机器学习中的一些经典理论定理
PAC学习理论
当使用机器学习方法来解决某个特定问题时,通常靠经验或者多次试验来选择合适的模型、训练样本数量以及学习算法收敛的速度等。但是经验判断或多次试验往往成本比较高,也不太可靠,因此希望有一套理论能够分析问题难度、计算模型能力,为学习算法提供理论保证,并指导机器学习模型和学习算法的设计,这就是计算学习理论。计算学习理论是机器学习的理论基础,其中最基础的理论就是可能近似正确学习理论。
机器学习中一个很关键的问题是期望错误和经验错误之间的差异,称为泛化错误。泛化错误可以衡量一个机器学习模型𝑓 是否可以很好地泛化到未知数据。

根据大数定律,当训练集大小|𝒟|趋向于无穷大时,泛化错误趋向于0,即经验风险趋近于期望风险。

由于我们不知道真实的数据分布 𝑝(𝒙, 𝑦),也不知道真实的目标函数 𝑔(𝒙),因此期望从有限的训练样本上学习到一个期望错误为0的函数𝑓(𝒙)是不切实际的。因此,需要降低对学习算法能力的期望,只要求学习算法可以以一定的概率学习到一个近似正确的假设,即PAC 学习。一个PAC 可学习的算法是指该学习算法能够在多项式时间内从合理数量的训练数据中学习到一个近似正确的𝑓(𝒙)。
PAC学习可以分为两部分:
(1) 近似正确:一个假设𝑓 ∈ ℱ 是“近似正确”的,是指其在泛化错误𝒢𝒟(𝑓)小于一个界限𝜖。𝜖一般为0到 1/2之间的数,0 < 𝜖 <1/2。如果𝒢𝒟(𝑓)比较大,说明模型不能用来做正确的“预测”。
(2) 可能:一个学习算法𝒜 有“可能”以1 − 𝛿 的概率学习到这样一个“近似正确”的假设。𝛿 一般为0到 1/2之间的数,0 < 𝛿 < 1/2。
PAC学习可以下面公式描述:

其中𝜖,𝛿 是和样本数量𝑁 以及假设空间ℱ 相关的变量。如果固定𝜖,𝛿,可以反过来计算出需要的样本数量
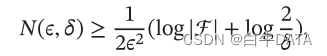
其中|ℱ|为假设空间的大小.从上面公式可以看出,模型越复杂,即假设空间ℱ 越大,模型的泛化能力越差。要达到相同的泛化能力,越复杂的模型需要的样本数量越多。为了提高模型的泛化能力,通常需要正则化(Regularization)来限制模型复杂度。
PAC学习理论也可以帮助分析一个机器学习方法在什么条件下可以学习到一个近似正确的分类器。从上面的公式可以看出,如果希望模型的假设空间越大,泛化错误越小,其需要的样本数量越多。
没有免费午餐定理
没有免费午餐定理证明:对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差.也就是说,不能脱离具体问题来谈论算法的优劣,任何算法都有局限性.必须要“具体问题具体分析”。
没有免费午餐定理对于机器学习算法也同样适用。不存在一种机器学习算法适合于任何领域或任务.如果有人宣称自己的模型在所有问题上都好于其他模型,那么他肯定是在吹牛。
奥卡姆剃刀原理
奥卡姆剃刀原理是由14世纪逻辑学家William of Occam提出的一个解决问题的法则:“如无必要,勿增实体”.它的思想和机器学习中的正则化思想十分类似:简单的模型泛化能力更好。如果有两个性能相近的模型,我们应该选择更简单的模型.因此,在机器学习的学习准则上,我们经常会引入参数正则化来限制模型能力,避免过拟合。
奥卡姆剃刀的一种形式化是最小描述长度原则,即对一个数据集𝒟,最好的模型𝑓 ∈ ℱ 会使得数据集的压缩效果最好,即编码长度最小。
最小描述长度也可以通过贝叶斯学习的观点来解释。模型𝑓 在数据集𝒟 上的对数后验概率为
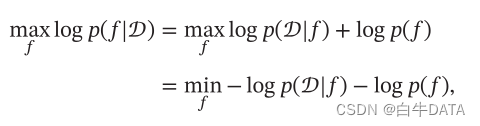
其中 log 𝑝(𝑓) 和 log 𝑝(𝒟|𝑓) 可以分别看作模型 𝑓 的编码长度和在该模型下数据集 𝒟 的编码长度。也就是说,我们不但要使得模型 𝑓 可以编码数据集 𝒟,也要使得模型𝑓 尽可能简单。
丑小鸭定理
丑小鸭定理(Ugly Duckling Theorem)是1969年由渡边慧提出的.“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”.这个定理初看好像不符合常识,但是仔细思考后是非常有道理的。因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的.如果从体型大小或外貌的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果从基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间的差别。
归纳偏置
在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置。比如在最近邻分类器中,我们会假设在特征空间中,一个小的局部区域中的大部分样本同属一类。在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是互相独立的。
归纳偏置在贝叶斯学习中也经常称为先验(Prior)。
相关文章:
机器学习中的一些经典理论定理
PAC学习理论 当使用机器学习方法来解决某个特定问题时,通常靠经验或者多次试验来选择合适的模型、训练样本数量以及学习算法收敛的速度等。但是经验判断或多次试验往往成本比较高,也不太可靠,因此希望有一套理论能够分析问题难度、计算模型能…...
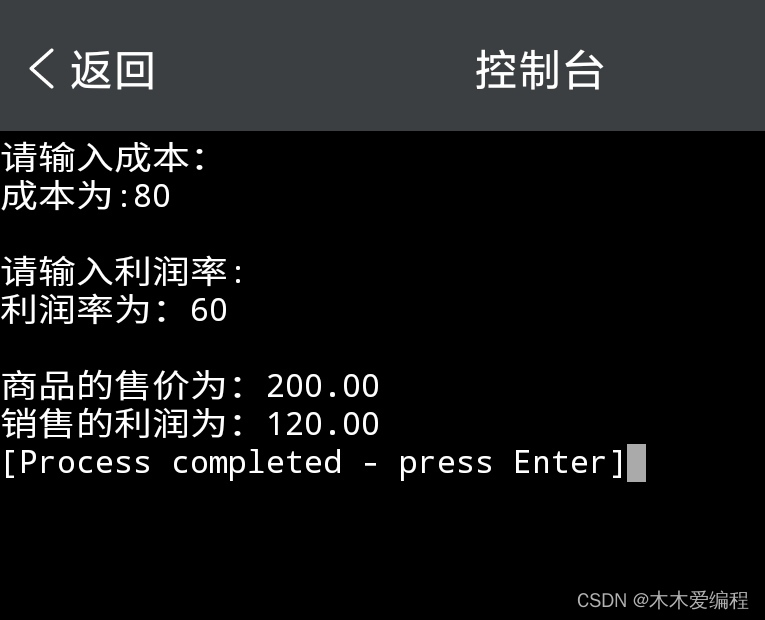
c语言:成本100元,40%的利润怎么计算|练习题
一、利润的计算公式: 利润售价-成本 售价成本/(1-利润率) 二、用c语言代码表示为: 如图: 三、计算源代码【带注释】 #include <stdio.h> int main() { float cost;//成本变量 int prof_rate;//利润率变量 float price;//…...

【Python必做100题】之第二十二题(复制列表)
题目:将一个列表的数据复制到另一个列表中 重点:确保复制到位要导入copy方法进行深度复制 代码如下: #将一个列表的数据复制到另一个列表中 import copy list [1,2,3,4] print(list) list1 copy.copy(list) list[0] 30 print(list) pri…...
Java 数据结构篇-实现堆的核心方法与堆的应用(实现 TOP-K 问题:最小 k 个数)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 堆的说明 2.0 堆的成员变量及其构造方法 3.0 实现堆的核心方法 3.1 实现堆的核心方法 - 获取堆顶元素 peek() 3.2 实现堆的核心方法 - 下潜 down(int i) 3.3 实…...

startUML6.0.1破解方法
startUML6.0.1破解方法 文章目录 startUML6.0.1破解方法1.startUML6.0.1快速破解2.概述3.安装Nodejs4.安装asar5.修改app.asar中的源码6.将修改后的源码重新压缩7.覆盖官方的asar文件8.重启startUML9.参考文档 1.startUML6.0.1快速破解 后绪步骤可以不看,直接下载我…...

Python实现多种图像分割方法:基于阈值分割和基于区域分割
Python实现多种图像分割方法:基于阈值分割和基于区域分割 图像分割是图像分析的第一步,是计算机视觉的基础,但也是图像处理中最困难的问题之一。经典的计算机视觉任务,如目标检测、图像识别等都和图像分割相关,图像分…...

SQL学习笔记+MySQL+SQLyog工具教程
文章目录 1、前言2、SQL基本语言及其操作2.1、CREATE TABLE – 创建表2.2、DROP TABLE – 删除表2.3、INSERT – 插入数据2.4、SELECT – 查询数据2.5、SELECTDISTINCT – 去除重复值后查询数据2.6、SELECTWHERE – 条件过滤2.7、AND & OR – 运算符2.8、ORDER BY – 排序2…...

SpringBoot的日志管理
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈,…...

leetcode---76. 最小覆盖子串 [C++/滑动窗口+哈希表]
原题:76. 最小覆盖子串 - 力扣(LeetCode) 题目解析: 此题在这道题的基础上进行理解会更简单 leetcode --- 30. 串联所有单词的子串[C 滑动窗口/双指针]-CSDN博客 本题要求在s字符串中找到含有t字符串所有字符的最短子串。 也就是…...
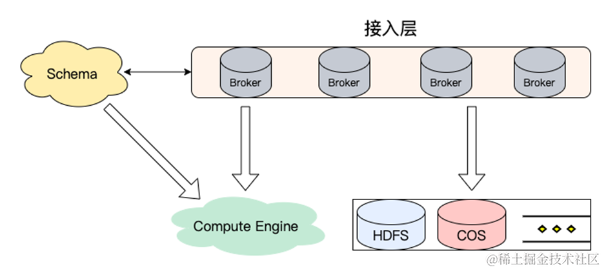
Kafka 分级存储在腾讯云的实践与演进
导语 腾讯云消息队列 Kafka 内核负责人鲁仕林为大家带来了《Kafka 分级存储在腾讯云的实践与演进》的精彩分享,从 Kafka 架构遇到的问题与挑战、Kafka 弹性架构方案类比、Kafka 分级存储架构及原理以及腾讯云的落地与实践四个方面详细分享了 Kafka 分级存储在腾讯云…...
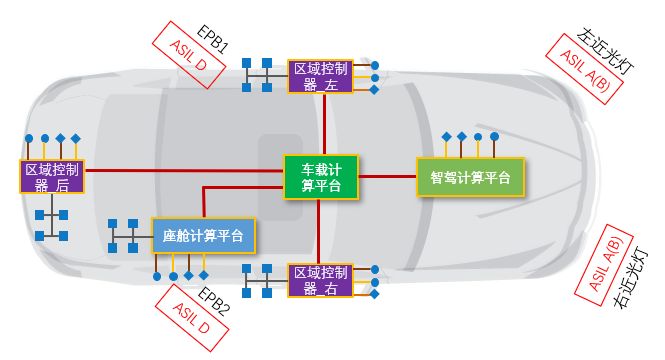
域架构下的功能安全思考
来源:联合电子 随着整车电子电气架构的发展,功能域控架构向整车集中式区域控制演进。新的区域控制架构下,车身控制模块(BCM),整车控制单元(VCU),热管理系统(TMS)和动力底…...

python多线程介绍
每个库或模块都有其特定的用途和优势,选择哪一个取决于具体的任务需求、计算资源。一般可以将任务分成两类: I/O 密集型任务:这些任务的瓶颈主要在于等待外部操作,如磁盘读写或网络通信。在这些等待期间,CPU 大部分时间…...

征文榜单 | 腾讯云向量数据库获奖名单公布
为了帮助开发者更快、更便捷地构建应用程序,有效提高开发人员生产力,腾讯云推出了AI原生向量数据库。它能提供全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据,是国内首个从接入层、计算层、到存储层提供…...
如何预防[[MyFile@waifu.club]].wis [[backup@waifu.club]].wis勒索病毒感染您的计算机?
导言: 近期,一种新兴的威胁[[MyFilewaifu.club]].wis [[backupwaifu.club]].wis勒索病毒,引起了广泛关注。这种恶意软件通过其高度复杂的加密算法,威胁着用户和组织的数据安全。本文将深入介绍[[MyFilewaifu.club]].wis [[backup…...

中国风春节倒计时【实时倒计时】
<head><meta charset="UTF-8"><meta name="apple-mobile-web-app-title...

基于RBAC的k8s集群权限管控案例
在日常的kubernetes集群维护过程中,常常涉及多团队协作,不同的团队有不同的操作和权限需求。比如,运维团队需要有node的所有操作权限,以便对集群进行节点的扩缩容等日常维护工作,但资产运营团队通常只需要node的查看权…...

【华为数据之道学习笔记】5-11 算法模型设计
算法是指训练、学习模型的具体计算方法,也就是如何求解全局最优解,并使得这个过程高效且准确,其本质上是求数学问题的最优化解,即算法是利用样本数据生成模型的方法。算法模型是根据业务需求,运用数学方法对数据进行建…...

Flink系列之:SELECT WHERE clause
Flink系列之:SELECT & WHERE clause 一、SELECT & WHERE clause二、SELECT DISTINCT 适用于流、批 一、SELECT & WHERE clause SELECT 语句的一般语法是: SELECT select_list FROM table_expression [ WHERE boolean_expression ]table_e…...

C#基础——委托、Action和Func的使用
1、委托 委托(Delegate)是一种类型,可以用来表示对一个或多个方法的引用。委托提供了一种方便的方式来将方法作为参数传递给其他方法,或将方法存储在数据结构中以供以后调用。 不带参数且没返回值的委托 delegate void HDLDelega…...
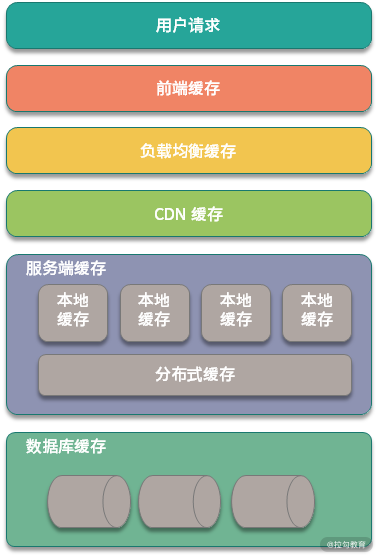
不止业务缓存,分布式系统中还有哪些缓存?
缓存是分布式系统开发中的常见技术,在分布式系统中的缓存,不止 Redis、Memcached 等后端存储;在前端页面、浏览器、网络 CDN 中也都有缓存的身影。 缓存有哪些分类 如果你是做业务开发的话,提起缓存首先想到的应该是应用 Redis&…...

Arm Forge工具链在HPC中的调试与性能优化实践
1. Arm Forge工具链概述高性能计算(HPC)领域的开发者经常面临并行程序调试和性能优化的挑战。Arm Forge作为一套集成化工具平台,包含了三个核心组件:DDT并行调试器、MAP性能分析器和Performance Reports报告生成工具。这套工具链特别适合处理MPI、OpenMP…...

Harbor:统一管理MCP服务器,告别AI助手配置混乱
1. 项目概述:Harbor,一个管理MCP服务器的统一中心如果你和我一样,在日常开发中深度依赖Claude、Cursor这类AI编程助手,那你一定对MCP(Model Context Protocol)服务器不陌生。简单来说,MCP服务器…...

汉字可视化探索平台:基于Flask+Vue的汉字浏览系统架构与实现
1. 项目概述:一个汉字学习者的“浏览器”如果你和我一样,对汉字的结构、演变和背后的文化故事着迷,那你一定经历过这样的时刻:在阅读古籍、碑帖,或者仅仅是看到一个生僻字时,心里会冒出无数个问号——这个字…...

为什么93%的DeepSeek PR被拒?揭秘CI流水线自动拦截的4类“伪Clean”代码陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么93%的DeepSeek PR被拒?揭秘CI流水线自动拦截的4类“伪Clean”代码陷阱 DeepSeek 开源仓库的 CI 流水线以严苛著称——最新统计显示,93% 的 PR 在 pre-commit 阶段即被自动…...

芯片设计人才培养:从Sondrel模式看产学合作如何弥合能力鸿沟
1. 项目背景与行业契机最近在整理行业资料时,翻到一篇十多年前的旧闻,讲的是英国一家名为Sondrel的系统级芯片设计咨询公司,与宁波诺丁汉大学合作,启动了一个针对中国学生的芯片设计人才培养项目。这件事发生在2013年,…...

数据库完整性约束与安全机制全解析
一、数据库完整性约束1、数据库完整性基本概念与核心机制(1)完整性定义与作用数据库完整性(Database Integrity)是指在任何情况下保证数据的正确性(Validity)和一致性(Consistency)&…...

3步实战UE4SS游戏Mod开发:从零构建你的第一个LUA脚本系统
3步实战UE4SS游戏Mod开发:从零构建你的第一个LUA脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4S…...

3PEAK思瑞浦 TPA3532-SO1R SOP8 运算放大器
特性 超低输入偏置电流:-在TA25C时最大土1pA(实验室测试限值)-在-40C至125C(实验室测试限值)下,最大土30皮安 低输入失调电压:250V(最大值)集成保护缓冲器,最大偏移电压200V低电压噪声密度:18nV/Hz(在1kHz时). 宽带宽:2.1MHz 供电电压:4.5V至16V(2.25V至…...

v7上线首周,93%老用户没发现的隐藏指令——高阶提示工程实战手册,含12个未公开参数调用语法
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7核心架构升级与隐性能力图谱 多模态融合推理引擎重构 Midjourney v7 引入了基于分层注意力对齐(Hierarchical Attention Alignment, HAA)的新型生成主干ÿ…...

AI赋能二进制安全:BinAIVulHunter项目实战与逆向工程集成
1. 项目概述与核心价值最近在安全圈里,一个名为BinAIVulHunter的开源项目引起了我的注意。这个项目名直译过来就是“二进制AI漏洞猎人”,光看名字就能猜到它的核心玩法:利用人工智能技术,来自动化分析二进制文件,挖掘其…...