BertTokenizer的使用方法(超详细)
导入
from transformers import BertTokenizer
from pytorch_pretrained import BertTokenizer
以上两行代码都可以导入BerBertTokenizer,transformers是当下比较成熟的库,pytorch_pretrained是google提供的源码(功能不如transformers全面)
加载
tokenizer = BertTokenizer.from_pretrained('bert_pretrain')
数据
首先定义一些数据:
sents = ['人工智能是计算机科学的一个分支。','它企图了解智能的实质。','人工智能是一门极富挑战性的科学。',
]
tokenize
将句子拆分为token,并不映射为对应的id
token = tokenizer.tokenize(sents[0])
print(token)
# 输出:['人', '工', '智', '能', '是', '计', '算', '机', '科', '学', '的', '一', '个', '分', '支', '。']
convert_tokens_to_ids
将token映射为其对应的id(ids是我们训练中真正会用到的数据)
ids = tokenizer.convert_tokens_to_ids(token)
print(ids)
#输出:[8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043]
同理convert_ids_to_tokens,就是上述方法的逆过程
encode(从此方法开始,只有transformers可以实现)
convert_tokens_to_ids是将分词后的token转化为id序列,而encode包含了分词和token转id过程,即encode是一个更全的过程,另外,encode默认使用basic的分词工具,以及会在句子前和尾部添加特殊字符[CLS]和[SEP],无需自己添加。从下可以看到,虽然encode直接使用tokenizer.tokenize()进行词拆分,会保留头尾特殊字符的完整性,但是自己也会额外添加特殊字符。
token = tokenizer.tokenize(sents[0])
print(token)
ids = tokenizer.convert_tokens_to_ids(token)
print(ids)
ids_encode = tokenizer.encode(sents[0])
print(ids_encode)
token_encode = tokenizer.convert_ids_to_tokens(ids_encode)
print(token_encode)
# 输出结果:
#['人', '工', '智', '能', '是', '计', '算', '机', '科', '学', '的', '一', '个', '分', '支', '。']
#[8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043]
#[1, 8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043, 2]
#['[CLS]', '人', '工', '智', '能', '是', '计', '算', '机', '科', '学', '的', '一', '个', '分', '支', '。', '[SEP]']
从运行结果可以看到encode确实在首尾增加了特殊词元[cls]和[sep]也就是1和2
encode_plus
返回更多相关信息:
ids = tokenizer.encode_plus(sents[0])
print(ids)
# {'input_ids': [1, 8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043, 2],
#'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
#'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
相关参数介绍:
out = tokenizer.encode_plus(text=sents[0],text_pair=sents[1],#当句子长度大于max_length时,截断truncation=True,#一律补零到max_length长度padding='max_length',max_length=30,add_special_tokens=True,#可取值tf,pt,np,默认为返回listreturn_tensors=None,#返回token_type_idsreturn_token_type_ids=True,#返回attention_maskreturn_attention_mask=True, #返回special_tokens_mask 特殊符号标识return_special_tokens_mask=True,#返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用#return_offsets_mapping=True,#返回length 标识长度return_length=True,
)for k, v in out.items():print(k, ':', v)
#input_ids : [1, 8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043, 2, 380, 258, 429, 15, 273, 826, 52, 5, 79, 207, 12043, 2]
#token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
#special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
#attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
#length : 30
batch_encode_plus
以 batch 的形式去编码句子
ids = tokenizer.batch_encode_plus([x for x in sents])
print(ids)
# {
#'input_ids': [[1, 8, 35, 826, 52, 10, 159, 559, 98, 147, 18, 5, 7, 27, 59, 414, 12043, 2], [1, 380, 258, 429, 15, 273, 826, 52, 5, 79, 207, 12043, 2], [1, 8, 35, 826, 52, 10, 7, 232, 456, 595, 1373, 267, 92, 5, 147, 18, 12043, 2]],
#'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
#'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
相关文章:
)
BertTokenizer的使用方法(超详细)
导入 from transformers import BertTokenizer from pytorch_pretrained import BertTokenizer以上两行代码都可以导入BerBertTokenizer,transformers是当下比较成熟的库,pytorch_pretrained是google提供的源码(功能不如transformers全面) 加载 tokenizer BertT…...
:编译过程中遇到的问题总结)
深度学习编译器CINN(3):编译过程中遇到的问题总结
目录 问题一:No module named XXXX 问题描述 分析与解决方案 问题二:catastrophic error: cannot open source file "float16.h"...

yum 安装mysql8数据全过程
mysql8安装方式:(使用官方yum仓库) 1. wget https://dev.mysql.com/get/mysql80-community-release-el7-4.noarch.rpm 安装 yum install mysql80-community-release-el7-4.noarch.rpm 2、生成yum源缓存 每次当我们编写了,…...
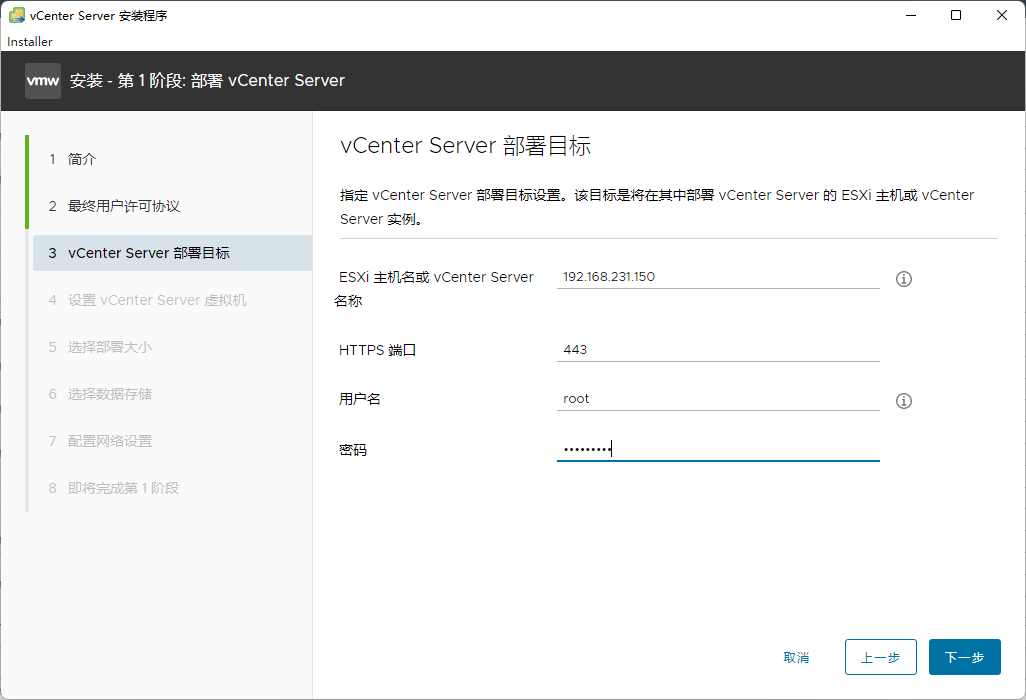
内网vCenter部署教程一
PS:因为交换机链路为trunk,安装先登录ESXI,将端口组改为管理vlan ID(1021) 一、双击镜像,打开文件夹,目录为F:\vcsa-ui-installer\win32,双击installer.exe 二、先设置语言为中文 三、点击下一步 四、选择需要安装esxi的主机。 五、设置Vcenter虚拟机的密码...

java 进阶—线程的常用方法
大家好,通过java进阶—多线程,我们知道的什么是进程,什么是线程,以及线程的三种创建方式的选择 今天,我们来看看线程的基础操作 start() 开启线程 public class Demo implements Runnable {Overridepublic void run…...
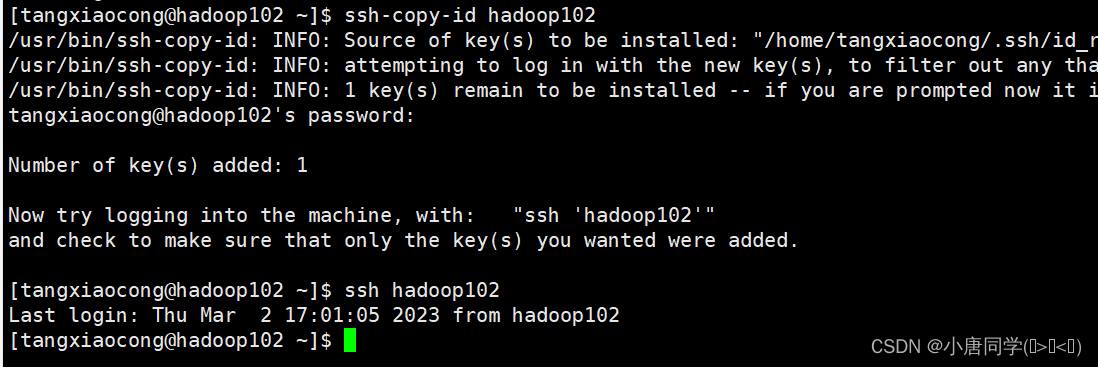
hadoop的运行模式
作者简介:大家好我是小唐同学(๑><๑),好久不见,为梦想而努力的小唐又回来了,让我们一起加油!!! 个人主页:小唐同学(๑><๑)的博客主页 目前…...

服务器(centos7.6)已经安装了宝塔面板,想在里面安装一个SVN工具(subversion),应该如何操作呢?
首先,在登录进入宝塔面板,然后点击左侧终端,进入终端界面,如下图:------------------------------------------如果是第一次使用会弹出输入服务器用户名和密码,此时输入root账号和密码,即可进入…...

从智能进化模型看用友BIP的AI平台化能力
随着人工成本的上升,智能和自动化技术的成熟,企业在越来越多的场景开始应用自动化技术来替代相对标准及有规则的工作,同时利用智能算法来优化复杂工作及决策,获得竞争优势。 不同于阅读、聊天、搜索等面向终端用户的应用场景&…...
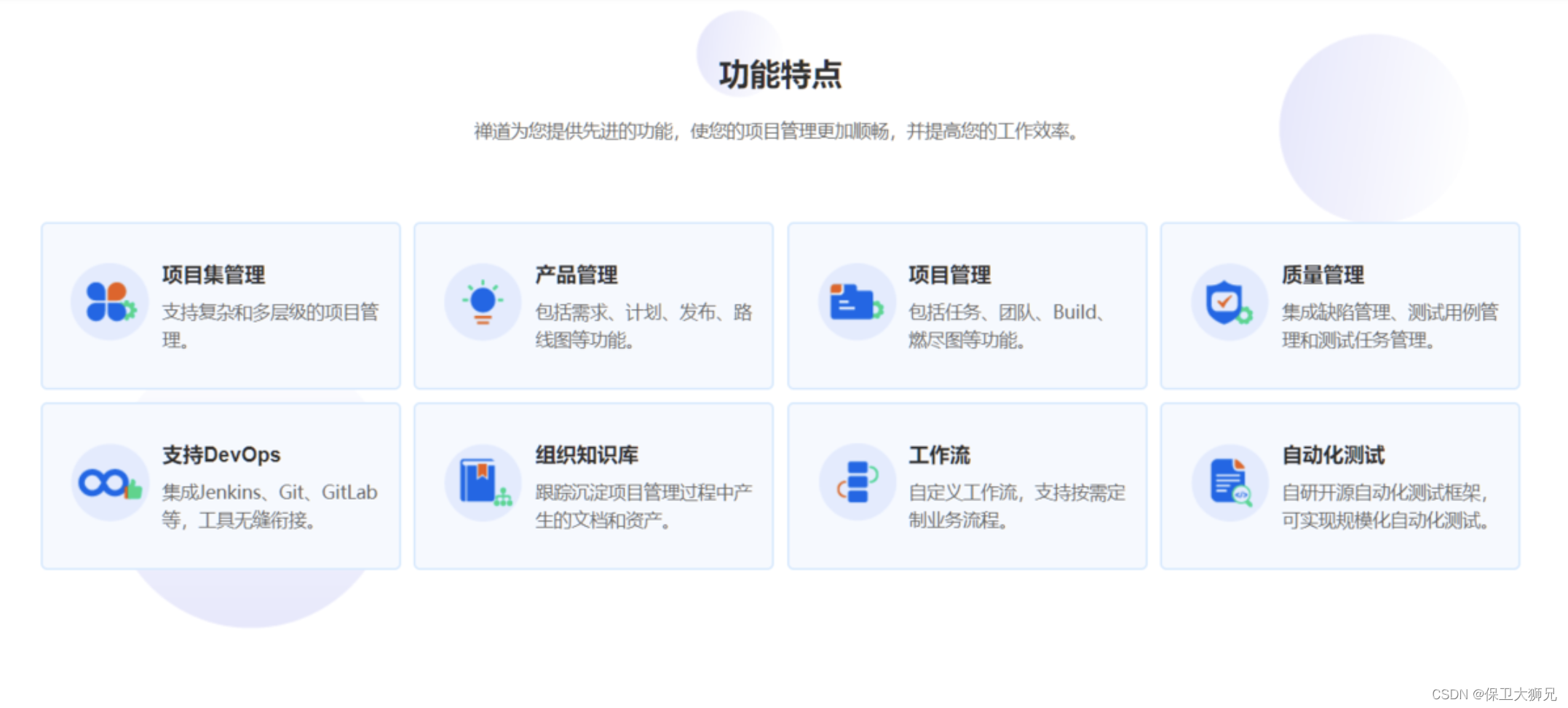
项目管理的主要内容包括哪些?盘点好用的项目管理系统软件
阅读本文您将了解:1、项目管理的主要内容包括哪些2、好用的项目管理软件 项目管理是为了实施一个特定目标,所实施的一系列针对项目要素的管理过程,包括过程、手段以及技术等。 通过项目管理,我们能够提前安排和控制项目的时间、…...
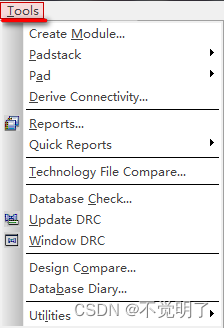
Allegro如何查看PCB上器件的库路径操作指导
Allegro如何查看PCB上器件的库路径操作指导 在做PCB设计的时候,有时需要检查PCB上器件使用的库的路径是否正确,Allegro支持快速将PCB上所有器件的库路径都列出来 如下图 如何显示这个报表,具体操作如下 点击Tools点击Report...

笔记【尚硅谷】大数据Canal教程丨Alibaba数据实时同步神器
视频教程:【尚硅谷】大数据Canal教程丨Alibaba数据实时同步神器教程资料:https://pan.baidu.com/s/1VhGBcqeywM6jyXJxtytd1w?pwd6666,提取码:6666本套教程以Canal的底层原理展开讲解,细致地介绍了Canal的安装部署及常…...

如何重定向命令行日志信息到指定txt文件?
如果你想把命令行的输出重定向到指定的txt文件,你可以使用一些符号来实现。例如,你可以在命令后面加上>或>>符号,然后指定文件名。例如: command > output.txt 这样就会把command的标准输出保存到output.txt文件中&…...

物理机不能访问虚拟机kali的web服务解决方案记录
目录 环境 问题描述 解决方案 知识补充 效果测试 其他思路 环境 kali(nat模式),物理机,可互ping 问题描述 kali的web服务器不能在物理机上访问。 1.本机能ping通虚拟机 2.虚拟机也能ping通本机 3.虚拟机能访问自己的web …...
服务器配置 | 在Windows本地显示远程服务器绘图程序
文章目录方法1:在MobaXterm的终端输入指令方法2:在Pycharm中运行前提概要,需要在本地Windows端显示点云的3d可视化界面 对于点云的3d可视化一般有两种方法,open3d显示或者是mayavi显示。这两个库都可以使用pip install来实现安装…...

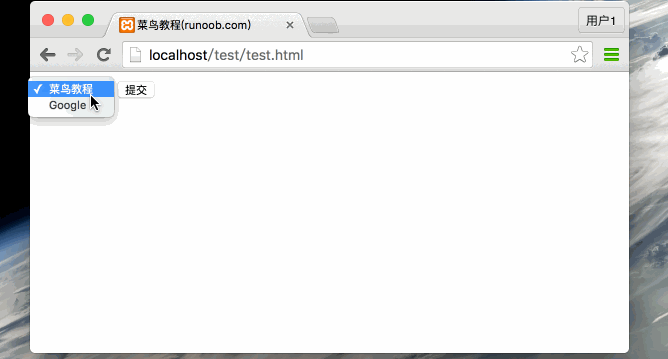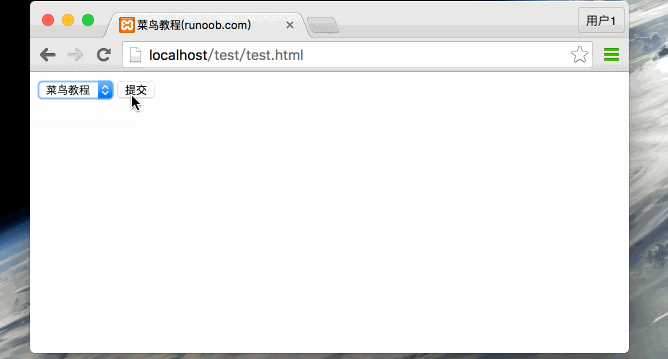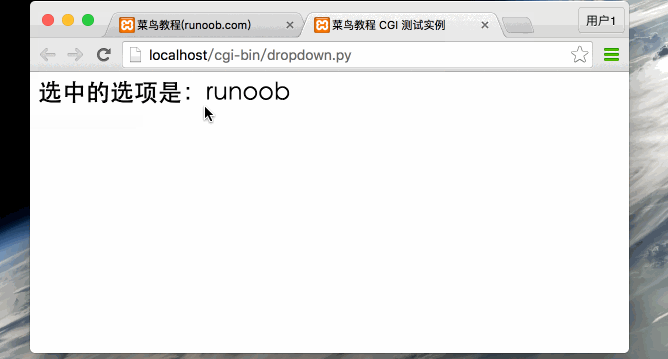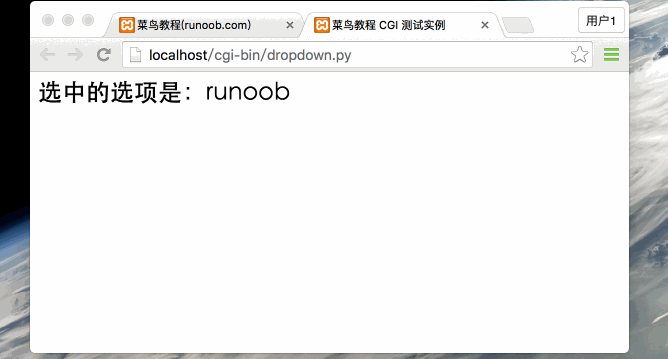
从0开始学python -47
Python CGI编程 -2 GET和POST方法 浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。 使用GET方法传输数据 GET方法发送编码后的用户信息到服务端,数据信息包含在请求页面的URL上,以"?"号分割…...
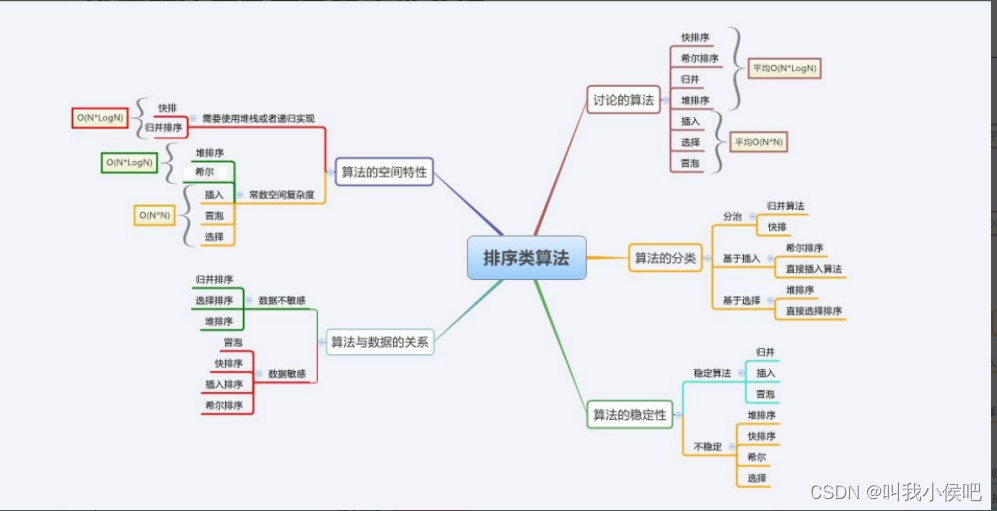
【数据结构】八大经典排序总结
文章目录一、排序的概念及其运用1.排序的概念2.常见排序的分类3.排序的运用二、常见排序算法的实现1.直接插入排序1.1排序思想1.2代码实现1.3复杂度及稳定性1.4特性总结2.希尔排序2.1排序思想2.3复杂度及稳定性2.4特性总结3.直接选择排序3.1排序思想3.2代码实现3.3复杂度及稳定…...
BI的能力边界:能解决的企业问题和不擅长的领域
数字化转型本就需要借助信息化相关技术、思想来完成,所以说信息化建设同样是数字化转型过程中非常重要的一环,而这就是商业智能BI和数字化转型的关系 BI 能解决的企业问题 数据是企业的重要资产,也是企业商业智能BI的核心要求。通常&#x…...

金三银四面试必备,“全新”突击真题宝典,阿里腾讯字节都稳了
前言招聘旺季就到了,不知道大家是否准备好了,面对金三银四的招聘旺季,如果没有精心准备那笔者认为那是对自己不负责任;就我们Java程序员来说,多数的公司总体上面试都是以自我介绍项目介绍项目细节/难点提问基础知识点考…...

MYSQL 基础篇 | 02-MYSQL基础应用
文章目录1 MySQL概述2 SQL2.1 SQL通用语法2.2 SQL分类2.3 DDL2.3.1 数据库操作2.3.2 表操作2.4 DML2.4.1 添加数据2.4.2 修改数据2.4.3 删除数据2.5 DQL2.5.1 基础查询2.5.2 条件查询2.5.3 聚合查询2.5.4 分组查询2.5.5 排序查询2.5.6 分页查询2.5.7 综合练习2.6 DCL2.6.1 管理…...

用OpenMV4 H7 PLUS做个智能分拣小车:颜色识别实战项目从硬件选型到代码集成
智能分拣小车实战:OpenMV4 H7 PLUS颜色识别与嵌入式系统集成 在创客竞赛和毕业设计中,智能分拣系统一直是热门选题。传统方案往往面临识别精度不足、响应延迟高或硬件兼容性差等问题。OpenMV4 H7 PLUS凭借其强大的图像处理能力和丰富的硬件接口ÿ…...

文心一言深度解析:国产多模态大模型的破局之路
文心一言深度解析:国产多模态大模型的破局之路 引言 在ChatGPT引爆全球AI热潮的背景下,国产大模型如何突围?百度推出的文心一言(ERNIE Bot)作为中国AI产业的一面旗帜,凭借其在多模态理解与生成、中文场景深…...

3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南
3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS用户设计的开源桌面歌词显示…...

智能网联汽车窄路车流预测与协同通行【附仿真】
✨ 长期致力于智能网联汽车、窄路段、短时车流量预测、协同通行研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)窄路车流时空异质图特征构建ÿ…...

Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器
Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器 【免费下载链接】ms-nfs41-client NFSv4.1 Client for Windows 项目地址: https://gitcode.com/gh_mirrors/ms/ms-nfs41-client 想要在Windows系统中像操作本地文件一样访问远程NFS服务器吗&a…...

VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯
VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯 第一次接触VESC驱动无刷电机时,面对满屏的ChibiOS源码和复杂的CAN通讯协议,很多嵌入式新手都会感到无从下手。特别是当你已经能用VESC Tool让电机转起来,但想通过…...
)
Vivado里配置RFSoC数据转换器IP,这10个参数新手最容易搞错(附PG269避坑指南)
Vivado中RFSoC数据转换器IP配置的10个关键参数解析与实战避坑指南 第一次在Vivado中配置RFSoC的数据转换器IP核时,面对密密麻麻的参数选项,即使是经验丰富的FPGA工程师也可能感到无从下手。RFSoC作为集成了高速数据转换器的异构计算平台,其配…...

Typora“激活”与“美化”实战指南
1. Typora基础认知与安装准备 Typora作为一款广受好评的Markdown编辑器,其独特之处在于将编辑与预览合二为一。不同于传统Markdown编辑器需要分屏显示源代码和渲染效果,Typora实现了真正的所见即所得——你在编辑区输入的Markdown语法会实时转换为排版效…...

2026发文避坑指南:告别大众型AI,用对垂直编辑器让过审更轻松
在2026年的学术大环境下,核心期刊的收录门槛持续走高,许多科研工作者正面临着一种隐性焦虑:明明实验数据扎实、研究背景深厚,投递出去的稿件却屡屡被退。其实,很多时候被拒的根本原因并非学术价值不足,而是…...

WarcraftHelper:魔兽争霸3终极增强插件完全指南
WarcraftHelper:魔兽争霸3终极增强插件完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争霸3设计的…...