【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。
| 组件 | 配置文件 | 启动进程 | 备注 |
|---|---|---|---|
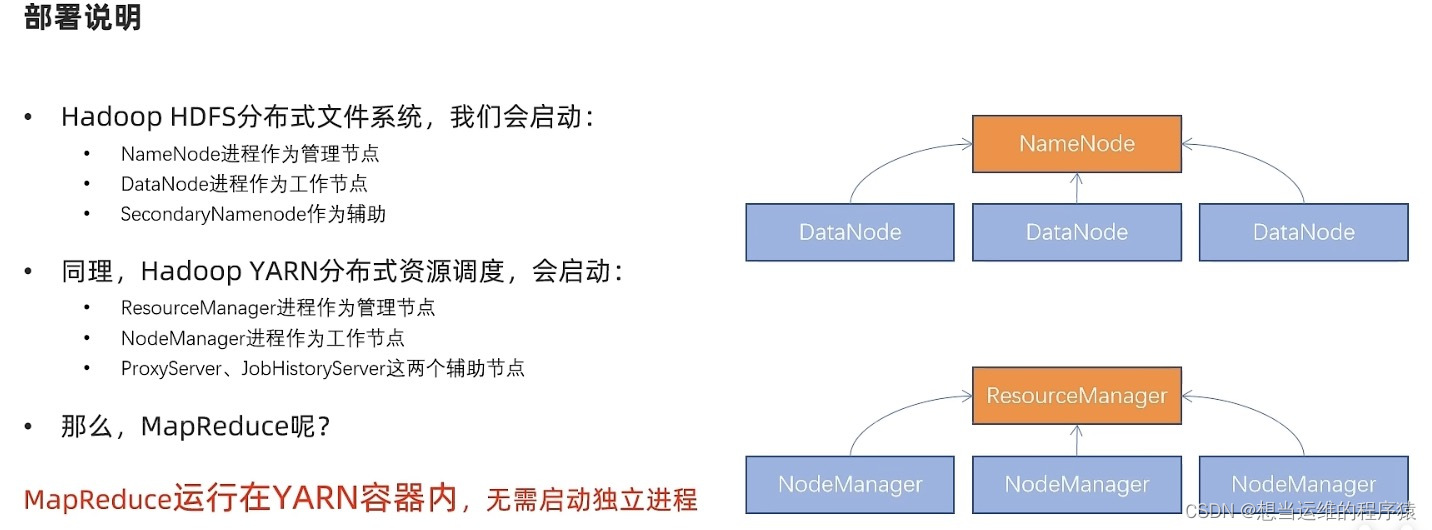
| Hadoop HDFS | 需修改 | 需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助 | 分布式文件系统 |
| Hadoop YARN | 需修改 | 需启动 ResourceManager(RM)作为集群资源管理者 NodeManager(NM)作为单机资源管理者 ProxyServer代理服务器提供安全性 JobHistoryServer历史服务器记录历史信息和日志 | 分布式资源调度 |
| Hadoop MapReduce | 需修改 | 无需启动任何进程 MapReduce程序运行在YARN容器内 | 分布式数据计算 |
Hadoop集群 = HDFS集群 + YARN集群
图中是三台服务器,每个服务器上运行相应的JAVA进程
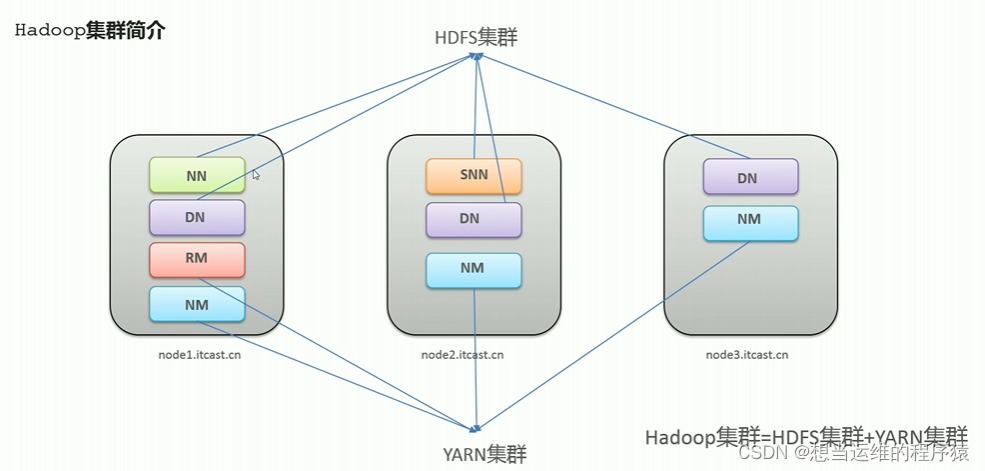
HDFS集群对应的web UI界面:
http://namenode_host:9870(namenode_host是namenode运行所在服务器的ip地址)
YARN集群对应的web UI界面:http://resourcemanager_host:8088(resourcemanager_host是resourcemanager运行所在服务器的ip地址)
一、HDFS
1.1 HDFS简介
- HDFS的全称为Hadoop Distributed File System,是用来解决大数据存储问题的,分布式说明其是横跨多台服务器上的存储系统
- HDFS使用多台服务器存储文件,提供统一的访问接口,使用户像访问一个普通文件系统一样使用分布式文件系统
- HDFS集群搭建完成后有个抽象统一的目录树,可以向其中放入文件,底层实际是分块存储(物理上真的拆分成多个文件,默认128M拆分成一块)在HDFS集群的多个服务器上,具体位置是在hadoop的配置文件中所指定的
1.2 HDFS shell命令行
- 命令行界面(command-line interface,缩写:cli),指用户通过指令进行交互
- Hadoop操作文件系统shell命令行语法:
hadoop fs [generic options]- 大部分命令与linux相同
hadoop fs -ls file:/// # 操作本地文件系统
hadoop fs -ls hdfs://node1:8020/ # 操作HDFS文件系统,node1:8020是NameNode运行所在的机器和端口号
hadoop fs -ls / #直接根目录,没有指定则默认加载读取环境变量中fs.defaultFS的值,作为要读取的文件系统
上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> <dst>
# 将本地文件传到HDFS文件系统中
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# <localsrc>本地文件系统中的文件(客户端所在机器),<dst>HDFS文件系统的目录
下载HDFS文件
hadoop fs -get [-f] [-p] <src> <localdst>
# 将本地文件传到HDFS文件系统中
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# <src>HDFS文件系统中的文件,<localdst>本地文件系统的目录
追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc>...<dst>
# <localsrc>本地文件系统中的文件,<dst>HDFS文件系统的文件(没有文件则自动创建)
# 该命令可以用于小文件合并
1.3 HDFS架构
HDFS包含3个进程NameNode、DataNode、SecondaryNameNode
(都是Java进程,可以在服务器上运行jps查看正在执行的java进程)
HDFS是主从模式(Master - Slaves),基础架构如下:
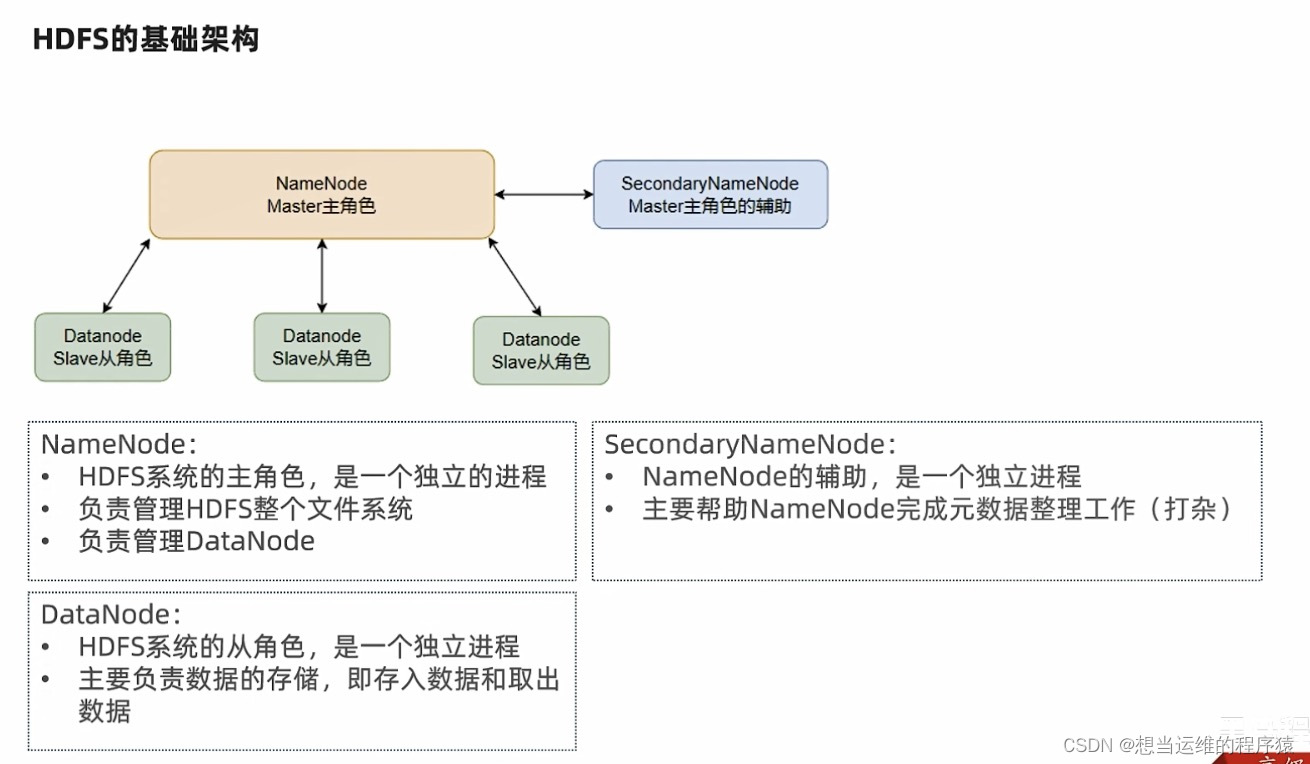
- NameNode: 维护和管理文件系统元数据,包括HDFS目录树结构,文件和块的存储位置、大小、访问权限等信息。NameNode是访问HDFS的唯一入口
- DataNode: 负责具体的数据块存储
- SecondNameNode: 是NameNode的辅助节点,但不能替代NameNode。主要是帮助NameNode进行元数据文件的合并。
- NameNode不持久化存储每个文件中各个块所在的DataNode的位置信息,这些信息在系统启动时从DataNode重建
- NameNode是Hadoop集群中的单点故障
- NameNode所在机器通常配置大内存(RAM),因为元数据都存在内存中,定时进行持久化存到磁盘中。
- DataNode所在机器通常配置大硬盘空间,因为数据存在DataNode中
HDFS集群部署举例:
node1、node2、node3表示三台服务器,形成一个集群:

node1服务器性能比较高,因此在node1上运行三个进程:NameNode、DataNode、SecondaryNameNode
在node2及node3上只运行DataNode进程
1.4 HDFS写数据流程
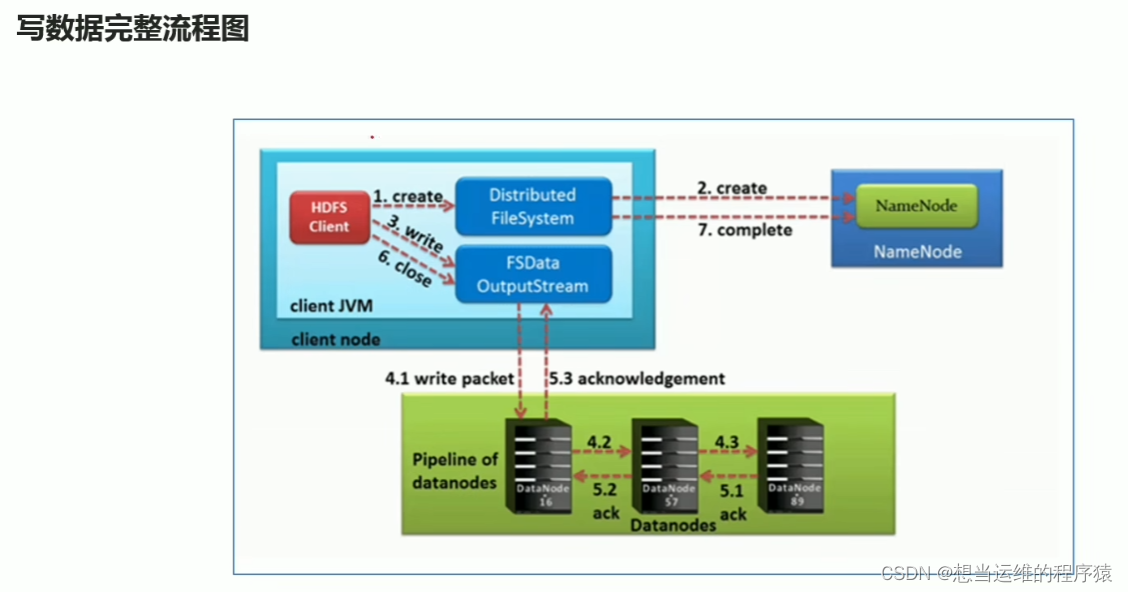
- HDFS客户端创建对象实例DistributeFileSystem(Java类的对象),该对象中封装了与HDFS文件系统操作的相关方法。
- 调用DistributeFileSystem对象的create()方法,通过RPC请求NameNode创建文件,NameNode执行各种检查判断:目标文件是否存在,客户端是否有权限等。检查通过后返回FSDataOutputStream输出流对象给客户端用于写数据。
- 客户端用FSDataOutputStream开始写数据
- 客户端写入数据时,将数据分成一个个数据包(packet 默认64k),内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储(即3个DataNode)。DataStreamer将数据包流式传输(每一个packet 64k传输一次)到pipeline的第一个DataNode,第一个DataNode存储数据后传给第二个DataNode,第二个DataNode存储数据后传给第三个DataNode。
- 传输的反方向上,会通过ACK机制校验数据包传输是否成功
- 客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
- DistributeFileSystem告诉NameNode文件写入完成。
二、Yarn
2.1 Yarn简介
Yarn是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
通用: 不仅支持MapReduce程序,理论上支持各种计算程序,YARN只负责分配资源,不关心用资源干什么。
资源管理系统: 集群的硬件资源,和程序运行相关,比如内存、cpu等
调度平台: 多个程序同时申请计算资源如何分配,调度的规则
2.2 Yarn架构
Yarn与HDFS一样,也是主从模式,包含以下4个进程
- ResourceManager:管理整个群集的资源,负责协调调度各个程序所需的资源。(申请资源必须找RM)
- NodeManager:管理单个服务器的资源,负责调度单个服务器上的资源提供给应用程序使用。
NodeManager通过创建Container容器来分配服务器上的资源。
应用程序运行在NodeManager所创建的容器中。
一个服务器上可以创建多个Container容器,各Container容器之间相互独立,实现了一个服务器上跑多个程序。
Container容器是具体运行 Task(如 MapTask、ReduceTask)的基本单位。
- ProxyServer代理服务器: ProxyServer默认继承在ResourceManager中,可以通过配置分离出来单独启动,可以提高YARN在开放网络中的安全性。
- JobHistoryServer历史服务器: 记录历史程序运行信息和日志,开放web ui提供用户通过网页访问日志。
YARN架构图:
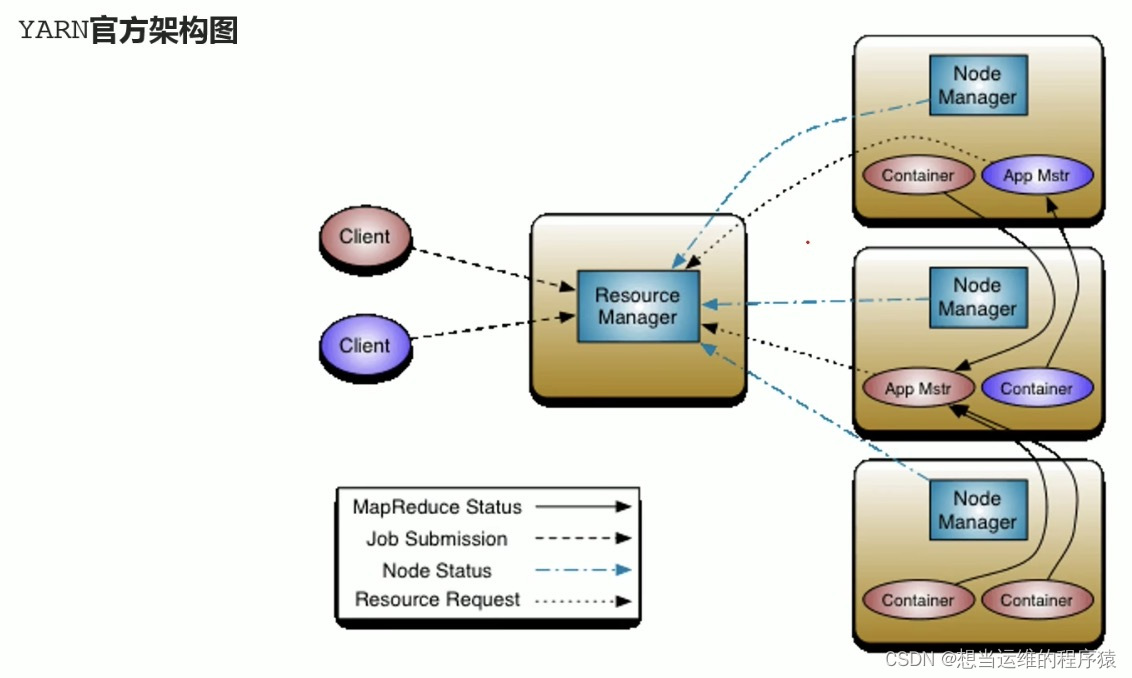
ApplicationMaster(App Mstr): 应用程序内的“老大”,负责程序内部各阶段的资源申请,管理整个应用。(当YARN上没有程序运行,则没有这个组件)
一个应用程序对应一个ApplicationMaster。
ApplicationMaster 运行在 Container 中,运行应用的各个任务(比如 MapTask、ReduceTask)。
YARN 中运行的每个应用程序都有一个自己独立的 ApplicationMaster。(以MapReduce为例,其中的MRAppMaster就是对应的具体实现,管理整个MapReduce程序)
YARN集群部署举例:
node1、node2、node3表示三台服务器,形成一个集群:

node1性能高,因此在node1上运行四个进程:ResourceManager、NodeManager、ProxyServer、JobHistoryServer
在node2及node3上只运行NodeManager进程
三、MapReduce
MapReduce程序在运行时有三类进程:
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask: 负责map阶段的整个数据处理流程
- ReduceTask: 负责reduce阶段的整个数据处理流程
- 在一个MR程序中MRAppMaster只有一个,MapTask和ReduceTask可以有一个也可以有多个
- 在一个MR程序中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段
- 在整个MR程序中,数据都是以kv键值对的形式流转的
MapReduce整体执行流程图:
左边是maptask,右边是reducetask,红框里是shuffle过程(shuffle包含了map和reduce)
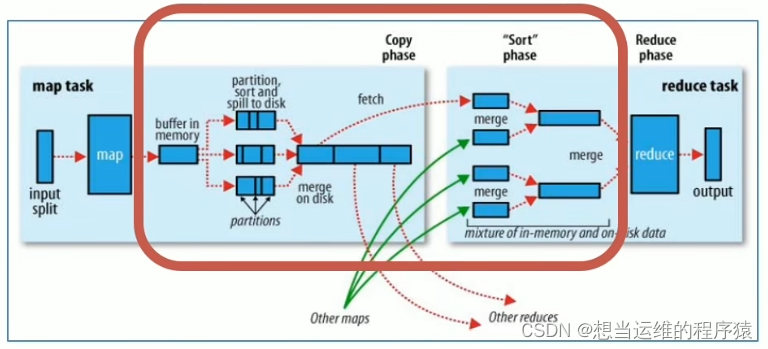
2.1 map阶段执行过程
- 第一阶段: 把所要处理的文件进行逻辑切片(默认是每128M一个切片),每一个切片由一个MapTask处理。
- 第二阶段: 按行读取切片中的数据,返回<key,value>对,key对应行数,value是本行的文本内容
- 第三阶段: 调用Mapper类中的map方法处理数据,每读取解析出来一个<key,value>,调用一次map方法
- 第四阶段(默认不分区): 对map输出的<key,value>对进行分区partition。默认不分区,因为只有一个reducetask,分区的数量就是reducetask运行的数量。
- 第五阶段: Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key按照字典序(a~z)进行排序sort
- 第六阶段: 对所有溢出文件进行最终的merge合并,形成一个文件(即一个maptask只输出一个文件)
2.2 reduce阶段执行过程
- 第一阶段: ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据
- 第二阶段: 把拉取来的数据,全部进行合并merge,即把分散的数据合并成一个大的数据,再对合并后的数据进行排序
- 第三阶段: 对排序后的<key,value>调用reduce方法,key相同<key,value>调用一次reduce方法。最后把输出的键值对写入到HDFS中
2.3 shuffle机制
- shuffle指的是将map端的无规则输出变成具有一定规则的数据,便于reduce端接收处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称为Shuffle
- Shuffle过程是横跨map和reduce两个阶段的,分别称为Map端的Shuffle和Reduce端的Shuffle
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复,是导致mapreduce计算慢的原因
相关文章:
【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。 组件配置文件启动进程备注Hadoop HDFS需修改需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助分…...
GitHub帐户管理更改电子邮件
登录到您的 GitHub 帐户: 前往 GitHub 网站并使用您的凭据登录。 访问个人设置: 单击右上角的您的头像,然后选择“Settings”(设置)。 选择电子邮件选项卡: 在左侧边栏中选择“Emails”(电子邮…...

InsCode实践分享
一、背景介绍 随着社交媒体的普及,越来越多的品牌和商家开始关注如何利用社交媒体平台来提高品牌知名度和销售额。其中,Instagram作为一个以图片和视频为主要内容的社交媒体平台,已经成为了很多品牌和商家进行营销的重要渠道。InsCode是Inst…...

大一C语言作业 12.14
1.A A:将pa指向的元素赋值给x,即x a[0] B:将a数组第二个元素的值赋给x,即x a[1] C:将pa指向的下一个元素的值赋给x,即x a[1] D:将a数组第二个元素的值赋给x,即x a[1] 2. 6 2 3 …...

微服务技术 RabbitMQ SpringAMQP P61-P76
B站学习视频https://www.bilibili.com/video/BV1LQ4y127n4?p61&vd_source8665d6da33d4e2277ca40f03210fe53a 文档资料: 链接:https://pan.baidu.com/s/1P_Ag1BYiPaF52EI19A0YRw?pwdd03r 提取码:d03r 一 初始MQ 1. 同步通讯 2. 异步通讯 3. MQ常…...
BearPi Std 板从入门到放弃 - 先天神魂篇(3)(RT-Thread I2C设备 读取光照强度BH1750)
简介 使用BearPi IOT Std开发板及其扩展板E53_SC1, SC1上有I2C1 的光照强度传感器BH1750 和 EEPROM AT24C02, 本次主要就是读取光照强度; 主板: 主芯片: STM32L431RCT6LED : PC13 \ 推挽输出\ 高电平点亮串口: Usart1I2C使用 : I2C1E53_SC1扩展板 : LE…...

中文分词演进(查词典,hmm标注,无监督统计)新词发现
查词典和字标注 目前中文分词主要有两种思路:查词典和字标注。 首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。 查词典的方法…...

Docker容器数据卷
一、概念 1.定义 卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性。 卷的设计目的就是数据的持久化,完全独…...
chatGPT 国内版,嵌入midjourney AI创作工具
聊天GPT国内入口,免切网直达,可直接多语言对话,操作简单,无需复杂注册,智能高效,即刻使用.可以用作个人助理,学习助理,智能创作、新媒体文案创作、智能创作等各种应用场景! 地址: https://ai.wboat.cn/...

Yum仓库架构解析与搭建实践
1.Yum仓库搭建 1.1本地Yum仓库图解 1.2Linux本地仓库搭建 配置本地光盘镜像仓库 1)挂载 [roothadoop101 ~]# mount -t iso996 /dev/cdrom/mnt 2)查看 [rooothadoop101 ~] # df -h | |grep -i mnt /dev/sr0 4.6G 4.4G 3…...
ElementPlus中的分页逻辑与实现
ElementPlus中的分页逻辑与实现 分页是web开发中必不可少的组件,element团队提供了简洁美观的分页组件,配合table数据可以实现即插即用的分页效果。分页的实现可以分成两种,一是前端分页,二是后端分页。这两种分页分别适用于不同…...
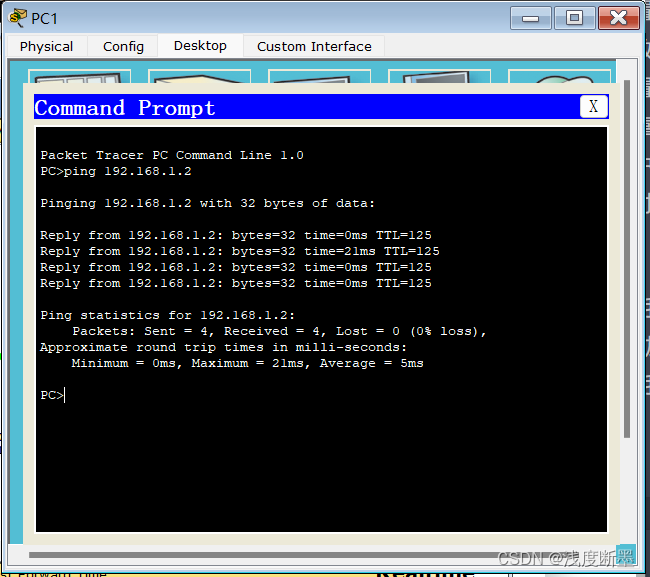
实验01:静态路由配置实验
1.实验目的: 本次实验的主要目的是了解静态路由的配置和实现原理,熟悉路由器的基本操作,掌握在网络中进行静态路由配置的方法和技巧。 2.实验内容: 搭建网络拓扑,包括三台路由器和两台PC。配置路由器的IP地址和路由…...

C#中简单的继承和多态
今天我们来聊一聊继承,说实话今天也是我第一次接触。 继承的概念是什么呢?就是一个类可以继承另一个类的属性和方法(成员) 继承是面向对象编程中的一个非常重要的特性。 好了,废话不多说,下面切入正题&a…...

15、lambda表达式、右值引用、移动语义
前言 返回值后置 auto 函数名 (形参表) ->decltype(表达式) lambda表达式 lambda表达式的名称是一个表达式 (外观类似函数),但本质绝非如此 语法规则 [捕获表] (参数表) 选项 -> 返回类型 { 函数体; }lambda表达式的本质 lambda表达式本质其实是一个类…...

spring boot 实现直播聊天室(二)
spring boot 实现直播聊天室(二) 技术方案: spring bootnettyrabbitmq 目录结构 引入依赖 <dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.96.Final</version> </dependency>Si…...

alibaba fastjson GET List传参 和 接收解析
之前一直都是 get传的都是单字符串(例如 xxxxxxxxx?name{name};name“woaini”;),并没有传list的. GET List传参 问题场景 String url"xxxxxxxx?id{id}"; HashMap<String,Object> param new HashMap<>(); param.pu…...
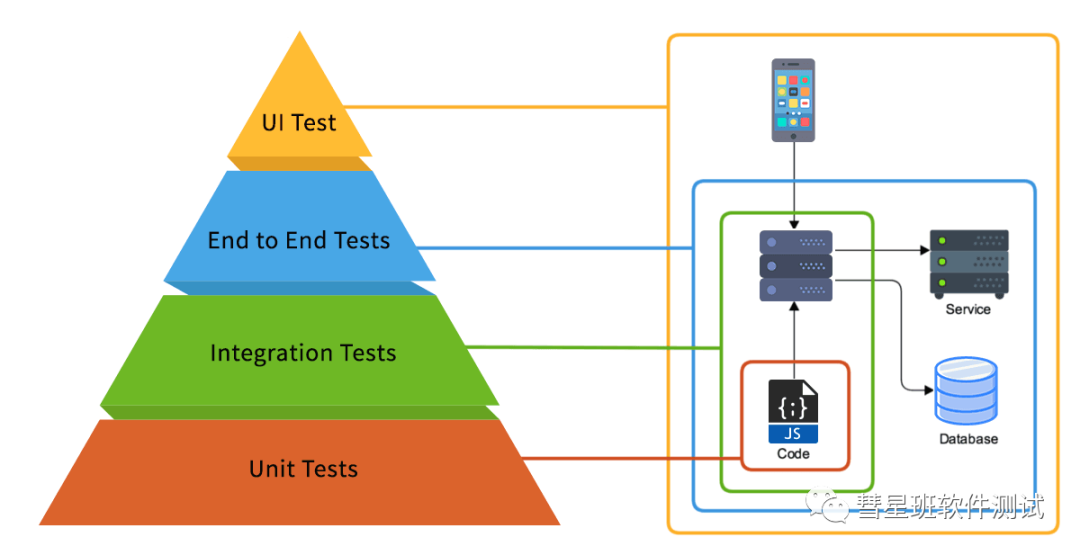
API自动化测试是什么?我们该如何做API自动化测试呢?
API测试已经成为测试工作中的常规任务之一。为了提高测试效率并减少重复的手工操作,API自动化测试变得越来越重要。本文总结了API自动化测试方面的经验和心得,旨在与读者分享。 掌握自动化技能已经成为高级测试工程师的必备技能。敏捷和持续测试改变了传…...

PyTorch 的 10 条内部用法
欢迎阅读这份有关 PyTorch 原理的简明指南[1]。无论您是初学者还是有一定经验,了解这些原则都可以让您的旅程更加顺利。让我们开始吧! 1. 张量:构建模块 PyTorch 中的张量是多维数组。它们与 NumPy 的 ndarray 类似,但可以在 GPU …...
Django、Echarts异步请求、动态更新
前端页面 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>echarts示例</title> <script src"jquery.min.js"></script><script type "text/javascript" src "echarts.m…...
Mac部署Odoo环境-Odoo本地环境部署
Odoo本地环境部署 安装Python安装Homebrew安装依赖brew install libxmlsec1 Python运行环境Pycharm示例配置 Mac部署Odoo环境-Odoo本地环境部署 安装Python 新机,若系统没有预装Python,则安装需要版本的Python 点击查询Python官网下载 安装Homebrew 一…...

如何用开源C模拟器在PC上运行Nintendo Switch游戏:Ryujinx技术深度解析
如何用开源C#模拟器在PC上运行Nintendo Switch游戏:Ryujinx技术深度解析 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款用C#编写的开源Nintendo Switch模拟器…...
)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖) 当你在Ubuntu 20.04上成功安装GAMMA后,可能会发现这仅仅是开始。真正的挑战在于构建一个完整、稳定的科研环境,让InSAR数据处理流程…...

从真空袋到回流焊:一份给硬件创业团队的元器件储存与使用避坑指南
从真空袋到回流焊:硬件创业团队的元器件储存与使用避坑指南 当你拆开一包全新的芯片,是否曾想过这些看似坚固的小方块其实对环境湿度极其敏感?对于资源有限的硬件创业团队来说,正确处理MSL(湿度敏感等级)元…...

大模型涌现能力:从原理到工程实践的激发与评测方法
1. 项目概述:从“玄学”到“可操作”的涌现能力拆解最近和几个做模型训练和评测的朋友聊天,话题总绕不开“涌现能力”。这个词现在火得不行,但聊深了发现,大家对这个概念的理解其实挺割裂的。有人说它是大模型“开窍”的瞬间&…...

BLDC电机与锂离子电池集成设计关键技术解析
1. BLDC电机与锂离子电池集成设计概述在电动工具、小型电动车等便携式设备领域,无刷直流电机(BLDC)与锂离子电池的组合已成为行业标配。这种搭配带来了显著的性能提升:BLDC电机相比传统有刷电机效率提升150%以上,而锂离子电池的能量密度是镍镉…...

在Windows电脑上玩转酷安社区:这款免费UWP客户端让你告别手机小屏幕
在Windows电脑上玩转酷安社区:这款免费UWP客户端让你告别手机小屏幕 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在用手机刷酷安社区吗?是时候体验大屏幕带来…...

Spoolman:终极3D打印线轴管理解决方案,让您的打印工作更高效 [特殊字符]
Spoolman:终极3D打印线轴管理解决方案,让您的打印工作更高效 🚀 【免费下载链接】Spoolman Keep track of your inventory of 3D-printer filament spools. 项目地址: https://gitcode.com/gh_mirrors/sp/Spoolman Spoolman是一个强大…...

基于Hi3516DV300的智能相机全流程设计方案:从硬件选型到算法集成
1. 项目概述:从一块开发板到一台智能相机手头拿到一块Hi3516开发板,很多嵌入式开发者的第一反应可能是:这能做个啥?如果告诉你,基于这块海思的经典芯片,我们可以设计出一台功能完整、具备智能分析能力的网络…...

J-Link V8变砖别慌!手把手教你用SAM-BA 2.14救活AT91SAM7S64芯片
J-Link V8救砖实战:用SAM-BA 2.14拯救AT91SAM7S64芯片全指南 当你的J-Link V8调试器突然"变砖"——LED灯熄灭、电脑无法识别、所有功能瘫痪时,那种感觉就像外科医生在手术台上突然失去所有仪器。但别急着宣布它的"死亡",…...

ElevenLabs奥里亚文语音合规性警告:印度《2023语言技术法案》生效后,这4类商用场景必须重做语音备案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs奥里亚文语音合规性警告的背景与紧迫性 ElevenLabs 作为领先的文本转语音(TTS)服务提供商,近期在其 API 文档与开发者控制台中新增了针对奥里亚文…...