R语言对医学中的自然语言(NLP)进行机器学习处理(1)
什么是自然语言(NLP),就是网络中的一些书面文本。对于医疗方面,例如医疗记录、病人反馈、医生业绩评估和社交媒体评论,可以成为帮助临床决策和提高质量的丰富数据来源。如互联网上有基于文本的数据(例如,对医疗保健提供者的社交媒体评论),这些数据我们可以直接下载,有些可以通过爬虫抓取。例如:在病人论坛上发表对疾病或药物的评论,可以将它们存储在数据库中,然后进行分析。
在这个之前需要了解什么是情绪分析,情绪分析是指赋予词语、短语或其他文本单位主观意义的过程。情绪可以简单地分为正面或负面,也可以与更详细的主题有关,比如某些词语所反映的情绪。简单来说就是从语言从提取患者态度或者情绪的词语,然后进行分析,比如患者对这个药物的疗效,她说好,有用,我们提取出这些关键词来进行分析。
自然语言(NLP)进行机器学习分为无监督学习和有监督学习,本期咱们先来介绍无监督学习。咱们先导入R包和数据
library(tm)
library(data.table)
library(tidytext)
library(dplyr)
library(tidyr)
library(topicmodels)
library(performanceEstimation)
library(rsample)
library(recipes)
library(parsnip)
library(workflows)
library(tune)
library(dials)
library(kernlab)
library(ggplot2)
training_data <- as.data.frame(fread("E:/r/test/drugsComTrain_raw.tsv"))
咱们先来看一下数据
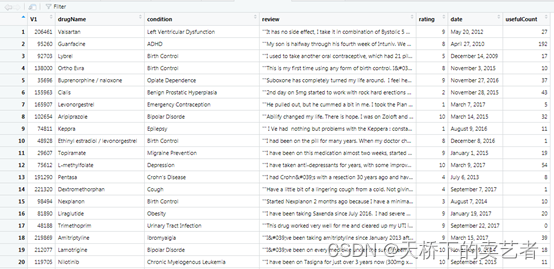
这是一个患者对药物评价的数据,该数据集提供了患者对特定药物及相关疾病的评估,以及10星级患者评级,反映了整体患者满意度。这些数据是通过爬取在线医药评论网站获得的。公众号回复:药物评论数据,可以获得该数据,我们先来看一下数据的构成,drugName:药物名称,condition (categorical)条件类别,多指患者的一些疾病类别,review:患者对药物的评论,rating患者对药物的打分,date (date)患者评论的日期,usefulCount发现评论有用的数据,代表浏览者支持这个观点。
这个数据有16万行,非常大,为了演示方便,我们只取5000个来演示
set.seed(123)
sample <- sample(nrow(training_data),5000)
data <- training_data[sample,]
dim(data)

因为这是网页抓取的数据,会存在一些乱码,所以咱们在分析前先要进行数据的清洗,编写一个简单的数据清洗程序,就是一些简单的正则式小知识
cleanText <- function(rawtext) {rawtext <- gsub("'", "?", rawtext)# Expand contractionsrawtext <- gsub("n?t", " not", rawtext)rawtext <- gsub("won?t", "will not", rawtext)rawtext <- gsub("wont", "will not", rawtext)rawtext <- gsub("?ll", " will", rawtext)rawtext <- gsub("can?t", "can not", rawtext)rawtext <- gsub("cant", "can not", rawtext)rawtext <- gsub("didn?t", "did not", rawtext)rawtext <- gsub("didnt", "did not", rawtext)rawtext <- gsub("?re", " are", rawtext)rawtext <- gsub("?ve", " have", rawtext)rawtext <- gsub("?d", " would", rawtext)rawtext <- gsub("?m", " am", rawtext)rawtext <- gsub("?s", "", rawtext)# Remove non-alphanumeric characters.rawtext <- gsub("[^a-zA-Z0-9 ]", " ", rawtext)# Convert all text to lower case.rawtext <- tolower(rawtext)# Stem wordsrawtext <- stemDocument(rawtext, language = "english")return(rawtext)
}
这个小程序我简单介绍一下,第一行就是就是把文字中的"'"全部改成“?”,其他也是差不多的,第二行就是把"n?t"改成" not".接下来gsub("[^a-zA-Z0-9 ]", " ", rawtext)这句前面有个^,表示把没有数据和字母的字符的字符串定义为缺失。tolower(rawtext)是把数据转成小写。
写好程序后咱们运行一下
data$review <- sapply(data$review, cleanText)
这样数据就被清洗一遍了,接下来咱们需要使用tidytext包中的unnest_tokens函数先把评论打散,变成一个个的单词,然后把含有stop的单词去掉,再把每行重复的词去掉,最后选择大于3个字符的词
tidydata <- data %>%unnest_tokens(word, review) %>% #将句子打散变成单个词anti_join(stop_words) %>% #Joining with `by = join_by(word)` remove stop wordsdistinct() %>% #去除重复filter(nchar(word) > 3)
我们看下整理后的数据,我们可以看到同一行被拆成多个词,当然数据也比原来大了很多
接下来咱们需要使用get_sentiments函数来对文本进行分析,它自带有很多字典咱们这次使用"bing"字典进行分析,咱们先来看下什么是"bing"字典
head(get_sentiments("bing"),20)

我们可以看到字典就是对应的字符串,假如匹配到abnormal 这个词,函数就会返回负面的negative,假如是abound这个词,函数就会返回正面的positive
tidydata %>%inner_join(get_sentiments("bing")) #使用"bing"的字典进行情感分析

咱们看到数据很大,咱们只取其中的4种药物来分析"Levothyroxine",“Vyvanse”,“Xiidra”,“Oseltamivir”,并且计算出每种药物的评价数量和百分比
drug_polarity <- tidydata %>%inner_join(get_sentiments("bing")) %>% #使用"bing"的字典进行情感分析filter(drugName == "Levothyroxine" | #选定4种药物drugName == "Vyvanse" |drugName == "Xiidra" |drugName == "Oseltamivir") %>%count(sentiment, drugName) %>% #对情感进行计数pivot_wider(names_from = sentiment, #选择要访问的列values_from = n, #输出列的名字values_fill = 0) %>% #如果缺失的话默认填0mutate(polarity = positive - negative, #评分percent_positive = positive/(positive+negative) * 100) %>% #计算百分比arrange(desc(percent_positive))
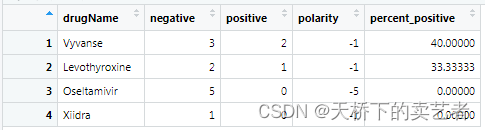
上图对显示出患者对药物的一些基本反馈。
下面咱们准备开始进行无监督学习,先要建立矩阵(DTM),
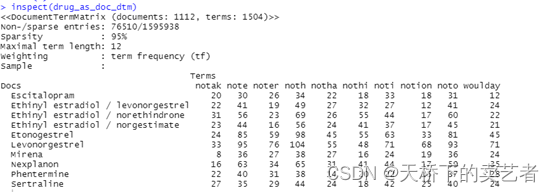
drug_as_doc_dtm <- tidydata %>%count(drugName, word, sort = TRUE) %>% #每种药物的评价词语的个数ungroup() %>% cast_dtm(drugName, word, n) %>% #将数据帧转换为tm包中DocumentTermMatrix,TermDocumentMatrix或dfmremoveSparseTerms(0.995)
我们看一下这个矩阵
inspect(drug_as_doc_dtm)
建立好矩阵后主要是通过topicmodels包的LDA函数来进行无监督学习,这里的K表示你想要分成几组,control这里可以设置一个种子
lda<- LDA(drug_as_doc_dtm, k = 3,control = list(seed = 123))
接着咱们对数据进行进一步提取
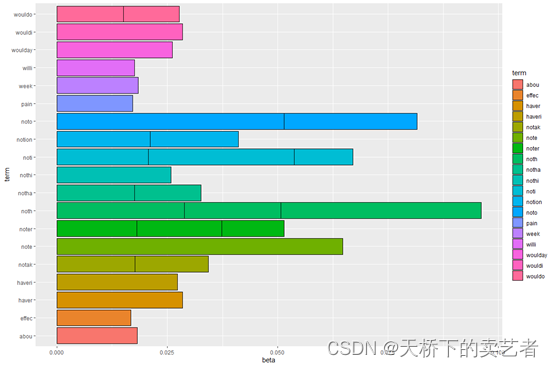
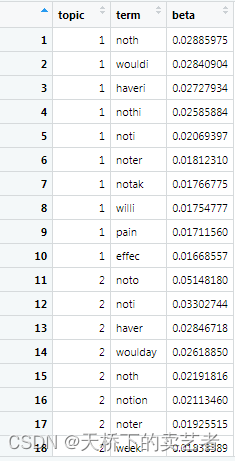
top_terms_per_topic <- lda %>%tidy(matrix = "beta") %>% #获取系数group_by(topic) %>% #分组arrange(topic, desc(beta)) %>% #排序slice(seq_len(10)) # Number of words to display per topic
看下提取后的数据,第一个是组别,第二个是它的名字,第三个是它的beta
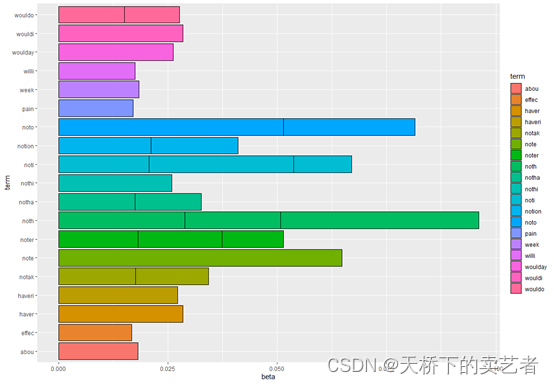
接下来咱们可以做一些简单的可视化,加入咱们想看这些词的几率
ggplot(top_terms_per_topic, aes(x = beta, y = term, fill = term)) +geom_bar(stat = "identity", color = "black")
或者做个词云图
library(wordcloud)wordcloud(top_terms_per_topic$term,top_terms_per_topic$beta,scale=c(3,0.3),min.freq=-Inf,max.words=Inf,colors=brewer.pal(8,'Set1'),random.order=F,random.color=F,ordered.colors=F)

本期先介绍到这里,下期继续介绍有监督学习,未完待续。
参考文献:
- tm包文档
- tidytext包文档
- topicmodels包文档
- Harrison, C.J., Sidey-Gibbons, C.J. Machine learning in medicine: a practical introduction to natural language processing. BMC Med Res Methodol 21, 158 (2021).
- https://www.cnblogs.com/jiangxinyang/p/9358339.html
- https://blog.csdn.net/sinat_26917383/article/details/51547298
相关文章:
R语言对医学中的自然语言(NLP)进行机器学习处理(1)
什么是自然语言(NLP),就是网络中的一些书面文本。对于医疗方面,例如医疗记录、病人反馈、医生业绩评估和社交媒体评论,可以成为帮助临床决策和提高质量的丰富数据来源。如互联网上有基于文本的数据(例如,对医疗保健提供者的社交媒体评论),这些数据我们可…...

什么是CI/CD?如何在PHP项目中实施CI/CD?
CI/CD(持续集成/持续交付或持续部署)是一种软件开发和交付方法,它旨在通过自动化和持续集成来提高开发速度和交付质量。以下是CI/CD的基本概念和如何在PHP项目中实施它的一般步骤: 持续集成(Continuous Integration -…...
:容器指令、生命周期、资源限制、容器化支持、常用命令)
玩转Docker(四):容器指令、生命周期、资源限制、容器化支持、常用命令
文章目录 一、容器指令1.运行2.启动/停止/重启3.暂停/恢复4.删除 二、生命周期三、资源限制1.内存限额2.CPU限额3.磁盘读写带宽限额 四、cgroup和namespace五、常用命令 一、容器指令 1.运行 按用途容器大致可分为两类:服务类容器和工具类的容器。 服务类容器&am…...
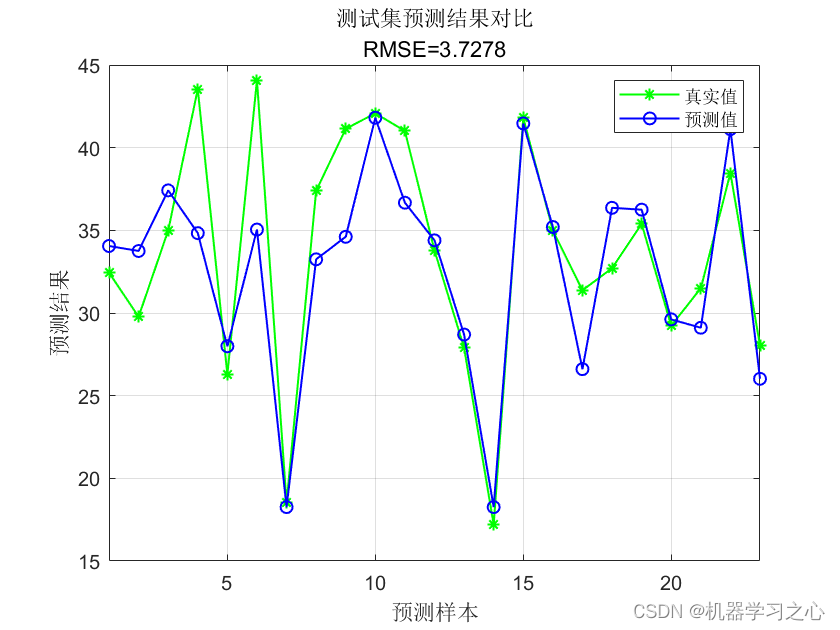
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图) 目录 回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)效果…...

Qt/C++视频监控安卓版/多通道显示视频画面/录像存储/视频播放安卓版/ffmpeg安卓
一、前言 随着监控行业的发展,越来越多的用户场景是需要在手机上查看监控,而之前主要的监控系统都是在PC端,毕竟PC端屏幕大,能够看到的画面多,解码性能也强劲。早期的手机估计性能弱鸡,而现在的手机性能不…...

【docker】容器使用(Nginx 示例)
查看 Docker 客户端命令选项 docker上面这三张图都是 常用命令: run 从映像创建并运行新容器exec 在运行的容器中执行命令ps 列出容器build 从Dockerfile构建映像pull 从注册表下载图像push 将图像上载到注册表…...
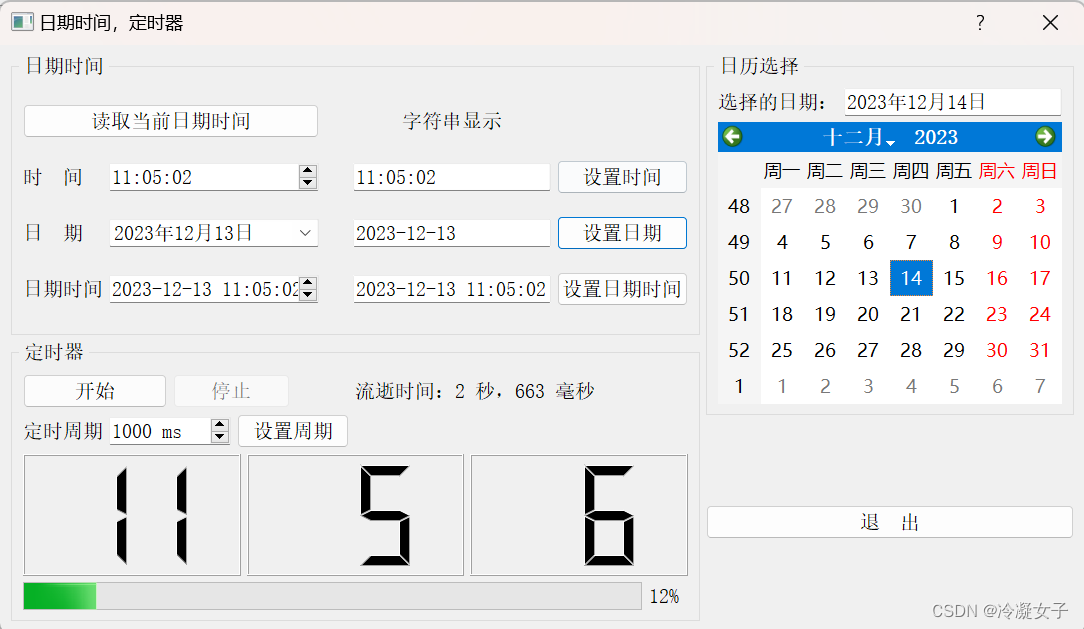
【QT】时间日期与定时器
目录 1.时间日期相关的类 2.日期时间数据与字符串之间的转换 2.1 时间、日期编辑器属性设置 2.2 日期时间数据的获取与转换为字符串 2.3 字符串转换为日期时间 3.QCaIendarWidget日历组件 3.1基本属性 3.2 公共函数 3.3 信号 4.实例程序演示时间日期与定时器的使用 …...

蓝桥杯专题-真题版含答案-【古代赌局】【古堡算式】【微生物增殖】【密码发生器】
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列ChatGPT和AIGC 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分…...

和鲸科技携手深圳数据交易所,“数据+数据开发者生态”赋能人工智能产业发展
信息化时代,数据驱动决策的重要性日益凸显。通过利用数据可以深入了解市场需求、客户行为、竞争态势等关键信息,从而制定更为有效的战略和决策。围绕推动数据要素产业发展,近日,深圳数据交易所(以下简称“深数所”&…...
中 CreateThread函数)
在MFC(Microsoft Foundation Classes)中 CreateThread函数
CreateThread是Windows API中用于创建新线程的函数。以下是对函数参数的详细解释: lpThreadAttributes(可选):指向SECURITY_ATTRIBUTES结构的指针,用于指定线程的安全性。可以设置为NULL,表示使用默认安全…...
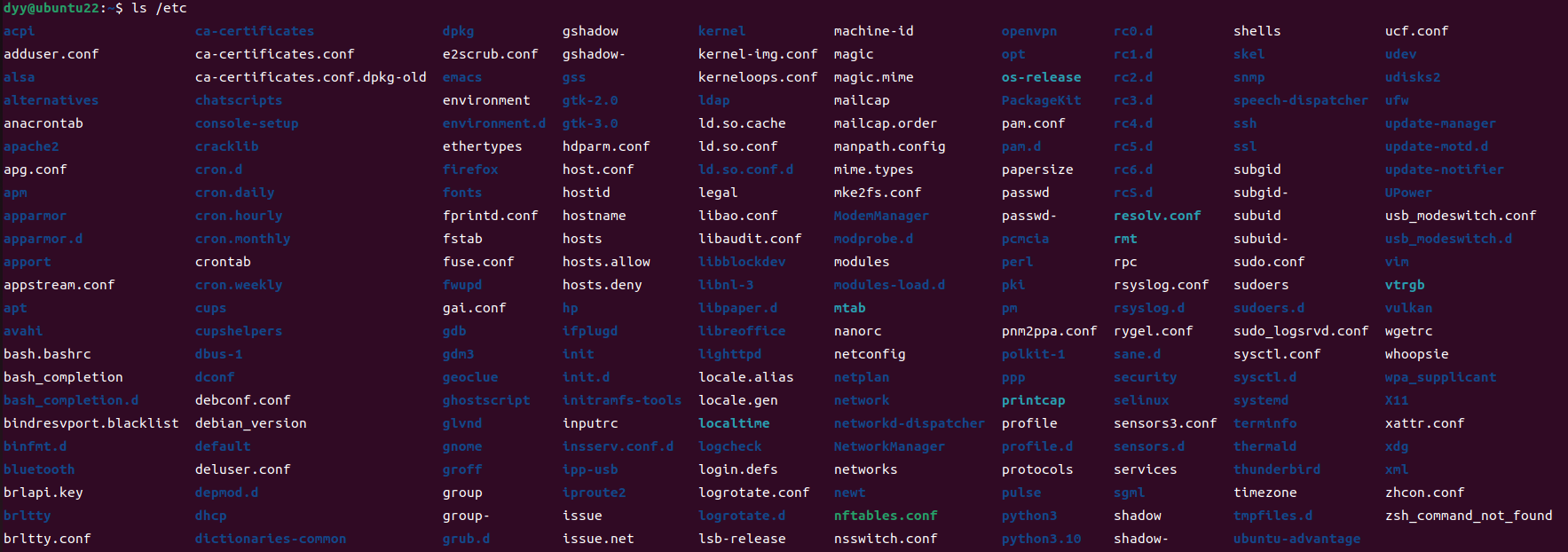
Ubuntu 常用命令之 ls 命令用法介绍
Ubuntu ls 命令用法介绍 ls是Linux系统下的一个基本命令,用于列出目录中的文件和子目录。它有许多选项可以用来改变列出的内容和格式。 以下是一些基本的ls命令选项 -l:以长格式列出文件,包括文件类型、权限、链接数、所有者、组、大小、最…...
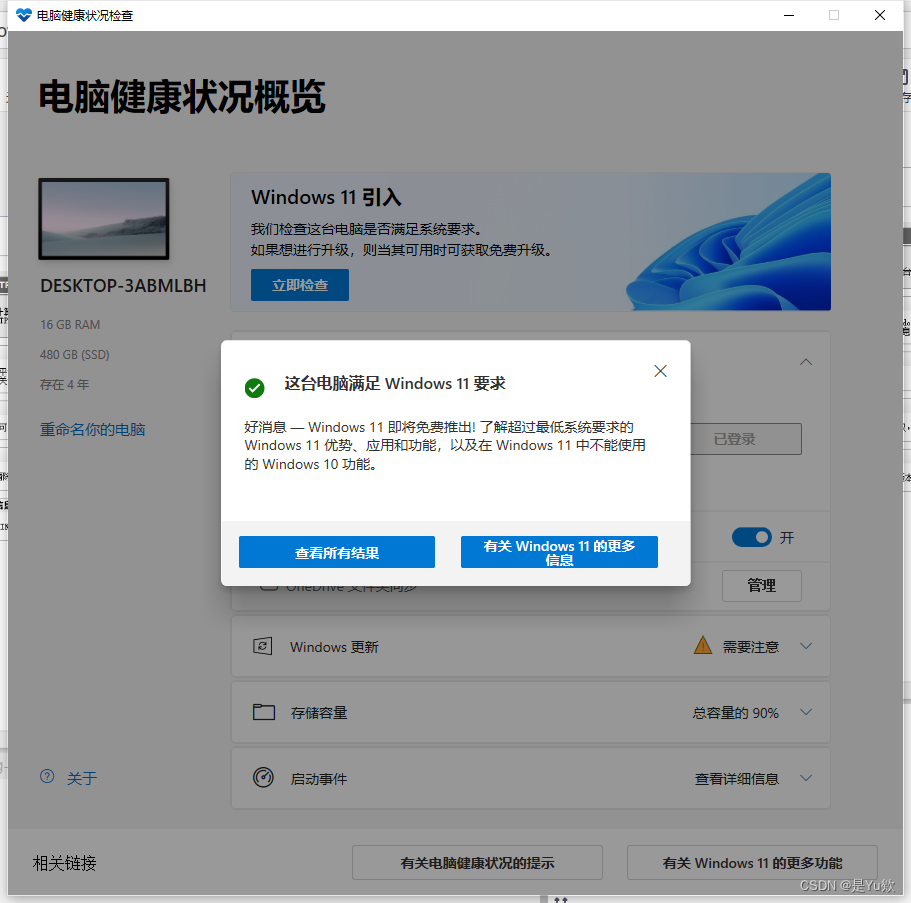
【解决】Windows 11检测提示电脑不支持 TPM 2.0(注意从DTPM改为PTT)
win11升级,tpm不兼容 写在最前面1. 打开电脑健康状况检查2. 开启tpm3. 微星主板AMD平台开启TPM2.0解决电脑健康状况检查显示可以安装win11,但是系统更新里显示无法更新 写在最前面 我想在台式电脑上用win11的专注模式,但win10不支持 1. 打…...

ChatGPT 也宕机了?如何预防 DDOS 攻击的发生
最近,开发人工智能聊天机器人的公司 OpenAI 遭受了一次规模较大的分布式拒绝服务(DDoS)攻击,导致其旗下的 ChatGPT 服务在短短 12 小时内遭遇了 4 次断网,众多用户遭受了连接失败的问题。 这次攻击事件引起了广泛的关…...

wireshark下载安装
下载 Wireshark Download 等待下载完成 安装 双击 下面的一定垚勾选上 下图的也一定要勾选上 修改为不重启,不需要重启也是正常的...
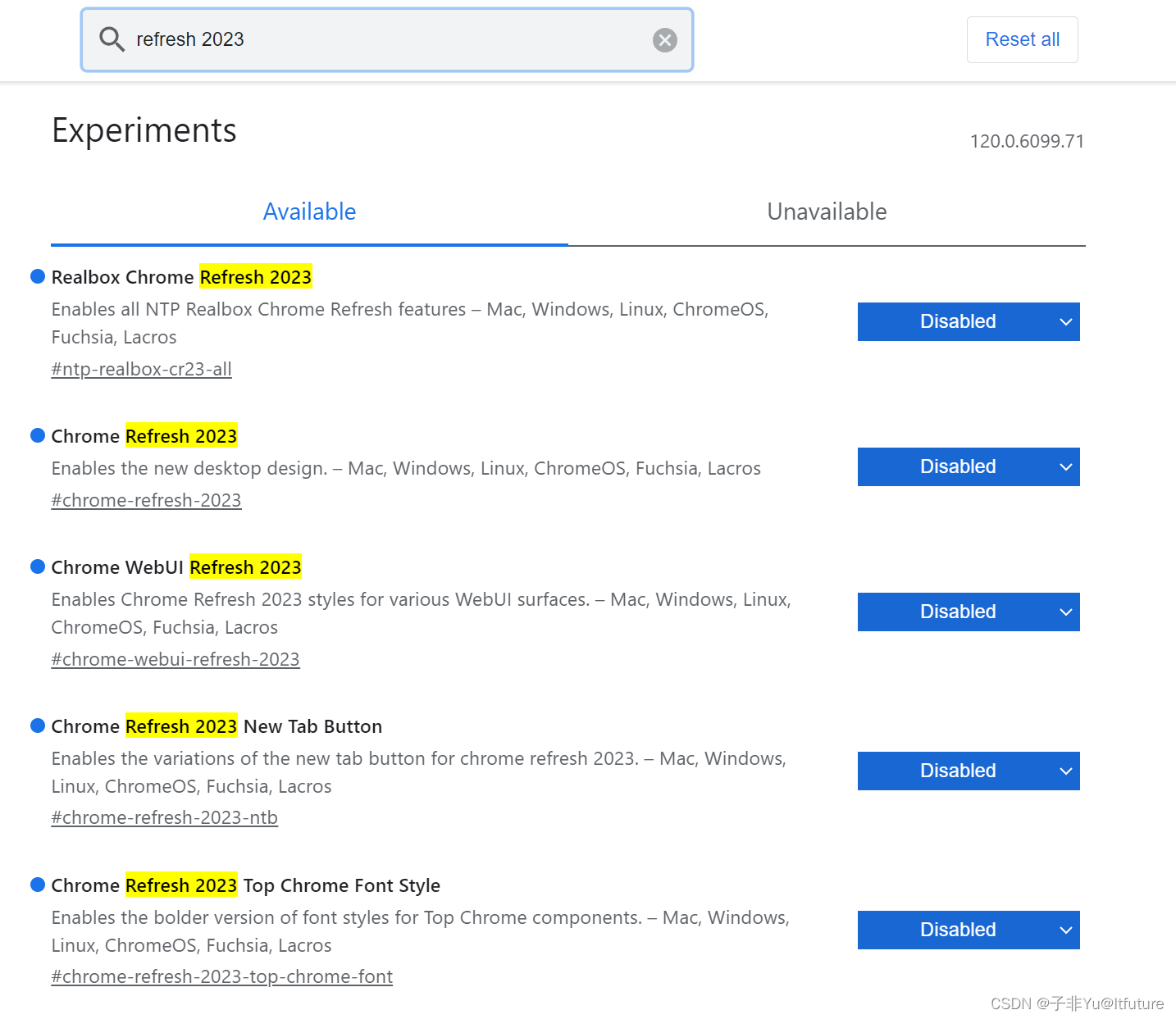
如何退回chrome旧版ui界面?关闭Chrome浏览器新 UI 界面
之前启用新UI的方式 Chrome 已经很久没有进行过大的样式修改,但近期在稳定分支中添加了新的 flags 实验性标志,带来了全新的设计与外观,启用方式如下: 在 Chrome 浏览器的搜索栏中输入并访问 chrome://flags 搜索“refresh 2023…...
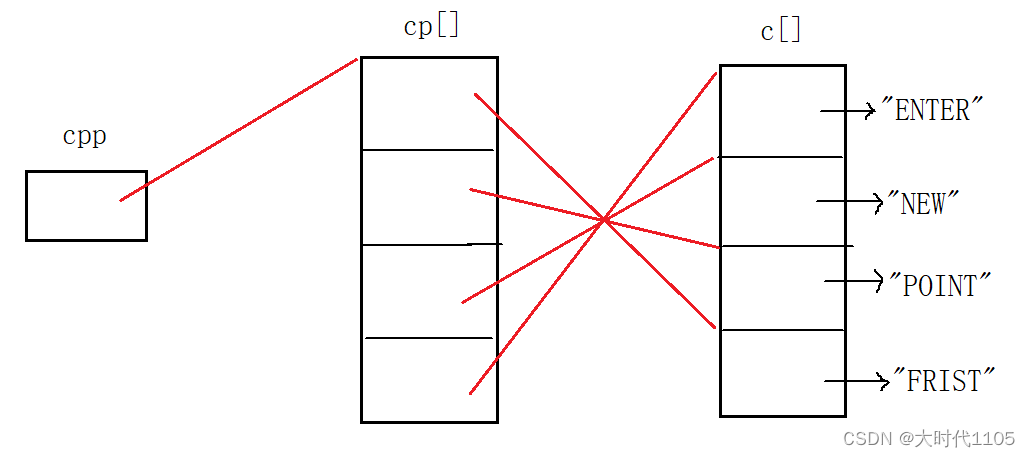
指针进阶篇
指针的基本概念: 指针是一个变量,对应内存中唯一的一个地址指针在32位平台下的大小是4字节,在64位平台下是8字节指针是有类型的,指针类型决定该指针的步长,即走一步是多长指针运算:指针-指针表示的是两个指…...

C语言之单链表理解与应用
其实网上有好多关于单链表理解,其实知乎上有一篇写的很好,利用图形与代码结合,我觉得写的很好,大家也可以去查一下,每个人都有自己的想法与理解,这里主要看单链表概念,应用场景,举例…...
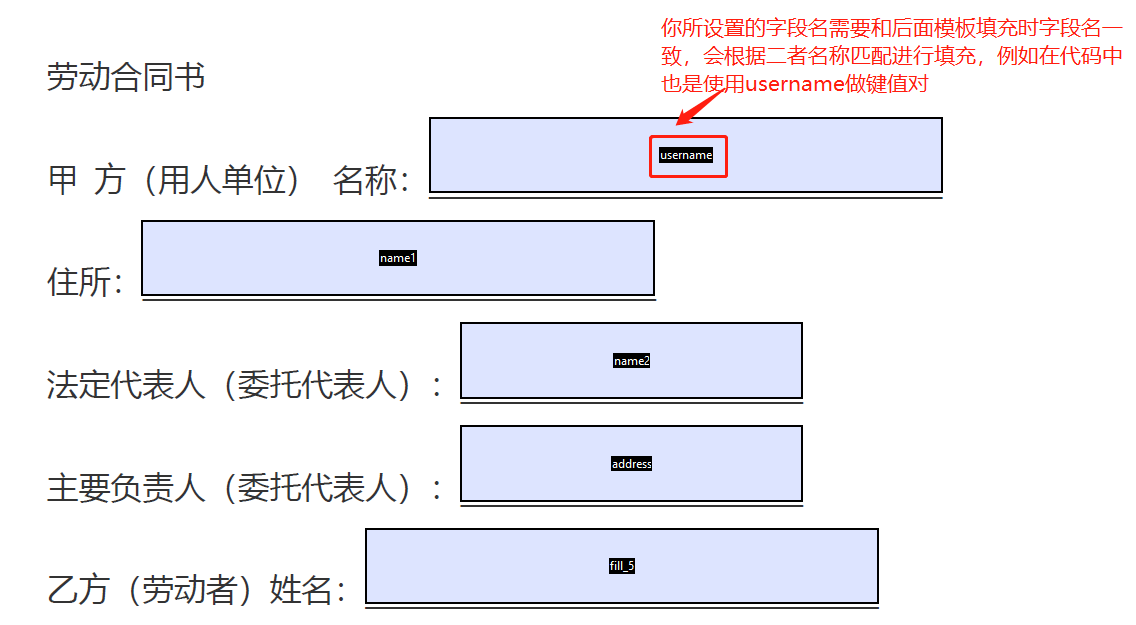
SpringBoot对PDF进行模板内容填充、电子签名合并
1. 依赖引入–这里只包含额外引入的包 原有项目包不含括在内 <!-- pdf编辑相关--> <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.13.3</version> </dependency><de…...
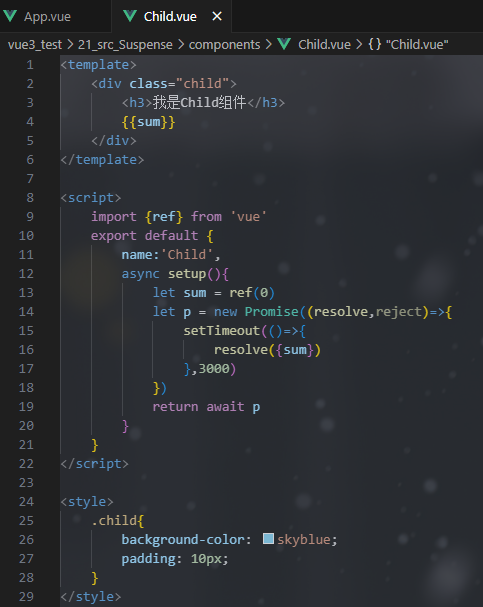
Vue3快速上手笔记
Vue3快速上手 1.Vue3简介 2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王)耗时2年多、2600次提交、30个RFC、600次PR、99位贡献者github上的tags地址:https://github.com/vuejs/vue-next/release…...
LLM中的Prompt提示
简介 在LLM中,prompt(提示)是一个预先设定的条件,它可以限制模型自由发散,而是围绕提示内容进行展开。输入中添加prompt,可以强制模型关注特定的信息,从而提高模型在特定任务上的表现。 结构 …...

小白友好!MogFace本地部署全攻略,从安装到检测只需3步
小白友好!MogFace本地部署全攻略,从安装到检测只需3步 1. 工具简介 MogFace是一款基于CVPR 2022论文的高精度人脸检测工具,特别适合需要保护隐私的本地化应用场景。它能够准确识别照片中的多个人脸,无论这些人脸是大是小、是正脸…...

AI数字人开源方案:Duix.Avatar本地化部署与应用指南
AI数字人开源方案:Duix.Avatar本地化部署与应用指南 【免费下载链接】Duix-Avatar 🚀 Truly open-source AI avatar(digital human) toolkit for offline video generation and digital human cloning. 项目地址: https://gitcode.com/GitHub_Trending…...

毕业设计实战:基于SSM+MySQL的税务门户网站设计与实现指南
毕业设计实战:基于SSMMySQL的税务门户网站设计与实现指南 在开发“基于SSMMySQL的税务门户网站”毕业设计时,曾因政策文件收藏表未通过用户ID与政策文件ID双外键关联踩过关键坑——初期仅设计收藏编号、收藏时间等基础字段,未与用户表、政策文…...

SDMatte与LSTM结合研究:时序视频抠图的初步探索
SDMatte与LSTM结合研究:时序视频抠图的初步探索 1. 引言:视频抠图的新挑战 视频抠图技术一直是影视后期和内容创作领域的重要工具。传统的静态图像抠图方法在处理视频时常常面临一个棘手问题:帧与帧之间的结果不一致,导致最终视…...

别再死记API了!用FreeRTOS消息队列的底层逻辑,彻底搞懂信号量、互斥锁和队列集
FreeRTOS同步机制的解密:从消息队列到信号量的统一视角 在嵌入式开发中,任务间的同步与通信是构建可靠系统的核心挑战。FreeRTOS作为广泛应用的实时操作系统,提供了丰富的同步机制——消息队列、信号量、互斥锁等。然而,许多开发者…...

实战应用:为团队部署即装即用的中文版mobaxterm统一环境
在团队协作开发中,统一开发环境配置是个常见痛点。最近我们团队就遇到了这个问题:新成员加入时,每个人都要手动配置MobaXterm的中文界面、服务器连接、工具集等,既费时又容易出错。经过实践摸索,我总结出一套用脚本自动…...

GeoServer REST API实战:手把手教你用Python封装自己的批量发布工具
GeoServer REST API深度封装:Python自动化发布框架设计与实战 1. 为什么需要自定义GeoServer发布工具? 在GIS项目实施过程中,我们经常面临数百个地理数据文件需要快速发布的场景。传统手动操作不仅效率低下(单个文件平均耗时2分钟…...

Nunchaku FLUX.1 CustomV3问题解决:提示词怎么写?参数怎么调?一篇搞定
Nunchaku FLUX.1 CustomV3问题解决:提示词怎么写?参数怎么调?一篇搞定 你是不是也遇到过这种情况:兴冲冲地打开了Nunchaku FLUX.1 CustomV3,想生成一张美美的吉卜力风格插画,结果出来的图片要么“货不对板…...

RSA2 - Writeup by AI
RSA2 - Writeup by AI 题目信息项目内容题目来源Bugku CTF题目类型Crypto (密码学)考点RSA 小指数攻击、Rabin 加密题目描述 给定 RSA 加密参数: 加密指数 e 2模数 N(3072 位)密文 c 要求解密得到 flag。 考点分析 核心知识点 RSA 小指数攻击…...

从“单点防御”到“全局联动”:手把手教你用EDR和NDR构建企业安全闭环
从“单点防御”到“全局联动”:手把手教你用EDR和NDR构建企业安全闭环 当企业的安全团队还在疲于应对零散的端点告警和网络流量异常时,攻击者早已开始采用自动化工具进行横向移动。传统孤立的防御手段就像用多个单点摄像头监控银行金库——每个摄像头都…...