一种磁盘上循环覆盖文件策略
目录标题
- 1. 前言
- 2. 软件设计流程思路
- 3. 模拟测试
- 3.1 分区准备工作
- 3.2 模拟写数据
- 3.3 测试
1. 前言
实际开发中经常需要存储数据, 无论是存储日志,还是二进制数据(图片,雷达数据或视频文件等), 不能一直存,是否存在一种策略:
当磁盘空间不足时,优先删除最开始写入的数据呢?
循环覆盖的策略应该有很多,这篇文章抛砖引玉,希望更多个伙伴给出更好的方案出来!
2. 软件设计流程思路
这里只提供思路,具体实现按照客户需求做多样化,最好写个抽象基类出来,后续可以多态各种需求。
- 初始化(挂载点/循环覆盖阈值T, 每次覆盖后预留一定的比例,比如覆盖阈值75,当使用率到了75后,删除的比例为5,那么删除后比例为70,)
- 策略有很多,看客户需求:
- 按照比例删除, 比如超过阈值,删掉{超过部分+一定过度,大概为5%~10%比例均可}。
- 按照时间删除,比如超过比例,删除掉最早日期的数据,如果日期内数据小,会导致删除频率高,这里多考量下多目录多文件情况下的事件复杂度(目录遍历) && CPU占用比例实际等,是否影响到系统性能。
- 组合删除。
- 空闲删除,某种方式设备休眠时做删除动作{主业务不启用等}。
- 策略有很多,看客户需求:
- 线程监测{按照比例删除流程}
- 监测
磁盘分区当前使用比例。 - 比较使用比例和循环覆盖阈值T, 当大于阈值比例时, 计算需要删除的比例DT, 通过(总大小乘 DT )计算删除的数据大小。
- 对磁盘文件做递归查询,将非目录文件部署到数组中(std::vector>。
- 通过文件属性拿到写操作的时间戳, 通过STL的算法sort按照时间戳做降序/升序排序,得到 std::vector{sort}的数组。
- 开始删除文件,这里需要注意std::vector<> erase坑。
- 每次删除成功记录实际删除的大小。
- 通过这个实际删除大小和理论删除对比,如果{>=}就停止, 调试线程开始。
- 因为目录中的文件可能都删除了,所以需要检测空目录的情况,当有空目录就删除。
- 监测
3. 模拟测试
3.1 分区准备工作
- 通过fdisk工具分区,假设我们分1个区域/dev/mmcblk1p1
- 格式化
mkfs.ext4 /dev/mmcblk1p1 - 挂载 mount -t ext4 /dev/mmcblk1p1 /mywork
3.2 模拟写数据
- 格式化后分区大小为0
- 使用dd命令写操作, 如下是写的一个自动化写数据elf文件源码
#include <unistd.h>#include <stdlib.h>
#include <stdio.h>
#include <string>
#include <vector>int main(int argc, char *argv[])
{if(argc < 5){printf("Usage: ./a.out <创建文件数量> <创建文件大小MB> <创建文件间隔 S> <拷贝目录绝对路径>\n");return -1;}std::string strcmd("");int nFileCount = atoi(argv[1]);int nFileSize = atoi(argv[2]);int nTimeSpan = atoi(argv[3]);std::string dir = argv[4];printf("创建文件数量:%d, 创建文件大小为:%d, 创建文件间隔:%d 拷贝的目录:%s\n", nFileCount, nFileSize, nTimeSpan, dir.c_str());for(int i = 0; i < nFileCount; ++i){strcmd =std::string( "dd if=/dev/zero of=") + dir + "/"+std::to_string(time(0))+"_"+std::to_string(i+1)+".file bs=1048576 count=" + std::to_string(nFileSize);printf("cmd:%s\n", strcmd.c_str());FILE * fp = popen(strcmd.c_str(), "r");if(nullptr == fp){printf("pipe error .\n");exit(127);}printf("create %02d , size:%d MB\n", i+1, nFileSize);fclose(fp); fp = 0;sleep(nTimeSpan);}return 0;
}运行日志如下:
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141122_91.file bs=1048576 count=100
create 91 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.40722 s, 30.8 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141125_92.file bs=1048576 count=100
create 92 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.47826 s, 30.1 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141129_93.file bs=1048576 count=100
create 93 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.28752 s, 31.9 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141132_94.file bs=1048576 count=100
create 94 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.49482 s, 30.0 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141136_95.file bs=1048576 count=100
create 95 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.62826 s, 28.9 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141139_96.file bs=1048576 count=100
create 96 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.27876 s, 32.0 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141143_97.file bs=1048576 count=100
create 97 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.32141 s, 31.6 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141146_98.file bs=1048576 count=100
create 98 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.30286 s, 31.7 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141149_99.file bs=1048576 count=100
create 99 , size:100 MB
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.28151 s, 32.0 MB/s
cmd:dd if=/dev/zero of=/home/ubuntu/pic/6/1703141152_100.file bs=1048576 count=100
create 100 , size:100 MB3.3 测试
- 开启一个窗口对分区写文件,执行
a.out 100 512 0.5 $PWD/2, 命令行的含义上面的代码有解释。 - 当模拟写的过程中,磁盘使用率越来越大。当到阈值T时,会对最早写的数据做删除动作,直到删除了
超出阈值+一定的缓冲,一般给5%~10%足够。 - 进入到目录中,确认目录中文件是否是先删除时间戳最早的文件。
相关文章:

一种磁盘上循环覆盖文件策略
目录标题 1. 前言2. 软件设计流程思路3. 模拟测试3.1 分区准备工作3.2 模拟写数据3.3 测试 1. 前言 实际开发中经常需要存储数据, 无论是存储日志,还是二进制数据(图片,雷达数据或视频文件等), 不能一直存,是否存在一种策略: 当磁盘空间不足时…...
elementui消息弹出框MessageBox英文内容不换行问题
问题:当MessageBox内容为中文时,会自动换行,但当内容为英文时不会触发自动换行 如图,内容名称为英文时,名称太长会戳出提示框,不会自动换行 为数字英文会在英文数字处换行但是我们往往不需要它换行 解决方…...

WPF——样式和控件模板、数据绑定与校验转换
样式和控件模板 合并资源字典 Style简单样式的定义和使用 ControlTemplate控件模板的定义和使用 定义 使用 Trigger触发器 数据绑定与校验转换 数据绑定的设置 代码层实现绑定 数据模板DataTemplate xml文件的读取与显示 方法的返回值作为源绑定到控件中ObjectDataProvider L…...
服务器数据恢复-raid5故障导致上层分区无法访问的数据恢复案例
服务器数据恢复环境&故障: 一台服务器上3块硬盘组建了一组raid5磁盘阵列。服务器运行过程中有一块硬盘的指示灯变为红色,raid5磁盘阵列出现故障,服务器上层操作系统的分区无法识别。 服务器数据恢复过程: 1、将故障服务器上磁…...
石器时代H5小游戏架设教程
本文讲解石器时代 H5 之恐龙宝贝架设教程,想研究 H5 游戏如何实现,那请跟着此次教程学习在拥有小游戏源码的情况下该如何搭建起来 开始架设 1. 架设条件 石器时代架设需要准备: 一台linux 服务器,建议 CentOs 7.6 版本…...

计算机网络-网络协议
一、TCP/IP协议 作为一个小萌新,当然我无法将tcp/ip协议的大部分江山和盘托出,但是其中很多面试可能问到的知识,我觉得有必要总结一下! 首先,在学习tcp/ip协议之前,我们必须搞明白什么是tcp/ip协议。 1、…...

多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现KOA-CNN-B…...
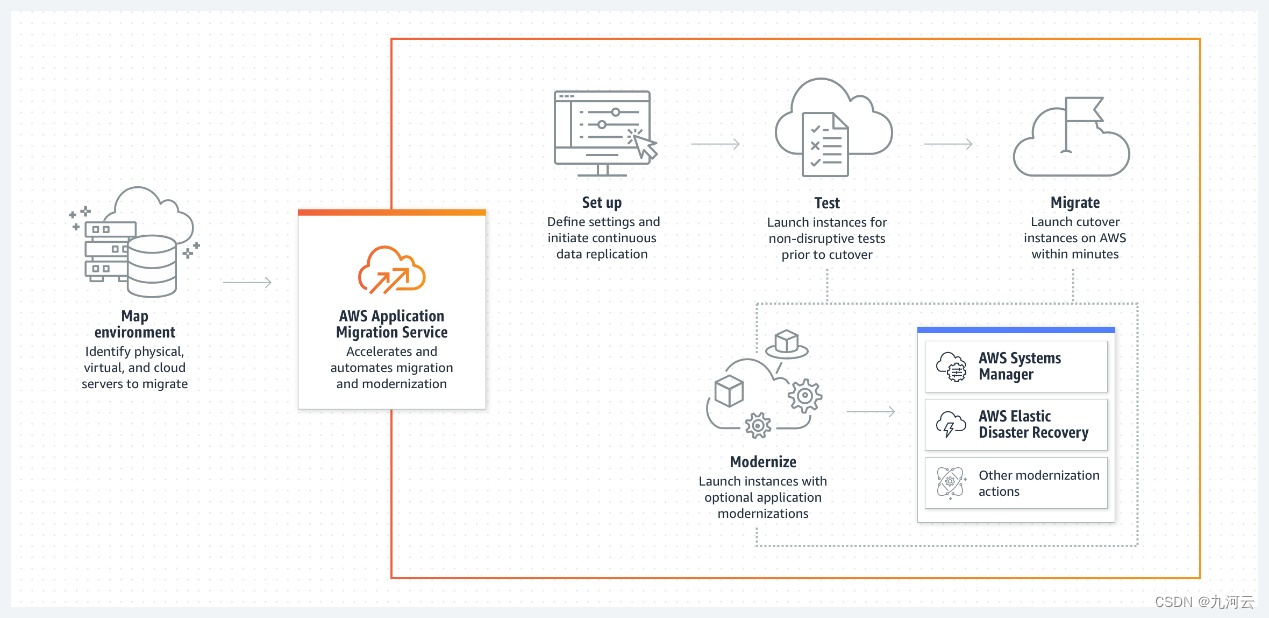
业务出海如何快速将站点搬迁到AWS云中?
随着国内市场趋于饱和,竞争压力越来越大,越来越多的企业选择出海,把业务放在海外做,从而追求更广阔的市场,获取更多客户。那都在讲出海,那怎么将站点完完整整的搬到海外呢?大家都会想࿰…...

ansible剧本playbook
Palybook组层部分 tasks 任务包含要在目标主机上执行的操作,使用模块定义这些操作,每个任务都是一个模块的调用variables变量:存储和传递数据,变量可以自定义,可以在palybook当中定义为全局变量,也可以在外部传参temp…...

.NET 中string类型的字符串内部化机制
当创建一个字符串时,如果具有相同字符序列的字符串已经存在于内存中,那么新创建的字符串会指向已经存在的那个字符串的内存地址,而不是创建一个全新的副本。这有助于节省内存,并提高字符串操作的效率。 因此相同内容的字符串变量…...

公共字段自动填充——后端
场景:当处理一些请求时,会重复的对数据库的某些字段进行赋值(如:在插入和更新某个物品时,需要更新该物品的更新时间和更新者的信息),这样会导致代码冗余。 如: 思路: 自…...

nginx upstream 6种负载均衡策略介绍
upstream参数 参数描述service反向服务地址加端口weight权重max_fails失败多少次,认为主机已经挂掉,踢出fail_timeout踢出后重新探测时间backup备用服务max_conns允许最大连接数slow_start当节点恢复,不立即加入 负载均衡策略 轮询&#x…...
基于Antd4 和React-hooks的项目开发
基于Antd4 和React-hooks的项目开发 https://github.com/dL-hx/react-cnode 项目依赖使用 react 16.13react-redux 7.xreact-router-dom 5.xredux 4.xantd 4axiosmoment 2.24 (日期格式化)qs 项目视图说明 首页主题详情用户列表用户详情关于 配置按需加载 https://3x.an…...

Spring中用到的设计模式
一、工厂模式 BeanFactory 1、简单工厂模型,是指由一个工厂对象决定创建哪一种产品类的实例,工厂类负责创建的对象较少,客户端只需要传入工厂类的参数,对于如何创建对象的逻辑不需要关心 优点: 只需传入一个正确的参数…...

常用网络接口自动化测试框架
(一)GUI界面测试工具:jmeter 1、添加线程组 2、添加http请求 3、为线程组添加察看结果树 4、写入接口参数并运行 5、在查看结果树窗口查看结果 6、多组数据可增加CSVDataSetConfig(添加.csv格式的文件,并在参数值里以${x}格式写入) 此时变量…...

【重点】【贪心】55.跳跃游戏
题目 法1:贪心 class Solution {public boolean canJump(int[] nums) {int maxIndex nums.length - 1;int curMaxIndex 0;for (int i 0; i < nums.length; i) {if (i < curMaxIndex) {curMaxIndex Math.max(i nums[i], curMaxIndex);if (curMaxIndex &…...

灰度化、二值化、边缘检测、轮廓检测
灰度化 定义 灰度图像是只含亮度信息,不含色彩信息的图像。灰度化处理是把彩色图像转换为灰度图像的过程,是图像处理中的基本操作。OpenCV 中彩色图像使用 BGR 格式。灰度图像中用 8bit 数字 0~255 表示灰度,如:0 表…...

基于JAVA的高校大学生创业管理系统 开源项目
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 系统公告模块2.2 创业项目模块2.3 创业社团模块2.4 政府政策模块2.5 创业比赛模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 系统公告表3.2.2 创业项目表3.2.3 创业社团表3.2.4 政策表 四、系统展示五、核心代码5.…...

神经网络学习小记录76——Tensorflow2设置随机种子Seed来保证训练结果唯一
神经网络学习小记录76——Tensorflow2设置随机种子Seed来保证训练结果唯一 学习前言为什么每次训练结果不同什么是随机种子训练中设置随机种子 学习前言 好多同学每次训练结果不同,最大的指标可能会差到3-4%这样,这是因为随机种子没有设定导致的&#x…...

ai学习笔记-入门
目录 一、人工智能是什么?可以做什么? 人工智能(Artificial Intelligence): 人工智能的技术发展路线: 产业发展驱动因素:数据、算力、算法 二、人工智能这个工具的使用原理入门 神经网络⭕数学基础 1.神经网络的生物表示 …...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

Grad-CAM实战:用热力图透视神经网络的决策焦点
1. Grad-CAM技术初探:为什么我们需要热力图? 当你训练了一个图像分类模型,准确率高达95%,但你真的了解它是如何做出判断的吗?我曾在项目中遇到过这样的尴尬:模型把一只坐在草地上的哈士奇误判为"狼&qu…...

【最新 v2.7.1 版本安装包】5 分钟搞定 OpenClaw,零基础无需命令一键部署保姆级教学
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案
Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 还在为传统游戏模组安装的繁琐流程而烦恼吗&…...

OpenClaw量化回测性能调优指南:从数据加载到并行计算的实战优化
1. 项目概述:从开源工具到性能调优的艺术最近在跟几个做量化交易的朋友聊天,他们都在为一个问题头疼:策略回测和实盘执行的速度。动辄几十个G的历史数据,复杂的因子计算,加上高频的模拟交易,一套流程跑下来…...