大型语言模型:RoBERTa — 一种稳健优化的 BERT 方法
一、介绍
BERT模型的出现BERT模型带来了NLP的重大进展。 BERT 的架构源自 Transformer,它在各种下游任务上取得了最先进的结果:语言建模、下一句预测、问答、NER标记等。
尽管 BERT 性能出色,研究人员仍在继续尝试其配置,希望获得更好的指标。幸运的是,他们成功了,并提出了一种名为 RoBERTa 的新模型 - 鲁棒优化的 BERT 方法。
在本文中,我们将参考官方 RoBERTa 论文,其中包含有关模型的深入信息。简而言之,RoBERTa 对原始 BERT 模型进行了多项独立改进——包括架构在内的所有其他原则保持不变。本文将介绍和解释所有的进步。
二、动态遮蔽
从 BERT 的架构中我们记得,在预训练期间,BERT 通过尝试预测一定百分比的屏蔽标记来执行语言建模。原始实现的问题在于,为不同批次的给定文本序列选择的掩码标记有时是相同的。
更准确地说,训练数据集被复制 10 次,因此每个序列仅以 10 种不同的方式进行屏蔽。请记住,BERT 运行 40 个训练周期,具有相同掩码的每个序列都会传递给 BERT 四次。研究人员发现,使用动态掩码效果稍好,这意味着每次将序列传递给 BERT 时都会唯一生成掩码。总体而言,这会减少训练期间的重复数据,从而使模型有机会处理更多不同的数据和屏蔽模式。

静态掩蔽与动态掩蔽
三、下一句预测
该论文的作者进行了研究,寻找对下一个句子预测任务进行建模的最佳方法。结果,他们发现了一些有价值的见解:
- 删除下一个句子的预测损失会带来稍微更好的性能。
- 与传递由多个句子组成的序列相比,将单个自然句子传递到 BERT 输入会损害性能。解释这种现象的最可能的假设之一是模型很难仅依靠单个句子来学习远程依赖关系。
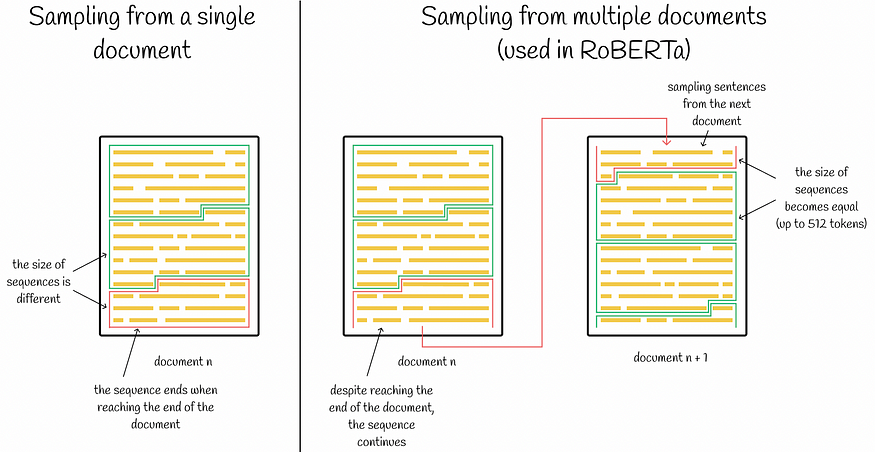
- 通过从单个文档而不是多个文档中采样连续的句子来构造输入序列更有利 。 通常,序列始终由单个文档的连续完整句子构建,因此总长度最多为 512 个标记。当我们到达文档末尾时,问题就出现了。在这方面,研究人员比较了是否值得停止对此类序列进行句子采样,或者额外采样下一个文档的前几个句子(并在文档之间添加相应的分隔符标记)。结果表明第一种方案效果较好。
最终,对于最终的 RoBERTa 实现,作者选择保留前两个方面并省略第三个方面。尽管观察到第三个见解背后的改进,但研究人员并没有继续下去,因为否则,它会使之前的实现之间的比较更加成问题。发生这种情况的原因是,到达文档边界并停在那里意味着输入序列将包含少于 512 个标记。为了在所有批次中具有相似数量的令牌,在这种情况下需要增加批次大小。这导致批量大小可变和研究人员希望避免的更复杂的比较。
四、增加批量大小
NLP 的最新进展表明,增加批量大小并适当降低学习率和训练步骤数通常会提高模型的性能。
提醒一下,BERT 基础模型是在 256 个序列的批量大小上训练一百万步的。作者尝试在 2K 和 8K 的批量大小上训练 BERT,并选择后者来训练 RoBERTa。相应的训练步数和学习率值分别变为31K和1e-3。
同样重要的是要记住,通过一种称为“梯度累积”的特殊技术,批量大小的增加会导致更容易的并行化。< /span>
五、字节文本编码
在 NLP 中,存在三种主要类型的文本标记化:
- 字符级标记化
- 子字级标记化
- 词级标记化
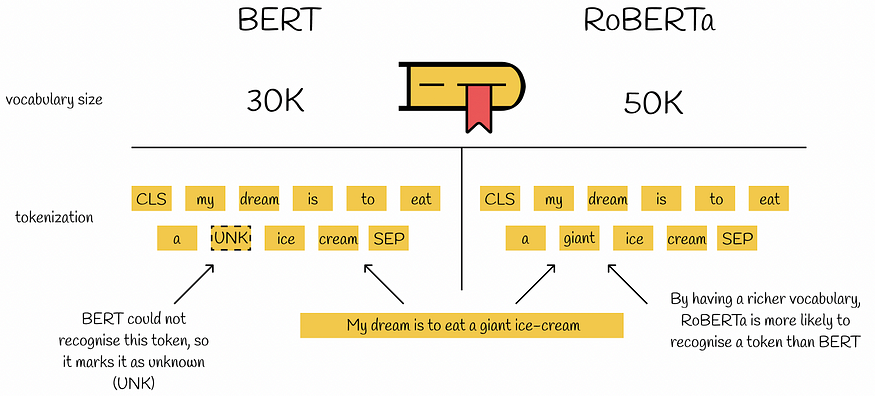
原始 BERT 使用词汇大小为 30K 的子字级标记化,这是在输入预处理和使用多种启发式之后学习的。 RoBERTa 使用字节而不是 unicode 字符作为子词的基础,并将词汇量扩展至 50K,无需任何预处理或输入标记化。这导致 BERT 基础模型和 BERT 大模型分别增加 15M 和 20M 的额外参数。 RoBERTa 中引入的编码版本表现出比以前稍差的结果。
尽管如此,与 BERT 相比,RoBERTa 词汇量大小的增长允许在不使用未知标记的情况下对几乎任何单词或子词进行编码。这给 RoBERTa 带来了相当大的优势,因为该模型现在可以更全面地理解包含稀有单词的复杂文本。
六、预训练
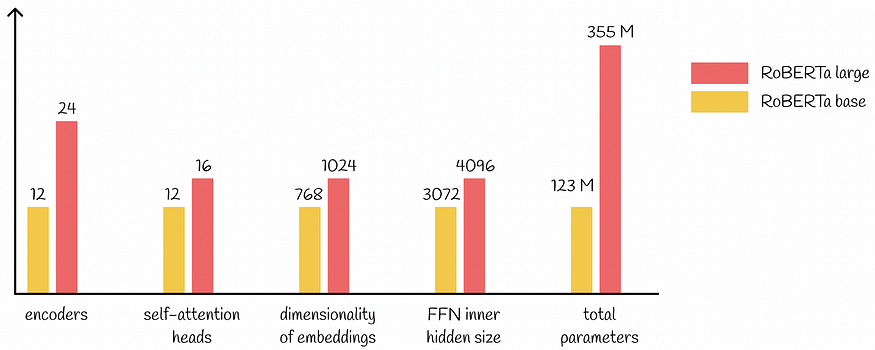
除此之外,RoBERTa 应用了上述所有四个方面,并具有与 BERT Large 相同的架构参数。 RoBERTa的参数总数为355M。
RoBERTa 在五个海量数据集的组合上进行了预训练,产生总共 160 GB 的文本数据。相比之下,BERT Large 仅在 13 GB 数据上进行预训练。最后,作者将训练步骤数从 100K 增加到 500K。
因此,在最流行的基准测试中,RoBERTa 在 XLNet Large 上的表现优于 BERT Large。
七、RoBERTa 版本
与 BERT 类似,研究人员开发了两个版本的 RoBERTa。基本版本和大版本中的大多数超参数是相同的。下图展示了主要区别:
RoBERTa 中的微调过程与 BERT 类似。
八、结论
在本文中,我们研究了 BERT 的改进版本,它通过引入以下几个方面来修改原始训练过程:
- 动态掩蔽
- 省略下一句预测目标
- 较长句子的训练
- 增加词汇量
- 使用更大批量的数据进行更长时间的训练
由此产生的 RoBERTa 模型在顶级基准测试中似乎优于其祖先。尽管配置更复杂,RoBERTa 仅添加了 15M 额外参数,保持了与 BERT 相当的推理速度。
相关文章:
大型语言模型:RoBERTa — 一种稳健优化的 BERT 方法
slavahead 一、介绍 BERT模型的出现BERT模型带来了NLP的重大进展。 BERT 的架构源自 Transformer,它在各种下游任务上取得了最先进的结果:语言建模、下一句预测、问答、NER标记等。 尽管 BERT 性能出色,研究人员仍在继续尝试其配置࿰…...
webpack知识点总结(基础应用篇)
一、为什么需要webpack 1.为什么使用webpack ①传统的书写方式,加载太多脚本会导致网络瓶颈,如不小心改变JavaScript文件加载顺序,项目会崩溃,还会导致作用域问题、js文件太大无法做到按需加载、可读性和可维护性太低的问题。 ②…...
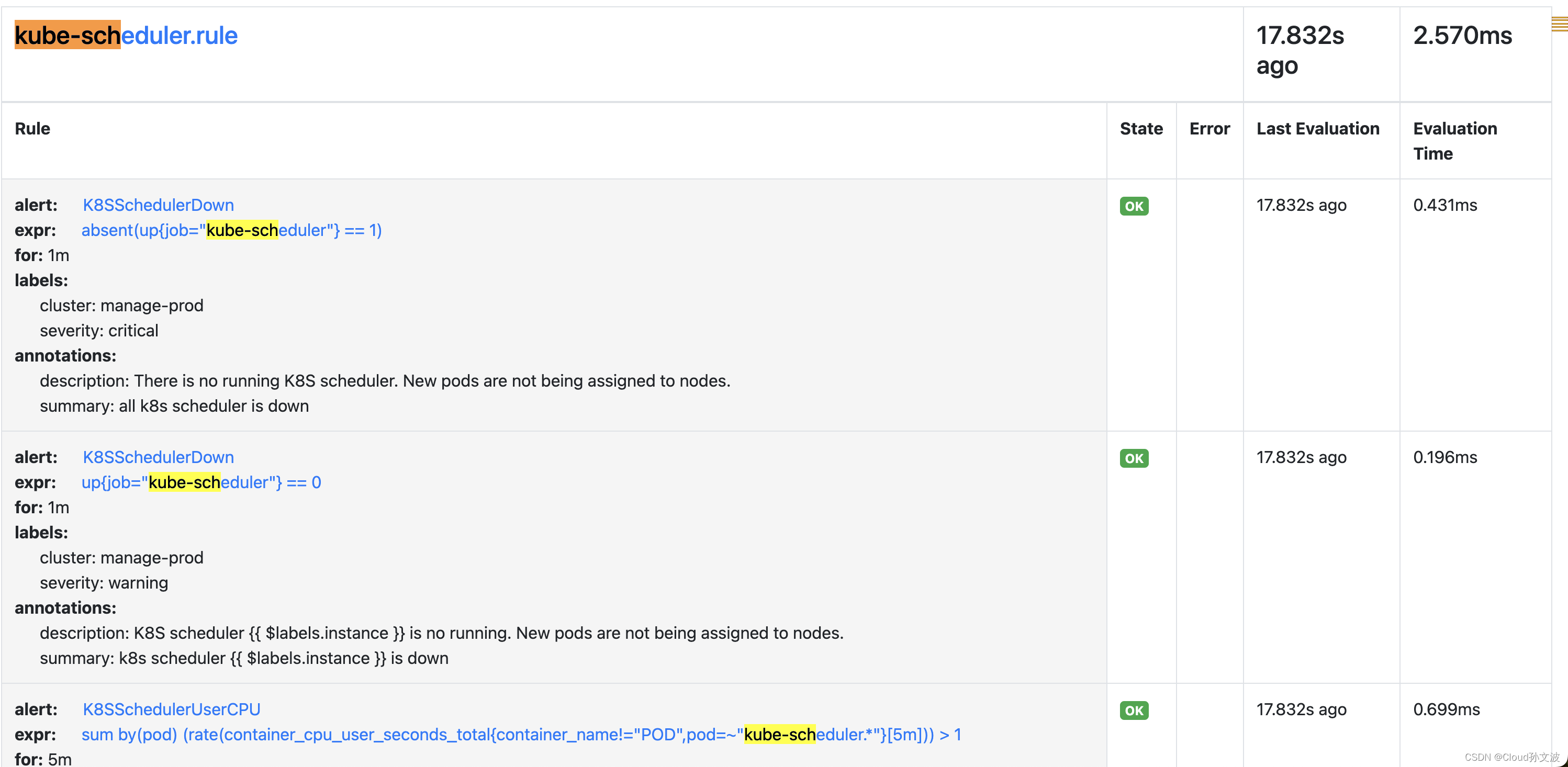
监控k8s controller和scheduler,创建serviceMonitor以及Rules
目录 一、修改kube-controller和kube-schduler的yaml文件 二、创建service、endpoint、serviceMonitor 三、Prometheus验证 四、创建PrometheusRule资源 五、Prometheus验证 直接上干货 一、修改kube-controller和kube-schduler的yaml文件 注意:修改时要一个节…...
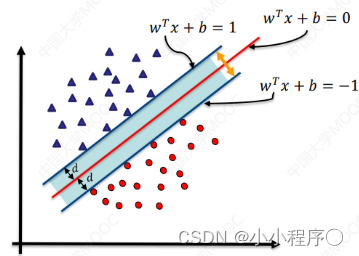
支持向量机 支持向量机概述
支持向量机概述 支持向量机 Support Vector MachineSVM ) 是一类按监督学习 ( supervisedlearning)方式对数据进行二元分类的广义线性分类器 (generalized linear classifier) ,其决策边界是对学习样本求解的最大边距超亚面 (maximum-margin hyperplane)与逻辑回归和…...
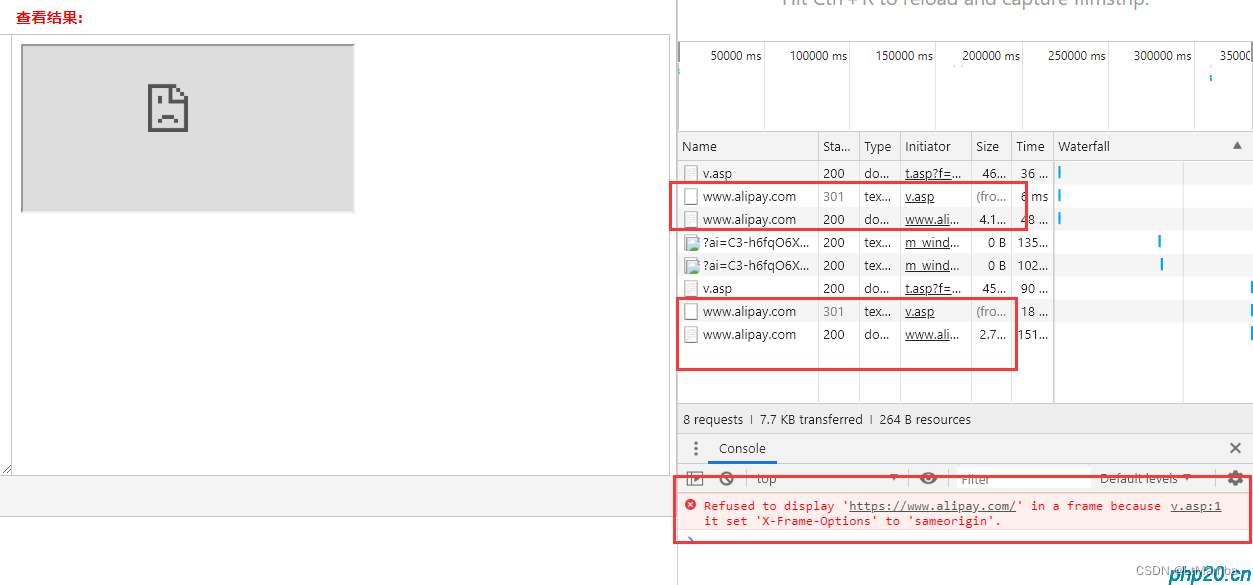
http -- 跨域问题详解(浏览器)
参考链接 参考链接 1. 跨域报错示例 Access to XMLHttpRequest at http://127.0.0.1:3000/ from origin http://localhost:3000 has been blocked by CORS policy: Response to preflight request doesnt pass access control check: No Access-Control-Allow-Origin header…...
Java对接腾讯多人音视频房间回调接口示例
在前面我们已经对接好了腾讯多人音视频房间相关内容:Java对接腾讯多人音视频房间示例 为了完善业务逻辑,我们还需要对接它的一些回调接口 官方文档地址 主要就下面这些 这里因为比较简单直接上代码 里面有些工具类和上一章一样这里就没贴,需要…...
vp与vs联合开发-通过FrameGrabber连接相机
添加控件 1.CogRecordDisplay 控件 用于显示图像 初始化相机对象方法 //启动窗体时 调用初始化相机方法 //封装相机关闭方法 //窗体关闭时 调用相机关闭方法 拍照 设置采图事件 // 保存图像 设置曝光按钮事件 1.可变参数...
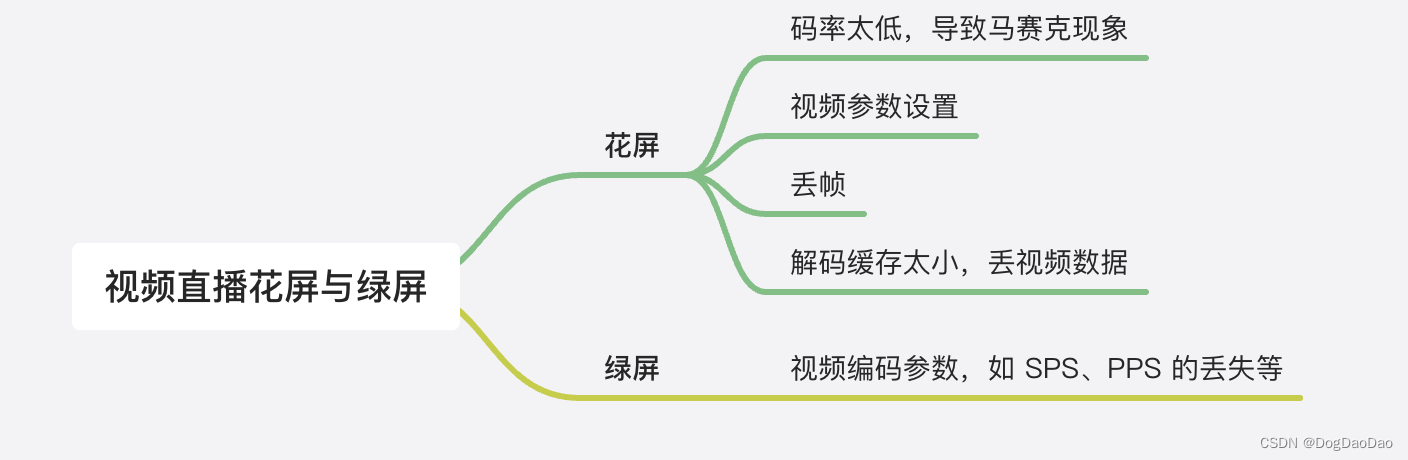
音视频直播核心技术介绍
直播流程 采集: 是视频直播开始的第一个环节,用户可以通过不同的终端采集视频,比如 iOS、Android、Mac、Windows 等。 前处理:主要就是美颜美型技术,以及还有加水印、模糊、去噪、滤镜等图像处理技术等等。 编码&#…...
JNDI注入Log4jFastJson白盒审计不回显处理
目录 0x00 前言 0x01 Maven 仓库及配置 0x02 JNDI 注入简介 0x03 Java-第三方组件-Log4J&JNDI 0x04 Java-第三方组件-FastJson&反射 0x05 白盒审计 - FastJson 0x06 白盒审计 - Log4j 0x07 不回显的处理方法 0x00 前言 希望和各位大佬一起学习,如果…...

FPGA实现腐蚀和膨胀算法verilog设计及仿真 加报告
要在FPGA上实现腐蚀和膨胀算法,你可以按照以下步骤进行: 图像存储:首先,你需要设计一个图像存储器来存储待处理的图像数据。这可以采用FPGA内部存储器或外部存储器。 读取图像数据:使用适当的接口从图像存储器中读取图像数据,并将其加载到FPGA的计算单元中。 结构元素定义…...

核和值域的关系:什么是矩阵的秩?
核和值域的关系:什么是矩阵的秩? 这篇博客将介绍一个任意矩阵的核和值域的关系,并由此说明矩阵秩的意义、子空间维数、子空间正交。 1、矩阵的核:N(A) A ∈ C m n A\in C^{m\times n} A∈Cmn,矩阵的核,记…...

【MyBatis Plus】Service Mapper内置接口讲解
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《MyBatis-Plus》。🎯🎯 &am…...
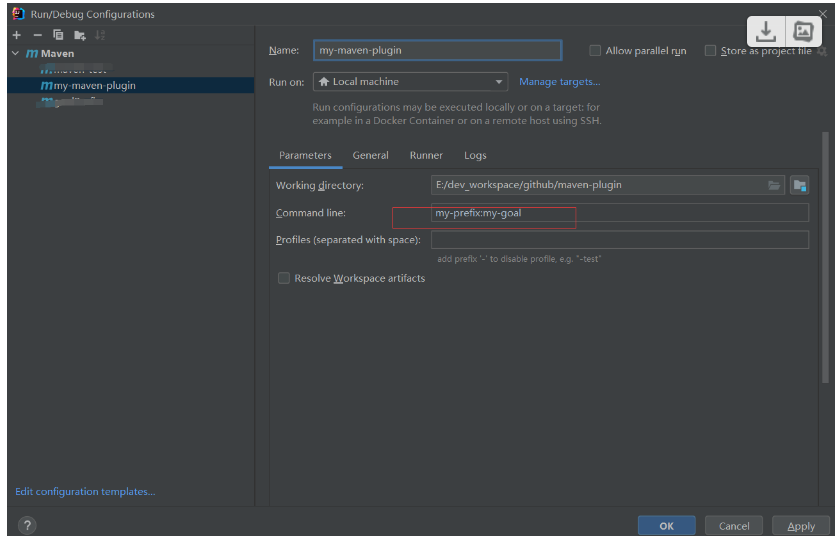
制作一个简单 的maven plugin
流程 首先, 你需要创建一个Maven项目,推荐用idea 创建项目 会自动配置插件 pom.xml文件中添加以下配置: <project> <!-- 项目的基本信息 --> <groupId>com.example</groupId> <artifactId>my-maven-plugi…...
基于linux系统的Tomcat+Mysql+Jdk环境搭建(三)centos7 安装Tomcat
Tomcat下载官网: Apache Tomcat - Which Version Do I Want? JDK下载官网: Java Downloads | Oracle 中国 如果不知道Tomcat的哪个版本应该对应哪个版本的JDK可以打开官网,点击Whitch Version 下滑,有低版本的,如…...

Ubuntu环境下SomeIP/CommonAPI环境搭建详细步骤
环境搭建 1.Boost安装 下载Boost源码 : https://www.boost.org/users/download/ 编译安装 首先安装编译所需依赖 sudo apt-get install build-essential g sudo apt-get install installpython-dev autotools-dev sudo apt-get install installlibicu-dev buil…...
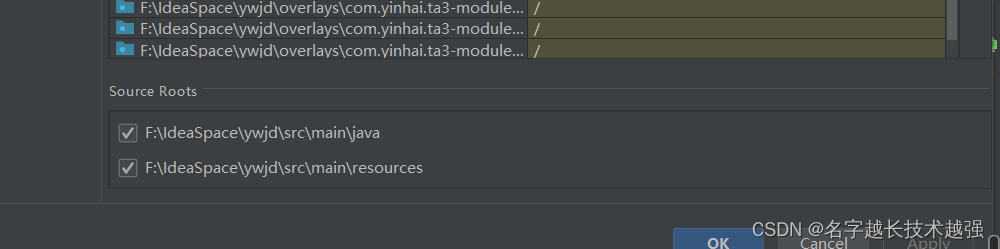
maven 项目导入异常问题
问题如下 一、 tomcat正再运行的包是哪一个 不同构建、打包情况下分别运行 out\artifacts下 当直接去Project Structure下去构建artifacts 后,运行tomcat 则会在out下target下 reimport项目后,则会在artifacts自动生成部署包。删除tomcat之前deployment 下的包(同…...

在 VMware 虚拟机上安装黑苹果(Hackintosh):免费 macOS ISO 镜像下载及安装教程
在 VMware 虚拟机上安装黑苹果(Hackintosh):免费 macOS ISO 镜像下载及安装教程 VMware 虚拟机解锁 macOS 安装选项使用 macOS iso 系统镜像安装使用 OpenCore 做引导程序安装 在 VMware 虚拟机上安装黑苹果(Hackintosh):免费 macOS ISO 镜像下载及安装…...
国产ToolLLM的课代表---OpenBMB机构(清华NLP)旗下ToolBench的安装部署与运行(附各种填坑说明)
ToolBench项目可以理解为一个能直接提供训练ToolLLM的平台,该平台同时构建了ToolLLM的一个开源训练指令集。,该项目是OpenBMB机构(面壁智能与清华NLP联合成立)旗下的一款产品,OpenBMB机构名下还同时拥有另外一款明星产…...
-C#串口通信数据接收不完整解决方案)
串口通信(5)-C#串口通信数据接收不完整解决方案
本文讲解C#串口通信数据接收不完整解决方案。 目录 一、概述 二、Modbus RTU介绍 三、解决思路 四、实例 一、概述 串口处理接收数据是串口程序编写的关键...

大数据分析岗是干什么的?
大数据分析岗主要负责从大规模数据集中提取、整理、分析和解释有关业务、市场或其他相关领域的信息的职位。 主要的职责和工作内容如下: 1. 数据收集和整理 收集各种数据源(包括结构化、非结构化和半结构化数据),并将其整理成可…...

从栅格到矢量:基于ArcScan的河道中心线智能提取与精度优化实践
1. 从栅格到矢量的技术背景 河道中心线提取是水文分析中的基础性工作。传统人工勾绘方式效率低下,一条10公里长的河道可能需要耗费专业人员半天时间。而基于ArcScan的自动化提取方法,能将这个时间缩短到10分钟以内,同时保证亚米级精度。 我在…...

AI提示词工程:用Claude+Cursor构建高效创意工作流
1. 项目概述:当创意遇上AI,一个提示词库如何改变工作流如果你是一位创意工作者——无论是设计师、插画师、文案策划还是视频创作者,最近几个月,你的工作流里可能多了一个新伙伴:Claude。这个由Anthropic推出的AI助手&a…...

Xshell6启动报错0xc000007b:从DLL缺失到Visual C++库修复的完整排障指南
1. 当Xshell6突然罢工:0xc000007b报错初体验 那天早上我像往常一样双击Xshell6图标,准备连接服务器,结果突然弹出一个冰冷的错误窗口:"应用程序无法正常启动(0xc000007b)"。这种系统级错误代码对很多Windows用户来说就…...

如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南
如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南 【免费下载链接】ChatGLM3 ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGLM3 ChatGLM3作为开源双语对话语言…...

如何在iOS设备上快速安装TrollStore:TrollInstallerX完整使用指南
如何在iOS设备上快速安装TrollStore:TrollInstallerX完整使用指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14.0到16.6…...

一文看懂:什么是大语言模型
在过去很长一段时间里,计算机只是“执行命令的工具”。但这两年,一种新的技术正在改变这一切——它不仅能理解人类语言,还能写文章、写代码,甚至和你对话。从 ChatGPT 到 DeepSeek,再到 Claude 和 Gemini,“…...

意法半导体权力交接:从博佐蒂到谢里的战略延续与挑战
1. 从Bozotti到Chery:一场静水深流的权力交接在半导体这个以技术迭代和资本狂热著称的行业里,权力更迭往往伴随着戏剧性的股价波动、战略急转弯或是人事地震。然而,2018年5月31日,当意法半导体(STMicroelectronics NV&…...

5分钟搞定B站视频数据分析:让数据采集变得像点外卖一样简单
5分钟搞定B站视频数据分析:让数据采集变得像点外卖一样简单 【免费下载链接】Bilivideoinfo Bilibili视频数据爬虫 精确爬取完整的b站视频数据,包括标题、up主、up主id、精确播放数、历史累计弹幕数、点赞数、投硬币枚数、收藏人数、转发人数、发布时间、…...
)
Linux内核开发避坑:你的kmalloc申请到底浪费了多少内存?(附slab/slub实战分析)
Linux内核内存优化实战:kmalloc申请背后的隐藏成本与调优策略 在性能敏感的内核模块开发中,每个字节的内存使用都可能成为系统瓶颈的导火索。我曾亲眼见证过一个网络驱动模块因为不当的kmalloc调用模式,导致系统在高压下额外消耗了12%的内存—…...

ZimaOS Blue:本地优先AI代理运行时,打造私有化智能助手
1. 项目概述:ZimaOS Blue,一个为“大胆构建者”准备的本地优先AI代理运行时 如果你和我一样,对当前AI应用生态里那些动辄需要联网、依赖特定云服务、数据隐私存疑的“智能助手”感到厌倦,同时又渴望一个能真正运行在自己设备上、…...