PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器
- 0. 前言
- 1. 卷积自编码器
- 2. 使用 t-SNE 对相似图像进行分组
- 小结
- 系列链接
0. 前言
我们已经学习了自编码器 (AutoEncoder) 的原理,并使用 PyTorch 搭建了全连接自编码器,但我们使用的数据集较为简单,每张图像只有一个通道(每张图像都为黑白图像)且图像相对较小 (28 x 28)。但在现实场景中,图像数据通常为彩色图像( 3 个通道)且图像尺寸通常较大。在本节中,我们将实现能够处理多维输入图像的卷积自编码器,为了与普通自编码器进行对比,同样使用 MNIST 数据集。
1. 卷积自编码器
与传统的全连接自编码器不同,卷积自编码器 (Convolutional Autoencoder) 利用卷积层和池化层替代了全连接层,以处理具有高维空间结构的图像数据。这样的设计使得卷积自编码器能够在较少的参数量下对输入数据进行降维和压缩,同时保留重要的空间特征。卷积自编码器架构如下所示:

从上图中可以看出,输入图像被表示为瓶颈层中的潜空间变量,用于重建图像。图像经过多次卷积(编码器)得到低维潜空间表示,然后在解码器中,将潜空间变量还原为原始尺寸,使解码器的输出能够近似恢复原始输入。
本质上,卷积自编码器在其网络中使用卷积、池化操作来代替原始自编码器的全连接操作,并使用反卷积操作 (Conv2DTranspose) 对特征图进行上采样。了解卷积自编码器的原理后,使用 PyTorch 实现此架构。
(1) 数据集的加载和构建方式与全连接自编码器完全相同:
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import numpy as np
from matplotlib import pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'img_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),transforms.Lambda(lambda x: x.to(device))
])trn_ds = MNIST('MNIST/', transform=img_transform, train=True, download=True)
val_ds = MNIST('MNIST/', transform=img_transform, train=False, download=True)batch_size = 256
trn_dl = DataLoader(trn_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
(2) 定义神经网络类 ConvAutoEncoder。
定义 __init__ 方法:
class ConvAutoEncoder(nn.Module):def __init__(self):super().__init__()
定义编码器架构:
self.encoder = nn.Sequential(nn.Conv2d(1, 32, 3, stride=3, padding=1), nn.ReLU(True),nn.MaxPool2d(2, stride=2),nn.Conv2d(32, 64, 3, stride=2, padding=1), nn.ReLU(True),nn.MaxPool2d(2, stride=1))
在以上代码中,通道数最初由 1 开始,逐渐增加到 64,同时通过 nn.MaxPool2d 和 nn.Conv2d 操作减小输入图像尺寸。
定义解码器架构:
self.decoder = nn.Sequential(nn.ConvTranspose2d(64, 32, 3, stride=2), nn.ReLU(True),nn.ConvTranspose2d(32, 16, 5, stride=3, padding=1), nn.ReLU(True),nn.ConvTranspose2d(16, 1, 2, stride=2, padding=1), nn.Tanh())
定义前向传播方法 forward:
def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x
(3) 使用 summary 方法获取模型摘要信息:
model = ConvAutoEncoder().to(device)
from torchsummary import summary
summary(model, (1,28,28))
输出结果如下所示:
```shell
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 32, 10, 10] 320ReLU-2 [-1, 32, 10, 10] 0MaxPool2d-3 [-1, 32, 5, 5] 0Conv2d-4 [-1, 64, 3, 3] 18,496ReLU-5 [-1, 64, 3, 3] 0MaxPool2d-6 [-1, 64, 2, 2] 0ConvTranspose2d-7 [-1, 32, 5, 5] 18,464ReLU-8 [-1, 32, 5, 5] 0ConvTranspose2d-9 [-1, 16, 15, 15] 12,816ReLU-10 [-1, 16, 15, 15] 0ConvTranspose2d-11 [-1, 1, 28, 28] 65Tanh-12 [-1, 1, 28, 28] 0
================================================================
Total params: 50,161
Trainable params: 50,161
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.14
Params size (MB): 0.19
Estimated Total Size (MB): 0.34
----------------------------------------------------------------
从以上模型架构信息可以看出,使用尺寸为 batch size x 64 x 2 x 2 的 MaxPool2d-6 层作为瓶颈层。
模型训练过程,训练和验证损失随时间的变化以及对输入图像的重建结果如下:
def train_batch(input, model, criterion, optimizer):model.train()optimizer.zero_grad()output = model(input)loss = criterion(output, input)loss.backward()optimizer.step()return loss@torch.no_grad()
def validate_batch(input, model, criterion):model.eval()output = model(input)loss = criterion(output, input)return lossmodel = ConvAutoEncoder().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)num_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(num_epochs):N = len(trn_dl)trn_loss = []val_loss = []for ix, (data, _) in enumerate(trn_dl):loss = train_batch(data, model, criterion, optimizer)pos = (epoch + (ix+1)/N)trn_loss.append(loss.item())train_loss_epochs.append(np.average(trn_loss))N = len(val_dl)for ix, (data, _) in enumerate(val_dl):loss = validate_batch(data, model, criterion)pos = epoch + (1+ix)/Nval_loss.append(loss.item())val_loss_epochs.append(np.average(val_loss))epochs = np.arange(num_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()for _ in range(5):ix = np.random.randint(len(val_ds))im, _ = val_ds[ix]_im = model(im[None])[0]plt.subplot(121)# fig, ax = plt.subplots(1,2,figsize=(3,3)) plt.imshow(im[0].detach().cpu(), cmap='gray')plt.title('input')plt.subplot(122)plt.imshow(_im[0].detach().cpu(), cmap='gray')plt.title('prediction')plt.show()



从上图中,我们可以看到卷积自编码器重建后的图像比全连接自编码器更清晰,可以通过改变编码器和解码器中的通道数,观察模型训练结果。在下一节中,我们将根据瓶颈层潜变量对相似图像进行分组
2. 使用 t-SNE 对相似图像进行分组
假设相似的图像具有相似的潜变量(也称嵌入),而不相似的图像具有不同的潜变量,使用自编码器,可以在低维空间中表示图像。接下来,我们继续学习图像的相似度度量,在二维空间中绘制潜变量,使用 t-SNE 技术将卷积自编码器的 64 维向量缩减至到 2 维空间。
在 2 维空间中,我们可以方便的可视化潜变量,以观察相似图像是否具有相似的潜变量,相似图像在二维平面中应该聚集在一起。接下里,我们在二维平面中表示所有测试图像的潜变量。
(1) 初始化列表,以便存储潜变量 (latent_vectors) 和相应的图像类别(存储每个图像的类别只是为了验证同一类别的图像是否具有较高的相似性,并不会在训练过程使用):
latent_vectors = []
classes = []
(2) 遍历验证数据加载器 (val_dl) 中的图像,并存储编码器的输出 (model.encoder(im).view(len(im),-1)) 和每个图像 (im) 对应的类别 (clss):
for im,clss in val_dl:latent_vectors.append(model.encoder(im).view(len(im),-1))classes.extend(clss)
(3) 连接潜变量 (latent_vectors) NumPy 数组:
latent_vectors = torch.cat(latent_vectors).cpu().detach().numpy()
(4) 导入 t-SNE 库 (TSNE),并将潜变量转换为二维向量 (TSNE(2)) ,以便进行绘制:
from sklearn.manifold import TSNE
tsne = TSNE(2)
(5) 通过在图像潜变量 (latent_vectors) 上运行 fit_transform 方法来拟合 t-SNE:
clustered = tsne.fit_transform(latent_vectors)
(6) 拟合 t-SNE 后绘制数据点:
fig = plt.figure(figsize=(12,10))
cmap = plt.get_cmap('Spectral', 10)
plt.scatter(*zip(*clustered), c=classes, cmap=cmap)
plt.colorbar(drawedges=True)
plt.show()

可以看到同一类别的图像能够聚集在一起,即相似的图像将具有相似的潜变量值。
小结
卷积自编码器是一种基于卷积神经网络结构的自编码器,适用于处理图像数据。卷积自编码器在图像处理领域有广泛的应用,包括图像去噪、图像压缩、图像生成等任务。通过训练卷积自编码器,可以提取出输入图像的关键特征,并实现对图像数据的降维和压缩,同时保留重要的空间信息。在本节中,我们介绍了卷积自编码器的模型架构,使用 PyTorch 从零开始实现在 MNIST 数据集上训练了一个简单的卷积自编码器,并使用 t-SNE 技术在二维平面中表示了所有测试图像的潜变量。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
相关文章:
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器 0. 前言1. 卷积自编码器2. 使用 t-SNE 对相似图像进行分组小结系列链接 0. 前言 我们已经学习了自编码器 (AutoEncoder) 的原理,并使用 PyTorch 搭建了全连接自编码器,但我们使用的数据…...

Milvus实战:构建QA系统及推荐系统
Milvus简介 全民AI的时代已经在趋势之中,各类应用层出不穷,而想要构建一个完善的AI应用/系统,底层存储是不可缺少的一个组件。 与传统数据库或大数据存储不同的是,这种场景下则需要选择向量数据库,是专门用来存储和查…...
使用Docker部署Nexus Maven私有仓库并结合Cpolar实现远程访问
文章目录 1. Docker安装Nexus2. 本地访问Nexus3. Linux安装Cpolar4. 配置Nexus界面公网地址5. 远程访问 Nexus界面6. 固定Nexus公网地址7. 固定地址访问Nexus Nexus是一个仓库管理工具,用于管理和组织软件构建过程中的依赖项和构件。它与Maven密切相关,可…...

GEE-Sentinel-2月度时间序列数据合成并导出
系列文章目录 第一章:时间序列数据合成 文章目录 系列文章目录前言时间序列数据合成总结 前言 利用每个月可获取植被指数数据取均值,合成月度平均植被指数,然后将12个月中的数据合成一个12波段的时间数据合成数据。 时间序列数据合成 代码…...

【深度学习】语言模型与注意力机制以及Bert实战指引之二
文章目录 前言 前言 这一篇是bert实战的完结篇,准备中。...
计算机网络 网络层下 | IPv6 路由选择协议,P多播,虚拟专用网络VPN,MPLS多协议标签
文章目录 5 IPv65.1 组成5.2 IPv6地址5.3 从IPv4向IPv6过渡5.3.1 双协议栈5.3.2 隧道技术 6 因特网的路由选择协议6.1 内部网关协议RIP6.2 内部网关协议 OSPF基本特点 6.3 外部网关协议 BGP6.3.1 路由选择 6.4 路由器组成6.4.1 基本了解6.4.2 结构 7 IP多播7.1 硬件多播7.2 IP多…...
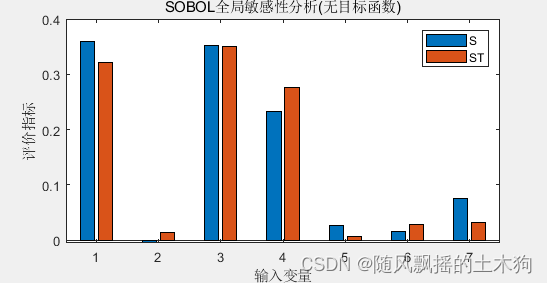
【MATLAB第83期】基于MATLAB的LSTM代理模型的SOBOL全局敏感性运用
【MATLAB第83期】基于MATLAB的LSTM代理模型的SOBOL全局敏感性运用 引言 在前面几期,介绍了敏感性分析法,本期来介绍lstm作为代理模型的sobol全局敏感性分析模型。 【MATLAB第31期】基于MATLAB的降维/全局敏感性分析/特征排序/数据处理回归问题MATLAB代…...
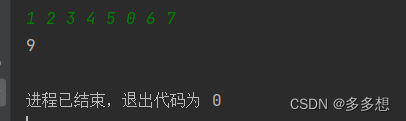
求奇数的和 C语言xdoj147
题目描述:计算给定一组整数中奇数的和,直到遇到0时结束。 输入格式:共一行,输入一组整数,以空格分隔 输出格式:输出一个整数 示例: 输入:1 2 3 4 5 0 6 7 输出:9 #inclu…...

全链路压力测试:解析其主要特点
随着信息技术的飞速发展和云计算的普及,全链路压力测试作为一种关键的质量保障手段,在软件开发和系统部署中扮演着至关重要的角色。全链路压力测试以模拟真实生产环境的压力和负载,对整个业务流程进行全面测试,具有以下主要特点&a…...

算法基础之约数个数
约数个数 核心思想: 用哈希表存每个质因数的指数 然后套公式 #include <iostream>#include <algorithm>#include <unordered_map>#include <vector>using namespace std;const int N 110 , mod 1e9 7;typedef long long LL; //long l…...
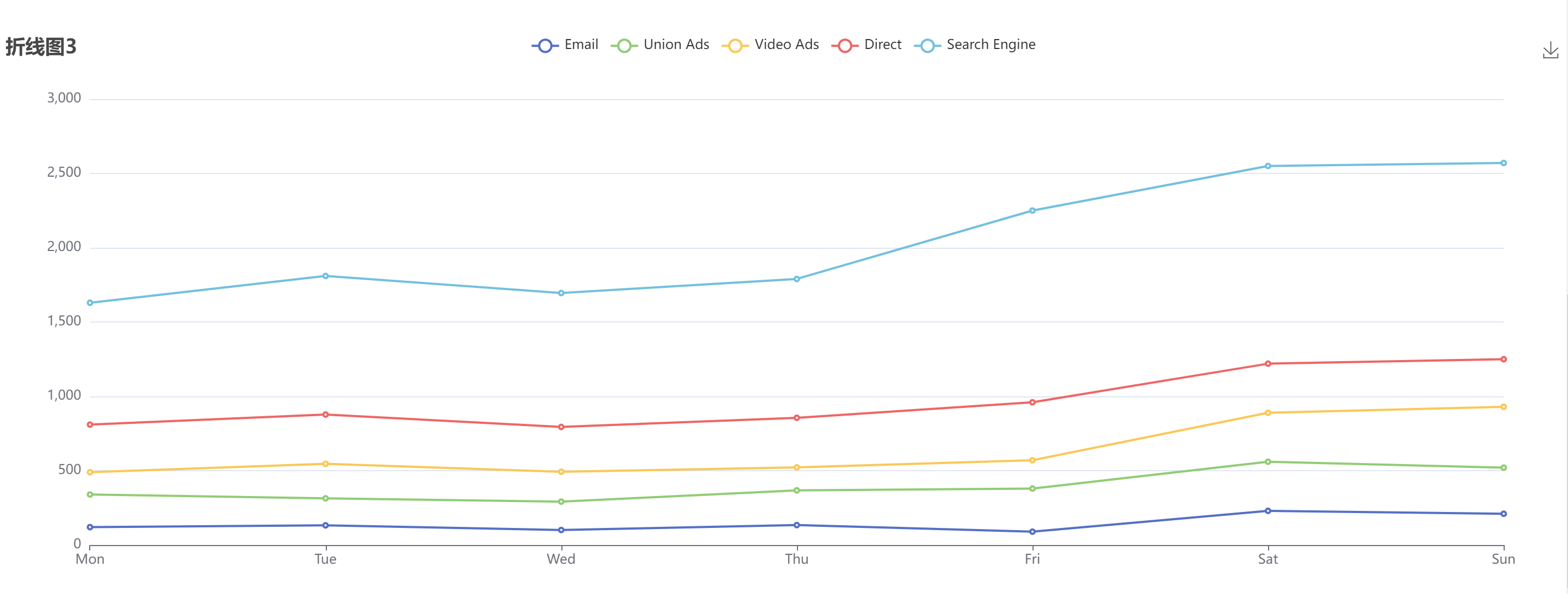
【ECharts】折线图
文章目录 折线图1折线图2折线图3示例 参考: Echarts官网 Echarts 配置项 折线图1 带X轴、Y轴标记线,其中X轴是’category’ 类目轴,适用于离散的类目数据。 let myChart echarts.init(this.$refs.line_chart2); let yList [400, 500, 6…...
java jdbc连接池
什么是连接池: Java JDBC连接池是一个管理和分配数据库连接的工具。在Java应用程序中,连接到数据库是一个耗时且资源密集的操作,而连接池可以通过创建一组预先初始化的数据库连接,然后将其保持在连接池中,并按需分配给…...
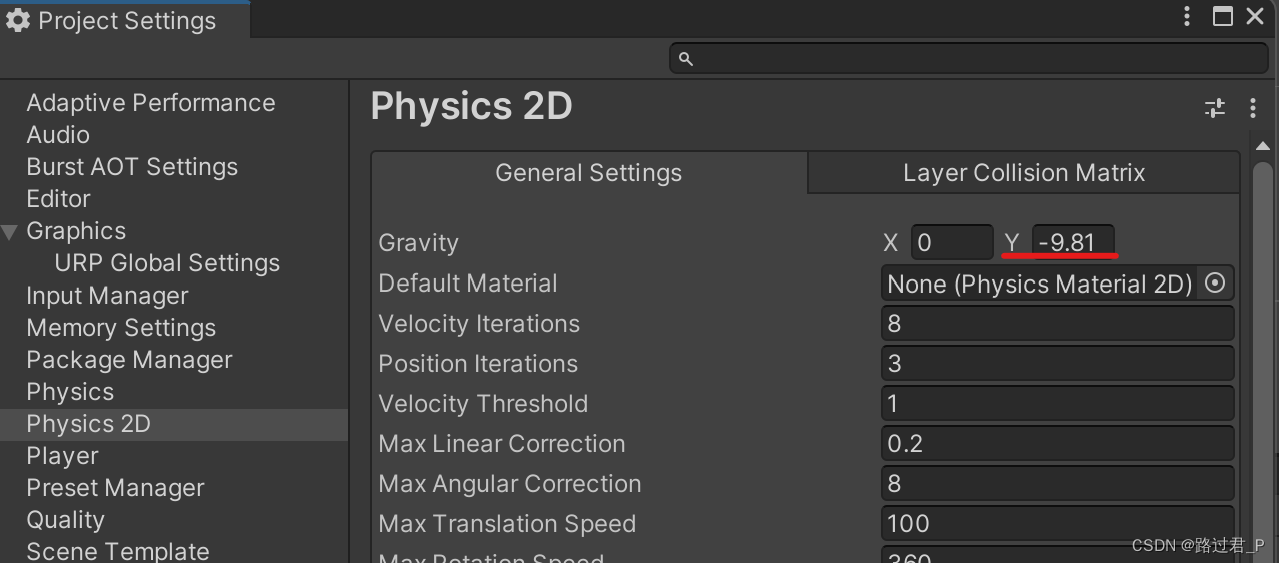
unity2d 关闭全局重力
UNITY2D项目默认存在Y轴方向重力,创建俯视角2D场景时可通过以下配置关闭 Edit > Project Settings > Physics 2D > General Settings > Gravity 设置Y0...
大数据时代,如何基于机密虚拟化技术构建数据安全的“基石”
云布道师 2023 年 10 月 31 日-11 月 2 日,2023 云栖大会在中国杭州云栖小镇举行,阿里云弹性计算产品专家唐湘华、阿里云高级安全专家刘煜堃、蚂蚁集团高级技术专家肖俊贤三位嘉宾在【云服务器 & 计算服务】专场中共同带来题为《大数据时代…...

为你自己学laravel - 15 - model的更新和删除
为你自己学laravel。 model的部分。 这一次讲解的是model当中怎么从数据库当中更新数据和删除数据。 先从数据库当中抓出来资料。 当然我们是使用php artisan tinker进入到终端机。 我们的做法是想要将available这个栏位修改成为true。 第一种更新方法 上面我们就是修改了对…...

列举mfc140u.dll丢失的解决方法,常见的mfc140u.dll问题
在使用电脑的过程中,有时会遇到mfc140u.dll文件丢失的问题,导致一些应用程序无法正常启动。本文将介绍mfc140u.dll丢失的常见原因,并提供相应的解决办法。同时,还会列举一些与mfc140u.dll丢失相关的常见问题和解答。 第一部分&…...

智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.野狗算法4.实验参数设定5.算法结果6.参考文献7.MA…...
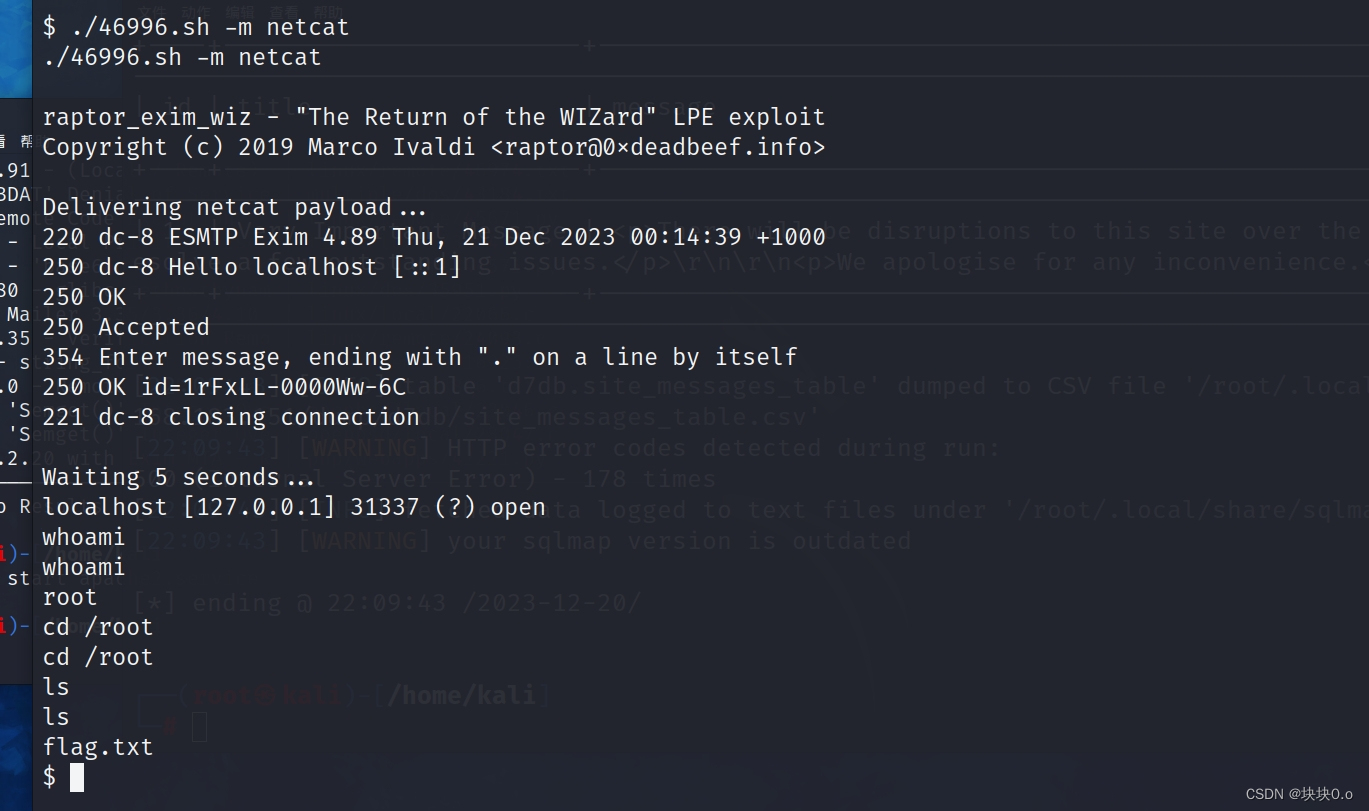
DC-8靶场
目录 DC-8靶场链接: 首先进行主机发现: sqlmap得到账号密码: 反弹shell: exim4提权: Flag: DC-8靶场链接: https://www.five86.com/downloads/DC-8.zip 下载后解压会有一个DC-8.ova文件…...
SQL Server 安装教程
安装数据库 1、启动SQL Server2014安装程序,运行setup.exe文件,打开”SQL Server安装中心“对话框,单击左侧 的导航区域中的”安装“选项卡。 2、选择”全新SQL Server独立安装或向现有安装添加功能“,启动SQL Server2014安装向导…...
快猫视频模板源码定制开发 苹果CMS 可打包成双端APP
苹果CMS快猫视频网站模板源码,可用于开发双端APP,后台支持自定义参数,包括会员升级页面、视频、演员、专题、收藏和会员系统等完整模块。还可以直接指定某个分类下的视频为免费专区,具备完善的卡密支付体系,无需人工管…...

通过taotoken审计日志追溯api调用详情与安全分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志追溯API调用详情与安全分析 对于将大模型API集成到业务流程中的团队而言,API调用的可见性与可控性…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...

FPGA高速ADC数据采集实战——基于AD9253 LVDS接口与ISERDESE2设计
1. AD9253高速ADC核心特性解析 AD9253这颗14位125MSPS四通道ADC芯片,在通信和医疗成像领域堪称经典。我经手过的多个雷达项目中,它的信噪比表现总能带来惊喜——75.3dBFS的实测数据比手册标称值还要稳定。但真正让工程师们又爱又恨的,是它那个…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

开源技能图谱工具SkillPort:Go语言构建的知识管理利器
1. 项目概述:一个技能图谱与知识管理的开源利器 最近在整理个人技术栈和团队知识库时,我一直在寻找一个能直观展示技能关联、又能深度管理学习路径的工具。市面上的笔记软件要么太“平”,只能线性记录;要么太“重”,像…...

AI项目脚手架:标准化与自动化提升工程效率
1. 项目概述:一个为AI项目量身定制的“脚手架”如果你和我一样,在AI领域摸爬滚打多年,从早期的机器学习模型到现在的深度学习、大语言模型应用,肯定经历过无数次从零开始搭建项目的“阵痛”。每次新建一个项目,都要重复…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...