KnowLM知识抽取大模型
文章目录
- KnowLM项目介绍
- KnowLM项目的动机
- ChatGPT存在的问题
- 基于LLama的知识抽取的智析大模型
- 数据集构建及训练过程
- 预训练数据集构建
- 预训练训练过程
- 指令微调数据集构建
- 指令微调训练过程
- 开源的数据集及模型
- 局限性
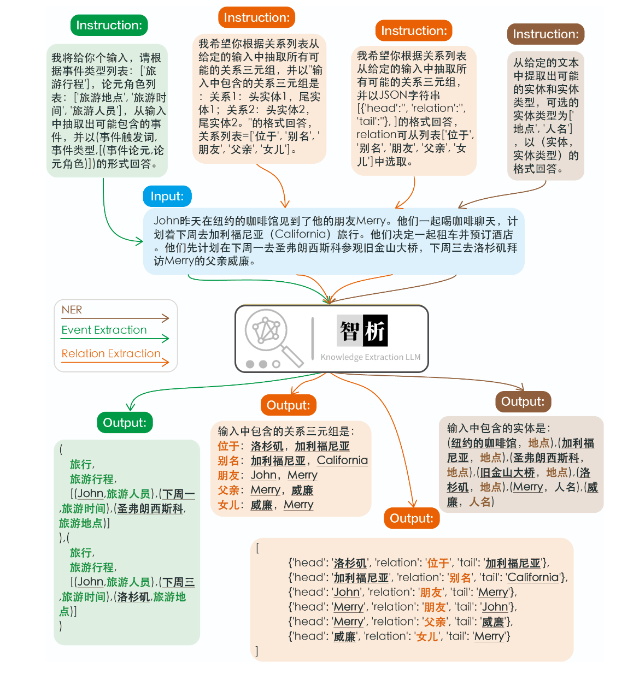
- 信息抽取Prompt
- 部署
- 环境配置
- 模型下载
- 预训练模型使用
- LoRA模型使用
KnowLM项目介绍
KnowLM 是由浙江大学NLP&KG团队的在读博士生研发并开源的项目,是一种将LLM与知识图谱结合的知识抽取大模型,主要包含的任务有命名实体识别(NER)、事件抽取(EE)、关系抽取(RE)。
github 地址:https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md
KnowLM 项目的主要工作:
- 围绕知识和大模型,用构建的中英双语预训练语料对大模型如LLaMA进行全量预训练
- 基于知识图谱转换指令技术对知识抽取任务,包括NER、RE、IE进行优化,可以使用人类指令来完成信息抽取任务
- 用构建的中文指令数据集(约1400K条样本),使用LoRA微调,提高模型对于人类指令的理解
- 开源了预训练模型的权重、指令微调的LoRA权重
- 开源了全量预训练脚本(提供大型语料的转换、构建和加载)和LoRA指令微调脚本(支持多机多卡)
KnowLM项目的动机
ChatGPT存在的问题
目前,大模型如ChatGPT等虽然在自然语言领域已经取得了显著的成就,但在学习和理解知识方面仍然有一些挑战和问题,如:
LLM存在知识固化,知识更新困难,以及模型中潜在的错误和偏差等知识谬误的问题。


LLM对于特定任务的能力欠佳:如知识抽取、推理等;

从上面的示例可以看出,尽管ChatGPT可以对指令进行理解,并给出了合理的输出格式,但效果看起来并不好。
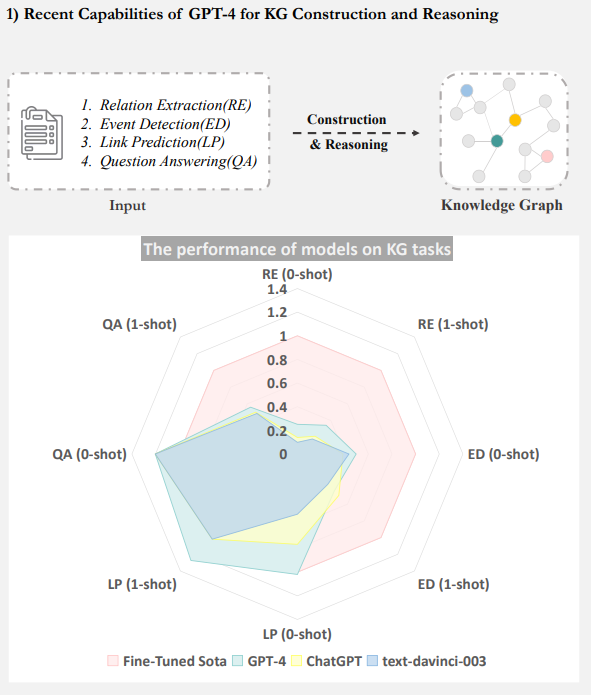
论文 LLMs for Knowledge Graph Construction and Reasoning:
Recent Capabilities and Future Opportunities 中对GPT-4、ChatGPT及在特定任务上的微调模型等在知识图谱构建和推理任务中的能力进行了评估,具体任务如关系抽取、事件检测、链接预测、问答等,评估效果如下所示:
基于LLama的知识抽取的智析大模型
数据集构建及训练过程
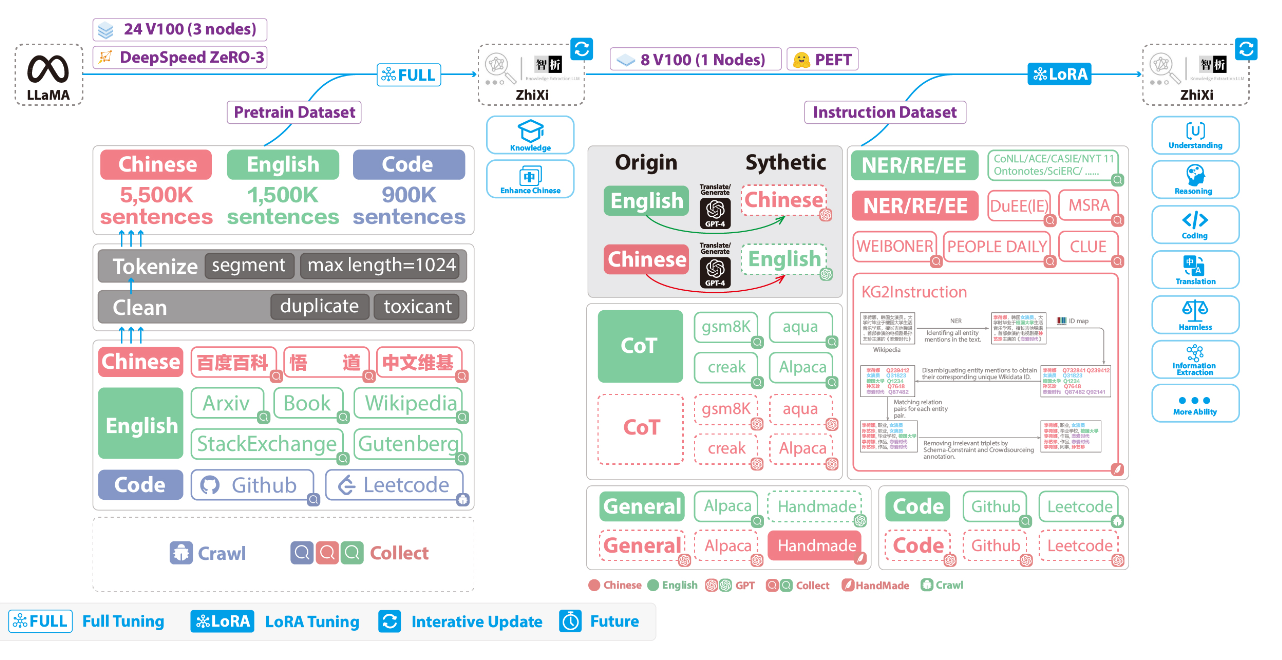
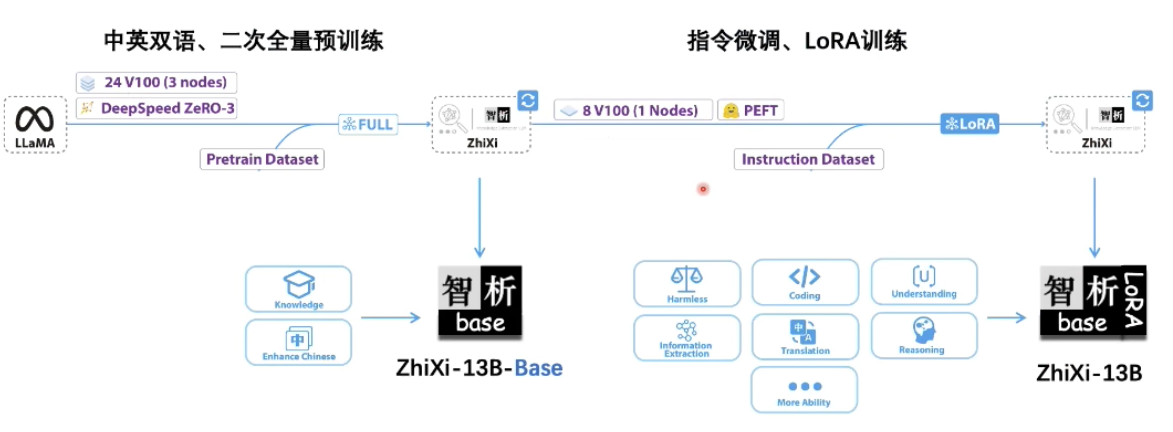
智析大模型的整个训练过程分为两个阶段:
第一阶段:全量预训练阶段。该阶段的目的是增强模型的中文能力和知识储备。
第二阶段:使用LoRA的指令微调阶段。该阶段让模型能够理解人类的指令并输出合适的内容。
数据集使用情况及训练过程如下图所示:
预训练数据集构建
为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,并没有对词表进行扩增,而是搜集了中文语料、英文语料和代码语料。
中文数据集:中文语料来自于百度百科、悟道和中文维基百科;
英文数据集:主要从LLaMA原始的英文语料中进行采样,不同的是维基数据,原始论文中的英文维基数据的最新时间点是2022年8月,团队成员额外爬取了2022年9月到2023年2月,总共六个月的数据;
代码数据集:爬取了Github、Leetcode的代码数据,一部分用于预训练,另外一部分用于指令微调。
对上面爬取到的数据集,团队成员使用了启发式的方法,剔除了数据集中有害的内容,此外,我们还剔除了重复的数据。
预训练训练过程
文档划分:通过贪心算法来对文档进行划分,贪心的目标是在保证每个样本都是完整的句子、分割的段数尽可能少的前提下,尽可能保证每个样本的长度尽可能长,设置的单个样本的最大长度是1024。

由于数据源的多样性,还设计了一套完整的数据预处理工具,可以对各个数据源进行处理然后合并。
由于数据量很大,如果直接将数据加载到内存,会导致硬件压力过大,于是参考了DeepSpeed-Megatron,使用mmap的方法对数据进行处理和加载,即将索引读入内存,需要的时候根据索引去硬盘查找。
最后,在5500K条中文样本、1500K条英文样本、900K条代码样本进行预训练。使用了 transformers 的 trainer 搭配 Deepspeed ZeRO3(实测使用ZeRO2在多机多卡场景的速度较慢),在3个Node(每个Node上为8张32GB V100卡)进行多机多卡训练。
Deepspeed ZeRO3解读:https://blog.csdn.net/v_JULY_v/article/details/132462452?spm=1001.2014.3001.5501
训练相关参数设置如下:
| 参数 | 值 |
|---|---|
| micro batch size(单张卡的batch size大小) | 20 |
| gradient accumulation(梯度累积) | 3 |
| global batch size(一个step的、全局的batch size) | 20 * 3 * 24=1440 |
| 一个step耗时 | 260s |
指令微调数据集构建
考虑到要加入一些通用的能力(比如推理能力、代码能力等),以及还要额外加入信息抽取能力(包括NER、RE、EE),使用下面数据集。
通用能力数据集(如推理能力、代码能力)
为了获得中文数据集,主要采用对英文数据集使用GPT4翻译的方式得到。英文数据集如比如alpaca数据集 CoT数据集、 代码数据集。
具体方式如下:
对于CoT数据集、 代码数据集等英文数据集,直接将问题和答案通过GPT4翻译成英文;
对于通用数据集如alpaca数据集,将英文问题输入给模型,让模型输出中文回答。
信息抽取(IE)数据集
英文数据集:对于如CoNLL ACE CASIS等开源的IE英文数据集,直接构造相应的英文指令数据集;
中文数据集:除了使用了开源的数据集如DuEE、PEOPLE DAILY、DuIE等,还采用了我们自己构造的KG2Instruction,构造相应的中文指令数据集。
KG2Instruction(InstructIE)是一个在中文维基百科和维基数据上通过远程监督获得的中文信息抽取数据集,涵盖广泛的领域以满足真实抽取需求。
此外,还额外手动构建了中文的通用数据集,使用第二种策略将其翻译成英文。最后得到的数据集分布如下:
| 数据集类型 | 条数 |
|---|---|
| COT(中英文) | 202,333 |
| 通用数据集(中英文) | 105,216 |
| 代码数据集(中英文) | 44,688 |
| 英文指令抽取数据集 | 537,429 |
| 中文指令抽取数据集 | 486,768 |
KG2Instruction及其他指令微调数据集 流程示意图
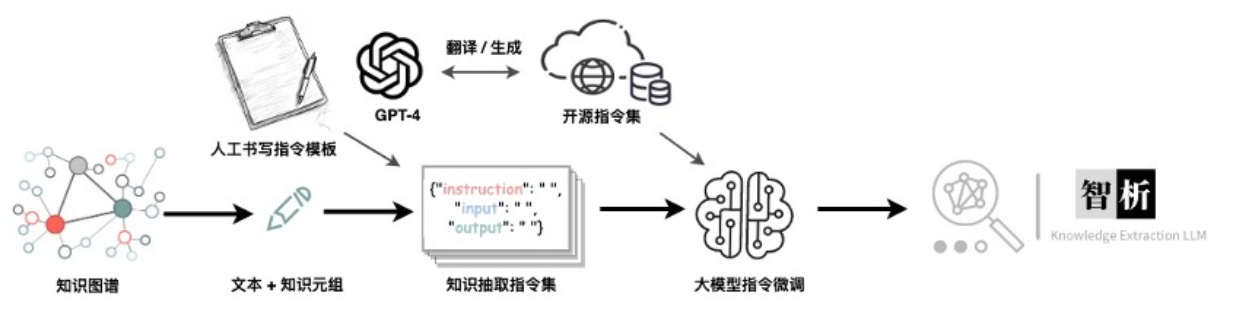
指令微调训练过程
目前大多数的微调脚本都是基于alpaca-lora,因此此处不再赘述。详细的指令微调训练参数、训练脚本可以在./finetune/lora找到。
开源的数据集及模型
| 类别 | 底座 | 名称 | 版本 | 下载链接 | 备注 |
|---|---|---|---|---|---|
| 基础模型 | LlaMA1 | KnowLM-13B-Base | V1.0 | HuggingFace | 底座模型 |
| 对话模型 | LlaMA1 | KnowLM-13B-ZhiXi | V1.0 | HuggingFace | 抽取模型 |
| 对话模型 | LlaMA1 | KnowLM-13B-IE | V1.0 | HuggingFace | 抽取模型 |
| 指令类型 | 数量 | 下载地址 | 智析是否使用 | 说明 |
|---|---|---|---|---|
| KnowLM-CR (推理相关指令数据,中英双语) | 202,333 | 谷歌云盘 HuggingFace | 是 | 无 |
| KnowLM-IE (抽取相关指令数据,中文) | 281,860 | 谷歌云盘 HuggingFace | 是 | 由于采用远程监督,因此存在噪音 |
| KnowLM-Tool (工具学习相关指令数据,英文) | 38,241 | 谷歌云盘 HuggingFace | 否 | 将在下一个版本使用 |
数据说明:
- 信息抽取的其他数据源来源于
CoNLLACEcasisDuEEPeople DailyDuIE等; KnowLM-Tool数据集来源于论文《Making Language Models Better Tool Learners with Execution Feedback》,github链接位于此处。KnowLM-IE数据集来源于论文《InstructIE: A Chinese Instruction-based Information Extraction Dataset》,github链接位于此处。
局限性
-
指令微调并没有使用全量指令微调,而是使用了LoRA的方式进行微调;
-
模型暂不支持多轮对话;
-
尽管致力于模型输出的有用性、合理性、无害性,但是在一些场景下,仍然会不可避免的出现有毒的输出;
-
预训练不充分,虽然准备了大量的预训练语料,但是没有完全跑完(没有足够的计算资源!);
信息抽取Prompt
对于信息抽取任务,比如命名实体识别(NER)、事件抽取(EE)、关系抽取(RE),提供了一些prompt便于使用,可以参考此处。当然你也可以尝试使用自己的Prompt。
relation_template = {0:'已知候选的关系列表:{s_schema},请你根据关系列表,从以下输入中抽取出可能存在的头实体与尾实体,并给出对应的关系三元组。请按照{s_format}的格式回答。',1:'我将给你个输入,请根据关系列表:{s_schema},从输入中抽取出可能包含的关系三元组,并以{s_format}的形式回答。',2:'我希望你根据关系列表从给定的输入中抽取可能的关系三元组,并以{s_format}的格式回答,关系列表={s_schema}。',3:'给定的关系列表是:{s_schema}\n根据关系列表抽取关系三元组,在这个句子中可能包含哪些关系三元组?请以{s_format}的格式回答。',
}relation_int_out_format = {0:['"(头实体,关系,尾实体)"', relation_convert_target0],2:['"关系:头实体,尾实体\n"', relation_convert_target2],3:["JSON字符串[{'head':'', 'relation':'', 'tail':''}, ]", relation_convert_target3],
}en_relation_template = {0: 'Identify the head entities (subjects) and tail entities (objects) in the following text and provide the corresponding relation triples from relation list {s_schema}. Please provide your answer as a list of relation triples in the form of {s_format}.',1: 'Identify the subjects and objects in the text that are related, and provide the corresponding relation triples from relation {s_schema} in the format of {s_format}.',2: 'From the given text, extract the possible head entities (subjects) and tail entities (objects) and give the corresponding relation triples. The relations are {s_schema}. Please format your answer as a list of relation triples in the form of {s_format}.',3: 'Your task is to identify the head entities (subjects) and tail entities (objects) in the following text and extract the corresponding relation triples, the possible relation list is {s_schema}. Your answer should include relation triples, with each triple formatted as {s_format}.',4: 'Given the text, extract the possible head entities (subjects) and tail entities (objects) and provide the corresponding relation triples, the possible relation list is {s_schema}. Format your answer as a list of relation triples in the form of {s_format}.',5: 'Your goal is to identify the head entities (subjects) and tail entities (objects) in the text and give the corresponding relation triples. The given relation list is {s_schema}. Please answer with a list of relation triples in the form of {s_format}.',6: 'Please extract the possible head entities (subjects) and tail entities (objects) from the text and provide the corresponding relation triples from candidate relation list {s_schema}. Your answer should be in the form of a list of relation triples: {s_format}.',7: 'Your task is to extract the possible head entities (subjects) and tail entities (objects) in the given text and give the corresponding relation triples. The relations are {s_schema}. Please answer using the format of a list of relation triples: {s_format}.',8: 'Given the {s_schema}, identify the head entities (subjects) and tail entities (objects) and provide the corresponding relation triples. Your answer should consist of relation triples, with each triple formatted as {s_format}',9: 'Please find the possible head entities (subjects) and tail entities (objects) in the text based on the relation list {s_schema} and give the corresponding relation triples. Please format your answer as a list of relation triples in the form of {s_format}.',10: 'Given relation list {s_schema}, extract the possible subjects and objects from the text and give the corresponding relation triples in the format of {s_format}.',11: 'Extract the entities involved in the relationship described in the text and provide the corresponding triples in the format of {s_format}, the possible relation list is {s_schema}.',12: 'Given relation list {s_schema}, provide relation triples for the entities and their relationship in the text, using the format of {s_format}.',13: 'Extract the entities and their corresponding relationships from the given relationships are {s_schema} and provide the relation triples in the format of {s_format}.',
}en_relation_int_out_format = {0: "{'head':'', 'relation':'', 'tail':''}",1: "(Subject, Relation, Object)",2: "[Subject, Relation, Object]",3: "{head, relation, tail}",4: "<head, relation, tail>",
}
部署
环境配置
# 下载 KnowLM 仓库代码
git clone https://github.com/zjunlp/KnowLM.git
# 进入KnowLM目录
cd KnowLM
# 激活conda环境
source activate
# 新建一个conda环境
conda create -n knowlm python=3.9 -y
# 进入knowlm的conda环境
conda activate knowlm
# 安装GPU版本的torch
pip install torch==1.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
# 安装其他相关依赖
pip install -r requirements.txt
模型下载
由于huggingface模型下载不稳定,故可以使用 https://hf-mirror.com 来下载模型,相关命令如下:
pip install -U huggingface_hubexport HF_ENDPOINT=https://hf-mirror.comexport HF_HOME='~/autodl-tmp/.cache/huggingface/hub'
# 下载 knowlm-13b-base
huggingface-cli download --resume-download --local-dir-use-symlinks False zjunlp/knowlm-13b-base-v1.0 --local-dir knowlm-13b-base-v1.0
# 下载 knowlm-13b-zhixi
huggingface-cli download --resume-download --local-dir-use-symlinks False zjunlp/knowlm-13b-zhixi --local-dir knowlm-13b-zhixi
预训练模型使用
python examples/generate_finetune_web.py --base_model /root/autodl-tmp/knowlm-13b-base-v1.0
LoRA模型使用
python examples/generate_lora_web.py --base_model /root/autodl-tmp/knowlm-13b-zhixi
相关文章:
KnowLM知识抽取大模型
文章目录 KnowLM项目介绍KnowLM项目的动机ChatGPT存在的问题 基于LLama的知识抽取的智析大模型数据集构建及训练过程预训练数据集构建预训练训练过程指令微调数据集构建 指令微调训练过程开源的数据集及模型局限性信息抽取Prompt 部署环境配置模型下载预训练模型使用LoRA模型使…...
MySQL数据库 索引
目录 索引概述 索引结构 二叉树 B-Tree BTree Hash 索引分类 索引语法 慢查询日志 索引概述 索引 (index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种…...

ES 错误码
2xx状态码(如200)表示请求成功处理,并且不需要重试。 400状态码表示客户端发送了无效的请求,例如请求的语法有误或缺少必需的参数。在这种情况下,重试相同的请求很可能会导致相同的错误。因此,应该先检查并…...

听GPT 讲Rust源代码--src/tools(18)
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/from_comment.rs 在Rust源代码中的from_comment.rs文件位于Rust分析器(rust-analyzer)工具的ide-ssr库中,它的作用是将注释转换为Rust代码。 具体来说,该文件实现了从注…...

如何实现设备远程控制?
在工业自动化领域,设备远程控制是一项非常重要的技术。它使得设备可以在远离现场的情况下进行远程操作和维护,大大提高了设备的可用性和效率。 设备远程控制的应用场景有哪些? 远程故障排除:当设备出现故障时,工程师…...

百度侯震宇详解:大模型将如何重构云计算?
12月20日,在2023百度云智大会智算大会上,百度集团副总裁侯震宇以“大模型重构云计算”为主题发表演讲。他强调,AI原生时代,面向大模型的基础设施体系需要全面重构,为构建繁荣的AI原生生态筑牢底座。 侯震宇表示&…...

[Java]FileOutputStream的换行/续写/一次性写出一个字符串的方法
1.续写:FileOutputStream这个io流中的write方法默认情况下是覆盖写入的,如果需要追加写入,需要添加一个参数true 2.虽然write只能一个字符一个字符写入 但是我们可以把想输入的字符串放在str 再将str转化成byte数组 import java.io.FileOutp…...

VM进行TCP/IP通信
OK就变成这样 vm充当服务端的话也是差不多的操作 点击连接 这里我把端口号换掉了因为可能被占用报错了,如果有报错可以尝试尝试换个端口号 注: 还有一个点在工作中要是充当服务器,要去网络这边看下他的ip地址 拉到最后面...

剑指Offer 队列栈题目集合
目录 用两个栈实现队列 用两个栈实现队列 刷题链接: https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6 题目描述 思路一: 使用两个栈来实现队列的功能。栈 1 用于存储入队的元素,而栈 2 用于存储出队的元素。 1.push…...

grafana基本使用
一、安装grafana 1.下载 官网下载地址: https://grafana.com/grafana/download官网包的下载地址: yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.2.2-1.x86_64.rpm官网下载速度非常慢,这里选择清华大…...
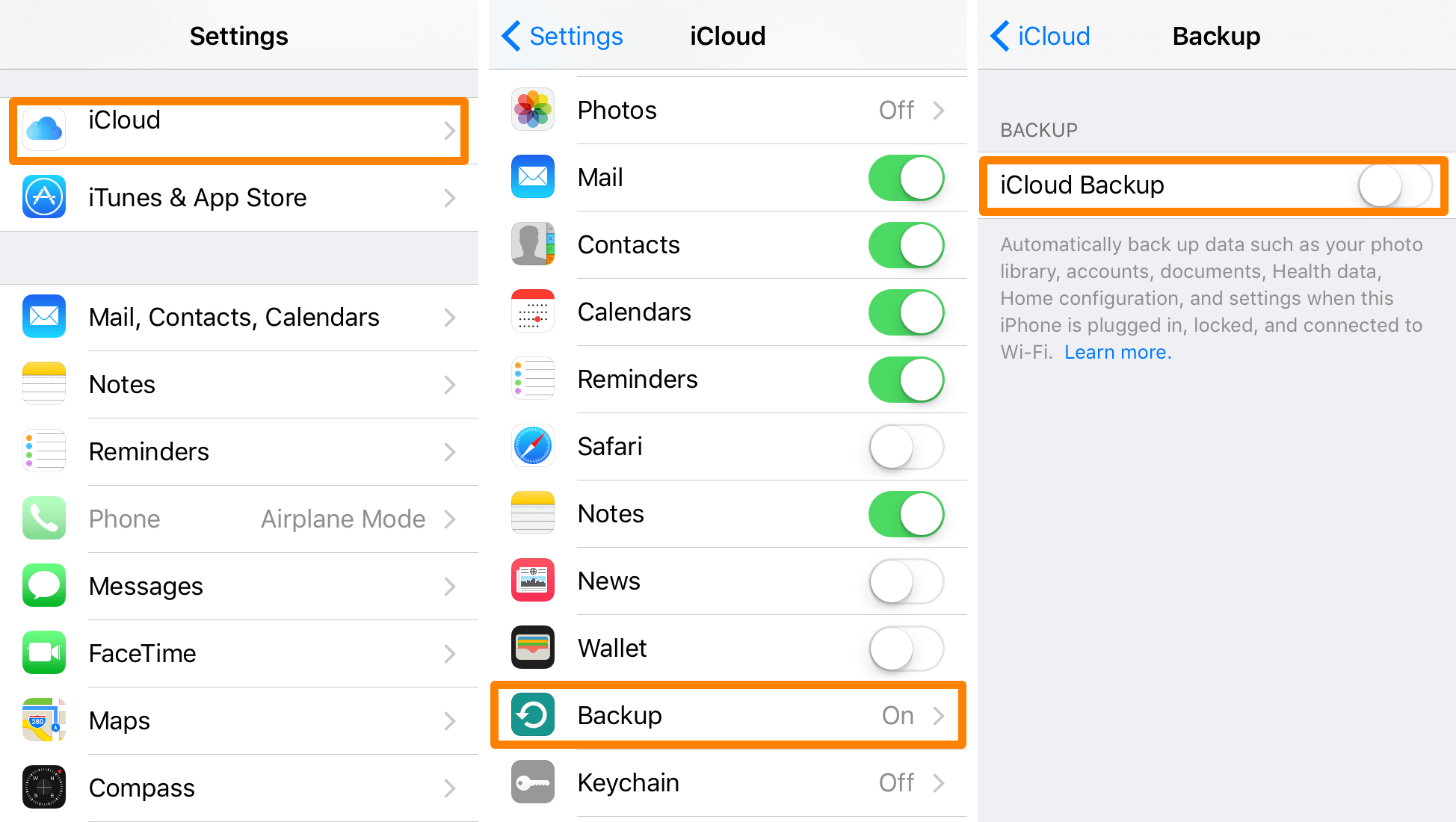
备份至关重要!如何解决iCloud的上次备份无法完成的问题
将iPhone和iPad备份到iCloud对于在设备发生故障或丢失时确保数据安全至关重要。但iOS用户有时会收到一条令人不安的消息,“上次备份无法完成。”下面我们来看看可能导致此问题的原因,如何解决此问题,并使你的iCloud备份再次顺利运行。 这些故…...

【项目问题解决】% sql注入问题
目录 【项目问题解决】% sql注入问题 1.问题描述2.问题原因3.解决思路4.解决方案1.前端限制传入特殊字符2.后端拦截特殊字符-正则表达式3.后端拦截特殊字符-拦截器 5.总结6.参考 文章所属专区 项目问题解决 1.问题描述 在处理接口入参的一些sql注入问题,虽然通过M…...
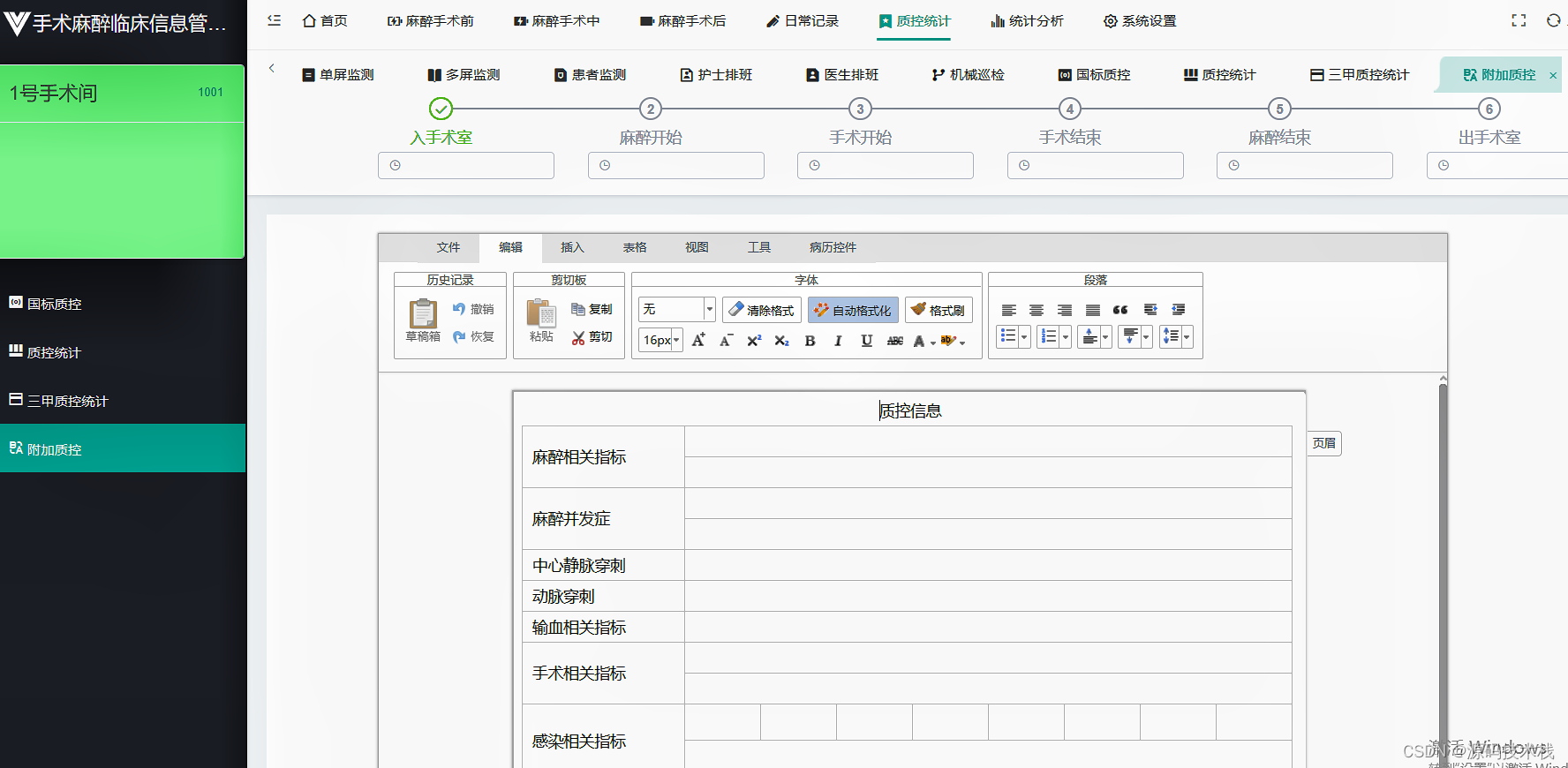
B/S医院手术麻醉临床管理系统源码 手术申请、手术安排
手术麻醉系统概述 手术室是医院各个科室工作交叉汇集的一个重要中心,在时间、空间、设备、药物、材料、人员调配的科学管理、高效运作、安全质控、绩效考核,都十分重要。手术麻醉管理系统(Operation Anesthesia Management System࿰…...

解锁高效工作!5款优秀工时管理软件推荐
工时管理,一直是让许多企业和团队头疼的问题。传统的纸质工时表、复杂的电子表格,不仅操作繁琐,还容易出错。幸好,随着科技的进步,我们迎来了工时管理软件的春天。今天,就让我们一起走进这个新时代…...

ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》 论文地址:https://openreview.net/forum?id=3bq3jsvcQ1 …...
边缘计算有哪些常用场景?TSINGSEE边缘AI视频分析技术行业解决方案
随着ChatGPT生成式人工智能的爆发,AI技术在业界又掀起一波新浪潮。值得关注的是,边缘AI智能也在AI人工智能技术进步的基础上得到了快速发展。IDC跟踪报告数据显示,2021年我国的边缘计算服务器整体市场规模达到33.1亿美元,预计2020…...

配置BGP的基本示例
目录 BGP简介 BGP定义 配置BGP目的 受益 实验 实验拓扑 编辑 组网需求 配置思路 配置步骤 配置各接口所属的VLAN 配置各Vlanif的ip地址 配置IBGP连接 配置EBGP 查看BGP对等体的连接状态 配置SwitchA发布路由10.1.0.0/16 配置BGP引入直连路由 BGP简介 BGP定义 …...
Flask解决接口跨域问题
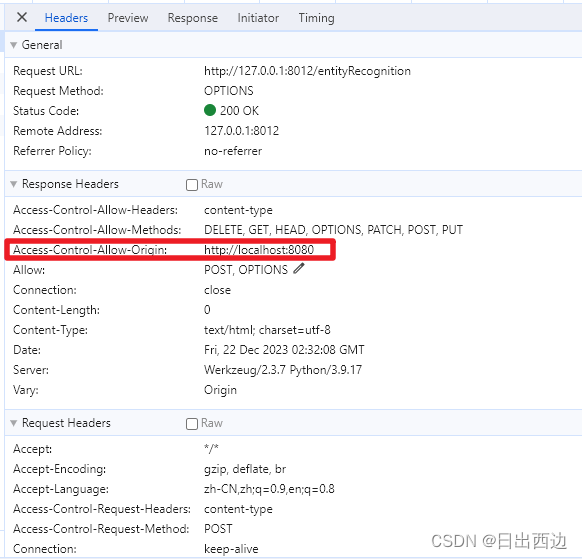
1、什么是跨域CROS CORS(Cross-Origin Resource Sharing,跨域资源共享)是一种浏览器安全策略,用于控制在一个网页应用中如何让一个域的Web页面能够请求另一个域的资源。在Web开发中,由于同源策略(Same-Ori…...
数据恢复工具推荐!这3款堪称删除文件恢复大师!
“快看看我!经常都会莫名奇妙丢失各种电脑文件,但是又无法通过简单的方法找回重要的数据,有没有什么简单的操作可以帮助我快速恢复数据的呀?非常感谢!” 在我们的日常生活中,无论是工作还是学习,…...

论文笔记 | ICLR 2023 ReAct:通过整合推理和行动来增强语言模型
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《ReAct: Synergizing Reasoning and Acting in Language Models》 一句话总结:ReAct 方法在问答任务中通过提示大语言模型生成与任…...

从FinFET到ESD设计:2013年半导体产业技术演进与工程实践启示
1. 行业动态聚焦:2013年4月,EDA/IP领域的那些关键信号作为一名在芯片设计行业摸爬滚打了十几年的老兵,我习惯每周花点时间翻翻行业新闻,不是为了追热点,而是想从那些看似零散的公告里,嗅出技术演进和产业协…...

豆包大模型免费API调用实战:逆向工程原理、集成方案与风险规避
1. 项目概述与核心价值最近在折腾大模型应用开发的朋友,估计都绕不开一个核心问题:API调用成本。无论是做个人项目练手,还是小团队内部测试,动辄按token计费的商业API,账单看着都让人心疼。特别是当你需要频繁调用、进…...

智能算法车队换道决策与轨迹规划【附仿真】
✨ 长期致力于车队换道、支持向量机、决策树、换道决策、多目标优化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)NGSIM数据清洗与特征重构…...

M4Markets:技术架构稳健性的多角度观察
在金融服务行业不断深化的当下,平台的综合实力已经成为客户筛选时的关注焦点。M4Markets作为活跃在国际金融领域的服务机构,多年来在多个维度展现出较为突出的特点。本文将从评测视角出发,对其综合表现进行多维度的观察与解读,希望…...

浏览器光标锁定技术:Pointer Lock API与全屏API实战指南
1. 项目概述:一个解决浏览器光标“越狱”问题的实用工具如果你是一名前端开发者,或者经常需要制作在线演示、录屏教程,甚至是在开发一个网页端的游戏,那你一定遇到过这个让人头疼的问题:鼠标光标在网页里“不老实”。当…...

2026年测试工程师常用性能测试平台:高效办公与场景适配指南
测试工程师作为性能测试的核心执行者,对性能平台的需求聚焦于高效办公、功能全面、易用性强、问题定位精准四大维度。测试工程师日常工作涵盖脚本开发、场景编排、压测执行、监控分析、报告生成等多个环节,合适的性能平台,能够提升工作效率&a…...

Ubuntu服务器性能检测工具NetData安装
1. NetData安装 打开Ubuntu终端并输入以下指令: $ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)中途会提示安装文件将为占用磁盘空间,是否继续(Y/N),输入Y即可,安装完成后的截图如下…...

Windows XP图标主题:如何在现代Linux桌面重现经典视觉体验
Windows XP图标主题:如何在现代Linux桌面重现经典视觉体验 【免费下载链接】Windows-XP Remake of classic YlmfOS theme with some mods for icons to scale right 项目地址: https://gitcode.com/gh_mirrors/win/Windows-XP 还在为现代桌面环境的单调图标感…...

网易有道发布企业级大模型聚合服务ThinkFlow,终结多模型适配困局,推动应用工程化
5月13日,网易有道正式发布企业级大模型聚合服务ThinkFlow。它将20余款主流大模型统一调度,解决多模型适配难题,还保障稳定、控制成本与安全,推动大模型应用工程化。ThinkFlow:多模型聚合新方案据有道智云平台消息&…...

FPG财盛国际:投资者教育生态的全面布局
FPG财盛国际:投资者教育生态的全面布局金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG财盛国际经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行…...