spark-常用算子
一,Transformation变换/转换算子:
这种变换并不触发提交作业,这种算子是延迟执行的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Action操作的时候才会真正触发。
1.Value数据类型的Transformation算子
这种变换并不触发提交作业,针对处理的数据项是Value型的数据
(1)输入分区与输出分区一对一型:
1.map算子
处理数据是一对一的关系,进入一条数据,出去的还是一条数据。map的输入变换函数应用于RDD中所有的元素,而mapPartitions应用于所有分区。区别于mapPartitions主要在于调度粒度不同。如parallelize(1
to 10 ,3),map函数执行了10次,而mapPartitions函数执行了3次。
2.flatMap算子
flatMap是一对多的关系,处理一条数据得到多条结果。将原来 RDD 中的每个元素通过函数 f 转换为新的元素,并将生成的 RDD
的每个集合中的元素合并为一个集合。
3.mapPartitions算子
mapPartitions遍历的是每一个分区中的数据,一个个分区的遍历。获 取 到 每 个 分 区 的 迭 代器,在 函 数 中 通 过 这
个 分 区 整 体 的 迭 代 器 对整 个 分 区 的 元 素 进 行 操 作,相对于map一条条处理数据,性能比较高,可获取返回值。可以通过函数f(iter)
=>iter.filter(_>=3)对分区中所有的数据进行过滤,大于和等于3的数据保留,一个方块代表一个RDD分区,含有1,2,3的分区过滤,只剩下元素3。
4.mapPartitionsWithIndex算子
拿到每个RDD中的分区,以及分区中的数据
(2)输入分区与输出分区多对一型
5.union算子
合并两个RDD,两个RDD必须是同种类型,不一定是K,V格式的RDD
6.cartesian算子
求笛卡尔积,该操作不会执行shuffle操作,但最好别用,容易触发OOM
(3)输入分区与输出分区多对多型
7.groupBy算子
按照指定的规则,将数据分组
groupByKey算子
有shuffle产生, 根据key去将相同的key对应的value合并在一起(K,V)=>(K,[V])
(4)输出分区是输入分区子集类型
8.filter算子
过滤数据,返回true的数据会被留下
9.distinct算子
distinct去重,有shuffle产生,内部实际是map+reduceByKey+map实现
10.subtract算子
取RDD的差集,subtract两个RDD的类型要一致,结果RDD的分区数与subtract算子前面的RDD分区数多的一致。
11.sample算子
sample随机抽样,参数sample(withReplacement:有无放回抽样,fraction:抽样的比例,seed:用于指定的随机数生成器的种子)
有种子和无种子的区别:
有种子是只要针对数据源一样,都是指定相同的参数,那么每次抽样到的数据都是一样的
没有种子是针对同一个数据源,每次抽样都是随机抽样
(5)Cache算子
13.cache算子
将结果缓存到内存中
14.persist算子
释放内存
cache()和persist()注意问题
- 1.cache()和persist()持久化单位是partition,cache()和persist()是懒执行算子,需要action算子触发执行
- 2.对一个RDD使用cache或者persist之后可以赋值给一个变量,下次直接使用这个变量就是使用持久化的数据。 * 也可以直接对RDD进行cache或者persist,不赋值给一个变量 *
- 3.如果采用第二种方法赋值给变量的话,后面不能紧跟action算子 * 4.cache()和persist()的数据在当前application执行完成之后会自动清除
2.Key-Value 数据类型的Transformation算子
这种变换并不触发提交作业,针对处理的数据项是Key-Value型的数据对
(1)输入分区与输出分区一对一
15.mapValues算子
针对K,V格式的数据,只对Value做操作,Key保持不变
flatMapValues
(K,V)->(K,V),作用在K,V格式的RDD上,对一个Key的一个Value返回多个Value
(2)对单个RDD或者两个RDD聚集
单个RDD聚集
16.combineByKey算子
首先给RDD中每个分区中的每一个key一个初始值
其次在RDD每个分区内部相同的key聚合一次
再次在RDD不同的分区之间将相同的key结果聚合一次
17.reduceByKey算子
首先会根据key去分组,然后在每一组中将value聚合,作用在KV格式的RDD上
18.repartition算子
重新分区,可以将RDD的分区增多或者减少,会产生shuffle,coalesc(num,true) = repartition(num)
两个RDD聚集
19.cogroup算子
合并两个RDD,生成一个新的RDD。分区数与分区数多个那个RDD保持一致
(3)连接
20.join算子
会产生shuffle,(K,V)格式的RDD和(K,V)格式的RDD按照相同的K,join得到(K,(V,W))格式的数据,分区数按照大的来。
21.leftOutJoin和rightOutJoin算子、fullOuterJoin算子
leftOuterJoin(K,V)格式的RDD和(K,V)格式的RDD,使用leftOuterJoin结合,以左边的RDD出现的key为主 ,得到(K,(V,Option(W)))
rightOuterJoin(K,V)格式的RDD和(K,W)格式的RDD使用rightOuterJoin结合以右边的RDD出现的key为主,得到(K,(Option(V),W))
fullOuterJoin算子(K,V)格式的RDD和(K,V)格式的RDD,使用fullOuterJoin结合是以两边的RDD出现的key为主,得到(K(Option(V),Option(W)))
intersection算子
取两个RDD的交集,两个RDD的类型要一致,结果RDD的分区数要与两个父RDD多的那个一致
二,.Action行动算子:
这类算子会触发SparkContext提交job作业,并将数据输出到Spark系统。
(1)无输出
22.foreach算子
遍历RDD中的每一个元素
(2)HDFS
23.saveAsTextFile算子
将DataSet中的元素以文本的形式写入本地文件系统或者HDFS中,Spark将会对每个元素调用toString方法,将数据元素转换成文本文件中的一行数据,若将文件保存在本地文件系统,那么只会保存在executor所在机器的本地目录
24.saveAsObjectFile算子
将数据集中元素以ObjectFile形式写入本地文件系统或者HDFS中
(3)Scala集合和数据类型
25.collect算子
collect回收算子,会将结果回收到Driver端,如果结果比较大,就不要回收,这样的话会造成Driver端的OOM
26.collectAsMap算子
将K、V格式的RDD回收到Driver端作为Map使用
27.count,countByKey,CountByValue算子
count统计RDD共有多少行数据
countByKey统计相同的key出现的个数
countByValue统计RDD中相同的Value出现的次数,不要求数据必须为RDD格式
28.take
take取出RDD中的前N个元素
takeSapmle(withReplacement,num,seed)
随机抽样将数据结果拿回Driver端使用,返回Array,
withReplacement:有无放回抽样,num:抽样的条数,seed:种子
29.reduce算子
30.aggregateByKey算子
首先是给定RDD的每一个分区一个初始值,然后RDD中每一个分区中按照相同的key,结合初始值去合并,最后RDD之间相同的key聚合
31.zipWithIndex算子
将两个RDD合成一个K,V格式的RDD,分区数要相同,每个分区中的元素必须相同
相关文章:

spark-常用算子
一,Transformation变换/转换算子: 这种变换并不触发提交作业,这种算子是延迟执行的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Action操作的时候才会真正触发。 1.Value数据类型的Transf…...

《opencv实用探索·二十一》人脸识别
Haar级联分类器 在OpenCV中主要使用了两种特征(即两种方法)进行人脸检测,Haar特征和LBP特征。用的最多的是Haar特征人脸检测。 Haar级联分类器是一种用于目标检测的机器学习方法,它是一种基于机器学习的特征选择方法,…...

前端项目配置下载源npm, yarn,pnpm
前端项目配置下载源 npm: npm config set registry registryhttps://registry.npmmirror.com -g验证: npm config get registry yarn: yarn config set registry registryhttps://registry.npmmirror.com -gyarn config get registryyarn找不到, 需要管理员在命令行: set-exec…...

Elasticsearch之ik中文分词篇
Elasticsearch之ik中文分词篇 ik分词器插件ik分词器安装ik分词模式es ik分词测试 ik分词器插件 es在7.3版本已经支持中文分词,由于中文分词只能支持到单个字进行分词,不够灵活与适配我们平常使用习惯,所以有很多对应中文分词出现,…...

2023_Spark_实验三十:测试Flume到Kafka
实验目的:测试Flume采集数据发送到Kafka 实验方法:通过centos7集群测试,将flume采集的数据放到kafka中 实验步骤: 一、 kafka可视化工具介绍 Kafka Tool是一个用于管理和使用Apache Kafka集群的GUI应用程序。 Kafka Tool提供了…...
urllib2 HTTP头部注入
文章目录 注入原理例题 [SWPU 2016]web7 注入原理 参考文章 应用场景是具有SSRF漏洞,结合CRLF注入 我们以redis数据库为例,当存在SSRF时我们伪造以下请求 http://127.0.0.1%0d%0aCONFIG%20SET%20dir%20%2ftmp%0d%0aCONFIG%20SET%20dbfilename%20evil%…...

在 WebRTC 中,Offer/Answer 模型是协商 WebRTC 连接参数的关键部分
在 WebRTC 中,Offer/Answer 模型是协商 WebRTC 连接参数的关键部分。当 Offer 和 Answer 交换失败时,可能涉及到多个原因。以下是一些可能的问题和解决方案: SDP 格式错误: Session Description Protocol(SDPÿ…...
数据结构:图解手撕B-树以及B树的优化和索引
文章目录 为什么需要引入B-树?B树是什么?B树的插入分析B树和B*树B树B*树分裂原理 B树的应用 本篇总结的内容是B-树 为什么需要引入B-树? 回忆一下前面的搜索结构,有哈希,红黑树,二分…等很多的搜索结构&a…...
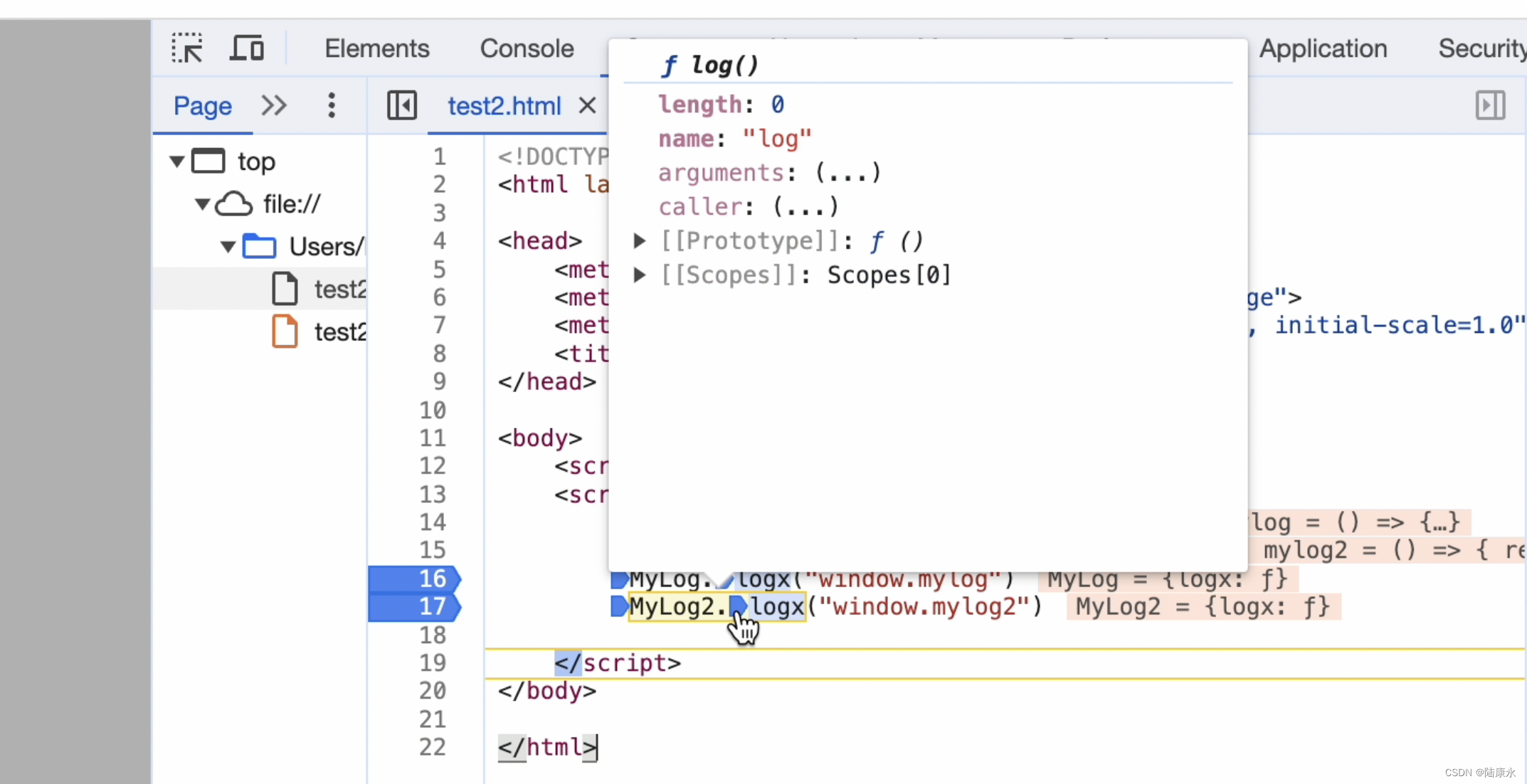
useConsole的封装,vue,react,htmlscript标签,通用
之前用了接近hack的方式实现了console的封装,目标是获取console.log函数的执行(调用栈所在位置)所在的代码行数。 例如以下代码,执行window.mylog(1)时候,console.log实际是在匿名的箭头函数()>{//这里执行的} con…...

Azure Machine Learning - 提示工程高级技术
本指南将指导你提示设计和提示工程方面的一些高级技术。 关注TechLead,分享AI全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,…...

七款创意项目管理软件解决方案推荐:高效项目管理与团队协作工具
企业无论大小,都离不开项目经理、营销团队和创意人员。他们参与各种头脑风暴,为特定目标打造项目。然而,在创意项目管理中,细节决定成败。若处理不当,可能导致项目失败和混乱。 过去,创意项目管理依赖纸质规…...
如何在公网环境下使用Potplayer访问本地群晖webdav中的影视资源
文章目录 本教程解决的问题是:按照本教程方法操作后,达到的效果是:1 使用环境要求:2 配置webdav3 测试局域网使用potplayer访问webdav3 内网穿透,映射至公网4 使用固定地址在potplayer访问webdav 国内流媒体平台的内…...

数据可视化Seaborn
数据可视化Seaborn Seaborn简介Seaborn API第一个Seaborn应用Seaborn基本概念Seaborn图表类型Seaborn数据集Seaborn样式Seaborn调色板Seaborn分面网格Seaborn统计图表Seaborn散点图Seaborn折线图Seaborn柱状图Seaborn箱线图Seaborn核密度估计图Seaborn分类散点图Seaborn回归分…...

AWS S3相关配置笔记
关闭 阻止所有公开访问 存储桶策略(开放外部访问) {"Version": "2012-10-17","Id": "S3PolicyId1","Statement": [{"Sid": "statement1","Effect": "Allow","Principal"…...

linux:linux的小动物们(ubuntu)
1.蒸汽小火车 输入下面的命令下载,再输出sl sudo apt-get install sl sl2.今天你哞了吗 apt-get moo 3.会说话的小牛 输入下面的命令下载一下 sudo apt-get install cowsay输入这个 cowsay jianbing cowsay -l 查看其它动物的名字 然后cowsay -f 跟上动物名&…...
----栈和队列--逆波兰表达式求值)
每日一题(LeetCode)----栈和队列--逆波兰表达式求值
每日一题(LeetCode)----栈和队列–逆波兰表达式求值 1.题目(150. 逆波兰表达式求值) 给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。 请你计算该表达式。返回一个表示表达式值的整数。 注意: 有效的算…...
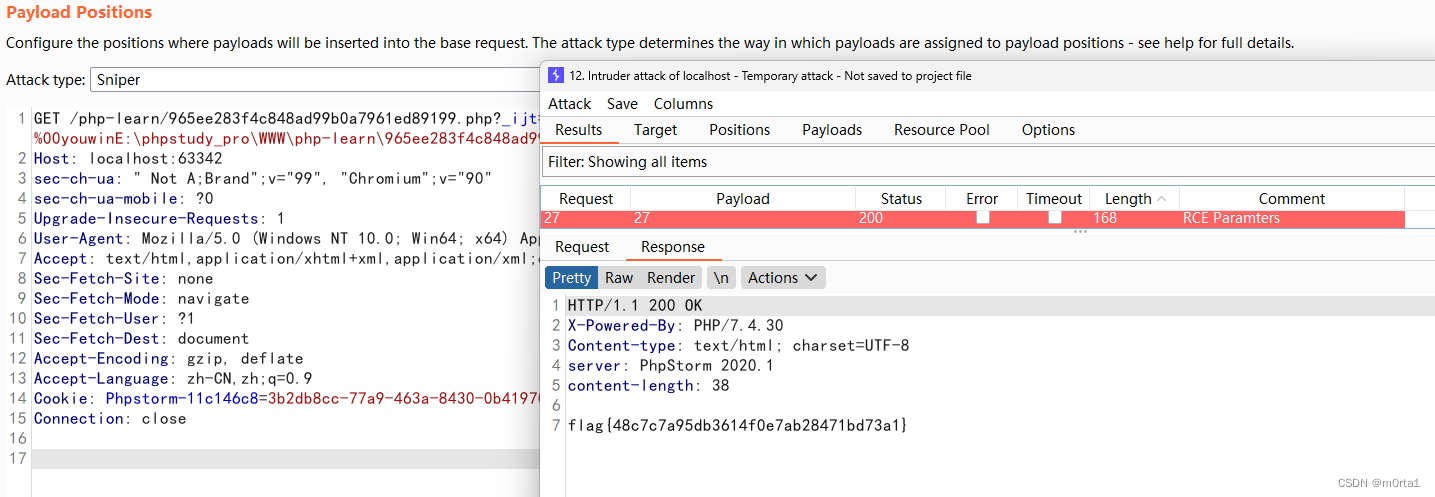
2023年第四届 “赣网杯” 网络安全大赛 gwb-web3 Write UP【PHP 临时函数名特性 + 绕过trim函数】
一、题目如下: 二、代码解读: 这段代码是一个简单的PHP脚本,它接受通过GET请求传递的两个参数:‘pass’和’func’: ① $password trim($_GET[pass] ?? );:从GET请求中获取名为’pass’的参数࿰…...
软件设计师——软件工程(一)
📑前言 本文主要是【软件工程】——软件设计师——软件工程的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是听风与他🥇 ☁️博客首页:CSDN主页听风与他 🌄…...

阿里云|人工智能(AI)技术解决方案
函数计算部署Stable Diffusion AI绘画技术解决方案 通过函数计算快速部署Stable Diffusion模型为用户提供快速通过文字生成图片的能力。该方案通过函数计算快速搭建了AIGC的能力,无需管理服务器等基础设施,专注模型的能力即可。该方案具有高效免运维、弹…...
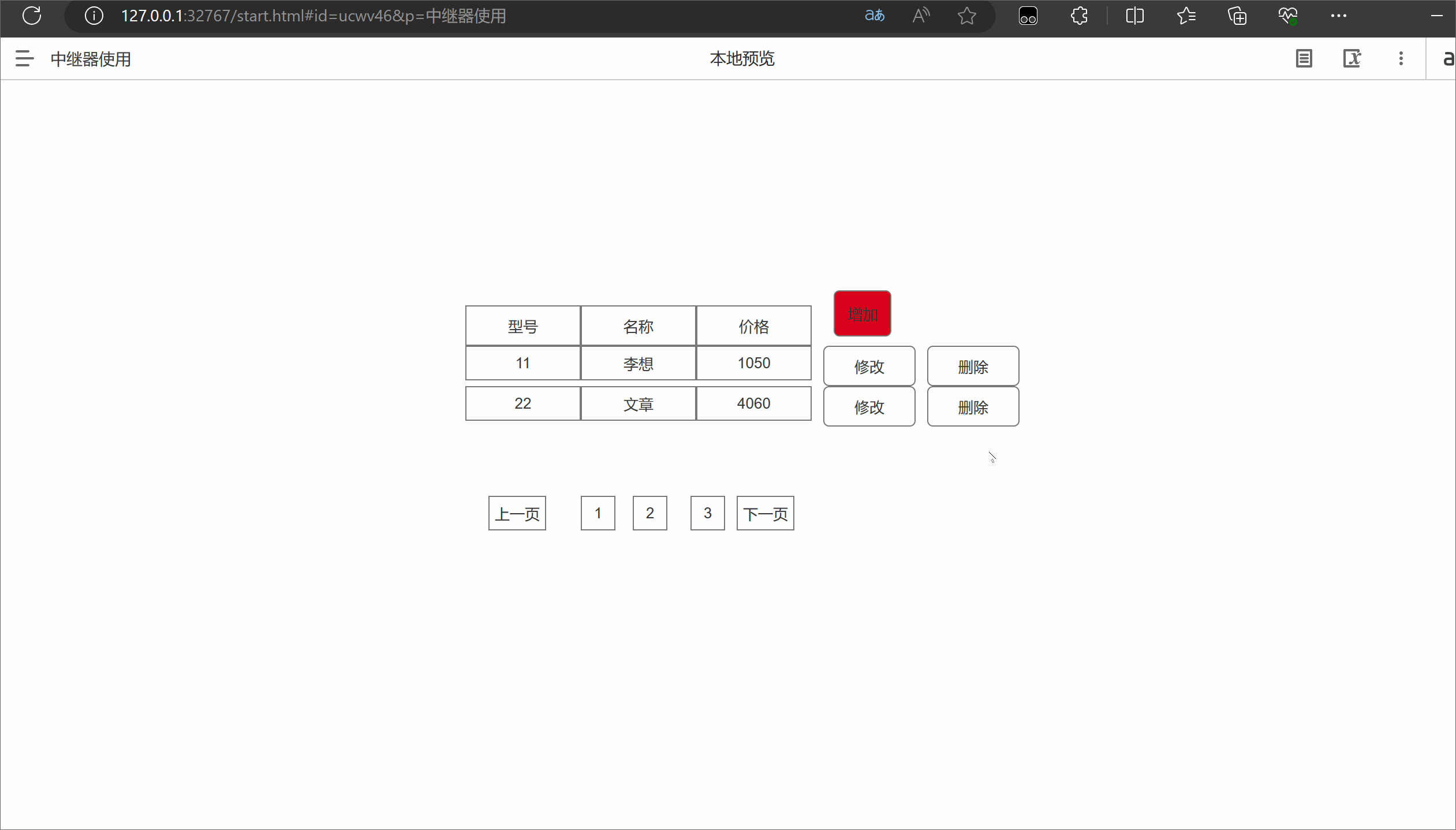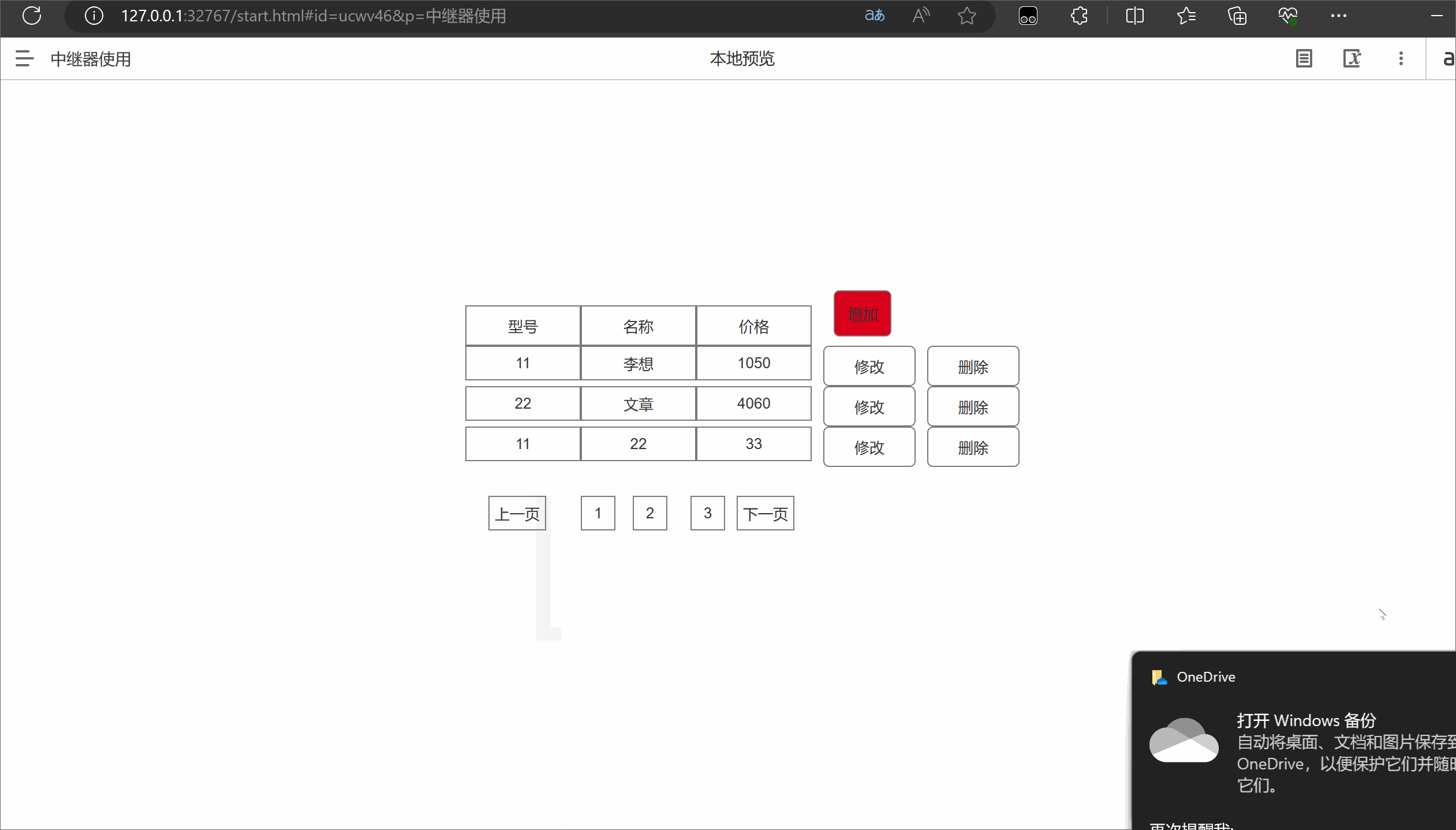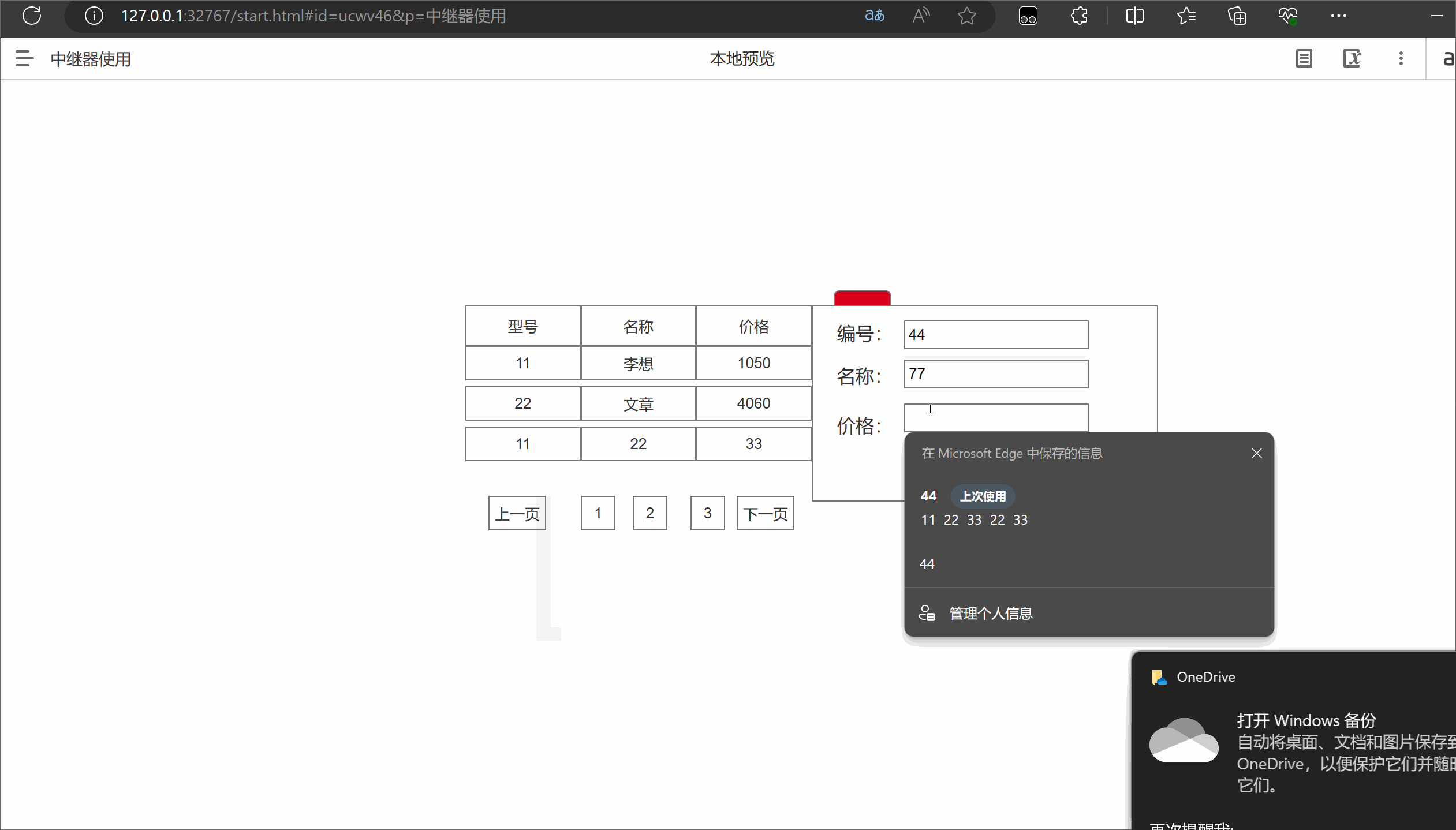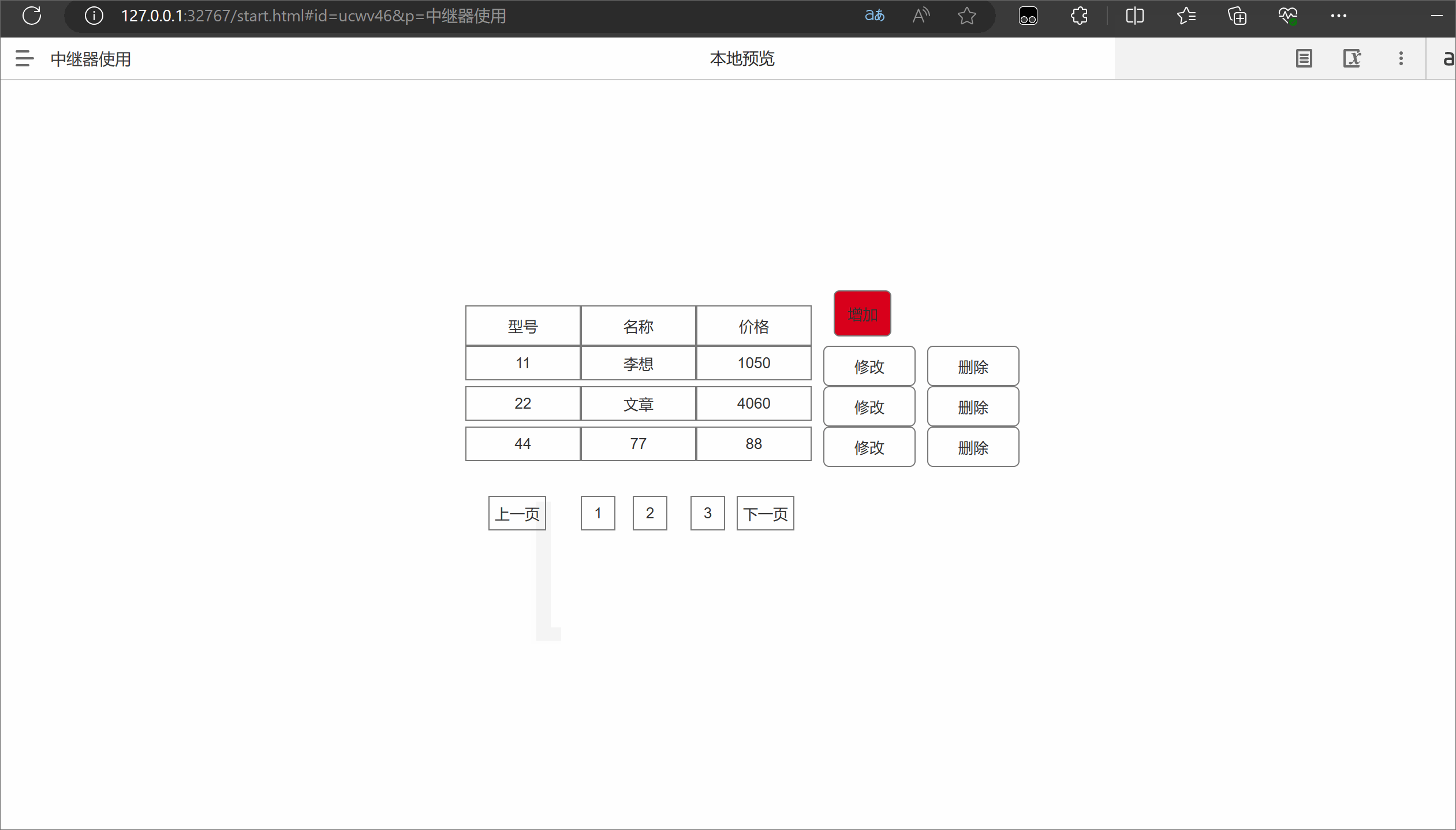
Axure中继器的使用
一.中继器介绍 在Axure中,中继器(Relays)是一种功能强大的元件,可以用于创建可重复使用的模板或组件。中继器允许您定义一个主要的模板,并在页面中重复使用该模板的实例。以下是中继器的作用和优缺点: 作…...

3分钟掌握Word转HTML:Mammoth.js让你的文档转换变得如此简单
3分钟掌握Word转HTML:Mammoth.js让你的文档转换变得如此简单 【免费下载链接】mammoth.js Convert Word documents (.docx files) to HTML 项目地址: https://gitcode.com/gh_mirrors/ma/mammoth.js 在现代办公和内容管理中,Word转HTML的需求无处…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...

微创式电子设备设计:从自动化到自主化的智能革命
1. 项目概述:从“工具”到“魔法”的隐形革命十几年前,我在《EE Times》上读到一篇由西蒙巴克(Simon Barker)撰写的文章,标题是一个直击灵魂的提问:“微创式电子设备在哪里?” 这个问题像一颗种…...

2025届学术党必备的五大降重复率方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下知网已然上线了AI检测功能,会针对论文里疑似人工智能生成的内容展开识别。为…...

C++ 特殊成员函数详解:构造、析构、拷贝与移动
C 特殊成员函数详解:构造、析构、拷贝与移动 目录 概述基础成员函数 默认构造函数虚析构函数 拷贝操作 拷贝构造函数拷贝赋值运算符 移动操作(C11) 移动构造函数移动赋值运算符 常见问题解析 为什么拷贝参数是 const T&?为什…...

开源情报自动化工具OpenClaw:模块化设计与实战部署指南
1. 项目概述:从“Resolver-TNG/ogas-openclaw”看开源情报自动化最近在开源情报(OSINT)和自动化数据采集的圈子里,一个名为“ogas-openclaw”的项目引起了我的注意。这个项目托管在Resolver-TNG的组织下,名字本身就很有…...

从零构建大模型推理引擎:KV缓存、算子融合与量化优化实战
1. 项目概述:从零理解大模型推理引擎如果你正在关注大语言模型(LLM)的实际应用,特别是如何让这些动辄数百亿参数的“庞然大物”在你的本地机器或服务器上高效地跑起来,那么你很可能已经听说过“推理引擎”这个词。anik…...

构建个人技能库:从代码片段到可复用技能单元的设计与实践
1. 项目概述:当代码遇上魔法,技能库的构建哲学在软件开发的日常里,我们常常会羡慕那些“魔法师”般的同事:他们似乎总能信手拈来一段代码,优雅地解决一个棘手问题;或者拥有一个私人的“百宝箱”,…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...

chatgpt.js:纯客户端集成ChatGPT,构建浏览器AI应用实战
1. 项目概述:一个专为浏览器环境打造的ChatGPT交互库如果你是一名前端开发者,或者经常需要在自己的网页项目中集成智能对话功能,那么你一定对调用大型语言模型的API不陌生。传统的做法是,在自己的后端服务器上封装一个接口&#x…...