自己动手写数据库: select 查询语句对应查询树的构造和执行
首先我们需要给原来代码打个补丁,在SelectScan 结构体初始化时需要传入 UpdateScan 接口对象,但很多时候我们需要传入的是 Scan 对象,因此我们需要做一个转换,也就是当初始化 SelectScan 时,如果传入的是 Scan 对象,那么我们就将其封装成 UpdateScan 接口对象,因此在 query 目录下增加一个名为 updatescan_wrapper.go 的文件,在其中输入内容如下:
package queryimport ("record_manager"
)type UpdateScanWrapper struct {scan Scan
}func NewUpdateScanWrapper(s Scan) *UpdateScanWrapper {return &UpdateScanWrapper{scan: s,}
}func (u *UpdateScanWrapper) GetScan() Scan {return u.scan
}func (u *UpdateScanWrapper) SetInt(fldName string, val int) {//DO NOTHING
}func (u *UpdateScanWrapper) SetString(fldName string, val string) {//DO NOTHING
}func (u *UpdateScanWrapper) SetVal(fldName string, val *Constant) {//DO NOTHING
}func (u *UpdateScanWrapper) Insert() {//DO NOTHING
}func (u *UpdateScanWrapper) Delete() {//DO NOTHING
}func (u *UpdateScanWrapper) GetRid() *record_manager.RID {return nil
}func (u *UpdateScanWrapper) MoveToRid(rid *record_manager.RID) {// DO NOTHING
}上面代码逻辑简单,如果调用 Scan 对象接口时,他直接调用其 Scan 内部对象的接口,如果调用到 UpdateScan 的接口,那么它什么都不做。完成上面代码后,我们在select_plan.go 中进行一些修改:
func (s *SelectPlan) Open() interface{} {scan := s.p.Open()updateScan, ok := scan.(query.UpdateScan)if !ok {updateScanWrapper := query.NewUpdateScanWrapper(scan.(query.Scan))return query.NewSelectionScan(updateScanWrapper, s.pred)}return query.NewSelectionScan(updateScan, s.pred)
}
上面代码在创建 SelectScan 对象时,先判断传进来的对象是否能类型转换为 UpdateScan,如果不能,那意味着s.p.Open 获取的是 Scan 对象,因此我们使用前面的代码封装一下再用来创建 SelectScan 对象。完成这里的修改后,我们进入正题。
前面我们在实现 sql 解析器后,在解析完一条查询语句后会创建一个 QueryData 对象,本节我们看看如何根据这个对象构建出合适的查询规划器(Plan)。我们将采取由简单到负责的原则,首先我们直接构建 QueryData 的信息去构建查询规划对象,此时我们不考虑它所构造的查询树是否足够优化,后面我们再慢慢改进构造算法,直到算法能构建出足够优化的查询树。
我们先看一个具体例子,假设我们现在有两个表 STUDENT, EXAM,第一个表包含两个字段分别是学生 id 和姓名:
| id | name |
|---|---|
| 1 | Tom |
| 2 | Jim |
| 3 | John |
第二个表包含的是学生 id,科目名称,考试乘机:
| stuid | exam | grad |
|---|---|---|
| 1 | math | A |
| 1 | algorithm | B |
| 2 | writing | C |
| 2 | physics | C |
| 3 | chemical | B |
| 3 | english | C |
现在我们使用 sql 语句查询所有考试成绩得过 A 的学生:
select name from STUDENT, EXAM where id = student_id and grad='A'
当 sql 解释器读取上面语句后,他就会创建一个 QueryData 结构,里面 Tables 对了就包含两个表的名字,也就是 STUDENT, EXAM。由于这两个表不是视图,因此上面代码中判断 if viewDef != nil 不成立,于是进入 else 部分,也就是代码会为这两个表创建对应的 TablePlan 对象,接下来直接对这两个表执行 Product 操作,也就是将左边表的一行跟右边表的每一行合起来形成新表的一行,Product 操作在 STUDENT 和 EXAM 表后所得结果如下:
| id | name | student_id | exam | grad |
|---|---|---|---|---|
| 1 | Tom | 1 | math | A |
| 1 | Tom | 1 | algorithm | B |
| 1 | Tom | 2 | writing | A |
| 1 | Tom | 2 | physics | C |
| 1 | Tom | 3 | chemical | B |
| 1 | Tom | 3 | english | A |
| … | … | … | … | … |
接下来代码创建 ScanSelect 对象在上面的表上,接着获取该表的每一行,然后检测该行的 id 字段是否跟 student_id 字段一样,如果相同,那么查看其 grad 字段,如果该字段是’A’,就将该行的 name 字段显示出来。
下面我们看看如何使用代码把上面描述的流程实现出来。首先我们先对接口进行定义,在 Planner 目录下的 interface.go 文件中增加如下内容:
type QueryPlanner interface {CreatePlan(data *query.QueryData, tx tx.Transaction) Plan
}
接着在 Planner 目录下创建文件 query_planner.go,同时输入以下代码,代码的实现逻辑将接下来的文章中进行说明:
package plannerimport ("metadata_management""parser""tx"
)type BasicQueryPlanner struct {mdm *metadata_management.MetaDataManager
}func CreateBasicQueryPlanner(mdm *metadata_management.MetaDataManager) QueryPlanner {return &BasicQueryPlanner{mdm: mdm,}
}func (b *BasicQueryPlanner) CreatePlan(data *parser.QueryData, tx *tx.Transaction) Plan {//1,直接创建 QueryData 对象中的表plans := make([]Plan, 0)tables := data.Tables()for _, tblname := range tables {//获取该表对应视图的 sql 代码viewDef := b.mdm.GetViewDef(tblname, tx)if viewDef != nil {//直接创建表对应的视图parser := parser.NewSQLParser(viewDef)viewData := parser.Query()//递归的创建对应表的规划器plans = append(plans, b.CreatePlan(viewData, tx))} else {plans = append(plans, NewTablePlan(tx, tblname, b.mdm))}}//将所有表执行 Product 操作,注意表的次序会对后续查询效率有重大影响,但这里我们不考虑表的次序,只是按照//给定表依次执行 Product 操作,后续我们会在这里进行优化p := plans[0]plans = plans[1:]for _, nextPlan := range plans {p = NewProductPlan(p, nextPlan)}p = NewSelectPlan(p, data.Pred())return NewProjectPlan(p, data.Fields())
}上面代码中 QueryData就是解析器在解析 select 语句后生成的对象,它的 Tables 数组包含了 select 语句要查询的表,所以上面代码的 CreatePlan 函数先从 QueryData 对象获得 select 语句要查询的表,然后使用遍历这些表,使用 NewProductPlan 创建这些表对应的 Product 操作,最后在 Product 的基础上我们再创建 SelectPlan,这里我们就相当于使用 where 语句中的条件,在 Product 操作基础上将满足条件的行选出来,最后再创建 ProjectPlan,将在选出的行基础上,将需要的字段选择出来。
下面我们测试一下上面代码的效果,首先在 main.go 中,我们先把 student, exam 两个表构造出来,代码如下:
func createStudentTable() (*tx.Transation, *metadata_manager.MetaDataManager) {file_manager, _ := fm.NewFileManager("student", 2048)log_manager, _ := lm.NewLogManager(file_manager, "logfile.log")buffer_manager := bmg.NewBufferManager(file_manager, log_manager, 3)tx := tx.NewTransation(file_manager, log_manager, buffer_manager)sch := record_manager.NewSchema()mdm := metadata_manager.NewMetaDataManager(false, tx)sch.AddStringField("name", 16)sch.AddIntField("id")layout := record_manager.NewLayoutWithSchema(sch)ts := query.NewTableScan(tx, "student", layout)ts.BeforeFirst()for i := 1; i <= 3; i++ {ts.Insert() //指向一个可用插槽ts.SetInt("id", i)if i == 1 {ts.SetString("name", "Tom")}if i == 2 {ts.SetString("name", "Jim")}if i == 3 {ts.SetString("name", "John")}}mdm.CreateTable("student", sch, tx)exam_sch := record_manager.NewSchema()exam_sch.AddIntField("stuid")exam_sch.AddStringField("exam", 16)exam_sch.AddStringField("grad", 16)exam_layout := record_manager.NewLayoutWithSchema(exam_sch)ts = query.NewTableScan(tx, "exam", exam_layout)ts.BeforeFirst()ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 1)ts.SetString("exam", "math")ts.SetString("grad", "A")ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 1)ts.SetString("exam", "algorithm")ts.SetString("grad", "B")ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 2)ts.SetString("exam", "writing")ts.SetString("grad", "C")ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 2)ts.SetString("exam", "physics")ts.SetString("grad", "C")ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 3)ts.SetString("exam", "chemical")ts.SetString("grad", "B")ts.Insert() //指向一个可用插槽ts.SetInt("stuid", 3)ts.SetString("exam", "english")ts.SetString("grad", "C")mdm.CreateTable("exam", exam_sch, tx)return tx, mdm
}
然后我们用解析器解析select查询语句生成 QueryData 对象,最后使用BasicQueryPlanner创建好执行树和对应的 Scan 接口对象,最后我们调用 Scan 对象的 Next 接口来获取给定字段,代码如下:
func main() {//构造 student 表tx, mdm := createStudentTable()queryStr := "select name from student, exam where id = stuid and grad=\"A\""p := parser.NewSQLParser(queryStr)queryData := p.Query()test_planner := planner.CreateBasicQueryPlanner(mdm)test_plan := test_planner.CreatePlan(queryData, tx)test_interface := (test_plan.Open())test_scan, _ := test_interface.(query.Scan)for test_scan.Next() {fmt.Printf("name: %s\n", test_scan.GetString("name"))}}上面代码运行后所得结果如下:

从运行结果看到,代码成功执行了 sql 语句并返回了所需要的字段。请感兴趣的同学在 B 站搜索 coding 迪斯尼,通过视频的方式查看我的调试演示过程,这样才能对代码的设计有更好的理解,代码下载:
链接: https://pan.baidu.com/s/16ftSp46cU5NLisScq-ftZg 提取码: js99
相关文章:
自己动手写数据库: select 查询语句对应查询树的构造和执行
首先我们需要给原来代码打个补丁,在SelectScan 结构体初始化时需要传入 UpdateScan 接口对象,但很多时候我们需要传入的是 Scan 对象,因此我们需要做一个转换,也就是当初始化 SelectScan 时,如果传入的是 Scan 对象&am…...

扬声器(喇叭)
扬声器(喇叭) 电子元器件百科 文章目录 扬声器(喇叭)前言一、扬声器(喇叭)是什么二、扬声器(喇叭)的类别三、扬声器(喇叭)的应用场景四、扬声器(喇叭)的作用原理总结前言 扬声器广泛应用于音响系统、公共广播系统、汽车音响、电视、电脑和移动设备等各种电子设备…...
汇总大厂-校招/社招 Java面试题--持续补充更新中-大家别光收藏,要看起来,巩固基础,就是干呀!
** 接上篇-汇总大厂-校招/社招 Java面试题(补充) ** markdown文件。持续更新中(阿里、腾讯、网易、美团、京东、华为、快手、字节…) 上面这篇也结合着看啊,通宵给整理出来的。 如需下载整套资料。关注公众号后台。…...

六. 函数
基本使用 ts与js一样拥有具名函数和匿名函数两种函数类型。但是ts的函数需要提前定义好参数类型以及函数的返回值类型。 具名函数 function add(num1: number, num2: number):number {return num1 num2 }匿名函数 匿名函数的定义相对麻烦,我们需要提前定义函数的…...
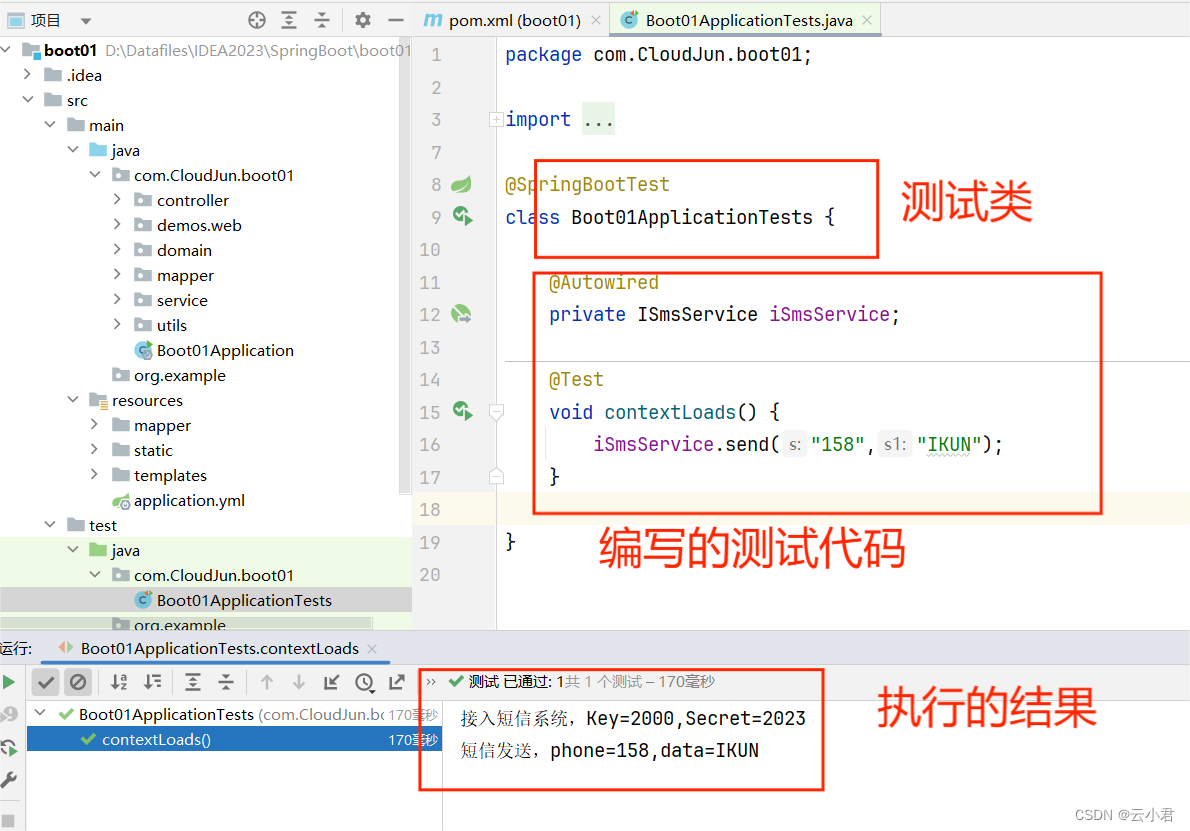
SpringBoot的Starter自动化配置,自己编写配置maven依赖且使用及短信发送案例
目录 一、Starter机制 1. 是什么 2. 有什么用 3. 应用场景 二、短信发送案例 1. 创建 2. 配置 3. 编写 4. 形成依赖 6. 其他项目的使用 每篇一获 一、Starter机制 1. 是什么 SpringBoot中的starter是一种非常重要的机制(自动化配置),能够抛弃以前繁杂…...

<蓝桥杯软件赛>零基础备赛20周--第9周--前缀和与差分
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

LeetCode-2487. 从链表中移除节点【栈 递归 链表 单调栈】
LeetCode-2487. 从链表中移除节点【栈 递归 链表 单调栈】 题目描述:解题思路一:可以将链表转为数组,然后从后往前遍历,遇到大于等于当前元素的就入栈,最终栈里面的元素即是最终的答案。解题思路二:递归&am…...

Redisson分布式锁原理分析
1.Redisson实现分布式锁 在分布式系统中,涉及到多个实例对同一资源加锁的情况,传统的synchronized、ReentrantLock等单进程加锁的API就不再适用,此时就需要使用分布式锁来保证多服务之间加锁的安全性。 常见的分布式锁的实现方式有ÿ…...
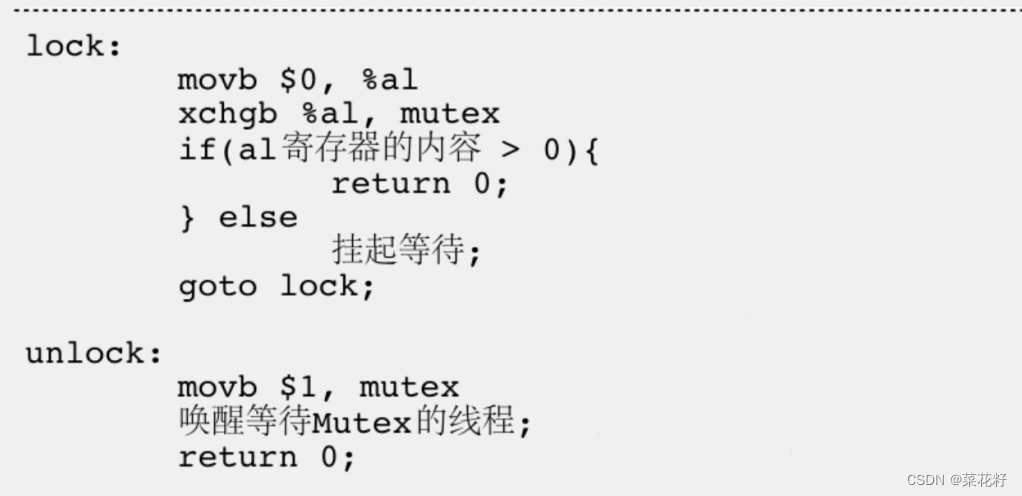
【Linux】:线程(二)互斥
互斥与同步 一.线程的局部存储二.线程的分离三.互斥1.一些概念2.上锁3.锁的原理4.死锁 一.线程的局部存储 例子 可以看到全局变量是所有线程共享的,如果我们想要每个线程都单独访问g_val怎么办呢?其实我们可以在它前面加上__thread修饰。 这就相当于把g…...

vscode报错Pylance client: couldn‘t create connection to server.
问题描述: 一打开vscode,右下角就弹报错,Pylance client: couldn’t create connection to server.,让我打开output,打开后似乎是在说连不上server 因为连不上server,所以我的python代码没法解析࿰…...

智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.萤火虫算法4.实验参数设定5.算法结果6.参考文…...
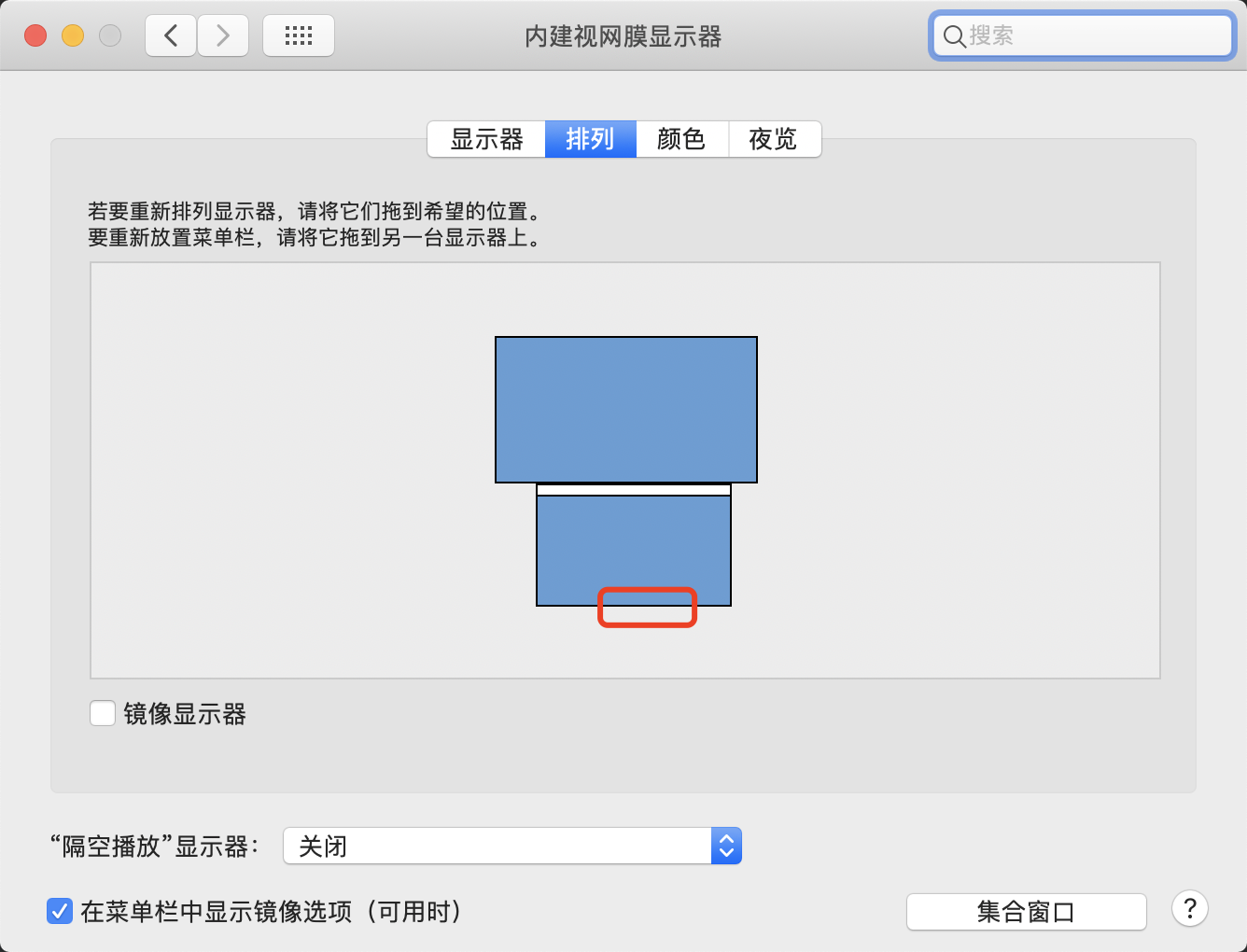
MacOS多屏状态栏位置不固定,程序坞不小心跑到副屏
目录 方式一:通过系统设置方式二:鼠标切换 MacOS多屏状态栏位置不固定,程序坞不小心跑到副屏 方式一:通过系统设置 先切换到左边 再切换到底部 就能回到主屏了 方式二:鼠标切换 我的两个屏幕放置位置如下 鼠标在…...
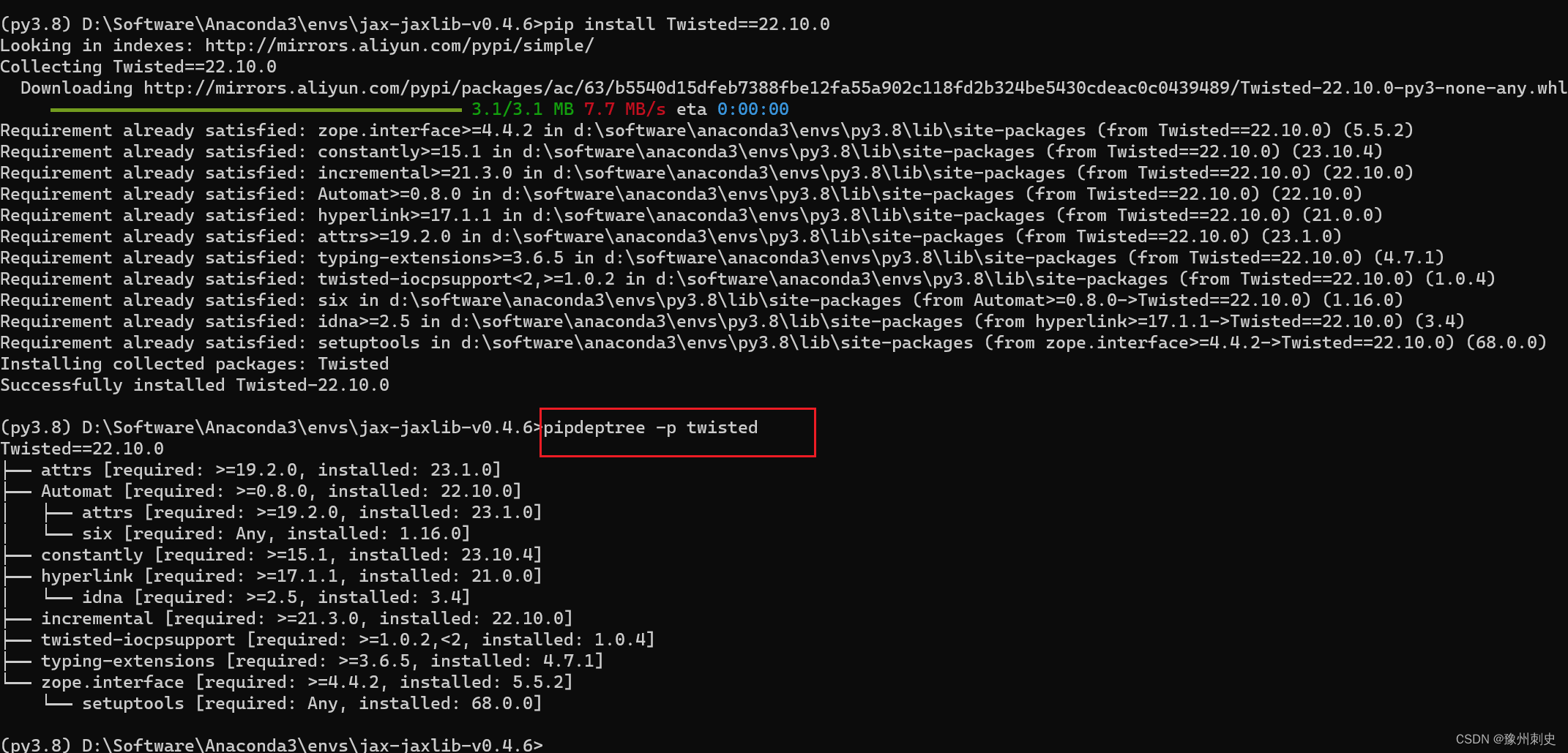
Python:pipdeptree 语法介绍
相信大家在按照一些包的时候经常会碰到版本不兼容,但是又不知道版本之间的依赖关系,今天给大家介绍一个工具:pipdeptree pipdeptree 是一个 Python 包,用于查看已安装的 pip 包及其依赖关系。它以树形结构展示包之间的依赖关系&am…...
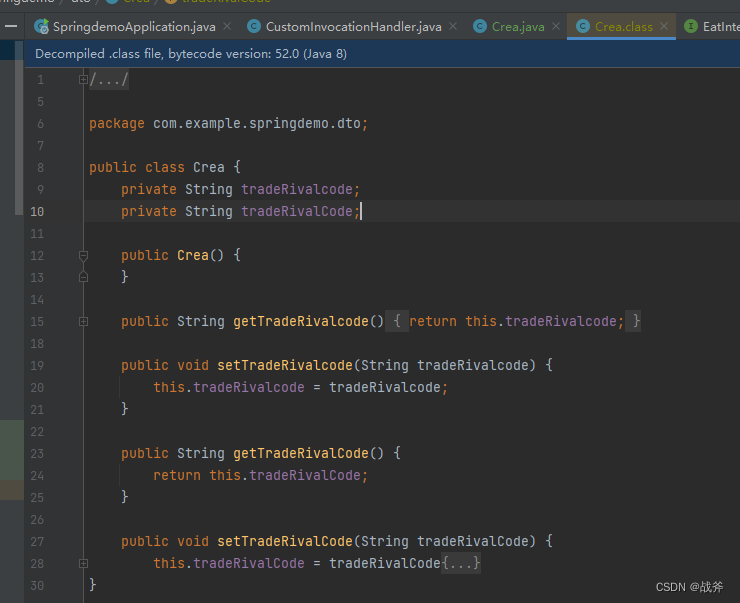
【问题处理】—— lombok 的 @Data 大小写区分不敏感
问题描述 今天在项目本地编译的时候,发现有个很奇怪的问题,一直提示某位置找不到符号, 但是实际在Idea中显示确实正常的,一开始以为又是IDEA的故障,所以重启了IDEA,并执行了mvn clean然后重新编译。但是问…...

跟着我学Python基础篇:08.集合和字典
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...
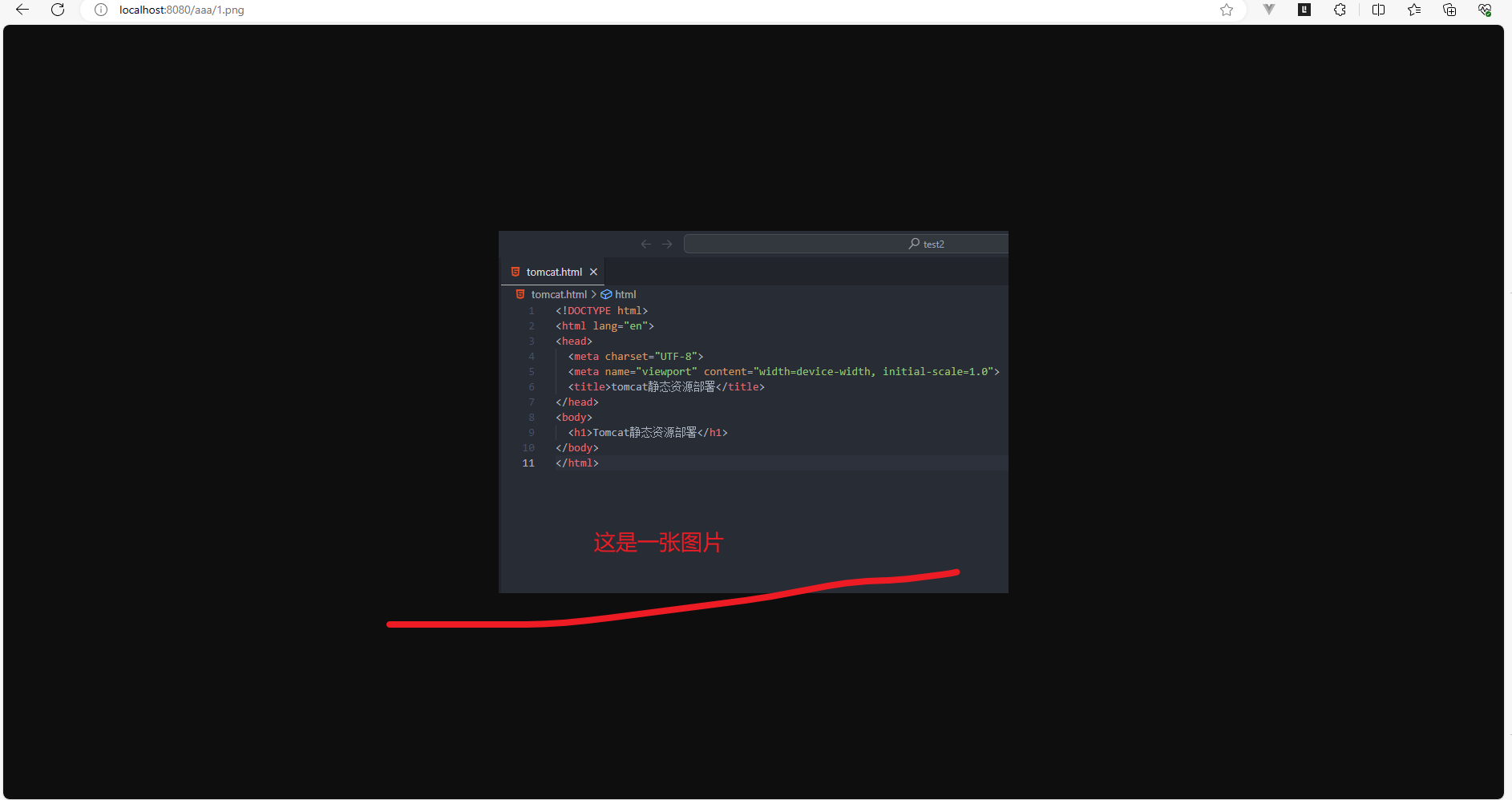
Tomcat部署(图片和HTML等)静态资源时遇到的问题
文章目录 Tomcat部署静态资源问题图中HTML代码启动Tomcat后先确认Tomcat是否启动成功 Tomcat部署静态资源问题 今天,有人突然跟我提到,使用nginx部署静态资源,如图片。可以直接通过url地址访问,为什么他的Tomcat不能通过这样的方…...

在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏?
引言 大家好,今天分享点个人经验。 有一定编程经验或者游戏开发经验的小伙伴,在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏? 利用现成开发框架。 1.什么是开发框架? 开发框架,顾名思…...

计网 - TCP四次挥手原理全曝光:深度解析与实战演示
文章目录 Pre导图过程分析抓包实战第一次挥手 【FIN ACK】第二次挥手 【ACK】第三次挥手 【FINACK】第四次挥手 【ACK】 小结 Pre 计网 - 传输层协议 TCP:TCP 为什么握手是 3 次、挥手是 4 次? 计网 - TCP三次握手原理全曝光:深度解析与实战…...

个人养老金知多少?
个人养老金政策你了解吗?税优政策你知道吗?你会计算能退多少税吗?… 点这里看一看...
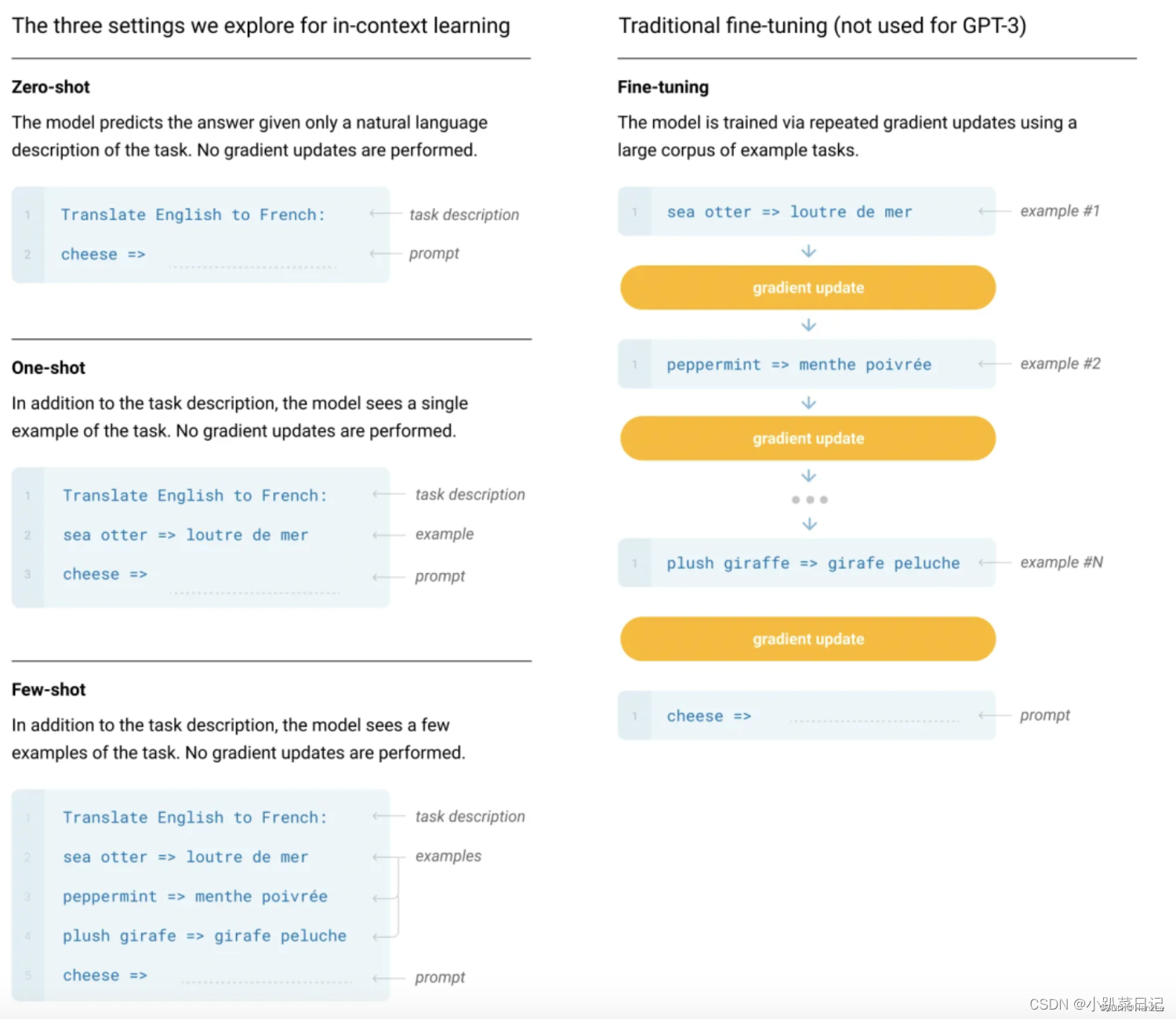
gpt3、gpt2与gpt1区别
参考:深度学习:GPT1、GPT2、GPT-3_HanZee的博客-CSDN博客 Zero-shot Learning / One-shot Learning-CSDN博客 Zero-shot(零次学习)简介-CSDN博客 GPT1、GPT2、GPT3、InstructGPT-CSDN博客 目录 gpt2与gpt1区别: gp…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...

基于RP2040与CircuitPython的HDMI倒计时器:RTC与DVI原生输出实践
1. 项目概述与核心价值如果你手头有一块带HDMI输出的微控制器开发板,比如Adafruit的Feather RP2040 DVI,又恰好需要一个能摆在桌面上、精确到秒的倒计时器,那么今天这个项目就是为你量身定做的。它不仅仅是一个简单的“Hello World”式显示应…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...

BiscuitLang:专为Web业务逻辑设计的轻量级脚本语言
1. 项目概述:一个为现代Web开发而生的轻量级语言如果你和我一样,长期在Web前端和全栈开发的泥潭里摸爬滚打,那你一定对JavaScript生态的“臃肿”与“复杂”深有体会。一个简单的项目动辄node_modules文件夹体积惊人,工具链配置繁琐…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

基于Arduino与加速度传感器的可穿戴智能徽章制作全解析
1. 项目概述:一个会“走路”的智能徽章几年前,当《Pokemon Go》风靡全球时,我注意到一个有趣的现象:深夜的公园里,总有一群玩家低头盯着手机屏幕,在昏暗的光线下穿梭。这固然是游戏的乐趣,但也带…...

龙芯3A6000平台Loongnix系统部署实战:从固件更新到驱动配置全解析
1. 项目概述:一次国产平台上的系统部署实战最近,我拿到了一台基于龙芯3A6000处理器和7A2000桥片的国产台式机。对于长期在x86/ARM生态里打转的开发者来说,这无疑是一个充满新鲜感和挑战的“新玩具”。它的核心使命,就是运行龙芯社…...

企业级自动化运维平台OpenClaw:微内核插件化架构与实战部署指南
1. 项目概述:企业级开源自动化运维平台的构建最近在和一些做企业IT运维的朋友聊天,大家普遍提到一个痛点:随着业务系统越来越复杂,服务器、中间件、数据库的规模成倍增长,传统的运维方式已经力不从心。半夜被报警电话叫…...