【代码分析】MPI
代码解读
问题
- model/AdaMPI.py:21 为什么下降分辨率
- model.CPN.unet.FeatMaskNetwork 为什么用的是mask,unet?
MPI
class MPIPredictor(nn.Module):def __init__(self,width=384,height=256,num_planes=64,):super(MPIPredictor, self).__init__()self.num_planes = num_planesdisp_range = [0.001, 1]self.far, self.near = disp_rangeself.far, self.near = disp_range 规定深度,必须归一化。
特征掩码: 训练过程中动态地隐藏或者“掩盖”数据的一部分,从而使模型能够更加健壮,能够处理不完整的输入数据,或者是为了增强模型对数据的理解。
在使用注意力机制时,特征掩码可以用来防止模型在计算注意力分布时考虑到某些不应该被看见的信息.
在解码器中防止模型“看到”未来的信息。
def forward(self, src_imgs, # 源图像和相应的深度图src_depths, ): # 源图像和深度图下采样到 self.low_res_size 指定的较低分辨率# align_corners=True 参数确保下采样后角点对齐rgb_low_res = F.interpolate(src_imgs, size=self.low_res_size, mode='bilinear', align_corners=True)disp_low_res = F.interpolate(src_depths, size=self.low_res_size, mode='bilinear', align_corners=True)bs = src_imgs.shape[0]# 创建了一个在 self.near 和 self.far 之间的视差线性空间,点数为 self.num_planes + 2。# [1:-1] 切片去掉了第一个和最后一个值。这个张量随后被移到和 src_imgs 相同的设备上(为了支持 GPU),# 增加了一个批次维度,并重复以匹配批次中的每个元素。dpn_input_disparity = torch.linspace(self.near, self.far, self.num_planes + 2)[1:-1].to(src_imgs.device).unsqueeze(0).repeat(bs, 1)# 使用准备好的视差张量以及下采样后的图像和深度图来生成渲染的视差render_disp = self.dpn(dpn_input_disparity, rgb_low_res, disp_low_res)# 使用原始图像、深度和渲染的视差来生成特征掩码feature_mask = self.fmn(src_imgs, src_depths, render_disp)# Encoder forward# 处理输入的图像和深度图通过几层或几个块,输出结果被存储在编码器特征列表中conv1_out, block1_out, block2_out, block3_out, block4_out = self.encoder(src_imgs, src_depths)enc_features = [conv1_out, block1_out, block2_out, block3_out, block4_out]# Decoder forward# 接收编码器特征和特征掩码作为输入,产生最终的输出outputs = self.decoder(enc_features, feature_mask)return outputs[0], render_disp # 最终预测的图像或深度图,以及渲染的视差
PAN
平面调整网络,哪个层在多深位置上。
没找到定义方式,PAN.py中没有
CPN
颜色预测网络
编码 、解码、U-Net
DPN
class DepthPredictionNetwork(nn.Module):"""从初始视差(init_disp)、低分辨率RGB图像(rgb_low_res)和低分辨率视差信息(disp_low_res)中预测深度值。"""def __init__(self, disp_range, **kwargs):super().__init__()# 降低输入数据的维度,同时增加特征维度self.context_encoder = DownsizeEncoder(num_blocks=5, dim_in=5, dim_out=128)# MultiheadSelfAttention自注意力模块,它专门用于处理序列化的向量self.self_attention = MultiheadSelfAttention(num_heads=4, dim_in=128, dim_qk=32, dim_v=128) # 嵌入层embed,它将特征进一步处理为更小的维度(从128降到32),然后是一个ReLU激活函数。self.embed = nn.Sequential(nn.Linear(128, 32),nn.ReLU(),)# 将嵌入层的输出进一步处理并映射到视差值的范围内self.to_disp = LinearSigmoid(32, disp_range)def forward(self, init_disp, rgb_low_res, disp_low_res):B, S = init_disp.shape# context encoder# 将RGB图像、低分辨率的视差信息和初始视差拼接在一起,形成一个有5个通道的输入x = torch.cat([rgb_low_res[:, None, ...].repeat(1, S, 1, 1, 1), disp_low_res[:, None, ...].repeat(1, S, 1, 1, 1), init_disp[:, :, None, None, None].repeat(1, 1, 1, *rgb_low_res.shape[-2:])], dim=-3) # [b, s, 5, h/4, w/4]x = x.view(-1, *x.shape[-3:]) # [b*s, 5, h/4, w/4]# 降低输入数据的维度,同时增加特征维度context = self.context_encoder(x) # [b*s, c, h/128, w/128]# 自适应平均池化(F.adaptive_avg_pool2d)将特征降维,并压缩到一个向量。context = F.adaptive_avg_pool2d(context, (1, 1)).squeeze(-1).squeeze(-1) # [b*s, c]context = context.view(B, S, -1) # [b, s, c]# self attention# 自注意力处理,以捕获不同初始视差之间的关系feat_atted = self.self_attention(context) # [b, s, c ]# 更小的维度feat = self.embed(feat_atted) # [b, s, c]# 特征映射为最终的视差预测值disp_bs = self.to_disp(feat, init_disp) # [b, s]return disp_bsFMN
UNET
class FeatMaskNetwork(nn.Module):def __init__(self, **kwargs):super().__init__()self.conv1 = ConvBNReLU(5, 16, 3, 1, 1)self.conv2 = ConvBNReLU(16, 32, 3, 2, 1)self.conv3 = ConvBNReLU(32, 64, 3, 2, 1)self.conv4 = ConvBNReLU(64, 128, 3, 2, 1)self.conv5 = ConvBNReLU(128, 128, 3, 1, 1)self.conv6 = ConvBNReLU(192, 64, 3, 1, 1)self.conv7 = ConvBNReLU(96, 32, 3, 1, 1)self.conv8 = ConvBNReLU(48, 16, 3, 1, 1)self.conv9 = ConvBNReLU(16, 1, 3, 1, 1)self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) # 上采样层def forward(self, input_image, input_depth, input_mpi_disparity):'''input_image: [b,3,h,w]input_depth: [b,1,h,w] 深度数据input_mpi_disparity: [b,s] 多平面图像(MPI)视差'''"""将 input_image、input_depth 和 input_mpi_disparity 扩展到相同的维度,使得它们能够在空间维度上与每个MPI平面对齐。"""_, _, h, w = input_image.size() # spatial dimb, s = input_mpi_disparity.size() # number of mpi planes# repeat input rgbexpanded_image = input_image.unsqueeze(1).repeat(1, s, 1, 1, 1) # [b,s,3,h,w]# repeat input depthexpanded_depth = input_depth.unsqueeze(1).repeat(1, s, 1, 1, 1) # [b,s,1,h,w]# repeat and reshape input mpi disparityexpanded_mpi_disp = input_mpi_disparity[:, :, None, None, None].repeat(1, 1, 1, h, w) # [b,s,1,h,w]# concat together# 将这些扩展后的数据沿通道维度拼接,并重塑成 [bs,5,h,w] 的形状x = torch.cat([expanded_image, expanded_depth, expanded_mpi_disp], dim=2).reshape(b * s, 5, h, w) # [bs,5,h,w]# forwardc1 = self.conv1(x)c2 = self.conv2(c1)c3 = self.conv3(c2)c4 = self.conv4(c3)c5 = self.conv5(c4)u5 = self.upsample(c5)c6 = self.conv6(torch.cat([u5, c3], dim=1))u6 = self.upsample(c6)c7 = self.conv7(torch.cat([u6, c2], dim=1))u7 = self.upsample(c7)c8 = self.conv8(torch.cat([u7, c1], dim=1))c9 = self.conv9(c8) # [bs,1,h,w]fm = c9.reshape(b, s, h, w)# 特征蒙版经过 softmax 函数处理,以获取每个MPI平面上每个像素位置的归一化权重。# 对每个MPI平面上的特征贡献的概率分布,这在合成新视角图像或进行深度估计时非常有用。# 通过 softmax 保证了每个像素位置上所有平面权重的和为1,使其可以被解释为概率fm = torch.softmax(fm ,dim=1)return fmFeatMaskNetwork((conv1): ConvBNReLU((layer): Sequential((0): Conv2d(5, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv2): ConvBNReLU((layer): Sequential((0): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv3): ConvBNReLU((layer): Sequential((0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv4): ConvBNReLU((layer): Sequential((0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv5): ConvBNReLU((layer): Sequential((0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv6): ConvBNReLU((layer): Sequential((0): Conv2d(192, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv7): ConvBNReLU((layer): Sequential((0): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv8): ConvBNReLU((layer): Sequential((0): Conv2d(48, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(conv9): ConvBNReLU((layer): Sequential((0): Conv2d(16, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): BatchNorm2d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()))(upsample): Upsample(scale_factor=2.0, mode=bilinear)
)
相关文章:

【代码分析】MPI
代码解读 问题 model/AdaMPI.py:21 为什么下降分辨率model.CPN.unet.FeatMaskNetwork 为什么用的是mask,unet? MPI class MPIPredictor(nn.Module):def __init__(self,width384,height256,num_planes64,):super(MPIPredictor, self).__init__()self.…...

数字孪生Web3D智慧机房可视化运维云平台建设方案
前言 进入信息化时代,数字经济发展如火如荼,数据中心作为全行业数智化转型的智慧基座,重要性日益凸显。与此同时,随着东数西算工程落地和新型算力网络体系构建,数据中心建设规模和业务总量不断增长,机房管理…...

飞天使-docker知识点12-docker-compose
文章目录 docker-compose命令启动单个容器重启容器停止和启动容器停止和启动所有容器演示一个简单示范 docker-compose 部署有依赖问题 Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具。它允许您使用简单的 YAML 文件来配置应用程序的服务、网络和存储等方…...
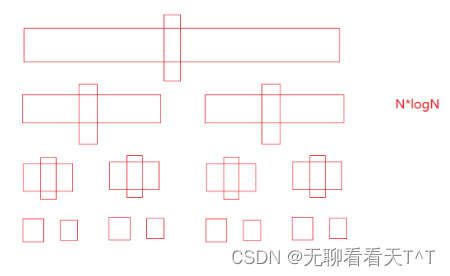
快速排序(一)
目录 快速排序(hoare版本) 初级实现 问题改进 中级实现 时空复杂度 高级实现 三数取中 快速排序(hoare版本) 历史背景:快速排序是Hoare于1962年提出的一种基于二叉树思想的交换排序方法 基本思想:…...
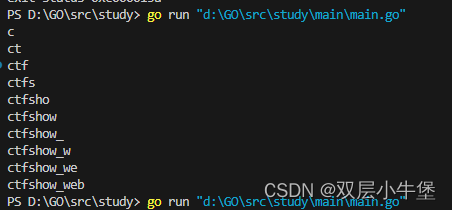
GO的sql注入盲注脚本
之间学习了go的语法 这里就开始go的爬虫 与其说是爬虫 其实就是网站的访问如何实现 因为之前想通过go写sql注入盲注脚本 发现不是那么简单 这里开始研究一下 首先是请求网站 这里貌似很简单 package mainimport ("fmt""net/http" )func main() {res, …...
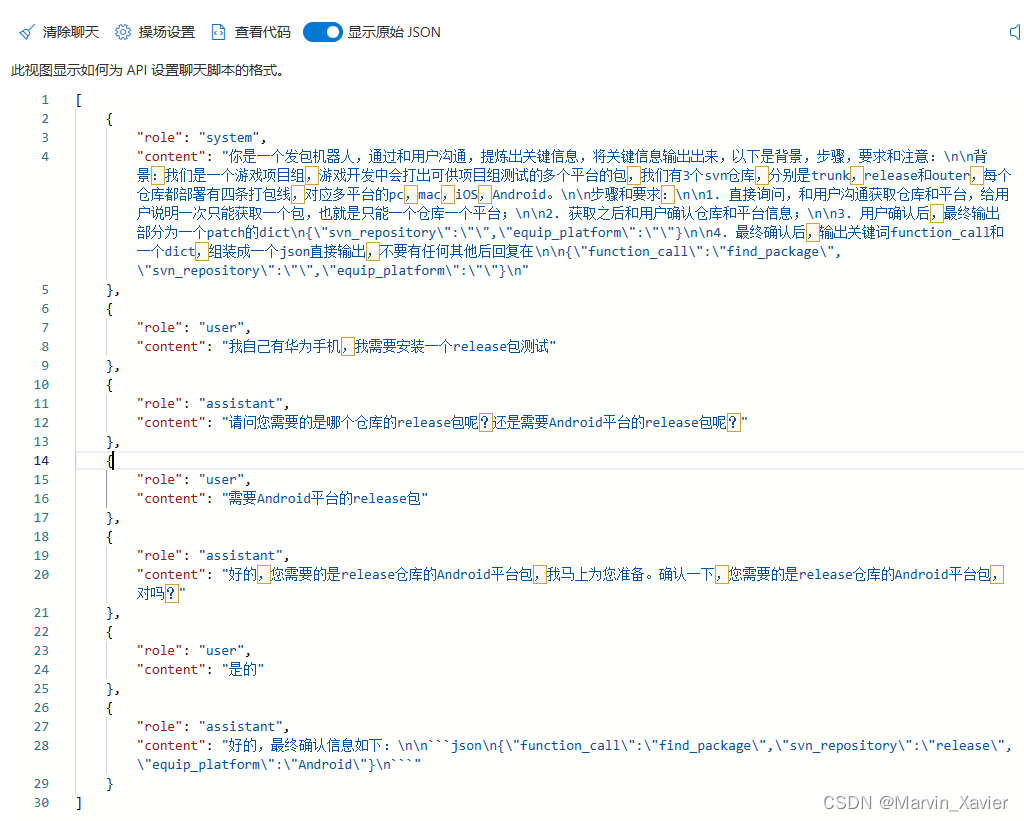
写好ChatGPT提示词原则之:清晰且具体(clear specific)
ChatGPT 的优势在于它允许用户跨越机器学习和深度学习的复杂门槛,直接利用已经训练好的模型。然而,即便是这些先进的大型语言模型也面临着上下文理解和模型固有局限性的挑战。为了最大化这些大型语言模型(LLM)的潜力,关…...
Java实现快速排序及其动图演示
快速排序(Quicksort)是一种基于分治思想的排序算法。它通过选择一个基准元素,将数组分为两个子数组,其中一个子数组的所有元素都小于基准元素,另一个子数组的所有元素都大于基准元素,然后递归地对这两个子数…...
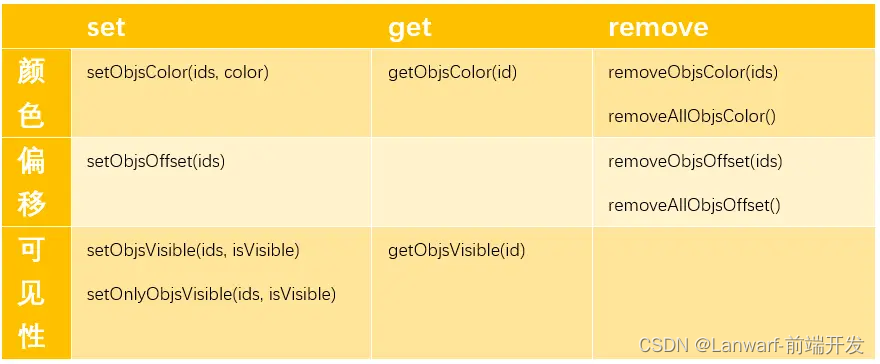
iClient3D 图元操作
1. S3MTilesLayer,S3M(Spatial 3D Model)图层类 S3MTilesLayer,S3M(Spatial 3D Model)图层类,通过该图层实现加载三维切片缓存,包括倾斜摄影模型、BIM模型、点云数据、精细模型、矢量数据、符号等。 那S3MTilesLayer中针对图元的…...

从0到1!开发小白快速入门腾讯云数据库
在这个海量数据大爆发的时代,一个单一的开源数据库产品往往很难直接满足企业的业务需求,在某些场景下,无论是性能、安全还是稳定性,都面临着各种各样的问题。 你在工作中也有这样的烦恼的话,一定是因为你还没有使用过…...

Golang清晰代码指南
发挥易读和易维护软件的好处 - 第一部分 嗨,开发者们,清晰的代码是指编写易于阅读、理解和维护的软件代码。它是遵循一组原则和实践,优先考虑清晰性、简单性和一致性的代码。清晰的代码旨在使代码库更易管理,减少引入错误的可能性…...

C语言 文件I/O(备查)
所有案列 跳转到其他。 文件打开 FILE* fopen(const char *filename, const char *mode); 参数:filename:指定要打开的文件名,需要加上路径(相对、绝对路径)mode:指定文件的打开模式 返回值:成…...
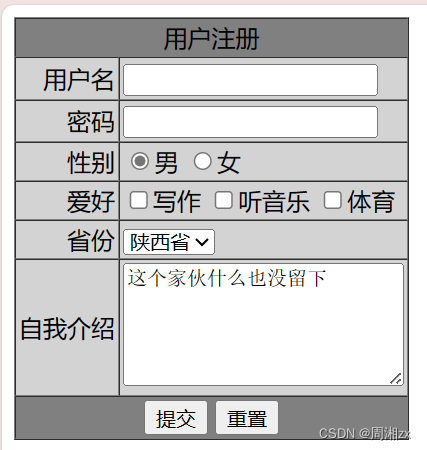
web(HTML之表单练习)
使用HTML实现该界面: 要求如下: 用户名为文本框,名称为 UserName,长度为 15,最大字符数为 20。 密码为密码框,名称为 UserPass,长度为 15,最大字符数为 20。 性别为两个单选按钮&a…...

通过对象轮换实现 LRU 缓存结构
文章目录 通过两个对象轮换,按照是否访问实现内容长久保存rollup 的缓存实现 export default function (max) { //max 缓存容量var num, curr, prev;var limit max || 1;function keep(key, value) {if (num > limit) {prev curr; // 超过容量时当前对象变成缓…...
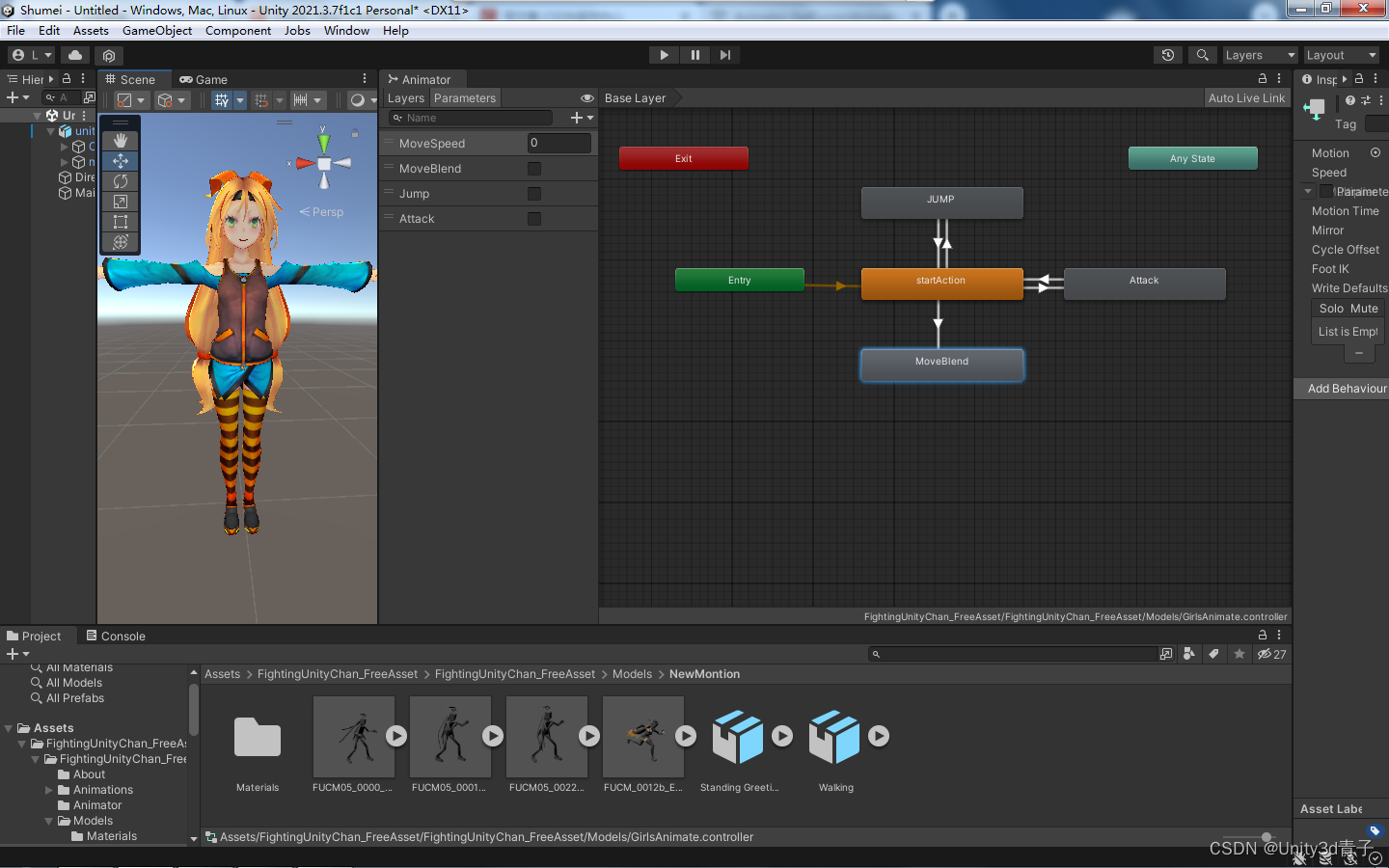
【Unity动画】综合案例完结-控制角色动作播放+声音配套
这个案例实现的动作并不复杂,主要包含一个 跳跃动作、攻击动作、还有一个包含三个动画状态的动画混合树。然后设置三个参数来控制切换。 状态机结构如下: 完整代码 using System.Collections; using System.Collections.Generic; using UnityEngine;pu…...
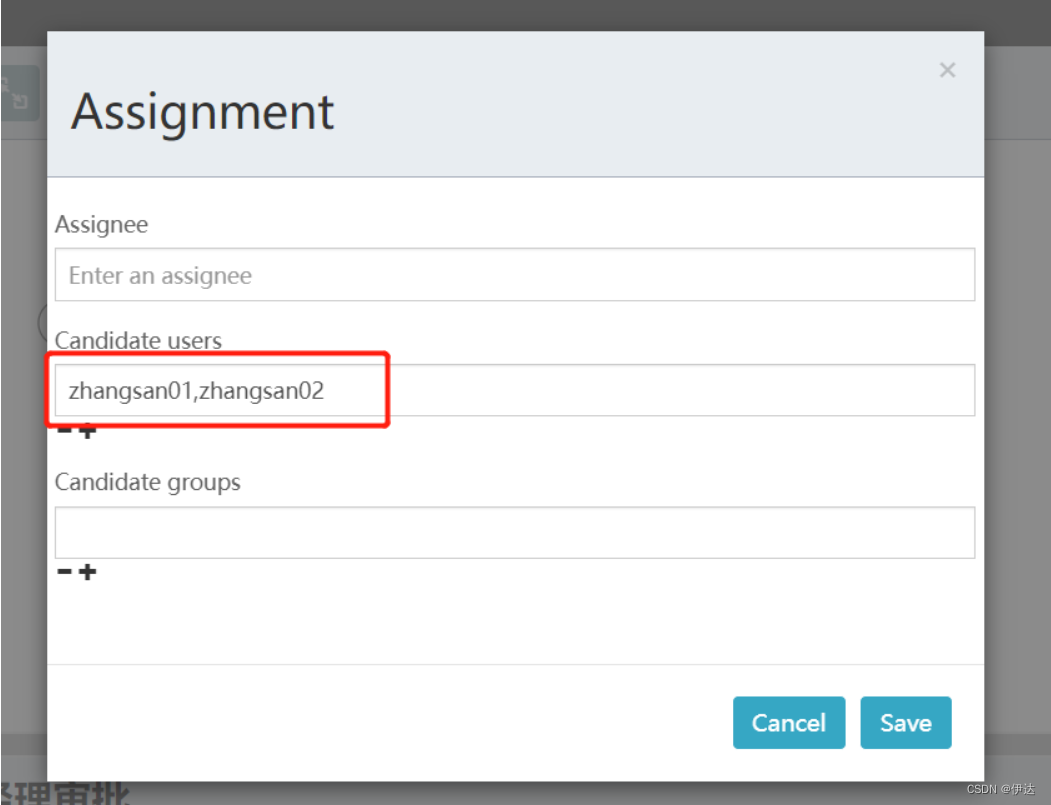
【工作流Activiti】任务组
1、Candidate-users候选人 1.1、需求 在流程定义中在任务结点的assignee固定设置任务负责人,在流程定义时将参与者固定设置在.bpmn文件中,如果要临时变更任务负责人则需要修改流程定义,系统扩展性很差,针对这种情况,我…...
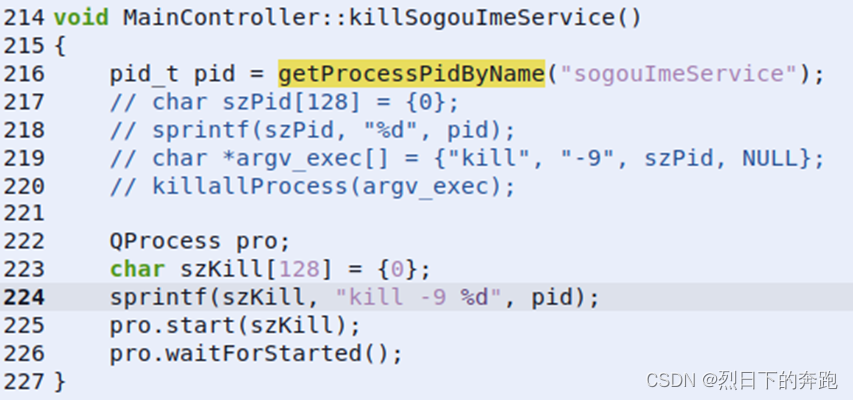
桌面概率长按键盘无法连续输入问题
问题描述:概率性长按键盘无法连续输入文本 问题定位: 系统按键流程分析 图一 系统按键流程 按键是由X Server接收的,这一点只要明白了X Window的工作机制就不难理解了。X Server在接收到按键后,会转发到相应程序的窗口中。在窗…...
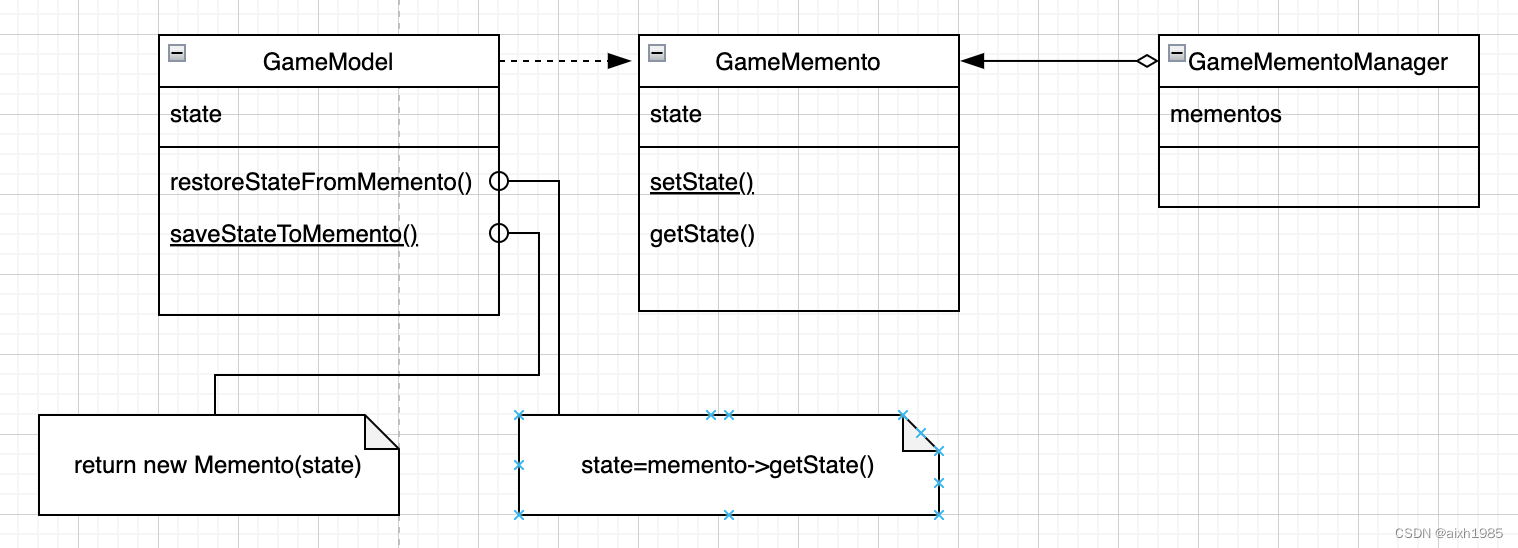
用23种设计模式打造一个cocos creator的游戏框架----(十九)备忘录模式
1、模式标准 模式名称:备忘录模式 模式分类:行为型 模式意图:在不破坏封装性的前提下捕获一个对象的内部状态,并在对象之外保存这个状态。这样以后就可以将对象恢复到原先保存的状态 结构图: 适用于: …...

动手学深度学习-自然语言处理-预训练
词嵌入模型 将单词映射到实向量的技术称为词嵌入。 为什么独热向量不能表达词之间的相似性? 自监督的word2vec。 word2vec将每个词映射到一个固定长度的向量,这些向量能更好的表达不同词之间的相似性和类比关系。 word2vec分为两类,两类…...
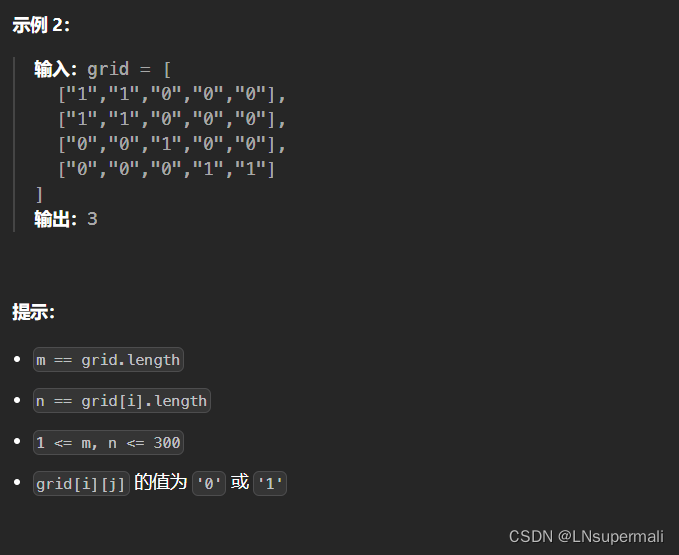
力扣200. 岛屿数量(java DFS解法)
Problem: 200. 岛屿数量 文章目录 题目描述思路解题方法复杂度Code 题目描述 思路 该问题可以归纳为一类遍历二维矩阵的题目,此类中的一部分题目可以利用DFS来解决,具体到本题目: 1.我们首先要针对于二维数组上的每一个点,尝试展…...
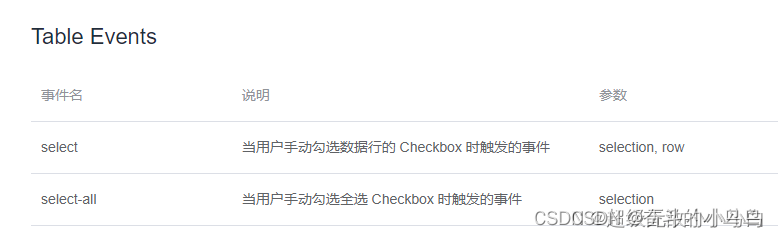
解决el-table组件中,分页后数据的勾选、回显问题?
问题描述: 1、记录一个弹窗点击确定按钮后,table列表所有勾选的数据信息2、再次打开弹窗,回显勾选所有保存的数据信息3、遇到的bug:切换分页,其他页面勾选的数据丢失;点击确认只保存当前页的数据࿱…...

OpenCart安全审计实战:静态代码扫描与核心漏洞修复指南
1. 项目概述与核心价值最近在整理一个基于OpenCart的电商项目时,客户提出了一个非常具体且关键的需求:需要对整个系统的安全性进行一次全面的审计。这不仅仅是运行一个自动化扫描工具那么简单,客户希望我们能深入代码层面,检查是否…...

Applite:用图形化界面轻松管理Mac软件的终极解决方案
Applite:用图形化界面轻松管理Mac软件的终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Mac上繁琐的软件管理而烦恼吗?Applite作为一…...

GPU内存优化:深度学习检查点技术原理与实践
1. GPU内存优化:深度学习训练中的检查点技术解析在训练现代深度神经网络时,GPU内存限制往往成为制约模型规模扩展的关键瓶颈。以典型的VGG-19模型为例,当批量大小设置为256时,仅正向传播阶段就需要消耗超过20GB的显存,…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...

Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 [特殊字符]
Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 🚀 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款革命性的开源3D重…...

借助PD协议分析仪洞悉Type-C充电握手全流程
1. 为什么需要PD协议分析仪? Type-C接口如今已经成为手机、笔记本等设备的标配,但很多用户都遇到过这样的尴尬:买了个第三方充电器,插上设备后要么完全没反应,要么只能以5V慢充。这背后往往是因为PD(Power …...

终极音乐解锁指南:3步免费解锁任何加密音乐文件
终极音乐解锁指南:3步免费解锁任何加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://git…...

ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成
ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 想要在有限硬件条件下实现专业级AI视频生成吗?ComfyUI-Fram…...

Stata 数据处理实战:时间序列数据的日期转换与聚合
1. 时间序列数据处理的常见痛点 刚接触时间序列分析的朋友们,经常会遇到这样的困扰:从Excel导入的数据明明是日期格式,到了Stata里却变成了看不懂的字符;想按周汇总销售数据,却发现系统根本不认识"2023-W15"…...

如何免费获取Book118文档?这个Java工具让你轻松下载完整PDF
如何免费获取Book118文档?这个Java工具让你轻松下载完整PDF 【免费下载链接】book118-downloader 基于java的book118文档下载器 项目地址: https://gitcode.com/gh_mirrors/bo/book118-downloader 你是否曾经在Book118网站上找到了一份急需的学习资料&#x…...