深度剖析知识图谱:方法、工具与实战案例
- 💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】
- 🤟 基于Web端打造的:👉轻量化工具创作平台
- 💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】
知识图谱作为一种强大的知识表示和关联技术,在信息处理领域展现出巨大潜力。本文将深度剖析知识图谱的构建方法、相关工具的应用,同时通过实际案例演示知识图谱在现实问题中的应用。
知识图谱作为一种强大的知识表示和关联技术,对于处理和组织复杂的知识体系具有显著的优势。在这一章节中,我们将深入介绍知识图谱的基本概念和其在语义搜索、自然语言处理等领域的广泛应用。
1.1 知识图谱的定义
知识图谱是一种图状数据结构,用于表示实体(Entity)之间的关系(Relationship)。这些实体和关系可以通过丰富的属性和语义信息相互连接,形成一个庞大而复杂的知识网络。通常,知识图谱的构建以及对其中知识的查询和推理都依赖于先进的人工智能技术。
1.2 知识图谱的应用领域
1.2.1 语义搜索
知识图谱为搜索引擎提供了更智能的语义理解能力。通过将搜索关键词与知识图谱中的实体和关系进行匹配,搜索引擎能够更准确地理解用户的意图,提供更精准的搜索结果。
1.2.2 自然语言处理
在自然语言处理领域,知识图谱为计算机理解和生成自然语言提供了基础。实体识别和关系抽取等技术与知识图谱的结合,使得计算机能够更好地理解文本中的实体及其关系,从而更智能地处理自然语言。
1.2.3 推荐系统
知识图谱在推荐系统中也发挥着重要作用。通过分析用户的行为和偏好,将用户、物品和其它关联信息表示在知识图谱中,系统能够为用户提供个性化的推荐服务。
1.3 构建知识图谱的关键步骤
1.3.1 实体识别与关系抽取
构建知识图谱的第一步是从文本中识别实体并抽取实体之间的关系。自然语言处理技术的应用,如命名实体识别(NER)和关系抽取,成为这一步骤中不可或缺的工具。
1.3.2 图数据库的存储
图数据库是知识图谱存储的理想之选。图数据库能够高效地存储实体、关系及其属性,并支持复杂的图查询操作。
1.4 知识图谱的未来展望
随着人工智能技术的不断发展,知识图谱将在更多领域发挥关键作用。未来,我们可以期待更智能、更灵活的知识图谱系统,为人们提供更高效、更智能的知识管理和应用服务。
通过本节的介绍,读者将对知识图谱的基本概念、应用领域以及构建过程有一个全面而深入的理解。在接下来的章节中,我们将进一步探讨知识图谱构建的具体方法和工具。
2. 构建知识图谱的方法
2.1 实体识别与关系抽取
在知识图谱的构建中,实体识别与关系抽取是一个关键的环节。这一步骤旨在从文本中准确地识别出实体,并推断实体之间的关系。采用自然语言处理技术,我们可以利用现有的工具和库来执行这些任务。
2.1.1 实体识别
实体识别的目标是从文本中抽取出具有特定类型的实体,例如人名、地名、组织名等。在示例代码中,我们使用了spaCy这一自然语言处理库,通过加载其预训练模型,能够对输入文本进行实体识别。
# 示例代码:使用spaCy进行实体识别
import spacy# 加载spaCy的预训练模型
nlp = spacy.load("en_core_web_sm")# 处理文本
text = "Apple Inc. was founded by Steve Jobs and Steve Wozniak."
doc = nlp(text)# 提取实体
entities = [(ent.text, ent.label_) for ent in doc.ents]
print("Entities:", entities)
在这个例子中,文本中的实体包括"Apple Inc."、“Steve Jobs"和"Steve Wozniak”,它们分别被正确地识别为组织名和人名。
2.1.2 关系抽取
关系抽取的目标是推断实体之间的关系,使得知识图谱能够更全面地呈现信息。在示例代码中,我们试图提取文本中实体之间的关系,并计算它们之间的相似度。
# 示例代码:使用spaCy进行关系抽取
relations = [(ent1.text, ent2.text, rel) for ent1 in doc.ents for ent2 in doc.ents if ent1 != ent2 for rel in ent1.similarity(ent2)]
print("Relations:", relations)
需要注意的是,实际的关系抽取可能需要更为复杂的算法和语义理解模型。在构建真实的知识图谱时,通常需要更加深入的自然语言处理技术和深度学习模型。
通过以上代码示例,读者可以初步了解实体识别和关系抽取在知识图谱构建中的应用。在后续章节中,我们将深入讨论更高级的知识图谱构建方法。
2.2 图数据库的应用
图数据库是存储和查询图状数据的理想选择。通过将知识图谱存储于图数据库中,我们能够高效地进行复杂的图查询操作。
# 示例代码:使用Neo4j进行图数据库操作
from py2neo import Graph, Node, Relationship# 连接Neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))# 创建节点
node1 = Node("Person", name="Steve Jobs")
node2 = Node("Person", name="Steve Wozniak")
node3 = Node("Company", name="Apple Inc.")# 创建关系
relation1 = Relationship(node1, "FOUNDED", node3)
relation2 = Relationship(node2, "FOUNDED", node3)# 将节点和关系添加到图数据库
graph.create(node1)
graph.create(node2)
graph.create(node3)
graph.create(relation1)
graph.create(relation2)
通过深度剖析知识图谱的构建方法、工具的应用和实际案例演示,读者将全面了解知识图谱的魅力和实用性。知识图谱不仅是理论上的概念,更是解决实际问题的有力工具。
⭐️ 好书推荐
《知识图谱:方法、工具与案例》

【内容简介】
《知识图谱:方法、工具与案例》介绍可供信息提供者构建和维护知识图谱的方法和工具,包括实施知识图谱,手动、半自动、自动构建验证语义标记,并将语义标记集成到知识图谱;还介绍用于半自动和自动整理图谱的基于生命周期的方法,可进行评估、纠错,以及利用其他静态和动态资源来丰富知识图谱。
📚 京东购买链接:《知识图谱:方法、工具与案例》
相关文章:
深度剖析知识图谱:方法、工具与实战案例
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】 知识图谱作为一种强大的知识表示和关联技术&am…...

Oracle中的dblink简介
Oracle中的dblink简介 是一种用于在不同数据库之间进行通信和数据传输的工具。它允许用户在一个数据库中访问另一个数据库中的对象,而无需在本地数据库中创建这些对象。 使用dblink,用户可以在一个数据库中执行SQL语句,然后访问另一个数据库中…...
ubuntu安装显卡驱动过程中遇到的错误,及解决办法!
ubuntu安装显卡驱动的过程中,可能会遇到以下问题,可以参考解决办法! 问题1: ERROR: An error occurred while performing the step: "Building kernel modules". See /var/log/nvidia-installer.log for details. …...
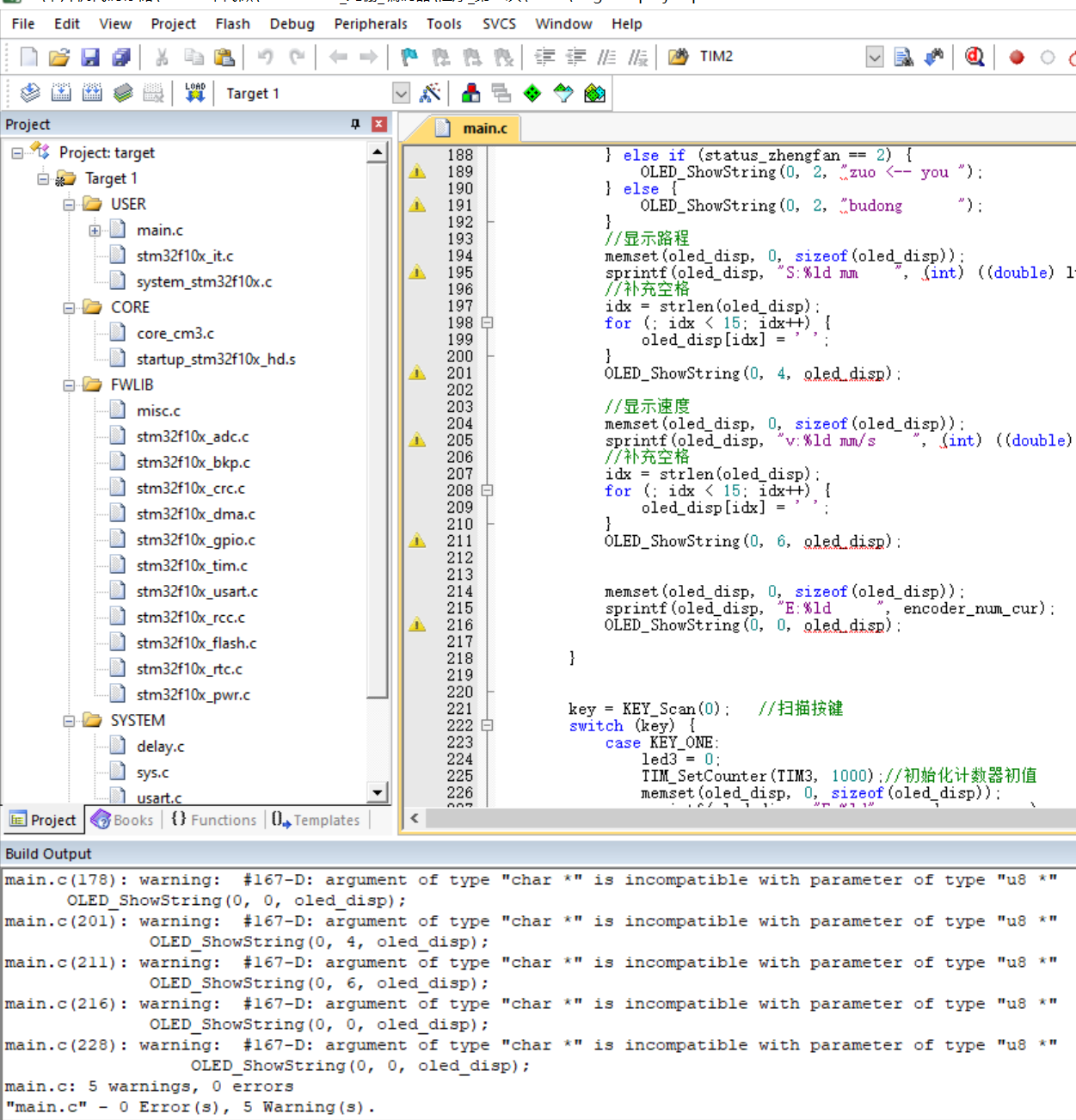
【程序】STM32 读取光栅_编码器_光栅传感器_7针OLED
文章目录 源代码工程编码器基础程序参考资料 源代码工程 源代码工程打开获取: http://dt2.8tupian.net/2/28880a55b6666.pg3这里做了四倍细分,在屏幕上显示 速度、路程、方向。 接线方法: 单片机--------------串口模块 单片机的5V-------…...
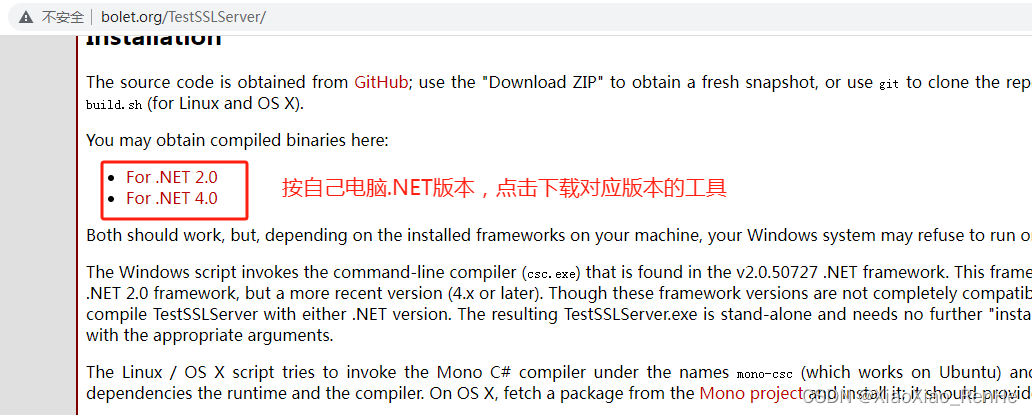
TestSSLServer4.exe工具使用方法简单介绍(查SSL的加密版本SSL3或是TLS1.2)
一、工具使用方法介绍 工具使用方法参照:http://www.bolet.org/TestSSLServer/ 全篇英文看不懂,翻译了下,能用到的简单介绍如下: 将下载的TestSSLServer4.exe工具放到桌面上,CMD命令行进入到桌面目录,执…...

新年跨年烟花超酷炫合集【内含十八个烟花酷炫效果源码】
❤️以下展示为全部烟花特效效果 ❤️下方仅展示部分代码 ❤️源码获取见文末 🎀HTML5烟花喷泉 <style> * {padding:0;margin:0; } html,body {positi...

计算机网络考研辨析(后续整理入笔记)
文章目录 体系结构物理层速率辨析交换方式辨析编码调制辨析 链路层链路层功能介质访问控制(MAC)信道划分控制之——CDMA随机访问控制轮询访问控制 扩展以太网交换机 网络层网络层功能IPv4协议IP地址IP数据报分析ICMP 网络拓扑与转发分析(重点…...
JMESPath语言
JMESPath(JSON Matching Expression Path) 一种查询语言。 主要用于从JSON文档中检索和过滤数据。 通过写表达式提取和处理JSON数据,而无需编写复杂的代码。 功能:数据提取、过滤、转换、排序。 场景:处理API响应…...
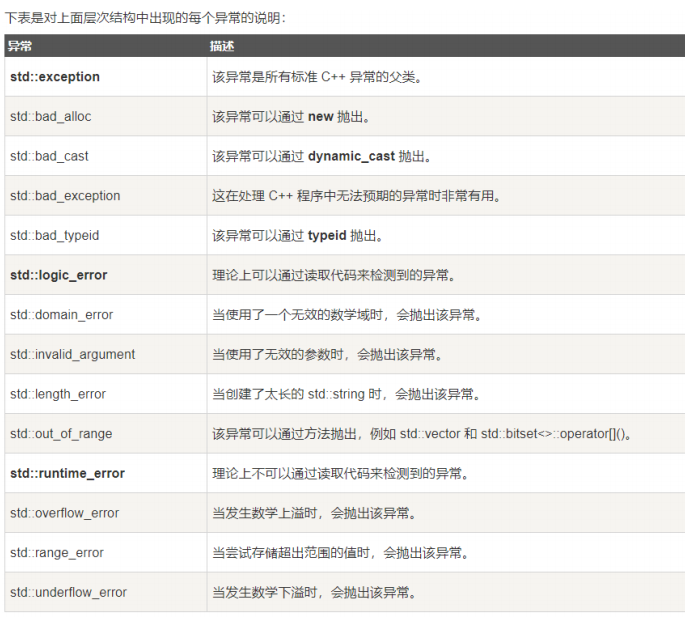
【C++高阶(七)】C++异常处理的方式
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 异常处理的方式 1. 前言2. C语言处理异常的方式…...

在Idea中创建基于工件的本地服务
目录 1、创建基于工件的Tomcat服务器: 2、修改名称: 3、修改服务器项: 4、部署项 5、最后记得点右下角的【应用】和【确定】保存。 1、创建基于工件的Tomcat服务器: 运行->编辑配置->【Tomcat服务器】->本地 2、修…...

十六、YARN和MapReduce配置
1、部署前提 (1)配置前提 已经配置好Hadoop集群。 配置内容: (2)部署说明 (3)集群规划 2、修改配置文件 MapReduce (1)修改mapred-env.sh配置文件 export JAVA_HOM…...

自己动手写编译器:语法解析的基本原理
在前面系列章节中我们完成了词法解析。词法解析的基本任务就是判断给定字符串是否符合特定规则,如果符合那么就给这个字符串分配一个标签(token)。词法解析完成后接下来的工作就要分配给语法解析,后者的任务就是判断一系列标签的组合是否符合特定规范。 …...
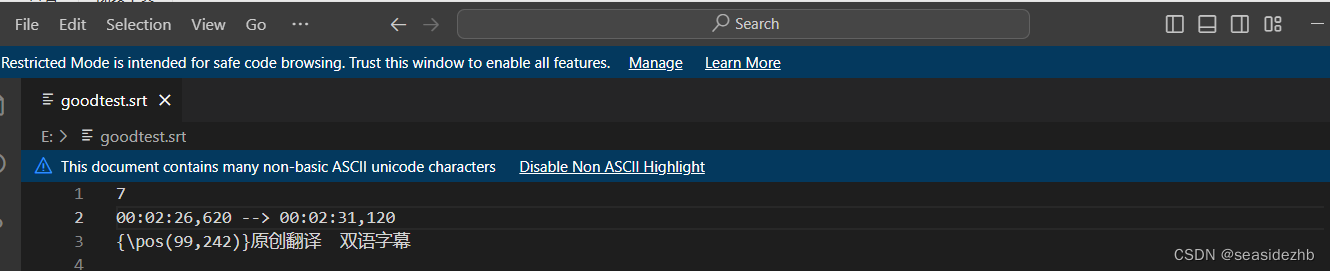
VS Code解决乱码
在上边搜索栏输入“>Change File Encoding”,更改编码格式,解决乱码格式。 VS Code会帮助确认编码格式,然后选择就好。 最后完成如下:...
宝塔Linux:部署His医疗项目通过jar包的方式
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有…...

Vim命令大全(超详细,适合反复阅读学习)
Vim命令大全 Vim简介Vim中的模式光标移动命令滚屏与跳转文本插入操作文本删除操作文本复制、剪切与粘贴文本的修改与替换文本的查找与替换撤销修改、重做与保存编辑多个文件标签页与折叠栏多窗口操作总结 Vim是一款文本编辑器,是Vi编辑器的增强版。Vim的特点是快速、…...

爬虫持久化保存
## open方法- 方法名称及参数markdown **open(file, moder, bufferingNone, encodingNone, errorsNone, newlineNone, closefdTrue)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t…...
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面? 医学大模型问题如何使用知识图谱加强和补足专业能力?大模型结构知识图谱增强大模型的方法 医学大模型问题 问诊。偏离主诉和没抓住核心。…...

读写分离之同步延迟测试
背景 读写分离是快速提高数据库性能的手段,主库只负责写入,从库负责查询。但在性能得到提升的同时,编程的复杂度就会提升。由其碰到主从同步延迟的情况,在数据写入后,在从库无法读取到最新数据,会对业务逻…...

SpringBoot+OCR 实现PDF 内容识别
一、SpringBootOCR对pdf文件内容识别提取 1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。 一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图…...

Go和Java实现抽象工厂模式
Go和Java实现抽象工厂模式 本文通过简单数据库操作案例来说明抽象工厂模式的使用,使用Go语言和Java语言实现。 1、抽象工厂模式 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创 建型模式,它…...
,使用异步方式写日志)
.NETCore Serilog 代码设置相关参数说明及按Sink设置不同级别(不同日志级别),使用异步方式写日志
rollingInterval设置为RollingInterval.Day与fileSizeLimitBytes配合使用: 在.NET Core Serilog中,同时设置rollingInterval RollingInterval.Day和fileSizeLimitBytes参数并不会产生配置冲突。这两个参数实际上是互补的,共同提供了更灵活的…...

Jaspersoft Studio 动态字体颜色设置实战指南
1. 为什么需要动态字体颜色? 在报表开发中,数据可视化是提升信息传达效率的关键手段。想象一下,当你的老板查看月度销售报表时,如果所有数字都是千篇一律的黑色,他需要花费多少时间才能找到异常数据?而如果…...

AI结对编程:利用快马平台智能助手深度理解和优化PyTorch代码
最近在折腾PyTorch项目时,发现很多细节问题光靠查文档效率太低。后来尝试用InsCode(快马)平台的AI辅助功能,发现它不仅能解释代码原理,还能直接给出优化方案,简直是深度学习开发的"外挂"。分享几个实用场景:…...

OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试
OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试 1. 为什么需要AI全流程编程辅助 作为经常需要写脚本处理数据的开发者,我发现自己陷入了一个典型困境:每天要花大量时间编写重复性代码,而真正需要创造性思考的部分反而被…...
非常详细收藏我这一篇就够了!大模型教程)
大模型入门学习教程(非常详细)非常详细收藏我这一篇就够了!大模型教程
本文系统介绍了LLM(大型语言模型)的基础知识,包括机器学习的数学基础、Python编程及其在数据科学中的应用、神经网络原理等。文章深入剖析了LLM科学家和工程师的角色,涵盖了大型语言模型架构、指令数据集构建、预训练模型、监督微…...

【Python 教程】如何将 JSON 数据转换为 Excel 工作表
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

3000份绝密文件外泄!Anthropic“核弹级”AI Mythos一夜封神,AGI防盗门被敲碎
Anthropic“防盗门”被敲了三下,声音来自自家后院。 一次配置失误,近3000份内部文档裸奔,把尚未出生的Mythos(对外昵称Capybara)推到了聚光灯下。 它有多强?一句话:在软件编程、学术推理、网络安…...

智能媒体捕获:猫抓cat-catch的资源拦截与解析技术方案
智能媒体捕获:猫抓cat-catch的资源拦截与解析技术方案 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch作为一款开源浏览器扩展,通过深度网络请求分析与流媒体协议…...

OpenClaw省钱方案:自建Qwen3-VL:30B替代高价多模态API
OpenClaw省钱方案:自建Qwen3-VL:30B替代高价多模态API 1. 为什么选择自建多模态模型 去年我在开发一个智能内容分析系统时,每月在商用多模态API上的支出高达数千元。当我尝试用OpenClaw对接本地部署的Qwen3-VL:30B后,成本直接降到了原来的1…...

如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战
如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战 【免费下载链接】recastnavigation Navigation-mesh Toolset for Games 项目地址: https://gitcode.com/gh_mirrors/re/recastnavigation 想要为你的游戏打造智能的AI导航系统吗?Re…...