后端打印不了trace等级的日志?-SpringBoot日志打印-Slf4j
在调用log变量的方法来输出日志时,有以上5个级别对应的方法,从不太重要,到非常重要
调用不同的方法,就会输出不同级别的日志。
trace:跟踪信息debug:调试信息info:一般信息warn:警告信息error:错误信息
问题:SpringBoot只打印了info等级的日志? 没有trace等级的日志?

原因:使用了Spring Boot(例如在测试类上添加了@SpringBootTest注解),日志的默认显示级别是info,则只会显示info、warn、error级别的日志,不会显示trace、debug级别的日志。
解决方法
1.首先我们确认使用了工具打印日志
在pom.xml中添加依赖
<!-- Lombok的依赖项,主要用于简化POJO类的编写 --><!-- 添加了Lombok后,在任何类的声明之前,添加@Slf4j注解,则编译期会自动声明一个名为log的变量,所以,可以在类中通过此变量来输出日志。 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.20</version><scope>provided</scope></dependency>
使用前,在任何类的声明之前,添加@Slf4j注解,如下则编译期会自动声明一个名为log的变量
@Slf4j
@SpringBootTest
class SmallApplicationTests {@Testvoid logTest(){int x = 1;int y = 2;System.out.println("x = " + x + ", y = " + y + ", x + y = " + (x + y)); // 传统做法log.trace("111x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法log.debug("222x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法log.info("333x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法log.warn("444x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法log.error("555x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法}
}
2.配置展示日志等级
在Spring Boot项目中,可以在配置文件(application.properties / application.yml / 相关Profile配置)中配置logging.level.包名属性,以指定某个包下的所有类的默认日志显示级别,此属性的值为5个级别中的某1个。
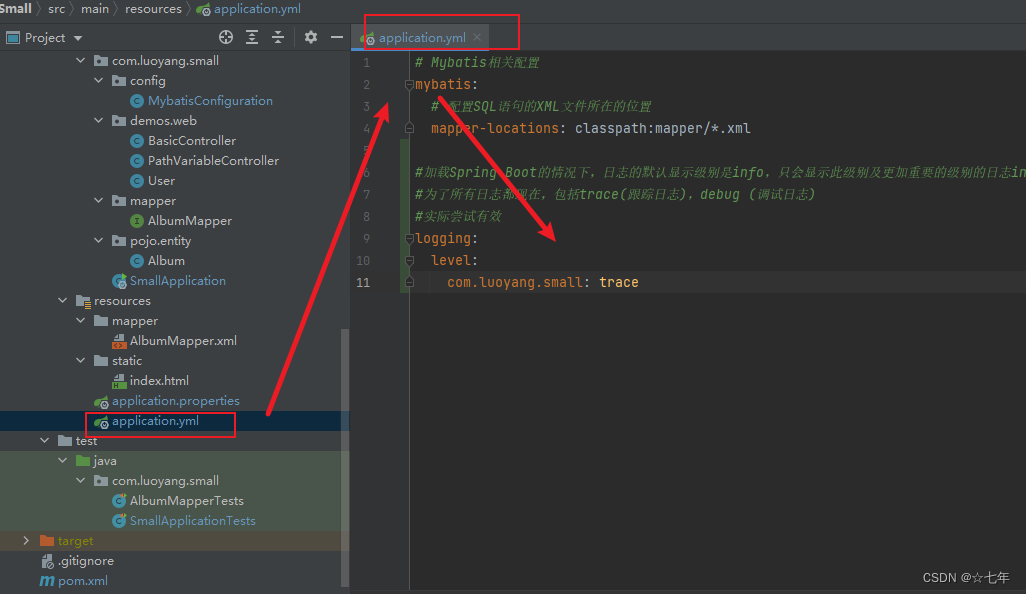
例如,在application.yml添加配置:
#加载Spring Boot的情况下,日志的默认显示级别是info,只会显示此级别及更加重要的级别的日志info.warn,error
#为了所有日志都现在,包括trace(跟踪日志),debug (调试日志)
#实际尝试有效
logging:level:com.luoyang.small: trace
或者在application.properties中添加配置
#实际尝试有效
logging.level.com.luoyang.small=TRACE
结果:

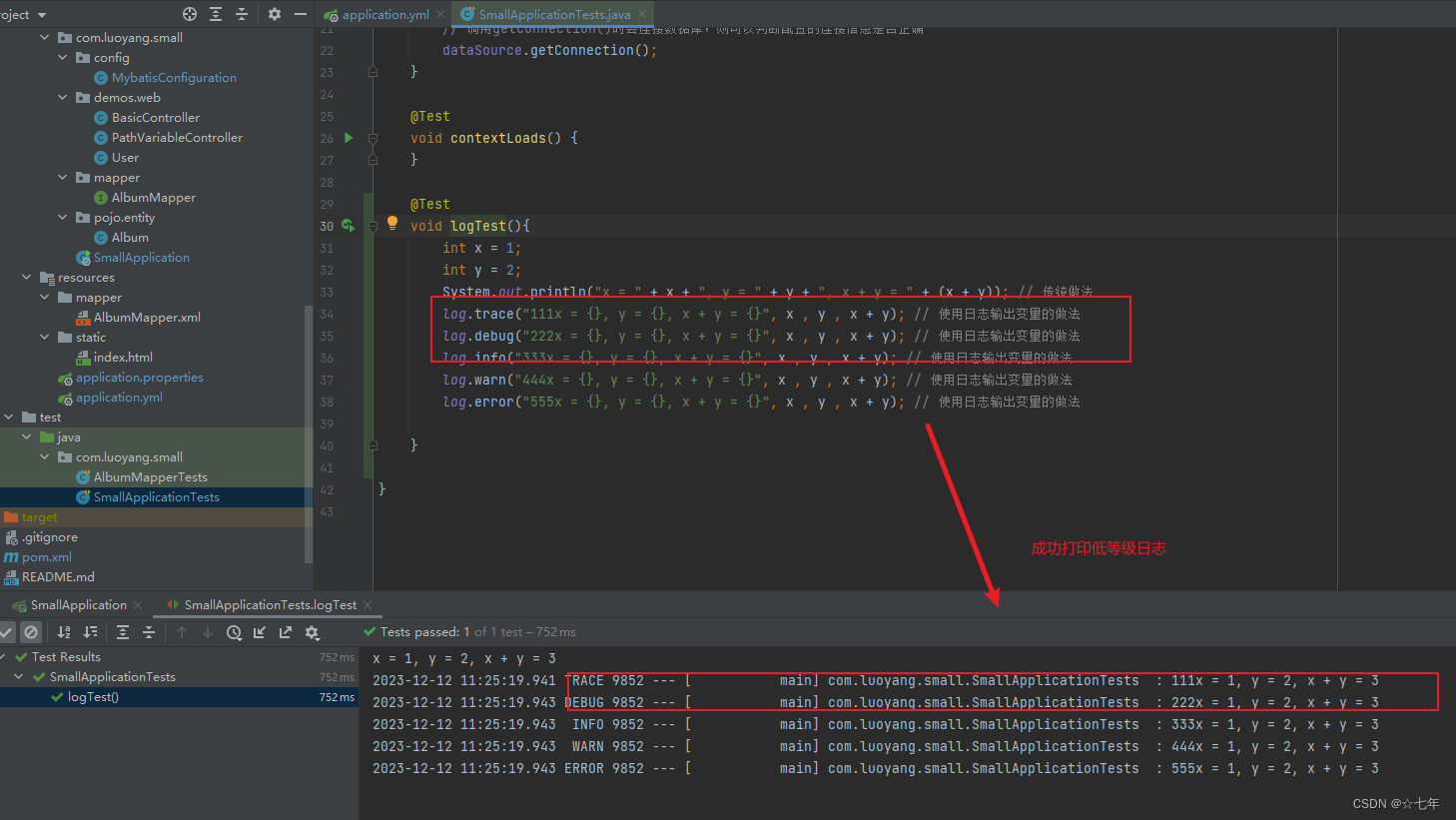
附加信息
提示: Mybatis框架会生成各Mapper接口的对象,这些对象在执行SQL语句时,也会输出日志。如果想看的trace和info级别的日志,也需要把日志的显示级别设置为较低的trace级别
日志占位符: 在调用日志的方法时,如果输出的信息中包含变量值,可以使用{}作为占位符,表示此处是一个变量值,然后,通过Object... args依次传入各占位符对应的值,如下:
@Testvoid logTest(){int x = 1;int y = 2;System.out.println("x = " + x + ", y = " + y + ", x + y = " + (x + y)); // 传统做法log.trace("111x = {}, y = {}, x + y = {}", x , y , x + y); // 使用日志输出变量的做法}
以上使用日志输出时,不会涉及到字符串的拼接,所以,执行效率会更高。并且,以上方法的第1个参数是字符串常量,是在内存中的字符串常量池中的,也可以一定程度上提高执行效率。
创造价值,乐哉分享!
相关文章:
后端打印不了trace等级的日志?-SpringBoot日志打印-Slf4j
在调用log变量的方法来输出日志时,有以上5个级别对应的方法,从不太重要,到非常重要 调用不同的方法,就会输出不同级别的日志。 trace:跟踪信息debug:调试信息info:一般信息warn:警告…...

声明式编程Declarative Programming
接下来要介绍第五种编程范式 -- 声明式编程。分别从它的优缺点、案例分析和适用的编程语言这三个方面来介绍这个歌编程范式。 声明式编程是一种编程范式,其核心思想是通过描述问题的性质和约束,而不是通过描述解决问题的步骤来进行编程。这与命令式编程…...

人工智能与天文:技术前沿与未来展望
人工智能与天文:技术前沿与未来展望 一、引言 随着科技的飞速发展,人工智能(AI)在各个领域的应用越来越广泛。在天文领域,AI也发挥着越来越重要的作用。本文将探讨人工智能与天文学的结合,以及这种结合带…...

JeecgBoot 框架升级至 Spring Boot3 的实战步骤
JeecgBoot 框架升级 Spring Boot 3.1.5 步骤 JEECG官方推出SpringBoot3分支:https://github.com/jeecgboot/jeecg-boot/tree/springboot3 本次更新由于属于破坏式更新,有几个生态内的组件,无法进行找到平替或无法升级,目前尚不完…...
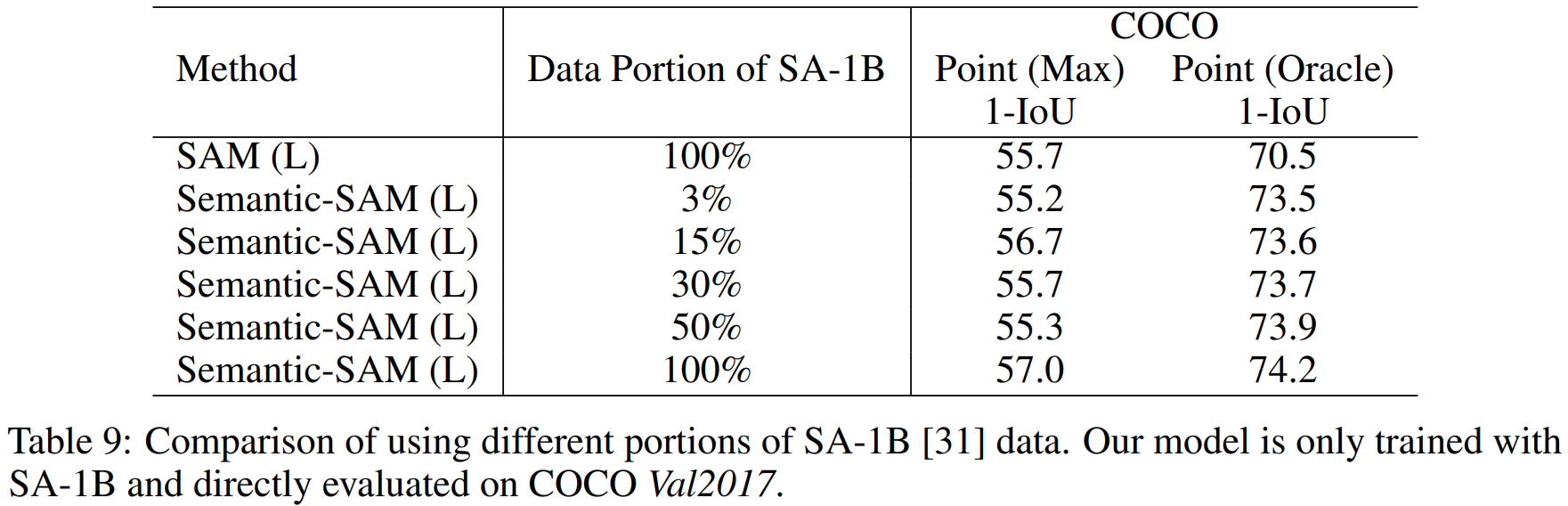
论文阅读——Semantic-SAM
Semantic-SAM可以做什么: 整合了七个数据集: 一般的分割数据集,目标级别分割数据集:MSCOCO, Objects365, ADE20k 部分分割数据集:PASCAL Part, PACO, PartImagenet, and SA-1B The datasets are SA-1B, COCO panopt…...
gitlab下载,离线安装
目录 1.下载 2.安装 3.配置 4.启动 5.登录 参考: 1.下载 根据服务器操作系统版本,下载对应的RPM包。 gitlab官网: The DevSecOps Platform | GitLab rpm包官网下载地址: gitlab/gitlab-ce - Results in gitlab/gitlab-ce 国内镜像地…...

【SpringBoot篇】Interceptor拦截器 | 拦截器和过滤器的区别
文章目录 🌹概念⭐作用 🎄快速入门⭐入门案例代码实现 🛸拦截路径🍔拦截器interceptor和过滤器filter的区别🎆登录校验 🌹概念 拦截器(Interceptor)是一种软件设计模式,…...
:在set_version方法中从pom.xml中读取版本号实现动态版本定义)
conan入门(三十六):在set_version方法中从pom.xml中读取版本号实现动态版本定义
一般情况下,我们通过self.version字段定义conan 包的版本号如下: class PkgConan(ConanFile):name "pkg"version "1.7.3"因为版本号是写死的,所以这种方式有局限性: 比如我的java项目中版本号是在pom.xml中…...

为什么 GAN 不好训练
为什么 GAN 不好训练?先看 GAN 的损失: 当生成器固定时,堆D(x)求导,推理得到(加号右边先对log求导,再对负项求导) 然后在面对最优Discriminator时,Generator的优化目标就变成了&…...

select、poll、epoll 区别有哪些
文章目录 select、poll、epoll 区别有哪些?select:poll:epoll: select、poll、epoll 区别有哪些? select: 它仅仅知道了,有 I/O 事件发生了,却并不知道是哪那几个流(可…...

大模型下开源文档解析工具总结及技术思考
1 基于文档解析工具的方法 pdf解析工具 导图一览: PyPDF2提取txt: import PyPDF2 def extract_text_from_pdf(pdf_path):with open(pdf_path, rb) as file:pdf_reader PyPDF2.PdfFileReader(file)num_pages pdf_reader.numPagestext ""f…...
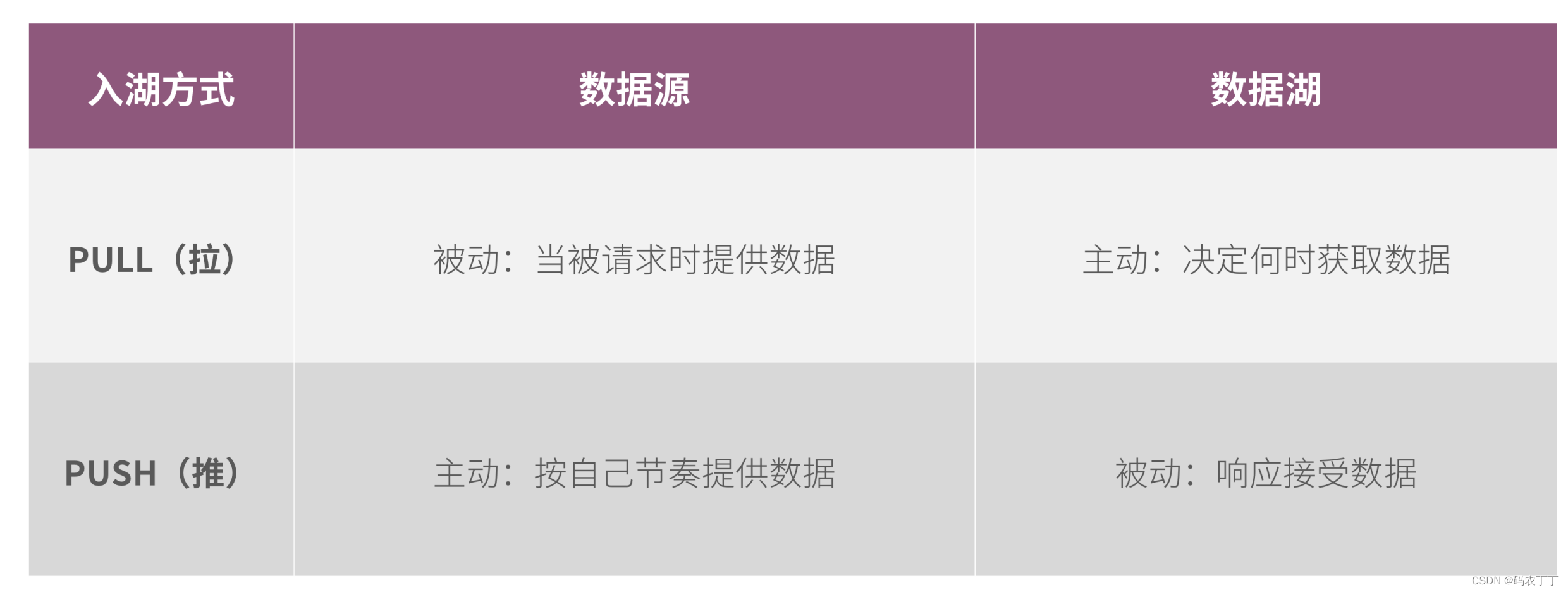
【华为数据之道学习笔记】5-4 数据入湖方式
数据入湖遵循华为信息架构,以逻辑数据实体为粒度入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性。原则上,一个逻辑数据实体的所有属性应该一次性进湖,避免一个逻辑实体多次入湖,增加入湖工作量。 数据入湖的方式…...
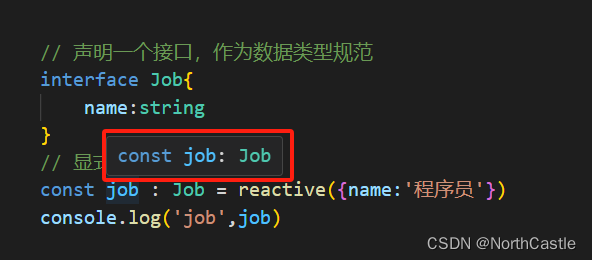
Vue3-03-reactive() 响应式基本使用
reactive() 的简介 reactive() 是vue3 中进行响应式状态声明的另一种方式; 但是,它只能声明 【对象类型】的响应式变量,【不支持声明基本数据类型】。reactive() 与 ref() 一样,都是深度响应式的,即对象嵌套属性发生了…...

OpenAI开源超级对齐方法:用GPT-2,监督、微调GPT-4
12月15日,OpenAI在官网公布了最新研究论文和开源项目——如何用小模型监督大模型,实现更好的新型对齐方法。 目前,大模型的主流对齐方法是RLHF(人类反馈强化学习)。但随着大模型朝着多模态、AGI发展,神经元…...
TeeChart.NET 2023.11.17 Crack
.NET 的 TeeChart 图表控件提供了一个出色的通用组件套件,可满足无数的图表需求,也针对重要的垂直领域,例如金融、科学和统计领域。 数据可视化 数十种完全可定制的交互式图表类型、地图和仪表指示器,以及完整的功能集,…...

计算机网络常见的缩写
计算机网络常见缩写 通讯控制处理机(Communication Control Processor)CCP 前端处理机(Front End Processor)FEP 开放系统互连参考模型 OSI/RM 开放数据库连接(Open Database Connectivity)ODBC 网络操作系…...
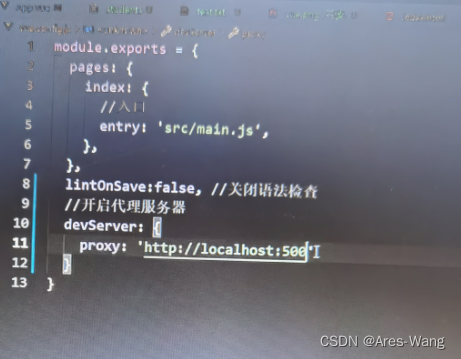
vue cli 脚手架之配置代理
方法二...
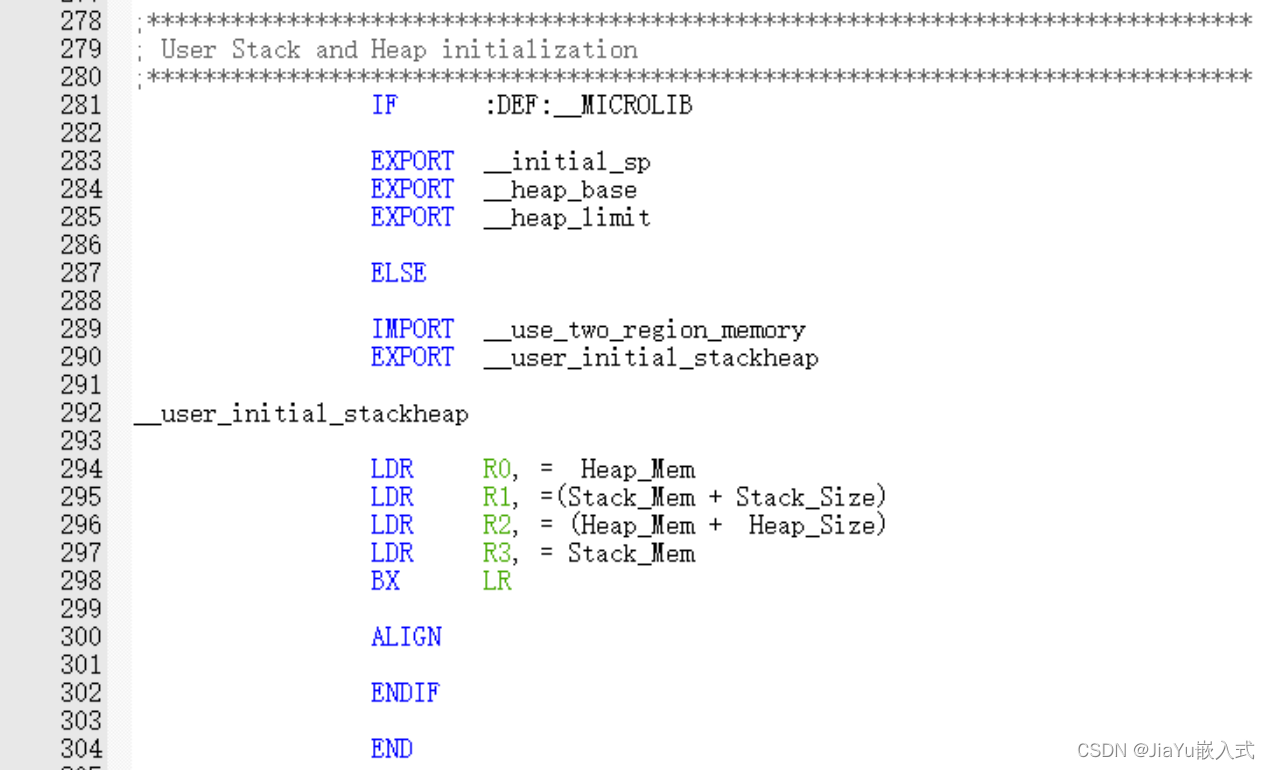
STM32启动流程详解(超全,startup_stm32xx.s分析)
单片机上电后执行的第一段代码 1.初始化堆栈指针 SP_initial_sp 2.初始化 PC 指针Reset_Handler 3.初始化中断向量表 4.配置系统时钟 5.调用 C 库函数_main 初始化用户堆栈,然后进入 main 函数。 在正式讲解之前,我们需要了解STM32的启动模式。 STM32的…...
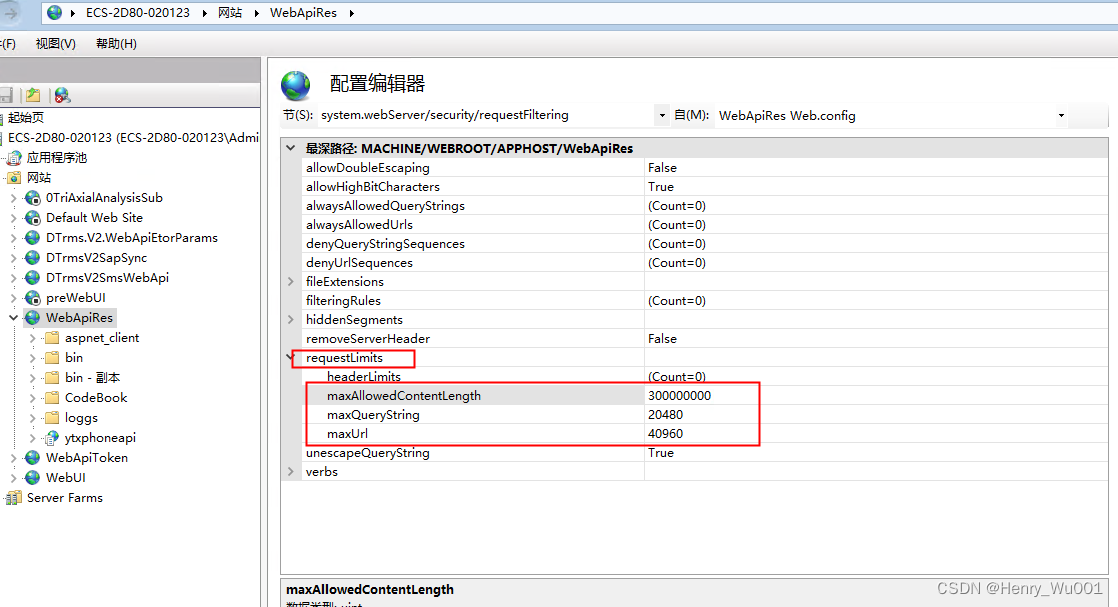
小程序接口OK,桌面调试接口不行
手机小程序OK,桌面版出现问题; 环境:iis反向url的tomcat服务,提供接口。 该接口post了一个很大的数组,处理时间比较久。 1)桌面调试出现错误,提示 用apipost调用接口同样出错, 502 - Web 服务器在作为网关或代理服…...

【贪心】LeetCode-406. 根据身高重建队列
406. 根据身高重建队列。 假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。 请你重新…...

智慧校园平台建设要多少钱?这份预算规划指南帮你理清思路
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

Win10系统下极点五笔输入法的兼容性配置与TSF框架适配实践
1. 为什么Win10需要特殊配置才能用极点五笔? 很多从Win7升级到Win10的五笔用户都会发现,用了十几年的极点五笔突然变得不听话了。这背后其实藏着微软输入法框架的大变革——从传统的IMM(Input Method Manager)架构转向了TSF&#…...

3步快速上手:Windows电脑直接安装安卓应用的终极指南
3步快速上手:Windows电脑直接安装安卓应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否渴望在Windows电脑上直接运行安卓应用ÿ…...

VMware Unlocker:免费解锁VMware的macOS虚拟机支持终极指南
VMware Unlocker:免费解锁VMware的macOS虚拟机支持终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想在Windows或Linux电脑上运行macOS虚拟机,却发现VMware根本不提供苹…...
)
Docker容器化高可用架构部署方案(二)
01-环境准备 本文档详细介绍部署前的环境准备工作,包括操作系统要求、Docker安装、内核参数配置和网络确认。 系统要求 硬件要求 CPU:至少2核心 内存:至少4GB 磁盘:至少40GB可用空间 操作系统 OpenEuler 24.03 SP3 或其他L…...
)
AI大模型赋能数据治理:小白也能掌握的5个高频场景与避坑指南(收藏备用)
数据治理是企业数字化转型难题,AI大模型带来破局点。本文阐述大模型如何解决效率低、门槛高、适配弱等痛点,提供3个高价值落地场景(非结构化数据治理、数据质量治理、数据资产化治理)及5个高频踩坑陷阱,并给出最佳实践…...

面向非技术人员的AI智能体实战:零代码自动化工作流构建指南
1. 项目概述:面向非工程师的AI智能体实战训练营如果你是一名市场、销售、运营或行政人员,每天被重复性的文档处理、数据分析、内容制作和跨平台沟通所淹没,看着工程师同事用代码自动化一切,自己却只能手动操作,那么你很…...
深度集成:让 AI 安全执行企业 API)
函数调用(Function Calling)深度集成:让 AI 安全执行企业 API
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 5/10 篇,当前这篇会重点解决:展示如何让 AI 安全可控地操作企业后端服务,实现真正的智能体能力。 上一篇回顾:第 4 篇《检索增强生成(RAG)实战:Spring AI 集成向量数据库实现知识问…...

别再被Linux的free命令骗了!手把手教你读懂‘可用内存’和‘实际空闲内存’的区别
别再被Linux的free命令骗了!手把手教你读懂‘可用内存’和‘实际空闲内存’的区别 刚接触Linux服务器管理时,看到free -m输出里那个触目惊心的"free"数值,我的第一反应是:"天哪,内存快用完了࿰…...

【译】《心悟内核:先懂设计,再读代码》—1、内核并非进程,而是整个系统本身
作者:Moon Hee Lee 原文: The Kernel in the Mind 心悟内核:先懂设计,再读代码——内核并非进程,而是整个系统本身Linux 内核既不是普通进程、守护进程,也不是应用程序。它是一套常驻内存的高特权运行环境,…...