学习记录 --- Pytorch优化器
文章目录
- 参考文献
- 什么是优化器
- optimizer的定义
- optimizer的属性
- defaults
- state
- param_groups
- optimizer的方法
- zero_grad()
- step()
- add_param_group()
- state_dict()、load_state_dict()
- 优化一个网络
- 同时优化多个网络
- 当成一个网络优化
- 当成多个网络优化
- 只优化网络的某些指定的层
- 调整学习率
个人学习总结,持续更新中……
参考文献
官方教程
【学习笔记】Pytorch深度学习—优化器(一)
【学习笔记】Pytorch深度学习—优化器(二)
什么是优化器
Pytorch的优化器:
管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。
分析
其中,可学习参数指 权值 和 偏置bias;
其次,优化器最主要的2大功能:
(1)管理:指优化器管理哪一部分参数;
(2)更新:优化器当中具有一些优化策略,优化器可采用这些优化策略更新模型中可学习参数的值;这一更新策略,在神经网络中通常都会采用梯度下降法。
什么是梯度下降法
<总结>
Pytorch中优化器optimizer 管理着模型中的可学习参数,并采用梯度下降法 更新着可学习参数的值。
optimizer的定义
以Adam为例:
class Adam(Optimizer):def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,weight_decay=0, amsgrad=False):
import torch# 构建1个2×2大小的随机张量,并开放"梯度"
weight = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer1 = torch.optim.Adam([weight], lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
# optimizer2 = torch.optim.Adam([weight])
import torch
import torch.nn as nninitial_lr = 0.1class model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))def forward(self, x):passnet = model()
optimizer = torch.optim.Adam(net.parameters(), lr=initial_lr)
optimizer的属性
defaults
优化器超参数,用来存储学习率、momentum的值等等;
import torch
import torch.nn as nninitial_lr = 0.1class model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))def forward(self, x):passnet = model()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(optimizer.defaults)
'''
{'lr': 0.01, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
'''
state
参数的缓存,如momentum的缓存;采用momentum时会使用前几次更新时使用的梯度,也就是前几次的梯度,把前几次的梯度值缓存下来,在本次更新中使用;
import torch
import torch.nn as nninitial_lr = 0.1class model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3))def forward(self, x):passnet = model()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(optimizer.state)
'''
defaultdict(<class 'dict'>, {})
'''
param_groups
管理的参数组;优化器最重要的属性,已经知道优化器是管理可学习参数,这一系列可学习参数就放在param_groups这一属性中,同时,这一参数组定义为list。
param_groups=[{‘params’:param_groups,‘lr’: 0.01,}]
因此,param_groups是1个list。而在list[ ] 中,每一个元素又是1个字典{ } ,这些字典中有很多key,其中最重要的key是-‘params’,只有’params’当中才会存储训练模型的参数。
import torch# 构建1个2×2大小的随机张量,并开放"梯度"
weight = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(optimizer.param_groups)
'''
[{'params': [tensor([[1., 2.],[3., 4.]], requires_grad=True)], 'lr': 0.01, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
'''
optimizer的方法
zero_grad()
清空所管理参数的梯度
Pytorch中tensor特性:tensor张量梯度不自动清零
已知参数param是1个特殊的张量,张量当中都会有梯度grad。由于Pytorch中张量tensor的梯度grad是不会自动清零的,它会在每一次backward反向传播时采用autograd计算梯度,并把梯度值累加到张量的grad属性中的。
由于Pytorch中的grad属性不自动清零,因此每计算1次梯度就自动累加到grad属性中造成错误;因此,一定要在使用完梯度后或者进行梯度求导(反向传播)之间通过zero_grad进行清零。

import torch# 构建1个2×2大小的随机张量,并开放"梯度"
weight = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=0.01, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(weight.grad)
'''
tensor([[1., 1.],[1., 1.]])
'''optimizer.zero_grad()print(weight.grad)
'''
tensor([[0., 0.],[0., 0.]])
'''
step()
执行一步更新
当计算得到Loss,利用Loss进行backward反向传播计算各个参数的梯度之后,采用step()进行一步更新,更新权值参数。step()会采用梯度下降的策略,具体方法有很多种,比如随机梯度下降法、momentum+动量方法、autograd自适应学习率等等一系列优化方法。
参数_new = 参数_old + 负梯度值 * 学习率
import torch# 构建1个2×2大小的随机张量,并开放"梯度"
weight = torch.tensor([[2., 3.], [4., 5.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=1.0, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(weight.data)
'''
tensor([[2., 3.],[4., 5.]])
'''optimizer.step() # 修改lr=0.1观察结果print(weight.data)
'''
tensor([[1.0000, 2.0000],[3.0000, 4.0000]])
'''
add_param_group()
添加参数组
add_param_group()添加一组参数到优化器中。已知优化器管理很多参数,这些参数是可以分组;对于不同组的参数,有不同的超参数设置,例如在某一模型中,希望特征提取部分的权值参数的学习率小一点,学习更新慢一点,这时可以把特征提取的参数设置为一组参数,而对于后面全连接层,希望其学习率大一点,学习快一点。这时,可以把整个模型参数设置为两组,一组为特征提取部分的参数,另一部分是全连接层的参数,对这两组设置不同的学习率或超参数,这时就需要用到参数组概念。
import torch# 构建1个2×2大小的随机张量,并开放"梯度"
weight = torch.tensor([[2., 3.], [4., 5.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=1.0, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)print(optimizer.param_groups)
'''
[{'params': [tensor([[2., 3.],[4., 5.]], requires_grad=True)], 'lr': 1.0, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
'''w2 = torch.randn((3, 3), requires_grad=True)optimizer.add_param_group({"params": w2, 'lr': 0.0001})print(optimizer.param_groups)'''
[{'params': [tensor([[2., 3.],[4., 5.]], requires_grad=True)], 'lr': 1.0, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}, {'params': [tensor([[ 0.2155, 1.3953, -0.2814],[ 1.3192, 2.0449, 1.6898],[ 2.0740, -1.5179, -0.1514]], requires_grad=True)], 'lr': 0.0001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
'''
import torch# 构建1个2×2大小的随机张量,并开放'梯度'
weight = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=1) # 0.1w2 = torch.tensor([[11., 12.], [13., 14.]], requires_grad=True)
w3 = torch.tensor([[11., 12.], [13., 14.]], requires_grad=True)
# 构建字典,key中 params中放置参数 w2,利用方法 add_param_group把这一组参数加进来
optimizer.add_param_group({"params": [w2,w3], 'lr': 0.0001})
# optimizer.add_param_group({"params": w3, 'lr': 0.0001})
state_dict()、load_state_dict()

import torch# 构建1个2×2大小的随机张量,并开放'梯度'
weight = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
# 构建1个2×2大小的全1梯度张量
weight.grad = torch.ones((2, 2))
# 将可学习参数[weight]传入优化器
optimizer = torch.optim.Adam([weight], lr=1) # 0.1w2 = torch.tensor([[11., 12.], [13., 14.]], requires_grad=True)
w3 = torch.tensor([[11., 12.], [13., 14.]], requires_grad=True)
# 构建字典,key中 params中放置参数 w2,利用方法 add_param_group把这一组参数加进来
optimizer.add_param_group({"params": [w2,w3], 'lr': 0.0001})
# optimizer.add_param_group({"params": w3, 'lr': 0.0001})opt_state_dict = optimizer.state_dict()# 打印step()更新之前的状态信息字典
print("state_dict before step:\n", opt_state_dict)optimizer.step()# 打印step()更新之后的状态信息字典
print("state_dict after step:\n", optimizer.state_dict())
# 保存更新之后的状态信息字典在当前文件夹下名为 optimizer_state_dict.pkl的文件
torch.save(optimizer.state_dict(), 'optimizer_state_dict.pkl')# -------------------------load state_dict --------------
# 重新构建优化器
optimizer = torch.optim.Adam([weight], lr=0.1)
optimizer.add_param_group({"params": [w2,w3], 'lr': 0.0001})
# optimizer.add_param_group({"params": w3, 'lr': 0.0001})
# 创建加载状态名
state_dict = torch.load("optimizer_state_dict.pkl")print("state_dict before load state:\n", optimizer.state_dict())# 利用load_state_dict方法加载状态信息,接着当前状态往下训练
optimizer.load_state_dict(state_dict)
print("state_dict after load state:\n", optimizer.state_dict())
优化一个网络

import torch
import torch.nn as nninitial_lr = 0.1class model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3))self.conv2 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3))def forward(self, x):passnet_1 = model()optimizer_1 = torch.optim.Adam(net_1.parameters(), lr=initial_lr)
print("******************optimizer_1*********************")
print("optimizer_1.defaults:\n", optimizer_1.defaults)
print("optimizer_1.param_groups:\n", optimizer_1.param_groups)'''
******************optimizer_1*********************
optimizer_1.defaults:{'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_1.param_groups:[{'params': [Parameter containing:
tensor([[[[-0.2143, -0.3299, 0.0063],[ 0.1602, -0.0350, 0.0579],[-0.1537, 0.0446, 0.0909]]]], requires_grad=True), Parameter containing:
tensor([-0.2204], requires_grad=True), Parameter containing:
tensor([[[[ 0.1074, -0.1432, 0.0954],[ 0.1079, 0.3233, -0.2487],[-0.1410, 0.1557, 0.0839]]]], requires_grad=True), Parameter containing:
tensor([-0.1368], requires_grad=True)], 'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}]
'''
同时优化多个网络

当成一个网络优化
这种方法,每个网络的学习率是相同的。
optimizer = torch.optim.Adam([*net_1.parameters(), *net_2.parameters()], lr = initial_lr)
当成多个网络优化
这样可以很容易的让多个网络的学习率各不相同。
optimizer_3 = torch.optim.Adam([{"params": net_1.parameters()}, {"params": net_2.parameters()}], lr = initial_lr)optimizer_3 = torch.optim.Adam( [{"params": net_1.parameters(), 'lr': initial_lr}, {"params": net_2.parameters(), 'lr': initial_lr}])
import torch
import torch.nn as nninitial_lr = 0.1class model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3,3))self.conv2 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3,3))def forward(self, x):passnet_1 = model()
net_2 = model()optimizer_2 = torch.optim.Adam([*net_1.parameters(), *net_2.parameters()],lr=initial_lr)
# optimizer_2 = torch.opotim.Adam(itertools.chain(net_1.parameters(), net_2.parameters())) # 和上一行作用相同
print("******************optimizer_2*********************")
print("optimizer_2.defaults:", optimizer_2.defaults)
print("optimizer_2.param_groups长度:", len(optimizer_2.param_groups))
print("optimizer_2.param_groups一个元素包含的键:", optimizer_2.param_groups[0].keys())
print()optimizer_3 = torch.optim.Adam([{"params": net_1.parameters()
}, {"params": net_2.parameters()
}],lr=initial_lr)
print("******************optimizer_3*********************")
print("optimizer_3.defaults:", optimizer_3.defaults)
print("optimizer_3.param_groups长度:", len(optimizer_3.param_groups))
print("optimizer_3.param_groups一个元素包含的键:", optimizer_3.param_groups[1].keys())optimizer_4 = torch.optim.Adam([{"params": net_1.parameters(),'lr': initial_lr
}, {"params": net_2.parameters(),'lr': initial_lr
}])
print("******************optimizer_4*********************")
print("optimizer_4.defaults:", optimizer_4.defaults)
print("optimizer_4.param_groups长度:", len(optimizer_4.param_groups))
print("optimizer_4.param_groups一个元素包含的键:", optimizer_4.param_groups[1].keys())
'''
******************optimizer_2*********************
optimizer_2.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_2.param_groups长度: 1
optimizer_2.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])******************optimizer_3*********************
optimizer_3.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_3.param_groups长度: 2
optimizer_3.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_4*********************
optimizer_4.defaults: {'lr': 0.001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_4.param_groups长度: 2
optimizer_4.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
'''
只优化网络的某些指定的层
optimizer = optim.SGD( [{'params': model.layer0.parameters(), "lr": 0.01}, {'params': model.layer2.parameters(), "lr": 0.01}])
from torch import optim
from torch import nn
import torchclass MLP(nn.Module):def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim):super(MLP, self).__init__()self.layer0 = nn.Linear(in_dim, hid_dim1)self.layer1 = nn.ReLU()self.layer2 = nn.Linear(hid_dim1, hid_dim2)self.layer3 = nn.ReLU()self.layer4 = nn.Linear(hid_dim2, out_dim)self.layer5 = nn.ReLU()def forward(self, x):x = self.layer0(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.layer5(x)return xmodel = MLP(10, 3, 3, 10)
optimizer = optim.SGD([{'params': model.layer0.parameters(), "lr": 0.01}, {'params': model.layer2.parameters(), "lr": 0.01}])data = torch.randn(10, 10)
label = torch.Tensor([1, 0, 4, 7, 9, 2, 4, 5, 3, 2]).long()
criterion = nn.CrossEntropyLoss()
for i in range(100):output = model(data)loss = criterion(output, label)optimizer.zero_grad()loss.backward()optimizer.step()if i == 0:print('model.layer0.parameters(): \n', [x for x in model.layer0.parameters()])print('model.layer4.parameters(): \n', [x for x in model.layer4.parameters()])optimizer.step()if i == 99:print('model.layer0.parameters(): \n', [x for x in model.layer0.parameters()])print('model.layer4.parameters(): \n', [x for x in model.layer4.parameters()])
调整学习率
torch.optim.lr_scheduler:调整学习率
相关文章:
学习记录 --- Pytorch优化器
文章目录参考文献什么是优化器optimizer的定义optimizer的属性defaultsstateparam_groupsoptimizer的方法zero_grad()step()add_param_group()state_dict()、load_state_dict()优化一个网络同时优化多个网络当成一个网络优化当成多个网络优化只优化网络的某些指定的层调整学习率…...

Flink State 状态后端分析
flink状态实现分析 state * State* |* -------------------InternalKvState* | |* MergingState |* | |* …...

和年薪30W的阿里测开工程师聊过后,才知道我的工作就是打杂的...
前几天和一个朋友聊面试,他说上个月同时拿到了腾讯和阿里的offer,最后选择了阿里。 阿里内部将员工一共分为了14个等级,P6是资深工程师,P7是技术专家。 其中P6和P7就是一个分水岭了,P6是最接近P7的不持股员工&#x…...

C#开发的OpenRA的界面布局数据加载
C#开发的OpenRA的界面布局数据加载 当显示完成加载界面之后,就是进行其它内容处理。 因为后面内容的加载会比较长时间,所以首先显示加载界面是一种非常友好的方法。 因此在软件设计里,尽可能先显示界面,让用户先看到程序正在运行, 然后再处理时间长的加载。如果不这样做,…...

并查集结构
文章目录并查集特点构建过程查找两个元素是否是同一集合优化查找领头元素设置两个元素为同一集合构建结构应用场景并行计算集合问题并查集特点 对于使用并查集构建的结构,可以使得查询两个元素是否在同一集合,以及合并集合的操作无限接近O(1) 构建过程…...

全国CSM敏捷教练认证将于2023年3月25-26开班,报名从速!
CSM,即Certified Scrum Master,是Scrum联盟发起的Scrum认证。 CSM可以帮助团队正确使用Scrum,从而提高项目整体成功的可能性。 CSM深刻理解Scrum的价值观、实践以及Scrum框架。 CSM是“服务型领导”,帮助Scrum团队一起紧密合作。 …...
JavaEE进阶第六课:SpringBoot ⽇志⽂件
上篇文章介绍了SpringBoot配置文件,这篇文章我们将会介绍SpringBoot ⽇志⽂件 荔枝1.日志有什么用2.自定义日志输出2.1获取程序日志对象2.2使用相关方法输出日志2.3日志级别2.3.1日志级别的作用2.3.2日志级别如何设置2.4日志格式3.持久化日志4.更简单的日志输出4.1使…...

外置MOS管平均电流型LED降压恒流驱动器
产品描述 AP5125 是一款外围电路简单的 Buck 型平均电 流检测模式的 LED 恒流驱动器,适用于 8-100V 电压 范围的非隔离式大功率恒流 LED 驱动领域。芯片采用 固定频率 140kHz 的 PWM 工作模式, 利用平均电 流检测模式,因此具有优异的负载调整…...

python+pytest接口自动化(6)-请求参数格式的确定
我们在做接口测试之前,先需要根据接口文档或抓包接口数据,搞清楚被测接口的详细内容,其中就包含请求参数的编码格式,从而使用对应的参数格式发送请求。例如某个接口规定的请求主体的编码方式为 application/json,那么在…...

开发手册——一、编程规约_3.代码格式
这篇文章主要梳理了在java的实际开发过程中的编程规范问题。本篇文章主要借鉴于《阿里巴巴java开发手册终极版》 下面我们一起来看一下吧。 1. 【强制】大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行;如果是非空代码…...
)
十七、Django-restframework之序列化器(二)
1. 序列化器 REST framework提供了一个serializer类,它可以非常方便的序列化模型实例和查询集为JSON或者其他内容形式。它还提供反序列化,允许在验证传入数据后将解析的数据转换回复杂类型。 2. 定义序列化器 在crm应用目录下创建serializers.py文件&a…...
python GUI图形化编程-----wxpython
一、python gui(图形化)模块介绍: Tkinter :是python最简单的图形化模块,总共只有14种组建 Pyqt :是python最复杂也是使用最广泛的图形化 Wx :是python当中居中的一个图形化,学习结构很清晰 Pywin :是pyth…...

【Python 】yyyy-MM-dd HH:mm:ss 时间格式 时间戳 全面解读超详细
时间格式 时间格式(协议)描述gg时期或纪元。y不包含纪元的年份。不具有前导零。yy不包含纪元的年份。具有前导零。yyyy包含纪元的四位数的年份。M月份数字。一位数的月份没有前导零。MM月份数字。一位数的月份有一个前导零。MMM月份的缩写名称,在AbbreviatedMonthN…...
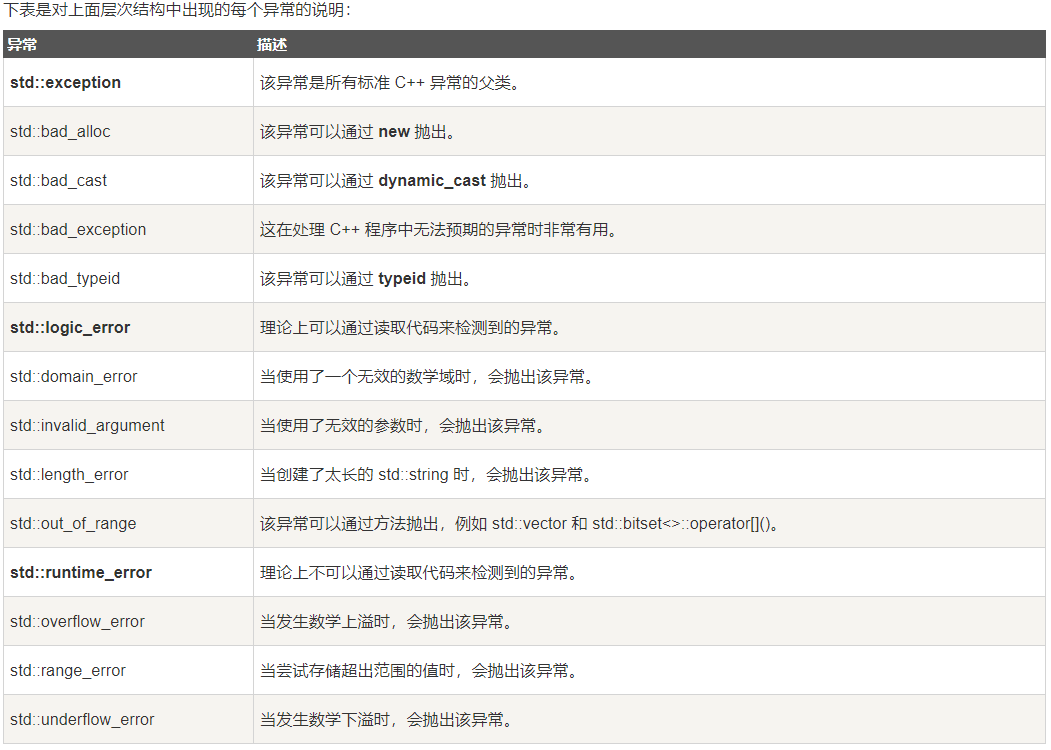
【C++】C++11 异常
目录 1. C语言传统的处理错误的方式 2. C异常概念 3. 异常的使用 3.1. 异常的抛出和捕获 3.2. 在函数调用链中异常栈展开匹配原则 3.3. 异常的重新抛出 3.4. 异常安全 3.5. 异常规范 4.自定义异常体系 5. C标准库的异常体系 6. 异常的优缺点 6.1. C异常的优点&…...
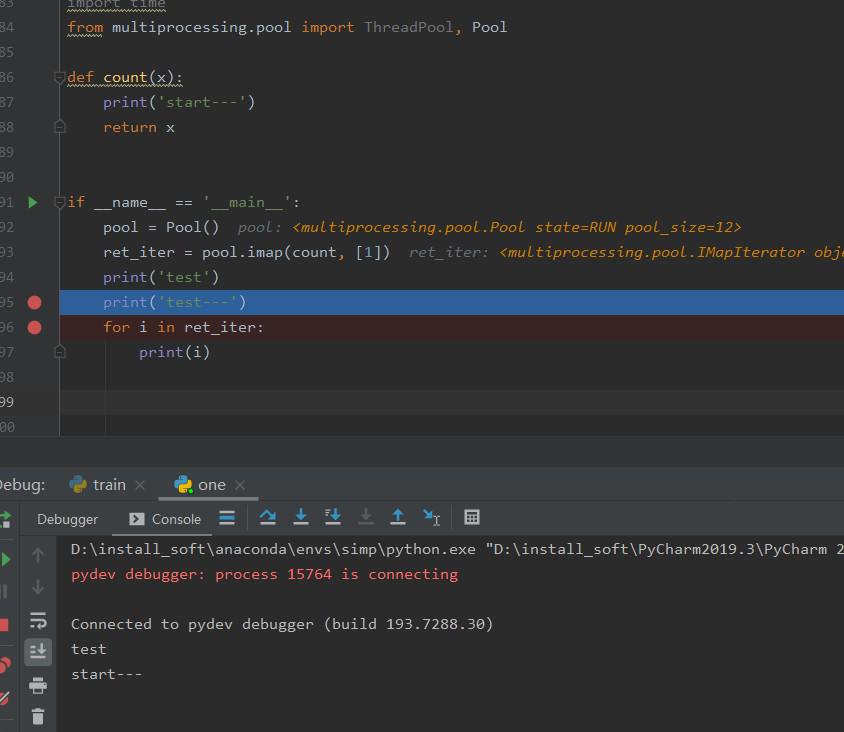
关于Thread.start()后的困惑、imap
在for循环中,接着开thread,开完就start,当时有个困惑,就是比如开的一个thread的这个start执行完,但是这个for循环还没执行完,那程序会跑到for循环的后面逻辑吗?比如下面13行for循环开始开第一个…...
qml学习之qwidget与qml结合使用并调用信号槽交互
学习qml系列之一说明: 学习qml系列之qwiget和qml信号槽的交互使用,并在qwidget中显示qml界面 在qml中发送信号到qwidget里 在qwidget里发送信号给qml 在qwidget里面调用qml界面方式 方式一:使用QQuickView 这个是Qt5.0中提供的一个类&…...
)
【 华为OD机试 2023】 组装新的数组(C++ Java JavaScript Python)
文章目录 题目描述输入描述输出描述备注用例题目解析C++JavaScriptJavaPython题目描述 给你一个整数M和数组N,N中的元素为连续整数,要求根据N中的元素组装成新的数组R,组装规则: R中元素总和加起来等于MR中的元素可以从N中重复选取R中的元素最多只能有1个不在N中,且比N中…...
)
【洛谷 P2089】烤鸡(循环枚举)
烤鸡 题目背景 猪猪 Hanke 得到了一只鸡。 题目描述 猪猪 Hanke 特别喜欢吃烤鸡(本是同畜牲,相煎何太急!)Hanke 吃鸡很特别,为什么特别呢?因为他有 101010 种配料(芥末、孜然等)…...
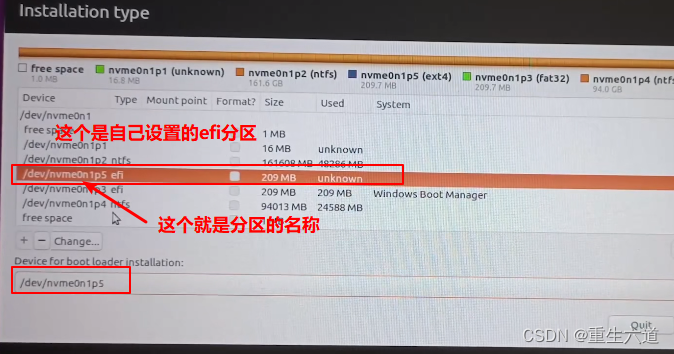
windows10安装ubantu双系统
windows10安装ubantu双系统 文章目录windows10安装ubantu双系统一、安装前准备1.前期说明2.制作U盘启动器3.设置硬盘分区相关4.设置给ubantu系统的硬盘大小,设置为未分配(删除卷)二、进行安装1.设置bios相关2.进入bios启动界面选择U盘安装3.进…...
)
【华为OD机试 2023】 人数最多的站点/小火车最多人时所在园区站点(C++ Java JavaScript Python)
文章目录 题目描述输入描述输出描述用例题目解析C++JavaScriptJavaPython励志做全网最全、解法最多的华为OD机考算法题库,帮助你上岸华为。提供C++/Java、JavaScript、Python四种语言的解法。每篇文章都有详细的结题步骤。有问题,随时解答。😁😁😁😁 目前为了造福广大…...

5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心
5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为Windows桌面上单调的系统监控而烦恼吗&#x…...

PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南
PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Onl…...

大模型评测实战指南:从基准测试到技术选型的全流程解析
1. 项目概述:为什么我们需要一个“大模型评测”清单?如果你在过去一年里深度参与过大语言模型(LLM)的应用开发、技术选型或者仅仅是技术追踪,你大概率会和我有同样的感受:“评测”这件事,变得越…...

免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案
免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently fo…...

Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包?
Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包? 每次在Linux服务器上部署FTP客户端时,我都会面临一个选择:是直接apt install filezilla,还是去官网下载tar包手动安装?五年前我可能…...

深耕落地,精准破局——应用型人工智能专业建设的实践路径
在人工智能产业快速迭代、人才需求持续升级的当下,应用型人工智能专业已成为高校布局新工科、服务区域产业的核心抓手。然而,作为一线专业带头人及授课教师,多数从业者都面临着一个共同的困惑:即便投入大量时间与精力优化培养方案…...

XXMI启动器终极指南:一站式管理原神、星穹铁道等热门游戏模组
XXMI启动器终极指南:一站式管理原神、星穹铁道等热门游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为多个游戏模组安装繁琐而烦恼吗?XXMI启…...

51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址
51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址 在嵌入式开发领域,51单片机因其经典架构和广泛的应用基础,依然是许多工程师入门的首选。然而,当开发者从简单的GPIO控制进阶到复杂的内存…...

云原生地理空间分析引擎Meridian:基于Arrow与GeoParquet的高性能架构解析
1. 项目概述:一个面向未来的开源地理空间数据引擎最近在折腾一个涉及大量地理信息处理的项目,从海量GPS轨迹点到复杂的多边形区域分析,传统的数据库和工具链在处理效率和灵活性上开始捉襟见肘。就在这个当口,我注意到了GitHub上一…...
:ChatGPT与Gemini,你选错一个就多花237万年运维成本)
仅剩72小时可获取的2026终极对比手册(含Prompt工程调优参数表、国产信创环境适配补丁包、等保2.0三级适配验证清单):ChatGPT与Gemini,你选错一个就多花237万年运维成本
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Gemini 2026年全面对比的基准定义与评估范式 为确保跨模型评估的科学性与可复现性,2026年主流AI基准已统一采用**多维动态评估范式(MDEP)**,该范…...