Python文本信息解析:从基础到高级实战‘[pp]]‘[

更多Python学习内容:ipengtao.com
大家好,我是彭涛,今天为大家分享 Python文本信息解析:从基础到高级实战,全文3600字,阅读大约10分钟。
文本处理是Python编程中一项不可或缺的技能,覆盖了广泛的应用领域,从字符串操作到正则表达式、自然语言处理和数据格式解析。在这篇文章中,将深入研究如何在Python中解析文本信息,提供详实的示例代码和实战指南,让大家更加全面地掌握文本处理的技术和应用。
基础字符串操作
从基础的字符串操作开始。通过示例代码展示了如何分割字符串、查找子串以及替换文本,这些是处理文本的常见操作。
text = "Python is a powerful programming language."# 分割字符串
words = text.split()
print("Words:", words)# 查找子串
substring = "powerful"
if substring in text:print(f"'{substring}' found in the text.")# 替换文本
new_text = text.replace("Python", "Ruby")
print("Updated Text:", new_text)正则表达式应用
正则表达式是处理文本的强大工具,通过示例展示了如何使用正则表达式匹配社会安全号(SSN)。
import repattern = r'\b\d{3}-\d{2}-\d{4}\b' # 匹配社会安全号
text = "John's SSN is 123-45-6789."match = re.search(pattern, text)
if match:ssn = match.group()print("SSN found:", ssn)使用NLTK进行自然语言处理
自然语言处理(NLP)在文本处理中占据重要地位。通过NLTK库展示了如何分词并去除停用词。
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwordsnltk.download('punkt')
nltk.download('stopwords')text = "Natural Language Processing is fascinating!"# 分词
tokens = word_tokenize(text)
print("Tokens:", tokens)# 去除停用词
filtered_tokens = [word for word in tokens if word.lower() not in stopwords.words('english')]
print("Filtered Tokens:", filtered_tokens)解析JSON数据
JSON是一种常见的数据格式,展示如何解析JSON数据并访问其中的字段。
import jsonjson_data = '{"name": "John", "age": 30, "city": "New York"}'# 解析JSON
parsed_data = json.loads(json_data)
print("Parsed Data:", parsed_data)# 访问JSON字段
print("Name:", parsed_data['name'])处理CSV文件
CSV文件是一种常见的数据存储格式。演示如何解析CSV文件并访问其中的数据。
import csvcsv_data = """Name, Age, City
John, 25, London
Alice, 30, Paris
Bob, 22, New York
"""# 解析CSV
csv_reader = csv.DictReader(csv_data.splitlines())
for row in csv_reader:print("Name:", row['Name'], "Age:", row[' Age'], "City:", row[' City'])使用Beautiful Soup解析HTML
Beautiful Soup是一个强大的HTML解析库,展示如何使用它解析HTML并提取文本内容。
from bs4 import BeautifulSouphtml_data = "<html><body><p>Hello, <b>world!</b></p></body></html>"# 解析HTML
soup = BeautifulSoup(html_data, 'html.parser')
text_content = soup.get_text()
print("Text Content:", text_content)利用正则表达式提取信息
再次展示正则表达式的应用,使用正则表达式提取文本中的邮箱地址。
import retext = "Contact us at support@example.com or sales@example.com"# 提取邮箱地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, text)
print("Emails:", emails)处理日期时间信息
演示如何解析日期字符串并将其转换为日期对象。
from datetime import datetimedate_string = "2023-01-15"# 解析日期字符串
parsed_date = datetime.strptime(date_string, "%Y-%m-%d")
print("Parsed Date:", parsed_date)文本信息分析与情感分析
文本信息分析涉及到对文本内容的深入理解和处理。
下面是一个简单的情感分析示例,使用TextBlob库。
from textblob import TextBlobtext = "Python is such a powerful language with a beautiful syntax."# 创建TextBlob对象
blob = TextBlob(text)# 分析情感
sentiment_score = blob.sentiment.polarity
if sentiment_score > 0:print("Positive sentiment!")
elif sentiment_score < 0:print("Negative sentiment!")
else:print("Neutral sentiment.")中文文本处理
针对中文文本处理,可以使用jieba库进行分词和关键词提取。
import jieba
from jieba.analyse import extract_tagschinese_text = "自然语言处理在中文信息处理中具有重要作用。"# 中文分词
seg_list = jieba.cut(chinese_text)
print("Chinese Segmentation:", "/".join(seg_list))# 提取关键词
keywords = extract_tags(chinese_text)
print("Chinese Keywords:", keywords)处理大型文本文件
对于大型文本文件,逐行读取是一个高效的方式。
以下是一个处理大型文本文件的示例:
file_path = "large_text_file.txt"# 逐行读取大型文本文件
with open(file_path, 'r') as file:for line in file:# 处理每行文本processed_line = line.strip()print(processed_line)使用Spacy进行高级自然语言处理
Spacy是一个强大的自然语言处理库,支持词性标注、命名实体识别等任务。
import spacynlp = spacy.load("en_core_web_sm")
text = "Spacy is an advanced NLP library."# 使用Spacy进行词性标注
doc = nlp(text)
for token in doc:print(f"Token: {token.text}, POS: {token.pos_}")总结
在本文中,深入研究了Python中解析文本信息的多个方面,从基础的字符串操作、正则表达式应用到高级的自然语言处理和大型文本文件处理。通过详实的示例代码,大家可以全面了解如何处理不同类型的文本数据,并运用强大的Python库和工具进行文本信息分析。
从处理英文文本的基础出发,介绍了字符串操作、正则表达式的妙用,以及自然语言处理库NLTK的应用。接着,展示了如何解析JSON数据、处理CSV文件,利用Beautiful Soup解析HTML,甚至深入到了情感分析和中文文本处理领域。对于大型文本文件,提供了逐行处理的高效方式,同时演示了Spacy库在高级自然语言处理中的应用。
这篇文章不仅提供了全面的文本处理技术,还为大家展示了如何根据任务需求选择合适的工具。从简单的字符串处理到复杂的自然语言处理,Python为文本数据的解析提供了强大的生态系统。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容
相关文章:
Python文本信息解析:从基础到高级实战‘[pp]]‘[
更多Python学习内容:ipengtao.com 大家好,我是彭涛,今天为大家分享 Python文本信息解析:从基础到高级实战,全文3600字,阅读大约10分钟。 文本处理是Python编程中一项不可或缺的技能,覆盖了广泛的…...

c语言多线程队列实现
为了用c语言实现队列进行多线程通信,用于实现一个状态机。 下面是实现过程 1.实现多线程队列入栈和出栈,不加锁 发送线程发送字符1,接收线程接收字符并打印。 多线程没有加锁,会有危险 #include "stdio.h" #include …...

一分钟带你了解电容
电容器中的电容究竟是怎么定义的? 一个电容器,如果带1库的电量时两级间的电势差是1伏,这个电容器的电容就是1法拉,即:CQ/U 。但电容的大小不是由Q(带电量)或U(电压)决定…...

SQLAlchemy 第一篇
安装SQLAlchemy pip install SQLAlchemy查看当前版本 # 查看当前版本import sqlalchemyprint(sqlalchemy.__version__)2.0.23创建数据库连接 此处我们以pymysql为mysql的数据库驱动 安装pymysql pip install pymysqlfrom sqlalchemy import create_engine engine create_…...

Node.js模块化的基本概念和分类及使用方法
1.模块概念 模块:指解决一个复杂问题的时候,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来讲,模块是可以组合、分解和更换的单元。 在编辑领域中的模块,就是遵守固定的规则,把一个大文件拆成独立并且相互…...
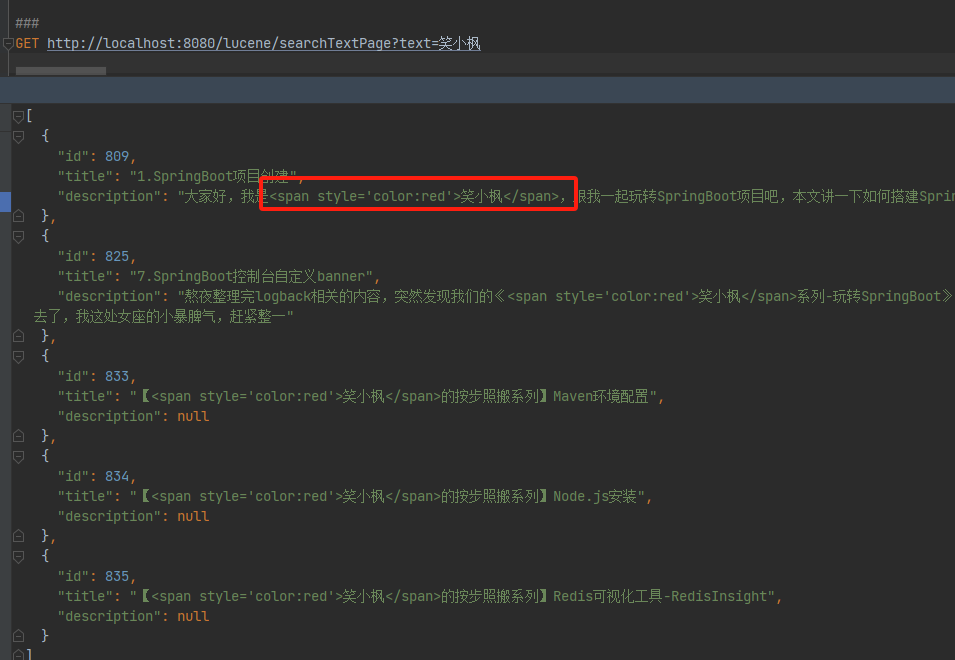
SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录 1. 项目背景2. 什么是Lucene3. 引入依赖,配置索引3.1 引入Lucene依赖和分词器依赖3.2 表结构和数据准备3.3 创建索引3.4 修改索引3.5删除索引 4. 数据检索4.1 基础搜索4.2 一个关键词,在多个字段里面搜索4.3 搜索结果高亮显示4.4 分页检…...

基于ssm生活缴费系统及相关安全技术的设计与实现论文
摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对生活缴费信息管理混乱,出错率高,信息安全性差…...
VS的python没有pandas(VS连接mysql数据库)
import pandas as pd from sqlalchemy import create_engine# 初始化数据库连接 engine create_engine(mysqlpymysql://root:556localhost:3306/仓库)sql_chaSELECT * FROM 库房 print(sql_cha) df_read pd.read_sql_query(sql_cha, engine); print(df_read);VS连接mysql如上…...

Java实现pdf文件合并
在maven项目中引入以下依赖包 <dependencies><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-examples</artifactId><version>3.0.1</version></dependency><dependency><groupId>co…...
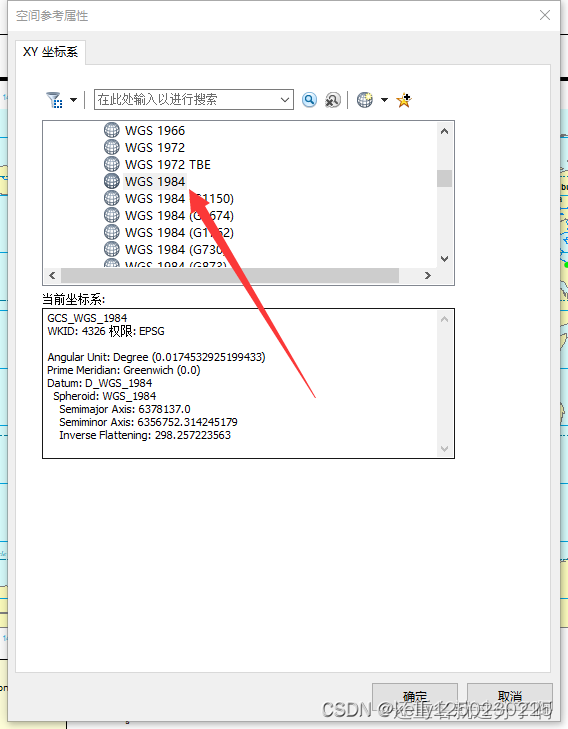
ArcGIS导入excel中的经纬度信息,绘制矢量
1.首先整理坐标信息 2.其次转成2003格式的excel文件 3.导入arcgis,点击右键添加excel数据 4.显示xy数据 5.显示经度和纬度信息 6:点击【地理坐标系】->【World】->【WGS 1984】->【确定】 7.投影带的确定方式: 因为自己一直…...
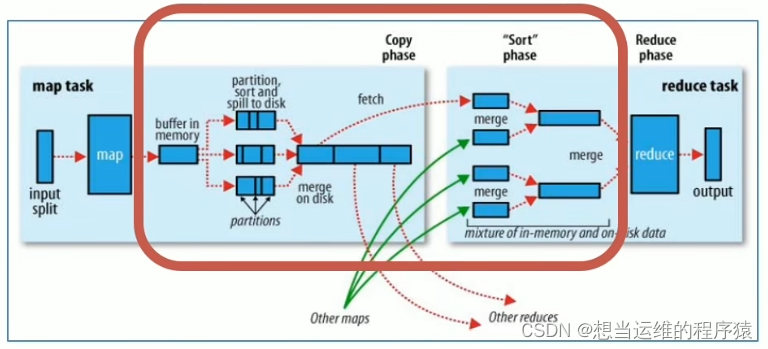
【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。 组件配置文件启动进程备注Hadoop HDFS需修改需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助分…...
GitHub帐户管理更改电子邮件
登录到您的 GitHub 帐户: 前往 GitHub 网站并使用您的凭据登录。 访问个人设置: 单击右上角的您的头像,然后选择“Settings”(设置)。 选择电子邮件选项卡: 在左侧边栏中选择“Emails”(电子邮…...

InsCode实践分享
一、背景介绍 随着社交媒体的普及,越来越多的品牌和商家开始关注如何利用社交媒体平台来提高品牌知名度和销售额。其中,Instagram作为一个以图片和视频为主要内容的社交媒体平台,已经成为了很多品牌和商家进行营销的重要渠道。InsCode是Inst…...

大一C语言作业 12.14
1.A A:将pa指向的元素赋值给x,即x a[0] B:将a数组第二个元素的值赋给x,即x a[1] C:将pa指向的下一个元素的值赋给x,即x a[1] D:将a数组第二个元素的值赋给x,即x a[1] 2. 6 2 3 …...

微服务技术 RabbitMQ SpringAMQP P61-P76
B站学习视频https://www.bilibili.com/video/BV1LQ4y127n4?p61&vd_source8665d6da33d4e2277ca40f03210fe53a 文档资料: 链接:https://pan.baidu.com/s/1P_Ag1BYiPaF52EI19A0YRw?pwdd03r 提取码:d03r 一 初始MQ 1. 同步通讯 2. 异步通讯 3. MQ常…...
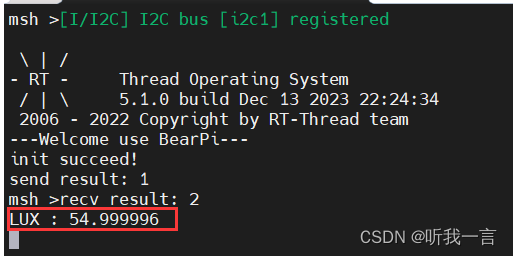
BearPi Std 板从入门到放弃 - 先天神魂篇(3)(RT-Thread I2C设备 读取光照强度BH1750)
简介 使用BearPi IOT Std开发板及其扩展板E53_SC1, SC1上有I2C1 的光照强度传感器BH1750 和 EEPROM AT24C02, 本次主要就是读取光照强度; 主板: 主芯片: STM32L431RCT6LED : PC13 \ 推挽输出\ 高电平点亮串口: Usart1I2C使用 : I2C1E53_SC1扩展板 : LE…...

中文分词演进(查词典,hmm标注,无监督统计)新词发现
查词典和字标注 目前中文分词主要有两种思路:查词典和字标注。 首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。 查词典的方法…...

Docker容器数据卷
一、概念 1.定义 卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性。 卷的设计目的就是数据的持久化,完全独…...
chatGPT 国内版,嵌入midjourney AI创作工具
聊天GPT国内入口,免切网直达,可直接多语言对话,操作简单,无需复杂注册,智能高效,即刻使用.可以用作个人助理,学习助理,智能创作、新媒体文案创作、智能创作等各种应用场景! 地址: https://ai.wboat.cn/...

Yum仓库架构解析与搭建实践
1.Yum仓库搭建 1.1本地Yum仓库图解 1.2Linux本地仓库搭建 配置本地光盘镜像仓库 1)挂载 [roothadoop101 ~]# mount -t iso996 /dev/cdrom/mnt 2)查看 [rooothadoop101 ~] # df -h | |grep -i mnt /dev/sr0 4.6G 4.4G 3…...

qt中自定义槽函数 内部继承逻辑、GUI+CLI协同1.0
bit::Shadow✧(≖ ◡ ≖✿ 目录 qt配置环境 QWidget父类 子类构造函数内显示调用父类构造函数 QT内核分析 自定义槽函数 GUI(图形化实现) Ⅰ按钮 Ⅱ右键按钮转到槽函数实现 CLI(命令行界面) Ⅲ功能槽(slot&a…...

从零理解无刷电机方波驱动:用STM32CubeMX配置TIM1 PWM与EXTI中断实现换相
STM32无刷电机方波驱动实战:CubeMX配置与六步换相详解 1. 无刷电机驱动基础认知 无刷直流电机(BLDC)凭借高效率、长寿命和低噪音特性,已成为工业自动化、消费电子和智能家居领域的核心动力元件。与传统有刷电机相比,BL…...

Midjourney立体主义风格生成成功率骤降?这5个隐藏变量正在 silently corrupt 你的构图——资深提示工程师紧急诊断报告
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格生成失效的系统性现象确认 近期大量用户反馈,在 Midjourney v6 及后续快速迭代版本中,使用经典立体主义(Cubism)提示词࿰…...

别再只懂install_github了!深入聊聊R包管理:GitHub PAT、依赖与Linux系统库的那些事儿
别再只懂install_github了!深入聊聊R包管理:GitHub PAT、依赖与Linux系统库的那些事儿 在数据科学和统计分析的世界里,R语言凭借其强大的包生态系统和活跃的开源社区,已经成为许多专业人士的首选工具。然而,当我们从个…...

Python开发者三步完成Taotoken API密钥配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken API密钥配置与调用 对于希望快速接入大模型能力的Python开发者而言,Taotoken平台提供的…...

前端入门必学:CSS盒子模型与图片样式全解析前言
在学习前端开发的过程中,掌握 CSS 的基础知识是至关重要的一步。本文将详细介绍 CSS 盒子模型、标签宽高、边框、边距 以及 图片与背景图片 的使用方法,适合刚入门的同学系统学习和复习。一、CSS 盒子模型——页面布局的基石1. 什么是盒子模型࿱…...

纺织行业智能化升级进入深水区:AI验布机从“可选项”变为“必选项”
过去三年,走访过数十家纺织服装企业的行业观察者会发现一个明显的变化:2023年时,AI验布机还是展会上引人驻足的新奇设备;到了2025年,它已经成为越来越多工厂标准配置的一部分。这一转变背后,折射出整个纺织…...
)
libhv实战:手把手教你用C++写一个带自动重连的WebSocket客户端(附避坑指南)
libhv实战:构建高可靠WebSocket客户端的工程化实践 在实时数据采集和监控系统中,WebSocket客户端的稳定性直接决定了业务连续性。当网络出现闪断、服务端重启或负载波动时,简单的连接断开可能导致关键数据丢失。libhv作为高性能网络库&#x…...

RK3576开发板AIoT实战:从模型转换到边缘部署全流程解析
1. 项目概述:从一块开发板到AI应用落地的完整旅程 最近几年,AIoT(人工智能物联网)的概念越来越火,但很多开发者朋友拿到一块功能强大的开发板后,往往卡在“如何把AI模型真正跑起来”这一步。我手头这块RK35…...

Redis分布式锁进阶第一二十五篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...