ElasticSearch学习篇8_Lucene之数据存储(Stored Field、DocValue、BKD Tree)
前言
Lucene全文检索主要分为索引、搜索两个过程,对于索引过程就是将文档磁盘存储然后按照指定格式构建索引文件,其中涉及数据存储一些压缩、数据结构设计还是很巧妙的,下面主要记录学习过程中的StoredField、DocValue以及磁盘BKD Tree的一些相关知识。
参考:
- https://juejin.cn/post/6978437292549636132
- https://juejin.cn/user/2559318800998141/posts
- Lucene 原理与代码分析完整版.pdf
- https://lucene.apache.org/core/9_9_0/core/org/apache/lucene/codecs/lucene99/package-summary.html#package.description
- 美团外卖搜索基于 Elasticsearch 的优化实践
目录
- Lucene数据分类
- Lucene字段存储
1、Lucene数据分类
在Lucene中索引数据存储的逻辑层次有多个层次,从大到小依次是
- index:索引代表了一类数据的完整存储
- segment: 一个索引可能有一个或者多个段构成
- doc: segment中存储的是一篇一篇的文档doc,每个segment是一个doc的集合
- field: 每个doc都有多个field构成,filed才包含了具体的文本,类似于一个json对象的一个属性
- term: 每个field的值可以进行分词,进而得到多个term,term是最基本的单元,每个field可以保存自己的词向量,用来计算搜索相似度
按照数据的维度整个Lucene把需要处理的数据分为这么几类
- PostingList,倒排表,也就是term->[doc1, doc3, doc5]这种倒排索引数据
- BlockTree, 从term和PostingList的映射关系,这种映射一般都用FST这种数据结构来表示,这种数据结构其实是一种树形结构,类似于Tire树,所以Lucene这里就叫BlockTree, 其实我更习惯叫它TermDict。
- StoredField ,一般类型的field原始数据存储。
- DocValue 键值数据,这种数据主要用于数值、日期类型的field,是用来加速对字段的排序、筛选的,列式存储。
- TermVector词向量信息,主要记一个不同term的全局出现频率等信息,用于score,如搜索的str会被分为一个个term,然后会被转为指定维度的向量,存储文档维护索引会根据当前文档、所有文档中term出现的频率以得到一个当前term的权重创建一个对应的指定维度的向量,然后就计算查询相关性score。
- Norms用来存储Normalisation信息, 比如给某些field加权之类的。
- PointValue 用来加速 range Query的信息。
一个段索引维护的数据,Lucene9_9_0版本https://lucene.apache.org/core/9_9_0/core/org/apache/lucene/codecs/lucene99/package-summary.html#package.description
- Segment info. This contains metadata about a segment, such as the number of documents, what files it uses, and information about how the segment is sorted。其中包含有关片段的元数据,例如文档数量、它使用的文件以及有关片段排序方式的信息
- Field names. This contains metadata about the set of named fields used in the index.包含文档fields的元数据以及名称。
- Stored Field values. This contains, for each document, a list of attribute-value pairs, where the attributes are field names. These are used to store auxiliary information about the document, such as its title, url, or an identifier to access a database. The set of stored fields are what is returned for each hit when searching. This is keyed by document number.以文档ID作为key,存储当前文档的fields键值对。
- Term dictionary. A dictionary containing all of the terms used in all of the indexed fields of all of the documents. The dictionary also contains the number of documents which contain the term, and pointers to the term’s frequency and proximity data.包含所有文档的所有索引字段中使用的所有term的字典。该词典还包含包含该term的文档数量,以及指向该术语的频率和邻近数据的指针。
- Term Frequency data. For each term in the dictionary, the numbers of all the documents that contain that term, and the frequency of the term in that document, unless frequencies are omitted (IndexOptions.DOCS)。term在当前文档出现的频率以及在全部文档出现的频率,主要用于score得分,比如term在当前文档出现的频率最高,在所有文档出现的频率最低,那么搜索该term在该文档中搜索得分高。
- Term Proximity data. For each term in the dictionary, the positions that the term occurs in each document. Note that this will not exist if all fields in all documents omit position data。term出现在所有文档的位置,可省略。
- Normalization factors. For each field in each document, a value is stored that is multiplied into the score for hits on that field.计算相关性score的时候可为某些field字段乘以一个系数。
- Term Vectors. For each field in each document, the term vector (sometimes called document vector) may be stored. A term vector consists of term text and term frequency. To add Term Vectors to your index see the Field constructors。每一个文档的每一个field会有一个term向量,主要根据term出现的频率计算出来,用于搜索的score分值计算。
- TextField: Reader or String indexed for full-text search。用于全文搜索。
- StringField: String indexed verbatim as a single token
- IntPoint: int indexed for exact/range queries.
- LongPoint: long indexed for exact/range queries.
- FloatPoint: float indexed for exact/range queries.
- DoublePoint: double indexed for exact/range queries.
- SortedDocValuesField: byte[] indexed column-wise for sorting/faceting,按列索引,用于排序
- SortedSetDocValuesField: SortedSet<byte[]> indexed column-wise for sorting/faceting
- NumericDocValuesField: long indexed column-wise for sorting/faceting
- SortedNumericDocValuesField: SortedSet indexed column-wise for sorting/faceting
- StoredField: Stored-only value for retrieving in summary results。仅存储值。
- Per-document values. Like stored values, these are also keyed by document number, but are generally intended to be loaded into main memory for fast access. Whereas stored values are generally intended for summary results from searches, per-document values are useful for things like scoring factors.类似StoreField,可以更快加载到内存访问,用于搜索的摘要结果,但是每个文档的值对于评分因素有很大的影响。
- Live documents. An optional file indicating which documents are live.一个可选文件,指定哪些文档是实时的。主要用于段数据删除时候,在段外部维护一个状态记录段的最新状态。
- Point values. Optional pair of files, recording dimensionally indexed fields, to enable fast numeric range filtering and large numeric values like BigInteger and BigDecimal (1D) and geographic shape intersection (2D, 3D).可选的一对文件,记录维度索引字段,以启用快速数值范围过滤和大数值,例如 BigInteger 和 BigDecimal (1D) 以及地理形状交集(2D、3D)。
- Vector values. The vector format stores numeric vectors in a format optimized for random access and computation, supporting high-dimensional nearest-neighbor search.
按照数据存储的方向维度可以分为
- 一般存储形式:按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档 (Document) –> 域(Field) –> 词(Term) ,层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息。如StoredFileld、DocValue存储形式。
- 反向存储形式:如倒排索引(PostingList + BlockTree)数据存储形式。
2、Lucene存储文件
一个索引相关的存储文件对应一个文件夹,一个段的所有文件都具有相同的名称和不同的扩展名。扩展名对应于下面描述的不同文件格式。当使用复合文件格式时(小段的默认格式),这些文件(段信息文件、锁定文件和文件夹文档文件除外)将折叠为单个.cfs文件。
- Segments info:多个段文件名永远不会重复使用。也就是说,当任何文件保存到目录时, 以前从未使用过的文件名。这是使用简单的生成方法实现的。比如说, 第一个段文件是segments_1,然后是segments_2,依此类推。生成是连续的长 以字母数字(以36为基数)形式表示的整数。主要保存段的元信息,segments_N 保存了此索引包含多少个段,每个段包含多少篇文档,实际的数据信息保存在field和词中的。
- Write.lock:写锁默认存储在索引目录中,名为“write.lock”。如果锁目录与索引目录不同,则写锁将被命名为“XXXX-write.lock”,其中“”是从索引目录的完整路径导出的唯一前缀。如果存在此文件,则表示编写者正在修改索引(添加或删除文档)。这个锁文件确保一次只有一个writer修改索引。
- Fields、Field Index 、Field Data:This is keyed by document number.也就是上面说的一般存储形式,保存了此段包含了多少个field,每个field的名称及索引方式以及数据。
- Term Vector Index、Term Vector Data:当你将字段设置为存储Term Vector时,Lucene会提取出该字段中每个词项的相关信息,并将其存储到倒排索引中。这样可以在搜索时不仅找到包含关键词的文档,还能得知每个关键词在文档中的频率和位置。因为不仅要根据倒排索引找到文档ID,还需要计算文档的相关性得分,会存储当前文档全部term的频率、位置信息,为了下一步也就是根据文档内全部的term的频率信息计算下面的vector value。
- Vector values:根据每个文档的所有term vector data数据,为每个文档计算出一个指定的相关性vector values,然后在跟query vevtor计算相关性score。

3、Lucene数据存储
ps:学习分析Lucene版本为9_9_0
3.1、StoredField
In Lucene, fields may be stored, in which case their text is stored in the index literally, in a non-inverted manner. Fields that are inverted are called indexed. A field may be both stored and indexed.
保存字段属性信息的,过程主要关注各数据类型是如何存储的? 最终写入索引是如何压缩的?Lucene的field数据类型有下面几大类
- int
- long
- Float
- Double
- String
- bytes
3.1.1、int
// TODO
3.1.2、long
3.1.3、Float
3.1.4、Double
3.1.5、String
3.1.6、bytes
3.2、DocValue
用于倒排查找的数据,加速筛选和排序的,主要关注
- DocValue 的类型有哪些?SortedNumericDocValue?SortedSet?应用场景等。
- DocValue是如何存储的?
相关文章:
ElasticSearch学习篇8_Lucene之数据存储(Stored Field、DocValue、BKD Tree)
前言 Lucene全文检索主要分为索引、搜索两个过程,对于索引过程就是将文档磁盘存储然后按照指定格式构建索引文件,其中涉及数据存储一些压缩、数据结构设计还是很巧妙的,下面主要记录学习过程中的StoredField、DocValue以及磁盘BKD Tree的一些…...

ROS机器人入门
http://www.autolabor.com.cn/book/ROSTutorials/ 1、ROS简介 ROS 是一个适用于机器人的开源的元操作系统。其实它并不是一个真正的操作系统,其 底层的任务调度、编译、寻址等任务还是由 Linux 操作系统完成,也就是说 ROS 实际上是运 行在 Linux 上的次级…...

30. 深度学习进阶 - 池化
Hi,你好。我是茶桁。 上一节课,我们详细的学习了卷积的原理,在这个过程中给大家讲了一个比较重要的概念,叫做input channel,和output channel。 当然现在不需要直接去实现, 卷积的原理PyTorch、或者TensorFlow什么的…...

工业应用新典范,飞凌嵌入式FET-D9360-C核心板发布!
来源:飞凌嵌入式官网 当前新一轮科技革命和产业变革突飞猛进,工业领域对高性能、高可靠性、高稳定性的计算需求也在日益增长。为了更好地满足这一需求,飞凌嵌入式与芯驰科技(SemiDrive)强强联合,基于芯驰D9…...
Webrtc 学习交流
花了几周的时间研究了一下webrtc ,并开发了一个小项目,用来点对点私密聊天 交流传输文件等…后续会继续扩展其功能。 体验地址,大狗子的ID,我在线时可以连接测试到我 f3e0d6d0-cfd7-44a4-b333-e82c821cd927 项目特点 除了交换信令与stun 没…...

华为云之轻松搭建 Nginx 静态网站
华为云之轻松搭建 Nginx 静态网站 一、本次实践介绍1. 本次实践目的2. 本次实践环境 二、ECS弹性云服务器介绍三、准备实践环境1. 预置环境2. 查看ECS服务器的账号密码信息3. 登录华为云4. 远程登录ECS服务器 四、安装配置 Nginx1. 安装nginx2. 启动nginx3. 浏览器中访问nginx服…...

【pytorch】图像运行过程中,保证梯度情况下变换
部分操作是危险的,会中断梯度流。 self.patch_transformer(adv_patch, lab_batch, img_size, do_rotateTrue, rand_locFalse)p_img_batch self.patch_applier(img_batch, adv_batch_t) # torch.Size([56, 3, 329, 416])可行危险操作 torch.clamp(adv_batch, 0…...
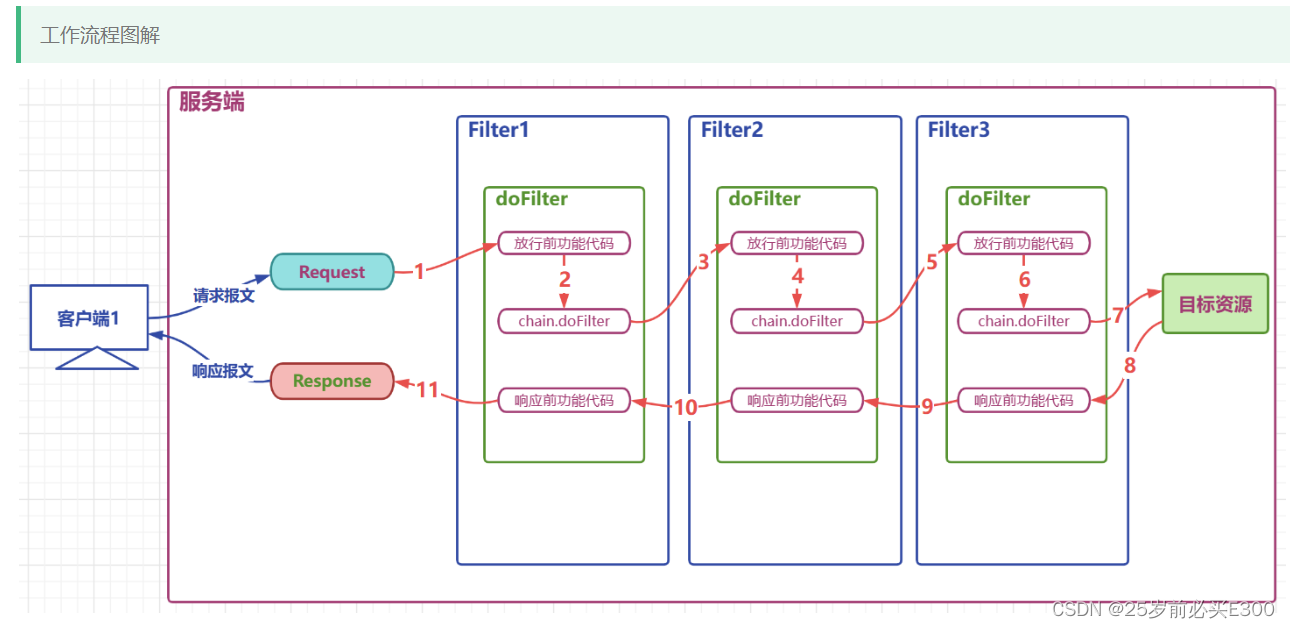
学习Java第70天,过滤器Filter简介
过滤器概述 Filter,即过滤器,是JAVAEE技术规范之一,作用目标资源的请求进行过滤的一套技术规范,是Java Web项目中最为实用的技术之一 Filter接口定义了过滤器的开发规范,所有的过滤器都要实现该接口 Filter的工作位置是项目中所有目标资源之前,容器在创建HttpServletRequest和…...
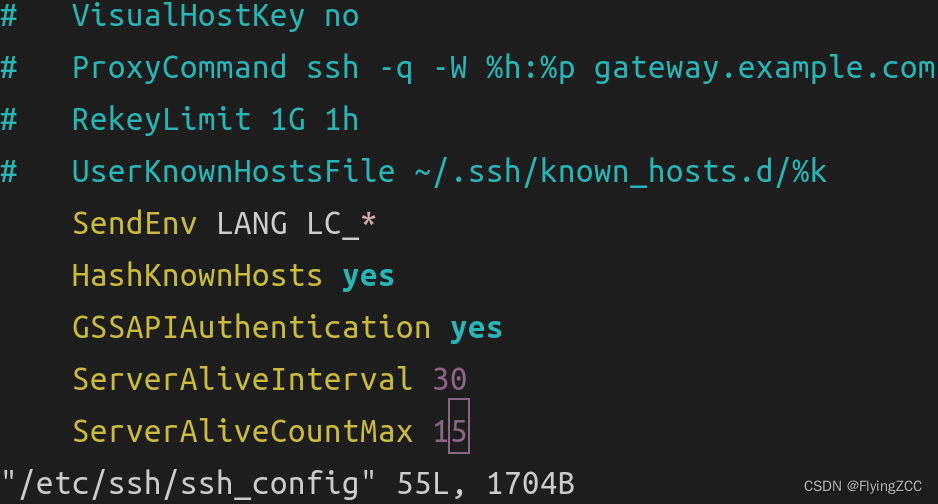
Ubuntu Desktop 22.04 设置 ssh 超时时间
Ubuntu Desktop 22.04 使用 ssh 连接服务器时,发现一段时间不操作就会自动断开连接,解决方法如下: 打开 /etc/ssh/ssh_config 文件: sudo vim /etc/ssh/ssh_config在文件最后添加: # ssh 客户端会每隔 30 秒发送一个…...

【微服务】Spring Aop原理深入解析
目录 一、前言 二、aop概述 2.1 什么是AOP 2.2 AOP中的一些概念 2.2.1 aop通知类型 2.3 AOP实现原理 2.3.1 aop中的代理实现 2.4 静态代理与动态代理 2.4.1 静态代理实现 三、 jdk动态代理与cglib代理 3.1 jdk动态代理 3.1.1 jdk代理示例 3.1.2 jdk动态代理模拟实现…...

Spring Boot JSON中文文档
本文为官方文档直译版本。原文链接 Spring Boot JSON中文文档 引言Jackson自定义序列化器和反序列化器混入 GsonJSON-B 引言 Spring Boot 提供与三个 JSON 映射库的集成: GsonJacksonJSON-B Jackson 是首选的默认库。 Jackson Spring-boot-starter-json 提供了…...
)
Flink系列之:State Time-To-Live (TTL)
Flink系列之:State Time-To-Live TTL 一、TTL二、TTL实现代码三、过期状态的清理 一、TTL Flink的TTL(Time-To-Live)是一种数据过期策略,用于指定数据在流处理中的存活时间。TTL可以应用于Flink中的状态或事件时间窗口࿰…...

数据结构(Chapter Two -01)—线性表及顺序表
2.1 线性表 线性表是具有相同数据类型的n个数据元素的有限序列。第一个元素为表头元素,最后一个元素为表尾元素。除第一个元素,每个元素有且仅有一个直接前驱。除最后一个元素,每个元素都仅有一个直接后继。 其中线性表包括以下(…...

【刷题笔记1】
笔记1 string s;while(cin>>s);cout<<s.length()<<endl;输入为hello nowcoder时,输出为8 (nowcoder的长度) 2.字符串的输入(有空格) string a;getline(cin, a);cout<<a<<endl;输入为ABCabc a 输出为ABCabc a …...

视频数据卡设计方案:120-基于PCIe的视频数据卡
一、产品概述 基于PCIe的一款视频数据收发卡,并通过PCIe传输到存储计算服务器,实现信号的采集、分析、模拟输出,存储。 产品固化FPGA逻辑,实现PCIe的连续采集,单次采集容量2GB,开源的PCIe QT客…...
Windows使用VNC Viewer远程桌面Ubuntu【内网穿透】
文章目录 前言1. ubuntu安装VNC2. 设置vnc开机启动3. windows 安装VNC viewer连接工具4. 内网穿透4.1 安装cpolar【支持使用一键脚本命令安装】4.2 创建隧道映射4.3 测试公网远程访问 5. 配置固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址5.3 测试…...
javascript 数组处理的两个利器: `forEach` 和 `map`(上)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
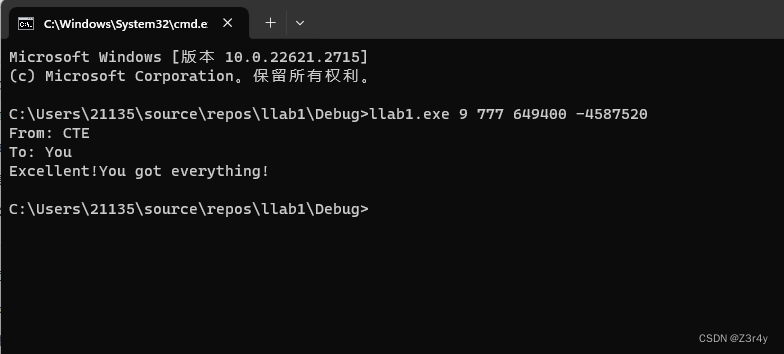
【C语言】SCU安全项目1-FindKeys
目录 前言 命令行参数 16进制转字符串 extract_message1 process_keys12 extract_message2 main process_keys34 前言 因为这个学期基本都在搞CTF的web方向,C语言不免荒废。所幸还会一点指针相关的知识,故第一个安全项目做的挺顺利的,…...

IDA pro软件 如何修改.exe小程序打开对话框显示的文字?
环境: Win10 专业版 IDA pro Version 7.5.201028 .exe小程序 问题描述: IDA pro软件 如何修改.exe小程序打开对话框显示的文字? 解决方案: 一、在IDA Python脚本中编写代码来修改.rdata段中的静态字符串可以使用以下示例代码作为起点(未成功) import idc# 定义要修…...
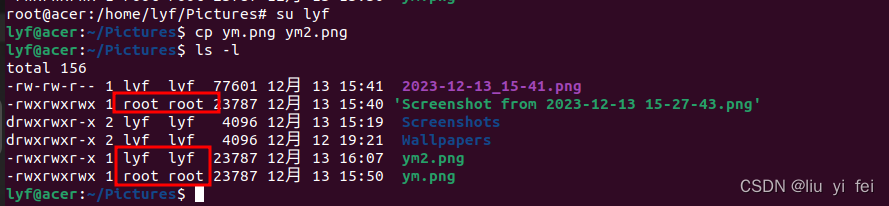
Ubuntu22.04切换用户
一、只有一个用户时没有切换用户菜单项 1、用户信息 cat /etc/passwd 2、系统菜单 二、添加用户 添加新用户ym,全名yang mi 三、有两个及以上的用户时出现切换用户菜单项 1、用户信息 cat /etc/passwd 2、系统菜单 四、切换用户 1、点击上图中Switch User …...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...
基于PWM舵机与NeoPixel的万圣节互动蝙蝠制作全解析
1. 项目概述:一个会动的万圣节蝙蝠又快到万圣节了,想给家里的装饰来点不一样的“活物”吗?每年都摆静态的南瓜灯和蜘蛛网,总觉得少了点气氛。今年我琢磨着,不如自己动手做一个能扑腾翅膀、眼睛还会发光的机械蝙蝠&…...

MCP服务器部署模板:容器化与CI/CD自动化实践指南
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或维护一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且对如何将其优雅、可靠地部署到生产环境感到头疼,那么你很可能已经…...

为AI智能体设计的任务管理后端:构建标准化、机器友好的任务元模型
1. 项目概述:一个为AI而生的待办清单最近在折腾各种AI工具链和自动化流程时,我遇到了一个挺普遍的问题:如何让AI助手,比如ChatGPT、Claude或者本地部署的大语言模型,更好地理解并管理我手头一堆零散、动态的任务&#…...

大语言模型并行推理技术Hogwild! Inference解析
1. 大语言模型并行推理的技术挑战在传统的大语言模型推理过程中,文本生成采用的是严格的自回归方式,即每个token的生成都依赖于之前所有token的输出。这种串行模式虽然保证了生成的连贯性,但也带来了显著的性能瓶颈。以1750亿参数的GPT-3为例…...