2023 亚马逊云科技 re:Invent 大会探秘:Aurora 无限数据库的突破性应用

文章目录
- 一、前言
- 二、Amazon Aurora 无限数据库
- 2.1 亚马逊云科技数据库产品发展历程
- 2.2 什么是 Amazon Aurora Limitless Database(无限数据库)
- 2.3 Amazon Aurora Limitless Database 设计架构
- 2.4 Amazon Aurora Limitless Database 分片功能
- 2.5 使用 Amazon Aurora Limitless Database 示例
- 2.5.1 创建 customer 分片表
- 2.5.2 创建 order 分片表
- 2.5.3 创建 tax_rate 分片表
- 三、在亚马逊云科技门户中创建 Amazon Aurora Limitless 数据库
- 四、文末总结
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道
一、前言
2023 年的亚马逊云科技 re:Invent 大会已于内华达州的拉斯维加斯盛大举行。在现今 2023 年该大会已经迎来了第 12 届。
在为期五天的大会里吸引了全球数万名观众和客户,共同深入探讨、学习并体验最新的云计算技术和行业趋势。作为亚马逊云科技每年一度的盛事,今年的re:Invent再次突显了该公司在云计算领域的领先地位和创新实力。此次盛会上,亚马逊云科技发布了一系列重要新品和解决方案,为全球客户带来了前所未有的科技盛宴。
而在今年的亚马逊 re:Invent 大会中,在关系型数据库方面,让我印象颇深的重磅发布是 Amazon Aurora Limitless Database (无限数据库)。

二、Amazon Aurora 无限数据库
在本博文开头我有提过,让我印象颇深的重磅发布是 Amazon Aurora Limitless Database (无限数据库),接下来让我们更加详细了解一下 Amazon Aurora Limitless Database (无限数据库)。
2.1 亚马逊云科技数据库产品发展历程
我们在详细介绍 Amazon Aurora Limitless Database(无限数据库)前,先了解一下亚马逊云科技数据库产品发展历程。

对于比较了解亚马逊云科技产品的小伙伴们应该不会陌生,亚马逊云科技拥有众多的数据库产品,针对不同的业务及功能需要,你可以选择不同的数据库产品。
而回顾亚马逊云科技关系型数据库 15 年的发展历程你会发现,数据库产品逐渐走向无,再从无走向了无限。
2009年推出:Amazon RDS(Relational Database Service)关系型数据库服务,支持多种关系型数据库引擎,如 MySQL、PostgreSQL、MariaDB、Oracle 和 Microsoft SQL Server。RDS 简化了数据库管理任务,提供了可扩展性和自动备份功能。
2014年推出:Amazon Aurora,是一种高性能、高可用性的关系型数据库引擎,与 MySQL 和 PostgreSQL 兼容。Aurora 的架构设计提供与商业数据库相媲美的性能,同时降低了成本。
2018年推出:Amazon Aurora Serverless,这项服务的推出是为了提供更加灵活和成本效益的数据库解决方案。相比于传统的数据库部署方式,Aurora Serverless 允许用户根据实际需求自动扩展数据库容量,从而降低了成本并提高了灵活性。用户无需管理底层的服务器或实例,而是根据实际数据库负载自动进行容量的扩展和缩减,这使得数据库更适应性更强。提供了数据库资源的无缝上下伸缩。
2018年推出:Amazon Aurora Limitless,通过自研的时钟同步,来实现高性能的分布式事务,提供了可以横向写扩展的分布式数据库。
2.2 什么是 Amazon Aurora Limitless Database(无限数据库)
Amazon Aurora Limitless Database(无限数据库)该数据库能够让你将 Amazon Aurora 集群扩展到每秒数百万次写入事务,并管理以 PB 计的数据量。借助这一新功能,你可以在 Aurora 上扩展关系型数据库工作负载,无需创建自定义应用逻辑或管理多个数据库。
Amazon Aurora Limitless Database(无限数据库)通过提供无服务器终端节点来轻松扩展你的关系型数据库工作负载,该节点会自动在多个 Amazon Aurora Serverless 实例之间分发数据和查询,并保持单个数据库的事务一致性。Amazon Aurora Limitless Database(无限数据库)提供分布式查询规划和事务管理等功能,消除了你创建自定义解决方案或管理多个数据库以进行扩展的需要。随着工作负载的增加,Amazon Aurora Limitless Database(无限数据库)会添加额外的计算资源,同时保持在指定预算范围内运行,因此无需为高峰时段进行配置,当需求低时,计算资源会自动缩减。
Amazon Aurora Limitless Database(无限数据库)目前仅在以下 Region 的 Amazon Aurora 与 PostgreSQL 兼容版本进行有限预览:
- 美国东部(俄亥俄州)
- 美国东部(弗吉尼亚北部)
- 美国西部(俄勒冈州)
- 亚太地区(东京)
- 欧洲(爱尔兰)
这里注意,现阶段只有 Aurora PostgreSQL 才支持,MySQL 版本暂时不支持。
2.3 Amazon Aurora Limitless Database 设计架构
Shards(分片) 是 Aurora PostgreSQL 数据库的实例,每个实例存储数据库的一部分数据,可实现并行处理,提高写入吞吐量。事务路由器负责管理数据库的分布式特性,并向数据库客户端呈现单一的数据库图像。
在 Aurora Limitless 的 DB Shard group 中具有两层架构,由多个数据库节点组成,包括事务路由器和分片。分片是 Aurora PostgreSQL 数据库实例,每个分片存储数据库的一部分数据,以实现并行处理以实现更高的写入吞吐量。
这些路由器维护有关数据存储位置的元数据,解析传入的SQL命令并将其发送到各个分片,聚合分片数据以向客户端返回单一结果,并管理分布式事务以确保整个分布式数据库的一致性。无限数据库架构中的所有节点均包含在一个数据库分片组中。数据库分片组具有单独的终端节点,提供访问无限数据库资源。
(查看清晰大图:右键图片新窗口打开后放大镜查看)
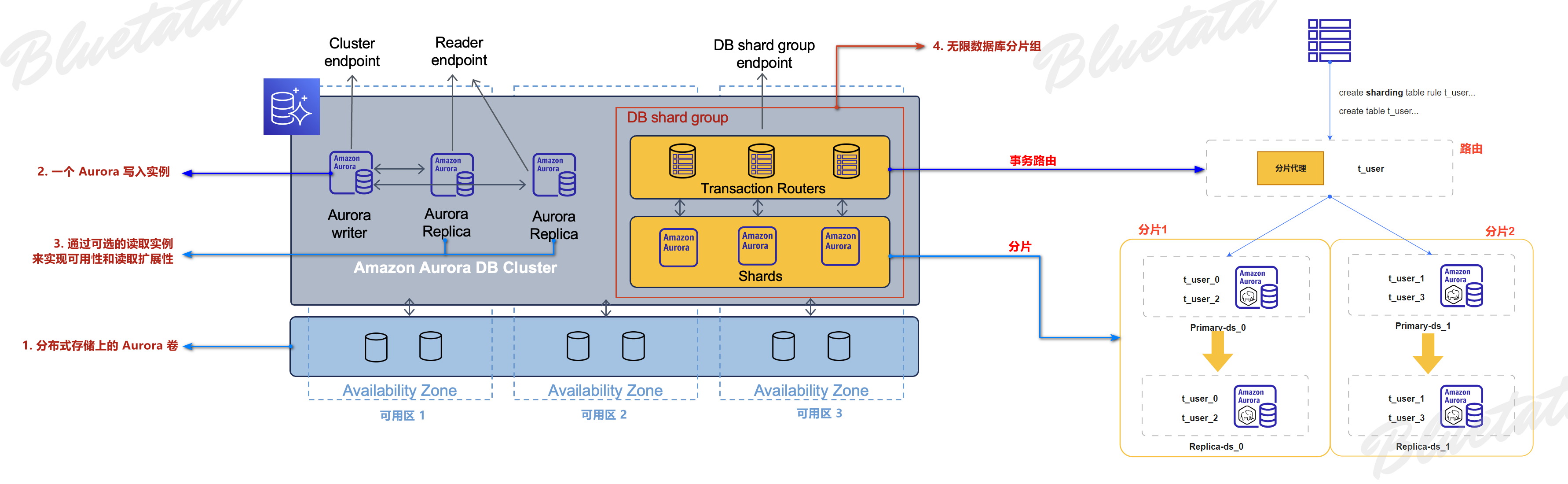
在上述架构图中,左侧是官方给出的 Amazon Aurora Limitless Database 设计架构图(点击这里),在这个标准的架构中,其中包括四个主要部分:
- 在分布式存储上的 Aurora 卷
- 一个 Aurora 写入实例
- 通过可选的读取实例来实现可用性和读取扩展性
- 在无限制数据库中引入了“分片组”的概念"
具体的详细处理流程已经在上述有说明;右侧架构可以认为是左侧架构图中黄色部分:数据库分片组内的放大架构,而这个架构非常类似于阿帕奇的 ShardingSphere(点击这里)。希望这个我后绘制的架构图,能够帮你更好的理解 Amazon Aurora Limitless Databas。
2.4 Amazon Aurora Limitless Database 分片功能
不知道你有没有使用过 Amazon Aurora Serverless v2,这个版本的 Aurora 支持多个可用区,并具备自动扩容功能。当你在 RDS 服务中选择创建 Aurora 的时候就能看到该选项(后文体验中也有标注)。
在这次 re:Invent 大会后,你是否对 Amazon Aurora Serverless v2 和 Amazon Aurora Limitless Database 之间有何不同进行过考虑,博主个人认为最大的差异就在于增加了分片功能,我们在上述的 Amazon Aurora Limitless 架构中也有提到。
Amazon Aurora Serverless v2 能够自动增减ACU(Aurora 容量单位)容量。但是,增加的上限为个 128 ACU。
想了解关于 Amazon Aurora ACU 的知识点可以 点击这里,本文不过多赘述。
这个128 ACU大概是亚马逊云科技物理服务器的最大值。到这里还不足以成为一个完全的无服务器服务。然而,Amazon Aurora Limitless Database 现在可以处理分片数据库。
这意味着当 ACU 数量超过128时,数据库可以分成 128 ACU 的主数据库加上附加数据库。换句话说,Amazon Aurora Limitless Database 非常有可能无上限地增加容量。
2.5 使用 Amazon Aurora Limitless Database 示例
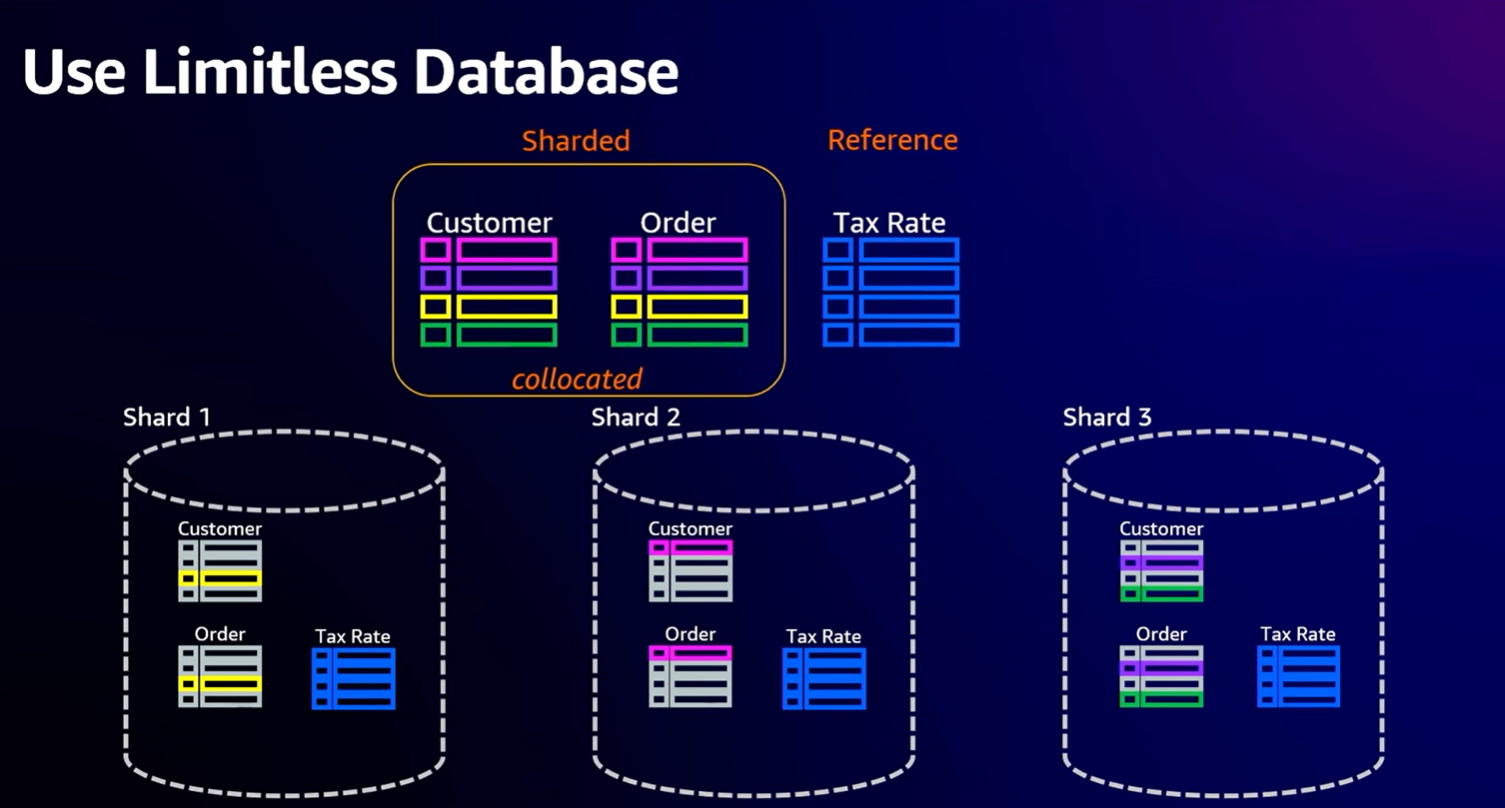
出于说明示例的目的,假设我们有一个客户表(Customer)、一个订单(Order)和一个税率表(Tax Rate)。将此分片后,你可以使用客户 ID 作为订单表中的分片键。连接客户表和订单表时,有相同键的数据很方便。每个分片上都有税率表作为参考表。
具体示例如下图所示:
2.5.1 创建 customer 分片表
在实际创建表时,现在引入了新概念:create table mode(创建表模式),并设置会话参数。
对于客户表(分片表),将 create table mode 设置为sharded,并指定cust_id作为分片键来创建表。
SET rds_aurora.limitless_create_table_mode='sharded';SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';CREATE TABLE customer (cust_id INT PRIMARY KEY NOT NULL,name TEXTemail VARCHAR(100));
2.5.2 创建 order 分片表
对于订单表,为分片表,同样将 create table mode 设置为sharded,并将分片键指定为cust_id,并且,我们将 collocate with 参数设置成我们刚才创建的customer 表。
SET rds_aurora.limitless_create_table_mode='sharded'; --可选项
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}'; --可选项SET rds_aurora.limitless_create_table_collocate_with='customer';CREATE TABLE order (order_id INT NOT NULL,cust_id INT NOT NULL,amount DOUBLE NOT NULL,tax_rate_id DOUBLE,PRIMARY KEY (order_id, cust_id)
);
注意:实际上,上面的三个SQL语句,表明我们将创建另一个分片表,它将与客户表(customer)放在同一个位置。因此两个表的所有数据将位于同一分片上,或者是具有相同分片键值的数据将位于同一分片上。
2.5.3 创建 tax_rate 分片表
最后的税率表是一个参考表,使用语法和上述类似,是将 create table mode 设置为reference。
从下面的语法中可以看到一方面limitless_create_table_mode的参数设置成了reference,而不是之前的sharded;另一方面创建 tax_rate 表的时候并没有指定分片键(limitless_create_table_shard_key)。所以 tax_rate 表和上述的客户和订单表不在同一个位置。
SET rds_aurora.limitless_create_table_mode='reference';CREATE TABLE tax_rate (tax_rate_id INT PRIMARY KEY NOT NULL,city TEXT NOT NULL,state TEXT,country TEXT NOT NULL,tax_rate DOUBLE NOT NULL
);-- 同时还支持直接创建标准的 Aurora 标准表。
SET rds_aurora.limitless_create_table_mode='standard';
除了 limitless_create_table_mode 设置成reference外,还支持直接创建标准的 Aurora 标准表,这也就意味着,这个标准表将与你的分片表和引用表位于同一个集群中。。
三、在亚马逊云科技门户中创建 Amazon Aurora Limitless 数据库
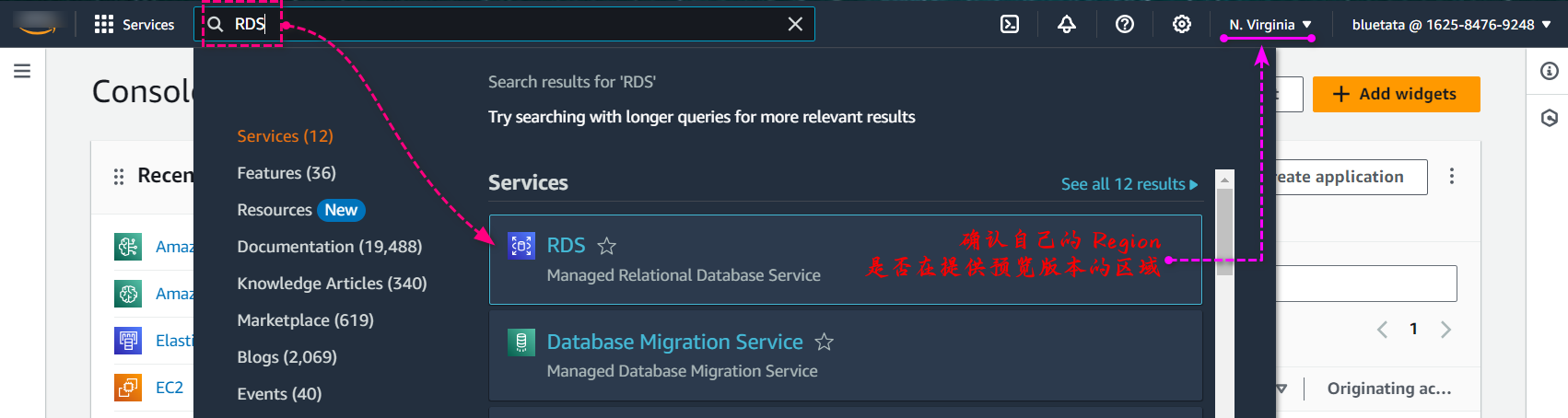
进入亚马逊门户首页,服务搜索框内,直接搜索RDS,注意文中开头有讲过 Amazon Aurora Limitless 数据库还是处于预览阶段,只有固定的几个 Region 中可以使用,所以需要确认自己的 Region。
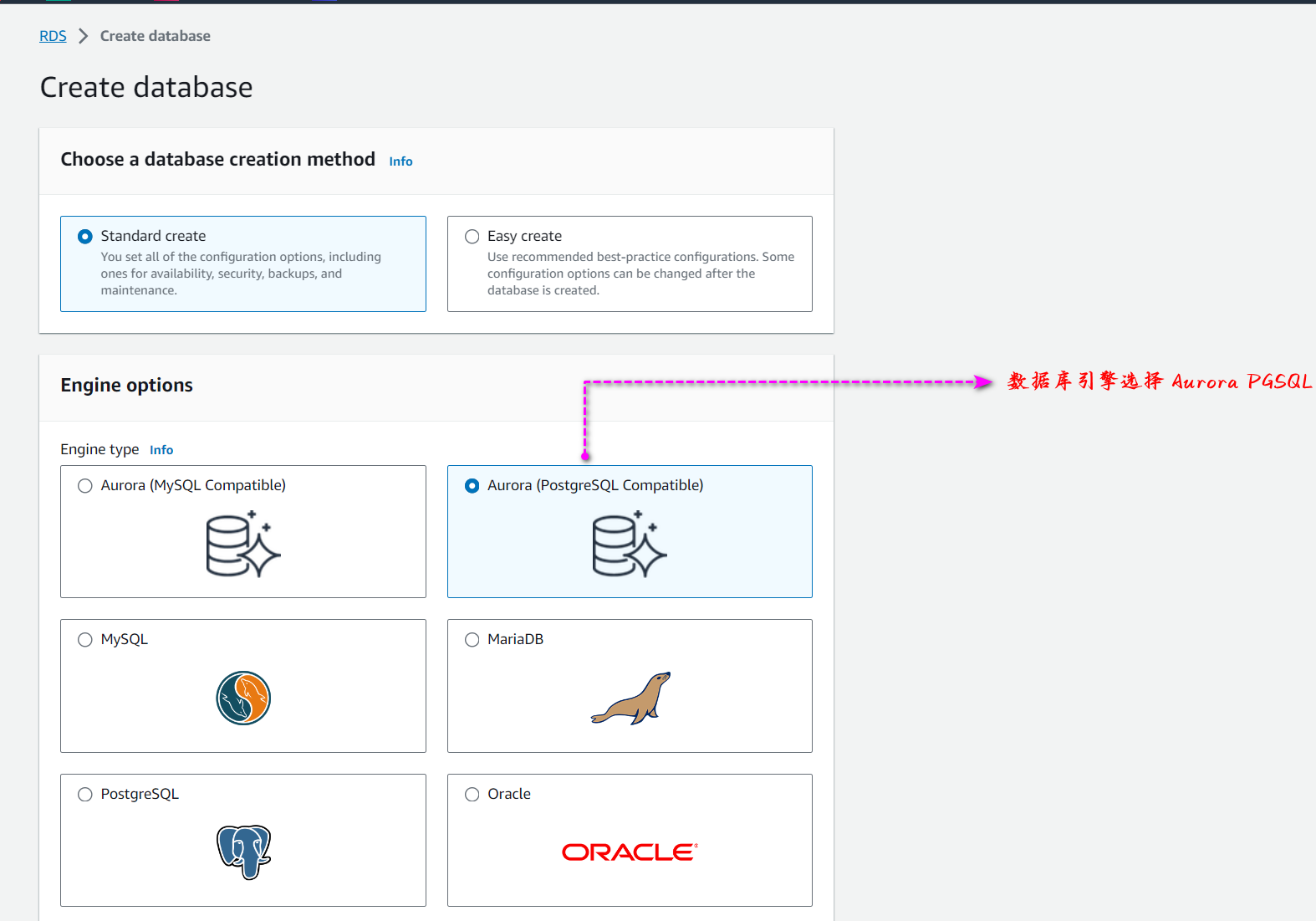
进入到创建数据库 RDS 界面后,选择 Aurora(PostgreSQL),因为现在 Amazon Aurora Limitless 数据库暂时只支持 PostgreSQL 版本,MySQL 和其他数据库暂时不支持。
进入到基础设置页面后,根据自身情况进行设置,如下图所示:
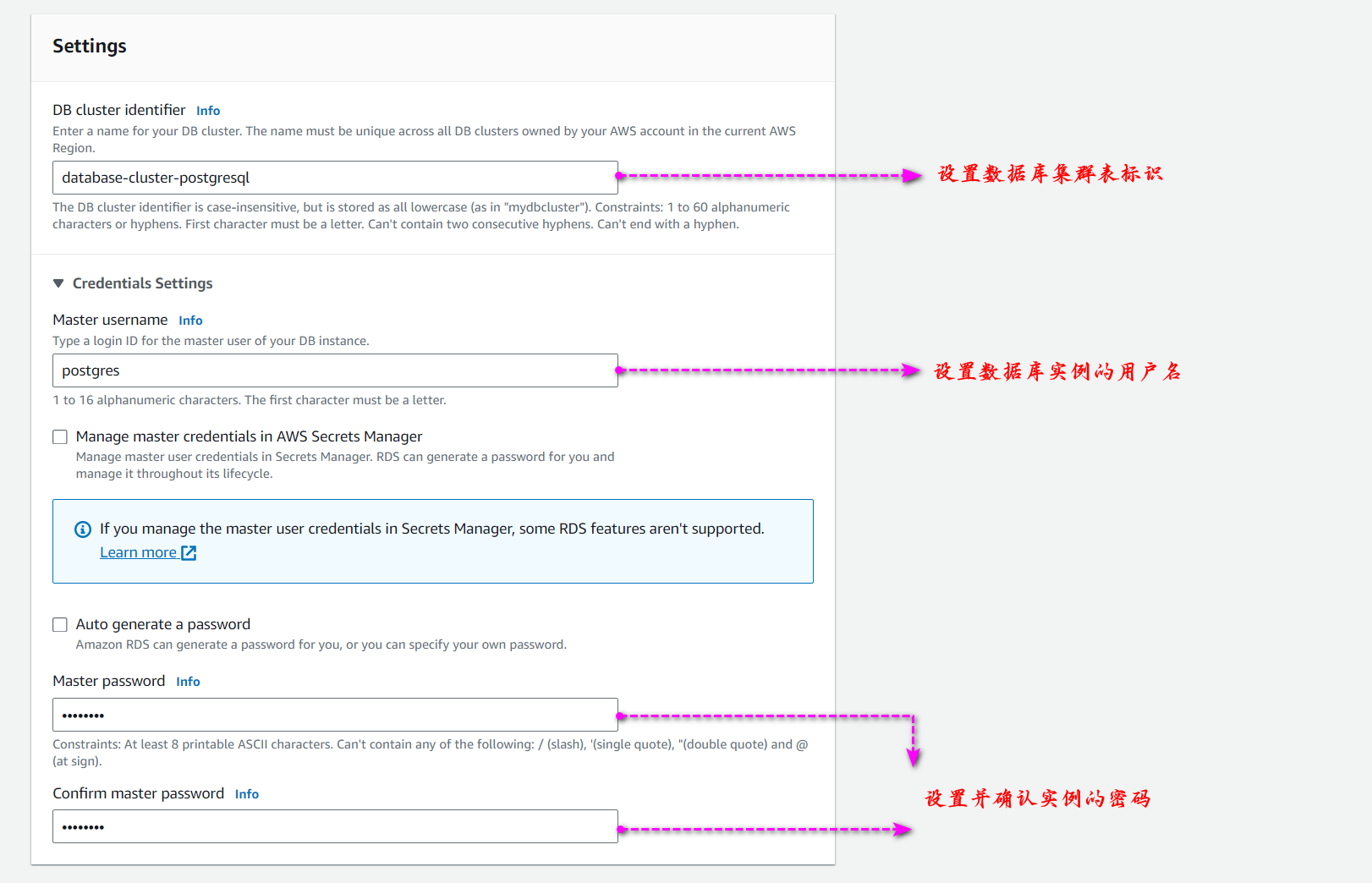
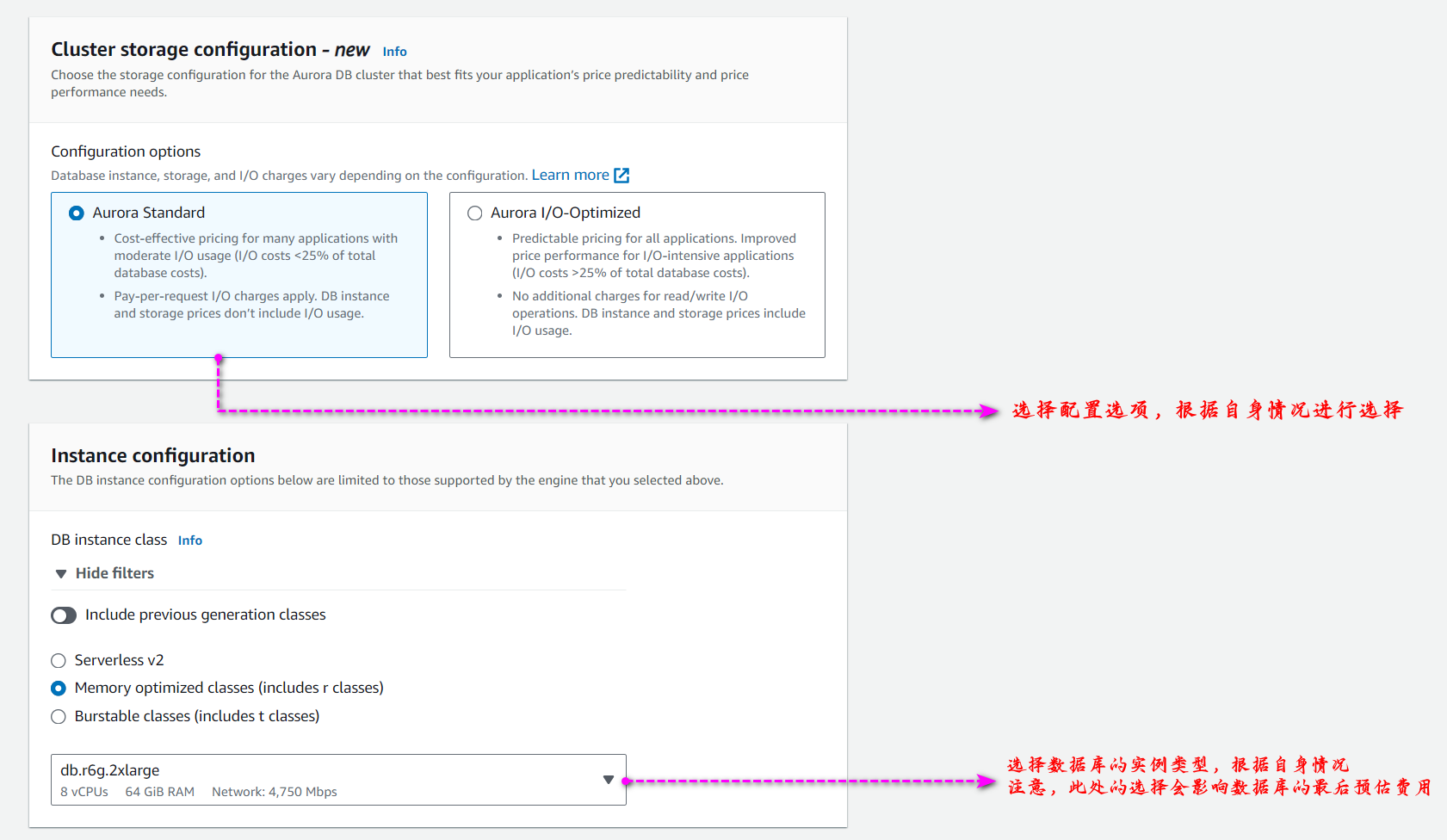
进入集群设置页面后,根据自身情况进行设置,我们之前在 3.4 Amazon Aurora Limitless Database 分片功能 章节中有提到多 AZ 集群的功能,在此处即可进行设置,如下图所示:
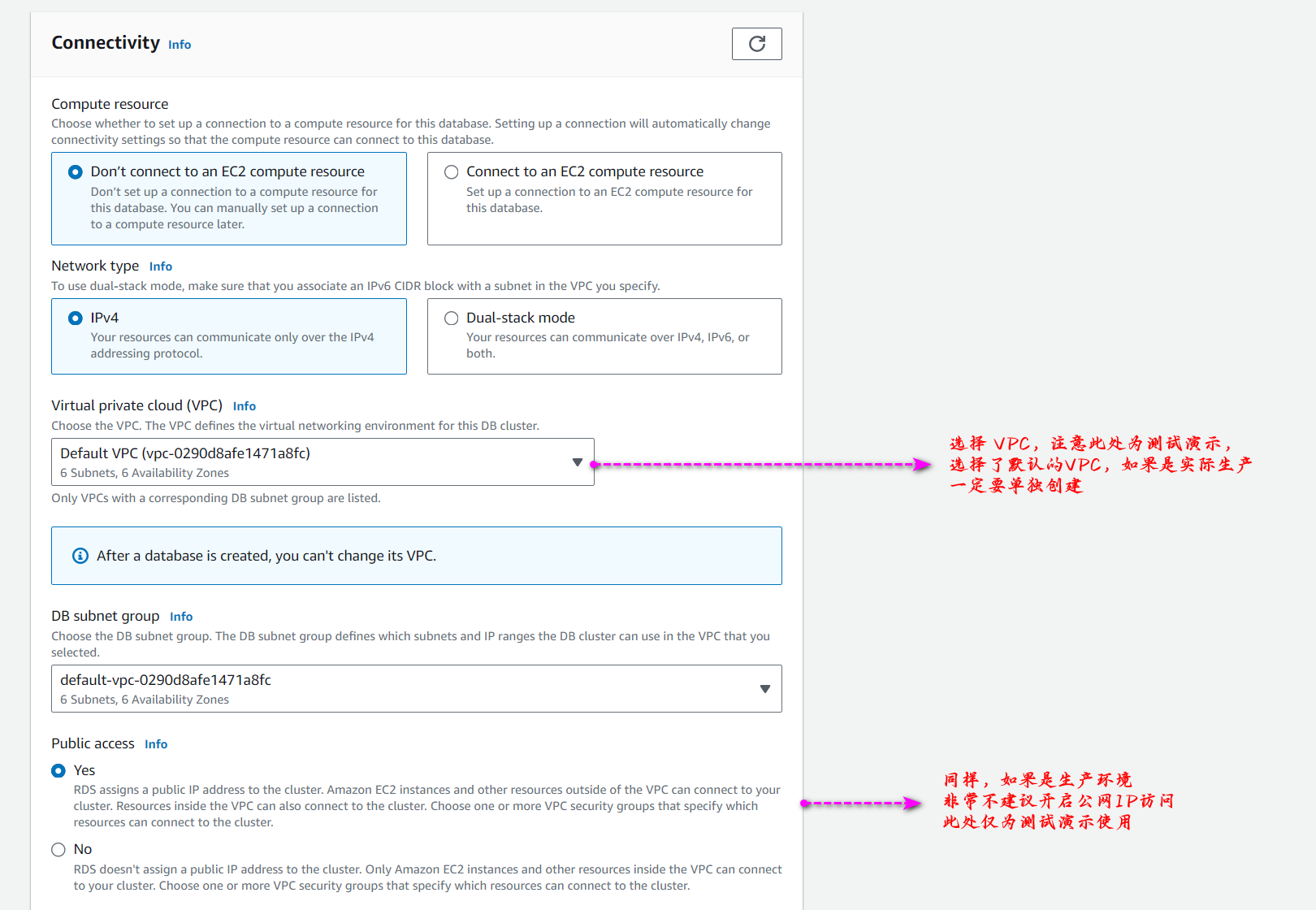
继续设置网络 VPC 及连接等相关设置
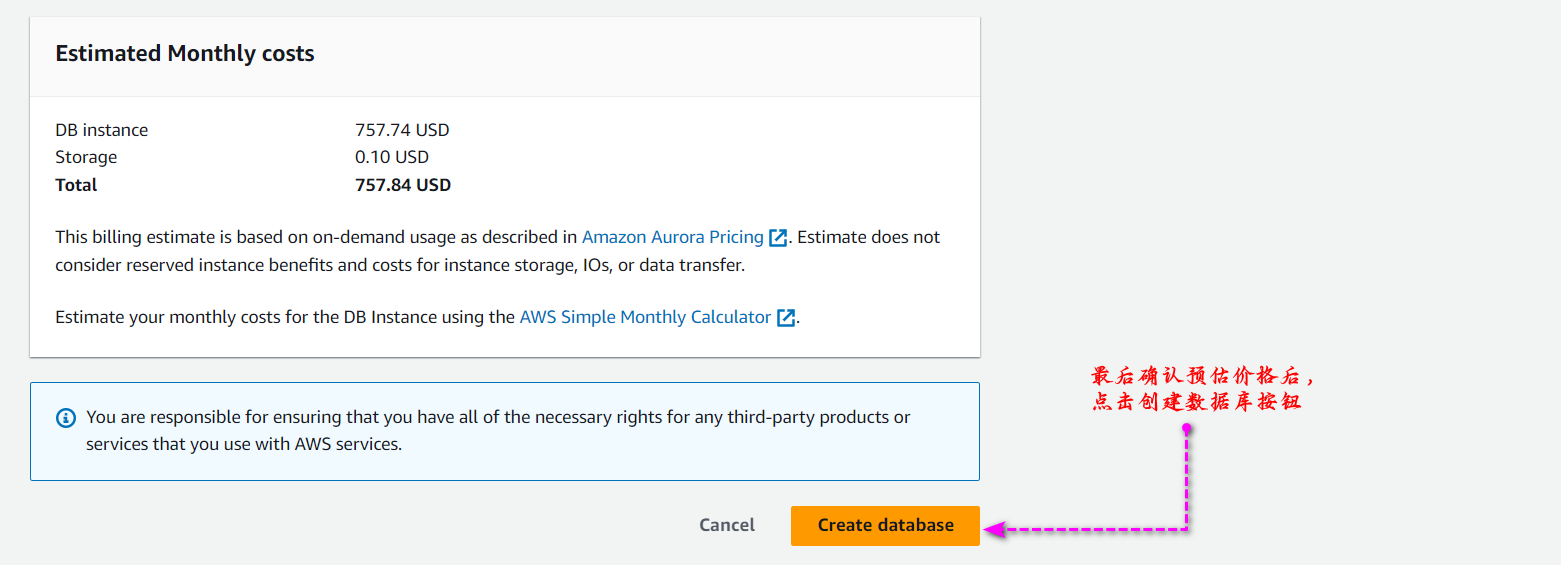
最后预览自己的配置以及价格,直接点击创建数据库按钮。
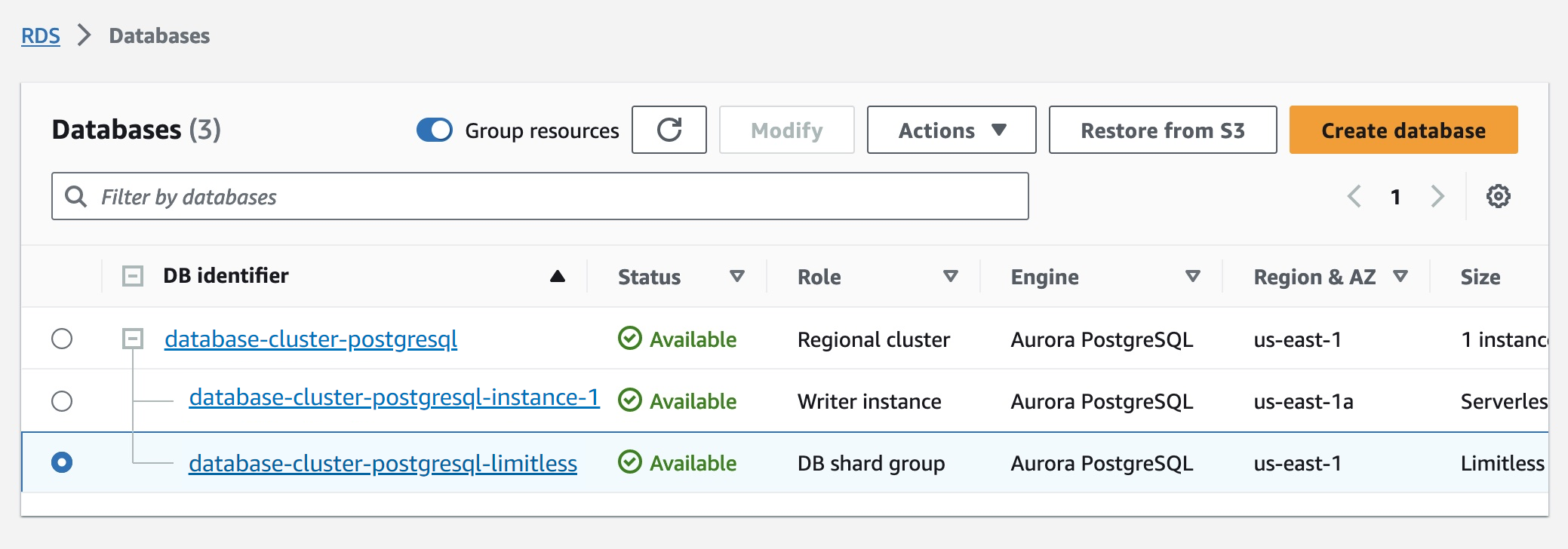
创建过程中需要等待一段时间,等待过后,在数据库页面可以看到刚才所创建的 Aurora 数据库,之后点击 Action 按钮,可以在弹出的菜单中找到添加数据库分片组的新功能。

添加并设置好后,可以看到我们的集群中,即包括普通 PostgreSql 的实例,也包括 Amazon Aurora Limitless 数据库。
四、文末总结
在2023年的亚马逊云科技 re:Invent 大会上,众多创新产品和解决方案亮相,其中 Amazon Aurora Limitless Database 成为备受瞩目的重磅发布。这一无限数据库扩展了 Amazon Aurora 的能力,使用户能够轻松地将数据库扩展到每秒数百万次写入事务,并管理以 PB 计的数据量。通过无服务器终端节点,该数据库提供了分布式查询规划和事务管理等功能,消除了用户创建自定义解决方案或管理多个数据库以进行扩展的需要。Amazon Aurora Limitless Database 的分片功能更进一步,允许数据库无限制地增加容量,为用户提供了无限的可能性和扩展性。
虽然目前仅支持部分地区的 PostgreSQL 版本,但这一创新展示了亚马逊云科技在数据库领域持续推动的领先地位和创新实力,为用户提供了更大的性能、灵活性和成本效益。
相关文章:
2023 亚马逊云科技 re:Invent 大会探秘:Aurora 无限数据库的突破性应用
文章目录 一、前言二、Amazon Aurora 无限数据库2.1 亚马逊云科技数据库产品发展历程2.2 什么是 Amazon Aurora Limitless Database(无限数据库)2.3 Amazon Aurora Limitless Database 设计架构2.4 Amazon Aurora Limitless Database 分片功能2.5 使用 A…...
IDEA添加Apifox插件后,返回参数不详细解决办法
Apifox官方文档地址(文档中返回的是特殊情况,跟我现在项目的返回不一样,因此需要更改配置) 点击跳转到官方API地址 实现步骤分为两步:第一步:添加配置,第二步使用注解。 1.添加配置 打开Idea设置,添加配置…...

js多图合成一张图
具体思路 先设置画布的宽高,再将每个图片整理成一个对象的数组通过某个方法传出合成后的base64 (1)、创建一个画布的类,他的属性是canvas虚拟dom和ctx (2)、构造器初始化convas对象、ctx、convas的宽高 …...
利用原始套接字解决mac地址错误问题【南瑞SysKeeper-2000】
一:案例描述 一键可视顺控图像智能项目在网络部署过程中,对网络限制隔离安全性要求很高,用到正向隔离装置(南瑞SysKeeper-2000型号)。 图一 正向装置示意图 现场发现问题:直连网线情况下,我方…...

JVM- 为什么G1垃圾回收器需要有大对象区
G1(Garbage-First)垃圾回收器在Java虚拟机(JVM)中引入了大对象区(也称为Humongous Region或H-Region)的概念,主要是为了高效地处理大型对象。在垃圾回收的上下文中,大对象指的是那些…...

操作系统的界面
(1) 请说明系统生成和系统引导的过程。 解: 系统的生成过程:当裸机启动后,会运行一个特殊的程序来自动进行系统的生成(安装),生成系统之前需要先对硬件平台状况进行检查,或者从指定文件处读取…...
1.【分布式】分布式事务详解
分布式事务 1.分布式事务是什么?数据库事务 2.分布式事务产生的原因?存储层拆分服务层拆分 3.分布式事务解决方案4.分布式事务有哪些开源组件SeateTCC 分布式服务组件基于消息补偿的最终一致性 5.两阶段提交,三阶段协议详解二阶段提交协议三阶…...

selenium-wire简介
一.简介 以下来自chatGPT回答: selenium-wire是一个基于selenium的Python库,它扩展了selenium的功能,使得我们可以在自动化测试中直接访问和修改浏览器的网络请求和响应。selenium-wire可以拦截和修改HTTP请求和响应,从而可以在…...
华为组播配置案例
igmp-snooping主要用于生成二层组播表项,防止交换机全部接口都发组播报文 PC端配置: 组播源配置: R1 interface GigabitEthernet0/0/0 ip address 10.0.0.1 255.255.255.0 pim dm interface GigabitEthernet0/0/1 ip address 192.168.0…...
lua语法
lua语法 1.lua数据类型 lua 脚本输出乱码,将lua脚本改为UTF-8编码,并且需要DOS下修改代码页:CHCP 65001 即可。 基本语法 注释 print("script lua win")-- 单行注释--[[多行注释]]--标识符 类似于:java当中 变量、…...

5A-Downloader,m3u8文件转mp4文件,音视频分离ts合并、转mp4
获取方式: 1.https://www.pgyer.com/DpxhpE 2.https://github.com/JoeLeeto/5A-Downloader 3.https://play.google.com/store/apps/details?idcom.leet.downloader...

标准IO与文件IO
标准IO通过缓冲机制减少系统调用,实现更高的效率 全缓冲:当流的缓冲区无数据或无空间时才执行实际IO操作 行缓冲:当在输入和输出中遇到换行符(\n)时,进行IO操作 当流和一个终端关联时,典型的行缓…...

流行的 React 相关库和框架
React 本身就是一个非常流行的 JavaScript 库,用于构建用户界面,特别是单页面应用。不过,有许多其他的库和框架与 React 结合使用,以提供额外的功能和优化开发体验。以下是一些最流行的 React 相关库和框架: Next.js&a…...
游戏引擎?
游戏引擎是指一些已编写好的可编辑电脑游戏系统或者一些交互式实时图像应用程序的核心组件。这些系统为游戏设计者提供各种编写游戏所需的各种工具,其目的在于让游戏设计者能容易和快速地做出游戏程式而不用由零开始。大部分都支持多种操作平台,如Linux、…...

C语言--字符函数与字符串函数
大家好,我是残念,希望在你看完之后,能对你有所帮助,有什么不足请指正!共同学习交流 本文由:残念ing 原创CSDN首发,如需要转载请通知 个人主页:残念ing-CSDN博客,欢迎各位…...

整理了一些热门、含免费次数的api,分享给大家
IP归属地-IPv4区县级:根据IP地址查询归属地信息,包含43亿全量IPv4,支持到中国地区(不含港台地区)区县级别,含运营商数据。IP应用场景- IPv4:IPv4应用场景是获取IP场景属性的在线调用接口&#x…...

Wireshark在网络性能调优中的应用
第一章:Wireshark基础及捕获技巧 1.1 Wireshark基础知识回顾 1.2 高级捕获技巧:过滤器和捕获选项 1.3 Wireshark与其他抓包工具的比较 第二章:网络协议分析 2.1 网络协议分析:TCP、UDP、ICMP等 2.2 高级协议分析:HTTP…...

关于设计师的自我评价(合集)
设计师的自我评价篇一 本人接受过正规的美术教育,具有较好的美术功底及艺术素养,能够根据公司的需要进行设计制作,熟练掌握多种电脑制作软件,能够高效率地完成工作。本人性格开朗、思维活跃、极富创造力,易于沟通&…...

Hudi Clustering
核心概念 Hudi Clustering对于在数据写入和读取提供一套相对完善的解决方案。它的核心思想就是: 在数据写入时,运行并发写入多个小文件,从而提升写入的性能;同时通过一个异步(也可以配置同步,但不推荐&…...
)
别再踩坑了!Django Ckeditor配置全指南:从基础使用到高级定制(2023最新版)
Django Ckeditor实战手册:2023年高效配置与深度定制技巧 如果你正在为Django项目寻找一个功能强大且可定制的富文本编辑器,Ckeditor无疑是最佳选择之一。但配置过程中那些令人头疼的兼容性问题、图片上传失败、工具栏自定义困难,确实让不少开…...

Ostrakon-VL终端实战:从扫码识别到生成抖音短视频脚本的创意延伸
Ostrakon-VL终端实战:从扫码识别到生成抖音短视频脚本的创意延伸 1. 像素特工终端介绍 想象你是一名零售侦探,手持的不是笨重的扫描枪,而是一个充满复古游戏风格的AI终端。这就是基于Ostrakon-VL-8B模型开发的像素风格交互界面,…...

S2-Pro数据库课程设计助手:从需求分析到SQL生成的全程辅助
S2-Pro数据库课程设计助手:从需求分析到SQL生成的全程辅助 1. 课程设计的痛点与解决方案 每到学期末,数据库课程设计就成了计算机专业学生的"必修课"。面对一个陌生的业务场景,从零开始梳理需求、设计E-R图、编写SQL语句…...

鸿蒙与Android双端蓝牙开发避坑指南:定位权限、虚拟地址与厂商SDK那些事
鸿蒙与Android双端蓝牙开发实战:权限策略与真实地址获取全解析 当你的应用需要同时在鸿蒙和Android设备上稳定运行蓝牙功能时,系统差异就像一片雷区——Android 12的权限拆分、鸿蒙4.0的虚拟地址返回、不同版本间的API兼容性,每个环节都可能让…...

如何突破设备限制?打造你的全场景跨平台开发中枢
如何突破设备限制?打造你的全场景跨平台开发中枢 【免费下载链接】code-server VS Code in the browser 项目地址: https://gitcode.com/GitHub_Trending/co/code-server 在多设备开发的时代,远程开发环境已成为连接不同终端的核心枢纽࿰…...

AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南
AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 在碧蓝航线…...
)
Arcgis符号化实战:用矢量文件制作专业级统计地图(附最新配色方案)
ArcGIS符号化实战:用矢量文件制作专业级统计地图(附最新配色方案) 当你面对一叠枯燥的表格数据时,是否想过如何让这些数字"活"起来?统计地图正是将抽象数据转化为直观视觉表达的利器。作为地理信息系统领域的…...

别再手算LLC参数了!用Mathcad Prime 8.0自动生成增益曲线,附我验证过的产品级模板
告别手工计算:用Mathcad Prime 8.0打造智能LLC设计工作流 深夜的办公室里,电源工程师小王盯着屏幕上密密麻麻的公式叹了口气——这已经是本周第三次因为手工计算LLC谐振参数出错导致样机测试失败了。在中小型电源企业,像小王这样的场景每天都…...

基于Xinference-v1.17.1的嵌入式Linux开发指南
基于Xinference-v1.17.1的嵌入式Linux开发指南 1. 引言 嵌入式设备上的AI推理一直是个技术挑战,特别是在资源受限的环境中部署大模型。Xinference-v1.17.1作为一个开源推理框架,为嵌入式Linux系统提供了轻量级的AI模型部署方案。无论你是想在树莓派上运…...

Zigbee网关配网操作全解析:从连接到触发
1. Zigbee网关配网前的准备工作 第一次接触Zigbee网关配网的朋友可能会觉得有点复杂,但其实只要跟着步骤一步步来,整个过程并不难。我刚开始接触时也踩过不少坑,现在把这些经验都整理出来,希望能帮你少走弯路。 首先得确认你的硬件…...