BERT、GPT学习问题个人记录
目录
1. 为什么过去几年大家都在做BERT, 做GPT的人少。
2. 但最近做GPT的多了以及为什么GPT架构的scaling(扩展性)比BERT好。
3.BERT是否可以用来做生成,如果可以的话为什么大家都用GPT不用BERT.
4. BERT里的NSP后面被认为是没用的,为什么?文章里是否有一些indication。
5. BERT的[CLS] token任意两个句子之间的相似度都很高,为什么。
1. 为什么过去几年大家都在做BERT, 做GPT的人少。
-
任务差异:BERT 主要用于双向语言模型预训练,能够更好地捕捉单词在上下文中的语境信息。先预训练再微调,它在各种下游任务上都取得了很好的效果,包括文本分类、命名实体识别、问答等。采用了Transformer架构。而GPT(特别是早期的 GPT-2)则主要用于单向语言模型预训练,即生成下一个可能的单词,更适合于生成型任务,如对话生成、文章生成等。
-
计算资源需求:GPT 模型相对来说更加庞大,需要更多的计算资源和时间进行训练。在早期,这使得许多研究团队难以承担 GPT 的训练成本,相比之下,BERT 的训练相对更加高效一些。
2. 但最近做GPT的多了以及为什么GPT架构的scaling(扩展性)比BERT好。
GPT-3等大型模型展示了在各种任务上取得强大性能的能力
-
自回归生成: GPT采用自回归生成的方式进行预训练,即在训练时每次生成一个单词的概率分布,下一个单词的生成依赖于前面已生成的单词,这种方式使得GPT更容易适应长距离依赖关系。
-
单向上下文: GPT只使用前向(单向)的上下文信息,这意味着在预测每个单词时只依赖于前面已生成的单词。这种模型结构更简单,也更容易进行横向扩展。(BERT的双向结构使得模型在扩展时需要考虑如何更好地捕捉双向上下文信息,增加了模型的复杂性和计算成本,例如权重参数量翻倍?)
-
参数量的增加: GPT的扩展性表现在参数量的增加上,例如,GPT-3拥有1750亿个参数。大规模的参数量使得GPT能够学习更丰富、更复杂的语言表示。
3.BERT是否可以用来做生成,如果可以的话为什么大家都用GPT不用BERT.
BERT并不适合直接用于生成文本。BERT是一种双向模型,它在训练时利用了一个掩码预测任务(Masked Language Model,MLM)来学习上下文信息。这使得BERT在理解和表示文本方面非常有效,但在生成文本方面并不擅长。
相对而言,GPT(Generative Pre-trained Transformer)系列模型专门设计用于生成文本。GPT采用单向的Transformer结构,在训练时使用自回归生成任务来预测下一个词,每个位置的预测都依赖于之前生成的所有位置,因此更适合用于生成连续文本序列。
4. BERT里的NSP后面被认为是没用的,为什么?文章里是否有一些indication。
-
数据偏差:NSP任务的数据集往往存在一定程度的偏斜,即负例(随机选择的句子)往往比正例(相邻句子)更容易识别(负例的主题、词汇等特征可能与正例存在明显差异),这导致模型倾向于简单地判断负例,而无法从中获得足够的有效信息。
-
训练目标冗余:一些研究发现,NSP任务和MLM任务(Masked Language Model)之间存在一定的冗余,即模型通过MLM任务已经学会了足够的语言表示能力,而NSP任务未能有效增加额外的语义理解。
-
实际应用中的有限帮助:在实际的自然语言处理任务中,例如文本分类、命名实体识别等,NSP任务并未表现出对模型性能的显著提升。
在一些研究中,通过去掉NSP任务,甚至只采用MLM任务进行预训练,可以获得和包括NSP任务的BERT模型性能相当甚至更好的结果。因此,一些研究者认为NSP任务在BERT中的作用有限,甚至可以被舍弃。
例如RoBERTa文章中就去掉了下一句预测(NSP)任务
5. BERT的[CLS] token任意两个句子之间的相似度都很高,为什么。
BERT模型预训练的任务之一是Next Sentence Prediction,即给定两个句子,判断它们是否是连续出现的句子。它并没有直接学习到语义相似性,而是通过判断句子是否连续来学习句子之间的关系,BERT模型会学习到将整个句子的语义信息编码到[CLS] token中的表示向量中。
BERT在预训练过程中,相邻的句子被视为正样本,BERT模型会将相邻的句子编码成相似的向量表示。即使两个句子在语义上并不相似,BERT模型也可能会它们编码成相似的向量表示。因此语义相不相似的两个句子的向量表示相似度可能都很高
相关文章:

BERT、GPT学习问题个人记录
目录 1. 为什么过去几年大家都在做BERT, 做GPT的人少。 2. 但最近做GPT的多了以及为什么GPT架构的scaling(扩展性)比BERT好。 3.BERT是否可以用来做生成,如果可以的话为什么大家都用GPT不用BERT. 4. BERT里的NSP后面被认为是没用的&#x…...
HeartBeat监控Mysql状态
目录 一、概述 二、 安装部署 三、配置 四、启动服务 五、查看数据 一、概述 使用heartbeat可以实现在kibana界面对 Mysql 服务存活状态进行观察,如有必要,也可在服务宕机后立即向相关人员发送邮件通知 二、 安装部署 参照章节:监控组件…...

软件开发经常出现的bug原因有哪些
软件开发中出现bug的原因是多方面的,这些原因可能涉及到开发流程、人为因素、设计问题以及其他一系列因素。以下是一些常见的导致bug的原因: 1. 错误的需求分析: 不正确、不完整或者模糊的需求分析可能导致开发人员误解客户的需求࿰…...
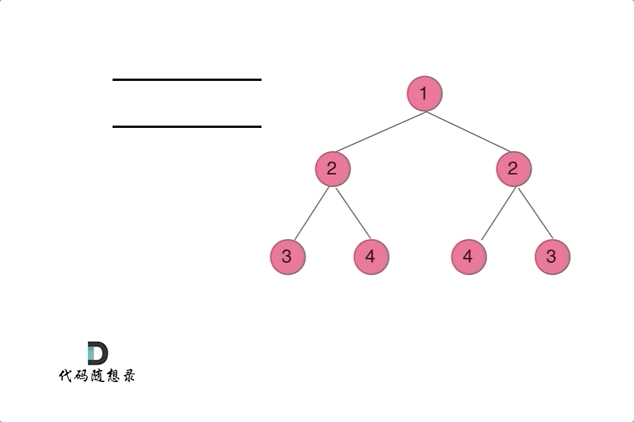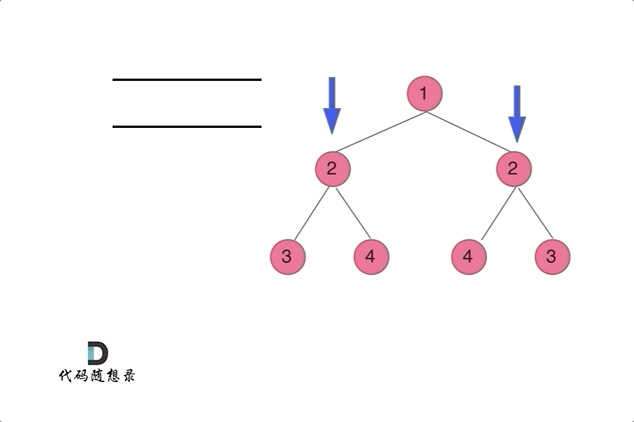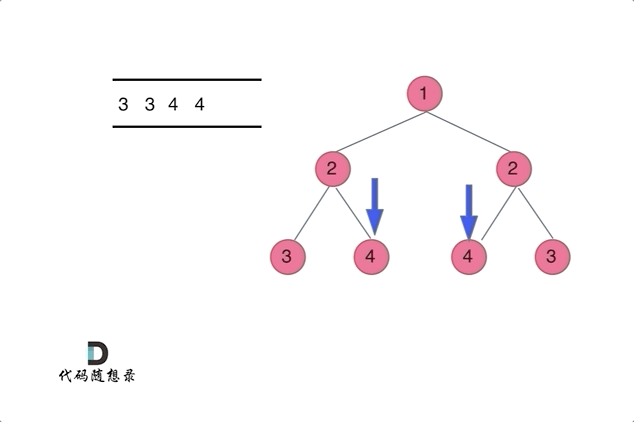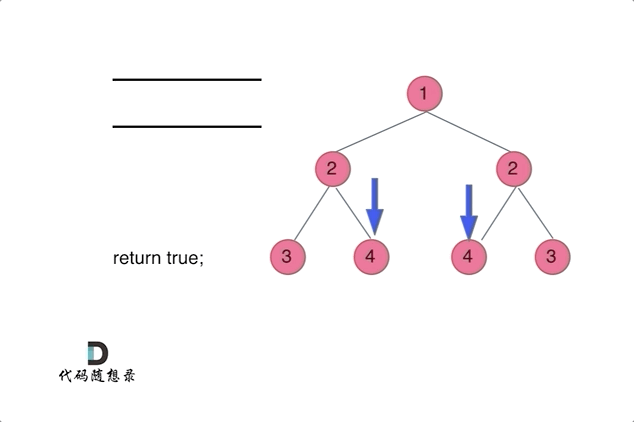
代码随想录27期|Python|Day15|二叉树|层序遍历|对称二叉树|翻转二叉树
本文图片来源:代码随想录 层序遍历(图论中的广度优先遍历) 这一部分有10道题,全部可以套用相同的层序遍历方法,但是需要在每一层进行处理或者修改。 102. 二叉树的层序遍历 - 力扣(LeetCode) 层…...
鸿蒙开发组件之Web
一、加载一个url myWebController: WebviewController new webview.WebviewControllerbuild() {Column() {Web({src: https://www.baidu.com,controller: this.myWebController})}.width(100%).height(100%)} 二、注意点 2.1 不能用Previewer预览 Web这个组件不能使用预览…...

成绩分析。
成绩分析 题目描述 小蓝给学生们组织了一场考试,卷面总分为 100分,每个学生的得分都是一个0到100的整数。 请计算这次考试的最高分、最低分和平均分 输入描述 输入的第一行包含一个整数n(1n104),表示考试人数。 接下来n行,每行包含…...
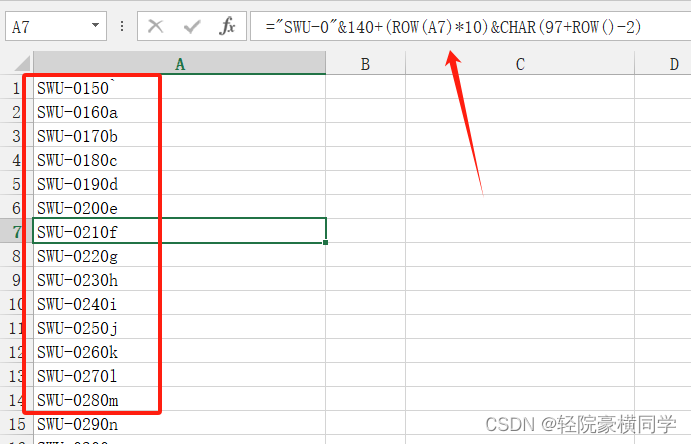
Excel实现字母+数字拖拉自动递增,步长可更改
目录 1、带有字母的数字序列自增加(步长可变) 2、仅字母自增加 3、字母数字同时自增 1、带有字母的数字序列自增加(步长可变) 使用Excel通常可以直接通过拖拉的方式,实现自增数字…...

Java之Stream流
一、什么是Stream流 Stream是一种处理集合(Collection)数据的方式。Stream可以让我们以一种更简洁的方式对集合进行过滤、映射、排序等操作。 二、Stream流的使用步骤 先得到一条Stream流,并把数据放上去利用Stream流中的API进行各种操作 中间…...

vue中element-ui日期选择组件el-date-picker 清空所选时间,会将model绑定的值设置为null 问题 及 限制起止日期范围
一、问题 在Vue中使用Element UI的日期选择组件 <el-date-picker>,当你清空所选时间时,组件会将绑定的 v-model 值设置为 null。这是日期选择器的预设行为,它将清空所选日期后将其视为 null。但有时后端不允许日期传空。 因此ÿ…...
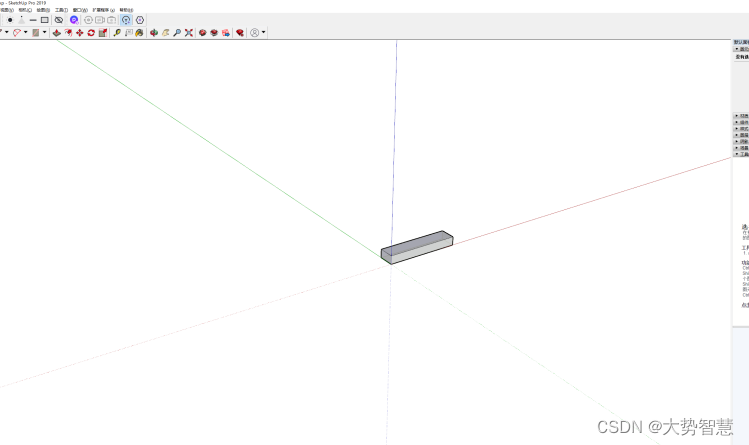
使用模方时,三维模型在su中显示不了怎么办?
答:可以借助截图功能截取模型影像在su中绘制白模。 模方是一款针对实景三维模型的冗余碎片、水面残缺、道路不平、标牌破损、纹理拉伸模糊等共性问题研发的实景三维模型修复编辑软件。模方4.1新增自动单体化建模功能,支持一键自动提取房屋结构ÿ…...
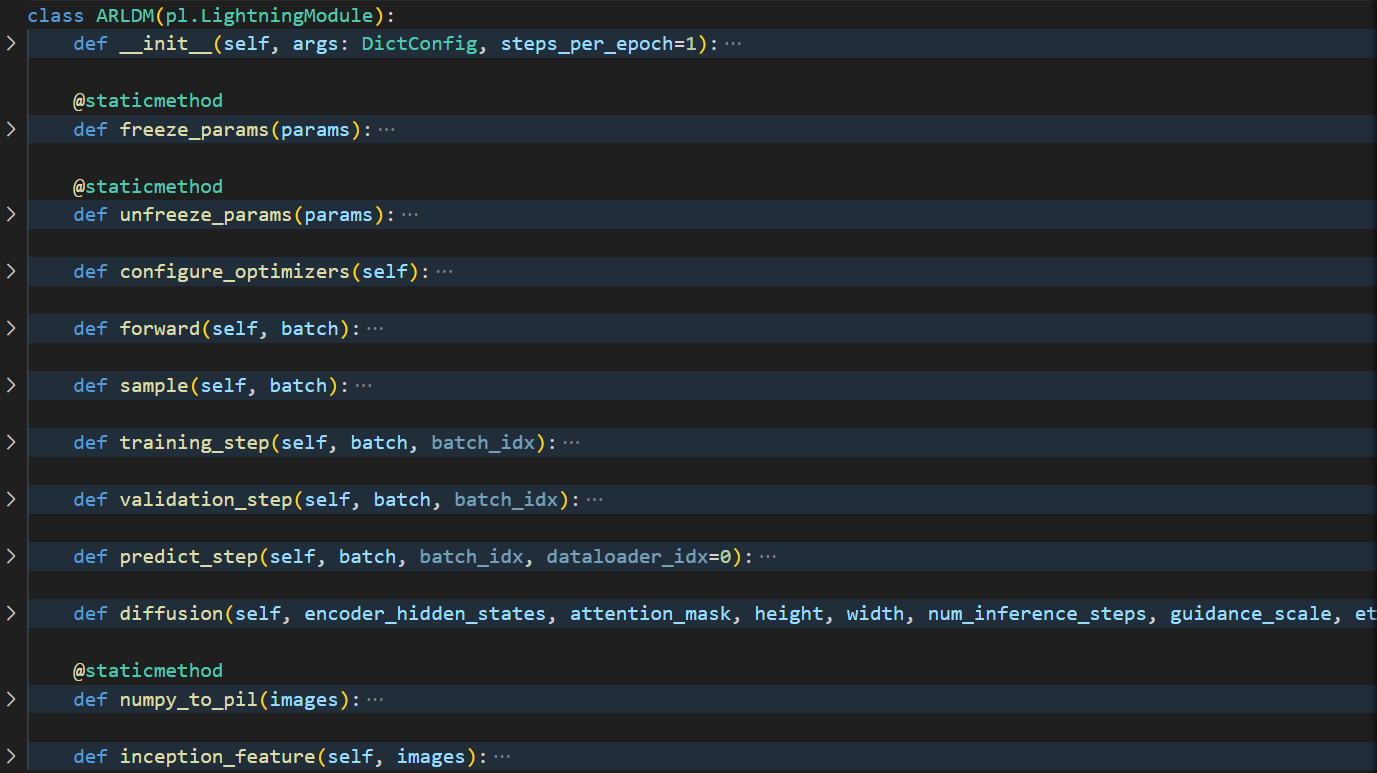
AR-LDM原理及代码分析
AR-LDM原理AR-LDM代码分析pytorch_lightning(pl)的hook流程main.py 具体分析TrainSampleLightningDatasetARLDM blip mm encoder AR-LDM原理 左边是模仿了自回归地从1, 2, ..., j-1来构造 j 时刻的 frame 的过程。 在普通Stable Diffusion的基础上,使用了1, 2, .…...

MySQL常见死锁的发生场景以及如何解决
死锁的产生是因为满足了四个条件: 互斥占有且等待不可强占用循环等待 这个网站收集了很多死锁场景 接下来介绍几种常见的死锁发生场景。其中,id 为主键,no(学号)为二级唯一索引,name(姓名&am…...
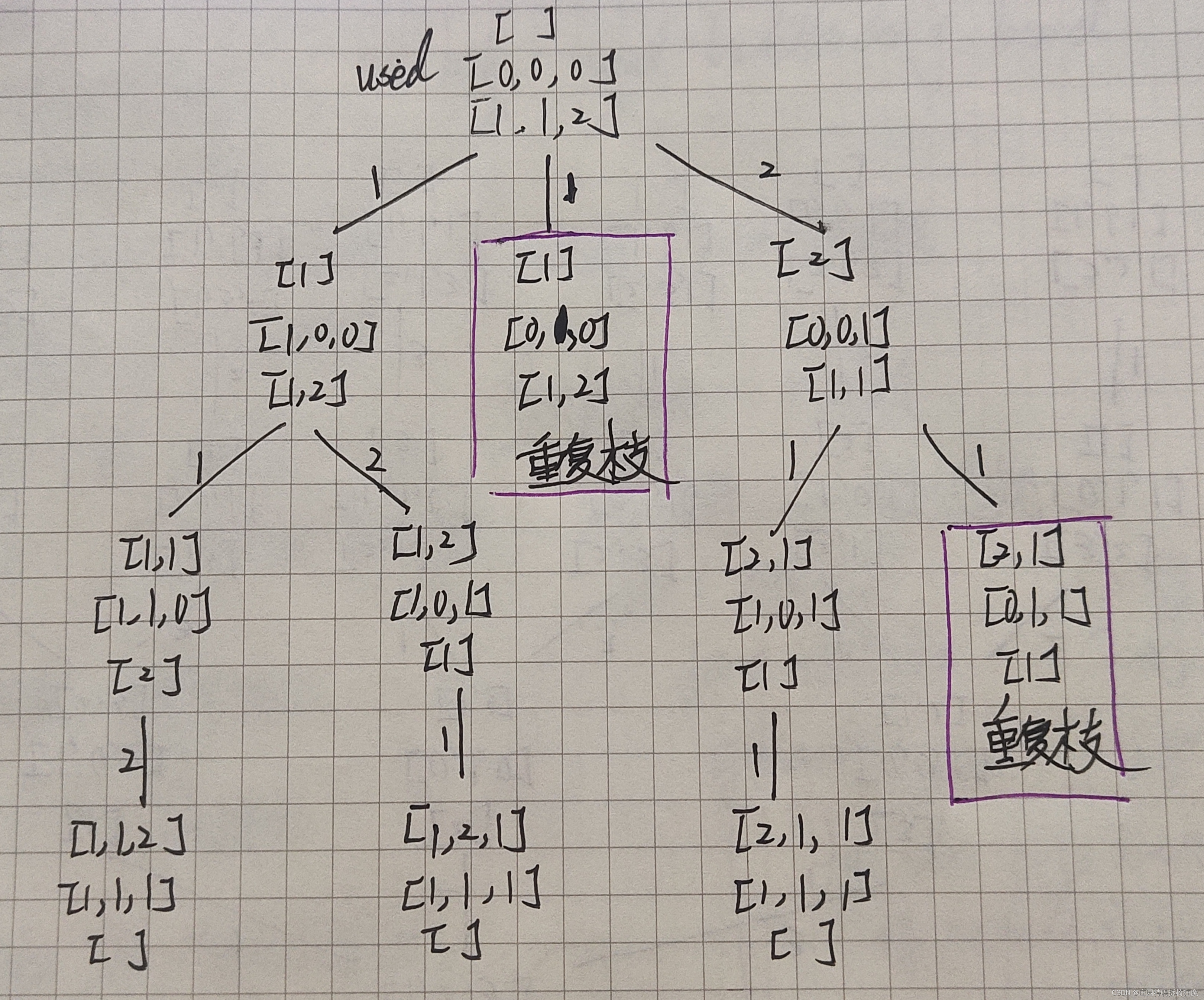
Leetcode 47 全排列 II
题意理解: 首先理解全排列是什么?全排列:使用集合中所有元素按照不同元素进行排列,将所有的排列结果的集合称为全排列。 这里的全排列难度升级了,问题在于集合中的元素是可以重复的。 问题:相同的元素会导致…...
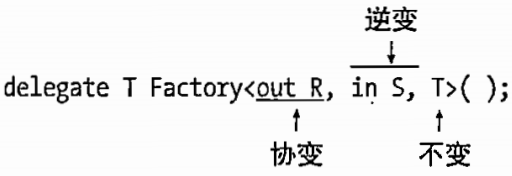
C# 图解教程 第5版 —— 第18章 泛型
文章目录 18.1 什么是泛型18.2 C# 中的泛型18.3 泛型类18.3.1 声明泛型类18.3.2 创建构造类型18.3.3 创建变量和实例18.3.4 使用泛型的示例18.3.5 比较泛型和非泛型栈 18.4 类型参数的约束18.4.1 Where 子句18.4.2 约束类型和次序 18.5 泛型方法18.5.1 声明泛型方法18.5.2 调用…...

保障事务隔离级别的关键措施
目录 引言 1. 锁机制的应用 2. 多版本并发控制(MVCC)的实现 3. 事务日志的记录与恢复 4. 数据库引擎的实现策略 结论 引言 事务隔离级别是数据库管理系统(DBMS)中的一个关键概念,用于控制并发事务之间的可见性。…...

Docker导入导出镜像、导入导出容器的命令详解以及使用的场景
一、Docker 提供用于管理镜像和容器命令 1.1 docker save 与 docker load 这是一对操作,用于处理 Docker 镜像。这个操作会将所有的镜像层以及元数据打包到一个 tar 文件中。然后,你可以使用 docker load 命令将这个 tar 文件导入到任何 Docker 环境中…...
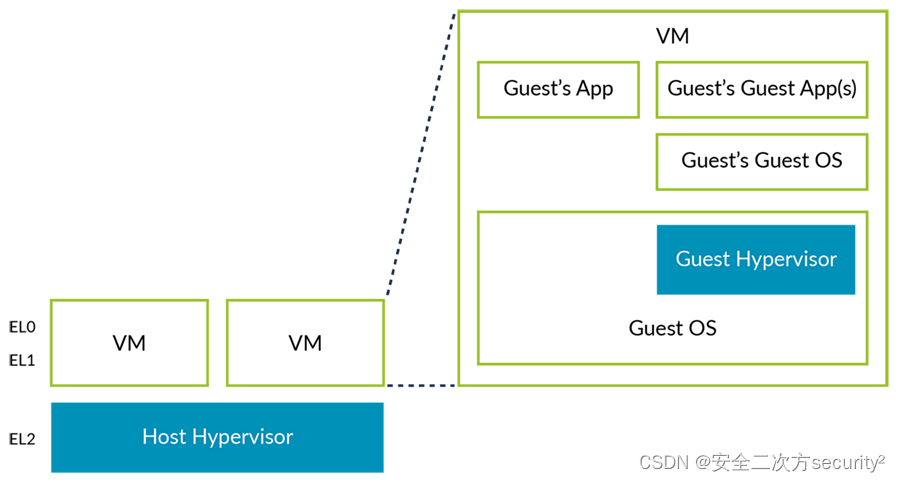
虚拟化嵌套
在理论上,可以在虚拟机(VM)内运行一个hypervisor,这个概念被称为嵌套虚拟化: 我们将第一个hypervisor称为Host Hypervisor,将VM内的hypervisor称为Guest Hypervisor。 在Armv8.3-A发布之前,可以通过在EL0中运行Guest Hypervisor来在VM中运行Guest Hypervisor。然而,这…...

【XILINX】记录ISE/Vivado使用过程中遇到的一些warning及解决方案
前言 XILINX/AMD是大家常用的FPGA,但是在使用其开发工具ISE/Vivado时免不了会遇到很多warning,(大家是不是发现程序越大warning越多?),并且还有很多warning根据消除不了,看着特心烦? 我这里汇总一些我遇到的…...
Tableau进阶--Tableau数据故事慧(20)解构Tableau的绘图逻辑
官网介绍 官网连接如下: https://www.tableau.com/zh-cn tableau的产品包括如下: 参考:https://zhuanlan.zhihu.com/p/341882097 Tableau是功能强大、灵活且安全些很高的端到端的数据分析平台,它提供了从数据准备、连接、分析、协作到查阅…...
)
45.0/HTML 简介(详细版)
目录 45.1 互联网简介 45.2 网页技术与分类 45.3 HTML 简介 45.3.1 什么是 HTML?(面试题) 45.3.2 HTML 文件结构 45.3.3 HTML 语法 45.3.4 实例演练步骤(面试题) 45.4 head 中的常用标签 45.4.1 title 标记 45.4.2 meta 标记 45.4.3 45.4.4 45.4.4(面试题)总结: 45…...

Verilog时钟分频:从原理到工程实践,避坑指南与最佳方案
1. 项目概述:为什么时钟分频是数字设计的基石在数字电路和FPGA设计里,时钟信号就像是整个系统的心跳。它驱动着寄存器、状态机和数据流,确保所有操作在正确的节拍下同步进行。但现实情况是,我们手头的时钟源往往只有一个固定的频率…...
的模板化部署)
统信UOS系统管理员必看:一招搞定用户配置文件(.config/autostart)的模板化部署
统信UOS系统配置模板化实战:从屏保设置到全局用户环境部署 在大型企业或教育机构的桌面环境管理中,统信UOS作为国产操作系统的代表,其标准化部署能力直接影响运维效率。当我们在模板用户中精心配置了各项参数——从屏幕保护时间到电源管理策略…...

观察Taotoken用量看板如何精细化管控API调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何精细化管控API调用成本 对于依赖大模型API进行开发的项目团队而言,成本控制与预算管理是项目…...

Midscene.js技术架构深度解析:构建企业级视觉驱动自动化测试平台的技术挑战与解决方案
Midscene.js技术架构深度解析:构建企业级视觉驱动自动化测试平台的技术挑战与解决方案 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今多平台、…...

从实验室到机房:把eNSP里练熟的Telnet AAA配置,无缝迁移到真实华为交换机上
从模拟到实战:华为交换机Telnet AAA配置的迁移指南 当你在eNSP模拟器中反复练习Telnet AAA配置,看着那些绿色指示灯亮起时,是否曾想过:"这些命令在真实设备上真的完全一样吗?"作为一位从实验室走向机房的网络…...
)
从调参到调优:手把手教你用RFSoC API榨干DAC性能(插值、滤波器、数据路径全解析)
从调参到调优:手把手教你用RFSoC API榨干DAC性能(插值、滤波器、数据路径全解析) 在无线通信和雷达系统的原型开发中,RFSoC的DAC性能直接决定了整个系统的信号质量与效率。许多开发者虽然能够完成基础配置,但当面临&qu…...

在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤 OpenClaw是一个功能强大的AI智能体开发框架,它允许开发者灵活…...

Linux服务器安全加固第一步:用好chattr隐藏权限和umask默认值
Linux服务器安全加固实战:chattr与umask的防御艺术 当一台裸机Linux服务器首次上线时,大多数管理员会立即部署防火墙、更新补丁和配置SSH密钥登录——这些确实是安全基础。但真正经历过服务器入侵事件的老手都知道,攻击者往往从最不起眼的文件…...

该不该现在买房?AI浪潮下,你的房贷是资产还是负债?
该不该现在买房?AI浪潮下,你的房贷是资产还是负债? 开篇:一个普通家庭的决策困境 深夜,东莞某小区的灯光次第熄灭。你刚刚哄睡一岁半的孩子,打开手机看到甲骨文最新一轮裁员的新闻,又瞥了一眼房…...

轻量化AI助手框架部署指南:基于Nectar-GPT构建社交场景智能机器人
1. 项目概述:一个面向社交场景的轻量化AI助手最近在GitHub上看到一个挺有意思的项目,叫socialtribexyz/Nectar-GPT。光看名字,你可能会觉得这又是一个基于GPT API的简单封装,或者是一个聊天机器人。但当我深入去研究它的代码结构、…...