在Python中使用Kafka帮助我们处理数据

Kafka是一个分布式的流数据平台,它可以快速地处理大量的实时数据。Python是一种广泛使用的编程语言,它具有易学易用、高效、灵活等特点。在Python中使用Kafka可以帮助我们更好地处理大量的数据。本文将介绍如何在Python中使用Kafka简单案例。
一、安装Kafka-Python包
在Python中使用Kafka,需要安装Kafka-Python包。可以使用pip命令进行安装。
pip install kafka-python二、生产者
在Kafka中,生产者负责将消息发送到Kafka集群。Python中使用Kafka-Python包可以轻松实现生产者功能。下面是一个生产者的示例代码:
rom kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers=['localhost:9092'])producer.send('test', b'Hello, Kafka!')
在上面的代码中,我们首先导入了KafkaProducer类,然后创建了一个生产者对象,并指定了Kafka集群的地址。接着,我们调用send()方法将消息发送到名为“test”的主题中。
三、消费者
在Kafka中,消费者负责从Kafka集群中消费消息。Python中使用Kafka-Python包可以轻松实现消费者功能。下面是一个消费者的示例代码:
from kafka import KafkaConsumerconsumer = KafkaConsumer('test', bootstrap_servers=['localhost:9092'])for message in consumer:print(message.value)
在上面的代码中,我们首先导入了KafkaConsumer类,然后创建了一个消费者对象,并指定了Kafka集群的地址和要消费的主题。接着,我们使用for循环遍历消费者返回的消息,并打印出消息的内容。
四、批量发送和批量消费
在实际应用中,我们通常需要批量发送和批量消费消息。Kafka-Python包提供了批量发送和批量消费的功能。下面是一个批量发送和批量消费消息的示例代码:
from kafka import KafkaProducer, KafkaConsumerfrom kafka.errors import KafkaErrorproducer = KafkaProducer(bootstrap_servers=['localhost:9092'])for i in range(10):message = 'Message {}'.format(i)future = producer.send('test', bytes(message, 'utf-8'))try:record_metadata = future.get(timeout=10)print('Message {} sent to partition {} with offset {}'.format(message, record_metadata.partition, record_metadata.offset))except KafkaError as e:print('Failed to send message {}: {}'.format(message, e))consumer = KafkaConsumer('test', bootstrap_servers=['localhost:9092'], auto_offset_reset='earliest', enable_auto_commit=True, group_id='my-group', max_poll_records=10)while True:messages = consumer.poll(timeout_ms=1000)if not messages:continuefor topic_partition, records in messages.items():for record in records:print(record.value.decode('utf-8'))在上面的代码中,我们首先创建了一个生产者对象,并使用for循环批量发送10条消息。在发送消息时,我们使用bytes()方法将消息转换为字节串,并使用producer.send()方法发送消息。在发送消息后,我们使用future.get()方法等待消息发送完成,并打印出消息的分区和偏移量。
接着,我们创建了一个消费者对象,并使用while循环批量消费消息。在消费消息时,我们使用consumer.poll()方法从Kafka集群中拉取消息,然后使用for循环遍历返回的消息,并打印出消息的内容。
五、总结
本文介绍了如何在Python中使用Kafka简单案例,包括生产者、消费者、批量发送和批量消费。通过本文的介绍,读者可以更好地理解Kafka-Python包的使用方法,进一步掌握Kafka的应用。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

相关文章:
在Python中使用Kafka帮助我们处理数据
Kafka是一个分布式的流数据平台,它可以快速地处理大量的实时数据。Python是一种广泛使用的编程语言,它具有易学易用、高效、灵活等特点。在Python中使用Kafka可以帮助我们更好地处理大量的数据。本文将介绍如何在Python中使用Kafka简单案例。 一、安装K…...

进程和线程和协程区别
目录 一、进程和线程 二、线程上下文切换 三、线程与协程区别 一、进程和线程 线程是可以由调度程序对立管理的最小程序指令集,而进程是程序运行的实例。 大多情况下,线程是进程的组成部分,一个进程中可以存在多个线程,这些线…...
银行测试:第三方支付平台业务流,功能/性能/安全测试方法
1、第三方支付平台的功能和结构特点 在信用方面,第三方支付平台作为中介,在网上交易的商家和消费者之间作一个信用的中转,通过改造支付流程来约束双方的行为,从而在一定程度上缓解彼此对双方信用的猜疑,增加对网上购物…...
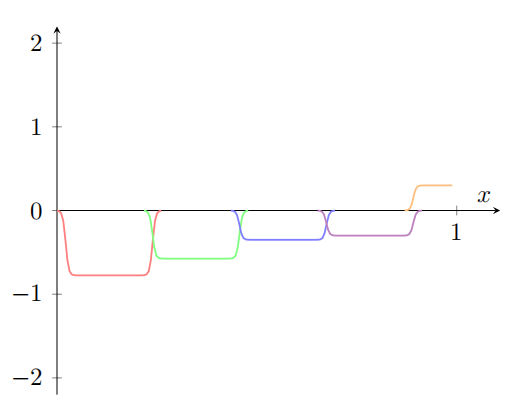
神经网络可以计算任何函数的可视化证明
神经网络可以计算任何函数的可视化证明 对于神经网络,一个显著的事实就是它可以计算任何函数。 如下:不管该函数如何,总有神经网络能够对任何可能的输入x,输出值f(x) 即使函数有很多输入和输出࿰…...
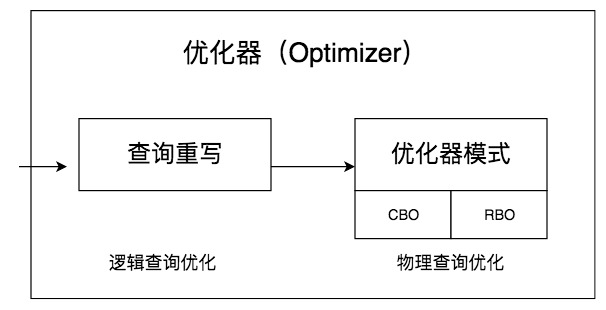
SQL进阶理论篇(十三):数据库的查询优化器是什么?
文章目录 简介什么是查询优化器查询优化器的两种优化方式总结参考文献 简介 事务可以让数据库在增删改查的过程中,保证数据的正确性和安全性,而索引可以帮数据库提升数据的查找效率。查询优化器,则是帮助我们获取更高的SQL查询性能。 本节我…...

视觉SLAM中的相机分类及用途
视觉SLAM(Simultaneous Localization and Mapping)算法主要用于机器人和自动导航系统中,用于同时进行定位和建立环境地图。这种算法依赖于相机来捕捉环境数据。根据视觉SLAM的具体需求和应用场景,可以使用不同类型的相机。以下是用…...

Gin之GORM多表关联查询(多对多;自定义预加载SQL)
数据库三个,如下: 注意:配置中间表的时候,表设计层面最好和配置的其他两张表契合,例如其他两张表为fate内的master和slave;要整合其对应关系的话,设计中间表的结构为master_id和slave_id最好(不然会涉及重写外键的操作) 重写外键(介绍) 对于 many2many 关系,连接表…...

linux 调试工具 GDB 使用
gdb是linux下常用的代码调试工具,本文记录常用命令。 被调试的应用需要使用 -g 参数进行编译,如不确定可使用如下命令查看是否支持debug readelf -S filename | grep "debug" 启动调试 gdb binFile 例如要调试sshd: 调试带参数…...

qt程序在Linux下打包的一般流程
编译 手动编写编译脚本 qmake make复制依赖库 参考文章: https://blog.csdn.net/JOBbaba/article/details/124289626 https://zhuanlan.zhihu.com/p/49919048 复制系统依赖库 编写复制脚本copy.sh ldd复制Qt依赖库 主要是libqxcb.so的相关依赖需要复制&…...
华为鸿蒙应用--欢迎页SplashPage+倒计时跳过(自适应手机和平板)-ArkTs
鸿蒙ArkTS 开发欢迎页SplashPage倒计时跳过,可自适应平板和手机: 一、SplashPage.ts import { BreakpointSystem, BreakPointType, Logger, PageConstants, StyleConstants } from ohos/common; import router from ohos.router;Entry Component struct…...

spring MVC概述和土门案例(无配置文件开发)
SpringMVC 1,SpringMVC概述2,SpringMVC入门案例2.1 需求分析2.2 案例制作步骤1:创建Maven项目步骤2:补全目录结构步骤3:导入jar包步骤4:创建配置类步骤5:创建Controller类步骤6:使用配置类替换web.xml步骤7:配置Tomcat环境步骤8:启动运行项目步骤9:浏览器…...

持续集成交付CICD:K8S 通过模板文件自动化完成前端项目应用发布
目录 一、实验 1.环境 2.GitLab 更新deployment文件 3.GitLab更新共享库前端项目CI与CD流水线 4.K8S查看前端项目版本 5.Jenkins 构建前端项目 6.Jenkins 再次构建前端项目 二、问题 1. Jenkins 构建CI 流水线报错 2. Jenkins 构建CI 流水线弹出脚本报错 3. Jenkins…...
【TB作品】51单片机 实物+仿真-电子拔河游戏_亚博 BST-M51
代码工程。 http://dt4.8tupian.net/2/28880a66b12880.pg3这段代码是用于一个数字拔河游戏的嵌入式系统,采用了基于8051架构的单片机,使用Keil C51编译器。 主要功能包括: 数码管显示:使用了四个数码管(通过P2的控制…...

MyBatis ${}和#{}区别
sql防注入底层jdbc类型转换当简单类型参数$不防止Statment不转换value#防止preparedStatement转换任意 除模糊匹配外,杜绝使用${} MyBatis教程,大家可以借鉴 MyBatis 教程_w3cschool 主要区别 1、#{} 是预编译处理,${} 是直接替换&#…...
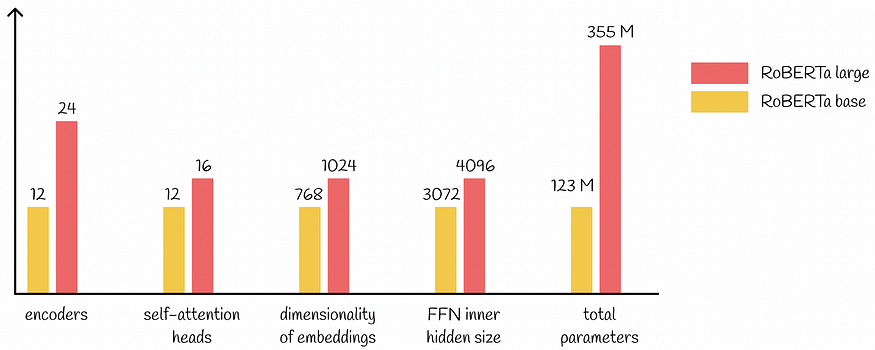
大型语言模型:RoBERTa — 一种稳健优化的 BERT 方法
slavahead 一、介绍 BERT模型的出现BERT模型带来了NLP的重大进展。 BERT 的架构源自 Transformer,它在各种下游任务上取得了最先进的结果:语言建模、下一句预测、问答、NER标记等。 尽管 BERT 性能出色,研究人员仍在继续尝试其配置࿰…...
webpack知识点总结(基础应用篇)
一、为什么需要webpack 1.为什么使用webpack ①传统的书写方式,加载太多脚本会导致网络瓶颈,如不小心改变JavaScript文件加载顺序,项目会崩溃,还会导致作用域问题、js文件太大无法做到按需加载、可读性和可维护性太低的问题。 ②…...
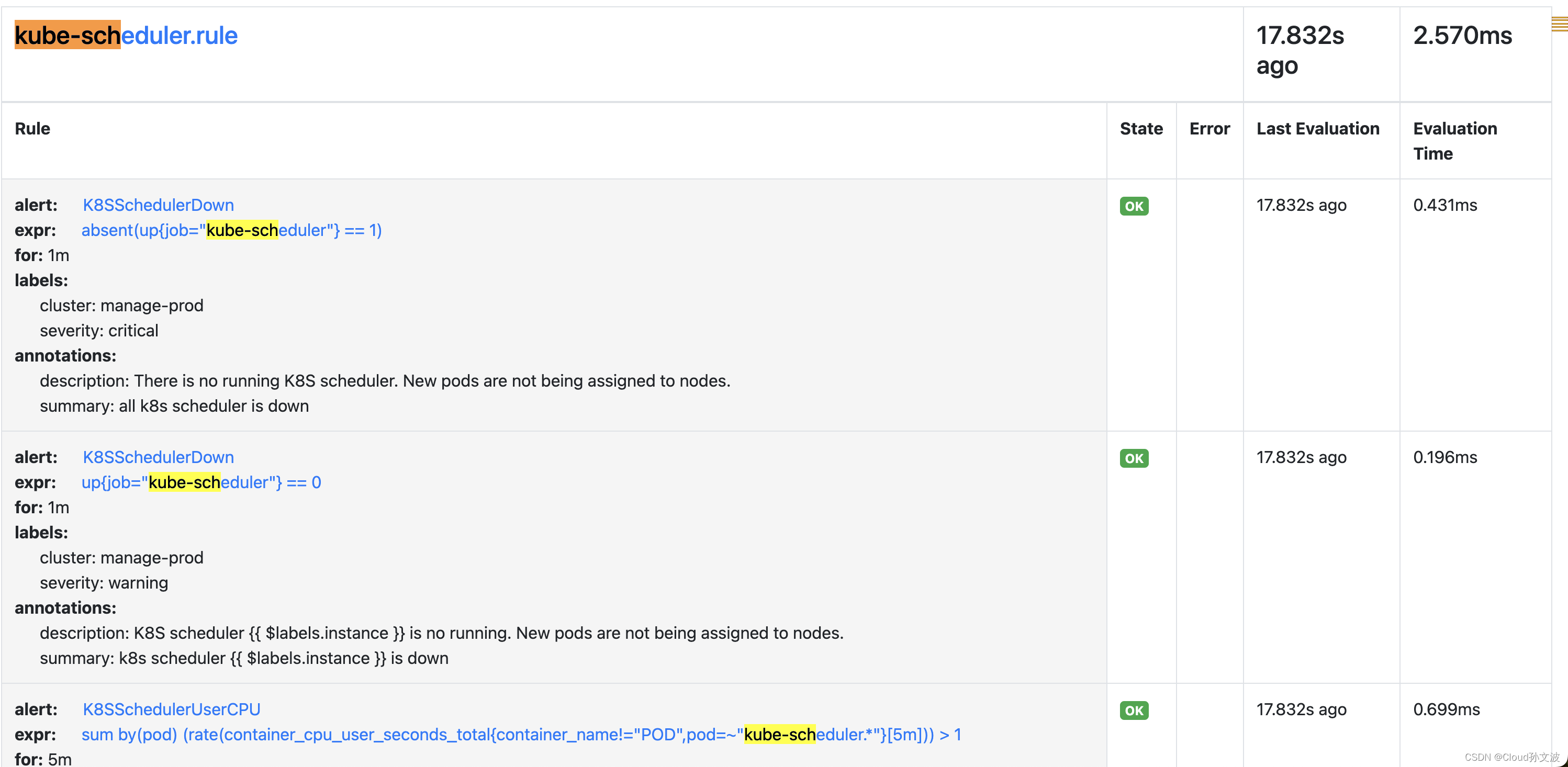
监控k8s controller和scheduler,创建serviceMonitor以及Rules
目录 一、修改kube-controller和kube-schduler的yaml文件 二、创建service、endpoint、serviceMonitor 三、Prometheus验证 四、创建PrometheusRule资源 五、Prometheus验证 直接上干货 一、修改kube-controller和kube-schduler的yaml文件 注意:修改时要一个节…...
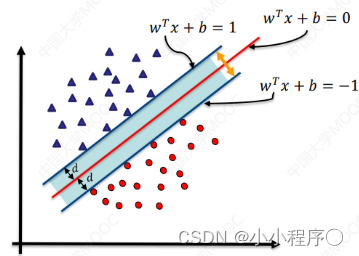
支持向量机 支持向量机概述
支持向量机概述 支持向量机 Support Vector MachineSVM ) 是一类按监督学习 ( supervisedlearning)方式对数据进行二元分类的广义线性分类器 (generalized linear classifier) ,其决策边界是对学习样本求解的最大边距超亚面 (maximum-margin hyperplane)与逻辑回归和…...
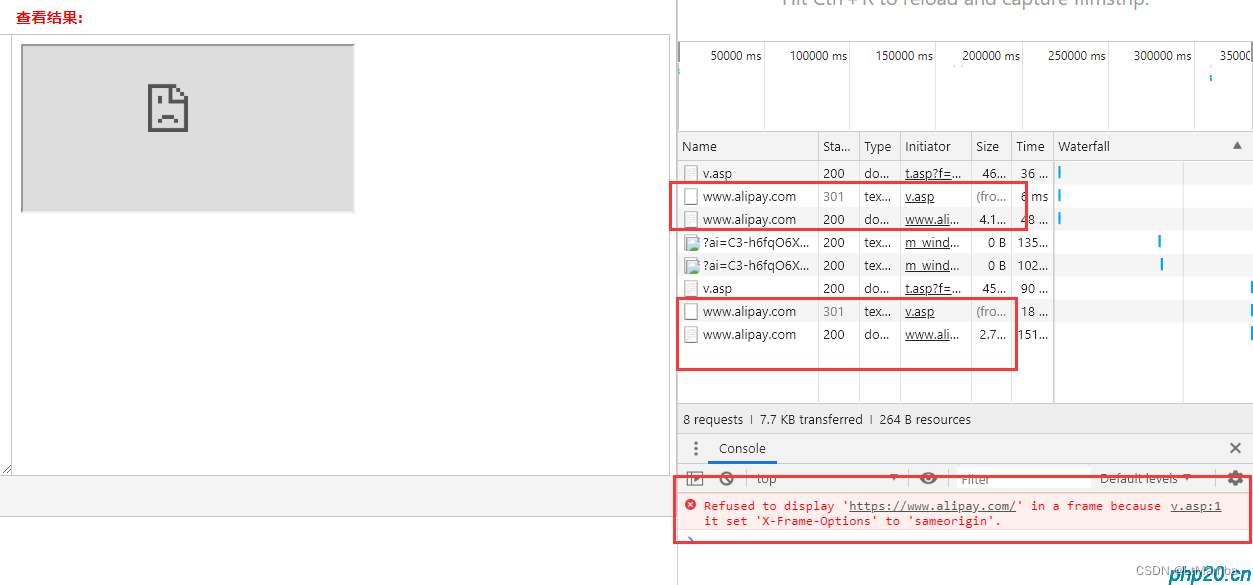
http -- 跨域问题详解(浏览器)
参考链接 参考链接 1. 跨域报错示例 Access to XMLHttpRequest at http://127.0.0.1:3000/ from origin http://localhost:3000 has been blocked by CORS policy: Response to preflight request doesnt pass access control check: No Access-Control-Allow-Origin header…...
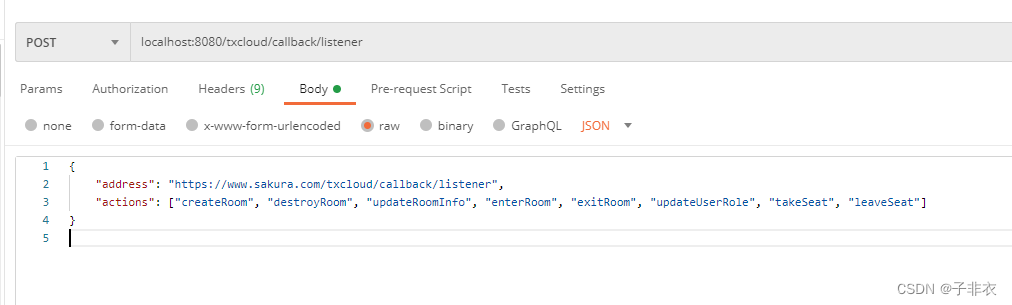
Java对接腾讯多人音视频房间回调接口示例
在前面我们已经对接好了腾讯多人音视频房间相关内容:Java对接腾讯多人音视频房间示例 为了完善业务逻辑,我们还需要对接它的一些回调接口 官方文档地址 主要就下面这些 这里因为比较简单直接上代码 里面有些工具类和上一章一样这里就没贴,需要…...

2026年搜索引擎大变革:生成式优化解决方案引领新潮流
引言随着ChatGPT、Google AI概览等工具成为主流搜索界面,传统的SEO策略已难以适配新时代的挑战。生成式引擎优化(GEO)应运而生,成为企业在线上生存与优化的新选择。本文将探讨2026年SEO行业格局的变化,分析GEO的核心逻…...

终极OFD转PDF指南:3分钟掌握免费开源转换工具Ofd2Pdf的完整教程
终极OFD转PDF指南:3分钟掌握免费开源转换工具Ofd2Pdf的完整教程 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 你是否经常遇到OFD格式文件无法打开的困扰?无论是电子发票、政…...

【Gemini Pro高级功能解锁指南】:20年AI工程师亲测的5个隐藏技巧,90%开发者至今未用
更多请点击: https://intelliparadigm.com 第一章:Gemini Pro高级功能解锁指南 Gemini Pro 作为 Google 推出的高性能多模态大模型,其高级功能远超基础文本生成。通过官方 API 与 SDK 的深度集成,开发者可启用结构化输出、多轮上…...

【Midjourney Holga风格权威调参手册】:基于1,843组实测Prompt的色偏校准模型与动态暗角衰减公式
更多请点击: https://intelliparadigm.com 第一章:Holga风格的视觉基因解码与Midjourney适配原理 Holga相机以其塑料镜头、不可控漏光、边缘暗角与柔和色散著称,构成了一套独特的“模拟故障美学”语言。将这种物理成像缺陷转化为AI生成语义&…...

音乐解锁终极指南:打破平台限制,释放你的音乐收藏
音乐解锁终极指南:打破平台限制,释放你的音乐收藏 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址…...

不精确计算:芯片设计中的功耗优化与精度权衡技术
1. 不精确计算:从学术概念到芯片设计的功耗革命在移动设备、物联网终端和边缘计算节点无处不在的今天,功耗已经取代了单纯的性能,成为许多芯片设计的首要约束。我们习惯了处理器以全精度、零误差的方式执行每一条指令,但你是否想过…...

为什么数据科学家都爱用Spyder?这6个独特优势让你告别Python开发烦恼! [特殊字符]
为什么数据科学家都爱用Spyder?这6个独特优势让你告别Python开发烦恼! 😊 【免费下载链接】spyder Official repository for Spyder - The Scientific Python Development Environment 项目地址: https://gitcode.com/gh_mirrors/sp/spyder…...

5步实现Cursor Pro永久免费:终极破解工具完整指南
5步实现Cursor Pro永久免费:终极破解工具完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...
)
保姆级教程:用Sigrity PowerSI提取5GHz内单端S参数(附DDR4仿真实例)
从零掌握Sigrity PowerSI:5GHz单端S参数提取与DDR4实战解析 在高速PCB设计中,信号完整性问题往往成为工程师的"隐形杀手"。当DDR4内存接口速率突破2400MHz时,传统时域分析方法已难以捕捉信号在传输过程中的微妙变化。散射参数&…...
)
Hydrin 1 ([Arg8, Gly10, Lys11, Arg12]-Vasotocin)
一、基础信息多肽名称:Hydrin 1,加压催产素变体 [Arg8, Gly10, Lys11, Arg12]-Vasotocin 三字母序列:Cys-Tyr-Ile-Gln-Asn-Cys-Pro-Arg-Gly-Gly-Lys-Arg 单字母序列:CYIQNCPRG GKR 氨基酸数目:12 aa 结构特征ÿ…...