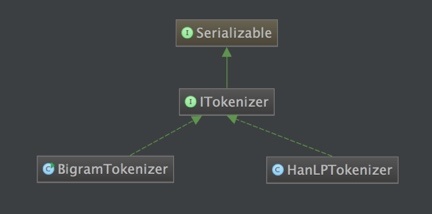
但文本分类是否一定需要分词?答案是否定的。 我们可以顺序选取文中相邻的两个字,作为一个“词”(术语叫bigram)。这两个字在数量很多的时候可以反映文章的主题(参考清华大学2016年的一篇论文《Zhipeng Guo, Yu Zhao, Yabin Zheng, Xiance Si, Zhiyuan Liu, Maosong Sun. THUCTC: An Efficient Chinese Text Classifier. 2016》)。这在代码中对应BigramTokenizer. 当然,也可以采用传统的分词器,如HanLPTokenizer。 另外,用户也可以通过实现ITokenizer来实现自己的分词器,并通过IDataSet#setTokenizer来使其生效。
特征提取
特征提取指的是从所有词中,选取最有助于分类决策的词语。理想状态下所有词语都有助于分类决策,但现实情况是,如果将所有词语都纳入计算,则训练速度将非常慢,内存开销非常大且最终模型的体积非常大。
本系统采取的是卡方检测,通过卡方检测去掉卡方值低于一个阈值的特征,并且限定最终特征数不超过100万。
调参调参
对于贝叶斯模型,没有超参数需要调节。
训练
本系统实现的训练算法是朴素贝叶斯法,无需用户关心内部细节。另有一个子项目实现了支持向量机文本分类器,可供参考。由于依赖了第三方库,所以没有集成在本项目中。
模型
训练之后,我们就得到了一个模型,可以通过IClassifier#getModel获取到模型的引用。该接口返回一个AbstractModel对象,该对象实现了Serializable接口,可以序列化到任何地方以供部署。 反序列化后的模型可以通过如下方式加载并构造分类器:
NaiveBayesModel model = (NaiveBayesModel) IOUtil.readObjectFrom(MODEL_PATH);
NaiveBayesClassifier naiveBayesClassifier = new NaiveBayesClassifier(model);
分类
通过加载模型,我们可以得到一个分类器,利用该分类器,我们就可以进行文本分类了。
IClassifier classifier = new NaiveBayesClassifier(model);
目前分类器接口中与文本分类有关的接口有如下三种:
/*** 预测分类** @param text 文本* @return 所有分类对应的分值(或概率, 需要enableProbability)* @throws IllegalArgumentException 参数错误* @throws IllegalStateException 未训练模型*/
Map<String, Double> predict(String text) throws IllegalArgumentException, IllegalStateException;/*** 预测分类* @param document* @return*/
Map<String, Double> predict(Document document) throws IllegalArgumentException, IllegalStateException;/*** 预测分类* @param document* @return* @throws IllegalArgumentException* @throws IllegalStateException*/
double[] categorize(Document document) throws IllegalArgumentException, IllegalStateException;/*** 预测最可能的分类* @param document* @return* @throws IllegalArgumentException* @throws IllegalStateException*/
int label(Document document) throws IllegalArgumentException, IllegalStateException;/*** 预测最可能的分类* @param text 文本* @return 最可能的分类* @throws IllegalArgumentException* @throws IllegalStateException*/
String classify(String text) throws IllegalArgumentException, IllegalStateException;/*** 预测最可能的分类* @param document 一个结构化的文档(注意!这是一个底层数据结构,请谨慎操作)* @return 最可能的分类* @throws IllegalArgumentException* @throws IllegalStateException*/
String classify(Document document) throws IllegalArgumentException, IllegalStateException;
classify方法直接返回最可能的类别的String形式,而predict方法返回所有类别的得分(是一个Map形式,键是类目,值是分数或概率),categorize方法返回所有类目的得分(是一个double数组,分类得分按照分类名称的字典序排列),label方法返回最可能类目的字典序。
情感分析
可以利用文本分类在情感极性语料上训练的模型做浅层情感分析。目前公开的情感分析语料库有:中文情感挖掘语料-ChnSentiCorp,语料发布者为谭松波。
接口与文本分类完全一致,请参考com.hankcs.demo.DemoSentimentAnalysis。
四、具体流程
特征提取
本系统采取的是卡方检测,通过卡方检测去掉卡方值低于一个阈值的特征,并且限定最终特征数不超过100万。


训练

测试结果

HanLP Github地址:https://github.com/hankcs/HanLP
HanLP文档地址:https://hanlp.hankcs.com/docs/api/hanlp/pretrained/index.html
📑文章末尾

相关文章:
SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析
. # 📑前言 本文主要是SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风…...
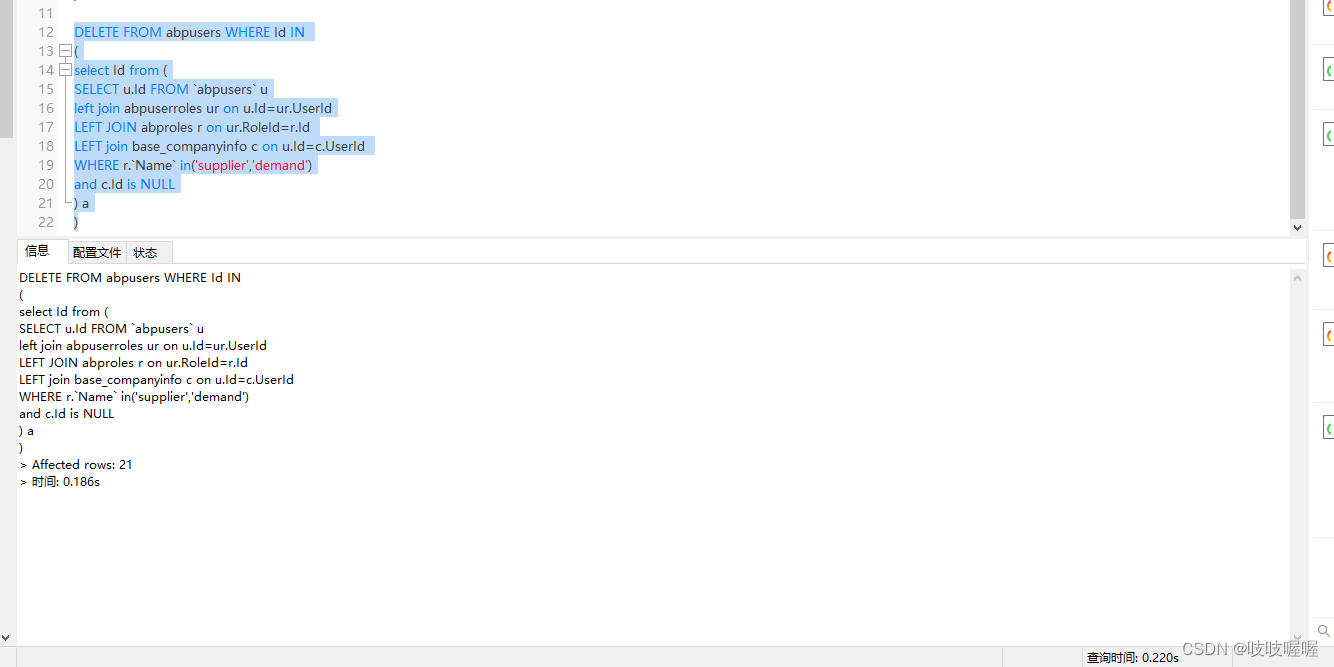
MySQL 报错 You can‘t specify target table for update in FROM clause解决办法
You can’t specify target table for update in FROM clause 其含义是:不能在同一表中查询的数据作为同一表的更新数 单独执行复合查询是正常的,如下: 但是当执行子查询删除命令时,报如下错误 DELETE FROM abpusers WHERE Id I…...

Linux中使用podman管理容器
本章主要介绍使用podman管理容器 了解什么是容器,容器和镜像的关系安装和配置podman拉取和删除镜像给镜像打标签导出和导入镜像创建和删除镜像数据卷的使用管理容器的命令使用普通用户管理容器 对于初学者来说,不太容易理解什么是容器,这里…...

飞天使-linux操作的一些技巧与知识点3-http的工作原理
文章目录 http工作原理nginx的正向代理和反向代理的区别一个小技巧dig 命令巧用 http工作原理 http1.0 协议 使用的是短连接,建立一次tcp连接,发起一次http的请求,结束,tcp断开 http1.1 协议使用的是长连接,建立一次tc…...
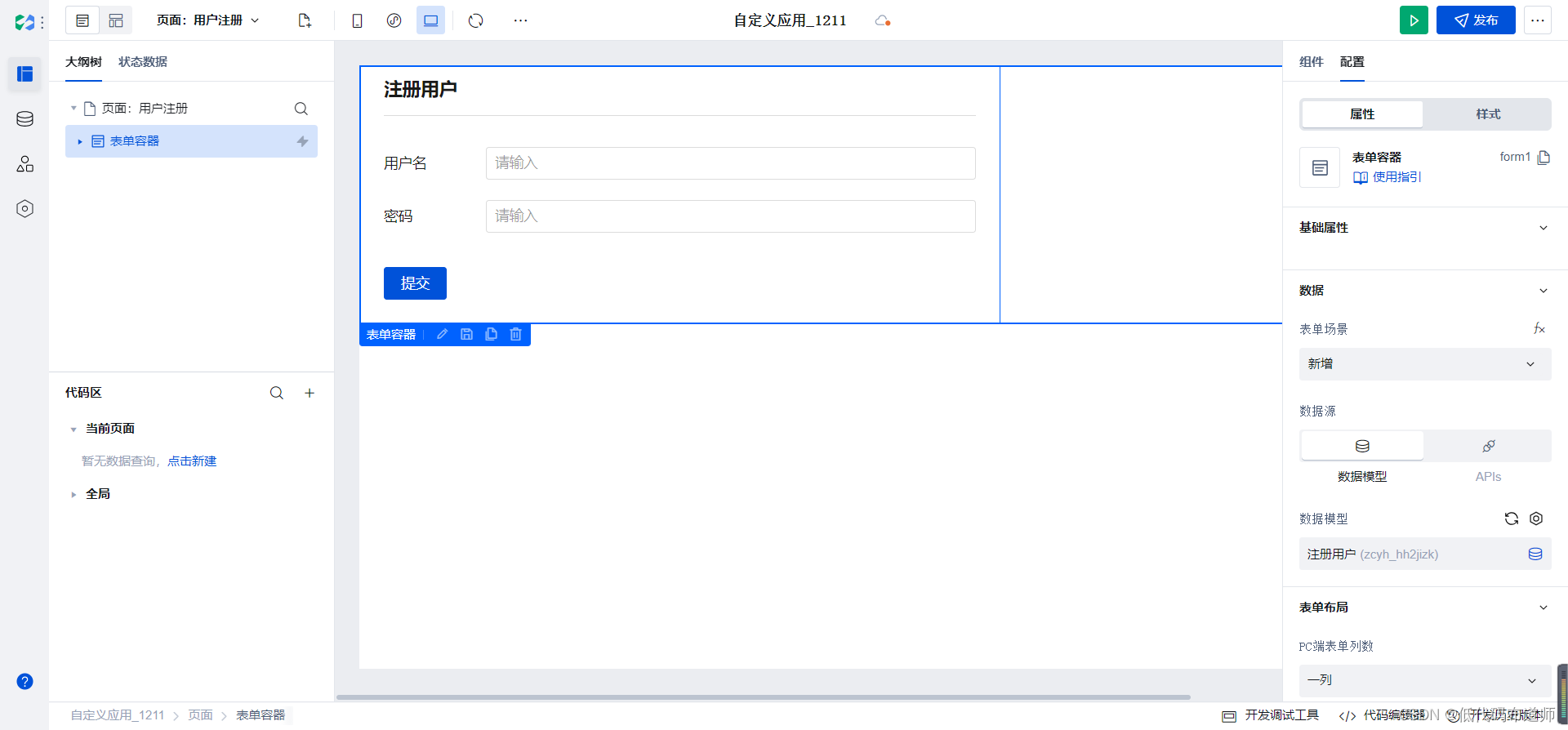
微搭低代码实现登录注册功能
目录 1 创建用户数据源2 实现登录逻辑3 搭建登录页面4 设置登录框5 实现登录的逻辑6 用户注册总结 原来产品在创建应用的时候可以创建模型应用,模型应用对应我们小程序的后端。最新的更新已经将模型应用的能力下线,那我们不得不自己实现一下后端的逻辑。…...
使用Cobalt Srike制作钓鱼文件
钓鱼 钓鱼文件是一种常见的网络攻击手段,旨在欺骗用户,诱使他们点击恶意链接、下载恶意附件或提供敏感信息。钓鱼文件的概念是通过伪装成合法、可信的文件或链接来欺骗受害者,使其相信文件或链接的来源是可信的,从而促使他们采取…...

任意文件读取漏洞
使用方法php://filter/readconvert.base64-encode/resourcexxx 任意文件读取漏洞 php://filter/readconvert.base64-encode/resourceflag 在url后边接上 以base64的编码形式 读取flag里面的内容 php://filter/readconvert.base64encode/resourceflag 用kali来解码 创建一个文…...

一个文件下png,jpg,jpeg,bmp,xml,json,txt文件名称排序命名
#utf-8 #authors 会飞的渔WZH #time:2023-12-13 import os# 要修改的图像所在的文件夹路径 root_path rD:\images\lines2\3 # 要修改的图像所在的文件夹路径filelist os.listdir(root_path) #遍历文件夹 print(len(filelist)) i0for item in filelist:if item.endswith(.…...
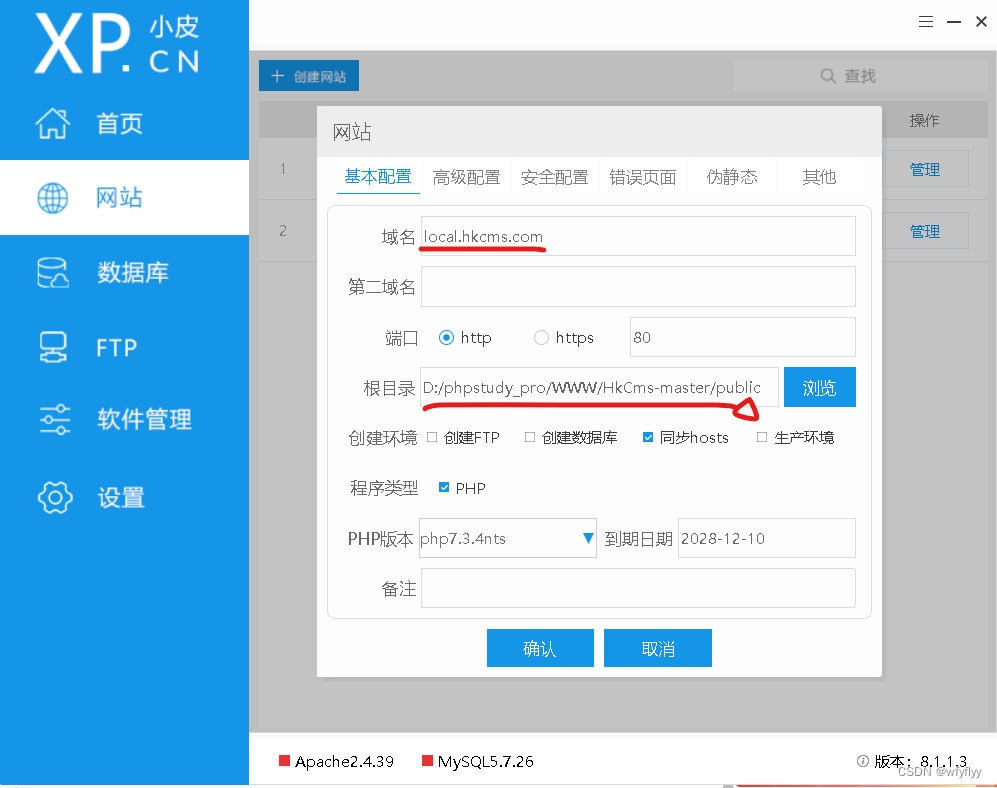
phpstudy小皮(PHP集成环境)下载及使用
下载 https://www.xp.cn/download.html直接官网下载即可,下载完解压是个.exe程序,直接点击安装就可以,它会自动在D盘目录为D:\phpstudy_pro 使用 phpMyAdmin是集成的数据库可视化,这里需要下载一下,在软件管理-》网站程…...

[BUG记录]UART占用CPUload过高问题
目录 关键词平台说明一、背景二、根本原因三、措施 关键词 嵌入式、C语言、autosar、TDA4 平台说明 项目ValueOSautosar OSautosar厂商vector芯片厂商TI编程语言C,C编译器HighTec (GCC) 一、背景 在基于TDA4开发的域控中使用到了UART打印debug信息,不…...

Flutter常用命令
一、环境安装 flutter --version 查看当前安装的flutter 版本 flutter upgrade 升级当前的flutter 版本 flutter doctor 检查环境安装是否完成 二、项目编译运行 flutter clean 清空build目录 flutter pub get 获取pub插件包 flutter run --设备名称 运行项目到指定设…...
:引用计数、共享指针、缓冲区管理)
【C++】POCO学习总结(十四):引用计数、共享指针、缓冲区管理
【C】郭老二博文之:C目录 1、Poco::AutoPtr 智能指针 1.1 说明 Poco::AutoPtr是一个含有引用计数的“智能”指针模版。 Poco::AutoPtr用于支持引用计数的类实例化。支持引用计数的类需要有以下要求: 维护一个引用计数(在创建时初始化为1)实现void du…...

Python之禅
import this 这是 Python 社区中著名的 "The Zen of Python"(Python之禅)文档,由 Python 创始人之一的 Tim Peters 撰写。这个文档包含了一系列关于编程和代码设计哲学的原则,以指导 Python 社区的开发者。以下是这些原…...
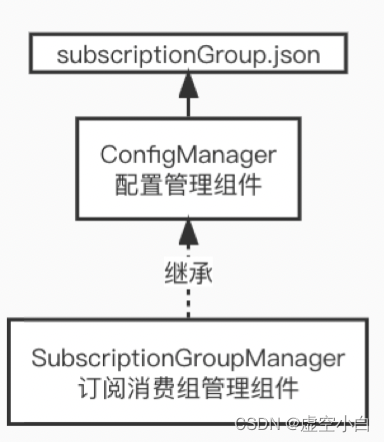
RocketMQ源码 Broker-SubscriptionGroupManager 订阅组管理组件源码分析
前言 SubscriptionGroupManager 继承了ConfigManager配置管理组件,拥有将内存数据持久化到磁盘文件subscriptionGroup.json的能力。它主要负责维护所有消费组在内存中的订阅数据。 源码版本:4.9.3 源码架构图 核心数据结构 主要的数据结构比较简单&am…...

go-zero开发入门-API网关鉴权开发示例
本文是go-zero开发入门-API网关开发示例一文的延伸,继续之前请先阅读此文。 在项目根目录下创建子目录 middleware,在此目录下创建文件 auth.go,内容如下: // 鉴权中间件 package middlewareimport ("context""e…...

[LLM]nanoGPT---训练一个写唐诗的GPT
karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs. (github.com) 原有模型使用的莎士比亚的戏剧数据集, 如果需要一个写唐诗机器人,需要使用唐诗的文本数据, 一个不错的唐诗,宋词数据的下载…...
docker compose部署wordpress
准备机器: 192.168.58.151 (关闭防火墙和selinux) 安装好docker服务 (详细参照:http://t.csdnimg.cn/usG0s 中的国内源安装docker) 部署wordpress: 创建目录: [rootdocker ~]# mkdir…...
【docker四】使用Docker-compose一键部署Wordpress平台
目录 一、YAML 文件格式及编写注意事项(重要) 1、yaml文件使用时注意事项: 2、yaml文件的基本数据结构: 2.1、声明变量(标量。是单个的不可再分的值,类型:字符串,整数,…...
:简易计算器)
HTML程序大全(1):简易计算器
HTML代码,主要创建了几个按钮。 <div class"container"><div class"output" id"output">0</div><button class"button" onclick"clearOutput()" id"clear">C</button>…...

esp32服务器与android客户端的tcp通讯
esp32 //esp32作为服务端 #include <WiFi.h>#define LED_BUILTIN 2 // 创建热点 const char *ssid "ESP32"; const char *password "12345678"; const int port 1122; //端口 WiFiServer server(port); void setup() {delay(5000);pinMode(LED_…...

【网络编程】UDP协议
目录 协议格式 特点 1.无连接(Connectionless) 2. 不可靠(Unreliable) 3. 面向报文(Message-Oriented) 常见问题 协议格式 特点 1.无连接(Connectionless) 特点:在…...

在模型广场中根据任务需求与预算选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场中根据任务需求与预算选择合适的模型 面对文本生成、代码编写、逻辑推理等多样化的任务,开发者常常需要从众…...

自托管MCP服务器模板:快速构建AI智能体私有工具箱
1. 项目概述:一个为AI智能体赋能的“工具箱”模板最近在折腾AI智能体(Agent)开发的朋友,可能都听说过MCP(Model Context Protocol)这个概念。简单来说,MCP就像是为AI大模型准备的一套标准化的“…...

Excel高手私藏技巧:用LOOKUP和FIND函数自动归类文本,快速整理海量调研问卷和评论关键词
Excel文本归类实战:用LOOKUPFIND构建智能关键词标签系统 当面对数千条开放式问卷反馈时,市场分析师小张正在为如何高效归类"用户最关注的手机功能"发愁。传统人工阅读标注不仅耗时,还容易因主观判断产生偏差。而Excel中一组被低估的…...

如何在PC上免费畅玩Switch游戏:yuzu模拟器终极指南
如何在PC上免费畅玩Switch游戏:yuzu模拟器终极指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想要在电脑上体验任天堂Switch游戏吗?yuzu模拟器是你的完美选择!作为目前最受…...

Nodejs项目接入Taotoken统一大模型API的完整配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs项目接入Taotoken统一大模型API的完整配置指南 1. 准备工作:获取API Key与模型ID 在开始编写代码之前ÿ…...

高层次综合百问
一、基础层Vivado HLS 的核心功能是什么?它与 Vivado 的核心区别是什么?HLS 中“可综合 C 代码”和普通软件 C 代码的最核心区别是什么?Vivado HLS 支持的输入语言有哪些(至少说出3种)?HLS 工程的基本组成部…...

Python websocket-client库避坑指南:从回调地狱到优雅关闭长连接
Python websocket-client库深度实战:从长连接管理到生产级解决方案 引言 在实时数据传输领域,WebSocket协议已经成为现代应用的基石。无论是金融行情推送、即时通讯系统还是物联网设备监控,WebSocket的双向通信特性都展现出无可替代的价值。P…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...
)
从原理到批量利用:深入剖析Apache Superset默认密钥漏洞(CVE-2023-27524)
1. Apache Superset安全漏洞背景 Apache Superset作为一款流行的开源数据可视化工具,在企业数据分析领域有着广泛应用。但正是这样一个看似无害的工具,却因为开发者的一个常见疏忽——使用默认密钥,导致了严重的身份验证绕过漏洞。这个编号为…...