Zookeeper-应用实战
Zookeeper Java客户端实战
ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。
-
ZooKeeper官方的Java客户端API。
-
第三方的Java客户端API,比如Curator。
ZooKeeper官方的客户端API提供了基本的操作:创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。
对于实际开发来说,ZooKeeper官方API有一些不足之处:
-
ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册。
-
会话超时之后没有实现重连机制。
-
异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
-
仅提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
-
创建节点时如果抛出异常,需要自行检查节点是否存在。
-
无法实现级联删除。
总之,ZooKeeper官方API功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。
Zookeeper 原生Java客户端使用
引入zookeeper client依赖
<!-- zookeeper client -->
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.0</version>
</dependency>注意:保持与服务端版本一致,避免兼容性的问题
ZooKeeper常用构造器
ZooKeeper (connectString, sessionTimeout, watcher)| 参数 | 描述 |
|---|---|
| connectString | 逗号分隔的列表,每个ZooKeeper节点是一个host.port对,host 是机器名或者IP地址,port是ZooKeeper节点对客户端提供服务的端口号。客户端会任意选取connectString 中的一个节点建立连接。 |
| sessionTimeout | session timeout时间。 |
| watcher | 接收到来自ZooKeeper集群的事件。 |
使用 zookeeper 原生 API,连接zookeeper集群
public class ZkClientDemo
{private static final String CONNECT_STR = "你的公网IP:2181";private final static String CLUSTER_CONNECT_STR = "192.168.65.156:2181,192.168.65.190:2181,192.168.65.200:2181";public static void main(String[] args)throws Exception{final CountDownLatch countDownLatch = new CountDownLatch(1);ZooKeeper zooKeeper = new ZooKeeper(CONNECT_STR, 4000, new Watcher(){@Overridepublic void process(WatchedEvent event){if (Event.KeeperState.SyncConnected == event.getState() && event.getType() == Event.EventType.None){// 如果收到了服务端的响应事件,连接成功countDownLatch.countDown();System.out.println("连接建立");}}});System.out.printf("连接中");countDownLatch.await();// CONNECTEDSystem.out.println(zooKeeper.getState());// 创建持久节点zooKeeper.create("/user", "gao".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}
}Zookeeper主要方法
| 方法 | 功能 |
|---|---|
| create(path, data, acl,createMode) | 创建一个给定路径的 znode,并在 znode 保存 data[]的 数据,createMode指定 znode 的类型。 |
| delete(path, version) | 如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除 znode |
| exists(path, watch) | 判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch |
| getData(path, watch) | 返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。 |
| setData(path, data, version) | 如果给定 path 上的 znode 的版本和给定的 version 匹配,设置 znode 数据。 |
| getChildren(path, watch) | 返回给定 path 上的 znode 的子 znode 名字,并在 znode 设置一个 watch。 |
| sync(path) | 把客户端 session 连接节点和 leader 节点进行同步。 |
方法特点:
-
所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化。
-
所有更新 znode 数据的 API 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为 -1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新。
-
所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来自服务端的响应。
同步创建节点:
public void createTest() throws KeeperException, InterruptedException
{String path = zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);log.info("created path: {}",path);
}异步创建节点:
public void createAsycTest() throws InterruptedException
{zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT,(rc, path, ctx, name) -> log.info("rc {},path {},ctx {},name {}",rc,path,ctx,name),"context");TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}修改数据:
public void setTest() throws KeeperException, InterruptedException
{Stat stat = new Stat();byte[] data = zooKeeper.getData(ZK_NODE, false, stat);log.info("修改前: {}",new String(data));zooKeeper.setData(ZK_NODE, "changed!".getBytes(), stat.getVersion());byte[] dataAfter = zooKeeper.getData(ZK_NODE, false, stat);log.info("修改后: {}",new String(dataAfter));
}Curator开源客户端使用
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册Watcher的问题以及NodeExistsException异常等。
Curator是Apache基金会的顶级项目之一,Curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。
Curator还为ZooKeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
在实际的开发场景中,使用Curator客户端就足以应付日常的ZooKeeper集群操作的需求。
官网:Apache Curator
引入依赖
-
curator-framework是对ZooKeeper的底层API的一些封装。
-
curator-client提供了一些客户端的操作,例如重试策略等。
-
curator-recipes封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。
<!-- zookeeper client -->
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.0</version>
</dependency><!--curator-->
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>5.1.0</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions>
</dependency>创建一个客户端实例
使用curator-framework包操作ZooKeeper前,首先要创建一个客户端实例(CuratorFramework类型的对象)
-
使用工厂类CuratorFrameworkFactory的静态newClient()方法
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3)
//创建客户端实例
CuratorFramework client = CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy);
//启动客户端
client.start();-
使用工厂类CuratorFrameworkFactory的静态builder构造者方法
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.128.129:2181").sessionTimeoutMs(5000) // 会话超时时间.connectionTimeoutMs(5000) // 连接超时时间.retryPolicy(retryPolicy).namespace("base") // 包含隔离名称.build();
client.start();-
connectionString:服务器地址列表,一个或多个。(多个地址列表用逗号分隔)
-
retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接 ZooKeeper 服务端。( Curator 内部,通过判断服务器返回的 keeperException 状态代码判断是否重试)
| 策略名称 | 描述 |
|---|---|
| ExponentialBackoffRetry | 重试一组次数,重试之间的睡眠时间增加 |
| RetryNTimes | 重试最大次数 |
| RetryOneTime | 只重试一次 |
| RetryUntilElapsed | 在给定的时间结束之前重试 |
-
超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。
创建节点
public void testCreate() throws Exception
{String path = curatorFramework.create().forPath("/curator-node");curatorFramework.create().withMode(CreateMode.PERSISTENT).forPath("/curator-node","some-data".getBytes())log.info("curator create node :{} successfully.",path);
}一次性创建带层级结构的节点
public void testCreateWithParent() throws Exception
{String pathWithParent="/node-parent/sub-node-1";String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent);log.info("curator create node :{} successfully.",path);
}获取数据
public void testGetData() throws Exception
{byte[] bytes = curatorFramework.getData().forPath("/curator-node");log.info("get data from node :{} successfully.",new String(bytes));
}更新节点
public void testSetData() throws Exception
{curatorFramework.setData().forPath("/curator-node","changed!".getBytes());byte[] bytes = curatorFramework.setData().forPath("/curator-node");log.info("get data from node /curator-node :{} successfully.",new String(bytes));
}删除节点
public void testDelete() throws Exception
{String pathWithParent="/node-parent";curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);
}guaranteed:保障删除成功,底层工作方式是:只要该客户端的会话有效,就会在后台持续发起删除请求,直到该数据节点在 ZooKeeper 服务端被删除。
deletingChildrenIfNeeded:指定了该函数后,系统在删除该数据节点的时候会以递归的方式直接删除其子节点,以及子节点的子节点。
异步接口
public interface BackgroundCallback
{/*** Called when the async background operation completes** @param client the client* @param event operation result details* @throws Exception errors*/public void processResult(CuratorFramework client, CuratorEvent event) throws Exception;
}默认在 EventThread 中调用
public void test() throws Exception
{//inBackground 异步处理默认在EventThread中执行curatorFramework.getData().inBackground((item1, item2) -> {log.info(" background: {}", item2);}).forPath(ZK_NODE);TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}指定线程池
public void test() throws Exception
{ExecutorService executorService = Executors.newSingleThreadExecutor();curatorFramework.getData().inBackground((item1, item2) -> {log.info(" background: {}", item2);},executorService).forPath(ZK_NODE);TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}Curator 监听器
/*** Receives notifications about errors and background events*/
public interface CuratorListener
{/*** Called when a background task has completed or a watch has triggered** @param client client* @param event the event* @throws Exception any errors*/public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception;
}Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 提供了反复注册的功能。Cache 分为两类注册类型:节点监听和子节点监听。
node cache:NodeCache 对某一个节点进行监听
@Slf4j
public class NodeCacheTest extends AbstractCuratorTest{public static final String NODE_CACHE="/node-cache";@Testpublic void testNodeCacheTest() throws Exception {createIfNeed(NODE_CACHE);NodeCache nodeCache = new NodeCache(curatorFramework, NODE_CACHE);nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {log.info("{} path nodeChanged: ",NODE_CACHE);printNodeData();}});nodeCache.start();}public void printNodeData() throws Exception {byte[] bytes = curatorFramework.getData().forPath(NODE_CACHE);log.info("data: {}",new String(bytes));}
}path cache: PathChildrenCache 会对子节点进行监听,但是不会对二级子节点进行监听,
@Slf4j
public class PathCacheTest extends AbstractCuratorTest{public static final String PATH="/path-cache";@Testpublic void testPathCache() throws Exception {createIfNeed(PATH);PathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, PATH, true);pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {log.info("event: {}",event);}});// 如果设置为true则在首次启动时就会缓存节点内容到Cache中pathChildrenCache.start(true);}
}tree cache:TreeCache 使用一个内部类TreeNode来维护这个一个树结构。并将这个树结构与ZK节点进行了映射。所以TreeCache 可以监听当前节点下所有节点的事件。
@Slf4j
public class TreeCacheTest extends AbstractCuratorTest{public static final String TREE_CACHE="/tree-path";@Testpublic void testTreeCache() throws Exception {createIfNeed(TREE_CACHE);TreeCache treeCache = new TreeCache(curatorFramework, TREE_CACHE);treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {log.info(" tree cache: {}",event);}});treeCache.start();}
}相关文章:

Zookeeper-应用实战
Zookeeper Java客户端实战 ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。 ZooKeeper官方的Java客户端API。 第三方的Java客户端API,比如Curator。 ZooKeeper官方的客户端API提供了基本的操作:创建会话、创建节点、读取节点、更新数据、…...
2017年第六届数学建模国际赛小美赛A题飓风与全球变暖解题全过程文档及程序
2017年第六届数学建模国际赛小美赛 A题 飓风与全球变暖 原题再现: 飓风(也包括在西北太平洋被称为“台风”的风暴以及在印度洋和西南太平洋被称为“严重热带气旋”)具有极大的破坏性,往往造成数百人甚至数千人死亡。 许多气…...
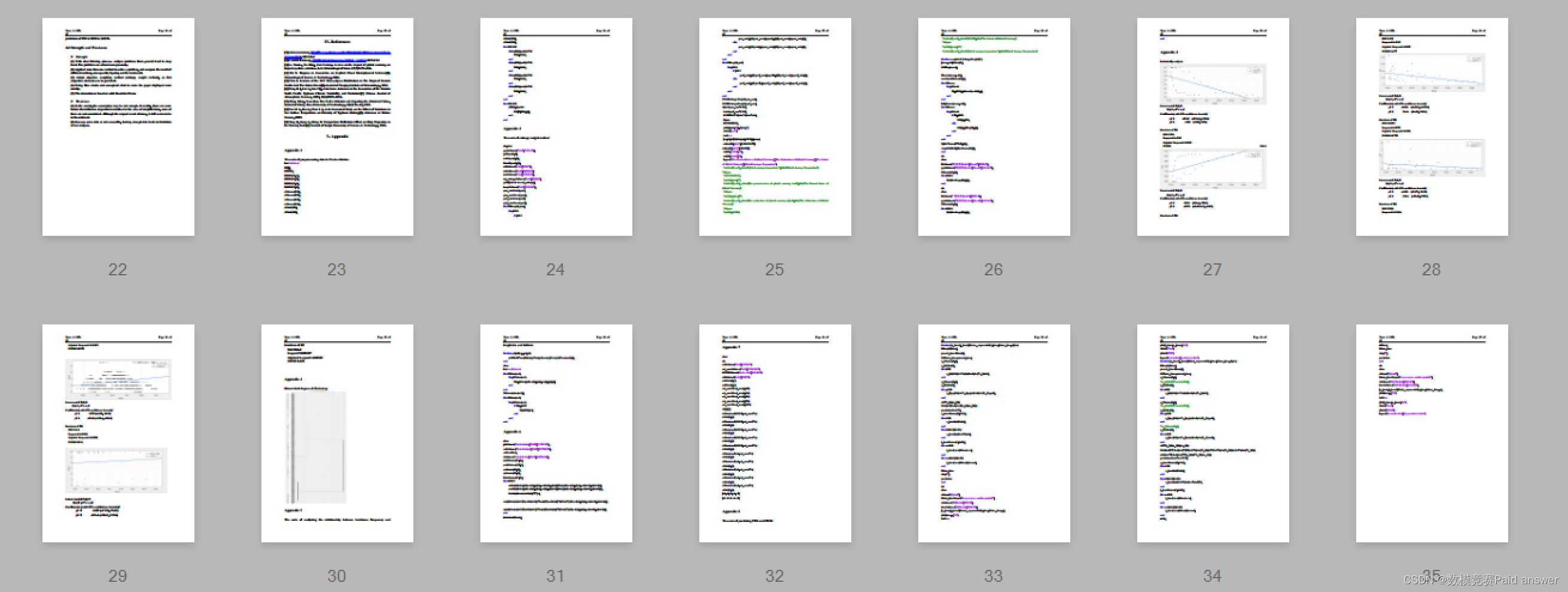
Node.js使用Express框架写服务端接口时,如何将接口拆分到不同文件中
项目目录结构说明: node.js连接mysql数据库步骤可参考:Node.js 连接 MySQL | 菜鸟教程 1、拆分之前的写法,未区分模块,所有接口api都写在了入口文件app.js中; 需求:想要将接口api拆分成根据不同的业务模块…...

Unity | Shader基础知识(第八集:案例<漫反射材质球>)
目录 一、本节介绍 1 上集回顾 2 本节介绍 二、什么是漫反射材质球 三、 漫反射进化史 1 三种算法结果的区别 2 具体算法 2.1 兰伯特逐顶点算法 a.本小节使用的unity自带结构体。 b.兰伯特逐顶点算法公式 c.代码实现——兰伯特逐顶点算法 2.2 代码实现——兰伯特逐…...
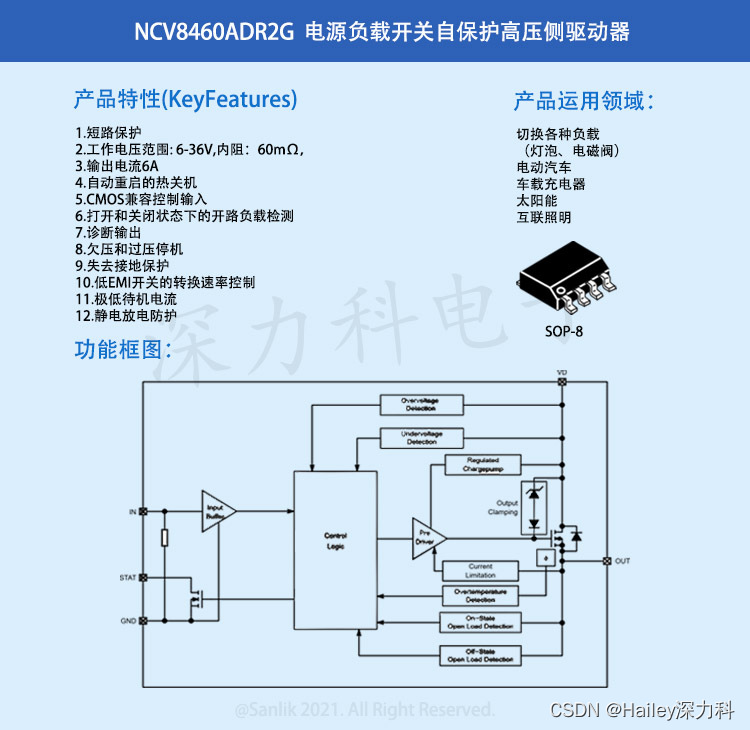
NCV8460ADR2G在汽车和工业应用中高压侧驱动如何破?
NCV8460ADR2G是一款完全保护的高压侧驱动器,可用于开关各种负载,如灯泡、电磁阀和其他致动器。该器件可以通过有源电流限制和高温关断针对过载情况进行内部保护。 诊断状态输出引脚提供了高温以及开关状态开路负载情况的数字故障指示。 特性:…...

在打日志时,如何使用snowflake-id快速方便得随机获取query的唯一id
步骤一:安装snowflake-id pip install snowflake-id步骤二:代码示例 from snowflake import SnowflakeGeneratorgen SnowflakeGenerator(42)for i in range(100):val next(gen)print(val)参考文档: https://pypi.org/project/snowflake-…...
Linux之yum管理器
目录 yum管理器 yum相关指令 yum list yum list | grep yum install yum remove 拓展 1.yum install -y man-pages 2.切换yum源 3.yum install -y epel-release 4. yum install -y lrzsz rz指令 sz指令 在window系统上,我们会在电脑自带的应用商…...

ubuntu 搭建本地私有pip源
# 搭建本地私有pip源 pip install pip2pi# 创建目录 mkdir /data/work/PyPip/ mkdir /data/work/PyPip/packages cd /data/work/PyPip/# 创建需要从外网源同步的package touch requirements_roop.txt# 批量同步 pip2tgz /data/work/PyPip/packages -r requirements_roop.txt# 同…...
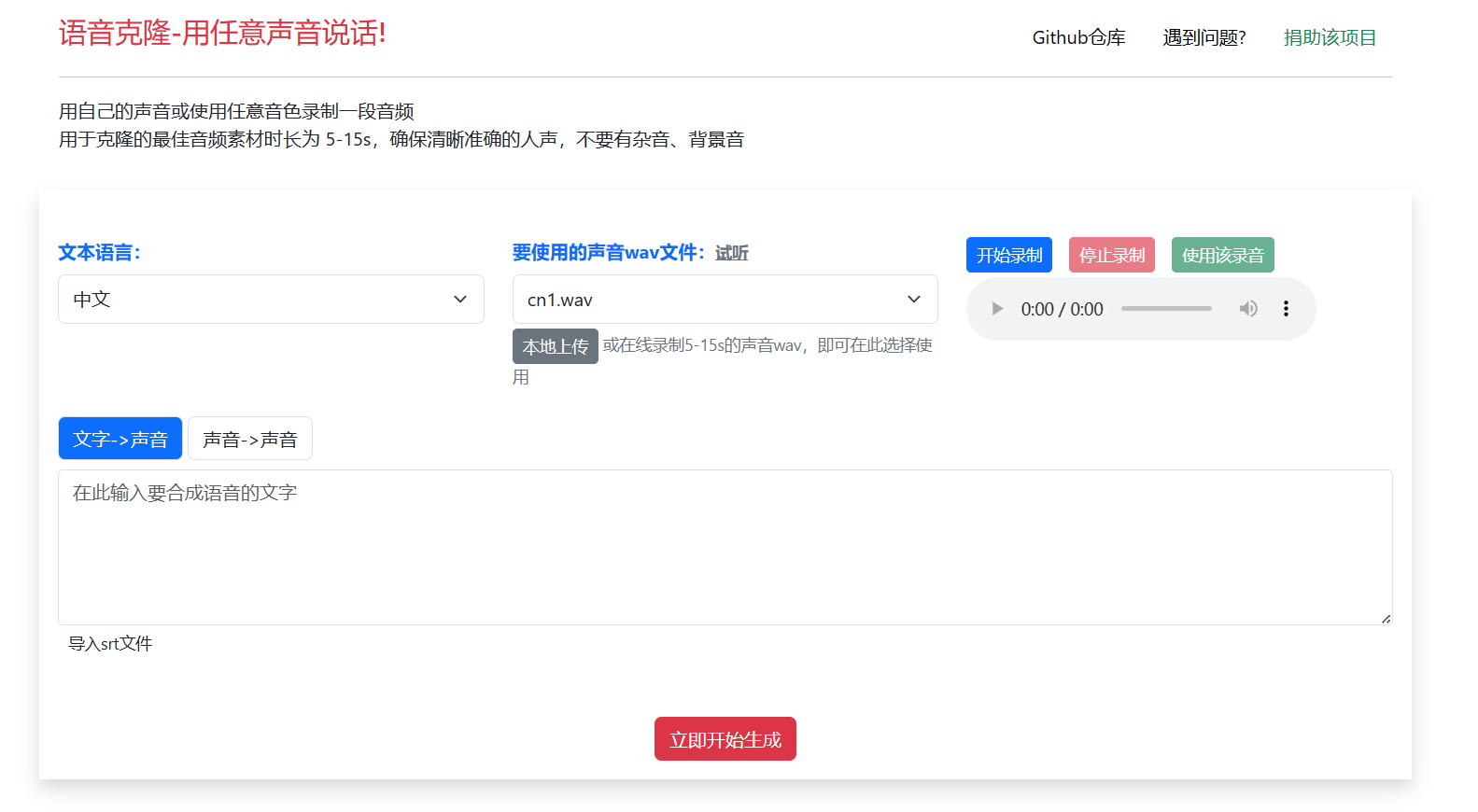
声音克隆:让你的声音变得无所不能
什么是声音克隆? 声音克隆是一种利用人工智能技术,根据一段声音样本,生成与之相似或完全相同的声音的过程。声音克隆可以用于多种场景。 声音克隆的原理是利用深度学习模型,从声音样本中提取声音特征,然后根据目标文…...

hadoop02_HDFS的API操作
HDFS的API操作 1 HDFS 核心类简介 Configuration类:处理HDFS配置的核心类。 FileSystem类:处理HDFS文件相关操作的核心类,包括对文件夹或文件的创建,删除,查看状态,复制,从本地挪动到HDFS文件系统中等。…...
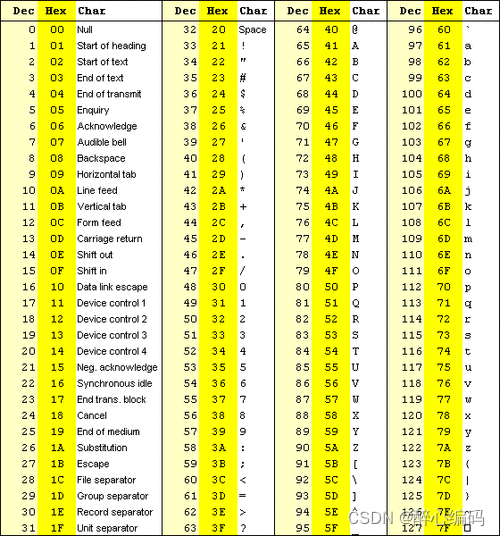
使用C语言将ASCII明文编码为GSM短信体格式
一、背景介绍 GSM(Global System for Mobile Communications)是全球移动通信系统的简称,而GSM 03.38是GSM系统中用于短信编码的标准。GSM 03.38字符集采用7-bit编码,与ASCII的8-bit编码有所不同。为了将ASCII编码的文本转换为GSM…...
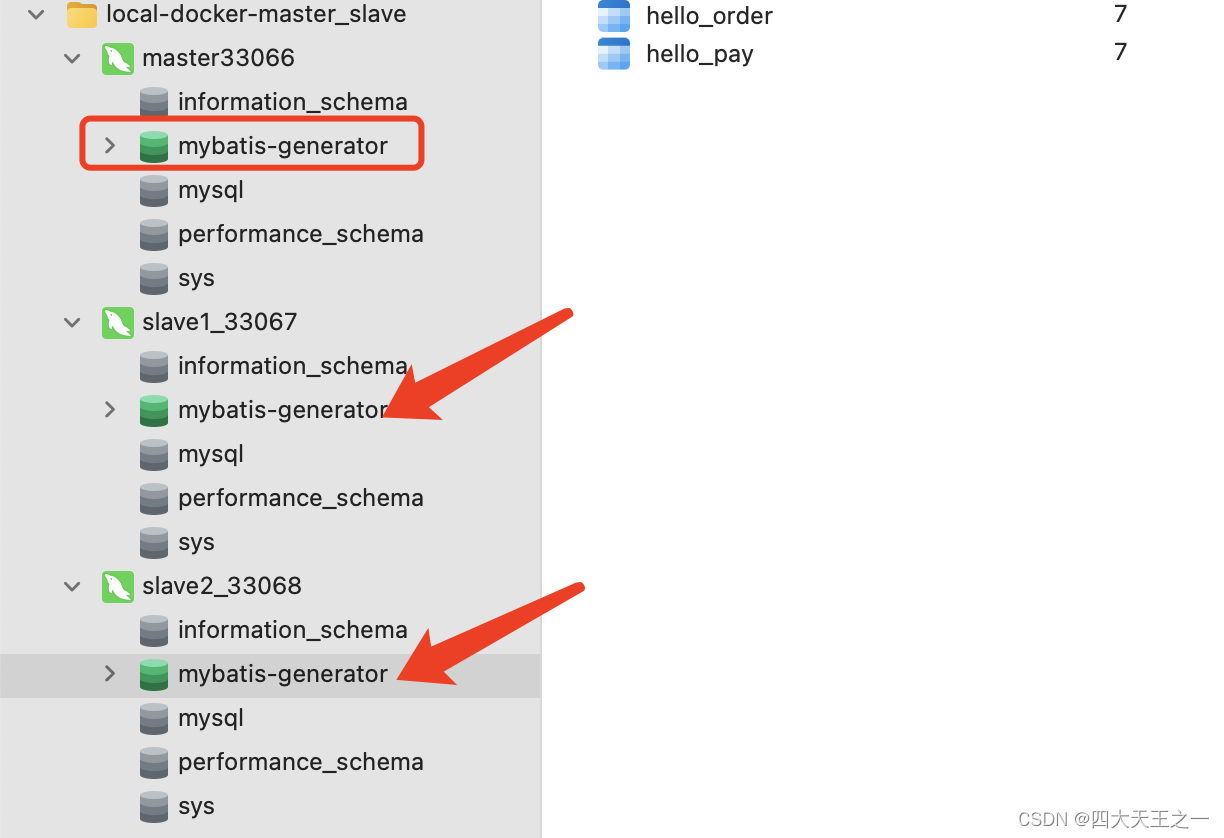
docker搭建mysql8.0.32,实现主从复制(一主两从)
安装docker的步骤、使用命令就不写了,本文章是基于会使用docker、linux基本命令的基础上来写的。 开始步骤: 1. 拉取 mysql 镜像 docker pull mysql:8.0.32 2. 启动容器并运行mysql a. 准备mysql的配置文件(该配置文件是:mysq…...

AOP springboot
1. 2. Around(“execution(* com.example.demo.controller..(…))”) 代表所有的类下面所有的方法任意参数 3....

Python Flask 基础入门第六课: Flask 全局变量 current_app, g 以及 session各自如何使用 有什么差异
全局变量 current_app, g 以及 session 全局变量差异汇总表current_app章节1 current_app - 当前应用实例current_app的基本概念current_app的作用current_app的使用 章节2:current_app的上下文什么是应用上下文?current_app与应用上下文的关系current_a…...

第33节: Vue3 方法与在线检测
UniApp 使用 Vue3 框架时,您可以使用方法和在线检测来处理应用程序中的逻辑和数据。下面是一个示例,演示了如何在 UniApp 中使用 Vue3 框架使用方法和在线检测: <template> <view> <button click"handleClick"&g…...

React学习计划-React16--React基础(二)组件与组件的3大核心属性state、props、ref和事件处理
1. 组件 函数式组件(适用于【简单组件】的定义) 示例: 执行了ReactDOM.render(<MyComponent/>, ...)之后执行了什么? React解析组件标签,找到了MyComponent组件发现组件是使用函数定义的,随后调用该…...

flink yarn-session 启动失败retrying connect to server 0.0.0.0/0.0.0.0:8032
原因分析,启动yarn-session.sh,会向resourcemanager的端口8032发起请求: 但是一直无法请求到8032端口,触发重试机制会不断尝试 备注:此问题出现时,我的环境ambari部署的HA 高可用hadoop,三个节点…...
)
.NET面试题(二)
1.c# 中new关键字的作用 实例化对象和调用构造函数:当使用 new 关键字创建一个类的实例时,它会为对象分配内存,并调用相应的构造函数来初始化该对象。 隐藏基类成员(方法、属性、事件等):当在派生类中…...

ffplay工具
在编译ffmpeg时,如果系统中包含了SDL库,则会默认编译生成ffplay工具,否则无法生成ffplay工具。 ffplay即可以作为播放器,也可以作为很多图像化音视频数据的分析工具,通过它可以看到视频图像的运动估计方向、音频数据的…...

第36节: Vue3 事件修饰符
在UniApp中使用Vue3框架时,你可以使用事件修饰符来更方便地处理用户交互事件。以下是一个示例,演示了如何在UniApp中使用Vue3框架使用事件修饰符: <template> <view> <button click.prevent"handleClick">Cli…...

GPT宏系统开发指南:从提示词模板到RAG知识库的自动化实践
1. 项目概述:一个让GPT“记住”并“执行”的自动化利器如果你经常和GPT打交道,无论是ChatGPT的Web界面,还是通过API调用,肯定都遇到过这样的烦恼:每次对话,你都得把那些重复的、固定的指令或背景信息再敲一…...

MCP Jenkins Intelligence:基于AI的Jenkins智能运维与效率提升实践
1. 项目概述:当Jenkins遇上AI,DevOps的“副驾驶”来了如果你和我一样,每天都要和Jenkins打交道,盯着那些流水线看构建状态、查失败日志、分析性能瓶颈,那你肯定也幻想过:要是能像聊天一样问它问题就好了。比…...

questasim下载安装
questasim下载安装 https://zhuanlan.zhihu.com/p/682726018...

基于Next.js urborepo的企业级电商全栈架构实战解析
1. 项目概述与核心价值最近在梳理企业级电商项目的技术选型与架构方案,发现了一个非常值得深入研究的开源项目——Blazity/enterprise-commerce。这不仅仅是一个简单的电商模板,而是一个基于Next.js 14、TypeScript和Turborepo构建的现代化、全栈式企业级…...

终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具
终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源下载卡在提取码这一步而烦恼吗?每次遇到需要密码的分享链接,都要…...

从国赛H题到实战:构建远程幅频特性测试系统的硬件设计精要
1. 从竞赛到实战的硬件设计转型 参加电子设计竞赛的朋友们都知道,国赛H题这类题目往往能给我们带来宝贵的实战经验。2017年的这道远程幅频特性测试装置题目,看似是一个具体的竞赛任务,实则蕴含了许多通用硬件设计原理。我在实际项目中多次运用…...

爱搜索 GEO 营销系统实效展示与能力验证
在当前的数字营销环境中,许多企业发现传统的 SEO 手段在应对 AI 驱动的搜索场景时显得力不从心。当潜在客户向大模型提问“哪家装修公司更靠谱”或“推荐几家铝板输送机厂家”时,如果品牌未能出现在 AI 生成的答案中,就意味着失去了最精准的流…...

控制面容灾实战:别让“不处理业务请求“的系统拖死全站
控制面容灾实战:别让"不处理业务请求"的系统拖死全站 前言 控制面是分布式系统里最隐蔽也最致命的单点故障源。 注册中心、配置中心、证书系统、观测后端,这些系统看似"不处理任何业务请求",但一旦不可用,…...

别再死记硬背了!用PyTorch和TensorFlow动手实现池化层,5分钟搞懂Max Pooling和Average Pooling的区别
用PyTorch和TensorFlow实战池化层:5分钟可视化Max与Average Pooling差异 刚接触深度学习的开发者常被各种理论概念困扰,尤其是池化层这类看似简单却暗藏玄机的操作。与其死记硬背定义,不如打开Jupyter Notebook,用PyTorch和Tensor…...

基于物联网的泵车远程运维与主动服务解决方案
某设备制造商拥有大量在役泵车,分布在全国各地的基建工地和商混站。长期以来,售后服务团队面临着严峻的挑战:由于泵车多在户外流动作业、分布范围广,设备一旦发生故障,售后工程师需要千里奔波到现场才能判断问题&#…...